
基于深度强化学习的道路交叉口生态驾驶策略研究
2024-03-03 01:02李传耀张帆王涛黄德鑫唐铁桥
交通运输系统工程与信息 2024年1期
李传耀,张帆,王涛,黄德鑫,唐铁桥
(1.中南大学,交通运输工程学院,长沙 410100;2.合肥工业大学,汽车与交通工程学院,合肥 230000;3.北京航空航天大学,交通科学与工程学院,北京 100191)
0 引言
道路交通系统是燃料浪费和空气污染的主要根源之一。2021 年内,中国的机动车辆(包括汽车、卡车和摩托车)排放的污染物总量已高达15577 百万t,其中,汽车排放占比超过90%。对于汽车而言,驾驶员频繁的加速和减速操作以及不合理的并线等行为产生了大量交通干扰,引发效率低下和能源浪费问题。此外,信号化路口频繁的“停停走走”现象也亟需解决。红灯前车辆的怠速运行也是造成浪费能源和污染物排放的主要原因之一[1]。因此,迫切需要采取有针对性的驾驶策略提高交通效率,实现节能减排。
为应对能源浪费和污染排放问题,研究者提出一种行之有效的交通管理控制策略——生态驾驶[2]。该策略通过车辆在行驶中获得的道路交通信息控制油门和刹车,维持车辆速度的平稳,避免不必要的加速和减速行为。在路口处,该策略还可以根据前方的信号相位和时序(Signal Phases and Timing,SPaT)信息合理控制速度,最小化排队时的发动机怠速时间。因此,该策略能够使车辆生成更加平稳的轨迹,减少交通波动,提高能源效率。近年来,车辆对车辆(Vehicle-to-Vehicle,V2V)和车辆对基础设施(Vehicle-to-Infrastructure,V2I)等互联通信技术的迅速发展为生态驾驶策略的自主实施提供了更多可能性。
生态驾驶策略通常被认为是一个最优控制问题,旨在为车辆设计最优的决策控制,改善能源消耗和降低行驶时间。刘显贵等[3]以油耗、排放和通行时间为目标,通过多目标遗传算法优化生态驾驶目标车速;程颖等[4]通过判定5 种不良驾驶行为并建立面板数据固定效应回归模型,分析这些不良驾驶行为对油耗的影响;XIA等[5]开发一种基于规则的速度规划算法,将信号状态纳入车辆跟驰模型,并通过仿真验证了该算法在降低能源消耗方面的有效性。LIAO等[6]通过考虑动力传动系统的内部功能,设计一种适合电动汽车的生态驾驶策略,以最小化总能耗。LI等[7]使用人工蜂群算法计算车辆通过交叉路口的最佳速度,有效提高了交通效率。上述模型的优点在于,车辆可以在已定义的环境中优化速度控制。然而,这些方法假设环境状态之间的转换是完全已知的,这一假设与现实相差较大,难以适应高维度的动态交通环境。此外,模型求解过程复杂,不利于车辆的实时决策。
相较于上述模型,强化学习(Reinforcement Learning,RL)使智能体和环境可以充分互动,以最大化累积奖励实现最优输出动作,为复杂环境中的实时车辆控制带来了新的解决方案。深度强化学习(Deep Reinforcement Learning,DRL)是强化学习与深度神经网络的结合,可以在高维环境状态中寻求最优驾驶策略,DRL 通过试错学习经验,能复现许多行动组合,突破了传统模型的决策限制。近年来,DRL已被用于解决各种交通管理控制问题。韩磊等[8]提出一种基于竞争双深度Q网络可变速限标志控制策略,该策略能够有效提升瓶颈区的通行能力;赵建东等[9]提出一种基于强化学习和分子动力学的换道决策模型,相对于DeepSet-Q 模型,该模型的拟合精度提高了90.2%;LI等[10]基于DRL算法设计具有风险感知的自动驾驶车(Autonomous Vehicle,AV) 控制策略,实现最小预期风险。LIU等[11]探讨多个连续交叉口场景下的CAV速度规划,结果表明,运用DRL 模型能提高CAV 的燃油经济性。SELIMAN等[12]基于DRL算法设计自动驾驶汽车在车道数减少时的驾驶策略,优化效率和安全性。
因此,本文采用深度强化学习方法,解决CAV和人工驾驶车辆(Human-Driven Vehicles,HRV)共存的交通环境中的生态驾驶问题。通过V2V 等技术获取车辆动态和信号状态信息,该方法通过控制CAV实现对HRV的速度引导,优化车辆轨迹,提高路口通行效率,改善能源消耗和污染物排放问题。本文的主要贡献与创新之处在于:
(1) 运用DRL 算法探索与优化CAV 的横向和纵向驾驶行为,实现生态驾驶。
(2)在状态空间中,同时考虑与周边车辆相关的局部特征变量和与路口相关的全局特征变量,降低状态的维度。
(3)在动作空间中,设定换道和不换道6种动作方式,满足现实中车辆的驾驶行为特征。
(4)在奖励函数中,除考虑效率和安全等传统指标外,还采用目标车道、信号激励及油耗奖励等设计,有助于提高车辆决策的自主性。
(5)选取典型道路信号交叉口进行仿真试验。同基准方法相比,本文方法可以提升交通效率,改善能源排放问题。
1 研究问题
CAV 能够在互联环境中获取当前道路段的相关信息,并及时调整其跟车和换道行为,以实现生态驾驶。典型的城市道路交叉口场景如图1 所示。车辆在有信号灯的路段上行驶,其中,实线车辆称为主体车辆,表示由DRL控制的CAV;虚线车辆为环境车辆,不受DRL算法控制。
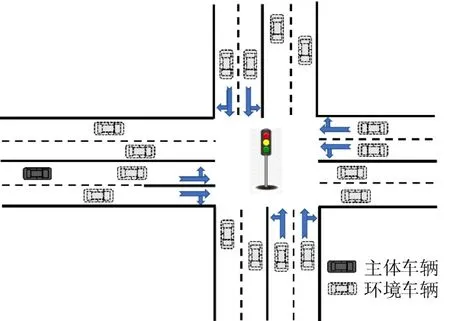
图1 城市道路交叉口场景Fig.1 Schematic diagram of urban road intersection scene
在实际情境中,交叉口前的路段通常存在一段禁止换道的实线区域,本文将其称为“跟车区域”。具有特定驾驶目标的车辆(例如,从左转车道换道到右转车道)需要在进入跟车区域之前换道至目标车道,因此,车辆需要根据允许换道区域的实时交通状况确定换道时机。为最小化换道引起的交通干扰,CAV 可结合SPaT 消息选择适当的换道时机。此外,在绿灯阶段,CAV 会引导下一车队通过交叉口,减少车队的频繁加速和减速操作以及排队时间,实现生态驾驶。如何选择适当的换道时机与引导车队通过交叉口,成为CAV 驾驶决策的主要挑战。
因此,可以通过为智能体设计合适的DRL 算法,并训练其与环境交互,使智能体控制的CAV能够自主学习生态驾驶策略,最终输出优化后的最优驾驶策略。
2 研究方法
2.1 马尔可夫决策过程
CAV 驾驶决策控制问题可转化为马尔可夫决策过程(MDP)。马尔科夫决策过程是一种具有时间序列的离散随机过程,通常用5 元组
2.1.1 状态空间
状态是影响智能体决策的环境变量。在城市交叉口场景中,CAV可以通过V2V和V2I技术实时获取周围车辆和SPaT 信息,并根据其车辆状态和周围交通状态做出驾驶决策。本文为智能体设计的状态空间包括车辆的一组局部变量和一组全局变量,即
式中:Ulocal为局部特征变量的集合;Uglobal为全局特征变量的集合。
图2 说明了在单行双车道场景中CAV 的局部变量集合Ulocal,包括自车和邻近车辆的动态数据,即
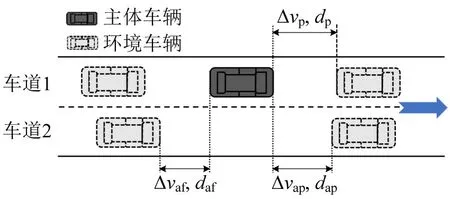
图2 局部特征变量Fig.2 Schematic diagram of local feature variables
式中:l为车辆的当前车道;v为瞬时速度;s为车辆的位置;dp和Δvp为CAV 与当前车道上前车的间距和速度差;dap和Δvap为CAV 与相邻车道上前车的间距和速度差;daf和Δvaf为CAV 与相邻车道上后车的间距和速度差。需要注意的是,式(2)中的速度差是前车速度减去后车速度的差值,间距是前车的尾部与后车的前部之间的距离。由于通信技术的限制,CAV可以检测到200 m 内的运动状态参数。
除局部特征变量,本文还考虑全局特征变量,即
式中:dinter为CAV在当前时刻距离下游交叉口的距离;tinter为到达交叉口所需的预期时间;ϕ为当前时刻的交通信号相位;ϕ′为交通信号相位的导数。dinter的计算式为
式中:sinter为下游交叉口的位置。
在式(3)中,tinter可解释为在CAV保持当前速度不变的情况下,到达下游交叉口所需的预期时间,即
此外,本文还将信号相位的状态参数纳入到全局特征变量中。为更好地描述当前的信号相位,并提高智能体的训练性能,本文使用三角函数描述交通信号[14],如图3所示。
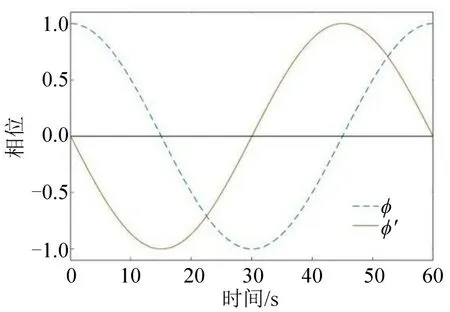
图3 信号相位及其导数的特征Fig.3 Characteristics of signal phase and its derivative
单个交通信号灯有3 个状态:绿色、黄色和红色。交通信号灯的周期T满足的方程为
式中:Tr,Ty和Tg分别为红灯、黄灯和绿灯的持续时间。
用tl表示与当前时间对应的信号周期中的时间点,即
式中:tl0为初始时间点,tl0∈[0,T];t为仿真时间。tl的零值从绿灯或黄红灯开始,例如,在图3中,当绿灯、黄灯和红灯的持续时间分别为27,3,30 s时,tl=10 表示绿灯相位的第10 s(x=10)或黄红灯相位的第10 s(x=40)。信号灯周期ϕ为
式中:δ=0 为绿灯阶段;δ=1为黄灯或红灯阶段。
本文设计的状态空间由上述9 个局部变量和4 个全局变量表示,共13 个特征变量,并随时间不断更新。
2.1.2 动作空间
在驾驶过程中,车辆通过调整油门、刹车和方向盘确保驾驶安全并完成跟车和换道行为。为采用离散的双深度强化学习网络算法(Double Deep Q-Network,DDQN),本文将动作空间设计为两个主要类别:换道和不换道。车辆进行换道操作需要3 s;不换道有5种机动方式:保持当前速度、轻微加速(0.8 m·s-²)、强烈加速(2 m·s-²)、轻微减速(-1 m·s-²)和强烈减速(-5 m·s-²)[15]。此外,为降低动作空间的维度,并提高学习性能,本文设定车辆在换道机动中保持恒定速度,即加速度为0。因此,智能体的动作空间为
式中:lc 为进行换道决策。
2.1.3 奖励函数
一旦执行动作,智能体会根据环境反馈接收奖励(或惩罚)。DRL 算法的目标是通过最大化未来折扣奖励的期望学习最优策略,意味着不同的奖励函数会影响智能体的学习性能。考虑到CAV和场景之间的复杂互动,本文基于多方面考虑设计奖励函数。
(1)驾驶安全
在驾驶过程中,无论是跟车还是换道行为,都需要确保车辆的安全,即CAV 不与其他环境车辆相撞。为使智能体学习安全规则,需要对碰撞行为进行惩罚。驾驶安全的奖励函数为
式中:Δvp≤0 为CAV同前车间距小于0 m,判定为发生碰撞。
(2)交通规则
如果CAV 在跟车区域进行换道行为,将受到惩罚。此外,当信号相位为红色时,CAV 必须停车等待;否则,受到惩罚。交通规则的奖励函数为
式中:tleave为CAV离开交叉口时刻的时间。
(3)舒适度
过大的加速度变化会降低驾驶舒适度。为提高驾驶体验,加速度的导数被设定为不超过3 m·s-3;否则,将受到惩罚。舒适度的奖励函数为
(4)驾驶效率
为鼓励CAV 提高车速,需要考虑驾驶效率。同时,出于安全考虑,当速度过高时(即速度高于道路限速的90%时),需要给予必要的惩罚。驾驶效率的奖励函数为
式中:vmax为道路的限速。
(5)目标车道
交叉口前的道路段包括左转直行车道和右转直行车道。对于不同的驾驶任务,CAV需要提前进入特定的目标车道,以顺利驶入交叉口下游。左转CAV的目标车道是车道1,右转CAV的目标车道是车道2。因为,本文要探究CAV 的换道选择时机,故不考虑CAV直行离开交叉口的情况。目标车道的奖励函数为
式中:κ=1 为CAV 离开交叉口时处于目标车道;κ=0 为CAV离开交叉口时未处于目标车道。
(6)信号协调
为确保车辆能够在绿灯阶段顺利通过交叉路口,需要设置反映CAV 与信号灯之间协同作用的奖励函数。信号协调的奖励函数为
(7)燃油消耗
为体现生态驾驶的重要性,将车辆能源排放考虑引入奖励函数中,即
式中:为每辆车的平均油耗;为车辆在最大速度和最大加速度下的油耗。fuel的计算式为
式中:N为车辆总数;fuel由VT-Micro模型计算[16],VT-Micro模型是以实际燃油数据为基础,通过对速度和加速度的多项式组合而建立的。研究人员最终确定该模型的最高次项为“3”。一方面,VT-Micro 模型只需输入瞬时车速和瞬时加速度即可计算瞬时能耗排放;另一方面,该模型的测量结果与实车测试数据高度一致。因此,该模型可用于测量车辆的燃油消耗量,即
式中:ei,fuel为第i辆车在t时刻的燃料消耗量(L·s-1);v为车辆的瞬时速度;a为加速度;m和n分别为速度和加速度的幂;Km,n为模型的回归系数,K=[Km,n] 为一个系数矩阵,具体数值见文献[16]。
考虑上述几个因素,最终的奖励函数为
2.2 双深层Q网络
Q 学习算法是一种经典的强化学习方法。该算法计算在给定状态u下不同动作z的动作价值函数Q(u,v),并创建一个Q值表。随后,对于每个状态,选择最大Q值相对应的动作a作为最优策略。Q值的更新是通过贝尔曼方程完成的,即
式中:α为学习率;rt+1+γmaxz′Q(ut+1,z′) 为时序差分(Time Difference,TD);rt+1+γmaxz′Q(ut+1,z′)-Q(ut,zt)为时序差分误差(Time Difference Error,TD Error)。
贝尔曼方程具体含义如下:Q(ut,zt)是智能体在状态ut下采取动作zt的动作价值,是未采取动作vt时的估计值。采取动作vt后,环境反馈奖励rt+1并进入状态ut+1。根据奖励rt+1,Q值表能更准确地预测状态ut+1下的最大动作价值maxu′Q(ut+1,z′) 。rt+1+γmaxz′Q(ut+1,z′) 为在状态ut下获得奖励与状态ut+1下预测的动作价值,故称时序差分。TD和Q(ut,zt)的差值称为时序差分误差。因为,TD 是根据已知的奖励rt+1的预测值,故比Q(ut,zt)更加准确,所以,TD Error 越靠近0,越说明Q值表的准确性。
Q 学习算法以Q表格为载体进行智能体的学习和训练。然而,对于高维的状态和动作,Q表格一对一的计算方法会消耗大量资源,且训练过程较慢。为解决这一问题,MINH等[17]提出深度强化学习网络(Deep Q-Network,DQN),即将Q 学习算法与深度学习相结合。深度学习通过引入神经网络的隐藏层实现。
在DQN 中,神经网络(参数θ)的输入是状态s,输出是所有可能动作的Q值。通过奖励监督神经网络,使预测的Q值与真实Q值之间的比较问题转化为模型拟合奖励的问题。然而,DQN 算法存在一个主要问题,那就是高估问题。为解决这一难题,哈瑟尔特等[18]提出DQN 的改进版本——DDQN。DDQN将行动选择和Q值的计算解耦,使用两个网络分别参与决策。具体来说,主网络Q(θ)用于选择行动,目标网络Q(θ′)用于评估行动。两个网络交替工作,更好地缓解高估问题。DDQN模型的损失函数为
式中:EM为期望;yt为时间差目标。
DDQN 算法解决流程如表1所示。

表1 DDQN算法Table 1 DDQN algorithm
3 仿真实验
3.1 实验设定
仿真实验使用软件为MATLAB。仿真场景设定为一个含交叉口的城市道路段,如图4所示。道路设定为单行双车道。车道1是左转和直行车道,车道2 是右转和直行车道。每个车道的速度限制为vmax=60 km·h-1。交叉口前的路段长度700 m,其中,包括500 m 的换道区域和200 m 的跟车区域。信号灯时间,即绿灯,黄灯,红灯时间分别设置为30,3,27 s。
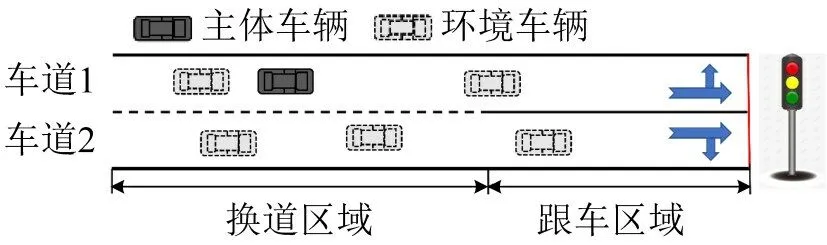
图4 城市道路模拟场景Fig.4 Schematic diagram of urban road simulation scenario
DDQN 算法仅操控CAV 智能体的驾驶行为,而其他环境车辆的驾驶行为遵循智能驾驶员模型(Intelligent Driver Model,IDM)[19]。IDM 模型由自由流动状态下的车辆加速度函数和防止与前车相撞的车辆减速趋势组成。设I表示交通系统中所有车辆的集合,对于每个i∈I,车辆i的加速度为
式中:vi为车辆i的速度;a0为车辆的最大加速度;v0为期望速度;δ为参数;si为自车前端与前车尾部之间的距离;Δvi为自车速度与前车速度之间的差异;s*(viΔvi)为期望距离,即
式中:s0为最小距离;O为同前车的安全时间间隔;b0为期望减速度。
在实验中,进行了1000次训练,每次训练包含750 个时间步,每个时间步的时长为0.2 s。在每次训练开始时,使用基于高斯的位置采样概率方法,在每条车道的前200 m 内随机生成7~20 辆车辆。这些车辆的初始速度在3~5 m·s-1,这有助于智能体在不同环境中进行全面学习。CAV 智能体的初始位置在车道1,并将目标路径设置为从右转车道驶出,即从车道2驶出交叉口,完成学习目标。
在每次训练中,当智能体控制的CAV 与其他车辆发生碰撞,或者模拟时间步长达到750 个,该周期将被认定为终止,训练将进入下一个周期。在下一个周期开始时,CAV 将返回到初始位置,模拟环境将被重置,并进行新的训练周期。
3.2 实验假设
(1)通信延迟和信息错误不在考虑之列。CAV通过车联网技术实时获取车辆和道路信息。蜂窝车联网(Cellular-Vehicle to Everything,C-V2X)主要体现现有的车联网通信技术,时延可降至1 ms。同时,CAV可以对获取的信息进行多种方式的融合和处理,提高数据的准确性和可靠性。
(2)CAV 可实时获取信号信息。通过车用无线通信技术(Vehicle to Everything,V2X),CAV可以实时掌握信号灯信息,帮助车辆做出合理的驾驶决策。
(3) 不考虑非机动车和行人对道路系统的干扰,只考虑车辆与SPaT数据之间的交互。
3.3 训练过程
为确保训练性能,需要对模型的深度神经网络和相关参数进行最佳设置,以适应具体情境。
在DDQN模型中,主网络的网络架构设置为一个输入层、一个输出层和一个隐藏层。后续训练表明,一个隐藏层足够以较低的计算资源消耗达到训练目标。在输入层中,通过式(1)表示的状态向量输入13个神经元,隐藏层设置为110个神经元。输出层设置为6个神经元,对应智能体可以执行的动作数量。深度神经网络的激活函数使用ReLU 函数,可以确保在x>0 时梯度保持不变,并加速网络的收敛。ReLU函数的表达式为
目标网络采用与主网络一致的网络结构。这两个网络的唯一区别在于参数的更新频率。主网络在每个时间步更新,而目标网络设置为每隔C个时间步更新一次。
对于模型中的其余参数定义如下:经验回放大小设置为20000;每个训练样本批次大小设置为80;关于ε-贪婪策略,初始时,ε设置为1,逐渐减小到最小值0.03,步幅为0.00002;学习率设置为0.001;累积回报的折扣率设置为0.95。具体的模型参数如表2所示。

表2 DDQN训练参数设定Table 2 DDQN training parameter settings
3.4 训练结果
由于DRL 是通过最大化累积奖励找到最优策略的,所以,其学习效果可以反映为最大累积奖励值。因此,可以通过比较每个训练周期中智能体的累积奖励评估模型的学习效果。训练过程的累积奖励曲线如图5 所示。由图5 可知,在初始训练阶段,每个周期的累积奖励较小。由于智能体处于探索环境的阶段,可用的有效经验较少,容易受到奖励函数设定的惩罚影响。随着训练周期数量的增加和ε值的减小,智能体可以利用大量有效经验。因此,累积奖励趋于增加,并在500 个周期后达到稳定水平,最终的奖励值收敛到400。表明智能体较好地平衡了探索和利用之间的关系,并学到了更好的驾驶策略。
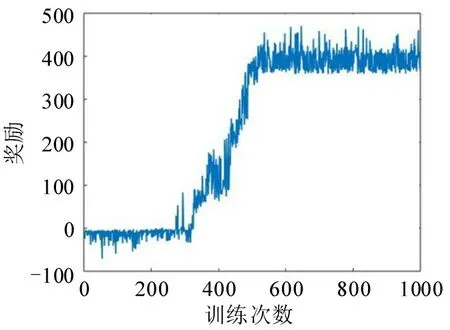
图5 累积奖励曲线Fig.5 Cumulative reward curve
安全是驾驶的首要考虑因素,也是评估模型性能的基本指标。在模拟过程中,智能体必须合理操控CAV采取适当的加速、减速和换道动作,以确保与周围车辆保持安全跟车距离。每一代训练结束时的模拟时间步数如图6 所示。在训练的初期阶段,由于贪婪策略的影响,智能体仍需学习安全驾驶策略。因此,安全驾驶时间远低于每个模拟任务的最大时间步数。随着训练的进行,在探索和利用的权衡过程中不断优化,智能体控制的CAV 能够逐渐维持长时间的安全驾驶。经过500次模拟后,能够稳定地运行到每个模拟任务的最大时间步数,表明智能体已经掌握了安全驾驶的能力。

图6 运行时间步数曲线Fig.6 Agent's running time steps curve per episode
3.5 CAV行为分析
模型训练到达最佳状态后,本文从微观角度介绍智能体控制的CAV在驾驶方面的学习表现。
3.5.1 换道行为
CAV在模拟中有两类换道行为。一方面,CAV在具备换道条件下的操作,如图7所示,具体来说,在仿真时步190 时,CAV 接收到智能体的换道指令,开始执行换道操作,在仿真时步205时,CAV刚好完成换道操作,顺利行驶在车道2 上。另一方面,CAV在不具备换道条件下的操作,如图8所示,具体来说,在仿真时步50 时,CAV 不存在换道条件,故智能体使其继续保持直行,等待换道时机,在仿真时步160 时,换道条件已经具备,智能体给CAV 下达换道指令,在仿真时步175 时,CAV 刚好完成换道操作,安全行驶在车道2上。
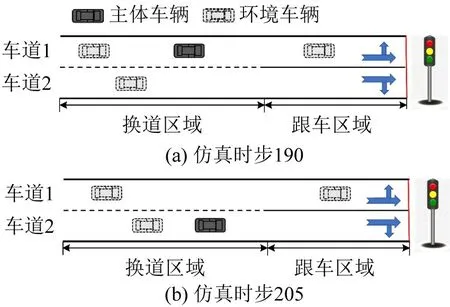
图7 换道操作Fig.7 Schematic diagram of lane change operation
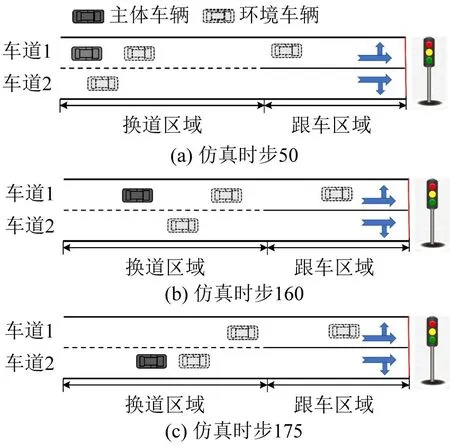
图8 换道操作Fig.8 Schematic diagram of lane change operation
3.5.2 生态驾驶行为
为展示智能体控制下CAV 的生态驾驶学习表现,记录CAV的轨迹和速度信息,如图9和图10所示。两幅图中:横坐标表示模拟时间步长;垂直短细虚线表示CAV从车道1切换到车道2的时间点,虚线左侧表示CAV在车道1中的信息,右侧表示换道至车道2后的信息;水平长粗虚线表示当前信号灯处于黄红灯相位。为确保观察到十字路口附近的车辆轨迹,记录了信号灯下游100 m 范围内的轨迹。
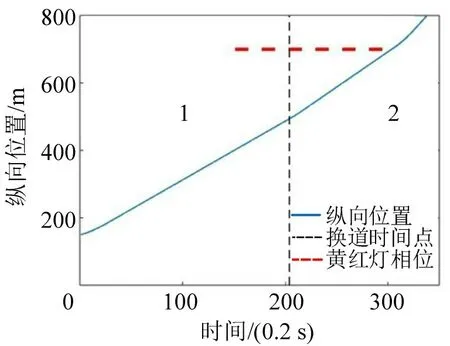
图9 CAV智能体的纵向轨迹曲线Fig.9 Longitudinal trajectory curve of CAV Agent

图10 CAV智能体的速度曲线Fig.10 Velocity profile of CAV Agent
从图9 和图10 可知,当CAV 刚驶入车道2 时,由于道路状况较好,车速略有增加。随后,车速稳定在10 m·s-1,并在绿灯阶段顺利通过交叉路口。在红灯时,没有发生闯红灯和排队的情况,从而避免了交叉路口的交通波动。可以看出,经过训练的智能体使CAV能够成功执行换道以及生态驾驶的任务。
3.6 对比分析
为验证基于DDQN算法智能体的性能,本文设定一个基准方案,具体如下:主体车辆的纵向运动使用IDM 模型,横向控制使用MOBIL 模型操控[20]。满足车辆换道操作的条件为
式中:as、af和aaf分别为主体车辆、当前车道中的后车以及目标车道中后车的加速度;、f和af为进行换道时三者相应的加速度;bsafe为安全限制;p为主体车辆的礼让系数,描述驾驶员的亲社会行为;ath为换道效益阈值。式(26)是安全准则,用于避免主体车辆与目标车道中的后车之间的碰撞。式(27)是换道的激励准则,即当满足条件,车辆可以通过换道提高速度。
为适应交叉路口区域的特殊情况,将传统的IDM模型进行如下改进:如果当前信号灯相位为红色或黄色,且前方车辆的位置距离下游交叉路口不足50 m(dinter≤50 m),为避免闯红灯,前车将信号灯视为速度为0 m·s-1的前车,并减速。此时,IDM 模型中的Δvi取值为-vi,si取值为dinter,更新车辆的加速度。
为便于比较两种方案对整体交通流的影响,对模拟场景进行附加设置:在模拟开始时,在车道1和车道2的入口处,以相同的车流率汇入车辆。在DDQN方案中,有多个CAV智能体从车道1进入道路,且将部分CAV 智能体的目标车道设置为车道2。在基准方案中,CAV 车辆将由基准方案操控。其余的设置与前面的模拟环境一致。基于上述描述,从以下几个方面比较和分析两种方案的生态驾驶性能。
3.6.1 轨迹分析
为展示两种方案在交通系统中的微观驾驶性能,绘制两个车道的时空轨迹,如图11所示。两个车道的流量为900 辆·h-1。在DDQN 方案下,使用经过训练的模型控制CAV智能体(图中以粗轨迹表示)。基准方案的轨迹曲线如图11(a)和图11(b)所示,基于DDQN 的轨迹曲线如图11(c)和图11(d)所示,图中,“*”表示车辆正在进入该车道,“o”表示车辆正在离开该车道。

图11 两种方案下的双车道车辆轨迹Fig.11 Two lane vehicle trajectory diagram under two scheme
由图11 可知,由基准方案控制的车辆能够顺利换道到车道2并驶出交叉路口。然而,由于缺乏与信号灯的协调,大量车辆需要在红灯时排队等待。由DDQN 控制的车辆不仅能够进行安全的换道操作,还能够实时感知下游的SPaT 信息。不仅使主体车辆能够顺利通过交叉路口,还能够在信号变为绿色时引导后续车队通过交叉口,避免红灯时的排队。因此,在与环境互动和学习后,DDQN 控制的车辆不仅能够完成换道到目标车道的任务,还能够成功引导其他车辆通过信号交叉口。大大提高了乘客的舒适性,避免因频繁的停车和起步而引起的交通振荡等不利影响。
3.6.2 效率分析
为观察DDQN对交叉路口段的改善效果,测量交叉路口停车线处的车头时距,如图12所示,横坐标表示队列中不同位置的车辆,队列位置1表示实际队列中第2辆车的数据,依此类推。

图12 交叉路口不同队列位置车辆的车头间距Fig.12 Headway of vehicles in different queue positions at intersection
从图12可知,在基准方案下,由于与信号灯缺乏协同作用,车辆会在红灯处停车排队,只有在信号变为绿灯时,才按顺序从0 m·s-1加速。因此,队列中靠前的车辆速度较低,导致通过交叉路口的车辆车头时距和绿灯丢失时间增加。此时,交叉口的平均车头时距为2.28 s。与基准方案相比,由DDQN 控制的车辆能够通过学习生态驾驶策略引导队列通过交叉口。此外,一些换道到车道2 的CAV 智能体(如图11(d)所示)也可以引导后续车辆进行生态驾驶。交叉口处车辆的平均车头时距为2.06 s,增加了约10.7%的容量。车头时距的减少意味着单位时间内通过交叉口停车线的车辆数量增加,提高了交叉口的饱和流量。
3.6.3 燃油消耗与CO2排放分析
本文从生态学的角度探讨DDQN 对交通系统的改进。使用式(18)测量两个车道上车辆的燃料消耗。除了计算燃料消耗外,还计算CO2排放量。RAKHA等[21]发现,燃料消耗与CO2排放之间的关系为
式中:Eco2为时刻t的车辆CO2排放量;Efuel为从式(18)计算得出的燃料消耗;δ1和δ2为速度和燃料消耗的相关系数,分别为3.5×10-8km·m-1和2.39kg·L-1。
两种方案下,每辆车随时间变化的平均燃料消耗和CO2排放曲线如图13 和图14 所示。可以看出,在DDQN 方案下,每辆车的总燃料消耗约为1.43 L,总CO2排放量约为3.42 mg。与基准方案相比,两者都降低了约7%。主要是因为DDQN 控制的CAV 车辆可以根据周围环境自主决策,并且与SPaT 数据协同进行平稳的加减速。因此,车队的速度波动减小,故燃料消耗和CO2排放更加平衡,提高了环境经济性。对于基准方案,频繁的加减速导致交叉路口的交通振荡,导致更显著的总体燃料消耗和CO2排放值。
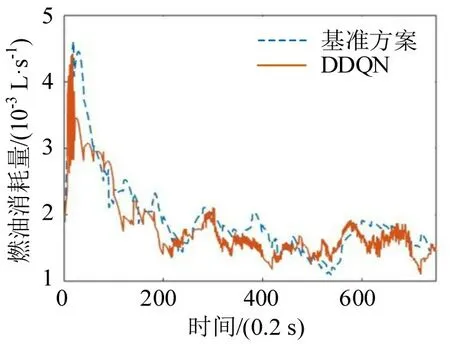
图13 每辆车的平均油耗曲线Fig.13 Average fuel consumption curve for each vehicle

图14 每辆车的平均CO2曲线Fig.14 Average CO2 emission curve for each vehicle
3.6.4 不同情况下的数值结果
此外,鉴于自动驾驶汽车和人工驾驶车辆在不久的将来会共存的观念,本文测量了不同流量和不同CAV 智能体渗透率(Penetration Rate,PR)对交通系统的潜在影响,如表3所示。为确保数据的有效性,数据均通过10次重复实验获得。
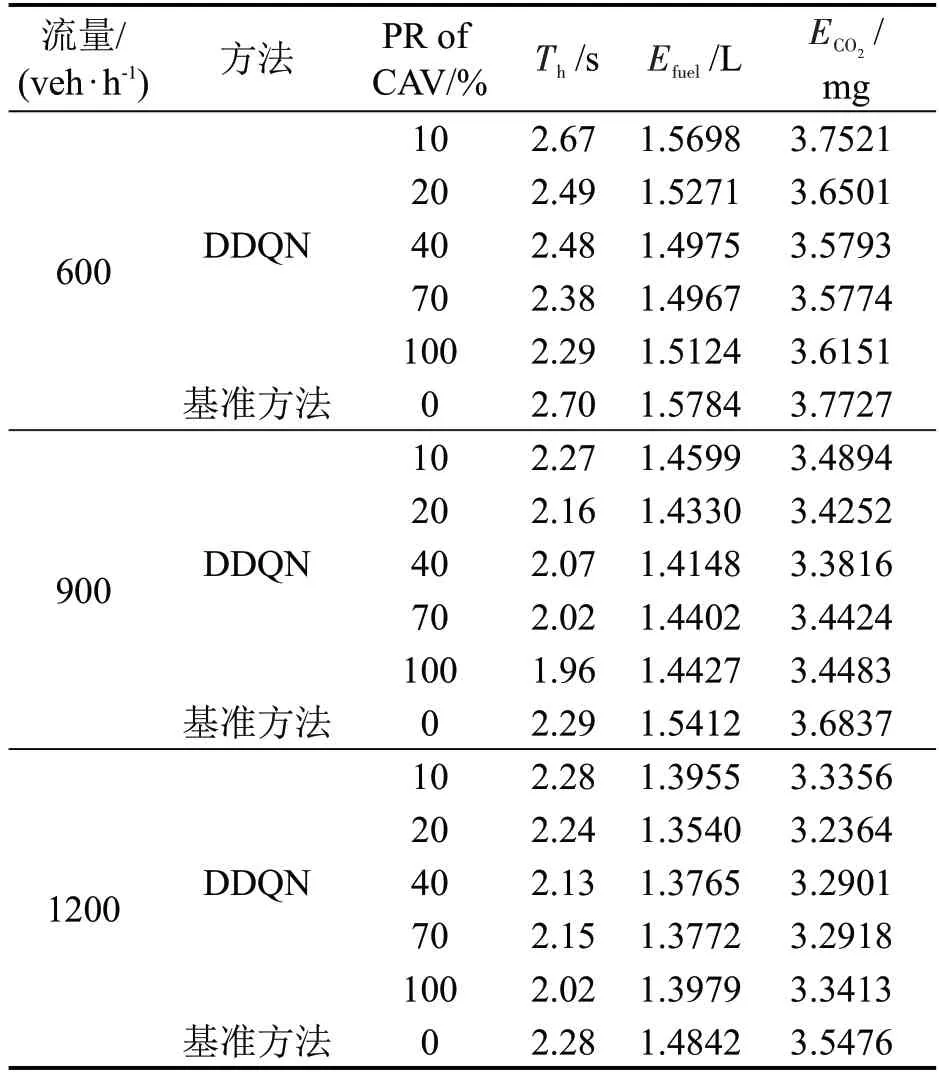
表3 DDQN方法和基准方法在不同场景下的数值结果Table 3 Numerical results of DDQN method and baselinemethod in different scenarios
本文测量3个指标,分别是交叉路口停车线上平均车头时距Th,每辆车的平均燃料消Efuel耗和CO2排放ECO2。显然,PR的增加可以降低交叉口附近的车头时距,并提高交叉口的饱和流量。与基准方案相比,在PR 等于100%的方案中,600,900,1200 veh·h-1这3种交通需求下,交叉口的饱和流量分别提高了17.90%,16.83%,12.87%。此外,不同的CAV 智能体PR 还可以降低交通系统的燃料消耗和CO2排放。不同交通拥堵水平下的燃料消耗和污染物排放可以减少5.19%~8.76%。
4 结论
本文得到的主要结论如下:
(1) 运用DDQN 算法探索CAV 智能体在典型城市道路交叉口场景中的生态驾驶策略。在状态空间中考虑与车辆动态相关的局部特征变量以及与信号灯状态和路口相关的全局特征变量,确保智能体与环境充分互动。侧向和纵向控制被用作行动输出,以确保智能体学习多样化的驾驶决策。奖励函数包括对交通规则的惩罚、与信号灯的连接奖励以及全局节能奖励,以加速车辆学习达到最佳的生态驾驶策略。
(2)本文构建符合实际道路环境的仿真场景,并对模型进行训练。结果表明,基于DDQN方案可以实现CAV 智能体的生态驾驶策略,使其能够顺利通过信号交叉口,并完成到目标车道的横向机动。此外,与基准方案的比较分析表明,所提出的方案可以在动态交通环境中引导人类驾驶车辆,将交叉口的容量增加了17.90%,并将每辆车的平均燃料消耗和污染物排放降低了约8.76%。
猜你喜欢
小猕猴智力画刊(2022年4期)2022-05-25
卫星应用(2021年11期)2022-01-19
科学大众(2021年9期)2021-07-16
中学生百科·大语文(2021年4期)2021-05-12
中国交通信息化(2020年11期)2021-01-14
重庆交通大学学报(自然科学版)(2017年3期)2017-05-17
发明与创新(2016年5期)2016-08-21
中国房地产业(2016年2期)2016-03-01
中国交通信息化(2015年10期)2015-06-06
系统工程学报(2015年3期)2015-02-28
