
基于SRv6技术的云网安全服务链自动编排方法
2024-03-05 08:19王宏杰徐胜超毛明扬蒋金陵
计算机与现代化 2024年1期
王宏杰,徐胜超,杨 波,毛明扬,蒋金陵
(广州华商学院数据科学学院,广东 广州 511300)
0 引 言
近年来云计算模式逐步向云网融合(简称“云网”)方向发展,云网最典型的应用是5G网络技术,云网可以提供多样化的云服务,使得越来越多的用户与企业使用云网存储和处理数据。这些数据包括隐私和其他重要信息,如果数据发生泄露或遭到攻击,会对用户造成损失。为此,将多个云计算环境中的安全服务进行组合,形成一个安全服务链路,可提供全面的云网安全保护。在此基础上,为了控制整个安全服务流程的执行顺序,需进行服务链编排,确保服务链按照正确的顺序和条件被调用,从而实现预期的业务逻辑。
云网在后台的实现最重要的是使用基于SRv6的服务链技术。SRv6 是一种基于IPv6 的段路由技术,可以根据源路由的状态实时编程报文转发路径,提高云网的性能。服务链自动编排是通过自动化组合与编排多个服务链来满足不同场景中的业务需求,动态调整服务链的安全策略,实现对网络安全服务的自动编排的。利用服务链自动编排可以提升云网安全等级,所以云网融合中提高服务链自动编排能力至关重要,值得深入研究。
文献[1]提出一种零接触网络编排法,在端平台基础上,通过对网络数据的监控和合理配置实现服务链的自主编排;文献[2]研究一种实时无缝编排法,利用服务端之间的保护机制,实现网络服务平台的异构,在网络管理的基础上,实现服务链的自动更新,添加一定的资源配置条件,实现服务链的编排。上述2种方法对服务链的可编程性不高,因此产生的消耗也较大。文献[3]利用网络功能虚拟化(Network Functions Virtualization,NFV)架构,提出一种服务功能链动态编排算法。通过广度优先搜索算法寻找最短路径,利用蚁群优化算法生成最优解,实现服务功能链编排。文献[4]将区块链技术与软件定义网络(Software Defined Network,SDN)结合,构建基于联盟链的异构物联网网络资源管理模型,部署轻节点和全节点;利用身份识别的思想,实现身份识别和资源信息的分离,构建链上身份识别和链下信息的模型,通过深度强化学习进行服务功能链编排,设计基于异步优势的服务功能链编排算法,优化编排,取得了较好的云网性能。
在上述研究的基础之上,本文提出一种基于SRv6 技术的云网安全服务链自动编排方法,采用SRv6 技术设计数据传输过程,提高服务链的可编程性,实现云网安全服务链自动编排的双向支持。针对云网安全服务链自动编排过程中的带宽消耗高的问题,本文设置约束条件获取最优解,不仅有效提高请求成功率,同时减小带宽消耗,提高有效传输的能力。基于决策节点和流调节点配置策略,本文通过控制器生成指令并下达至交换机,完成云网安全服务链自动编排。
1 基于SRv6技术的云网可编程性设置
SRv6 属于源路由技术[5],可以实现对节点和路径的自由选择,具备辅助和引导网络数据包沿着指定路径通过云网的功能,报文转发过程中依托于SRv6的目的地址信息[6],指导报文的具体转发路径,通过在目的地址中指定服务链标识,报文根据指定服务链顺序依次经过不同的安全服务链,完成服务节点的安全防护,从而实现灵活的网络路径选择以及网络服务链编排,优化网络流量。
SRv6 技术可以应用在多种设备上完成技术支持,在服务器、客户端和网络节点均支持SRv6技术的情况下,服务器可作为SRv6 源节点的分类器[7]。服务节点负责定义本地行为,利用网络节点处理SRv6报文,根据服务ID 实现具体的调用服务,通过客户端实现计算优先云网中的数据传输,可以免除对服务节点的依赖,减少算力路由的消耗。数据源地址实际对应的是客户端IP,报文传送目的地址对应的是服务IP,将计算优先云网节点开始时数据传输的第一跳作为服务节点IP,第二跳作为服务ID。当服务节点收到云网传输数据包时,左侧分端减1,节点根据安全状态查询对应绑定服务器,实时反馈调用结果[8],通过动态调度和实时反馈结果,能够有效降低故障率,提高请求成功率。
选择服务节点对应端口或回送IP 作为服务ID,服务节点在调用ID 时,需要通过选择出来的端口或者回送IP,倘若服务节点正好位于云网入口位置[9],此时服务ID 与云网内的服务器IP 相照应,等待节点的实时调用。云网内客户端在请求服务过程中产生的数据传输如图1所示。
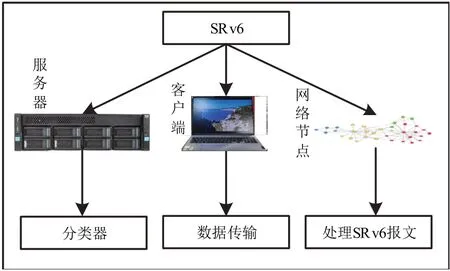
图1 SRv6技术下的数据流示意图
将计算优化云网节点作为SRv6 的源节点池,利用节点定义本地行为并处理SRv6 报文,解除对SRv6数据的封装,在代理节点的辅助下,能有效地转换报文协调传输程度,实现对云网安全服务链自动编排的双向支持,在此基础上可实现对后续自动编排的部署[10]。
2 云网安全服务链自动编排的约束条件
通过云网可编程性设置,可完成云网安全服务链自动编排的双向支持。然而在自动编排过程中需要考虑多种约束条件,安全服务链上的请求量须小于等于对应物理节点所能提供的资源量,同时带宽请求量也需要小于等于云网安全链路上的带宽提供量,虚拟链路与实际物理路径之间只能有一段映射,为此描述各类约束条件[11]。
为了减少云网安全服务链自动编排过程中的带宽消耗[12],本文将最小化总带宽设定为自动编排目标minu(li),L表示云网中的物理链路集合,li表示链路集合中包含的某段链路,u(li)表示该段链路上对应的实际带宽消耗量[13-14]。
节点约束是虚拟网络功能放置中的约束条件之一,目的是保证云网安全服务链上需要的虚拟内存等,并满足其不超过放置物理节点的提供量,具体的约束过程如下:
其中,N表示云网拓扑结构中所有物理节点的集合,ni表示云网安全服务链路中的某一物理节点,Mni为ni上已存放的虚拟机实例集合,Vni表示放置在ni上的所有云网虚拟网络功能集合,表示云网安全服务链对应的业务组合,mj表示ni上已存放的信息实例集合中一个单元因子,R表示虚拟网络功能中请求的资源类型种类集合,r表示其中的某一类资源,表示单元因子相对于r类资源的数据请求数量,表示物理节点ni对于r类资源所能提供的数据量。
在云网安全服务链路中放置虚拟网络功能,主要分为服务链路上架构出的虚拟链路和云网拓扑结构中实际包含的物理链路。链路约束[15]也是保证服务链自动编排实现的约束条件之一,它能保证带宽的提供量在可控范围内:
其中,S(li)表示在链路li所能提供出的带宽总量,针对随机物理链路而言,u(li)不能超过S(li),C表示映射在云网服务链路上的所有请求,P表示云网服务功能链上接受到的请求,pj表示云网安全服务请求中对应的虚拟业务链路,w(pj)表示虚拟业务链路pj实际对应的物理链路集合表示虚拟业务链路pj中接收到的带宽资源请求量[16]。
映射约束主要保证虚拟网络功能以及物理节点之间实现资源配置平衡:
其中,v表示节点对应资源状态,φ为空集符号,表示物理节点的资源约束条件。
根据以上约束关系式可以更好地实现云网安全服务链在虚拟功能网络中的自动编排,达到多个条件在同一时间内获取到最优解[17]。
3 云网安全服务链自动编排过程
在获取云网安全服务链自动编排的约束条件后,针对云网安全防护方案,需建立自动编排部署框架。根据上层用户的安全业务需求和自动架构服务链策略,实现虚拟安全设备保护功能,将正在传输的数据流安全调度到虚拟安全设备中,达到传输序列的安全防护。本文主要用到粒子群算法实现自动编排过程,具体如下:
步骤1初始化粒子群,随机生成一组粒子,每个粒子代表一个可能的策略组合,也称为编排解。
步骤2根据预定的评估函数,对每个粒子进行适应度评估。
步骤3记录粒子群中适应度最好的粒子的位置,即全局最优解。
步骤4通过考虑个体历史最优位置和全局最优位置更新每个粒子的速度和位置。
步骤5重复执行步骤2~步骤4,直到满足终止条件,获取适应度最好的粒子的位置,该位置即为最优解,对应于最佳的安全服务链策略组合。
步骤6根据最优解所代表的最佳策略组合,使用自动化编排工具或其他相关工具,实施和部署安全服务链,不断优化和调整,完成自动编排过程。
云网安全服务链自动编排部署框架能够自动实现服务链策略的编排和虚拟安全设备的自动部署,将数据流安全调度到相应的虚拟安全设备中进行安全防护,提高安全防护可靠性,并降低管理工作量。在这一过程中需要完成2 个关键性的问题:1)解决在云网安全服务链自动编排中的策略冲突问题[18];2)解决网络流调度优化条件。为解决这2 个问题,本文设计自动编排部署框架,如图2所示。
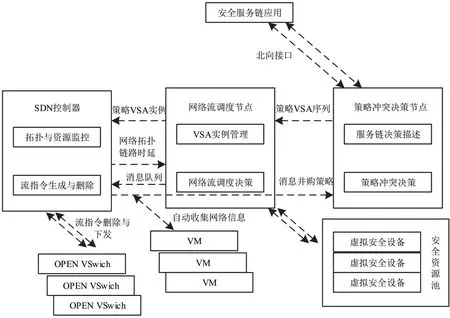
图2 云网安全服务链自动编排部署框架
在自动编排决策发生冲突的情况下,云网安全的决策节点首先通过开放北向接口[19],自动为云网用户提供网络安全防护服务。在构建安全入侵检测防护的同时,应增加对云网用户流量清洗,将2 种防护有机结合成安全服务链策略,把用户的访问数据流引入策略序列中,实现对安全访问和数据流属性的细粒度控制[20]。但受到前后策略不同的影响,很可能导致执行动作之间存在一定的冲突,这时使用自动化编排工具Ansible 编写编排逻辑,可以自动协调和管理各个服务之间的关系,使得决策节点根据网络服务链的优先级来正确编排网络流传输,消除云网中的冲突,减少网络拥塞,从而减轻CPU 负载,降低CPU 利用率,同时将决策结果传输至对应的流调节点[21]。
云网安全服务链中的流调度节点负责分析和管理安全资源池内的信息实例,有效实现对负载信息的自动化监控,根据防护策略输出相应的安全流调配置,解析安全设备类型[22],从服务链实时的状态信息中评估出调度路由的最佳方案,通过消息队列,将实际配置的安全流调信息策略自动传输给云网的控制器,实现数据流量的定向处理[23]。因为消息队列采用异步通信的方式,发送方将消息发送到队列中,不需要等待接收方的响应,所以可提高安全服务链的响应速度。
云网中控制器主要负责对资源实行相对集中的控制管理,具备全局统筹能力。在此基础上对网络的拓扑结构进行监控[24-25],当某个组件或服务器出现故障时,自动化编排服务根据预设的容错策略,自动切换到备用的组件或服务器上,以自动恢复故障,提高服务链的可用性。另外,它能够实时检测并响应系统的变化和需求。在必要时给予数据流相应的指令,接收到路由调度结果后,控制器首先需要分析并生成指令,并将指令下达到交换机,可以实时完成对云网安全服务链中数据流量的定向牵引和安全防护,在这一步结束后才算完成整个安全服务链的框架部署。至此实现云网安全服务链自动编排,为组织提供可靠的安全保障,确保其关键信息和业务在云网中的安全运行。
基于上述内容可知,通过研究云网安全需求,明确上层用户的安全业务需求,根据需求设计服务链策略,确定数据流调度顺序,建立安全资源池,解析安全设备,配置决策节点和流调度节点,实现安全流调度配置和信息实时监控,利用控制器生成指令并下达至交换机。根据上述配置,将框架部署到云网环境中,即可完成SRv6的服务链编排,最后进行测试和验证,确保安全服务链的可靠运行[26-27]。
4 实验与性能分析
4.1 实验参数的设置
为了验证本文的自动编排方法的有效性,本文通过方法性能实验对比来进行验证。在实验过程中,本文随机生成较大规模的云网物理拓扑结构,建立一定数量的云网服务功能链路及用户请求,分别使用零接触网络编排法(文献[1]方法)、实时无缝编排法(文献[2]方法)和本文方法来处理生成的云网服务功能链映射请求,评估分析不同自动编排方法下的各项指标,并进行对比,同时实验中还考虑安全服务链上虚拟功能网络的数量对不同编排方法代数的影响情况。
首先完成参数设定。云网的物理拓扑结构中包含一个主要的核心层交换机,另外的交换机在聚合层和边缘层的数量分别为5 个和40 个。实验参数的具体设定情况如表1 所示。利用阿里云配置API 网关请求总数。打开API 网关控制台,进入目标API 分组的管理页面。在左侧导航栏中的“流控策略”选择“请求总数”作为流控策略类型,将安全服务功能链路的请求总数设定在500 次。为保证实验结果的真实性,在相同参数下共进行20 次测试,根据实验次数依次将安全服务链上的虚拟网络功能数量从1增加到20,每次的请求数设置为20。

表1 实验参数设定
实验使用Matlab 软件,操作系统为Windows 10,内存为16 GB,利用Matlab 软件中的Service Orchestrator 工具包导入实验所需参数,并使用不同方法分别在Matlab中进行实验。
4.2 平均总带宽消耗测试
在实验参数的基础上,对零接触网络编排法、实时无缝编排法和本文方法的平均总带宽消耗情况进行实验数据分析。实验中对云网输入相同的物理拓扑结构,对3 种方法均投入相同次数的安全服务链请求,并对比3 种算法的平均总带宽消耗。平均总带宽消耗的计算过程如公式(7)所示:
其中,D表示总数据量,T表示数据传输时间。具体情况如图3所示。

图3 3种方法下平均总带宽消耗情况
根据图3 可知,虽然零接触网络编排法的运算过程相对简单,能大大提高编排算法的效率,但是相对应的平均总带宽消耗较高,消耗量远远大于实时无缝编排法和本文方法。本文方法的变化相较于零接触网络编排法和实时无缝编排法更加平稳,在用户对云网的安全服务链请求次数不断增加的过程中,本文方法的平均总带宽消耗量能稳定维持在一定的水平区间。这主要是因为本文方法在进行服务链自动编排的过程中,将最小化总带宽设定为自动编排目标,减少了云网安全服务链自动编排过程中的总平均带宽消耗量,保证了平均总带宽消耗量能稳定维持在一定的水平区间。
4.3 请求成功率测试
接下来针对不同算法条件下的请求成功率进行对应实验分析。实验中对云网输入相同的物理拓扑结构,保证3 种方法的安全服务链请求数量相同,对零接触网络编排法、实时无缝编排法和本文方法的请求成功率进行实验分析对比。请求成功率的计算如公式(8)所示:
其中,Nc表示请求成功数,N1表示总请求数。具体的实验结果如图4所示。

图4 不同算法下的请求成功率
根据图4 可知,零接触网络编排法对应的用户安全服务链请求成功率远远低于实时无缝编排法和本文方法。对比零接触网络编排法和本文方法可以看出,随着云网用户对安全服务链的请求数量不断增多,本文方法的请求成功率能保持稳定的状态,且始终高于零接触网络编排法。这表明本文方法在节省带宽消耗的情况下,能在一定程度上有效地提高云网用户的请求成功率,实现更好的服务链自动编排。分析原因是因为通过SRv6 对服务节点进行动态调度,同时利用实时反馈结果,有效降低了系统的故障率,从而提高了请求成功率。
4.4 边缘设备的CPU负载率测试
最后为验证本文的安全服务链自动编排方法能够实现云网的正常运行,对云网内最大边缘设备的CPU负载率进行实验数据分析,其主要验证的是安全服务链网络功能之间是否存在通信开销这一类不良影响,以及经过自动编排后能否保证云网内边缘设备的负载均衡。最大边缘设备CPU 利用率的计算如公式(9)所示:
其中,c表示CPU 空闲时间,z表示CPU 总运行时间。具体的实验结果如图5所示。

图5 不同方法下最大边缘设备CPU负载率
根据图5可知,3种算法相比之下,零接触网络编排法和实时无缝编排法的边缘设备CPU 使用率相对较高,而本文方法的CPU 使用率始终没能超过1.0%,这表明本文方法在完成安全服务链自动编排的过程中,云网安全服务链的网络功能之间只存在计算开销,而零接触网络编排法和实时无缝编排法中包含了一部分的通信开销,这对云网安全服务链会造成一定的不良影响。这主要是由于构建了云网安全服务链自动编排部署框架,其中的决策节点根据网络服务链的优先级进行编排,消除云网冲突,减少网络拥塞,从而减轻了CPU负载,降低了CPU利用率。
5 结束语
本文通过SRv6 实时编程报文转发路径,可以根据源路由的状态提高网络链路的可编程性,设计编排部署框架,确定目标函数完成对应的自动编排。实验表明,本文方法能有效降低云网服务链路的平均带宽总消耗,同时提高用户对安全服务链的请求成功率,大大减小边缘设备的CPU 使用率,经过编排后能有效保证云网的稳定、快速运行。
猜你喜欢
纺织科学研究(2023年9期)2023-10-23
广东通信技术(2022年10期)2022-12-22
信息通信技术与政策(2022年11期)2022-12-06
移动通信(2021年5期)2021-10-25
电信科学(2021年8期)2021-09-10
学生天地(2020年5期)2020-08-25
军民两用技术与产品(2020年6期)2020-07-18
电子测试(2018年10期)2018-06-26
汽车博览(2016年9期)2016-10-18
交通建设与管理(2015年15期)2015-03-20
