
点云投影结合轻量化卷积神经网络实现三维成像声呐快速目标分类∗
2024-02-29 10:58任露露巩文静李宝奇黄海宁
应用声学 2024年1期
任露露 尹 力 巩文静 李宝奇 黄海宁
(1 中国科学院声学研究所 北京 100190)
(2 中国科学院先进水下信息技术重点实验室 北京 100190)
(3 中国科学院大学 北京 100049)
0 引言
随着声呐技术的发展,基于声呐图像的目标探测和分类技术得到了广泛研究。在水下矿产资源勘探、管道和电缆探测、海洋生物分类等领域具有重要作用[1-2]。目前常用的声呐设备类型有侧扫声呐、前视二维声呐、合成孔径声呐以及三维成像声呐等。侧扫声呐、前视二维声呐以及合成孔径声呐都属于二维成像声呐,其声呐图像是真实三维场景在二维斜距平面上的投影,相同距离不同高度的点在声呐图像中重合在一起,给后期的目标识别分类带来很大困难。三维成像声呐通过发射宽波束的声脉冲照射场景,使用二维接收面阵对回波信号进行采集,再经过波束形成获得三维空间中散射点的强度信息,可以实现对水下场景和目标的立体观测。三维成像声呐获取的目标信息相比二维声呐增加了高度维度的信息,因此三维成像声呐更加适合用于水下目标的分类识别。
近年来,利用声呐图像实现水下目标分类识别是国内外学者的研究重点。例如,Dura等[3]使用无监督马尔科夫分割算法分割出目标阴影并拟合为椭圆,提取椭圆参数作为形状特征,实现了对水下目标的分类;许文海等[4]利用水平集方法提取水下目标的轮廓,计算目标的不变矩特征,并将其作为后续目标分类的依据,取得了较好的效果。然而,上述方法基于人工设计并提取特征,对专业领域知识要求较高,且在特征提取过程中会不可避免地丢失部分关键信息,导致泛化能力不足。随着深度学习理论的不断发展,卷积神经网络(Convolutional neural networks,CNN)在声呐图像目标分类领域得到了重要应用[5]。McKay 等[6]使用预训练的CNNs 结合支持向量机方法,与VGG16、VGG19 等网络进行了比较,表明了其在合成孔径图像识别中的有效性;Alshalali 等[7]采用迁移学习的方法,利用预训练的YOLO 模型,以45 frame/s 实现水下蛙人的实时检测;巩文静等[8]通过对MobilNetV2 网络进行改进,将三维成像声呐声学深度图像和同步采集的光学图像作为网络输入,实现了更好的分类性能。然而,由于水下光学成像作用距离有限,可能会限制该方法在实际应用中的具体表现,并且仅仅使用三维成像声呐成像结果的深度图这一点也具有改进的空间。
与前视二维声呐、侧扫声呐和合成孔径声呐不同,三维成像声呐的成像结果是三维点云,包括场景中散射点的位置信息和强度信息。由于三维点云具有高度稀疏性和不规则性,增加了点云处理难度,传统的三维点云目标分类方法主要通过提取点云特征点的结构属性、强度属性、形状属性或者多种属性的组合进行对比实现点云的分类任务。基于深度学习的方法也在点云数据处理任务上取得大的成功,比如使用体素方法Voxelnet[9]和使用点云特征方法PointNet[10-11]。但是总体来说,点云数据处理的计算量和复杂度远大于二维图像处理,其处理时间和功耗也会大于二维图像处理。
基于以上讨论,本文采用二维图像的目标分类方法而不是直接对点云进行处理来实现三维成像声呐目标分类任务。首先,本文提出一种投影方法,根据三维成像声呐的波束方向,将三维成像声呐的成像结果三维点云投影为深度图和强度图,分别保存三维点云的位置信息和强度信息。然后,利用深度图和强度图分别作为第一个通道和第二个通道构建混合通道图,将混合通道图作为目标分类网络的输入。最后,使用轻量化卷积神经网络MobilnetV2 完成三维声呐图像中的水下目标分类。该方法的优点是既保留了三维点云中散射点的深度信息和强度信息,同时也避免了三维点云目标分类方法巨大的计算量和功耗。实验结果验证了该方法的有效性,可以满足水下实时目标检测的需求。
1 三维成像声呐点云生成
1.1 三维成像声呐波束形成
三维成像声呐一般由无指向性发射换能器、二维接收面阵以及数据处理模块组成。发射换能器发射声脉冲照亮整个成像场景,二维接收面阵用来接收回波信号[12],数据处理模块主要的任务是对回波数据进行波束形成,得到成像结果[13-15]。按照文献[16]中提出的方位角和俯仰角如图1 所示,二维接收面阵有M×N个阵元,其中沿着y方向分布N行阵元,沿着x方向分布M列阵元。三维成像声呐需要对所有距离切片上回波数据进行波束形成,这样便可以获得每一个距离切片上散射点的强度分布。远场波束形成中每个距离切片上回波数据的波束形成方法是一样的,现在对单个距离切片上回波数据的波束形成方法进行说明。对于单个距离切片的某个散射点,其单位方向矢量u和其在yz平面上的投影之间的夹角为βi,u和其在xz平面上的投影之间的夹角为αi。
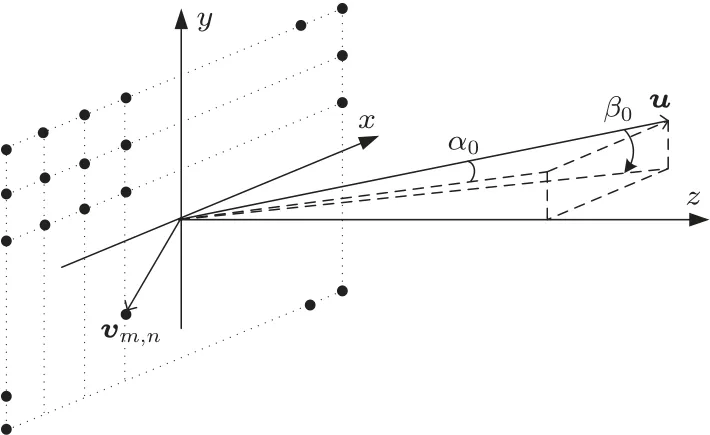
图1 方位角及俯仰角定义Fig.1 Azimuth and pitch angle definition
散射点的单位方向矢量表达式:
则该距离切片上所有散射点的回波信号可以表示为
其中,Ai为信号幅度为噪声矩阵,表示与目标方向有关的信号相位矩阵。
其中,m=1,2,···,M,n=1,2,···,N。远场回波信号的相位可以分成与俯仰和方位向相关的两个独立分量。方位向与俯仰向波束形成导向矢量可以表示为
因此二维平面接收阵远场单个距离切片上回波数据的常规波束形成计算公式为
根据公式(6)便可以将原始回波数据中的每一个距离切片进行波束形成,得到每个距离切片上散射点的强度分布。三维成像声呐接收到的原始回波数据维度为M×N×Nr,M×N是平面接收阵元的数量,Nr为距离向的采样点数;将所有距离切片的回波数据经过常规波束形成之后波束域数据的维度是Nα×Nβ×Nr,其中Nα和Nβ是方位向和俯仰向的波束数目,波束形成之后的波束域数据表示成像空间中散射点的强度。对于波束域中索引为(α,β,r)的点在笛卡尔坐标系下的位置表示为
式(7)中:r=ct/2,t为回波到达时间。如图2 所示,通过计算波束域数据中每个散射点的空间位置便可以将波束域数据转换为原始点云P,其中原始点云P中包含Nα×Nβ×Nr个散射点的位置信息和强度信息。
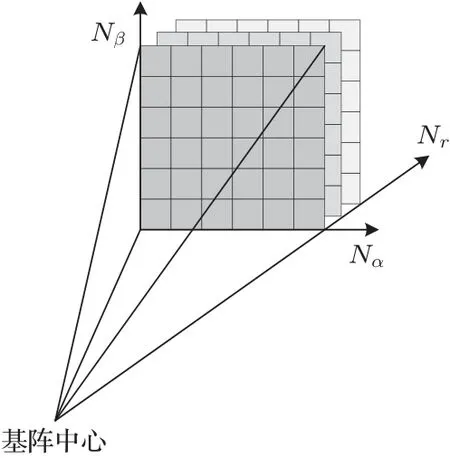
图2 波束形成示意图Fig.2 Schematic diagram of beamforming
由于海洋环境的复杂性,三维成像声呐系统采集得到的回波信号不仅包括探测场景和目标的信息,还包括海洋背景噪声、混响、声呐自身系统噪声干扰等非目标信息。这些干扰在声呐图像上表现为噪点,需要对声呐图像进行预处理,实现抑制干扰、提升图像质量的目的。三维成像声呐成像结果的预处理包括最大值滤波和阈值滤波这两个步骤,可以去除大部分的干扰和噪声,而且操作简单,运算量小,可以实时运行。
1.2 最大值滤波
三维成像声呐的使用场景包括水下地形测绘、水中目标探测等,其中感兴趣目标在整个三维成像空间中表现为若干连续曲面和孤立散射点的集合。而三维成像声呐波束形成之后的波束域数据维度是Nα×Nβ×Nr,表示整个三维成像空间中的散射点的强度分布,其中大部分空间中并不存在目标,其强度为环境噪声,需要将其去除。由于三维成像声呐的工作频率为数百千赫兹且工作距离通常不大于100 m,其声波穿透射能力弱、声线弯曲效应小,同时其波长短,远小于感兴趣目标的尺度,在对感兴趣目标成像时不会发生绕射,同一个波束前方物体会对后方物体造成遮挡。所以对波束域数据按照波束方向进行最大值滤波,即每个波束方向仅仅保留强度最大的点,经过最大值滤波之后的点云中包含了Nα×Nβ个散射点位置信息和强度信息。图3 为方框、渔网、绳子这3种目标最大值滤波后点云。
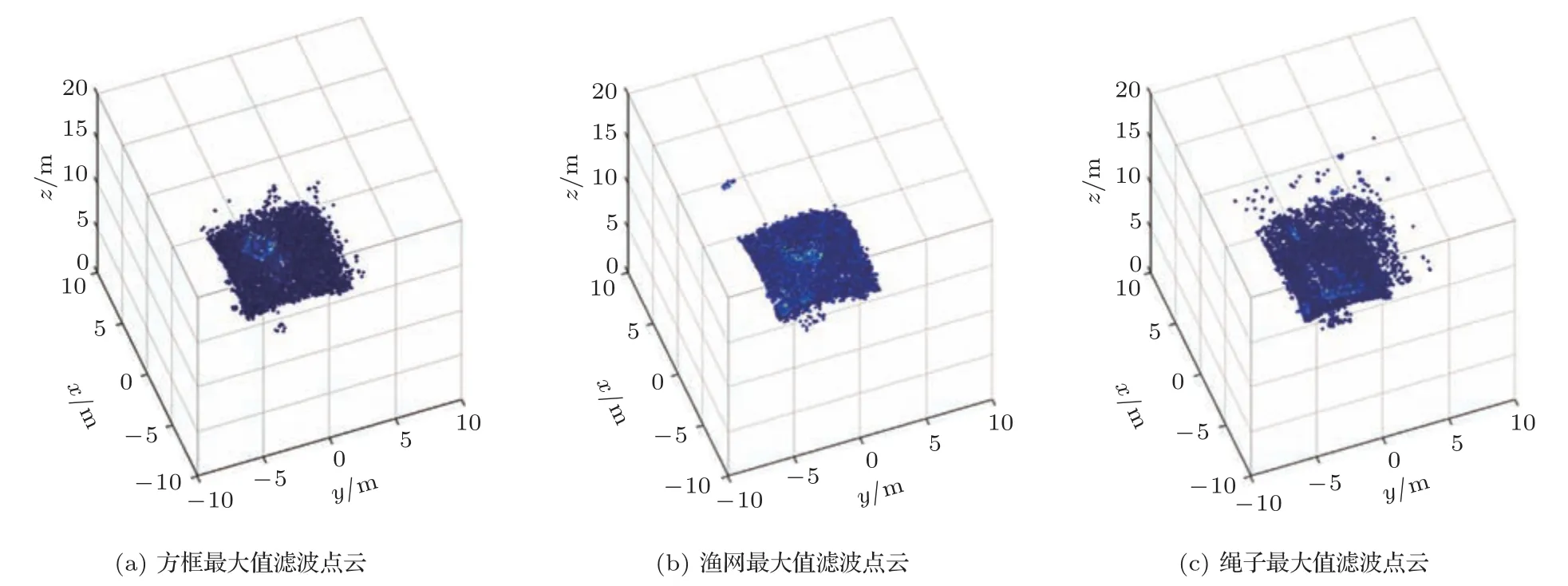
图3 最大值滤波点云Fig.3 Maximum filtered point cloud
1.3 阈值滤波
最大值滤波已经大大降低了数据量,去除了大部分噪声,但是从最大值滤波的输出结果中仍然存在很多噪声,很难分辨出目标。考虑到三维成像声呐通常用于水下小目标探测,感兴趣目标通常不会充满整个观测视野,而且目标的后向散射强度要明显大于环境噪声。根据这一特性,使用阈值滤波将幅度较小的噪声点进行去除,阈值设定为最大强度的22%,即最大强度的第一旁瓣(-13.26 dB)高度。如图4 所示,经过阈值滤波之后便可以看出目标轮廓。为了方便后续将三维点云投影至二维图像,阈值滤波将强度小于设定阈值的散射点强度和距离都置零,这样阈值滤波之后点云中点的个数依旧是Nα×Nβ。
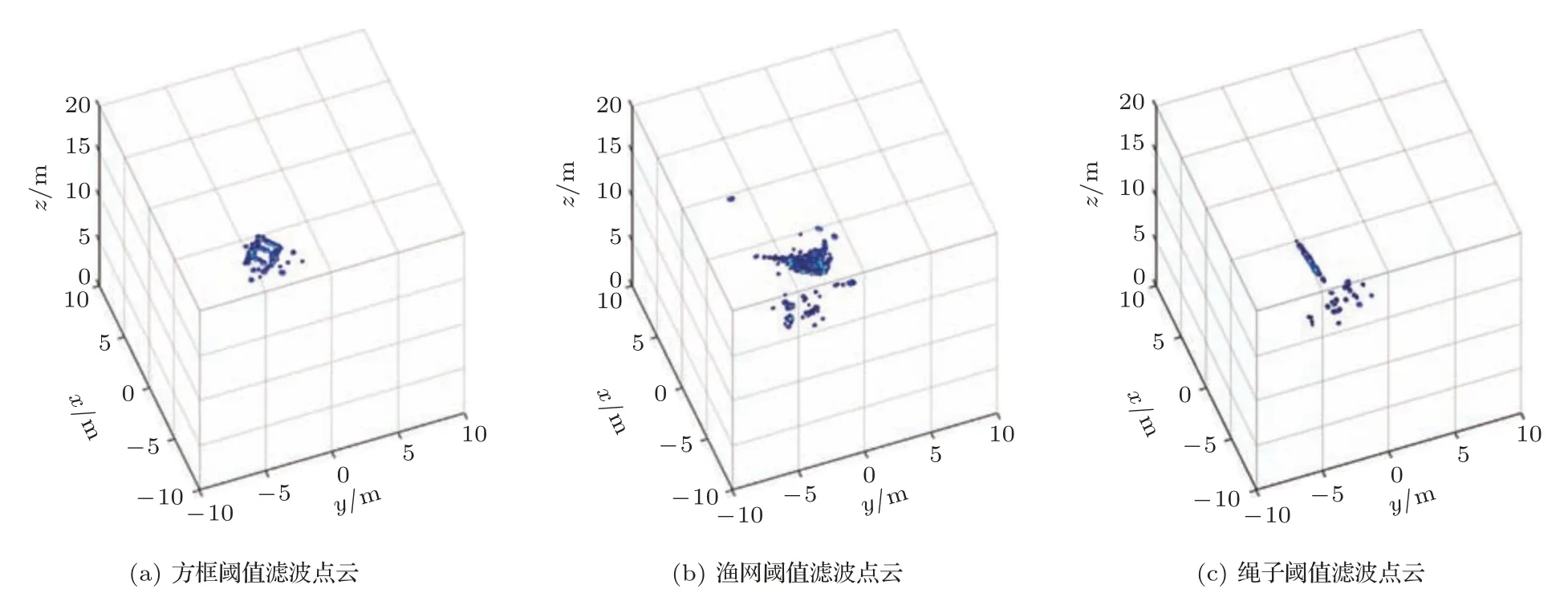
图4 阈值滤波点云Fig.4 Threshold filtered point cloud
2 三维点云至二维图像投影
三维点云具有高度稀疏性和无序性,这两个特点使得三维点云难以处理以及处理运算量大。三维成像声呐生成的点云同样是高度稀疏的和无序的,但是这些点云中的点分布具有一定的规律性,在距离向以及两个角度向都分布在预定义的网格上。利用这个特性,便可以将三维点云投影为二维图像,同时保留点云的强度信息和位置信息。图5 为三维点云至二维图像投影流程图。
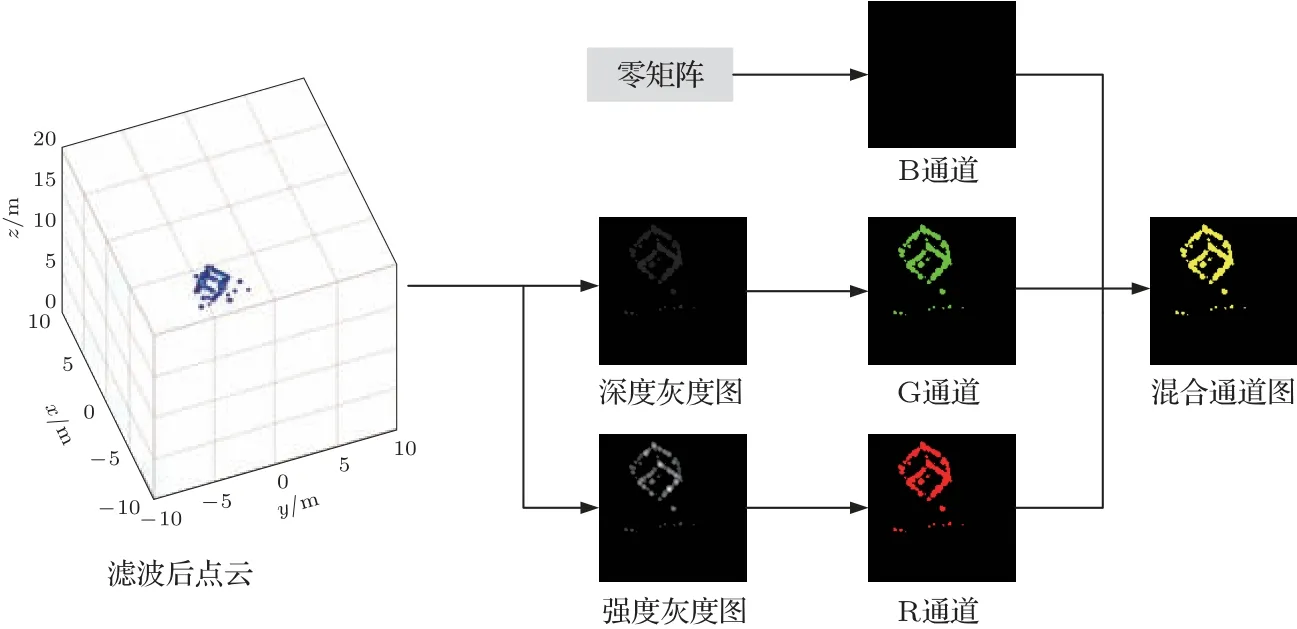
图5 三维点云至二维图像投影流程图Fig.5 Flow chart of 3D point cloud to 2D image projection
2.1 点云生成深度图
经过阈值滤波和最大值滤波之后,三维成像声呐点云中包含了Nα×Nβ个散射点的位置信息和强度信息,Nα和Nβ分别是水平方向和垂直方向的波束数量,其中位置信息为散射点在声呐坐标系下的三维坐标,用公式(8)表示。
将每个波束方向散射点的距离进行归一化处理并且映射至0∼255 区间范围,便可以实现深度图的生成,深度图中每个像素数值与其对应散射点的三维坐标的关系如下:
其中,⎿.」表示向下取整,∥·∥表示取模,∥pα,β∥表示散射点与声呐之间的距离,Rmax为声呐的作用距离。生成的深度图为单通道的灰度图,为了方便观察,将单通道深度灰度图进行伪彩化得到伪深度伪彩图,如图6所示。

图6 不同目标深度图Fig.6 Depth image
2.2 点云生成强度图
和深度图类似,经过阈值滤波和最大值滤波之后的点云中保存了每个波束方向散射点的强度信息bα,β,强度信息也经过归一化处理并且映射至0∼255区间范围,便可以实现强度图的生成:
图7 为生成的强度图为单通道灰度图,同样进行伪彩化得到强度伪彩图。
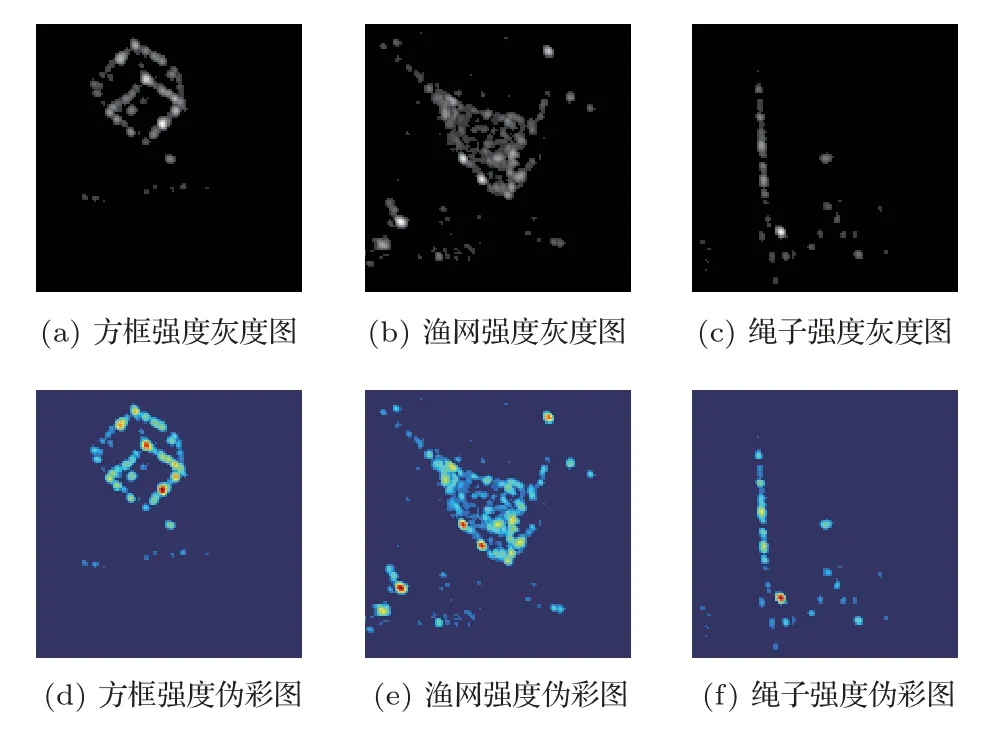
图7 不同目标强度图Fig.7 Intensity image
2.3 混合通道图
三维成像声呐成像结果三维点云中包含的散射点位置信息和强度信息,分别生成深度图和强度图。深度图中像素点的值越大,代表该波束方向的散射点距离声呐越远,强度图中像素值越大,代表该波束方向散射点强度越大。深度图和强度图都是单通道的灰度图,MobileNetV2 网络输入为三通道的RGB 图像。为了在目标分类任务中充分利用三维成像声呐成像结果中的距离信息和强度信息,将深度图和强度图进行融合生成混合通道图。如图5流程图所示,混合通道图是三通道RGB图像,其维度为Nα×Nβ×3,单通道强度图作为混合通道图的R 通道,单通道的深度图作为混合通道图的G 通道,混合通道图的B 通道为零矩阵,图8 为使用各个目标强度图和深度图生成的混合通道图。

图8 不同目标混合通道图Fig.8 Mixd image
3 目标分类网络
三维成像声呐通常搭载于无人平台或者蛙人手持使用,需要目标分类算法实时运行的情况下同时具有计算量小和低功耗的特点。目标分类网络选用轻量化卷积神经网络MobileNetV2,MobileNet是由Google 在2017 年提出的新型轻量化网络[17],适用于移动和嵌入式设备;MobileNetV2 在其基础上进一步改善了网络性能[18],相比普通的全卷积网络能够减少80%∼90%的计算量,与VGG16 等常用网络相比,具有低消耗和实时性等优点,符合实时目标分类任务的要求。
3.1 深度可分离卷积
传统标准卷积既过滤输入又将过滤后的输出进行组合,最终形成一组新的输出,如图9(a)所示。假设卷积核尺寸为DK,特征图的大小为DF,输入通道数为M,输出通道数为N,则标准卷积的计算量为DK·DK·M·N·DF·DF。深度可分离卷积将一个标准卷积分解成一个深度卷积(Depthwise convolutions)和一个逐点卷积(Pointwise convolutions)。深度卷积将输入的每个通道各自与其对应的卷积核进行卷积,产生与输入通道数个数相同的结果,最后将得到的各个通道对应的卷积结果作为最终的深度卷积结果,完成输入特征图的过滤,如图9(b)所示。深度卷积的计算量为DK·DK·M·DF。逐点卷积将深度卷积的结果作为输入,卷积核大小为1×1,卷积过程与标准卷积类似,其通道数与输入一致,完成对深度卷积输出的线性组合,如图9(c)所示。逐点卷积的运算量为M·N·DF·DF。
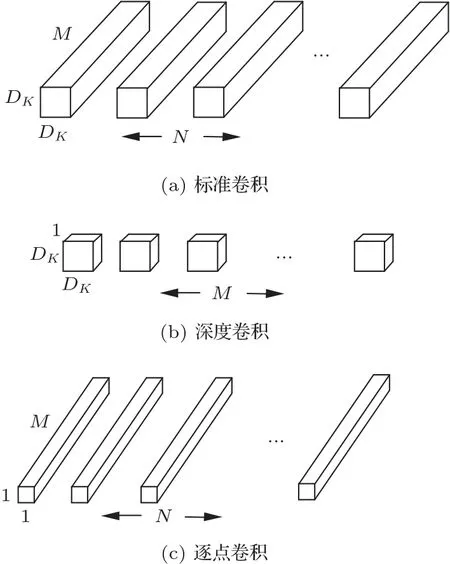
图9 标准卷积与深度可分离卷积过程示意图Fig.9 Schematic diagram of standard convolution and depth-separable convolution
则深度可分离卷积的计算量与标准卷积计算量比值为
由此可见,当使用3×3 大小的卷积核时,深度可分离卷积的计算量可以减小至标准卷积的1/9。
3.2 反向残差结构
反向残差网络结构是先升维、再卷积、最后降维的过程,首先输入通过1×1 的卷积来进行通道扩张以扩展维度,再用3×3 的深度卷积提取特征,最后用1×1 的卷积将通道数压缩,整个过程与残差网络相反,因此称其为反向残差网络。图10(a)和图10(b)分别表示卷积步长为1 和步长为2 的情况下反向残差网络结构图。

图10 反向残差网络结构图Fig.10 Reverse residual network structure diagram
3.3 MobileNetV2分类网络
MobileNetV2 网络相比标准卷积网络具有更低的资源消耗和较高的实时性,MobileNetV2 网络包括普通卷积(Conv2d)、具有反向残差结构的深度可分离卷积(Bottleneck)和平均池化(Avgpool)。MobileNetV2 网络的结构如图11 所示,参数如表1所示。t为中间卷积通道的扩展因子,c为输出通道个数,n表示该层的重复次数,s为卷积步长。
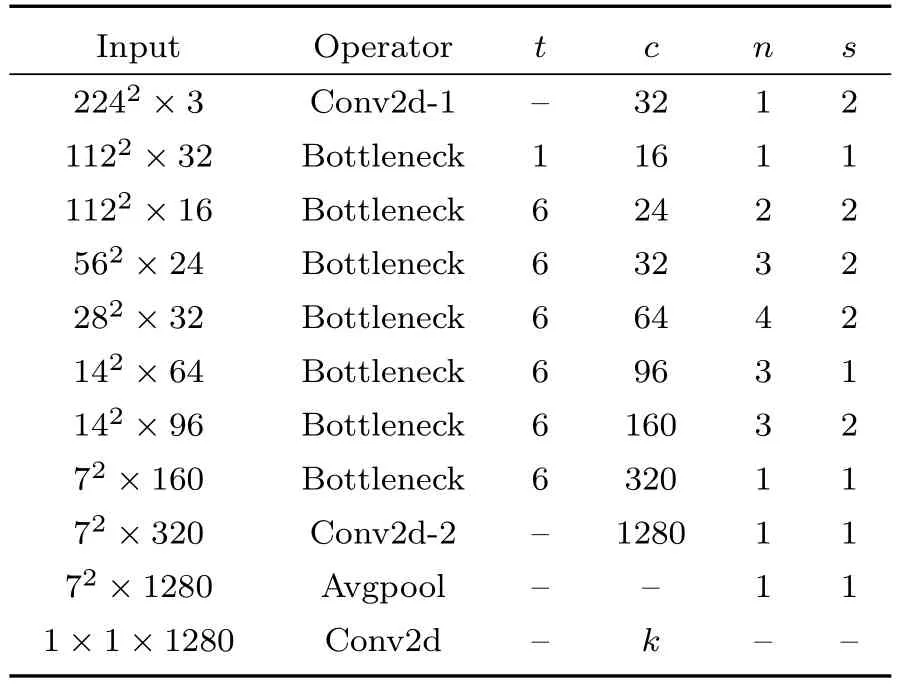
表1 MobileNetV2 网络结构Table 1 Network structure of MobileNetV2

图11 MobileNetV2 网络结构Fig.11 MobileNetV2 network structure
3.4 模型复杂度评估
网络模型的复杂度通常使用参数量和计算量进行评估,卷积层和全连接层的参数量和计算量可以表示
其中,P和F分别代表模型的参数量和计算量,Ml和Kl分别表示输入图片的尺寸和卷积核大小,Cl-1和Cl为输入特征图与输出特征图的通道数,D1、D2为网络中卷积层与全连接层的个数。
4 实验分析
为了验证使用二维图像网络实现三维成像声呐点云目标分类任务的可行性,同时对比不同图像输入情况下网络收敛情况,本文设计了以下实验:首先使用三维成像声呐采集水下目标数据,数据采集场地在杭州千岛湖,三维成像声呐通过支架固定在水下2 m 深的位置,观测方向水平,通过线缆与上位机相连进行控制与供电,实验过程中目标由可移动的船搭载,在3∼30 m 距离内随机移动,进行数据采集。三维成像声呐的参数为:工作频率600 kHz,作用距离120 m,发射信号为CW脉冲,脉宽33 ms,距离分辨率为2.5 cm;接收面阵规模为48×48,阵元间距为2.5 mm,采用512 个采样通道稀疏布阵,接收阵孔径为0.12 m×0.12 m,可以计算得到角度分辨率1◦,方位角范围θα=(-45◦,45◦),俯仰角度范围θβ=(-45◦,45◦)。接着对三维成像声呐获取的回波数据进行波束形成,波束形成过程中设置方位向和俯仰向的波束数目Nα=224、Nβ=224,经过最大值滤波以及阈值滤波之后得到目标三维点云数据,再使用本文所提方法将三维点云数据投影至二维图像制作实验数据集。选取铁框、渔网、绳子3 种水下物体作为分类的目标,分别建立深度图、强度图及混合通道图的数据集。3 个数据集各有494 张图像,图像尺寸为224×224,其中铁框图像210 张,渔网图像132张,绳子图像152 张。使用MobilenetV2 及其他网络模型作为特征提取部分对网络进行训练,对比不同输入下模型的训练、测试结果,验证混合通道图对水下目标的分类效果。实验使用的所有网络均基于Keras 深度学习框架基础,实验计算机采用CPU 为6 核i7-10750H、Windows 操作系统、GPU为RTX2070。
4.1 不同输入数据下MobileNetV2 模型分类准确率
使用上述数据集,分别将水下目标的深度伪彩图、强度伪彩图及深度强度混合通道图作为网络的输入部分,利用MobileNetV2 模型对水下目标进行分类。根据网络和数据集设置的学习率大小为0.00005,迭代次数设置为100,训练批次batchsize为16,采用分类交叉熵作为代价函数。将目标数据集中的398 张图像作为训练集对模型进行训练,将其余的96 张作为测试集进行测试。对该模型进行100 次的运行测试,取平均值作为最终模型准确率。图12 为不同输入数据下MobileNetV2 模型训练过程代价函数值及分类准确率随迭代次数的变化曲线,表2 为不同输入数据下MobileNetV2 网络的分类结果。
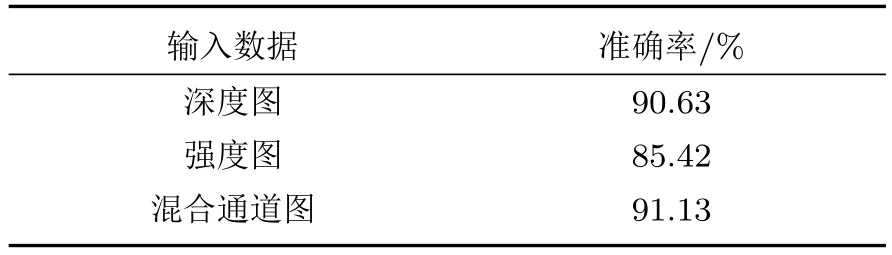
表2 不同输入数据下模型分类准确率Table 2 Model classification accuracy under different input data
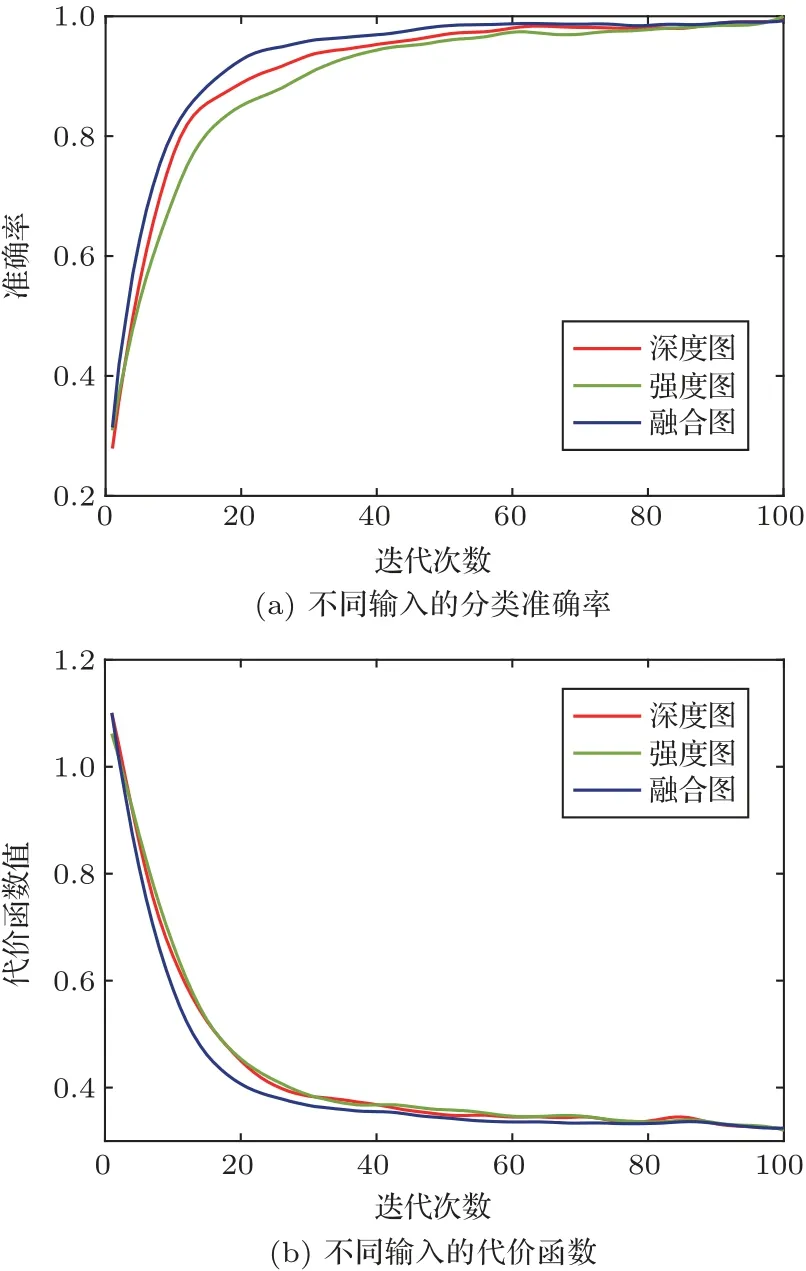
图12 训练过程曲线Fig.12 Change curve of training process
由训练过程曲线及表中数据可以看出,本文所提出的投影方法结合轻量化卷积神经网络Mobilenetv2,可以实现三维点云目标分类任务。在模型训练过程中,使用混合通道图作为网络输入得到的代价函数训练曲线相比单纯使用深度图或者强度图得到的训练曲线收敛更快,此种情况下模型的分类性能更好。同时,在水下目标分类任务中,将混合通道图作为模型输入得到的分类准确率达到91.13%,相比深度图和强度图作为模型输入时的分类准确率平均提高0.5%和5.71%。由此说明,目标的强度深度混合通道图包含深度图和强度图两种特征的数据,网络学习到的目标信息更为全面,有利于提高分类准确率。
4.2 轻量化性能比较
MobileNetV2 网络中的深度分离卷积模块相比标准卷积具有轻量化的特点,为了验证本文所使用模型的轻量化优势,分别使用VGGNet16、ResNet50 与本文MobileNetV2 网络在水下目标数据集上进行特征提取和分类实验。实验使用数据集为铁框、渔网、绳子3 种水下目标的混合通道图,训练过程中的模型的参数设置均与4.1节实验相同,将混合深度图数据集中的398张图像作为训练集对模型进行训练,剩余部分作为测试集进行测试。几种不同模型的参数量如表3所示。

表3 不同模型参数量Table 3 Different network model parameters
由表3 中的数据能够看出,VGGNet16 网络的参数量高达121.58 M,其参数量在3 个模型当中最大,由此可见该模型的空间复杂度较高,对计算机硬件资源的要求较高。ResNet50 的参数量为45.75 M,相比VGGNet16减少一半以上,而本文使用的MobileNetV2 模型参数仅为2.28 M,模型参数量较小,能够有效应用到各种嵌入式设备中。
4.3 模型计算速度比较
由公式(11)可知,当使用3×3大小的卷积核时,深度可分离卷积的计算量可以减小至标准卷积的1/9,与计算量相对应的是模型的计算速度。为了进一步衡量本文使用模型在水下目标分类任务中的计算速度,分别使用VGGNet16、ResNet50 与本文MobileNetV2网络对水下目标图像进行特征提取和分类,所使用的数据集及参数设置均与4.2 节实验相同,3 种模型的计算速度如表4 所示。其中,训练时间是指模型在训练过程中对每张图像耗费的时间,测试时间是指模型在测试过程中对每张图像进行预测所需要的时间。

表4 不同模型计算速度Table 4 Computational speed of different network models
从训练时间来看,VGGNet16 训练每张图像所需要的时间为17 ms,ResNet50 则需要20 ms,本文MobileNetV2 模型只需要9 ms 即可完成对每张图像的训练,训练时间减少一半左右。从测试时间来看,VGGNet16 对每张图像的预测时间最长,需要27 ms,ResNet50 预测每张图像需要13 ms,而MobileNetV2 仅需要4 ms 便可实现对图像的类别预测。不同模型的实验结果表明,VGGNet16 及ResNet50 网络在训练和测试时间上均大于本文所用的模型。由此可见,本文所用模型计算时间较短,对于实时性要求较高的水下目标分类任务更具优势。
4.4 不同模型分类准确率
在充分考虑模型参数及计算量的基础上,使用VGGNet16、ResNet50 与本文MobileNetV2 网络对水下目标图像进行特征提取和分类,通过分类准确率进一步衡量本文使用模型的分类性能。实验使用的数据集仍为3 种目标的混合通道图,将其中398张图像作为训练集进行模型训练,剩余部分作为测试集,参数设置与前述实验相同,对3 个模型均进行100 次的运行测试,取平均值作为最终模型准确率,实验结果如表5所示。

表5 不同模型分类准确率Table 5 Model classification accuracy of different network models
由此可见,本文MobileNetV2 模型与VGGNet16 模型对上述3 类目标的分类准确率达到91%以上,相比ResNet50模型要高出2.3%左右。但是综合考虑4.2 节及4.3 节中VGGNet16 较高的参数量和计算代价,本文方法在该水下目标分类任务中具有更好的实用性。
5 结论
本文对三维成像声呐目标分类这一问题进行了研究。首先,针对三维点云目标分类网络计算量大的问题,从三维成像声呐波束形成原理出发,提出了一种在不丢失目标散射点位置信息和强度信息的前提下将三维成像声呐点云投影至二维图像的方法,从而可以使用二维图像分类网络实现三维成像声呐点云目标分类任务。接着使用MobileNetV2网络实现了三维成像声呐快速目标分类,通过对比深度图,强度图以及混合通道图分别作为网络输入的实验结果,可以看出混合通道图比单独的深度图和强度图收敛速度更快,目标分类准确率也更高,说明了三维成像声呐所获取目标的位置信息和强度信息对于目标分类都非常重要。然后通过和VGGNet16、ResNet50 对比,可以看出MobileNetV2 在保证目标识别正确率的情况下具有网络参数少、运行速度快的特点。
猜你喜欢
中学生数理化·八年级物理人教版(2022年9期)2022-10-24
海洋信息技术与应用(2020年3期)2020-08-24
小学科学(学生版)(2019年10期)2019-11-16
计算机应用(2019年3期)2019-07-31
通信技术(2019年3期)2019-05-31
电子测试(2018年6期)2018-05-09
声学与电子工程(2017年1期)2017-06-22
软件导刊(2016年9期)2016-11-07
科技视界(2016年2期)2016-03-30
四川师范大学学报(自然科学版)(2015年4期)2015-02-28
