
基于流计算和大数据平台的实时交通流预测
2024-02-22 07:45李星辉魏鹏飞
计算机工程与设计 2024年2期
李星辉,曾 碧,魏鹏飞
(广东工业大学 计算机学院,广东 广州 510006)
0 引 言
如今,城市每天所产生的交通数据量庞大,以深圳某一年的GPS数据为例,深圳市每一辆车的实时定位数据每5 min产生一次,一个月的深圳市滴滴网约车GPS数据就已达到140 GB,而大数据及其可视化技术的发展为交通数据数据挖掘方面提供了便利,不仅为数据提供了足够的存储空间,而且在实时数据抓取和预处理方面贡献巨大。
近期在交通流预测方面,Hsueh等[1]提出用LSTM作为预测交通流速度的模型。交通流预测模型往往参数量多,通常是在GPU上以离线的方式训练相当长的时间,然后部署到实际的云服务器中用于实时预测。但在实际交通场景中,交通数据不断更新,交通流预测模型也需要能随着数据集的更新不断调整。因此这里提出一种基于流计算和大数据平台的实时交通流预测方法,在保持一定精度前提下,训练速度比在GPU上跑的更快,可对实时交通流数据进行捕获、建模分析和预测,从而满足实时应用的需求。
综上所述,主要贡献如下:
(1)提出一种Flink流计算框架和交通数据预处理方法。
用Kafka消息系统采集交通路段传感器的数据,经过Flink流式的预处理后,把数据送入到独立分布式的大数据集群中,实现了对交通流数据的实时抓取—预处理—分流。
(2)提出一种基于Hadoop大数据平台的深度学习模型并行训练模式,充分利用大数据资源与技术实现最大程度的数据并行。
(3)采用了某个交通路段的多个道路传感器产生的数据对模型进行训练和预测实验。利用滑动窗口自动地选取最近邻的历史数据集对模型进行训练并用于预测,追求流式自动化和实时处理。在保持一定的精度的情况下,探索了比GPU训练方式更快的模式,满足了实时预测的要求。
1 相关工作
1.1 交通流预测相关研究
在交通流预测领域里,基本上都是采取先训练模型,然后用实时数据集去预测未来的某个道路的车速度和流量。Fitters等[2]利用LSTM模型,先基于车流的密度去划定一些圆形的区域,提取坐标点之间的时空联系作为特征输入到模型,以预测未来某个路口的交通流量。Chen等[3]以Bi-GRU模型作为主干网络预测未来道路的车流速度,通过增加GRU模型的层数让模型学习到的特征更多,从而提高训练精度。Zhang等[4]通过KNN模型与额外的时间-空间-距离权重公式结合去直接预测交通流量,整个过程都将模型运行在Spark中得以加速。以上所提到的方法都是采用离线训练和处理的方式,模型参数量大,需要较长的训练时间,很难满足实时性的要求。所以如何让模型在保持一定精度的情况下,尽可能缩短训练时间来实现预测实时性是亟待解决的问题。
1.2 流计算的相关研究
流计算通常是采用基于大数据框架的实时采集、分析和导出数据的工具来实现的,目前应用最多的是SparkStrea-ming和Flink。流计算被广泛应用到很多领域,这些领域都对实时性要求高和比较依赖于历史的时间性或空间性,Kanavos等[5]在冬季天气预测里,SparkStreaming主要负责实时采集天气传感器的各类特征数据。在网络冲突检测领域,Garcia等[6]以SparkStreaming 作为主要框架进行网络交通流信息的处理。Tun等[7]提出了采用Kafka集群对输入流进行采集,经过SparkStreaming批转换然后进行实时分析。对比SparkStreaming微批处理机制,Flink在时间处理机制方面有着更为灵活的方式,不但能够基于当前的处理时间,也能够基于实际的事件时间。Abbas等[8]对交通拥塞进行减缓,在对交通拥塞的检测之前,利用交叉路口的摄像头捕捉数据,并对连同道路设施信息一起计算出平均速度、车辆的密度等指标。这种方式可以及时地捕捉到路况的时空变化。Flink对数据集处理延时低,但Abbas等[8]并未涉及交通流预测,本文将Flink实时流计算框架和深度学习模型结合,实现实时采集、处理和训练的一体化。
1.3 并行计算的研究
Mahmud等[9]和Dafir等[10]对并行计算进行了分类。首先“垂直并行”是运行在同一个服务器上并且添加一定的处理器、内存和快速硬件,如FPGA;而“横向并行”则是集成多个分布式服务器的系统,把工作量分配给多个服务器去并行。
“垂直并行”中,GPU最大的特点是它拥有超多计算核心。图1为GPU和CPU的组成原理对比,GPU每个处理器都相当于一个“核",在实际的GPU运算场景中,这些处理器之间相互独立,其计算能力比起CPU核较弱。GPU相对于CPU是非常昂贵的资源,以时空图卷积网络[11]和分层结构的图神经网络[12]作为主干网络的交通流预测模型,GPU在离线的情况下训练这些深度学习网络加速效果很明显,但是GPU显存不够用会导致训练时batch大小被限制,GPU的并行效果突破不了瓶颈,在这种情况下,可能需要再引入显存更大的GPU以满足需求,但这样成本太高。
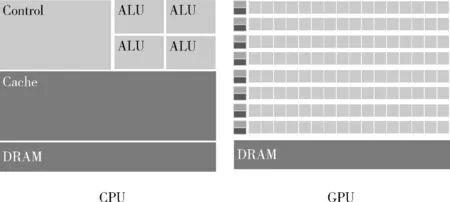
图1 GPU与CPU内部组成对比
Hadoop大数据集群的Yarn资源管理多“核”和内存,CPU核计算单元对比GPU单个计算单元的处理能力要出色,所以从理论上来说利用大数据平台的多核资源提高并行度,把工作量分配给多个节点,通过增大每次“喂入”深度学习网络的batch-size来提升训练速度,有着潜在的优势。
1.4 分布式计算框架相关研究
1.4.1 Spark和Ray
Spark继Mapreduce后,在工作负载方面表现较优越。近几年频繁项集挖掘相关算法(FIM)被部署在了Hadoop Mapreduce上,但是由于磁盘IO的问题,Mapreduce在FIM这种高迭代的算法上效率不高,Singh等[13]把FIM的其中一种算法Eclat的思想设计成Spark的RDD框架下的逻辑,使之并行化,并且通过不断地增加可用核数和数据集的大小优化效率,展现出了可扩展性。Zarindast等[14]在Spark RDD的框架下设计识别高速公路拥堵的模型和逻辑,其模型能够展现范围更大的时空拥堵特征,其计算能力之高与覆盖范围之广得益于高效Spark分布式数据处理系统。
Ray[17]分布式计算框架吸收了Spark在数据逻辑上的好处并且具备了像Yarn一样的资源管理功能。在Ray的远程调用函数中可以自由定义多个远程节点并按需分配计算资源。Ray的分布式应用能直接无缝地集成到Spark数据处理的流水线中,在Spark平台中Ray给予其更为灵活的资源分配与调度方式。
1.4.2 分布式集群下的深度学习
深度学习与大数据平台的结合在电商领域,Mishra等[15]基于Analytics Zoo,把商品推荐算法关联规则分析和协同过滤算法部署在分布式计算平台上取得了一定的成效,展现了Spark集群的可扩展性,比起单机模式在训练精度和速度上大大提升。Haggag[16]基于SparkDL,通过不同的节点数和并行度,对比在不同的配置下网络冲突检测算法的训练速度。
以上方法基于分布式集群加快模型训练速度的,但是对于节点的每个任务的资源分配无法细化,而Ray可以进一步操控资源的分配,使资源利用率和扩展性更高和更强。
2 系统架构与问题建模
2.1 系统架构
整个系统架构如图2所示,主要包括两大部分:一个是基于Flink流计算的环境部署;另一个是分布式深度学习的环境部署。

图2 实时交通预测系统架构
2.1.1 数据抓取、预处理和采集
首先实时的交通数据都分别存于Mysql,总共有307个传感器的数据,Flink对这些数据进行校验,对异常数据,如塞车或者速度检测异常的数据实时过滤。这些数据源源不断地流入到Kafka并在某个Topic中进行存放,然后Flink再把这些数据从Kafka“沉积”到HDFS文件系统。
2.1.2 滑动窗口选取数据集
数据进入HDFS文件系统后,本文采用滑动窗口形式选取数据,每过一段时间从HDFS中选取最近的历史序列数据作为大数据并行框架下预测模型的输入来训练模型。
每当有新的数据进入,即新增一小时的数据进入HDFS,负责采集最新数据集的窗口就会以若干小时为单位去移动(具体多少个小时由实际的交通场景去确定)并进行实时预测,如图2所示。
2.1.3 大数据平台下的数据并行环境
大数据并行的环境主要包括SparkonYarn和RayonSpark两个方面。
第一,SparkonYarn作为Spark的其中一种运行模式,将Spark应用部署在Yarn上,SparkonYarn流程如图3所示。
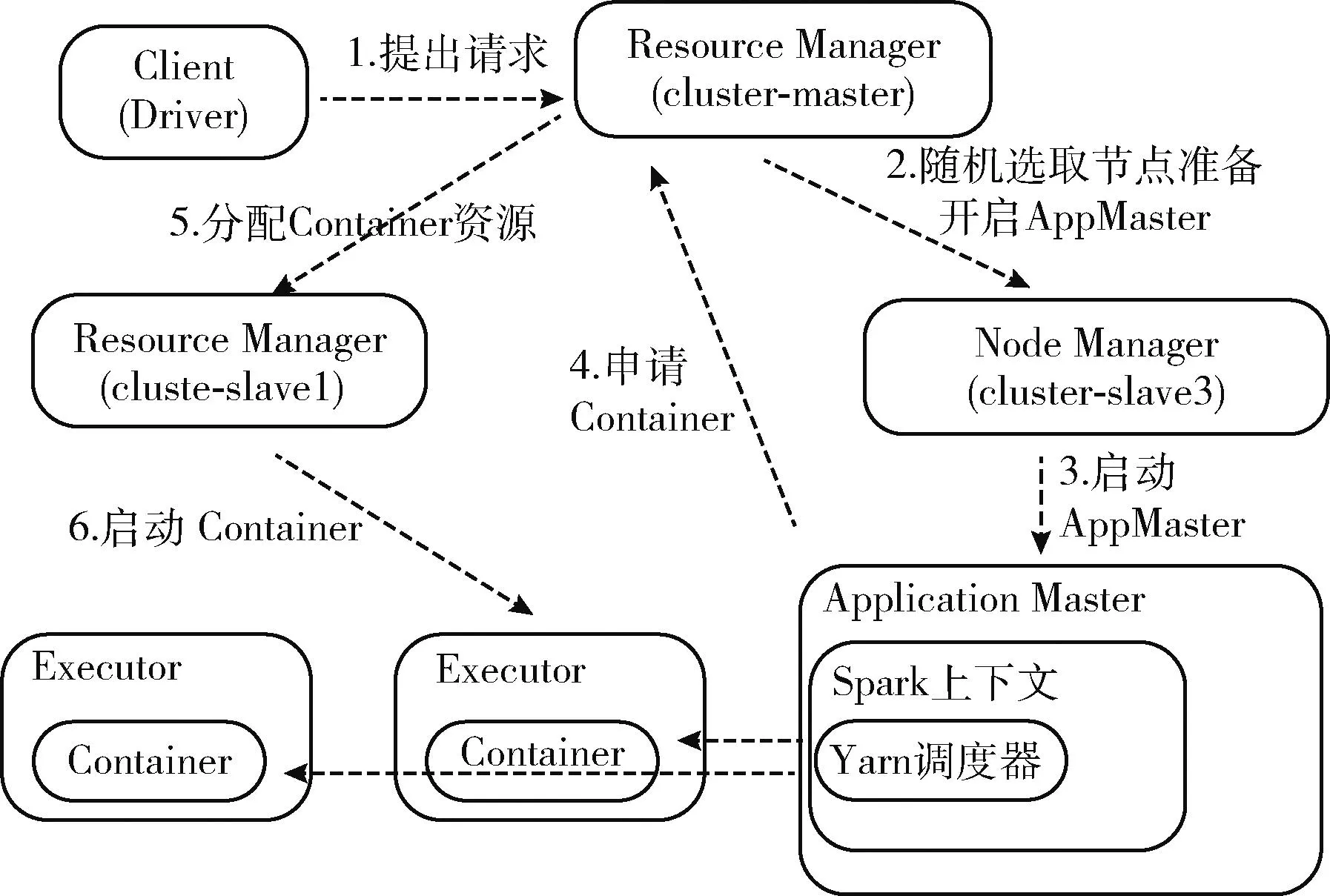
图3 SparkonYarn整体流程
第二,RayonSpark把Ray部署在了Spark大数据集群之上,首先,使用conda-pack打包Python环境,在运行时分发到各个节点上。其次,Spark会在Driver节点上启动一个Spark上下文的实例,SparkContext会在整个集群启动多个Spark executor执行Spark的任务。除了Spark上下文之外,RayonSpark设计中还会在Spark Driver中创建一个Ray上下文的实例,利用现有的Spark上下文将Ray在集群里启动起来,Ray的进程会伴随着在Spark executor,包括一个Ray 主节点进程和其它的Ray从节点进程,图4为RayonSpark整体架构建立流程。

图4 RayonSpark整体架构建立流程
结合相关工作所述,把大数据平台的Yarn和Spark、Ray两个分布式框架进行整合,使得从数据逻辑方面到资源调度方面可控性高,可扩展性强。
2.2 问题建模
本文基于大数据平台,采用LSTM作为交通流预测模型,LSTM部署在远程大数据平台,结合基于Flink的实时流计算模式,以及部署在大数据平台多节点的资源分配算法,本文提出了一种基于流计算和大数据平台下LSTM的实时交通流预测方法RT-LSTM(real-time LSTM)。在后面对比实验中,与之对比的是离线模式下GPU的训练方式G-LSTM(GPU-LSTM)和基于CPU和内存的方式(CM-LSTM)。
2.2.1 LSTM模型
(1)LSTM模型包含输入门Zi、遗忘门Zf和输出门Zo,其计算公式见式(1)~式(4),其中xt,ht分别为t时刻的输入和隐藏层输出
Z=tanh(W(xt-1,ht))+b
(1)
Zi=σ(Wi(xt-1,ht))+b1
(2)
Zf=σ(Wf(xt-1,ht))+b2
(3)
Zo=σ(Wo(xt-1,ht))+b3
(4)
(2)长期记忆Ct、短期记忆ht和最后的输出Yt的计算见式(5)~式(7)
Ct=Zf·Ct-1+Zi·Z
(5)
ht=Zo·tanh(Ct)
(6)
Yt=σ(W′·ht)
(7)
其中,t指输入序列的长度,W开头的参数与输入和隐藏层维度的拼接的维度一致,需训练参数有W、Wi、Wf、Wo和W′这5个参数矩阵。
2.2.2 多个远程节点的资源分配算法
在Ray_on_Spar和Spark_on_Yarn的环境部署完毕后,在大数据平台开启多个训练节点,并把所准备的资源分配到这些节点上,最后得到多个远程工作节点。具体实现过程如下。
首先获取Ray的上下文,从Ray上下文获取到每个executor所分配的core数和executor数,而在Ray层,可以再次划分子节点数,见算法1的过程(1)至(4)所示。
接着Ray分布式框架开启多个远程节点(Remote Runner),并根据每个executor的所分配的core数、executor数和子节点worker数(worker_per_node)分配资源,Ray 把参数Params分配给对象 obj,并且形成远程工作节点Remote Runner的公式可表示成如算法1的过程(4)。其中RemoteRunner的类型即为obj的类型,而此处的对象类型是基于Pytorch的分布式训练器,本文2.2.3给出其定义。
预定义好Ray远程节点的相应参数和对象类型后,接着分配计算资源,包括子工作节点和cpu核,最后将所有工作节点集合起来启动torch分布式模式setup_torch _distributed,setup_torch_distributed的分布式的原理会在2.2.3详细介绍。
算法1:启动多个远程节点
输入:Raycontext:Ray环境上下文
PC:在Spark on Yarn后获取每个executor的所分配的core数。
N:在Spark on Yarn后获取executor数。
W:预设的每个节点的子工作节点数。
TR:TorchRunner(Pytorch模型封装运行器)。
Params:LSTM模型参数(包括模型结构model、优化器optimizer、损失函数loss、评判指标merics等)。
预定义函数:R(params)(obj)。
输出:多个远程工作节点RW
过程:
(1)Ray_ctx←RayContext.get()

num_nodes←Ray_ctx.N*W
(3)RemoteRunner←R(PC)(TR)
foralli∈{1,2…num_nodes}do
(4)RWi←R(params)(RemoteRunner)
(5) (RWi指的是第i个RemoteWorker)
endfor forallj∈{1,2…num_nodes}do
RWj←set_up(cores_per_node)
(6)endfor
(7)HW←RW0
(8)addr←HW.set_up_address()
(9)forallk∈{1,2…num_nodes}do
RWk.setup_torch_distributed(addr,k,num_nodes)
endfor
2.2.3 Pytorch分布式训练流程
环境部署后,需要把RT-LSTM模型参数打包给训练器,这里所用到的是基于Pytorch的训练器(Torch-Runner),训练器主要负责把模型参数封装好,并且定义并行度以及已有资源分配方面的参数,比如子节点数,表示每个训练器分配多少个worker去训练。
Pytorch分布式训练通信的后端使用的是gloo或者NCCL,其中NCCL对应于GPU分布式训练,gloo对应于CPU分布式训练(即本文采用的模式)。Pytorch中的数据并行训练,涉及nn.Data Parallel(DP)和nn.parallel.Distributed DataParallel(DDP)两个模块。效率较高的是DDP模式,图5为DDP模式下各设备(Rank0~Rank4)的参数传输机制。

图5 DDP模式参数传输机制
Pytorch分布式训练流程如图6所示,第一次循环后,每个设备会把收到的数据和自己的数据相加,然后进行下一个循环,经过K-1次循环后,每个设备都有其中一部分参数的完整数据,比如设备0有完整的b,设备1有完整的c。经过上述的Scatter-reduce后。后续再进行All_gather过程。这样经过K-1次后,所有的设备都将具有所有参数的完整数据,如图6所示,下一步将把这些参数汇总到第一个设备RW0上,也如算法2过程的式(5)所示。

图6 DDP Scatter-reduce和All_gather
算法2的步骤如下:首先根据device、训练集与测试集比例,输入与输出的序列制作数据集,根据RemoteWorker的数量分发数据集到每个工作节点,然后依据batch_size构建批数据集,即增加一个关于batch的维度,接着多个工作点开始同时训练,不断地以Pytorch分布式DistributedData-Parallel的机制去更新模型参数,最后汇总到rank为0的device上,并预测未来的速度值。
算法2:RT-LSTM分布式训练的算法流程
输入:epoch:训练迭代次数
Size:RemoteWorker的数量
RW:RemoteWorker
W:预设的每个结点的子工作节点数
Para:LSTM模型参数
X:最近一小时的各个传感器的记录的车流速度
Device:设备(CPU或者GPU)
v_path:数据文件路径
train_pct:训练集比例
n_time:历史时间序列
out_time:以未来的某个时间标签值
Info:训练参数
数据集转换函数:TFD(d,v,train,test,n,o)
数据集分发函数:DistributedSampler(d,s,r)
输出(output):模型预测的未来的15 min个传感器的速度值
过程:
(1)Ds←TFD(device,v_path,train_pct,test_pct,n_time,out_time)
(2)foralli∈{1,2…size}do
Di←DistributedSampler(Ds,size,rank)
(其中D={D1,D2…Dsize})
endfor
(4)forallj∈{1,2…size}do
Dataloaderj←Datacreator(Dj,batch_size)
endfor
(5)forallk∈{1,2…epochs}doRWj.train_epochk(Dataloader,Info)
(表示第j个RW的第k个epoch,此处多个RW同时进行训练。)

endfor
(6)Output=RW0.model(x)
3 实验及分析
3.1 数据集
本文的交通数据从PEMS 数据集中选取,这些数据已被广泛用于测试大规模交通流预测模型,它们都来自于美国加州某主要路段300多个loop传感器采集的数据。传感器每30 s采集一次,并以5 min为一个周期聚合。本文采用了2018年两个月的数据,并选用了其中的速度值作为特征进行实验。超参数优化之后,以12作为窗口大小(1 h,12个5 min)选取数据集进行预测。
3.2 对比方法
对比方法根据并行的理论进行分类,首先是基于CPU与内存的离线训练模式—CM-LSTM,其次是GPU模式G-LSTM,利用GPU本身的并行机制,通过调整batch-size的大小,使之一次性尽可能地处理更多的数据。最后是Ray-Spark大数据框架并行模式—RT-LSTM,调整不同并行度(D3、D6、D12)作比较。为了能够对比不同模式上的实时性,这里通过调整batch-size,使得所用的内存和GPU并行模式所用的显存基本一样,都约为8 G。
后面的实验从两个方面展开,一方面是在运行内存基本一样的情况下,从训练的时间和误差(RMSE)去对比几个模式的并行的效果;另一方面通过调整不同executor数量、worker_per_node(子工作节点数)、core数量,以研究RT-LSTM训练的最优化效果。
3.3 实验设置
3.3.1 显卡配置
GPU Memory:11 019 MB
CUDA 版本:11.4
3.3.2 Hadoop集群配置
集群节点数:3
可用RAM:40 960 MB
存储空间:28.4 TB
3.4 对比结果和分析
首先本文在相同的显存和内存的情况下进行了实验一,比较了CM-LSTM、G-LSTM和RT-LSTM大数据框架并行两种模式下模型训练的效果,主要比较它们的训练误差、训练速度和拟合的效果,表1为整体对比效果。

表1 各种模式实验效果对比
其次,在大数据框架并行模式下进行了实验二至实验四,对比了不同参数时的训练误差RMSE、训练速度和实现拟合收敛所需的epoch数,从表1和表2可看出相应的对比效果。而从表3得出计算资源分配数量与训练速度的关系。

表2 RT-LSTM模式下不同节点数和worker数的对比

表3 RT-LSTM模式下(工作节点数相同)的不同节点分配的core数结果对比
3.4.1 实验一
首先对比的是CM-LSTM、G-LSTM模式和框架并行RT-LSTM的测试误差RMSE,RMSE为均方根误差,从框架下的并行(RT-LSTM)里可以看出,由于数据集被分发了3份、6份和12份分别进行训练,训练误差方面虽然不如G-LSTM模式和CM-LSTM,但是相差不是很大,只相差了大约0.33 km/h,这个误差在实际的场景中是可以接受的,比如预测速度值是50.33 km/h,而实际的速度值是50 km/h。在训练速度方面,对比的是总训练时间,总训练时间等于拟合所需要的epoch数乘以平均每个epoch的所需要的时间,可以看到,在所需内存相同的情况下,大数据框架并行模式所需总训练时间最多为93.8 s,比GPU模式总训练时间要小很多,可见在训练速度方面均优于GPU并行,而从表1可以看出,CM-LSTM已经完全不具备实时性。图7和图8分别为不同模式在总训练时间和训练误差的对比。
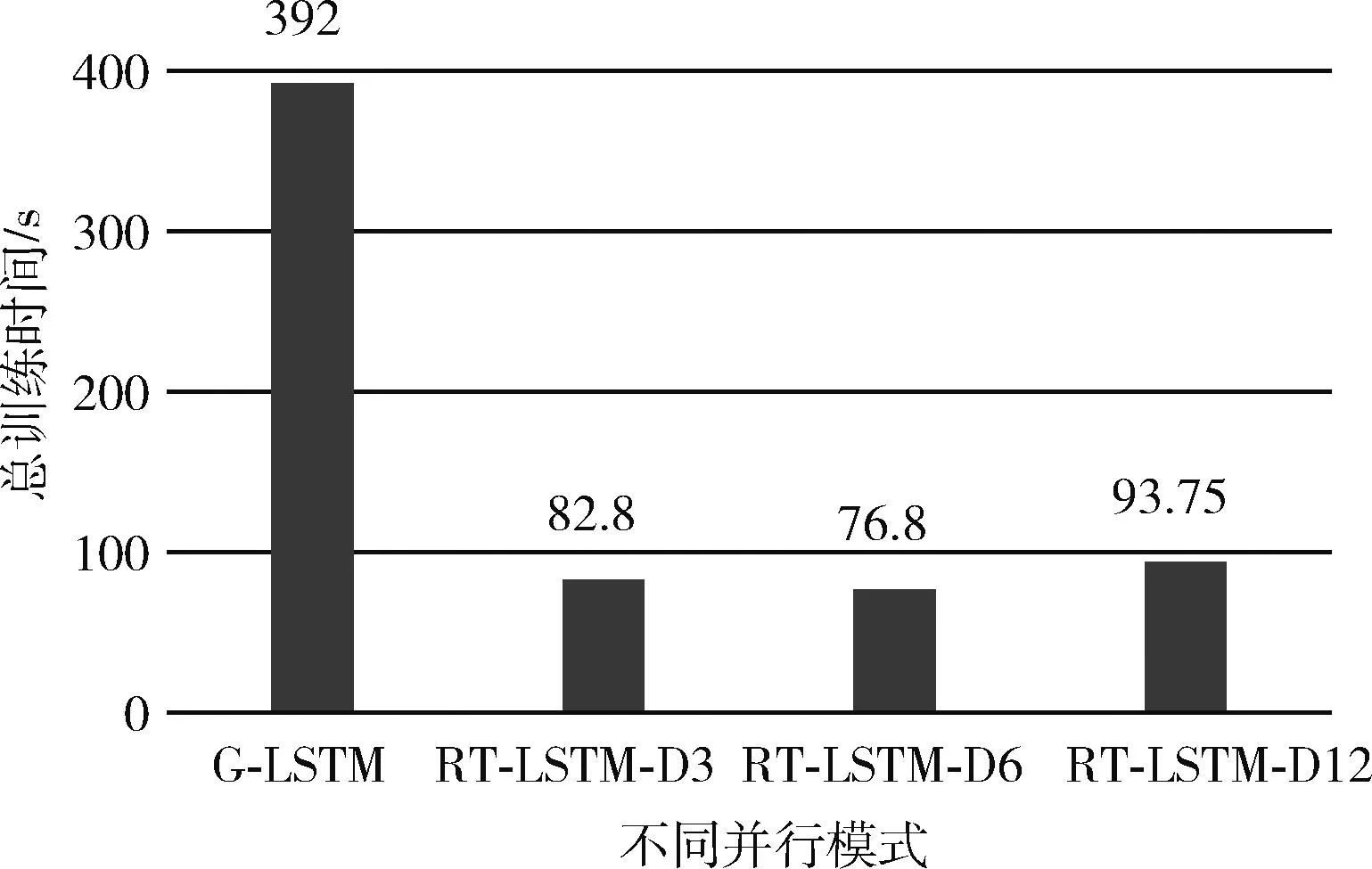
图7 不同模式总训练时间对比

图8 不同并行模式训练误差对比
3.4.2 实验二
在大数据框架并行模式中,不同的TorchRunner数量对训练误差影响不大,但是速度上会有显著的区别,TorchRunner即为总工作节点数,其数量等于数据并行度(并行度=num_node*worker_per_node),误差效果方面最好的是并行度为3的情况,误差为3.678。然而在总训练时间方面,虽然并行度提高了对于本来可以一次让模型的效果达到拟合收敛的数据集,被划分成了3份,需要一份接着一份地去让模型进行学习,相当于要把训练的“步伐”减缓。图9和图10分别为不同工作节点数的训练误差和训练时间对比,其中n1w3表示executor数为1,子工作节点为3,其工作节点数为n*w=3,其它以此类推,图11为每个epoch所需的时间的结果对比。

图9 RT-LSTM下不同工作节点数之误差对比
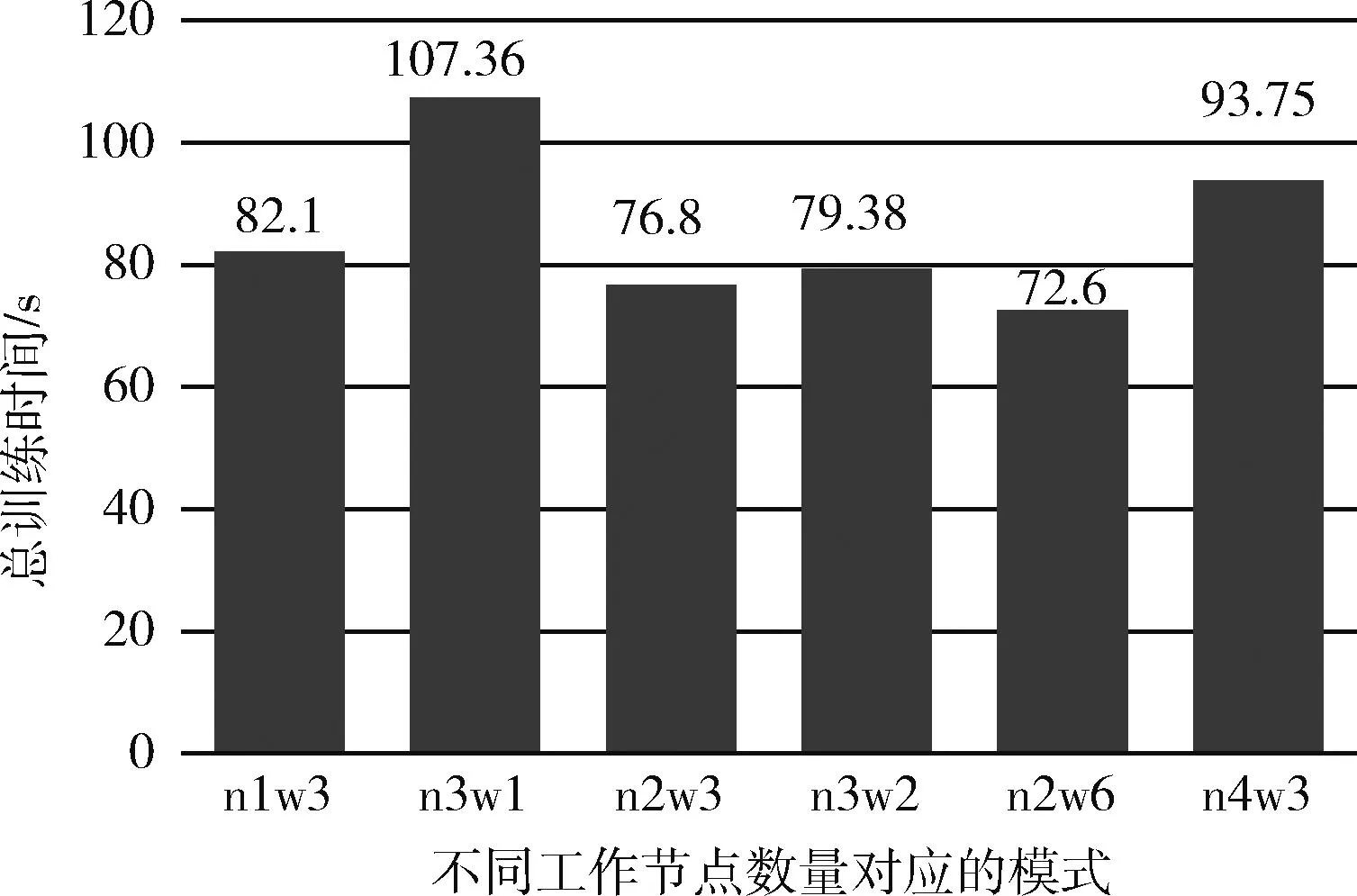
图10 RT-LSTM下不同工作节点数之总训练时间对比

图11 RT-LSTM下不同工作节点数之epoch时间对比
3.4.3 实验三
RT-LSTM模式中,在同样的工作节点数量下,也就是数据并行度一样的情况下,子工作节点数对模型的训练也有所影响,每个节点的worker数主要影响的是节点的每次训练的batch-size。虽然在环境准备时,所分配给每个节点的core资源是一样的,worker_per_node数量越高,单个工作节点每次训练的batch-size会越小,batch的数量会提高,但是由于RT-LSTM的多核的环境下并行度随着子工作节点数量的提高而变高,所以如图12所示,每个epoch需要的时间减少,即训练速度加快。此外,由于batch-size减小使每次epoch对参数的更新次数增加了,训练“步伐”加快,因此收敛所需要的迭代次数降低,从而缩短了总训练时长,如图13所示。
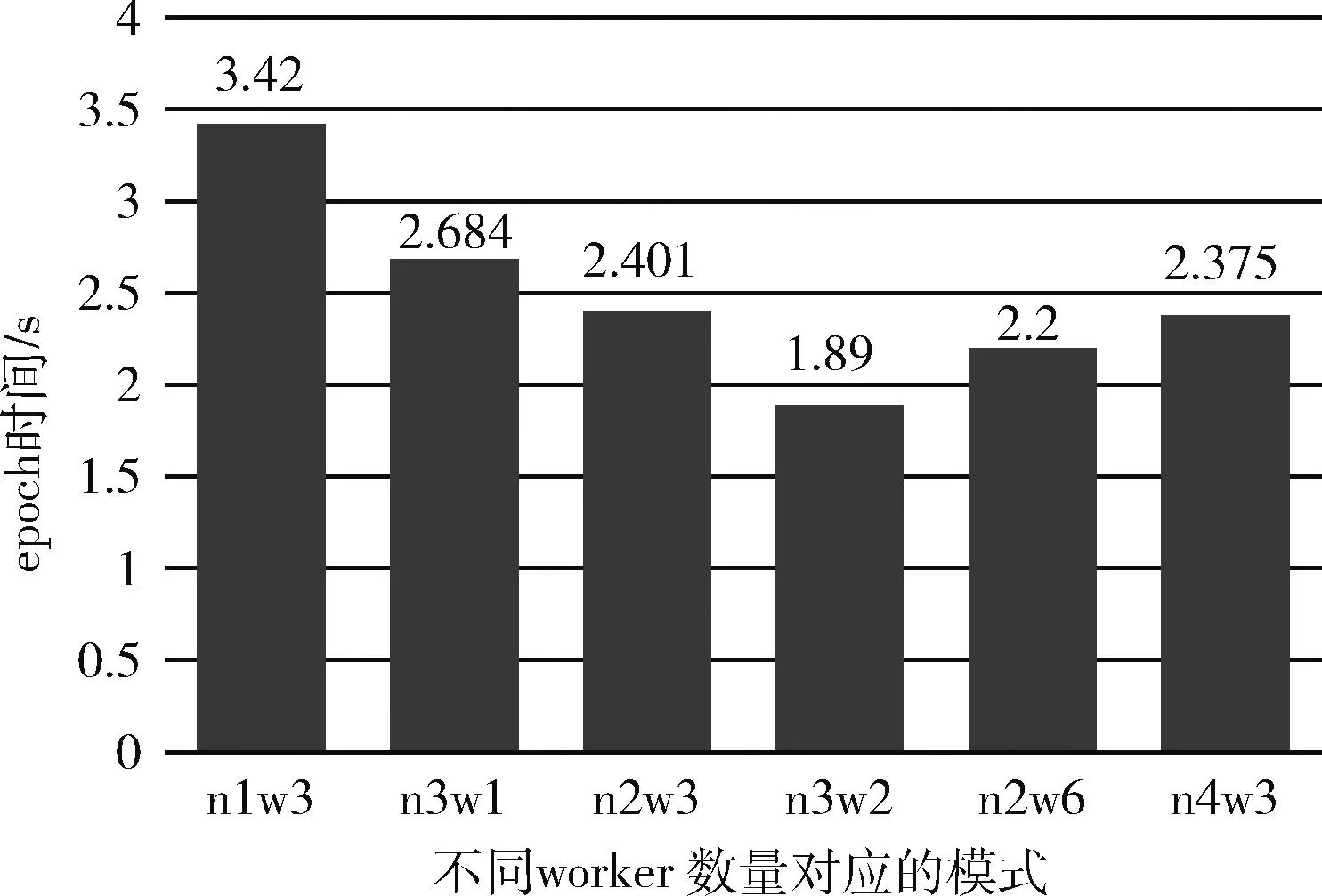
图12 不同worker_per_node数目之单个epoch时间对比

图13 不同worker_per_node数目之总训练时间对比
3.4.4 实验四
对于每个训练节点,给予其不同数量的core资源,训练速度也会有提高。若分配给工作节点的core数量越高,即可运行的资源会更多,训练速度越快,但是达到一定数量情况下,由于不是所有的core会参与到训练中,所以训练速度会到达一个瓶颈就不再上升。图14为相同训练节点数的情况下分配资源不同的实验对比,其中C6表示6个core。

图14 不同core分配数量的单个epoch时间对比
3.5 交通路况可视化
为了可视化交通流的速度预测效果,从307个传感器中选取位于PaloAlto至Giltroy路段的26个作为研究对象,传感器在主干道路的分布如图15所示,若以一小时窗口大小的数据作为模型预测的输入,把窗口末尾5 min作为当前的时间,其部分传感器车速值分布如图15上所示,而未来15 min内传感器的速度预测值分布如图15下所示。

图15 当前速度值和未来15 min内的速度预测值分布
4 结束语
本文设计一种基于Flink流计算框架和大数据平台结合的实时交通流预测方法,并采用该方法对实际交通路段中的多个传感器产生的海量数据进行实时捕捉、存储和建模分析,实现了对该路段交通流的实时预测。探讨和比较了CM-LSTM、G-LSTM和大数据框架下RT-LSTM并行模式下模型训练效果。实验结果表明,在大数据框架下的多节点同时训练的横向并行模式,比起纵向并行模式(G-LSTM),横向并行模式训练速度大大提升,并且又能保持一定的预测精度。但并行的训练方式在数据集分布不均匀时,还是存在收敛速度慢和效果相差较大的风险,如何去把控数据集的分布问题、训练的并行度以及模型收敛问题是未来需要进一步探索的。
猜你喜欢
小资CHIC!ELEGANCE(2022年1期)2022-01-11
数学物理学报(2020年3期)2020-07-27
能源(2017年10期)2017-12-20
能源(2017年5期)2017-07-06
法大研究生(2017年1期)2017-04-10
西南交通大学学报(2016年3期)2016-06-15
中国工程咨询(2016年1期)2016-02-14
雷达与对抗(2015年3期)2015-12-09
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
数学年刊A辑(中文版)(2014年1期)2014-10-30
