
一种用于智能零售视觉结算的增量学习方法
2024-03-04 06:02:44魏秀参
南京理工大学学报 2024年1期
陈 昊,魏秀参,肖 亮
(南京理工大学 计算机科学与工程学院,江苏 南京 210094)
计算机视觉技术在工业互联网和智能新经济的高速发展中起到了至关重要的推动作用。智能零售作为其中的代表性产业和技术应用场景,受到了相关方向学术界和工业界共同的热切关注。其中视觉结算(Automatic check-out,ACO)作为智能零售中的重要组成部分,利用图像识别技术来自动识别产品的要求越来越高,而ACO旨在从所需购买的零售产品视觉结算图像中对零售产品进行精确地识别和计价。从图像识别的角度出发,ACO任务存在的难点包括:大规模、细粒度、小样本和跨域,这4个中的任意一点都被当前计算机视觉领域视为主要挑战[1]。针对这4个主要挑战,Wei等[1]提出了一个大型细粒度商品视觉结算(Retail product checkout,RPC)数据集,同时从目标检测角度提出了一个基线方法,以供后续研究者参考。Li等[2]改进了Wei等[1]提出的基线方法,在目标检测网络的基础上增加了一个计数器,对视觉结算图像中检测到产品的数量进行校正约束。
然而除了这4个主要挑战外,智能零售中的ACO任务还面临着另一个问题:超市和商店中的零售产品是会不断更新的,新的产品将被不断地添加到产品数据库中。因此,针对这个问题的最佳解决方案是一种可以快速更新视觉结算系统的方法,具备快速识别新产品的能力,而不用从头开始重新训练模型。这属于增量学习范畴。增量学习[3]是一种不断扩展现有模型的知识以进一步学习新的类别、任务或领域等的方法。在计算机视觉领域,增量学习已经在不同的研究方向上引起了关注,例如视觉识别、目标检测、语义分割等。在视觉识别的增量学习方面,以前的工作可以大致分为3种范式,即基于参数的方法[4-11]、基于蒸馏的方法[12-15]和基于重放的方法[16-18]。具体来说,基于参数的方法试图估计原始模型中每个参数的重要性,并对重要参数的变化增加惩罚。例如,EWC[4]通过Fisher信息矩阵估计权重的重要性;SI[5]使用优化轨迹上的路径积分;MAS[6]利用了网络输出的梯度。而对于基于蒸馏的方法,它们是通过部署知识蒸馏[19]来建立的,以将知识从观察到的新类别中转移。Li等[12]将学到的模型应用于新的任务,同时用概率的正则化项保留了之前获得的知识,该方法被称为不遗忘学习(Learning without forgetting,LwF)。He等[13]提出了一种在线场景中的增量学习方法,让在线数据与离线训练结合,并通过一个改进的交叉蒸馏损失来避免灾难性遗忘和因旧类新数据导致的概念漂移。Aljundi等[14]提议在不同的任务上训练多个网络,并采取自动编码器为每个测试样本选择一个。Hou等[15]提议使用知识蒸馏来促进对新任务的适应。关于基于重放的方法[16-18],他们通过使用一些旧数据来弥补训练数据,缓解了灾难性遗忘。然而以前的增量学习方法没有针对智能零售中的视觉结算任务进行设计和优化。
为了在ACO任务中实现增量学习,本文从目标检测角度出发,认为不仅需要识别原有零售产品,同时需要识别新产品。具体而言,本文开发了一个名为“增量收银员”(Incremental cashier,iCashier)的深度学习模型,由合成网络S、渲染网络R和检测网络D这3个子网络组成,其中,S与R实现从单品示例图像到视觉结算图像的数据增广,而D用于检测生成的结算图像。
1 问题定义
给定一个候选产品集P={pi}和一张测试集中的测试图像It∈T(这类图像也被称为产品视觉结算图像,用Ic表示),ACO的任务目标就是准确预测It中每类产品的数量count(p)∀p∈P,未出现产品的count(p)为零。这样单品示例图像集可表示为S={(Is,ys)|ys∈P},其中Is是单品示例图像,ys是对应的类别标签。而产品视觉结算图像集可以表示为C={(Ic,Yc)},Yc包括Ic中各个实例的类别和边界框注释信息。

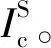
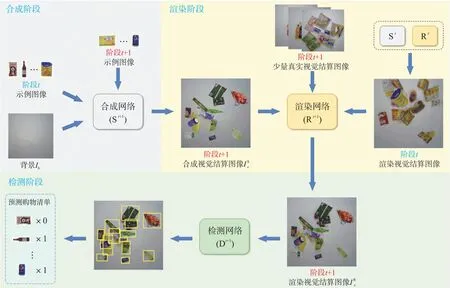
图1 iCashier流程图
2 合成网络
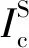
(1)
式中:⊕代表α-混合操作[20],θS是合成网络S的参数。为了尽可能地接近真实的产品视觉结算图像,被分割的独立产品被随机选择并自由放置在背景图像上,同时设定每个独立产品的遮挡率小于50%。另外,受文献[21]的启发,本文利用一个二维仿射变换来实现A(·),其参数为一个六维矢量。在不丧失一般性的情况下,A(·)也可以通过其他类型的图像变换来实现。
如式(1)所示,有一个产品集的示例{pi}被放置在背景图Ib上。为了更接近现实中的产品视觉结算布局并简化优化过程,本文设计了一个渐进式放置策略,在每次迭代中放置一个单品pi,如图2所示。

图2 渐进式放置策略
(2)

3 渲染网络
在应用合成网络S后,合成图像与产品视觉结算图像之间仍然存在域差异。这2个域之间的差异可以通过观察图像的光照条件、阴影模式和放置布局轻易辨别。为了进一步缩小这种域差异,让合成图像更自然地接近产品视觉结算图像,本文提出一个可以同时渲染产品放置和外观的渲染网络R。
为了在产品放置和图像外观上接近真实产品视觉结算图像,渲染网络R拥有2个对抗性学习模块,用于调整产品放置并同时渲染产品视觉结算图像的外观。为了便于理解,图3介绍了在一个学习阶段中渲染的主要流程,以示证明。第5节中介绍了在渲染网络R上增量学习阶段的顺序训练。
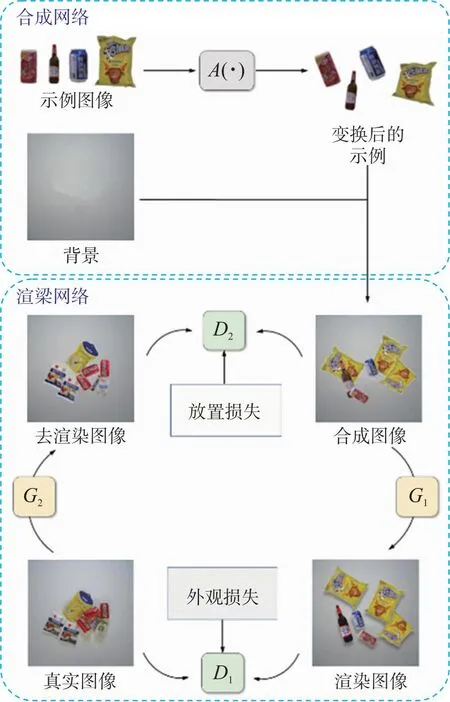
图3 合成网络与渲染网络协同学习
(3)
(4)
式中:L1为外观损失,让网络渲染得到接近真实产品外观的视觉结算图像;L2为放置损失,让原本合成图像中产品放置更接近真实布局。另外,循环一致正则化[22]被用于这2个对抗性学习模块,以减少学习空间并稳定对抗性训练。循环一致性通过以下方式实现
Lcyc1=EIc[‖G1(G′1(Ic))-Ic‖]+
(5)
(6)
式中:G′1和G′2分别表示循环一致结构[13]中G1和G2的反向对抗学习,可以视为G1和G2的反函数。此外,根据文献[23],为了确保翻译后的图像保留原始图像的特征,本文进一步引入了一个身份损失
(7)
(8)
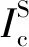
为了更好地同时实现产品布局和产品视觉结算图像外观的合成真实性,在iCashier中合成网络S和渲染网络R是相互连接的,可以进行端到端的训练。本文采用交替优化方法[24]来联合优化模型直到收敛。
4 检测网络
(9)

5 增量学习阶段的顺序训练
事实上,在参考三元组C=〈S,R,D〉的当前副本时,训练单个iCashier模型与训练一个iCashier模型序列是等价的。
(1-λ)EI′clog[D1(I′c)]+
λEIclog[D1(Ic)]+(1-λ)EI′clog[D1(I′c)]+
(10)
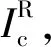
(11)
并能在增量学习阶段逐步检测不同类别的产品。而在试验中,渲染图像与合成图像也同时被用于训练检测器。
6 试验结果
本文为了验证所提出的iCashier模型在智能零售视觉结算任务增量学习设定中的性能,进行相关试验,并把Li等[2]、He等[13]与Wu等[11]提出的增量学习方法作为基线方法进行对比。试验所用数据集为RPC数据集[1],评价指标同样遵循RPC所提出的4个ACO指标,即结算准确率(Checkout accuracy,cAcc)、平均计数误差(Average counting distance,ACD)、平均类别计数误差(Mean category counting distance,mCCD)以及平均类别交并比(Mean category intersection of union,mCIoU)。另外,本文依据RPC数据集的特点(即所有200个产品细粒度类别从属于17个元类别),对17个元类别各随机选择一个细粒度产品类别作为增量学习阶段的新产品类别。那么,这就构成了一个具有2个增量学习阶段的ACO任务,其中阶段t有183个原有产品,阶段t+1包含17个新的产品。这17个新产品的具体标签为:4_puffed_food、17_dried_fruit、25_dried_food、32_instant_ drink、46_instant _noodles、59_dessert、78_drink、80_alcohol、97_milk、114_canned_ food、127_chocolate、138_gum、 145_candy、160_seasoner、167_personal_hygiene、181_tissue、199_stationery。RPC的训练集中包含183类原有产品的单品示例图像49 421张,17类新产品的单品示例图像4 318张,共计53 739张单品示例图像;RPC的验证集中包含183类原有产品的单品示例图像3 342张,17类新产品的单品示例图像2 658张,共计6 000张产品视觉结算图像;RPC的测试集中仅含183类原有产品的视觉结算图像13 271张,包含17类新产品的视觉结算图像10 729张,共计24 000张产品视觉结算图像。iCashier模型的参数量为4.963×107。
表1中报告了在视觉结算场景中对RPC的增量产品的识别结果。首先在183个原有产品类别的基本集合上应用增量学习模型(有一个学习阶段),然后也在同样的183个类别上进行评估。在该表中,这种设定被表示为“183/183”,并被作为增量产品识别结果的参考。同时,作为一个基线对比结果“183/200”,在183个类别上训练好的增量学习模型被直接用于测试所有200个类别的ACO指标。而当应用增量学习模型时,该类结果被表示为“183(+17)/200”,其中“(+17)”代表将这17类新产品作为一个增量学习阶段对模型进行训练。另外,表中的符号“↑”表示数值越大性能越好,数值的取值范围是[0,1];而符号“↓”表示数值越小性能越好,数值的取值范围是[0,+∞)。iCashier方法中的3种混杂模式由RPC定义,具体细节见文献[1]。
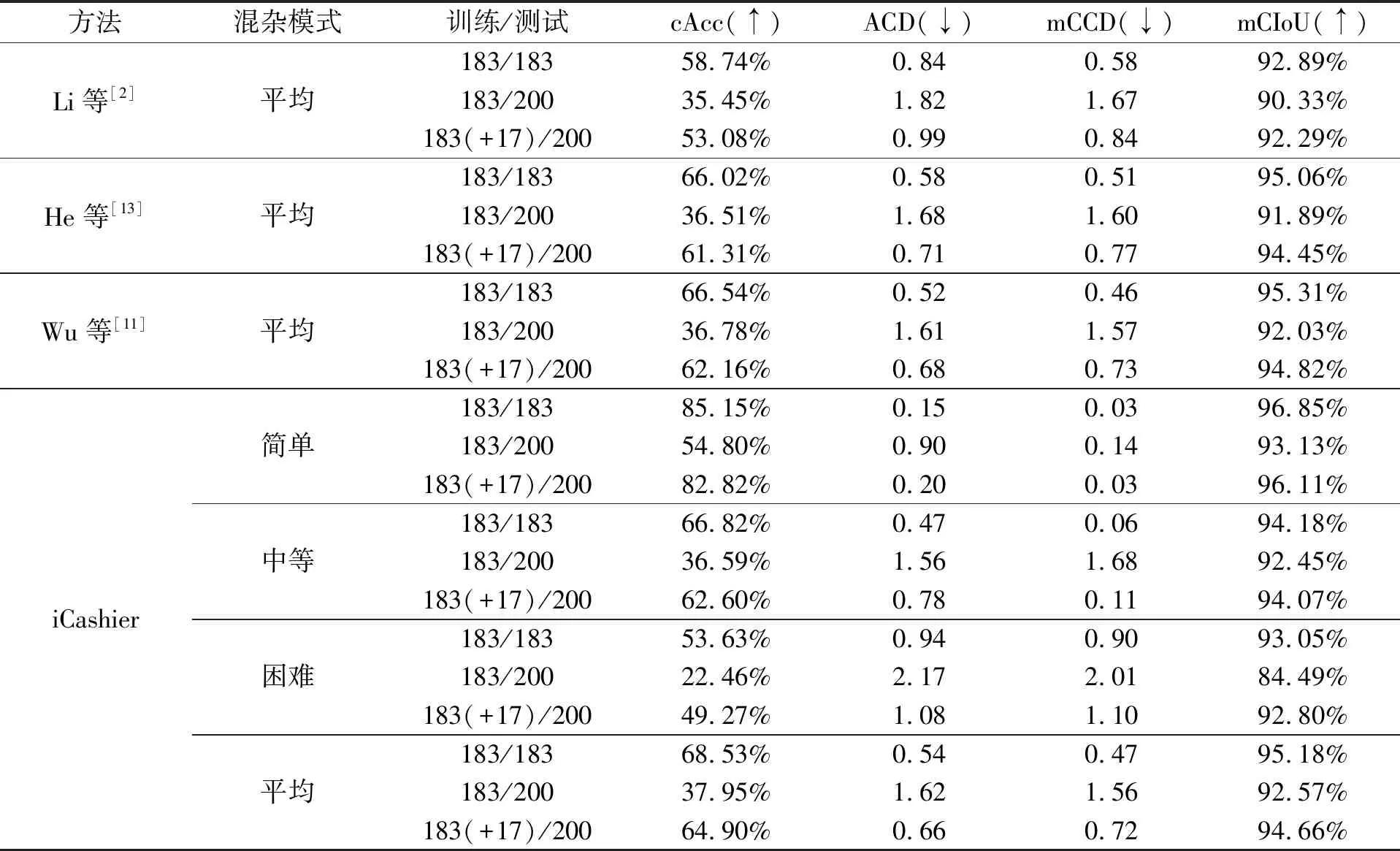
表1 增量产品识别试验结果
比较“183/183”和“183/200”的结果,很明显,由于未观察到的模式以及新产品造成的混乱,ACO准确率大幅下降。从“183/183”和“183(+17)/200”的结果可以发现,不论是基线增量学习方法还是本文提出的iCashier,都对防止灾难性遗忘具有显著效果。Li等[2]把ACO准确率的衰减从23.29%降低到了5.66%,He等[13]的方法则是将衰减从29.51%减小到了4.71%,Wu等[11]的方法将衰减从29.79%减小到了4.38%,而iCashier在平均模式下则把ACO准确率的衰减从30.58%降低到了3.63%,这组数据对比也说明了iCashier模型的优越性。另外,比较iCashier中各个混杂模式的数据,可以发现各个模式“183/183”和“183/200”的ACO准确率都相差30%左右;而“183(+17)/183”和“183/200”的ACO准确率差异则是从“简单”到“困难”模式逐渐增加,分别是2.33%、4.22%和4.36%。这说明混杂模式越“困难”,iCashier可以学习到的有效知识越少。观察4种方法在平均模式下“183(+17)/183”的结果可以发现,iCashier的性能同样是最佳的,比次优的Wu等[11]方法的ACO准确率要高出2.71%。
此外,根据不同类型的训练数据,表2给出了检测网络D在200类完整数据集上的消融学习试验结果,其中训练数据类型共有4类,包括单品示例图像、合成结算图像、使用渲染结算图像,以及同时使用合成与渲染结算图像。表中粗体数字为该列最优结果。从表中可以看出同时使用合成与渲染结算图像可以达到最佳结果,而直接使用单品示例图像无法对真实结算图像进行有效检测。
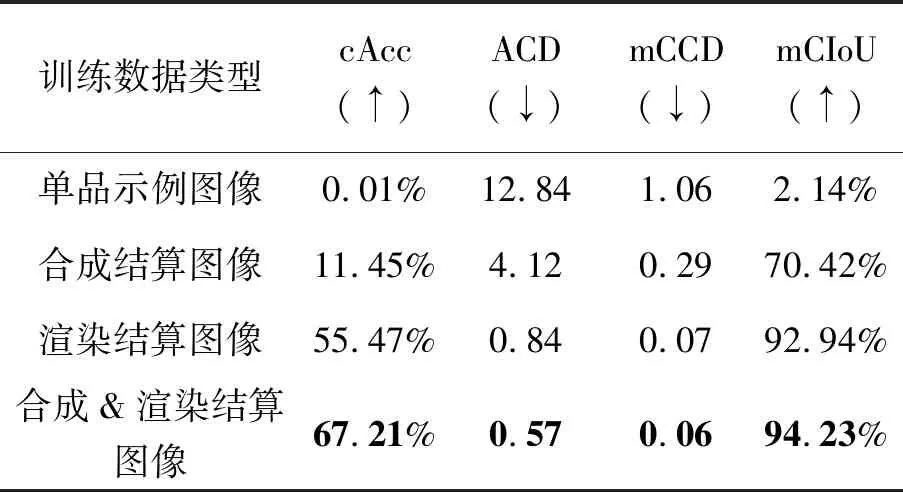
表2 iCashier消融学习试验结果
另一方面,图4展示了iCashier的可视化定性试验结果,其中绿框为正确检测框,红色为错误分类的检测框,前5张图像为正确检测结果,第6张为错误结果,表现为2个紧密相连的同类产品被识别为一个产品。

图4 iCashier可视化试验结果
7 结束语
为了以实际可行的方式逐步识别原有的和新的产品,本文提出了一个由3个子网络(即合成网络、渲染网络和检测网络)作为一个三元组构成的iCashier模型。该模型利用单品示例图像来合成与渲染接近真实的视觉结算图像,实现数据增广,然后用这些生成的视觉结算图像训练检测网络。基于本文提出的增量学习方式,iCashier可以将上一阶段识别原有产品的知识迁移到当前的学习阶段,同时在新产品出现时进行对新类的学习。试验结果证明,iCashier拥有强于2种对比方法的对抗灾难性遗忘的能力。然而iCashier仍存在一些问题,比如基于数据增广的增量学习需要占用较大存储空间;而且增量外的网络是一个二阶段的模型,包括一个由合成网络与渲染网络实现的数据增广阶段和一个由检测网络实现的零售产品检测阶段,并非一个端到端的网络。未来工作将致力于实现占用存储资源较少的、端到端的视觉结算增量学习模型。
猜你喜欢
作文周刊·小学一年级版(2023年40期)2023-10-18 08:07:57
当代陕西(2022年6期)2022-04-19 12:12:22
新世纪智能(语文备考)(2019年10期)2019-12-18 02:46:14
中学生数理化·中考版(2019年9期)2019-11-25 09:39:44
山东冶金(2019年5期)2019-11-16 09:09:22
中学生数理化·七年级数学人教版(2018年9期)2018-11-09 01:24:56
中国化妆品(2018年3期)2018-06-28 06:21:14
Coco薇(2016年10期)2016-11-29 02:29:30
米娜·女性大世界(2016年8期)2016-08-17 17:08:19
电信科学(2016年9期)2016-06-15 20:27:25
