
基于生成对抗网络的维语场景文字修改网络
2024-03-05 08:20:18付鸿林张太红杨雅婷艾孜麦提艾瓦尼尔
计算机与现代化 2024年1期
付鸿林,张太红,杨雅婷,艾孜麦提·艾瓦尼尔,马 博
(1.新疆农业大学计算机与信息工程学院,新疆 乌鲁木齐 830052;2.新疆农业信息化工程技术研究中心,新疆 乌鲁木齐 830052;3.中国科学院新疆理化技术研究所多语种信息技术研究室,新疆 乌鲁木齐 830011)
0 引 言
文本作为人类传递信息的代表,在图像理解中起到至关重要的作用。随着深度学习技术的进步,基于深度学习的场景文本检测算法得到了很大的发展,与传统方法相比,检测精度有了明显提升。深度学习之所以在计算机视觉中取得成功可以归功于以下3 个方面:1)模型容量增大;2)硬件设备计算效率的提高;3)拥有大量标记数据可供使用。随着高性能移动设备的快速发展和普及,场景文本检测和识别技术已经成为计算机视觉领域的一个研究热点。与文档OCR相比,场景文本检测和识别仍然存在很大的问题,比如文本的多样性、复杂多变的图像背景,以及外部因素的干扰(光照不均、分辨率低等因素)。目前,学术界公开的场景文本数据集(如ICDAR2013、SVT、RCTW 等)大多局限于主流文字(英文、中文等),而对少数民族语言和多语言的检测和识别的数据集很少。因此,少数民族语言和多语种的场景文本数据集具有很高的研究价值和意义。
场景文本检测和识别是一项具有挑战性但非常有用的任务。在数据驱动的深度学习时代,数据集的大小将直接决定模型的性能。近年来,越来越多的文本图像合成方法被用于场景文本检测和识别任务中。这些方法结合不同的渲染算法进行建模,将文字渲染到背景图像上。然而,如果合成的图像与真实图像不能完美契合,这将影响后续模型的训练精度。
本文主要讨论现实场景中的维文替换问题。据知,目前没有针对维语的场景文字修改网络被提出。替换自然场景中的维文的任务可以表示为:用户提供的任意的维文文本替换图像中存在的文本,并且替换结果难以区分。因此,在进行文本替换的同时,要尽可能保留原始图像文本的字体、颜色、大小和图像背景,从而使生成的图像具有更真实的视觉效果。本文延续了SRNet[1]的框架思想,采用“分而治之”的策略,将场景文字修改任务分解为3 个子任务:文字风格迁移、背景修复和融合。本文方法也是通过GAN替换场景文本。与其他方法不同之处在于,本文引入高效的Transformer 模块[2]重构网络,优势在于:1)在可以提取图像全局特征的前提下,相比传统视觉Transformer 模块,计算量大大减少;2)在背景修复阶段,可以综合整张背景图像信息,选取合适的纹理对文字区域进行填充,修复效果更佳;3)将卷积神经网络强大的局部特征提取能力融入网络中。此外,由于模型通过不同模块之间协作完成场景文字修改,考虑到不同模块的输出结果在融合阶段出现偏差,通过添加微调模块对融合结果进行微调。采用WGAN 思想训练网络,相比原生成对抗训练方法,可有效应对模型崩溃、梯度爆炸等问题。由于真实场景中没有成对的数据集,本文使用合成数据对模型进行训练,在真实场景图像上进行测试。
1 相关研究
1.1 GAN
生成对抗网络自2014 年由Goodfellow[3]提出以来,其在计算机视觉中得到广泛应用,如图像生成[4-5]、艺术品生成[6]和视频生成[7]。此外,可通过对抗训练[8]来执行提高图像质量、风格转移[9]、图像修复[10]、图像超分辨率[11]和其他任务。CGAN[12]通过添加条件,使生成任务变得可控,增加可解释性。DCGAN[13]首次将卷积神经网络(CNN)引入到GAN中,解决了训练不稳定、模型崩溃的问题。Stack-GAN[14]探索文本到图像的转换,并创建文本描述的内部表示。StyleGAN[15]提出了一种基于风格的生成器,以实现深层空间解耦,使生成图像更加生动清晰。
1.2 场景文字修改
目前已经存在一些场景文字修改的相关工作,最初的场景文字修改模型[16]是对每个字符做修改,尽管该方法可以应用到真实场景文字图像中,但不能应对原始图像中文字长度与目标文字长度不同的情况,进而影响模型生成性能。SRnet[1]为词级别的STE 模型,模型整体结构为CNN,在提取特征时,无法获得全局上下文信息。SwapText[17]通过TPS 算法,提取风格图像文字位置特征应用于目标文字,在文字风格迁移模块中加入自注意力机制,在一定程度上缓解CNN 本身的限制。RewriteNet[18]模型通过引入场景文字识别模型,将场景文字图像中文字内容与风格进行解耦,通过识别模型提取文本内容信息,但当识别错误时,误差也将进一步传递,造成生成图像中文字内容错误。TextStyleBrush[19]通过对场景文字图像风格与内容解耦,将风格特征进行映射,在合成图像时与文字内容特征多尺度融合,以及通过引入预训练识别模型进行识别校正,但该模型并不适用于跨语言的场景文字修改。Zhang 等人[20]将通道注意力机制嵌入SRnet 风格迁移模块,以及监督图像中文字结构信息,生成藏语场景文字图像。PsGAN[21]在训练时需要借助文字边界检测器,同时无法应对文字较小的情况。
2 本文方法
2.1 模型结构
本文提出的场景文字修改模型,简称TFGAN,主要由3个子网络组成,分别为文字风格迁移模块、背景修复模块以及融合模块。模型总体结构如图1所示。
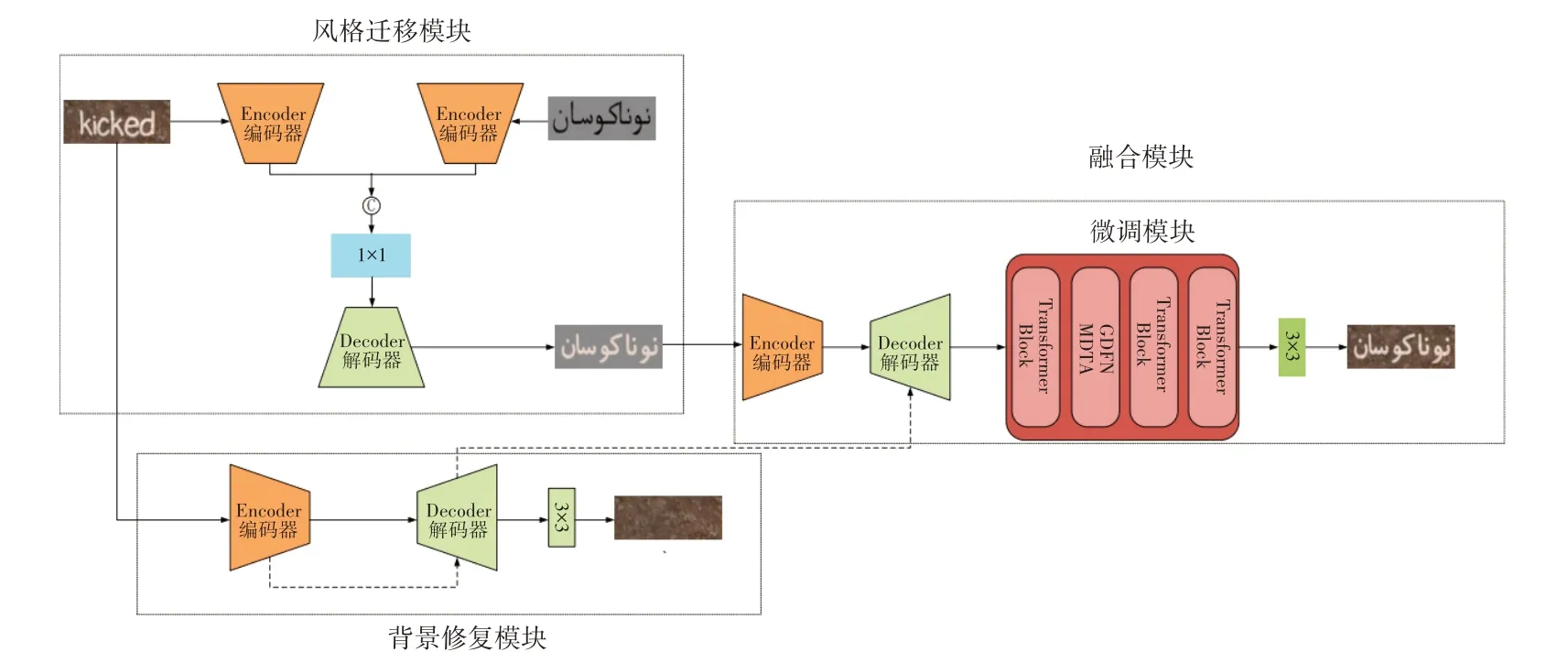
图1 TFGAN模型总体结构图
文字风格迁移模块的目的在于提取原始风格图像的前景风格特征,将其迁移到目标文字上。前景风格特征包括字体、字体颜色、文字布局等。文字风格迁移模块的输入为风格图像和目标文字图像,输出为语义信息和目标文字,且风格保持原始图像前景风格。它使用编码器和解码器模块来完成相应计算。在编码器中,原始图像通过一个3×3尺度不变卷积将通道扩为48,再经过3 次下采样和8 个Transformer 模块,其中每次下采样之后都经过不同数量的Transformer 模块。目标文字图像采用相同的编码操作。将2 个编码器得到的输出特征按深度进行连接。在特征输入解码器之前对编码器的输出经过1×1 卷积使得通道数减半。在解码器中,经过3 次上采样,每次上采样后都经过不同数量的Transformer 模块。具体参数如表1 所示,其中TF 代表Transformer 模块,down表示下采样,up表示上采样。
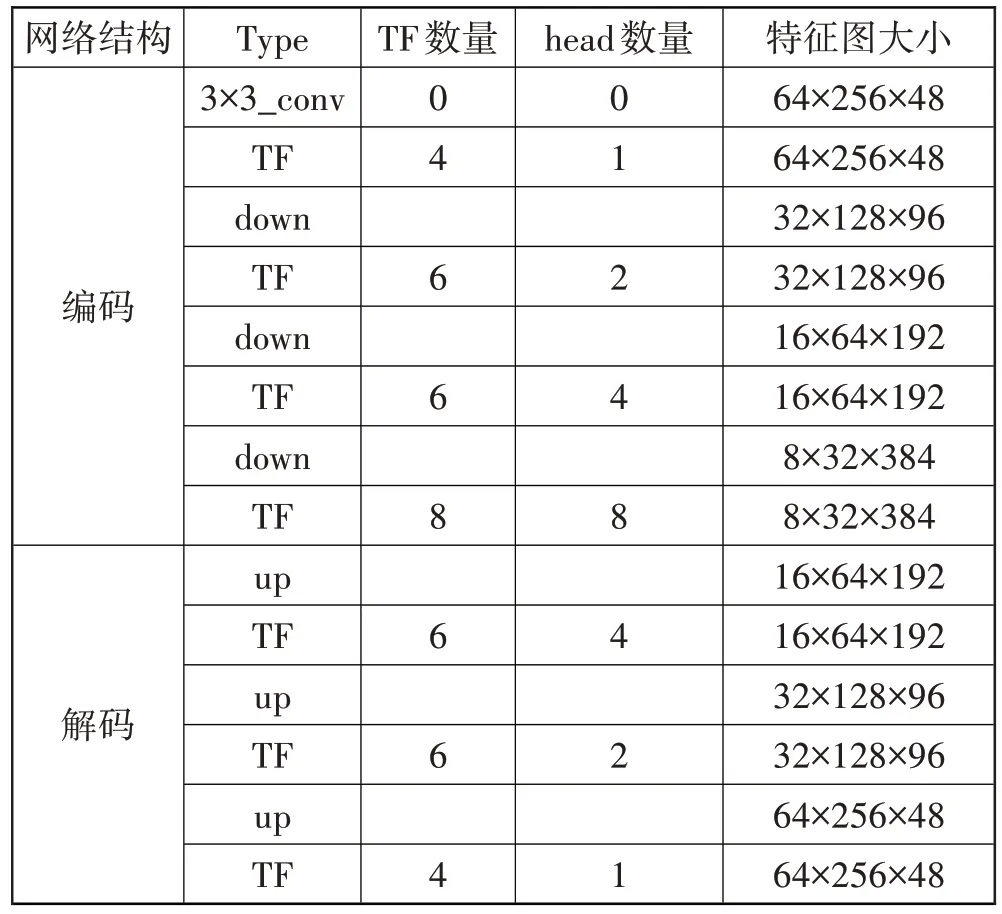
表1 编码器和解码器网络结构
其中,Tconvert表示文字风格迁移模型,It为输入的目标文字图像,Is为输入的风格文字图像,Ot为文字风格迁移模型的输出。这里本文使用像素损失来监督文字风格迁移模块的输出,文字风格迁移损失为:
其中,Tt为风格迁移模块的标签。
图像背景修复模块的目标是完成词级别的场景文字擦除任务。这个模块的输入仅为原始风格文字图像,输出为原始风格图像的背景图像,原文字区域由适当的背景纹理进行填充。编码器和解码器模块与文字风格迁移模块相同,不同之处在于,将编码器每次下采样之前的特征图与解码器上采样之后的特征图按深度进行连接,并在后2 次连接后经过1×1 卷积将通道减半。在解码器之后经过一个3×3 尺度不变卷积将输出通道调整为3,输出背景图像,并计算背景修复的损失。
本文采用像素损失和WGAN 对抗损失来监督背景擦除模块的输出,图像背景修复损失为:
其中,sp为谱归一化,Tb为背景修复网络的参考图像,为背景修复网络的判别器,Ob为背景修复网络生成器的输出结果,α为像素损失的权重系数,本文设置为10。
文字融合模块是将之前2 个模块的输出进行融合,生成最终修改之后的场景文字图像。模块延续之前编码器和解码器框架,输入为文字风格迁移模块生成的前景文字图像。在解码器阶段,将特征图与相同尺寸的背景擦除模块的解码器特征图按深度进行连接,在前2 个连接之后,采用1×1 卷积将通道减半,在第3 个连接之前对背景擦除模块的特征图采用1×1卷积将通道数减半再按深度进行连接。在解码器之后,将特征图输入微调模块,微调模块为4 个Transformer模块堆叠而成,使用3×3尺度不变卷积,将输出通道变为3,得到修改文字之后的图像。
本文采用像素损失和WGAN 对抗损失来监督修改之后的文字图像,文字融合模块损失为:
其中,为文字融合网络的判别器,Tf为文字融合网络的参考图像,β为像素损失的权重系数,本文设置为10,Of为文字融合网络生成器的输出结果。
为使生成图像更加真实,引入感知损失[22]和风格损失[23]。损失可以表示为:
其中,λ1为内容感知损失的权重,λ2为风格损失的权重,分别设置为1 和500。φi为在ImageNet[24]上预训练的VGG-19 模型[25]的relu1_1 到relu5_1 的激活特征图,N为5,G为Gram 矩阵。SR 为模型输出的图像,HR为标签图像。
整个框架的损失为:
本文使用的判别器与PatchGAN[26]网络结构相似,但为应对模型崩溃与梯度爆炸等问题,采用WGAN 思想训练网络,将原PatchGAN 中的sigmoid 层去掉,将原结构中的批量归一化替换为谱归一化,最后一层不加谱归一化。
2.2 Transformer模块
本文采用的Transformer 模块由多头深度可分离卷积注意力机制模块和门控深度可分离前馈网络模块2个部分构成。
2.2.1 多头深度可分离卷积注意力机制模块(MDTA)
Transformer 中主要的计算开销来源于自注意力层,在传统的SA(self-attention)中,key-query 点积的时间复杂度会随输入的空间像素呈平方倍增长,对于输入图像为W×H,其时间复杂度为O(W2H2),这极大地增加了模型计算的难度。为降低计算复杂度,本文使用MDTA组件,如图2所示,MDTA的复杂度为线性复杂度。这里SA 通过计算通道之间的相关性,生成对全局上下文信息的隐式编码注意力特征图。除此之外,MDTA 的另一个重要组件为引入深度可分离卷积,在生成全局注意力特征图之前,将CNN 提取局部信息的强大能力也融入到Transformer中来,这进一步减少了训练参数。
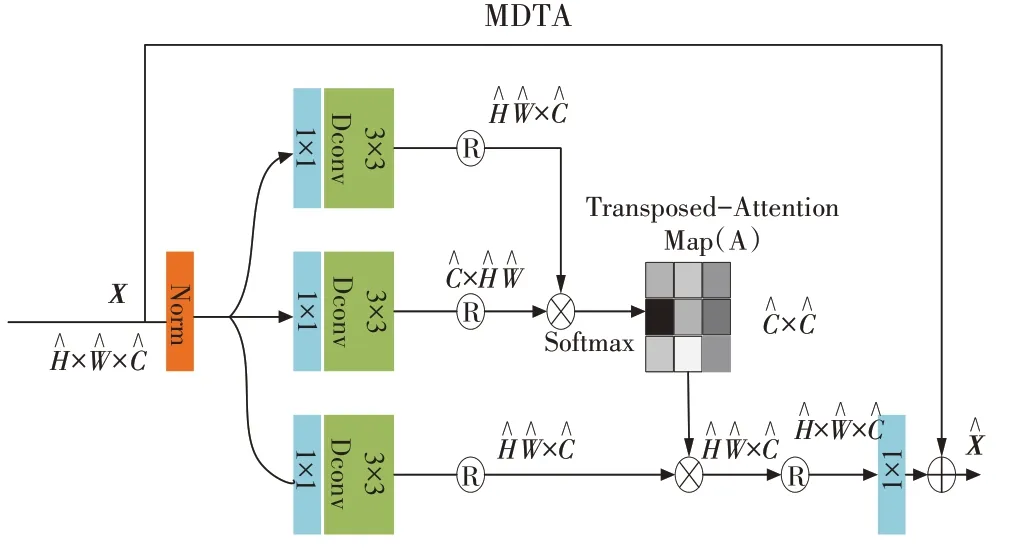
图2 MDTA组件结构图
假设一个通过层归一化的张量Y∈RH×W×C作为输入,MDTA 为生成具有丰富的局部信息的query(Q),key(K)和value(V)特征向量,采用1×1 卷积去整合各通道之间的上下文信息,再经过3×3尺度不变深度可分离卷积对通道级的空间信息进行编码,生成Q=为1×1 逐点卷积,Wd(·)为3×3 深度可分离卷积。在网络中本文使用无偏差卷积。之后对query和key进行改变形状,经过点积之后产生一个转置注意力特征图A,尺寸为C×C,代替原始Transformer产生的巨大的注意力特征图,尺寸为HW×HW。综上所述,MDTA 的处理过程可以定义为:
其中,X和为特征图的输入和输出,最初的Q,K,V∈RH×W×C经 过 改 变 形 状 变 为∈RC×HW;∈RC×HW∈RHW×C。ω为可学习的参数,在经过Softmax 激活函数之前对和的点积结果进行控制。与传统的多头自注意力机制相似,将通道的数量分别放入不同的“head”中并行计算。
2.2.2 门控前馈网络模块(GDFN)
GDFN 组件结构如图3 所示,这个门控机制通过2 个平行路径的线性转换层进行逐元素点积的方式完成。采用Gelu 非线性激活函数。类似于MDTA中,GDFN 采用深度可分离卷积对空间上相邻的元素信息进行编码,有效地学习图像的局部信息对于图像的生成具有重要作用。这里假设输入一个张量X∈RH×W×C,GDFN公式如下:

图3 GDFN组件结构图
其中,⊗表示逐像素相乘,θ表示Gelu 非线性激活函数,LN为层归一化。GDFN控制网络结构中各层级信息的传递,可以使各层级专注于更细粒度的特征,将其传递给其他层级。通过减少膨胀系数γ(此参数体现在图3 中,通过1×1 卷积对通道数进行膨胀,通常设置为4,本文通过实验调整将其设置为2.66),在能达到相同效果的同时减少了模型参数量和计算负担。
3 实验及结果分析
3.1 运行环境及参数设置
本文实验采用Pytorch 框架,虚拟环境为Python3.7 和CUDA 10.2,使用RMSprop 优化器,学习率为1×10-4,交替更新生成器与判别器参数,训练20 万步,即30 个epoch。在反向传播时本文设置α=β=10,λ1=1,λ2=500,来规范每一部分的损失梯度;γ=2.66,批次设置为8,输入尺寸为64×256。测试时可以输入任意大小的图像。本文模型在4 块型号为V100 的GPU上完成训练,使用的上采样方式和下采样方式为pixel-shuffle[27]和pixel-unshuffle。
3.2 实验数据集
合成数据集。为获得成对的训练数据,本文采用SRNet 提供的公开合成工具SRNet-Datagen,收集维语字体50种。背景图像来源于SynthText提供的背景图像数据集,以及DTD 背景纹理图像数据集。合成英文训练集5 万对,测试集1500 对,以及对SRNet-Datagen 进行修改合成维文训练集5 万对,测试集1500对。
真实场景文字图像。ICDAR13 自然场景文字图像来源于Robust Reading Challenges 2013。首先通过该数据集提供的标签对图像中包含文字的区域进行裁剪,获得场景文字图像。本文将非英文字母以及字符数少于3的图像去除,经过过滤可裁剪1598张词级别场景文字图像。
The Street View Text(SVT)是谷歌采集的街景场景文字图像,图像具有丰富的多样性且包含了许多低分辨率的图像,其中包含了350张图像,测试249张(可裁剪647 张词级别场景文字图像),训练101 张图像(可裁剪257 张词级别场景文字图像)。值得注意的是本文提出的模型只在合成数据集上进行训练,真实场景文字图像只用作测试。
3.3 评估指标
本文采用图像生成领域中普遍使用的评估指标来评估本文的模型,其中包括:1)PSNR,峰值信噪比;2)SSIM,计算2 张图像的平均结构相似度。PSNR 和SSIM的值越大,意味着结果越接近于标签真值。
3.4 对比实验
首先,对本文模型的背景修复模块与其他STE模型中的背景修复模块进行对比:SRnet背景修复模块和SwapText 背景修复模块。由于需要将修改之后的文字融合到原始风格图像的背景上,若文字擦除不干净将会影响最终生成图像的质量。由于未公开代码,本文对以下模型进行复现,在本文合成数据集上完成训练和测试。这些方法均保持与原论文一致的配置参数。如表2 所示,本文所提出背景修复模块相对于SRNet_bg(即SRNet 背景修复模块)在PSNR 和SSIM指标上分别提升3.02 dB 和0.063。SwapText_bg(即SwapText背景修复模块)通过使用空洞卷积来增大感受域,而本文通过高效Transformer模块可以提取图像的全局上下文信息,相对于空洞卷积提升更明显。本文提出模型相比SRNet 模型,在英文合成数据集PSNR 和SSIM 分别提高1.74 dB 和0.138。为进一步验证本文方法的有效性,本文选择在字形更复杂的维语上进行文字修改,PSNR 和SSIM 分别提高1.43 dB和0.121,定量结果如表3所示。
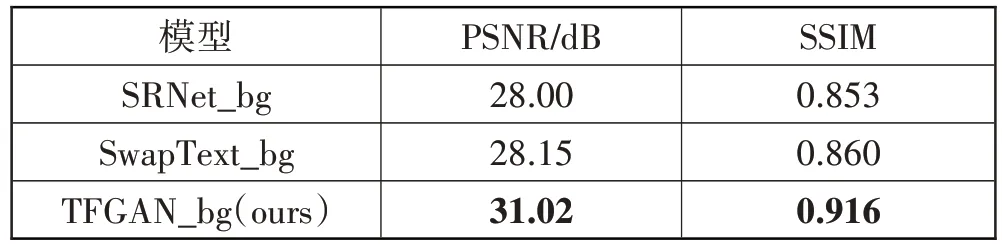
表2 在英文合成数据上背景擦除模块定量结果

表3 在合成数据集上定量结果
3.5 消融实验
在这一节中,本文对设计的各个组件进行消融实验。验证各组件对模型整体效果的影响定量结果如表4所示。
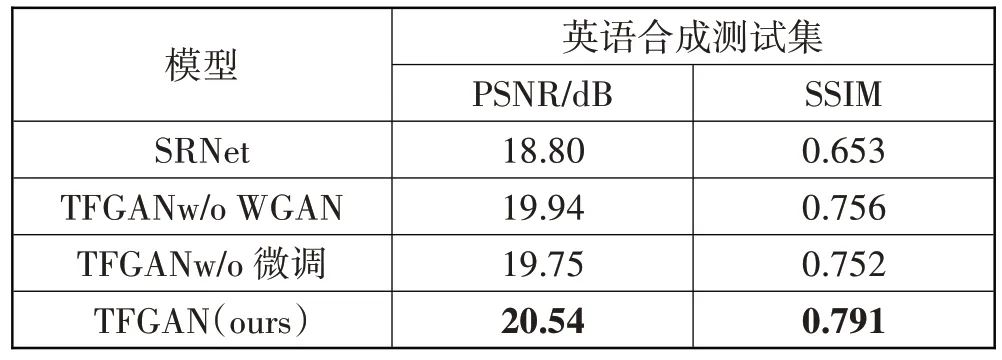
表4 在英文合成数据上的定量结果
微调模块。由于本文模型将STE 分解为3 个子任务,在融合阶段将风格迁移模块输出的文字特征图与背景修复输出的背景特征图进行融合,考虑到2 个子模块之间存在融合偏差,风格文字不能很好地与背景完美融合,通过微调模块对融合结果进行微调。
WGAN。由于原对抗损失造成模型训练不稳定,易出现梯度爆炸等问题,采用WGAN 思想训练,模型训练更稳定,更易收敛到最优值。
3.6 结果展示
如图4 所示,第1 列、第3 列为输入的风格图像,第2 列、第4 列为对应图像修改之后的维语场景文字图像,可见在视觉效果上可以达到难以分辨的效果,且文字细节纹理清晰,表明本文模型可将输入图像的风格应用到维语上。为验证本文模型在真实场景文字图像上的修改效果,图5、图6 为在真实场景ICDAR13、SVT 数据集上的效果展示,上为英文到英文修改效果,下为英文到维文修改效果。

图4 英语到维语样例展示

图5 ICDAR13 效果展示

图6 SVT效果展示
4 结束语
本中通过设计一种基于生成对抗网络的维语场景文字修改模型,采用高效的Transformer模块进行构建,充分考虑了图像全局与局部特征信息,弥补模型受限与卷积神经网络接收域的问题。此外,添加了一个微调模块对融合结果进行微调,处理不同模块间的融合偏差,并采用WGAN思想训练模型,有效应对模型崩溃、梯度爆炸的问题;对公开的合成工具进行修改,合成维语训练集和测试集,使本文模型可以应用于维语场景文字修改,且无论在视觉效果还是评价指标上均取得不错的效果,帮助构建跨语言场景文字图像训练语料。本文研究了在维语和英语上的修改效果,下一步将在其他语言上进行进一步研究并对模型进一步优化。
猜你喜欢
汽车工程师(2021年12期)2022-01-17 02:29:54
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
小天使·一年级语数英综合(2021年9期)2021-09-22 12:18:18
当代陕西(2020年14期)2021-01-08 09:30:42
小雪花·小学生快乐作文(2020年6期)2020-10-13 09:48:27
文苑(2020年12期)2020-04-13 00:55:10
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
贵州师范学院学报(2016年4期)2016-12-01 03:54:07
电视技术(2014年19期)2014-03-11 15:38:20
