
室内机器人动态SLAM技术
2024-02-22 07:45韩慧妍韩方正况立群曹亚明
计算机工程与设计 2024年2期
韩慧妍,韩方正,韩 燮,况立群,曹亚明
(1.中北大学 计算机科学与技术学院,山西 太原 030051;2.机器视觉与虚拟现实山西省重点实验室,山西 太原 030051;3.山西省视觉信息处理及智能机器人工程研究中心,山西 太原 030051)
0 引 言
同时定位和映射(SLAM)在无人系统导航和人机交互中起着重要作用。在室内场景地图构建过程中,大多数SLAM假设环境是静态的,然而室内环境存在人、宠物等动态物体,当运动物体进入相机的视场时,这些物体将保留在构建的地图中,同时会干扰相机的姿态估计[1]。
针对此类问题,早先的方法将预定义运动物体的语义信息与空间几何信息相结合[2],消除运动物体的负面影响。事实上,语义分割方法提供的对象原始掩膜并不完善,无法完全覆盖运动的物体,尤其是运动物体的轮廓边界,其边界信息被泄漏到点云图中,形成大量的噪声块。在本文中,提出了一种在室内动态环境下工作的BN-SLAM系统,该系统具有较为完整的精确特征点匹配,且移动物体去除方法与ORB-SLAM3相结合。在BN-SLAM中,BN网络是一种实时的深度神经网络,它可以同时获得环境中运动物体的语义包围盒和原始掩膜,利用运动物体的语义包围盒将深度图像快速划分为静态环境区域和潜在的动态区域。静态环境区域中的匹配点可以通过构建潜在动态区域中的外极约束来定位,再利用深度图像的几何信息对原始掩模进行修正,以更完整地覆盖运动物体,使用修正后的掩模去除局部点云中的噪声块,通过合并这些局部点云,可以得到一个清晰的全局点云图。本文的主要贡献如下:第一,提出了一种结合原始掩模和深度图像信息获取运动物体修正掩模的方法;第二,提出了一种消除点云图构造中由运动物体形成的噪声块的方法。
1 相关工作
在未获取运动物体信息时,寻求可靠的静态匹配特征是动态SLAM系统的基本任务。Zhang等[3]提出了一种基于RGB-D数据的运动去除方法,作为一个预处理模块来过滤掉运动的物体。DMS-SLAM[4]使用GMS[5]和滑动窗口进行系统初始化,消除运动物体的影响,构建静态三维地图,通过重投影得到与局部地图中当前帧对应的三维点云,将这些点与参考帧模型相结合,实现当前帧的位姿估计并更新局部地图中三维点云。DynaSLAM[6]结合多视角几何和初始掩膜,去除预定义的运动目标,并填充该区域。DynaSLAM II[7]估计摄像机位姿,构建稀疏3D地图并记录摄像机的运动轨迹,利用光束平差法优化静态场景结构及动态物体的姿态。MaskFusion[8]基于图像的实例级语义分割创建语义对象掩码,识别运动物体。MaskFusion也可以分割语义类标签,并将其分配给场景中的不同对象,同时进行跟踪和重建。MIDFusion[9]通过提取几何、语义和运动特征识别运动物体。DS-SLAM[10]滤除运动物体后,基于物体运动的连续性去除动态匹配点。DP-SLAM[11]基于贝叶斯似然估计架构追踪动态匹配点,纠正几何约束和语义分割中的错误。以上动态SLAM系统侧重于提高摄像机定位精度,本方法的重点是可以在动态环境中获得干净和准确的点云图。深度图像[12]存在一定的深度缺失区域,不适合使用多模态网络对RGB-D图像进行语义分割,在平衡了性能和实时性之后,本系统选择BN作为语义分割网络,同时可以进一步消除运动物体产生的噪声块,剔除运动物体在场景中的拖影和轮廓边界。
2 BN-SLAM系统
2.1 BN-SLAM系统概述
基于实验室已购置的松灵移动机器人、RGB-D摄像机、工控机,搭建BN-SLAM系统,具体研究方案如图1所示。RGB图像通过BN网络,获得原始掩膜和环境对象的语义包围盒[13],原始掩膜与深度掩膜结合可以进行修正得到修正掩膜。在摄像机定位过程中,通过移动物体的语义包围盒,可以将图像快速划分为环境区域和潜在的动态区域,通过环境区域中的匹配点来构建外极约束,以对潜在动态区域中的静态和动态匹配点进行分类。然后,使用静态匹配点进行相机定位。在精确估计相机姿态后,通过拼接局部点云,可以得到全局点云图。
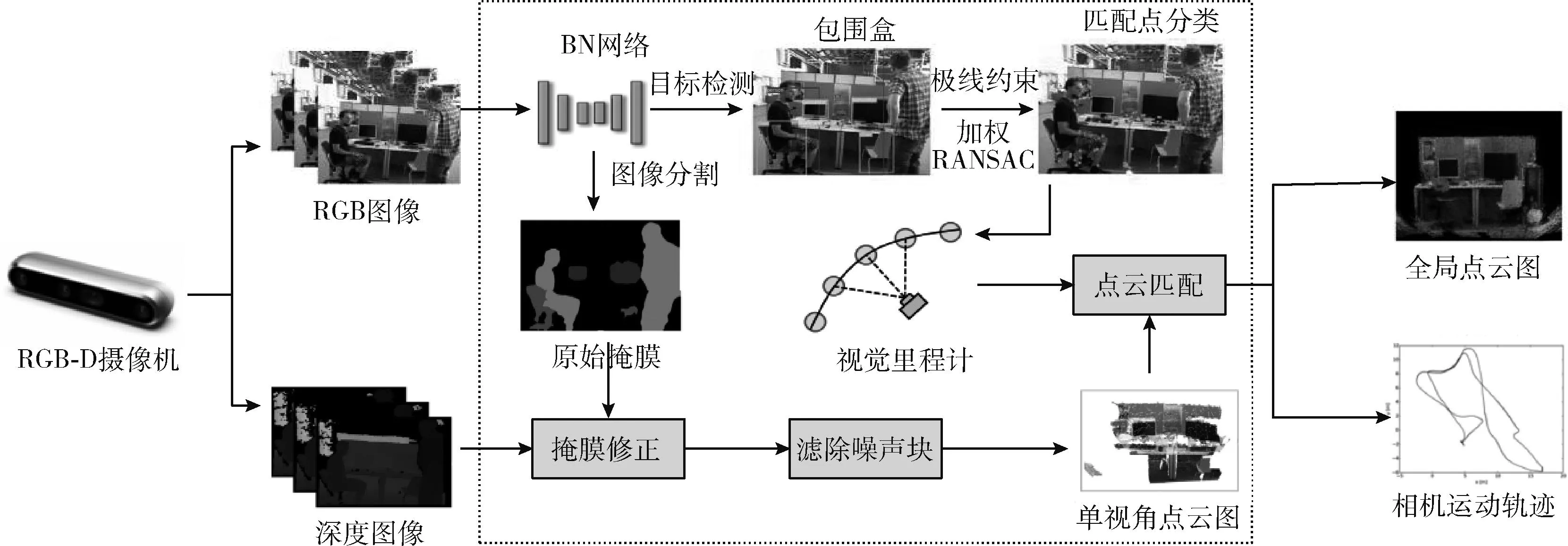
图1 BN-SLAM系统方案
根据对象在环境中的状态,对象大致可以分为3类:移动的物体:如行走的人。这些物体不仅直接干扰摄像机的姿态估计,而且在构建的环境地图中留下大量的噪声块。静态对象:如冰箱、桌子、监视器等。这些对象通常位于环境中的相同位置,并且不会经常被移动。可移动的物体:如椅子、书籍等。这些对象可以是移动的,也可以是静态的。
由于BN网络获得的原始目标掩模不完善,因此利用目标区域的深度信息对原始掩模进行改进,即得到能够完全覆盖目标区域的修正掩模。在去除由移动物体引起的噪声块后,可以获取清晰的局部点云。在构建全局点云图中,即将每一组关键帧对应的局部点云进行合并。如式(1)所示
(1)
其中,Pi表示局部点云,PE表示全局点云图,旋转矩阵Ri和平移矩阵ti由摄像机所在参考坐标系的位姿决定。
2.2 基于深度信息修复初始掩膜
由于深度摄像机的限制,深度图像中的一些区域失去了其深度值。当一个物体的表面非常光滑时,这个物体的深度值也会严重缺失。针对深度图像的缺失等问题,使用大小为2×2的滑窗遍历深度图像,并记录滑窗内的深度值,如式(2)所示,其中(u,v)表示滑窗左上角像素对应的图像坐标,边缘点可通过式(3)提取,τ1为阈值

(2)
(3)
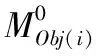
(4)
(5)
(6)
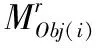
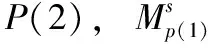
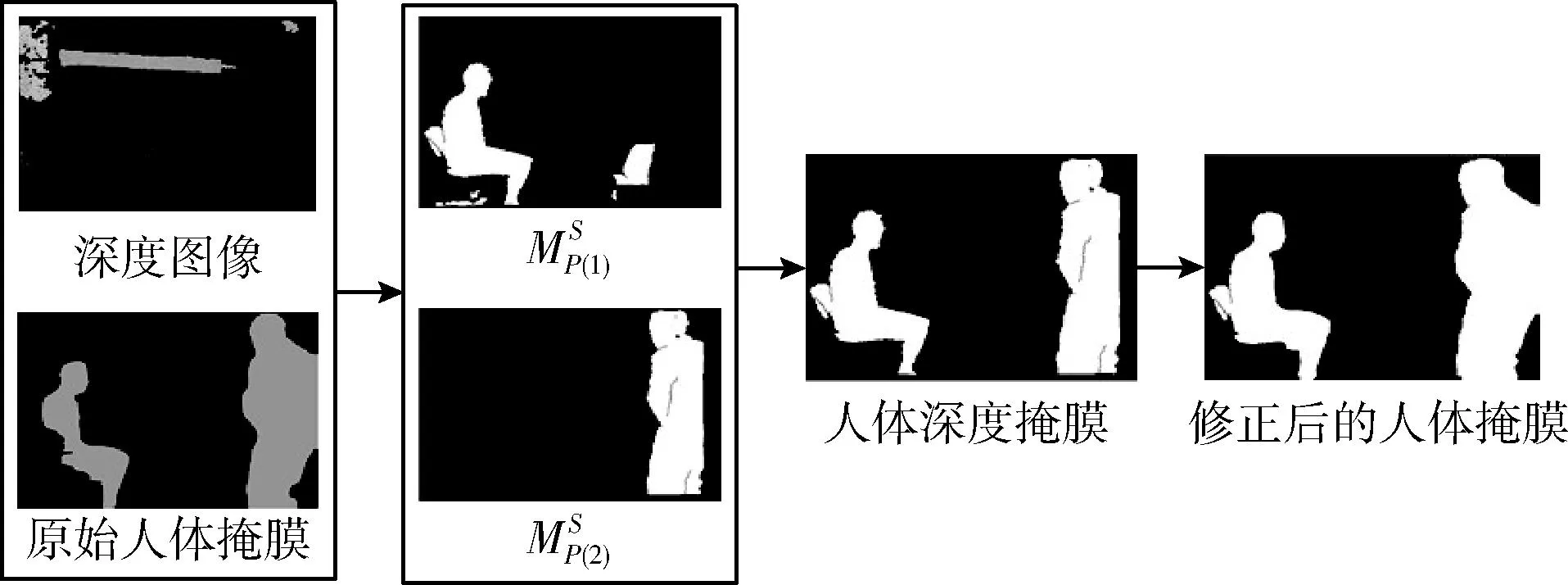
图2 人轮廓的修正过程
2.3 移除与运动物体交互的可移动物体
(1)判断二者是否发生交互
对掩膜修正后,若运动物体的掩膜与可移动物体的掩膜有交集,则认为两者存在交互,如式(7)所示,其中i=1,…,n,n为图像中运动物体的总量,j=1,…,m,m为图像中可移动物体的总量,DObj和SObj分别为运动物体和静态物体的集合
(7)
如图3所示,两个人和两把椅子修改后的掩膜显示在方框中。转椅是C(1), 普通椅子是C(2), 两人与图2一致。经过判断,P(1) 与C(1) 发生互动。
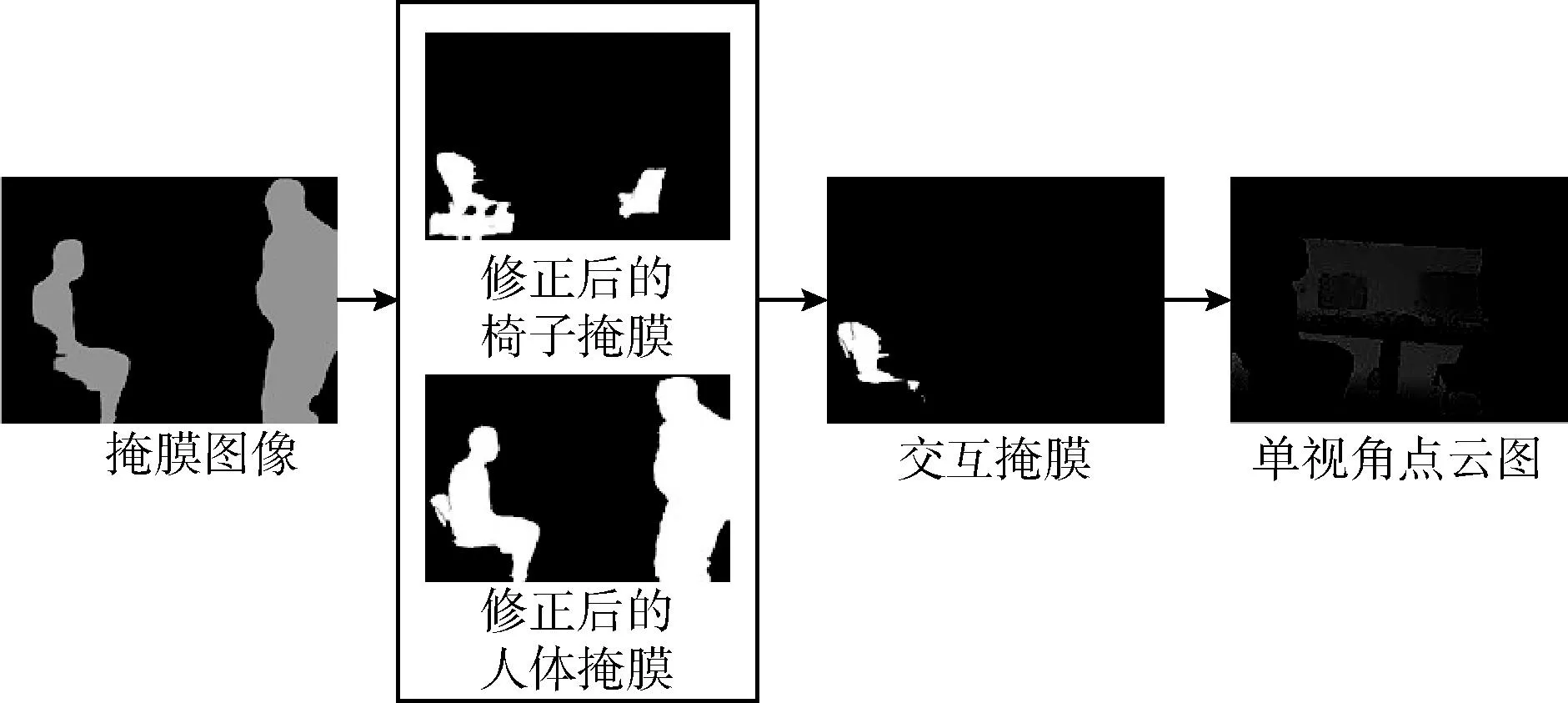
图3 人与椅子交互
(2)移除移动物体的残留噪声
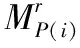
pC=HpP
(8)
利用相邻两帧残差边界的深度值相差较大的特性将边界噪声去除,如式(9)所示,其中dP和dC是IP和IC对应的深度图像,τ4为阈值。最后,通过形态学方法去除深度图像中的孤立图像块,以确保完全去除运动物体所在区域
(9)
基于以上操作,将得到清晰完整的单视角静态场景点云图。对应的给出流程如图4所示。
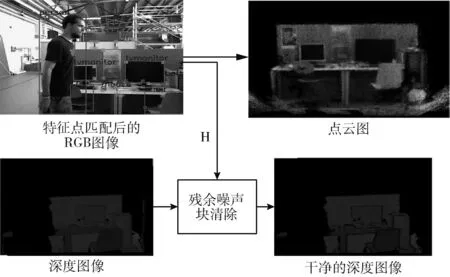
图4 残余噪声块清除
如图5所示,第一行为去除噪声块之前的局部点云,噪声块用矩形标记。第二行为去除噪声块后的局部点云数据。即噪声块被完全除去。

图5 去除运动物体前后点云图比较
2.4 静态匹配点位姿
在摄像机定位过程中,基于运动物体的语义包围盒,将图像快速划分为静态区域和潜在动态区域。基于极线约束并使用加权RANSAC方法,将潜在动态区域分类为静态和动态匹配点,为可靠性较高的静态物体点赋予较高的置信度,以有效消除来自运动物体和可移动物体的不利影响,利用剩余的静态匹配点计算摄像机位姿。
设前一帧IP和当前帧IC的两组静态匹配点为PP={PP1,PP2,…,PPm}和PC={PC1,PC2,…,PCm},IP与IC之间的摄像机位姿变换可通过最小二乘法求解式(10)得到
(10)
从IP和IC的静态区域中提取匹配点,其中I为潜在动态区域所对应匹配点的集合。内点查找函数使用输入模型对样本进行评估,并返回误差小于阈值的内点子集。加权RANSAC步骤如图6所示。
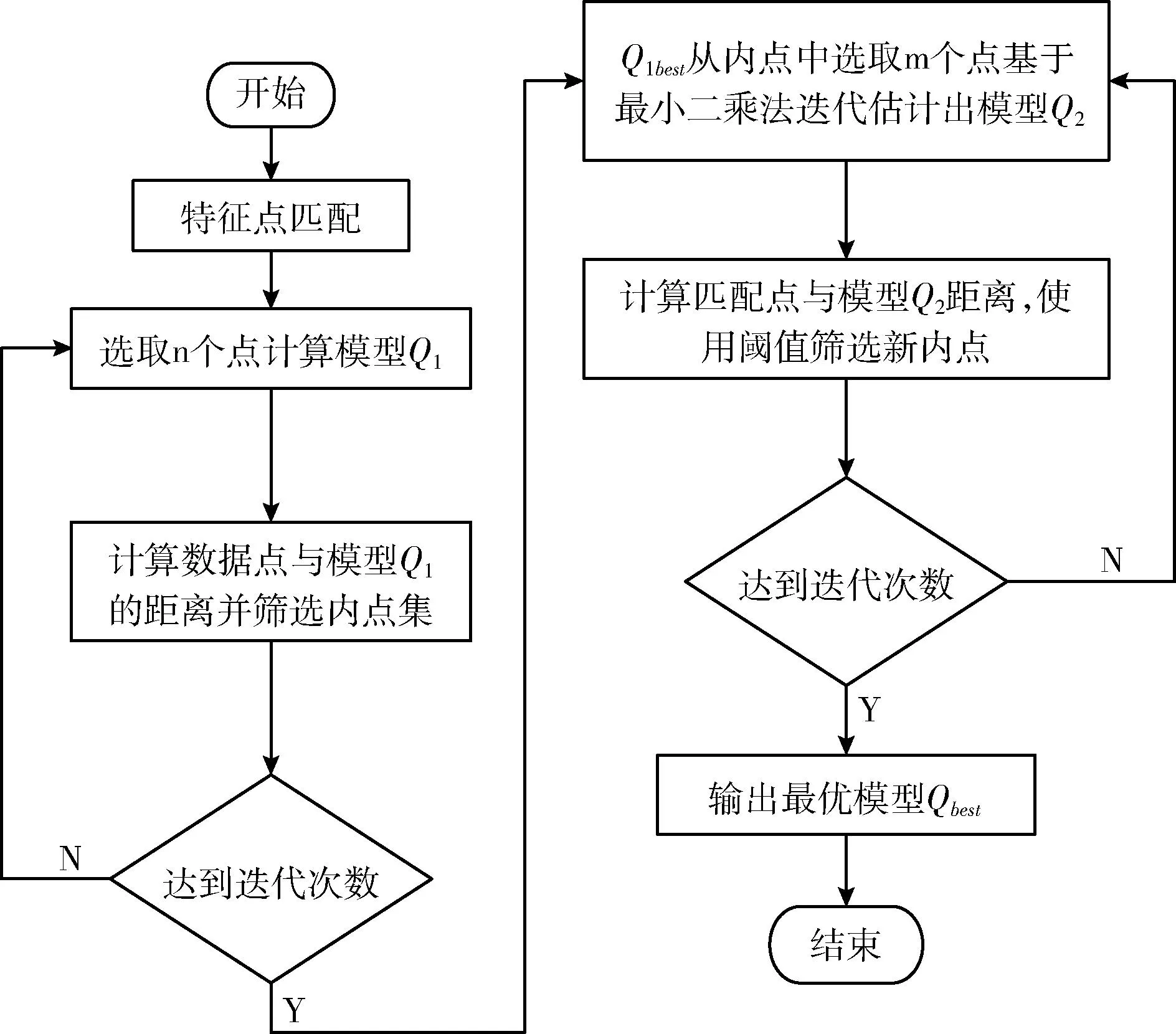
图6 加权RANSAC步骤流程
步骤1 与传统算法RANSAC算法一致,从数据集P中随机选取n个实验数据,所选取的n个实验数据需要满足构成对应图像数据集模型Q1的数量,并计算模型参数;
步骤2 模型Q1对图像数据集的所有匹配点进行距离计算,并根据阈值判断内外点,保留内点,剔除外点;
步骤3 将已获取的内点集作为初始样本,进行基于最小二乘法的初始样本模型,得到Q2;
步骤4 计算内点集与经过最小二乘法优化过的样本模型Q2间的距离,并通过与阈值比较,筛选内点,剔除外点;
步骤5 对以上4步进行循环迭代,使得迭代次数满足预期设定迭代值,得到最优模型Qbest。
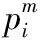
(11)
在IP和IC的潜在动态区域中提取匹配点集PDP=[uDP,vDP,1],PDC=[uDC,vDC,1]。 计算潜在动态匹配点到对应极线的距离,如式(12)所示,其中,lx和ly可通过式(13)求得
(12)
(13)
计算潜在动态区域中第i个匹配点状态的方法如式(14)所示,其中D和S分别表示动态和静态匹配点集,τ5为阈值。静态匹配点定位流程如图7所示。详细步骤如下:
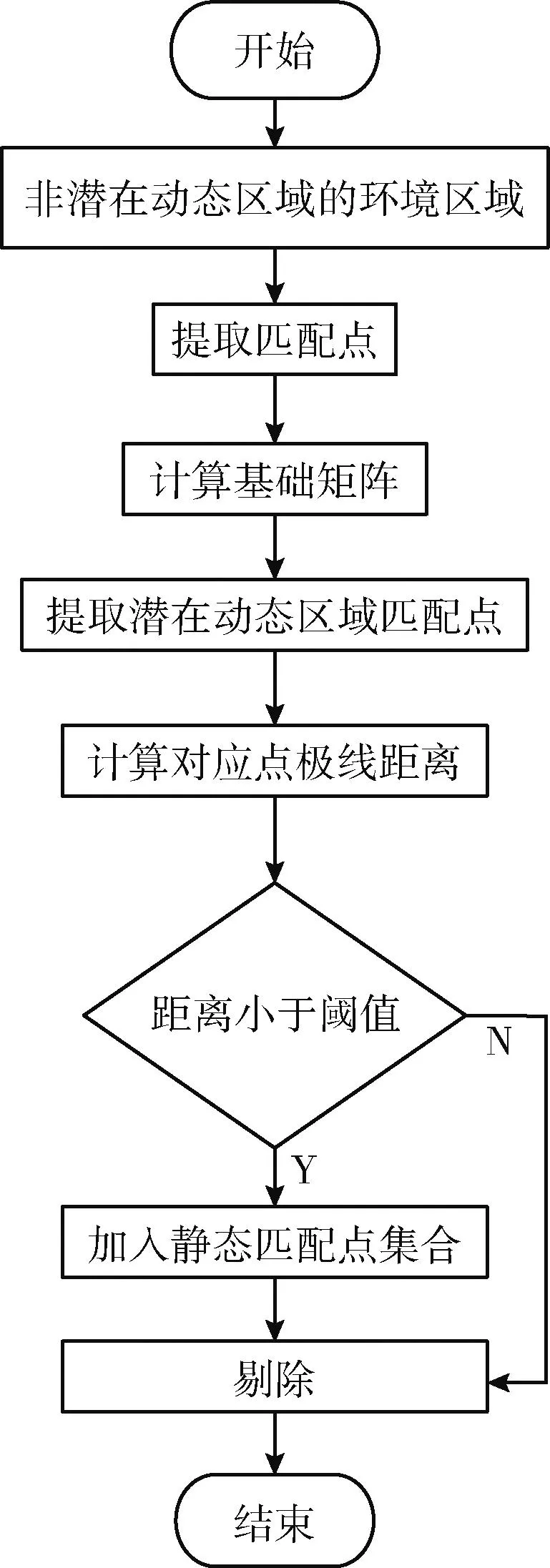
图7 静态匹配点算法流程
步骤1 获取正确的RGB图像,选取在非潜在动态区域的静态环境区域,并提取静态点;
步骤2 将提取到的特征点通过加权RANSAC算法得出基础矩阵;
步骤3 选取在潜在动态区域匹配点,通过计算对应点极线的距离,当对应点极线距离小于阈值则加入到静态匹配点集合;
步骤4 当对应点极线距离大于阈值则剔除;
步骤5 通过上述4步操作,即可得到静态匹配点集合
(14)
3 实验和讨论
3.1 机器人搭建
本文搭建的地面机器人采用四轮差速底盘,可以四轮驱动,底盘最小转弯半径为0 m,爬坡角度接近30度。选用额定功率为300 W的12寸轮毂电机作为驱动电机,采用无刷直流驱动器驱动车轮转动,如图8所示。机器人分为3层:顶层包括D435相机[15]、激光雷达;中间层包括各类传感器和工控机;底层包含电源、Jetson AGX Xavier和显示器。其中,Jetson AGX Xavier可以进行视觉测距、传感器融合、定位与地图绘制、障碍物检测等工作,拥有32万亿次运算/秒(TOPS)的峰值计算能力和750 Gbps的高速I/O性能,如图9所示。

图8 机器人实物
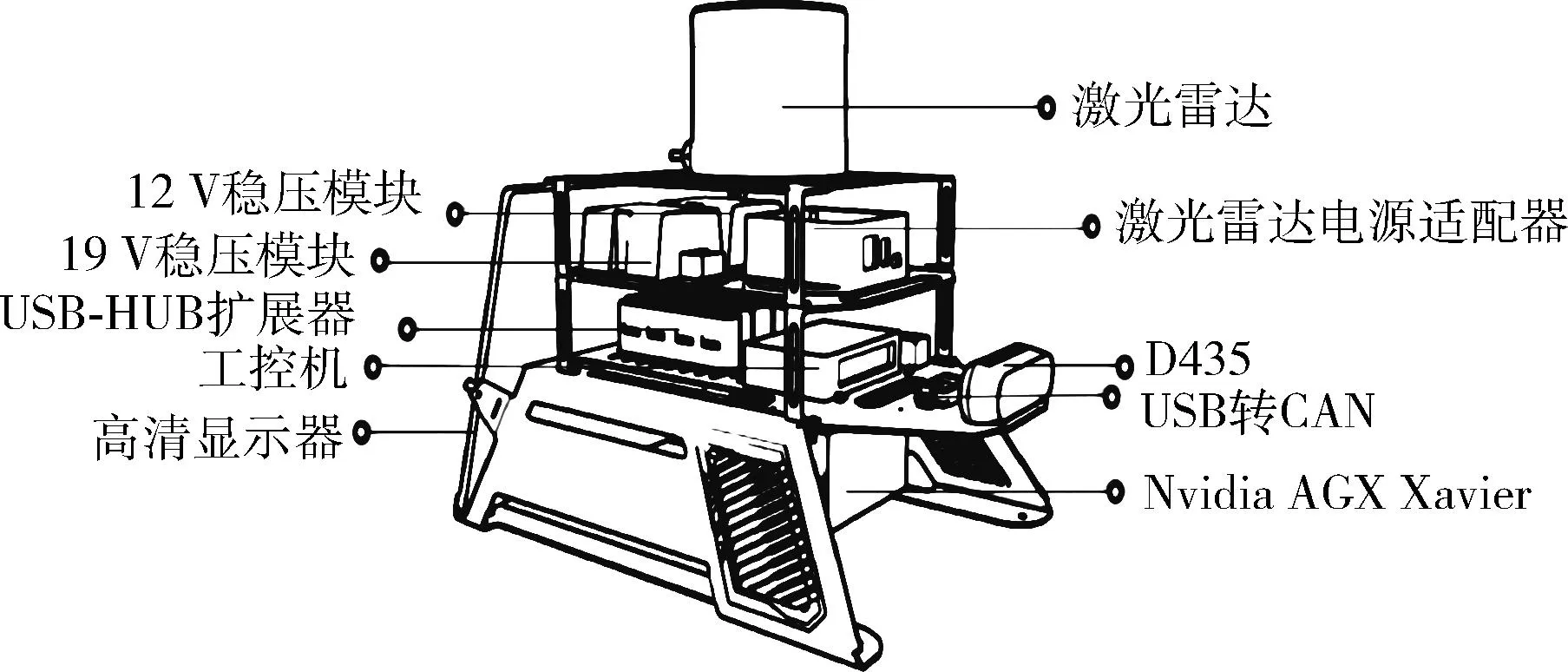
图9 机器人配件
3.2 实验环境设置
机器人工控机搭载Ubuntu20.04系统,Ubuntu系统内安装的机器人操作系统(robot operating system,ROS)作为机器人程序的运行平台。在ROS中实现用户界面(userinterface,UI)、人机交互、图像处理、SLAM、运动决策等功能并通过控制串口收发实现对机器人运动的控制与传感器信号的获取,该机器人分别进行两次实验,第一次运行标准TUM数据集来验证各类算法的精确度,并展现本文BN-SLAM系统的优化效率;第二次验证本文所提出的BN-SLAM系统在实际环境中的效果。为了保证数据的高速传输,将D435及各类传感设备连接到主机的USB3.0端口,所有获得的数据记录在机器人内部工控机。
3.3 实验功能实现
该实验中,在TUM RGB-D数据集上比较BN-SLAM与ORB-SLAM2[14],Dyna-SLAM和DS-SLAM的性能。TUM数据集提供了具有相机轨迹和参数的动态场景。选取步行序列代表高度动态的环境,并作为实验数据集。
相机有4种运动模式:半球形(half),相机在半球形轨迹上移动;rpy,表示相机绕主轴旋转;static,表示相机保持固定;xyz,表示相机沿x、y和z轴移动。使用fr3/w/half、fr3/w/rpy、fr3/w/static、fr3/w/xyz来表示4组步行图像序列,其中fr3、w分别代表参与实验的人、运动为行走。
3.4 误差估计
在实验中,绝对轨迹误差(ATE)和相对姿势误差(RPE)用于定量评估[16]。让P1,…,Pn∈SE(3) 表示估计的相机位姿,Q1,…,Qn∈SE(3) 表示实际轨迹位姿。ATE测量估计轨迹全局的一致性,ATEFi在时间步长i可以通过式(15)求得
(15)
S表示刚体变换,它将估计轨迹与实际轨迹对齐。RPE测量固定时间内估计轨迹的局部精度Δ,RPEEi在时间步长i可以通过式(16)求得
(16)
首先,对4个系统的ATE和RPE进行定量分析。4个SLAM系统的ATE和RPE的均方根误差(RMSE)和标准偏差(S.D.)值如表1~表3所示。RMSE测量观测值与真实值之间的偏差,即反映了系统的鲁棒性。S.D.衡量整体数据的偏差程度,则展现了系统的稳定性。表中的改进率计算式(17)如下
(17)
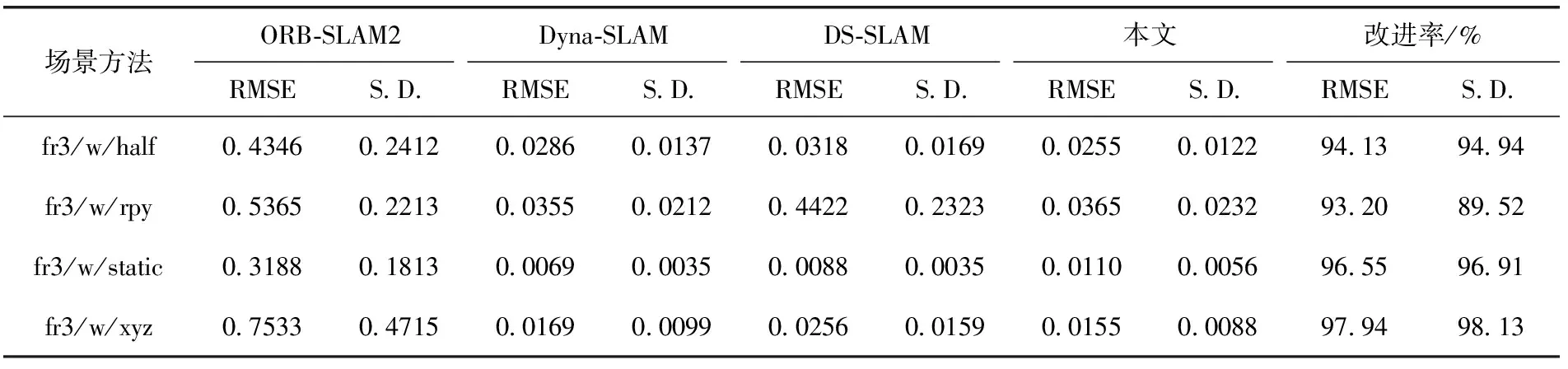
表1 绝对轨迹误差(ATE)的结果
其中,κ表示改进值,α是ORB-SLAM2的值,β代表本文的值。
表1和表2,BN-SLAM在fr3/w/half和fr3/w/xyz序列中,ATE和平移RPE的效果最好;在fr3/w/rpy序列中,BN-SLAM的结果仅次于Dyna-SLAM。表3显示了旋转RPE的结果,BN-SLAM在fr3/w/half序列中的S.D.实现了最佳值;在序列fr3/w/rpy中,BN-SLAM的结果仅次于Dyna-SLAM。
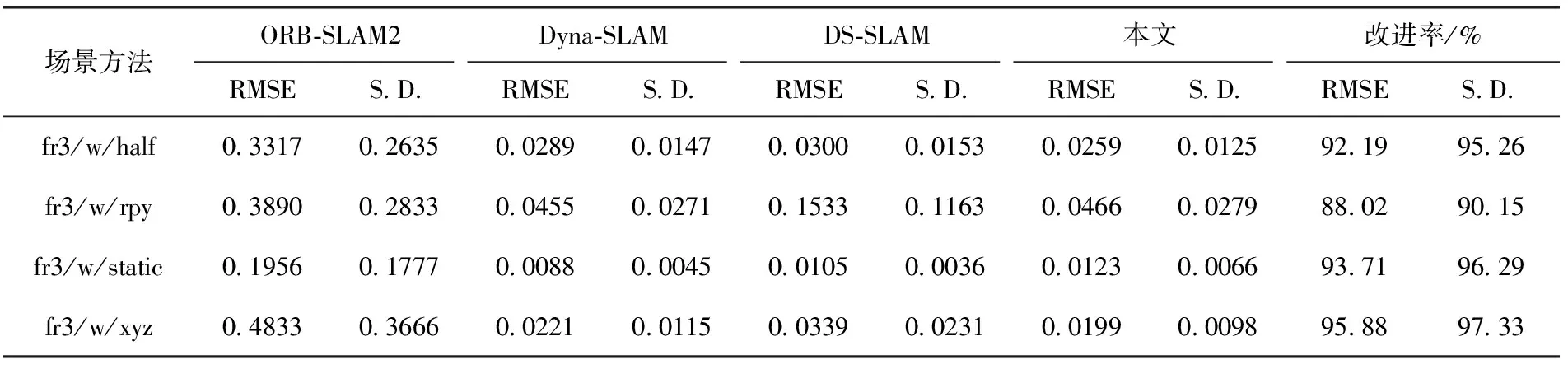
表2 平移相对姿势误差(RPE)的结果
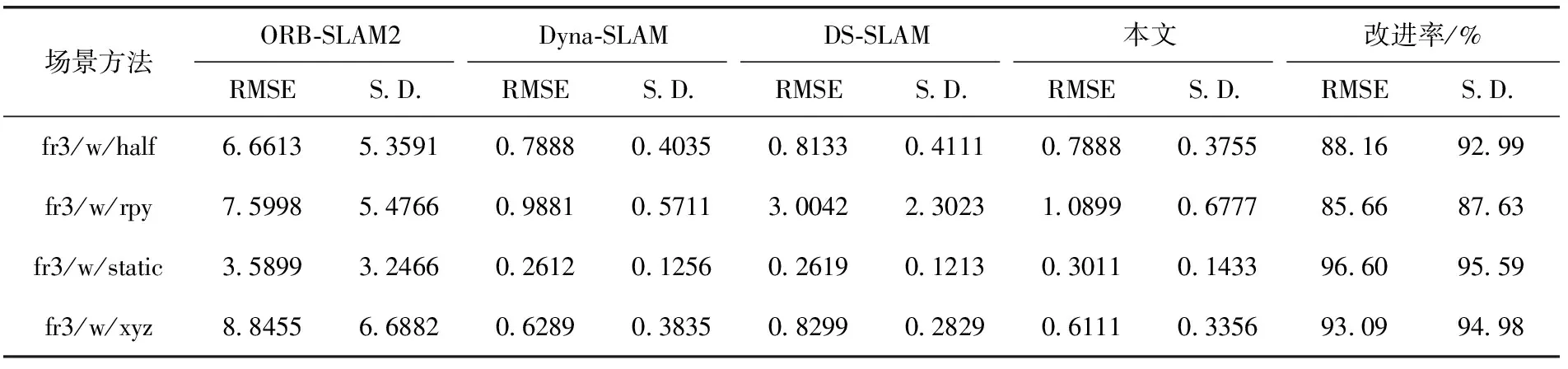
表3 旋转相对姿势误差(RPE)的结果
根据表1~表3获得的结果,在高动态环境中,消除移动物体后,相机的姿态估计将大大提高。Dyna-SLAM、DS-SLAM和BN-SLAM在上述4组序列中取得了良好的姿势估计结果。对于BN-SLAM,序列中ATE、平移RPE和旋转RPE的平均RMSE值分别为95.46%、92.45%和90.88%。且平均S.D.值分别为94.88%、94.76%和92.80%。
从图10可以看出,4个SLAM系统都失去了部分轨迹点。为定量比较4个系统跟踪的轨迹点,获取了实际跟踪轨迹点的结果,见表4。与ORB-SLAM2、Dyna-SLAM和DS-SLAM相比,BN-SLAM跟踪的轨迹点在序列中是最完整的。在该实验序列中,BN-SLAM跟踪轨迹点结果的平均率为98.80%。
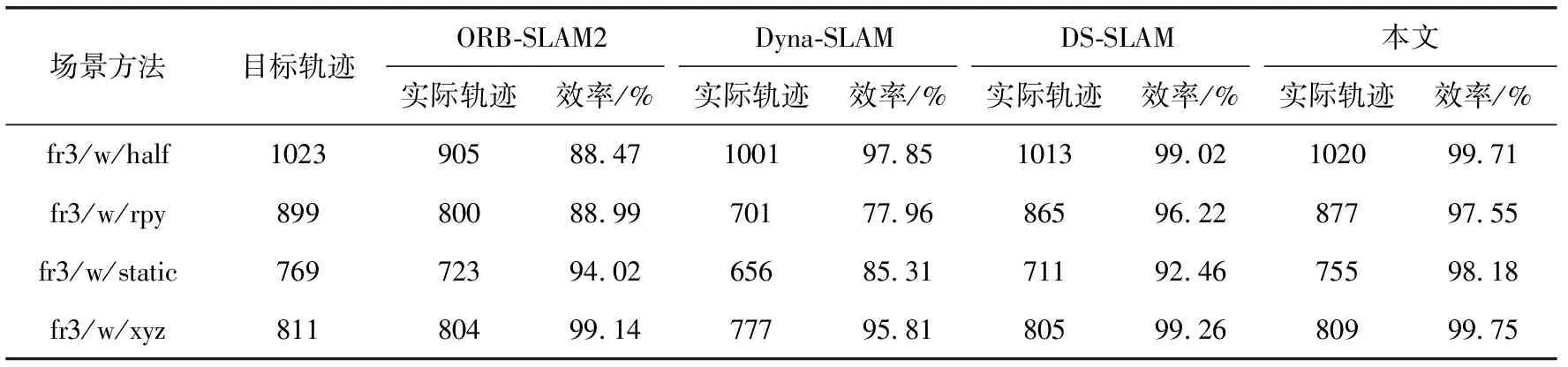
表4 实际跟踪轨迹对比结果
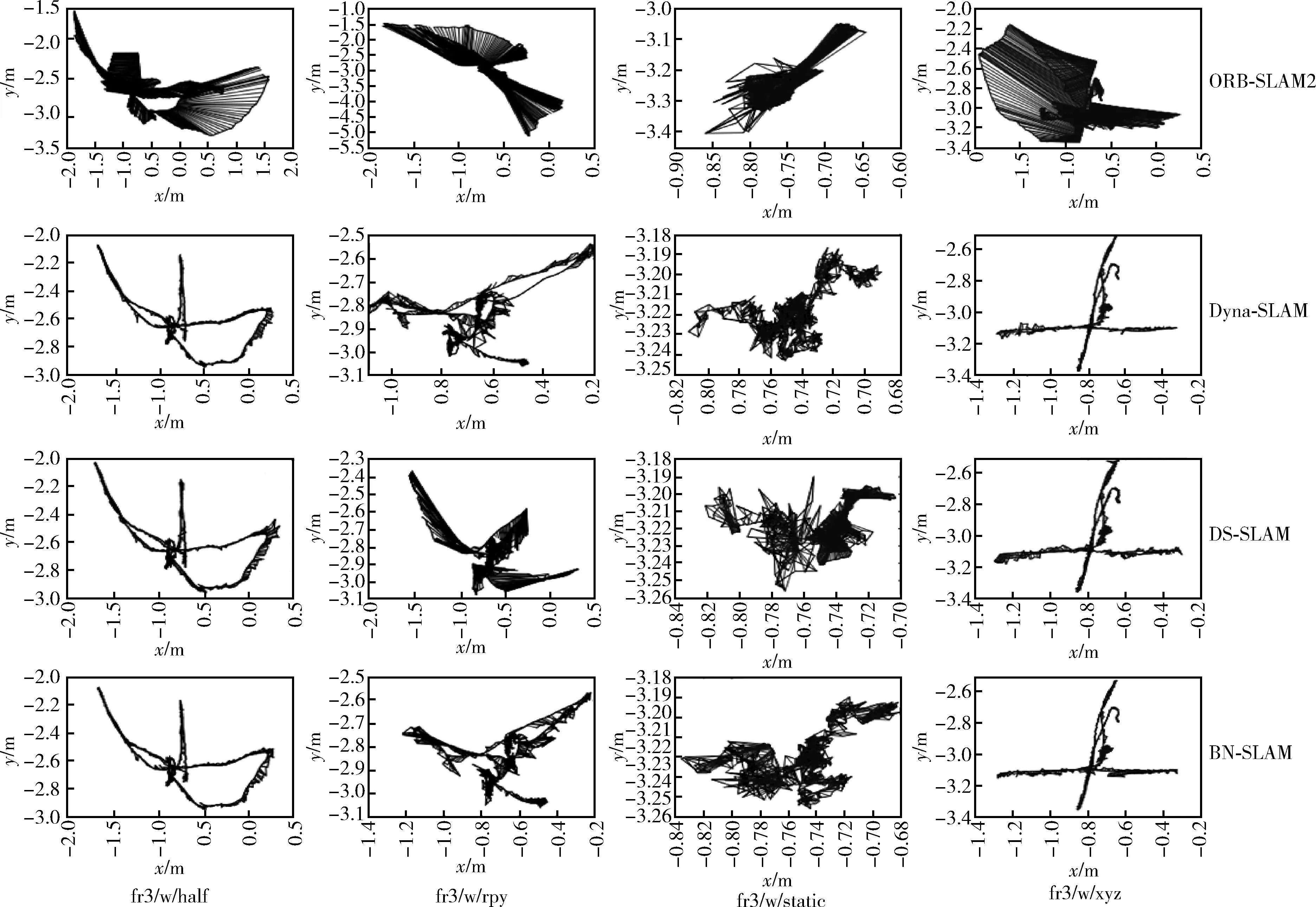
图10 4种SLAM轨迹对比
3.5 点云图的估计
图11显示了TUM数据集在高动态序列中对运动物体去除的结果。第一行显示从序列中选取的RGB图像。第二行和第三行分别显示了获得的原始掩膜和该方法修正后生成的掩膜,即原始掩膜的边界是平滑的,而修改后的掩膜边界更清晰。原始掩膜无法覆盖移动物体的某些部分,例如第一列中行人的腿,第三列中坐着的人的脚和背部,以及第四列左侧人的手臂。与原始掩膜相比,修正后的掩膜可以更完整地覆盖移动物体的区域。第四行图像是去除运动物体的修正掩模所覆盖区域后获得的局部点云,其中运动物体形成的拖尾已被去除。

图11 运动物体去除结果
如图12所示,ORB-SLAM2、Dyna-SLAM和DS-SLAM在高动态序列fr3/w/xyz中获得的全局点云图的三视图。两人的大部分信息都未能去除,桌子的木板严重变形。Dyna-SLAM和DS-SLAM消除了两人的干扰,但由于语义分割不完善,两人的边界信息被泄露到点云图中。与ORB-SLAM2相比,Dyna-SLAM和DS-SLAM的点云图中的噪声块相对稀疏,即可以清楚地看到环境中有哪些对象,但仍在点云图中具有大量噪声块。由于环境中移动人员泄露的边界信息已经被滤除,所以在BN-SLAM获得的点云图中几乎没有剩余的人员信息。

图12 高动态序列fr3/w/xyz中点云图对比
4个SLAM算法在低动态序列fr3/s/xyz中获得的点云图的三视图如图13所示。在第一列图像中,由于ORB-SLAM2可以在低动态环境中准确地定位相机,且这些点被映射到正确的位置,所以点云图中的对象清晰可见,且桌面板不会变形,但两人的信息仍未能去除。第二列和第三列的图像中,Dyna-SLAM和DS-SLAM已经滤除了这两个人的大部分信息,但仍泄露出由噪声块造成的两人轮廓边界。从第四列的图像中可以看出,去除了由两人形成的噪声块。与其它3种SLAM系统相比,BN-SLAM在低动态序列中获得的全局点云图效果最好。

图13 低动态序列fr3/s/xyz中点云图对比
3.6 在现实环境中的评估
为了验证BN-SLAM在现实环境中的有效性,使用D435相机在实验室环境中进行实验。图14显示了动态特征点的剔除结果,该实验将实际场景中静态环境区域和潜在动态区域快速划分,精准识别出运动物体,即图中语义包围盒中的运动的人。非运动物体上的大部分特征点被判定为静态点。在实验中,可以较好识别出各类静动态物体。图15分别显示了在去除人的信息前后所构建的点云图。在第一行,人体后方的静态物体被移动的人形成的噪声块挡住,墙壁也由于错误的相机定位而严重变形。在第二行中,人体的干扰被消除,静态物体清晰可见,房间的几何结构保存完好。

图14 动态特征点的剔除结果

图15 去除人的信息前后所构建的点云图
4 结束语
在本文中,提出了一个在动态环境中工作的BN-SLAM系统,它将原始掩膜和移动物体的深度信息结合起来得到深度掩膜,其深度掩膜与原始掩膜结合得到的修正掩模可以有效覆盖运动物体的区域。本文使用移动对象的语义包围盒,将图像分为环境区域和潜在的动态区域。利用环境区域中的匹配点构建极性约束,以去除潜在动态区域中的异常值。实验结果表明,BN-SLAM系统能够在动态环境中获得准确的相机姿态和清晰的全局点云图。本文系统目前设计用于处理室内动态场景,尚未扩展到室外场景,如何快速识别并滤除室外场景中的多类移动物体是下一步工作的重心。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
中国体视学与图像分析(2021年3期)2021-11-24
云南画报(2021年8期)2021-11-13
中国农资(2019年44期)2019-12-03
阅读(低年级)(2019年4期)2019-05-20
制造技术与机床(2017年10期)2017-11-28
名家名作(2017年3期)2017-09-15
光学精密工程(2016年4期)2016-11-07
科技资讯(2016年21期)2016-05-30
小天使·四年级语数英综合(2015年3期)2015-04-20
