
基于注意力机制改进的YOLOv7服装缝线疵点检测方法
2024-02-27 03:45束方盛徐增波鲍禹辰
毛纺科技 2024年1期
束方盛,徐增波,鲍禹辰
(上海工程技术大学 纺织服装学院,上海 201620)
随着经济的发展和社会的不断进步,服装消费市场向多样化趋势发展。服装行业生产规模也逐渐扩大。传统服装检测方式对于人工依赖较大[1],在这种扩大化规模生产的背景下,低效的检测方式会降低企业的生产效益,也不能适应人工智能大背景下的企业模式。
常见的服装瑕疵有,缝线疵点与纹理疵点。相较于纹理疵点而言,缝线疵点存在特征不够明显、特征区域较小的特点,给实际的检测工作带来更大的挑战。常见缝线疵点可以分为:断线、线迹不齐、线头、车线不牢。缝线疵点实时检测可以满足市场对服装行业多样化的需求,但服装疵点的种类繁多,各类疵点差异性特征不够显著[2],漏检误检概率较大。随着科学技术的进步,国内外不少学者提出了一些基于传统计算机视觉技术的方法[3-4]来实现服装疵点的目标检测。这些方法虽然一定程度上减轻了检测人员的工作量,但是检测的主体仍然是人工,没有统一标准的客观评价指标。近年来,随着大数据的应用和芯片算力的逐渐提高,基于深度学习[5-6]的目标检测技术得到快速发展,计算机视觉技术的跨领域应用的研究越来越多。在基于深度学习的目标检测方法中,可以分为两阶段目标检测方法和单阶段目标检测方法。两阶段目标检测方法以Girshick等[7]提出的R-CNN为代表,它利用深度卷积神经网络在目标检测精度这一评价指标上取得了优异的表现,但是其冗余的运算量导致了它在运算时间和空间上的开销过于庞大,难以在服装缝线疵点检测任务上进行实际部署。相较于两阶段目标检测方法,单阶段的目标检测算法不仅检测速度快、准确率高,在实际项目部署的难度也低于两阶段目标检测方法。Law等[8]提出的基于关键点的单阶段目标检测方法CornerNet,该方法一定程度减少了运算开销,但是容易存在较多的边界框,无法满足缝线疵点检测的要求。Duan等[9]在ConveNnet的基础上进行改进,构建出了CenterNet框架以优化性能,但是其结构简单,无锚结构导致其综合表现不够稳定,无法满足缝线疵点检测任务的实际需要。目前基于人工智能技术对服装疵点进行检测的实验研究相对较少[10],因此对服装缝线疵点进行合理的数据标注,对算法结构进行优化改良,以较小的计算代价来增强模型对于特征的学习,对实验取得良好效果有着极为重要的影响。现有研究大都为基于统计学或者机器学习的方法[11-12]来进行的。
本文采用单阶段目标检测的方法来实现服装缝线疵点的实时目标检测,只需要对特征进行一次提取便可以达到目标检测的效果,其综合性能表现优于同期的两阶段目标检测方法。目前单阶段目标检测的代表性方法有You Only Look Once(YOLO)[13]、 Single Shot MultiBox Detector(SSD)[14],本文将基于卷积神经网络的检测思想移植到服装疵点检测上,以满足服装工业检测的实际需求[15]。
1 实验数据与方法
1.1 数据集的构建
在服装工厂的实际质检步骤中进行服装图片采样,采样设备为EOS R50单反相机(佳能公司)。
在构建数据集的过程中,通过不同角度、不同距离的方式对服装进行采样拍摄,采样多个质检员负责质检的不同类型的服装数据。然后人工挑选出一些重复性较高和一些肉眼识别存在较大难度而没有拍摄清晰的冗余数据。最终构建出一个包含1 500张缝线疵点的数据集。图1为数据集标注的工作实例。

图1 图片标注实例Fig.1 Example of image labeling.(a) Whole marker for stitching defects; (b) Sub-marker for stitching defects
在程序进行目标检测工作的时候,在其预测阶段,神经网络模型会输出多个候选框,但是这些候选框容易在同一目标区域进行重叠。尽管采用非极大值抑制[16]的方法可以有效过滤掉不正确的锚框,但是如果2个疵点目标的距离比较接近,容易发生漏检。
考虑到在疵点密集区域内,整块标记疵点区域会导致标记框的重叠,因此只采用分块标记的方法进行缝线疵点的目标检测,并对2种标记方法进行对比。
1.2 数据集的预处理
1.2.1 混合数据增强
混合数据增强(Mixup Data Augmentation)[17]是一种根据混合因子来随机混合图像的数据增强方法。它利用线性插值来构造额外的训练样本和标签。处理标签公式如式(1)(2)所示:
(1)
(2)
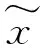
数据集经过混合数据增强效果如图2所示。

图2 混合数据增强效果示意图Fig.2 Schematic diagram of hybrid data enhancement effect
1.2.2 马赛克数据增强
马赛克数据增强方法(Mosaic Data Augmentation)[18]是一种利用随机剪切4幅图并合成一幅新的图像作为训练样本数据的增强方法。它极大丰富了训练集的样本数量和样本信息,增强了网络的健壮性,能有效降低图形处理器(GPU)的显存占用。数据集经过马赛克数据增强的效果如图3所示。

图3 马赛克数据增强效果示意图Fig.3 Schematic diagram of the mosaic data enhancement effect
1.3 实验环境
本文所采用的GPU平台是NVIDIA RTX3090,拥有24 GB显存和3 840 个CUDA内核,中央处理器(CPU)平台为 12 核,Xeon(R) Platinum 8255,操作系统为Ubantu18.04, Pytorch版本为1.9.0, Python解释器的版本为3.8.0,CUDA的版本为11。
1.4 训练所示的参数
实验过程中所使用的训练参数如表1所示。

表1 训练参数Tab.1 Training parameters
1.5 评价指标
为客观评价实验真实效果,采用通用的目标检测评价指标,主要包括精度P(Precision)、召回率R(Recall)、平均精度均值(mAP)、F1分数,其计算公式分别见式(3)~(5)。其中TP为真阳,FP为假阳,FN为假阴。
(3)
(4)
(5)
精度P反应的是模型区分负样本的能力,精度越高,模型区分负样本的能力越强,而召回率R反应的是模型识别正样本的能力,召回率越高,模型识别正样本的能力越强。F1用来综合评价上述2类指标,F1得分越高说明模型的鲁棒性会越好。
平均精度均值是在不同的召回率下最高精度的平均值(即单独类别下AP的均值),其计算公式为:
(6)
(7)
式中:r1,r2,…,rn,是按升序排列的Precision插值段的一个插值处对应的召回率值。
1.6 相关理论
YOLOv7[16]算法融合注意力机制在服装缝线疵点检测任务上具有高速度、高精度、应用难度较低等优势,但是它需要大量的数据进行训练,对于复杂背景下的缝线疵点检测容易存在误检问题。在实际生产检测过程中,服装企业对于服装有无疵点的关注度更为敏感,对于疵点分类准确度的敏感度相对较低,YOLOv7相较于其他的检测方法存在部署成本代价低,实时性和高性能等优势。
1.6.1 YOLOv7
针对缝线疵点目标小,目标干扰较大,检测实时性要求较高等特点,本文选用较为稳定和鲁棒性较强的YOLOv7模型进行检测。YOLOv7是一种具有较好表现的单阶段目标检测算法,图4是YOLOv7的网络结构图。YOLOv7模型的预处理方法继承YOLOv5的方法,采用马赛克数据增强的方式来加强对小目标的特征学习。在总体网络结构方面,它提出了基于ELAN模块扩展的ELAN-H模块,该模块可以实现在不破坏原有梯度路径的情况下不断加强网络对于特征的学习能力,采用控制梯度最短、路径最长的方法,让处于较深的网络层次也能得到有效的收敛,将模型重参数化的思想引入到网络结构中,以使网络结构中的不同模块学习到更多特征。
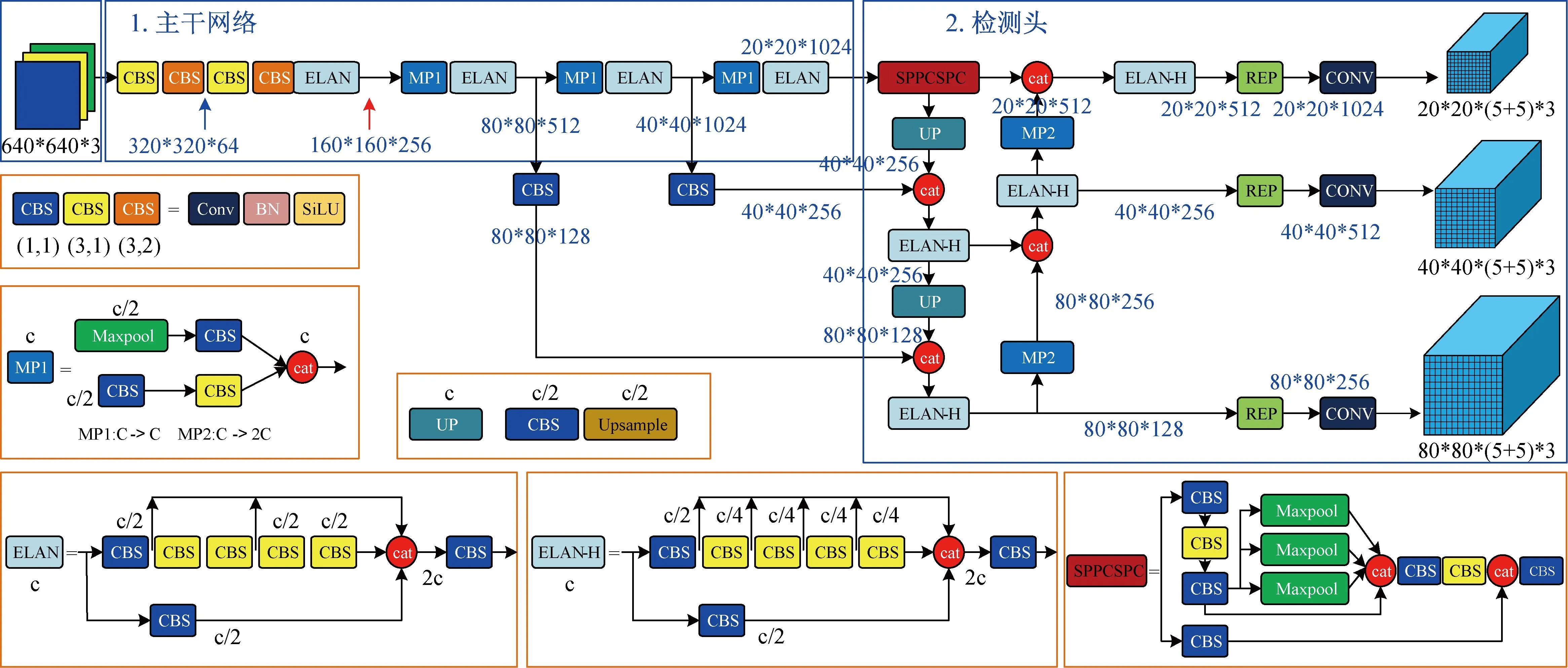
图4 YOLOv7模型结构图Fig.4 YOLOv7 model structure diagram
1.6.2 基于注意力机制改进的YOLOv7
注意力机制是机器学习中一种常见的数据处理方法。在计算机视觉领域内,注意力机制[19]的核心思想是关注重点目标,将计算资源倾斜于更重要的任务,降低其他信息的关注度,解决信息的过载问题,主要包括通道注意力,像素注意力,多头注意力。SK注意力是一种通道注意力,它能对输入特征图进行通道特征加强,最终由SK输出,且不会改变输入特征图的大小。SK注意力的模型结构如图5所示。
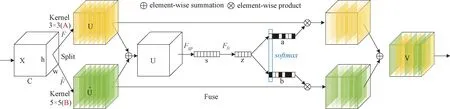
图5 SK注意力模型结构图Fig.5 Structure of SK attention model
SK注意力模块通过采用让网络自我学习的方式来融合不同的特征信息,能够使用不同特征的卷积核对输入图进行特征提取,自动选择卷积核所提取的合适信息,对不同大小视野(卷积核),不同尺度(远近、大小)会有不同的效果。
1.6.3 YOLOv7引入SK注意力机制
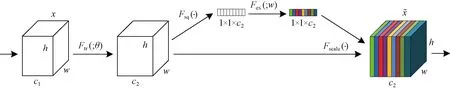
在原有的YOLOv7网络结构里增加SK注意力机制模块,其结构如图6所示。该模块可以进一步加强网络对于不同尺度特征的学习,提高主干网格的特征提取能力。但是随着注意力机制的引入,注意力机制模块可能会破坏原有网络的结构构,导致原始权重值破坏,从而干扰网络的预测能力。对此,在不破坏网络主干结构提取原有特征的前提下,在增强网络特征提取部分的地方引入了注意力机制模块。

图6 改进后的YOLOv7模型结构图Fig.6 Structure of the improved YOLOv7 model
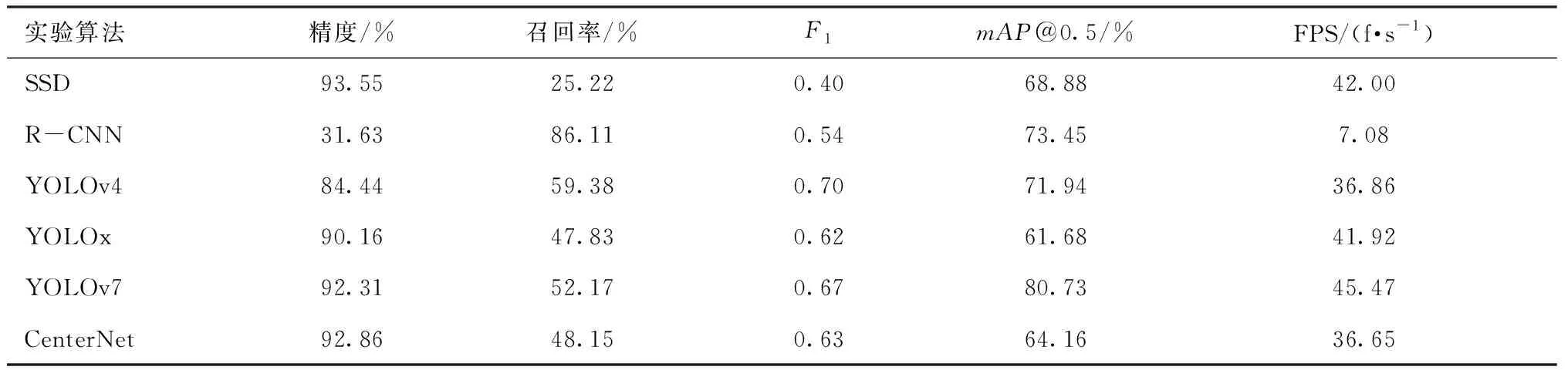
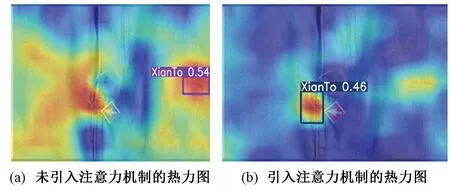
SK注意力机制模块的工作原理主要如下:首先对输入维度为C×H×W的特征图分别使用3×3(卷积核A),5×5(卷积核B)的卷积核进行卷积操作,得到相同尺寸的特征图,将对应尺寸的像素进行相加来完成特征融合的步骤;然后把融合后的特征图进行全局平均池化,此时得到的特征图的维度为C×1×1;再通过全连接层进行降维以提取通道注意力信息得到特征图Z,此时的维度为d×1×1(d 为客观评价改进算法SK-YOLOv7的效果。采用引进CBAM[18]注意力机制模块和SE[19]注意力机制模块嵌入进YOLOv7的backbone进行消融实验。这2个模块结构图分别如图7、8所示。 图7 CBAM模块结构图Fig.7 CBAM module structure 图8 SE模块结构图Fig.8 SE module structure diagram 在服装疵点缝线检测任务的模型选择过程中,将主流的目标检测算法模型应用到自建的服装疵点检测数据集上进行训练和验证。并对精度、召回率、mAP@0.5和F1评分进行比较分析。最终采用YOLOv7作为基础检测模型开展后续的检测工作,实验结果如表2所示,其中FPS表示实时检测速度。 表2 不同目标检测算法对比Tab.2 Comparison of different object detection algorithms 分析表2可知,YOLOv7在精度和F1评分上取得了相对较好的表现,同时在mAP@0.5方面也领先于其于算法模型。这是因为YOLOv7采用了更先进的网络结构和更高效的训练策略。同时得益于网络结构的优化和对GPU资源的高效利用,在检测速度上,YOLOv7也取得了最佳表现。然而,YOLOv7在召回率的表现却落后于YOLOv4,这可能是YOLOv7在一定程度上牺牲了召回率来换取更高的精度和更快的检测速度。 YOLOv7是一种高效、精准的目标检测算法模型,具有优秀的综合表现。但随着深度学习技术的飞速发展,新的检测算法和技术不断迭代,需要对此不断地进行研究和比较,从而找到最适合缝线疵点检测这一任务的算法模型。 为了验证改进工作的有效性,将SK作为注意力机制模块插入到YOLOv7的主干网络当中,并在自建的服装缝线疵点检测数据集上进行实验。实验结果如表3所示,实验的评价指标与上述实验采用相同的评价标准,其中FLOPS表示浮点运算次数。 在此次实验中,“√”表明使用该模块,“×”表明未使用该模块。从表3的实验结果可以看出,本文所提出的SK-YOLOv7算法在缝线疵点检测任务上的表现优于CBAM-YOLOv7和SE-YOLOv7算法,并且与原算法相比,精度提高了7.69%,召回率提高了12.64%,mAP@0.5提高了2.6%,且计算开销也相对持平,这表明SK模块在增强算法模型对于疵点特征的理解和学习具有良好的效果。 同时,CBAM-YOLOv7和SE-YOLOv7算法的精度分别下降了3.42%和上升了7.67%,召回率分别下降了3.47%和上升了6.16%。虽然算法在其中的一个指标表现较好,但是其他指标却普遍下降,并且还带来了额外的训练支出,这表明改进算法的设计没有较好地考虑评价指标与计算支出之间的关系。 综上所述,SK模块可以有效加强网络对于疵点特征的理解与学习,以较小的训练费用为代价提高了模型的表现,针对缝线疵点检测任务而言,是一种有效的改进手段。 为了充分验证改进模块的有效性,对检测结果绘制热力图,如图9所示。对训练集、验证集和测试集的划分比例为6∶2∶2。训练过程中的损失图如图10所示,由图10可知,随训练次数的增加,模型逐渐收敛。 图9 注意力机制热力图 Fig.9 Heat map of the attention mechanism. (a) Heat map of the class without the introduction of the attention mechanism; (b) Heat map of the class with the introduction of the attention mechanism 图10 实验过程中的损失图Fig.10 Losses during the experiment 在文章前面的部分,采用2种方式对于缝线疵点检测数据集进行标注。为此,在SK-YOLOv7上对于不同的标注方式进行了实验,实验的结果如表4所示,“√”表明使用此方法,“×”表明未使用此方法。 表4 不同标记方法的对比实验Tab.4 Comparison experiments of different labeling methods 由表4可知,分块标记的疵点特征的实验结果优于整体标记的表现。一般而言,卷积神经网络模型在对图像进行特征提取时,感受野反映的是单个高层次的特征信息与原始图像的对应关系,这取决于网络卷积核。随着网络层数的加深,特征在传递时被逐级放大,由于整块标记包含了冗余和干扰特征[20-21],这就导致了神经网络模型丢失了原有的特征信息。不少疵点特征属于小目标检测,导致网络在聚焦特征时,像素包含的正确特征的像素较少,从而导致像素识别失败。因此,整体标记的方法并不太适用于服装疵点缝线检测这项任务。 图11示出最终测试的检测效果。图11中候选框分别标记了线头(Xiantou)、爆口(Baokou)、断线(Duanxian),对应数字表示该特征为此分类的置信度。 图11 检测结果图Fig.11 Graph of test results 在使用YOLOv7对数据集进行训练时采用了数据增强技巧来提高模型的泛化性能。实验结果如表5所示,其中,“√”表明使用此方法,“×”表明未使用此方法。实验数据表明,采用在线数据增强技巧,特别是马赛克数据增强和混合数据增强,可以提高模型的表现。在每一个训练步骤中,使用了50%的概率应用马赛克数据增强,并接着使用25%的概率应用混合数据增强。这些数据增强方法能够在一定程度上增强模型的泛化表现,但是相较于改进后的SK-YOLOv7,其表现仍然不够优秀。 表5 不同数据增强方法的对比实验Tab.5 Comparison experiments of different data enhancement methods 对于马赛克数据增强,其可以在图像中随机选取小区域,再将其缩放并拼接起来,从而生成“马赛克”效果。这种数据增强方法可以使模型对于同一对象出现在不同位置时仍能准确识别。同时,混合数据增强也能够将不同的图像混合起来,在增强数据集的同时,也增加了数据集的多样性。 实验结果表明,2种数据增强方法的结合优于单一1种方法或未使用数据增强的情况。这表明了数据增强技巧的重要性。然而,在实验中也发现即便使用了数据增强方法,模型仍然存在着泛化能力不足的问题。因此,在今后的研究中,需要与SK-YOLOv7的改进方法相结合,构建更加优秀的目标检测模型,以满足日益增长的实际应用需求。 本文构建了一个服装缝线疵点检测的数据集,它包括了1 500张真实采样图片,本文在YOLOv7的基础上加以改进,在主干网络中插入了3个SK模块,优化了网络结构。在纯卷积结构的YOLOv7引入注意力机制,并与CBAM-YOLOv7和SE-YOLOv7进行对比。实验结果表明SK-YOLOv7的综合表现最佳,此外考虑存在候选框重叠的问题,提出就部分标注和全局标注的方法,并进行了对比实验。提出的SK-YOLOv7算法在实验过程中取得了较为优秀的表现。 由于缝线疵点不同于纹理疵点,它的检测存在一定的挑战,会不可避免地在实验过程中发生漏检、误检等问题。为了降低误检的概率,可采用增加负样本的策略。对于漏检,可采用在每次迭代训练中过滤掉损失较大的样本的策略,并将其送进下一轮的迭代训练中。2 实验结果与分析

2.1 目标检测算法对比实验
2.2 引入注意力机制的对比实验

2.3 不同标注方法的对比实验


2.4 数据增强方法的消融实验

3 结束语
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
纺织科技进展(2021年3期)2021-06-09
中华养生保健(2020年4期)2020-11-16
电子技术与软件工程(2019年22期)2020-01-16
四川蚕业(2018年3期)2018-11-19
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
瞭望东方周刊(2015年46期)2016-04-01
实用手外科杂志(2015年3期)2015-08-27
中国医疗美容(2015年1期)2015-07-12
