
Image Recognition Model of Fraudulent Websites Based on Image Leader Decision and Inception-V3 Transfer Learning
2024-02-29 10:34ShengliZhouChengXuRuiXuWeijieDingChaoChenXiaoyangXu
China Communications 2024年1期
Shengli Zhou ,Cheng Xu ,Rui Xu ,Weijie Ding ,Chao Chen ,Xiaoyang Xu
1 Information Department of Zhejiang Police College,Hangzhou 310053,China
2 Hangzhou Dianzi University,Hangzhou 310018,China
3 Big Data Laboratory of Zhejiang Police College,Hangzhou 310053,China
4 Hangzhou Public Security Bureau,Hangzhou 310002,China
Abstract: The fraudulent website image is a vital information carrier for telecom fraud.The efficient and precise recognition of fraudulent website images is critical to combating and dealing with fraudulent websites.Current research on image recognition of fraudulent websites is mainly carried out at the level of image feature extraction and similarity study,which have such disadvantages as difficulty in obtaining image data,insufficient image analysis,and single identification types.This study develops a model based on the entropy method for image leader decision and Inception-v3 transfer learning to address these disadvantages.The data processing part of the model uses a breadth search crawler to capture the image data.Then,the information in the images is evaluated with the entropy method,image weights are assigned,and the image leader is selected.In model training and prediction,the transfer learning of the Inception-v3 model is introduced into image recognition of fraudulent websites.Using selected image leaders to train the model,multiple types of fraudulent websites are identified with high accuracy.The experiment proves that this model has a superior accuracy in recognizing images on fraudulent websites compared to other current models.
Keywords: fraudulent website;image leaders;telecom fraud;transfer learning
I.INTRODUCTION
Telecom fraud has caused serious harm to national security,political stability,social order,and people’s rights to life and property and can easily lead to other crimes.Cyber fraud is characterized by few contacts,strong camouflage,and difficulty of detection.It has become an important policing issue in social governance.According to statistics from the Ministry of Public Security,crimes across the country have shifted from offline to online on a large scale,and the number of victims is increasing exponentially.Considering the severity of the situation,an integrated system of preventing and cracking down on fraudulent websites is urgently needed.By analyzing the characteristics of fraudulent websites,we can block such crimes effectively and accurately reveal their nature.A prominent information medium and carrier for recognizing fraudulent website images is vital to crack down on fraudulent websites.
This paper proposes an image recognition model for fraudulent websites based on image leader decisions,referred to as IRM-FWLD.It addresses the problems of insufficient model feature learning and single identification of fraudulent website types due to the limited image samples,difficulty obtaining data,and insufficient analysis of the information contained in images.The IRM-FWLD model makes image leader decisions by combining gradient,color,and texture features.It selects images with high information content for model training and improves recognition accuracy.This study applied the Inception-v3 model to fraudulent website recognition.Combined with transfer learning technology,it accurately identifies multiple websites based on small sample image data,including gambling,pornography,and normal sites.
II.RESEARCH AT HOME AND ABROAD
With the development and application of big data and artificial intelligence,extensive in-depth research has been carried out on fraudulent website recognition.Most current research focuses on the URL,HTML[1–5],and text features [6–9] combined with deep learning,sensitive feature selection,similarity analysis,and attention mechanisms.However,as antiinvestigation awareness of crime improves,the weight of URL keywords and text features of a fraudulent nature is reduced,which lowers the identification accuracy of fraudulent websites.Compared with the features of URL,text,and other dimensions,the images of fraudulent websites are unique in actual application.Based on image recognition technology used widely in many fields [10–12],this technology is being implemented in fraudulent website recognition research.Current research focuses more on optimizing model performance [13–15],while the research on fraudulent website recognition started relatively late.Fraudulent website image recognition analyzes the icons,images within pages,and text in images of fraudulent websites.For example,the analysis method proposed by Liu Yongming et al.[16]for dynamic detection applications utilizes hash perception algorithms to detect real-time human-machine interaction similarity with the target application interface.Zhang Menni et al.[17] proposed using the DAN method to quickly recognize unknown fraudulent websites by utilizing fraudulent website images combined with the AlexNet model.In addition,Chen Shihan et al.[18]identified fraudulent websites by considering URLs,HTML,images,and other multi-dimensional features.Considering that the existing research rarely considered the text features contained in the images in the static files of web pages,Zhou Feng et al.[19] realized the accurate identification of fraudulent websites by using the SVM algorithm to extract text features from images.These methods have problems in the process of fraudulent website recognition,such as insufficient feature information [16],information redundancy [18],and low recognition accuracy[17,19].Most studies identify a single type of fraudulent website,and little research has been done on the multi-classification identification of fraudulent ones.This paper proposes a fraudulent website image recognition model based on image leader decisions.By mining the RGB,gradient change,and texture features of known fraudulent website images and combining these features with the entropy method,images with high information content are selected to form a training set.The Inception-v3 model is combined with transfer learning technology to identify multiple types of fraudulent websites with limited sample image data.
III.MODEL DESIGN
IRM-FWLD mainly includes two parts,leader decision and fraudulent website image recognition algorithm,which is shown in Figure 1.
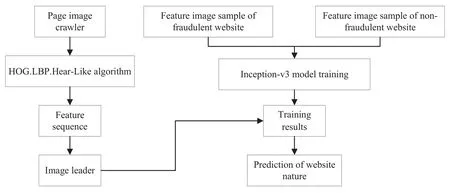
Figure 1. Flowchart of IRM-FWLD.
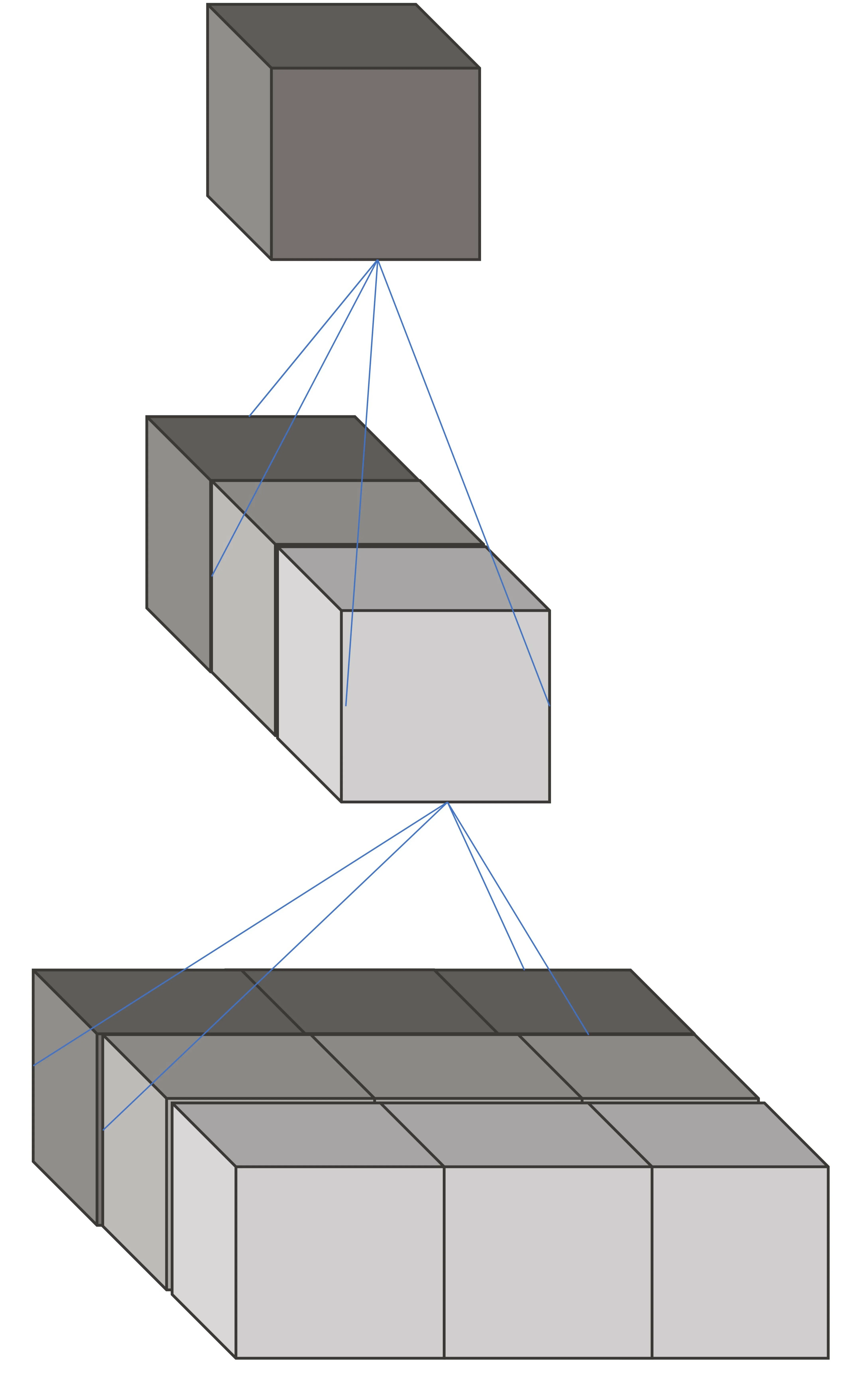
Figure 3. Convolution kernel asymmetric decomposition.
3.1 Image Crawling
Image crawling adopts a breadth-first search algorithm to crawl all the links of the target website for classification.The website page is regarded as a tree structure represented by G(V,E),where G represents the website,V is the collection of web pages,and E is the collection of images.It marks and saves the current page’s image and simultaneously searches for different images to crawl layer by layer.
3.2 Image Leader Decision
3.2.1 Image Feature Sequence
IRM-FWLD judges the amount of information in an image based on gradient,color,and texture features.The algorithm calculates the image features separately,and then,the feature vectors in the three parts are used to express the image feature sequence.
Step 1: gradient feature
The gradient changes around the edges and corners of an image are obvious,so the gradient feature is often used to represent the shape of an object.The Histogram of Gradients (HOG) expresses the change in gradient direction and gradient size of the image.The input image is normalized by cropping the canvas size,redefining the resolution size,removing the background,and adopting Gamma correction.The Gamma correction equation is as follows:
The amplitude and direction of the vertical and horizontal gradients are calculated.The image is divided into small units,and the gradient histogram array value is calculated to express the gradient change of the image.
Step 2: color feature
Color moments can express image color features effectively.First,the first moment(mean)of the image color is calculated.The equation is as follows:
Next,the second moment (variance) is calculated.The equation is as follows:
The third moment (skewness) is calculated as follows:
Through the third-order color moment calculation,the image feature vector is finally obtained and stored in an array.Image color features are generally distributed in low-order moments.Color moments can express the distribution of color features accurately in the case of fewer feature dimensions and are widely used in image filtering to narrow the scope of retrieval.
Step 3: texture feature
The academic community believes that with the gray-level co-occurrence matrix algorithm,a computer language can replace the gray-level direction,change,and other image features of natural images.The algorithm analyzes the arrangement and combination of local texture and internal elements.Converting an image to a grayscale matrix image for quantization permits the grayscale co-occurrence matrix to be calculated.Next,the matrix is segmented to form multiple windows.The eigenvalues of the cooccurrence matrix are calculated for each window.The angular second-moment matrix is used to measure the grayscale distribution and texture of the image as follows:
The contrast is calculated to represent image resolution,texture groove change,and local shape as follows:
The inverse differential moment matrix is calculated to reflect whether the texture is regular and natural.The equation is as follows:
To reflect whether the size of the image feature and the law are random,the entropy is calculated as follows:
The mean and variance of the matrix expressed by the window are calculated and represented as an array,which is used as an image texture feature to eliminate the influence of the direction component on the texture feature.
Finally,the three-dimensional vectors of gradient,color,and texture are combined and expressed as an image feature sequence.
3.2.2 Leader Decision
To address the problem of insufficient consideration of the information contained in the image samples in previous studies,image feature leader decisions were made to select images that carry more information as training data for the model.Images retrieved on the same website are converted into corresponding image feature sequences.Since the feature numbers of each dimension in the sequence are different and the amount of information carried is different,the entropy method is used for weight calculation.The sequence is transformed into a matrix X(3×m),where 3 is the dimension and m represents the eigenvalue of each dimension.Xijindicates the j-th feature value of the i-th feature of the image.The equation is as follows:
The sequence is normalized as follows:
The entropy value of each index is calculated as follows:
The weight of each index is calculated as follows:
Finally,the weight value of each index is obtained,and each fraudulent website image is assigned a score based on this weight.The images with higher scores are selected as the image leaders,which are used to form the training set of the model.
3.3 Fraudulent Website Image Recognition Algorithm
By comparing the image features of fraudulent websites (please refer toExperimental Procedurefor detailed analysis),it can be observed that fraudulent websites generally have large areas of single colors,multiple dynamic flashes,multiple special representative symbols,and counterfeit registered icons.Moreover,images of the same type of fraudulent websites are quite similar,indicating that those image features are highly useful for fraudulent website recognition.However,as fraudulent websites often contain sensitive information and are strongly camouflaged in a wide range of types,traditional image recognition methods may result in a low recognition rate due to a severe shortage of training samples.This paper proposes a fraudulent website image recognition algorithm based on the Inception-v3 model that considers the situation there are few samples and multiple features of fraudulent website images.It is combined with transfer learning to better adapt to research on fraudulent website image recognition.
3.3.1 Convolutional Network Construction and Convolution Kernel Decomposition
We standardize image input,traverse,and import datasets of fraudulent website image classification,redefine image size,resolution,and other element features,form an image matrix described by RGB values,and finally use it as input.
We circularly extract features,build a convolutional neural network,and use the convolutional layers to extract image feature elements.They are mainly used to position and recognize elements in the image of the model,segment targets,and detect key parts.
Next,we calculate the convolution kernel and input the average weight of each image pixel to the model to collect features in the same area.Weights are shared to reduce parameters,optimize efficiency,and maintain the learning effect.
Figures 2 and 3 show the convolution kernel’s construction and decomposition.
3.3.2 Reduced Feature Map via Convolution Kernel Decomposition
We establish parallel pooling modules,convolution modules,and input feature maps and then combine the outputs to obtain a reduced feature map.The reduced feature map greatly reduces the calculation load while avoiding feature loss and maintaining the precision of the model.Parallel modules are shown in Figure 4.
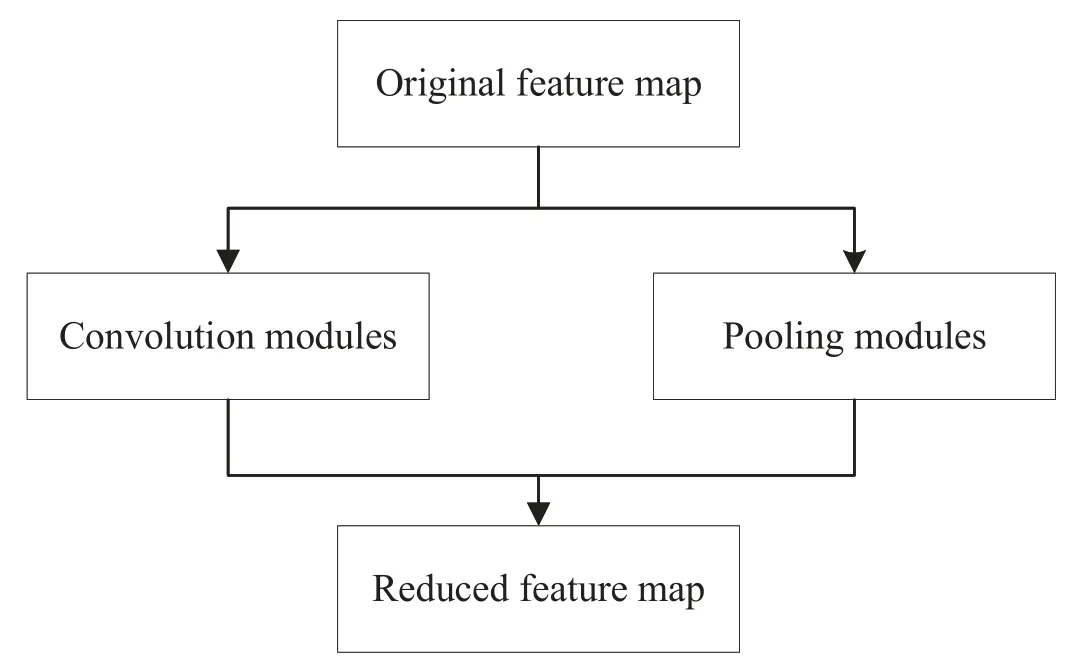
Figure 4. Flowchart for obtaining a reduced feature map.
3.3.3 Label Smoothing Regularization
The theory of label smoothing regularization is added to the model,which calculates the loss of the wrong label position to reduce the error rate.
The probability that the image output through the activation function belongs to a different website category is calculated,where Piis the probability that the current sample belongs to category i,ziindicates the classification rating corresponding to current sample i,and n is the total number of samples.The equation is as follows:
The cross-entropy is calculated as the sample loss as follows:
Finally,y is set as the label of the sample through one-hot encoding,ϵ is the smoothing factor,and the sample smoothing label equation y′is as follows:
The label smoothing process takes greater account of the error samples in the loss function so that the classification result of the SoftMax activation function is closer to the correct result,improving the precision of recognition.
3.3.4 Inception Layer
Given the difficulties in obtaining image data from various fraudulent websites,model training convergence is difficult,and the model’s generalization is poor due to the small number of images.Based on the pretrained Inception-v3 model,itself based on the ImageNet dataset,this paper extracts the shallow features of the image.It incorporates transfer learning to construct the image recognition model in the IRMFWLD model.Transfer learning applies a model that completes learning tasks in a certain field to learning tasks in a new field.Since the features learned in the front layer of a network model are general ones,some model parameters with similar general features can be migrated to the target task model,which can greatly shorten the training time of the model and improve its generalization.
In transfer learning,the shallow feature convolution layer,but not the last fully connected layer or the output layer,is saved to reduce the training scale of the model.The pre-training model is fine-tuned using the image dataset of fraudulent websites,and a new,fully connected layer and output layer are trained.Then,the final image recognition model is generated.The Adam optimizer algorithm is used in the finetuning process to find the optimal parameters of the model to solve the problem that some parameters in the model have trouble converging.The advantage of the Adam algorithm is that it automatically adjusts the learning rate to adapt to the characteristics of different parameters.Also,cross-entropy is used as the training loss function to evaluate the gap between the predicted value and the real value during training and further optimize the training effect of the fully connected layer.In backpropagation,the model quickly updates model parameters according to the gradient information of cross-entropy loss.After rounds of training,the fully connected layer of the fraudulent website image recognition model is obtained,and the output layer parameters are modified to generate the output.The pseudocode for IRM-FWLD is shown in Algorithm 1.

IV.EXPERIMENT AND ANALYSIS
4.1 Experimental Setup
The dataset used in the experiment is obtained through the web crawler module in the IRM-FWLD according to the marked fraudulent website URLs provided by the actual combat department.The dataset includes 3800 images of fraudulent websites,divided into three types: gambling,pornography,and normal.Table 1 shows the number of image types in the dataset.
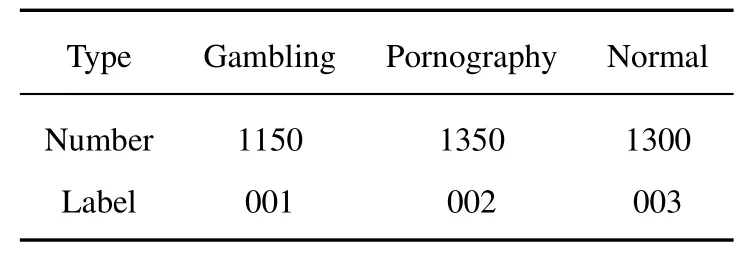
Table 1. Fraudulent website image dataset.
4.2 Evaluation Index
4.2.1 ROC Curve
The ROC curve indicates the precision of the model.The abscissa is the FPR,indicating the probability that a wrong sample is predicted to be the correct one.The ordinate is the TPR,indicating the probability that a correct sample is predicted.This study represents different classification predictions by drawing each classification’s ROC curve.
The diagonal line in the ROC curve represents perfect chance,and the farther the curve is from the diagonal line,the more effective the classification.The ACC area lies below the curve,and the larger the area,the more effective the classification.
4.2.2 Precision and Recall
TP represents the number of fraudulent website images successfully identified as fraudulent,FP represents the number of normal website images misidentified as fraudulent,and FN represents the number of fraudulent website images that failed to be recognized.The equation for the precision rate P is as follows:
and the equation for the recall rate R is as follows:
The precision and recall rates show the wane and wax along with the change of parameters.The optimal parameters of the optimal Inception-v3 model in fraudulent website image recognition are determined by adjusting various parameters to balance precision and recall.
4.3 Experimental Procedure
4.3.1 Crawling Website Feature Images
The address of each webpage of the suspicious websites is crawled using breadth-first traversal and then put into the address sequence.With the depth of the crawling webpage set to 3,we use the regex match method to obtain the image address in the webpage source code and download the image of the same website in the same folder.
4.3.2 Extracting Image Features
We read the images in the same folder (for the same website)in a loop,calculating their gradient direction and amplitude.Next,it is converted into a gradient histogram,the HOG feature vector of the image is calculated,and the gradient features of the image are expressed.Then,we uniformly convert the image into the HSV mode,calculate the mean,standard deviation,and gradient,and put them into a one-dimensional array to form image color features.We set the maximum grayscale of the image to 16,shrink images with a grayscale greater than 16,normalize the size of the gray-level co-occurrence matrix,and finally calculate the gray-level co-occurrence matrix to express the image texture features.The three types of features are put into the image tuple for expressing each image.
Since a normal website image sample contains various website types,the image data do not have a fixed gradient,color,or texture features,so the image leader decision of a normal website image is not made in IRM-FWLD.A fraudulent website usually has a special design;common characteristics can be found among these images by observing different image features.
Grayscale images are important in converting images into program input and in reducing data volume.By converting fraudulent website image samples into grayscale images,the brightness of image colors can be analyzed quantitively.Figure 5 shows the grayscale histogram of an image sample,which is used to express the frequency of occurrence of the grayscale value of different image pixels.It is formed by the mapping between its gray value and frequency.By analyzing a large number of samples,it can be seen that the grayscale values of fraudulent website images have a small concentration in the frequency domain from 200 to 255,indicating that the UI design of fraudulent websites is generally bright.
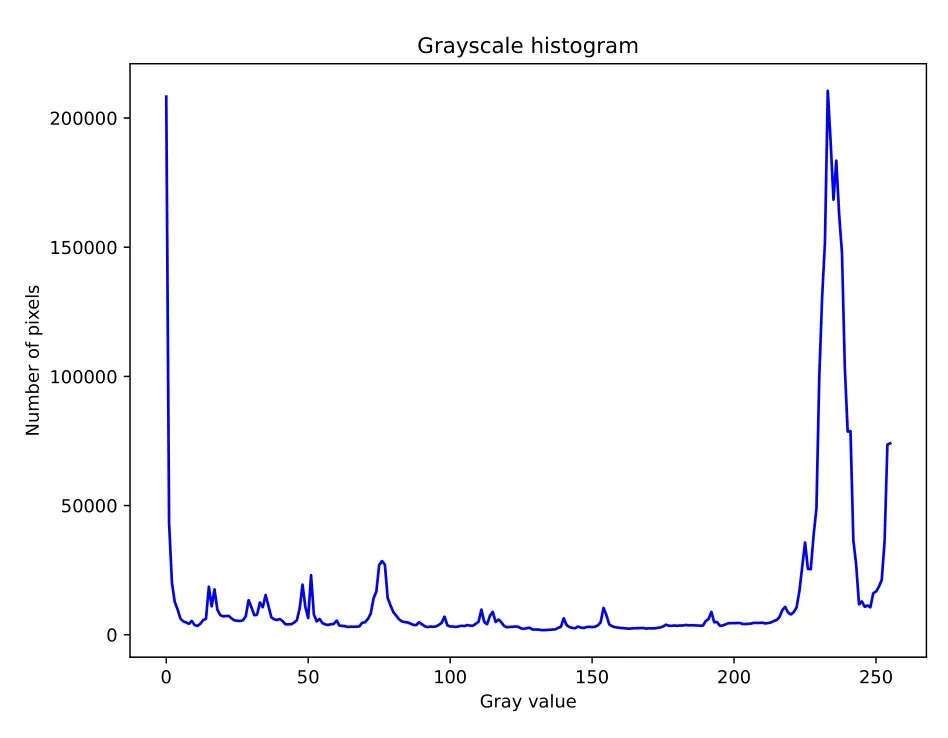
Figure 5. Grayscale histogram of image samples.
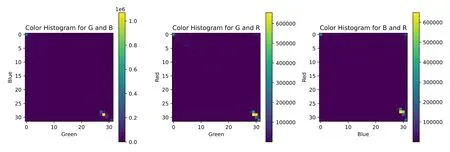
Figure 6. Color feature maps of image samples.
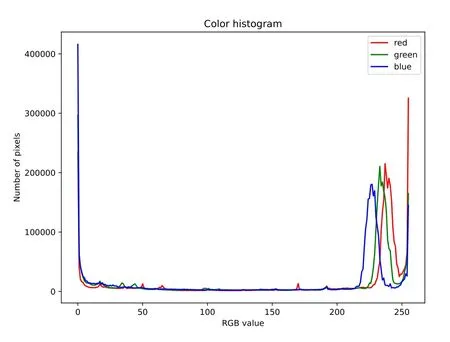
Figure 7. Color histogram of image samples.
The color feature map and RGB histogram of the image samples are shown in Figures 6 and 7,respectively.An analysis of the color feature map shows that the images of fraudulent websites have fewer composite colors,and their colors are marginalized.According to a statistical analysis of the RGB histogram,the frequency and scope of red exceed those of green and blue.
The GLCM texture feature map of the image sample is shown in Figure 8.Through the analysis using the GLCM algorithm,the images of fraudulent websites show element repetition and a primitive arrangement rule.The images usually show a single texture direction,concentrated spacing,a small change range,and local uniformity.
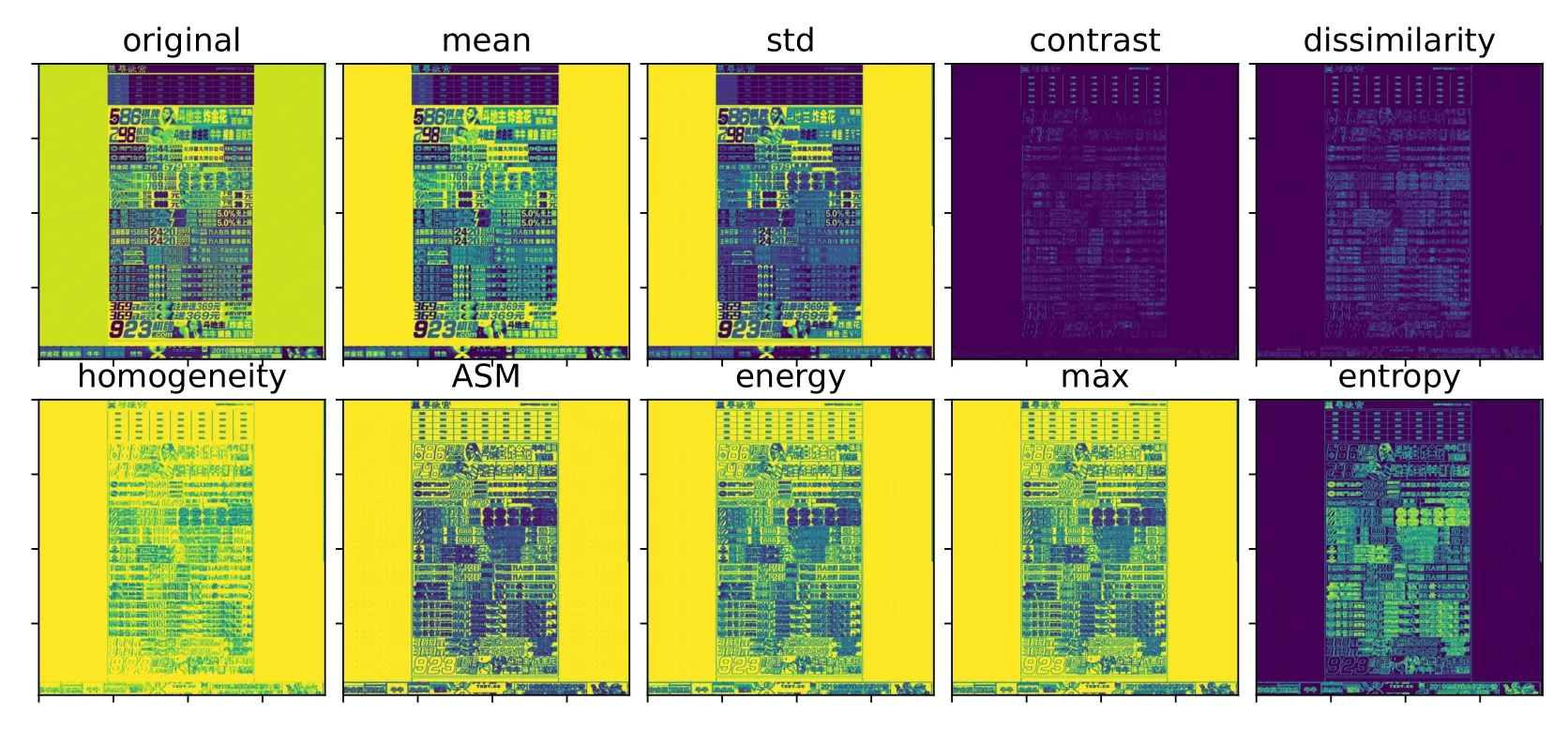
Figure 8. GLCM texture feature maps of image samples.
The LBP texture features of image samples are shown in Figure 9.The LBP algorithm is used to calculate the local features of image samples.The LBP algorithm’s analysis of fraudulent website images shows that their textures have maximum similarity.

Figure 9. LBP texture feature map of image samples.
4.3.3 Image Leader Decision
The image feature sequence is converted into a matrix,and the data are processed according to the image feature matrix and normalized to obtain 20 image features.In turn,the entropy method is used to calculate the score of each image according to the total of the 20 image features.Then,the feature values of each image with the same label are compared according to their scores,and the higher-scored images are used as the image leader to form the model training set.The sample score results of some fraudulent gambling websites are shown in Table 2.

Table 2. Sample scores of gambling fraudulent websites obtained by entropy method.
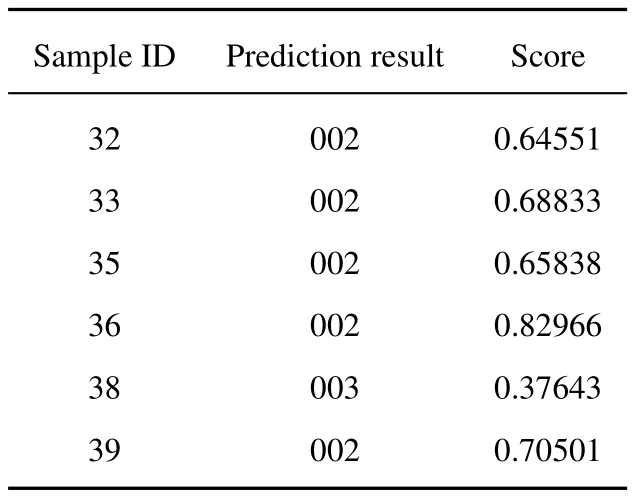
Table 3. Examples of prediction results.
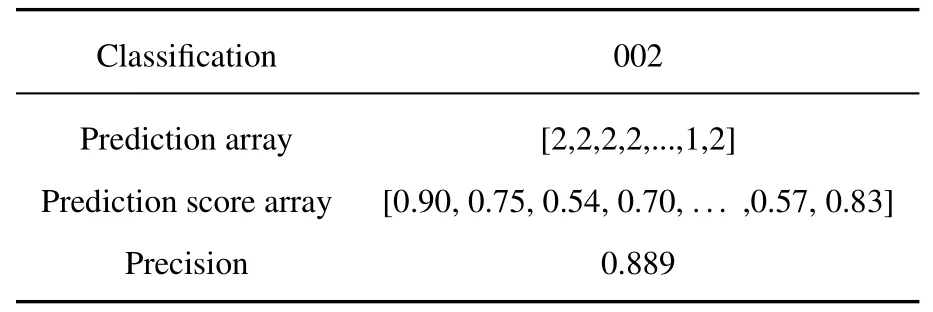
Table 4. Prediction results of pornographic websites.
4.3.4 Inception-V3 Model Training and Result Prediction
The dataset is split into a training set and a test set according to the image leader decision score results in the ratio of 9:1.The format of all types of fraudulent website images in the training set is unified as 224×224×3,which is imported into the Inception-v3 pre-model for transfer learning,and the parameters are adjusted.The step size is set to 4,000,the learning rate is 0.01,and the batch size is 256,forming a fraudulent website image recognition model.The test set is imported to verify the model’s and test set’s accuracy.Finally,the goal of identifying the nature of the website based on gambling,pornography,and the normal types of website images is achieved.The prediction results of data labeled 002 (pornography) are shown in Tables 3 and 4.Table 5 shows the prediction results for fraudulent website image classifications.
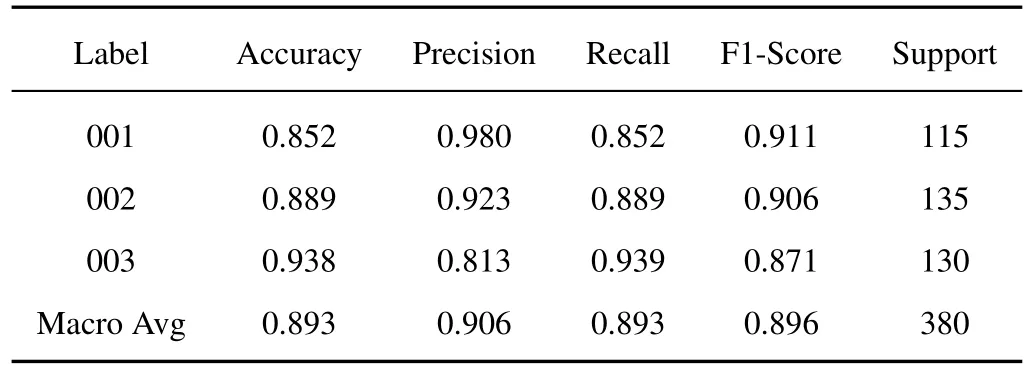
Table 5. Fraudulent website image classification prediction results.
The ROC curves of the predicted results are shown in Figure 10.
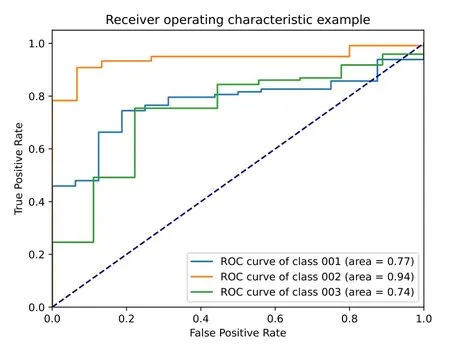
Figure 10. ROC curve comparison of each class.
According to Table 5,the precision of IRM-FWLD in predicting the test set data was 0.893,and the recall rate was 0.906.The traceability analysis indicates that the macro average precision of image recognition of fraudulent websites is superior.However,some classified images have a low recognition rate because of the diversity and complexity of the classified fraudulent websites.For example,gambling websites are often combined with pornographic websites,resulting in many forms of gambling websites,so the precision is not high.Also,the datasets in this paper are widely classified in the normal websites,and the FN value is low,which results in a low recall rate.The ROC curve in Figure 10 shows that the pornographic website curves are closer to the TPR axis;normal websites are closer to the diagonal.The model in this paper has different prediction accuracies for different types of fraudulent websites:the AUC of pornographic websites is the highest,the AUC of gambling websites is the second,and the AUC of normal websites is the lowest.
4.3.5 IRM-FWLD Ablation Experiments
Ablation experiments were carried out to verify the effect of the image leader decision module based on the entropy method.The images of gambling and pornography fraudulent websites in the dataset were randomly divided,and the training and test sets of the model were obtained with a ratio of 9:1.The experimental results are shown in Table 6.

Table 6. Image leader decision module ablation experimental results.
The ablation experiment results show that the accuracy,precision,recall rate,and F1 score of the model of non-image leader decision are lower than the prediction results of the model of image leader decision,that is,this module can improve the recognition effect of the model for different types of fraudulent websites.According to the analysis,the image samples containing low information are used to train the model when random division is done.This leads to the model not learning part of the image features adequately when few samples are used for training.Through the image leader’s decision,images with high information are found stably,and the learning effect of the model on image features can be improved.
A comparative experiment was conducted to verify the effectiveness of Inception-v3 transfer learning.The parameters of each layer in the Inceptionv3 model are randomized,and the training set is used to train the entire Inception-v3 model.The trained Inception-v3 model is tested with the same test set.The experimental results are shown in Table 7.

Table 7. Comparison results of transfer learning effect.
According to this comparison,an image recognition model of fraudulent websites without transfer learning technology needs more training time than one using transfer learning technology,so transfer learning has advantages in terms of accuracy,recall,and F1 value.The model without transfer learning in the same training round has not fully learned all the features in the image data of the fraudulent websites.The lower recall rate without transfer learning also indicates that the classification of normal websites in the dataset of this paper is wide.
4.3.6 Comparison of Classification Results of IRMFWLD and Other Models
A classic machine learning algorithm (support vector machine,SVM) and a classic deep learning algorithm (convolutional neural network,CNN) were selected for comparative experiments in image recognition.Based on the minimization of structured risk and optimization theory,the SVM algorithm takes the HOG gradient features as decision points to classify images.It has better generalization of samples that have not been trained.The CNN algorithm has convolution and pooling that extract different image features,improve the feature dimension,and demonstrate superior fitting ability.In the comparison experiment,the dataset was divided into a training set and a test set in the ratio of 9:1 by random division,and the experimental results are summarized in Table 8.
According to this comparison,IRM-FWLD was superior to the SVM and CNN models in precision and recall rate.The CNN model requires selecting a large feature dimension to form a convolutional layer,which is inconsistent with the small sample dataset considered in this paper.The SVM model achieves classification based on image HOG features,but there are too many image elements and feature dimensions in recognizing fraudulent website images.The compression of image resolution can reduce the image recognition rate,decreasing the comprehensive recognition ability of the CNN and SVM models.IRM-FWLD has the ability of the neural network to process multidimensional features and integrates the ability of transfer learning,thus showing good effectiveness in recognizing fraudulent website images with high recognition precision in a short time.
V.CONCLUSION
Telecom fraud occurs mainly in cyberspace,seriously endangering the safety of people’s lives and property.With the characteristics of low contact,strong camouflage,and difficulty in detection,it has become a significant public security issue in social governance.Analyzing the features of fraudulent websites is important to combat and prevent telecom fraud crime,effectively blocking it and accurately revealing its law.Fraudulent images are important to those websites for disseminating information and attracting visitors.Image recognition began to be applied to fraudulent website recognition research relatively late,so there is little related research on multi-classification identification.This paper formulates the image leader decision to improve the overall prediction effect of a model aiming at analyzing insufficient image information.Dealing with fewer training samples due to the difficulty of obtaining relevant data,the small sample learning of the Inception-V3 model is applied to image recognition on fraudulent websites.Analyzing the image features of gradient,color,and texture achieves a highly precise recognition of fraudulent websites and promotes the application of image recognition technology in fraudulent website recognition.Subsequent research can further acquire fraudulent website image data and update the feature extraction and score calculation methods in image leader decisions to further improve the recognition effect of the model.
ACKNOWLEDGEMENT
This research was supported by the National Social Science Fund of China(23BGL272)

- China Communications的其它文章
- Design Framework of Unsourced Multiple Access for 6G Massive IoT
- 6G New Multiple Access Technology
- OFDMA-Based Unsourced Random Access in LEO Satellite Internet of Things
- Cluster-Based Massive Access for Massive MIMO Systems
- A Joint Activity and Data Detection Scheme for Asynchronous Grant-Free Rateless Multiple Access
- The Extended Hybrid Carrier-Based Multiple Access Technology for High Mobility Scenarios