
近红外光谱技术用于快速检测藜麦营养成分的研究进展
2024-02-27 10:20顾洪涛苏婷婷
农产品加工 2024年1期
李 慧,顾洪涛,苏婷婷
(内蒙古华瑞检验检测有限公司,内蒙古呼和浩特 010010)
藜麦(Chenopodium quinoa Willd)属于藜科藜属的双子叶植物,原产地为南美洲安第斯山脉的高海拔山区,是当地印加人的传统粮食作物[1-2]。近年来,我国内蒙古、山西、青海、甘肃等地大面积种植藜麦,目前已初步形成了藜麦规模化种植和智能化产业链[3]。藜麦的营养价值较高,富含蛋白质和膳食纤维等物质。有研究表明,藜麦中富含人体所需的9 种必需氨基酸和赖氨酸,脂肪中不饱和脂肪酸占80%左右;藜麦中丰富的皂苷、黄酮类物质、多酚和植物甾醇等具有多种生物活性,在食疗领域发挥着有益功效[4]。
目前,藜麦营养成分检测的方法以常规化学分析法和光谱技术为主,常规化学法操作方法比较复杂,且试验中需要使用大量试剂,存在对环境、人体有害等诸多不足。为了满足低成本、快速和无损检测的需求,研究人员开发了核磁共振、高光谱、荧光光谱和紫外光谱等检测技术[5-7]。与这些光谱技术相比,NIRS 作为一种便携技术被更多人喜爱,具有快速且无损耗的检测特点[8-9],可检测到特定的已知化合物基团,常用于农产品安全检测领域[10-11]。当通过漫反射或透射光谱处理样品时,由于物料颗粒的尺寸、形状和包装等影响,散射光产生了不受控制的物理变化。因此,为了最大限度地减少散射干扰,开发和构建稳健的检测模型也同样重要。
1 基于近红外光谱预测模型的发展
自20 世纪50 年代起,人们对近红外光谱有了初步认识,因灵敏度较低,有较强干扰性而逐渐被人淡忘。20 世纪80 年代以后,计算机技术的使用让近红外光谱不仅可用于评估食品质量安全方面,还可结合化学计量法应用于普通化学分析法难以检测的成分特征,避免了常规图谱解析的困难[12]。近红外光谱测得的数据中不仅包含样品的结构特征和组成信息,也包含了噪声、漫反射和基线倾斜等背景及其他干扰信息。因此,需要在建立近红外光谱模型前进行适当的预处理来降低或消除其他因素对光谱的干扰[13]。
1.1 近红外光谱预处理技术
平滑(Saviztky-Golay,SG)是消除噪声的高效方法,该方法假设光谱中的噪声为零均值随机噪声,取多次测量的平均值来减少随机噪声,以提高信噪比[14],滤除高频噪声并保留低频噪声。标准正态变量变换(Standard normal variate transformation,SNV)和多元散射校正(Multiplicative scatter correction,MSC)主要用于减弱不同粒度大小的物料颗粒造成的散射等物理影响,SNV 是单独处理一条光谱,而MSC 的处理对象通常为一组光谱[15],因此部分研究认为SNV相比于MSC 更能提升藜麦营养组分的预处理效果。此外,还有加权多元散射处理(WMSC)、标准化多元散射处理(SMSC)和反向多元散射处理(IMSC)等方法。一阶导数(First derivative,1st Der)和二阶导数(Second derivative,2nd Der)用直接差分法和SG 法进行求导来消除基线偏移和光谱的旋转,可以减少仪器背景等误差,并且二阶导数可以通过连续计算两次一阶导数得到。此外,在藜麦等谷物检测用到较少的方法如隐变量正交投影(Orthogonal projection to latent structures,OPLS)和扩展乘法信号校正(Extended multiplication signal correction,EMSC)等,OPLS 可移除与样品浓度无关的光谱数据,并有效增强非线性组分的预测模型和提高稳定性[16]。Encina-Zelada C 等人[17]为了最大限度地减少光散射的乘法效应,参考其他原料的EMSC 用于藜麦检测中,EMSC 将物理散射光与化学吸收(振动)光分离,有助于校正光谱中与波长相关的基线效应[18]。
1.2 特征波长选择
近红外光谱数据为全波段型,包含丰富信息量的同时,也带来了各种干扰信号,造成吸收带严重重叠,因此对光谱的特征波长进行筛选来提高模型的准确度也是必要步骤。基于藜麦甚至农产品的特征波长选择多为经验判断,此外还有竞争性自适应重加权法(Competitive adaptive reweighted sampling,CARS)、连续投影算法(Successiveprojectionsalgorithm,SPA)[19]和无信息变量消除法(Uninformation variable elimination,UVE)[20]等常用于食品检测的特征光谱可供选择。CARS 算法可最小化光谱的无用信息;SPA 是一种通过向量的投影达到变量间共线性最小化的波长选择算法,可最大程度消除共线性的影响。
1.3 近红外光谱模型进展
1.3.1 定性分析
主成分分析(Principal component analysis,PCA)是常用的光谱定性分析方法,利用降维的思维将多个波长下的原始变量通过组合形成有限的几个因子,且各成分之间的所属类别也不同。PCA 对样本与训练集间的确切位置缺乏定量的解释,单独在藜麦等谷物检测中很少使用,一般结合其他统计学方法用于产地溯源等方面。
马氏距离(Mahalanobis distance,MD)是近红外光谱定性分析中另一种常用的方法,一般适用于近红外光谱中异常数据的剔除并建立样本间相似度的模型。因为MD 常常依赖较为准确的预处理和波长筛选结果,所以独立应用在食品中的场合较少。为此,研究人员常常先对样本进行PCA 分析筛选主成分,再进行MD 分析,这样可以得到较为准确的域值信息。
簇类独立软模式法(Soft independent modeling of class analogy,SIMCA)被普遍认为是发展最成熟的化学计量学方法之一。传统的SIMCA 采用PCA 参数和F 检验构建新模型,并以样本与各类主成分空间的欧氏距离作为判断类别的依据[21],大量光谱应用。结果表明,SIMCA 方法分类可以获得较好的效果,但是对于区分成分相近又存在着微小差异的样本,SIMCA 方法分类的效果并不理想。
K -近邻法(K-nearest neighbor,KNN)算法可以用来分类和回归,是最简单的算法之一,其核心是某样本的k 个特征空间最邻近样本大部分属于一个类别,则将该样本归为一类。KNN 理论成熟,易于理解,缺点是不仅计算量较大,当样本容量不一致时,还容易产生新样本对其他样本的误判,解决方法之一是去除已知样本中对分类作用不大的样本,但仅限于容量较大类域的自动分类。
BP 神经网络是一种非线性回归方法,可建立定性和定量分析模型,由输入层、一个或多个隐藏层和输出层组成的神经元。每个神经元具有激活功能。优点是可以自动找出规律来解决复杂问题,缺点是收敛速度慢、容易陷入局部极小值等。此外,还有研究者提出深度信念网络(DBN)、卷积神经网络(CNN)、径向基神经网络(RBF)等优化性能模型以待参考[22]。
1.3.2 定量分析
主成分回归(Principle component regression,PCR)以主成分为自变量,将频谱数据投影到新的正交二维轴上来做回归分析,主要用于样品的变量与质量参数之间的线性关联。由于新变量之间互不相关,因此成功解决了多重共线性或变量相互依赖问题,但是无法处理非线性数据。
多元线性回归(MLR)(Multivarate linear regression,MLR)是2 个或以上自变量的N 个推广,用MLR 建模前应对原始光谱进行特征光谱筛选,适用于关联性不强或微弱的图谱。MLR 的计算简单且容易理解,但无法解决多重共线性或非线性的波长数据,使用MLR 方法的前提是样本数量必须大于特征数量[23]。
偏最小二乘回归(Partial least squares regression,PLSR)是目前流行的模型方法,用于解决变量多和有着多重相关性等问题,对变量多的样本及其成分分析较为友好,比PCR 更快且精度更高,结果更加合理,但是当图谱数据有噪声时,拟合模型也会更复杂,且当添加一组新数据时,模型需重新建立,因此在实际应用中常常被限制。最近有人提出了PLSR 的泛化,被称为规范幂偏最小二乘法(CPPLS),以及正交偏最小二乘判别分析(OPLS-DA)有待应用。
随机森林回归(Random forest regression,RFR)是随机森林的重要应用分支,通过样品的特征进行独立并行的结果预测,整合取平均值后得到整个森林的回归预测。对数据维度要求相对要低,优点是受异常值和噪声的干扰度较小,且计算成本低,不会过度拟合,是比较通用的方法之一。
支持向量机(Support vector machine,SVM)是一种由线性求解非线性的分类方法,常用于“二分类”问题中。通过核函数(如多项式、径向基本函数等)将数据映射到更高维度的空间,构造线性的最优分类超平面,这样的计算开销小,基于校准集的子集可以获得出色的模型,但属于非概率性抽样,需要设置缺失的数据和优化核函数等各种关键的参数[24]。此外,还可被用于多变量校正建模,即支持向量回归(Support vector regression,SVR),在分析化学领域潜力巨大。
2 近红外光谱技术在藜麦营养成分检测方面的应用
适合NIRS 的藜麦营养成分检测步骤包括光谱采集、预处理、波长选择和模型开发,具体的方法对于不同品种(白藜、黑藜和红藜)和不同形态(谷粒、面粉)在一定程度上是通用的,但目前最常见方法为通过反复试验将这些光谱数据处理方法结合起来获得最优模型。藜麦含有丰富的微量元素,NIRS 评估其营养成分和其他杂粮不同,应该主要关注微量元素及相关参数方面。
近红外光谱的不同处理方式对藜麦营养成分的影响见表1。
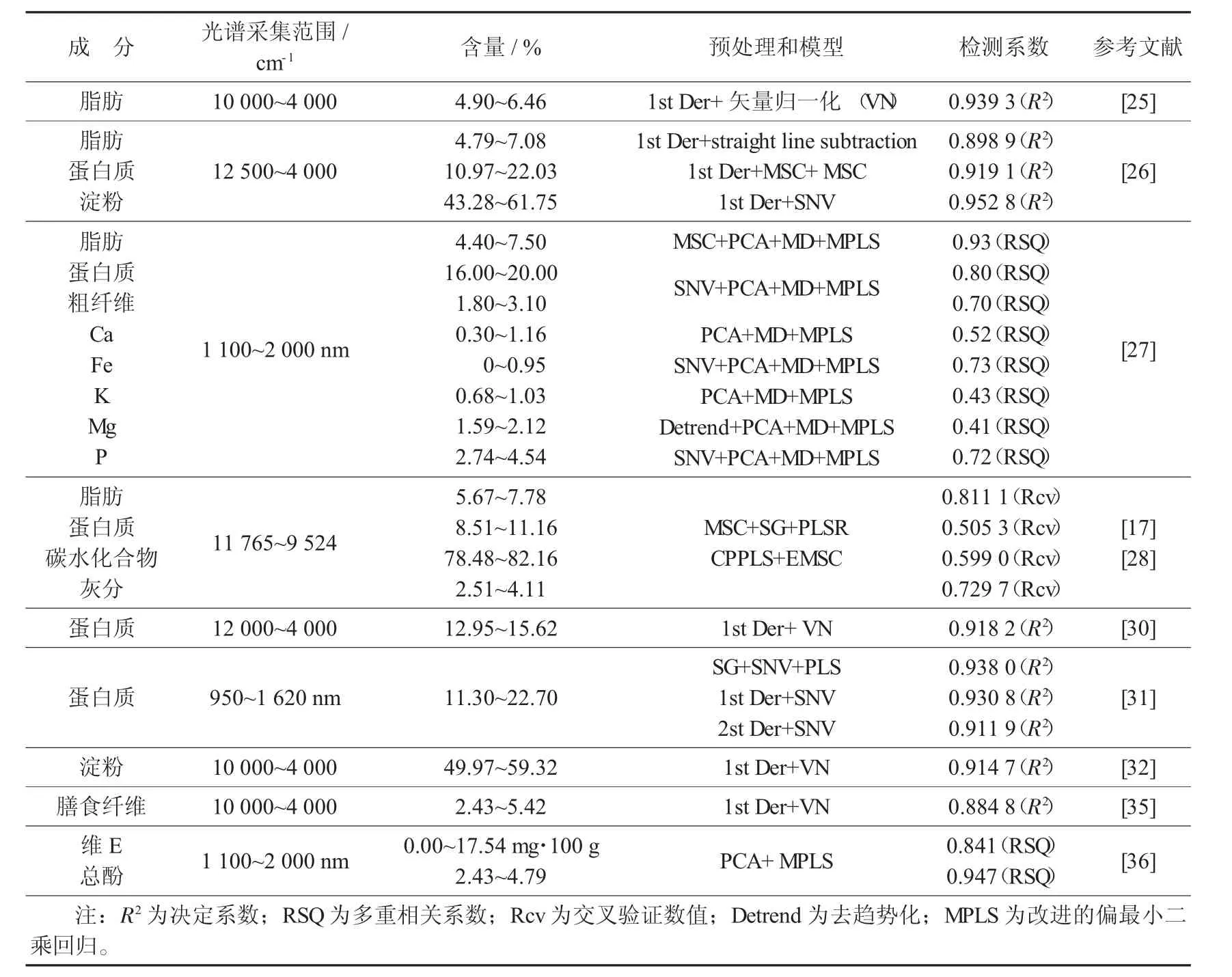
表1 近红外光谱的不同处理方式对藜麦营养成分的影响
2.1 脂肪含量的快速检测
脂质水平与产品腐败等质量问题息息相关,是农产品必检的指标之一,藜麦中脂肪含量较多且种类丰富,是潜在的油品来源,也是藜麦作为健康减肥原料的原因之一。曹晓宁等人[25]采集100 个藜麦样品,运用一阶导数和矢量归一化的化学计量学对光谱进行预处理,发现这2 种方法结合后校正和预测效果更佳,其中决定系数为0.939 3,与索氏抽提法相比具有快速无损的特点。石振兴等人[26]采集国内外101 份藜麦原料制成粉末,通过构建最小二乘回归预测模型来测定藜麦中粗脂肪含量,结果与国标脂肪含量测定的方法相比具有快速筛选和较高准确度。Martín M 等人[27]在智利采集不同品种的48 个藜麦样品进行红外光谱对营养成分的检测分析。结果发现,比传统定量酸培养基中测定醚提取物的方法效率更高,并且采用PCA 法应用于校准集的数据;用MD法检测异常光谱数据;使用改进的偏最小二乘回归法来获取所研究营养成分的NIR 方程,采取SNV 和去趋势化处理进行多元回归方程优化,最终所得结果更稳定、更准确。Encina-Zelada C 等人[28]通过近红外投射光谱估算藜麦中的成分,旨在开发应用于藜麦等谷物的稳健化学计量模型,该模型经过SG 预处理、MSC 和扩展乘法信号校正(EMSC)校正,通过PLSR 和规范动力偏最小二乘法(CPPLS)提取潜在变量,结果发现平滑光谱提高了脂肪检测模型的准确性,EMSC 结合CPPLS 也获得了较高的准确度,通过交叉验证(Rcv)值为0.811 1。
2.2 蛋白含量的快速检测
藜麦的蛋白质具有较高营养价值,有开发婴儿配方食品的潜力,藜麦蛋白质主要是白蛋白和球蛋白类型,由类似酪蛋白的平衡氨基酸组成[29]。传统蛋白质检测方法为国际通用的凯氏定氮法,结果较为准确但步骤繁琐。张晋等人[30]通过NIRS 建立了一种藜麦粗蛋白含量的检测方法,以100 份藜麦为样品,采用一阶导数结合矢量归一化处理方式对光谱进行预处理,可减小其他因素(组分、粒度、光谱模型)对蛋白质含量的误差,提高准确性,交叉验证决定系数为0.918 2。赵丽华等人[31]采集122 份藜麦扫描得到近红外原始光谱,比较了9 种光谱预处理方法,结果发现用滤波拟合法和标准正态变量建立的SIRS模型拟合度较高,R2为0.938 0,预测效果良好。有研究发现,NIRS 对藜麦蛋白质含量模型(CPPLS+EMSC)的检测准确度最低,RCV 仅为0.5。Martín 发现,NIRS 测得蛋白质含量高于其他农作物,但Regalona 基因型藜麦的蛋白含量最低,仅为17.3左右。
2.3 淀粉含量的快速检测
淀粉是藜麦中含量最多的基础物质,占干物质的50%以上,但对藜麦淀粉的研究明显少于蛋白质等其他物质,常规的淀粉测定方法是酶解法,步骤特别繁琐并且准确度不高,研究一种稳定、准确和快速检测的淀粉含量测定方法至关重要。曹晓宁等人[32]对比旋光仪法和近红外光谱法检测藜麦淀粉含量,采集100 个藜麦样品,运用一阶导数结合矢量归一化对光谱进行预处理,再结合化学方法建立藜麦粗淀粉含量定量模型。石振兴等人[26]通过交叉验证,筛选出藜麦淀粉最佳光谱区间为7 505.9~5 446.2 和4 605.4~4 242.8;最佳预处理方式为一阶导数结合标准正态变量变换,该模型具有极高的决定系数(0.952 8)。Encina-Zelada C 等人[28]对比PLSR,CPPLS 和MSC,EMSC 对藜麦碳水化合物含量的影响,发现CPPLS+MSC 得到最高的验证值(RCV=0.767),在他的另一篇文章中,藜麦光谱经过CPPLS 和EMSC 优化后,RCV 仅为0.599。
2.4 其他成分的快速检测
藜麦是膳食纤维和维E 的良好来源,其中可溶性膳食纤维和不溶性膳食纤维占总质量6%左右;藜麦中的微量营养素含量较高,钙含量是大米的3 倍,铁含量是大米的5 倍,磷含量与小麦相当[33-34]。曹晓宁等人[35]采集100 个藜麦样品,将NIRS 原始光谱进行一阶导数+矢量归一化预处理,最终测定粗纤维含量与国标方法测定的数据接近,R2为0.884 8。Martín 通过马氏距离和偏最小二乘回归法优化光谱后,测得的Fe 和P 含量较接近ICPOES 测定的值,相关系数RSQ 大于0.7;Ca,K 和Mg 含量测RSQ 为0.5 左右,效果并不明显。Moncada G 等人[36]通过PCA,MPLS 和多种散射校正的数学处理方法对光谱进行优化,测得藜麦中的维E 和总酚含量接近化学法所测,RSQ 分别为0.841 和0.947。
3 结语
概述了部分可优化NIRS 的化学计量学方法,包括光谱预处理、波长选择和模型评估,及其在藜麦营养成分检测的应用,汇总后发现以下问题:
(1)尽管所有预处理经过反复交叉验证用来提高信噪比,但是仍可能会导致原始信息丢失频谱。此外,多项研究表明采用最佳数据集和应用程序先进的算法后,预处理的效果也在最终模型中不再突出[37]。
(2)目前,相对稳定、准确且高效的模型,如多元散射校正、偏最小二乘法和多元线性回归等,其中涉及波长选择的方法较少,合适的波长可以减少在原始光谱中的冗余信息,明显提高性能并降低计算的消耗[38],因此将波长筛选结合研究前沿的预处理和回归方法(线性、非线性)可能会得到更好的结果,尤其在藜麦蛋白质、膳食纤维、多酚和其他微量营养素定量检测方面。
(3)有研究证明,NIRS 对部分谷物和豆类中不溶性膳食纤维的预测准确度远大于可溶性膳食纤维含量[39-40],在藜麦中也同样适用,今后的研究应该推进藜麦中微量元素的准确定量模型的开发。
(4)由于不同成分的交互作用,进行NIRS 检测时应充分考虑外部因素(水分、物料形态等),利用感官评价等人工干预手段对光谱进行初筛,近红外光谱用来评估藜麦保质期的模型也有待探究。
猜你喜欢
特产研究(2022年6期)2023-01-17
北京航空航天大学学报(2022年8期)2022-08-31
制导与引信(2017年3期)2017-11-02
实用口腔医学杂志(2017年6期)2017-09-19
中国照明(2016年4期)2016-05-17
工业设计(2016年11期)2016-04-16
中国光学(2015年5期)2015-12-09
环境科技(2015年6期)2015-11-08
物理实验(2015年9期)2015-02-28
电网与清洁能源(2015年2期)2015-02-28
