
典型山区撂荒耕地精准识别及驱动机制研究
2024-02-20 00:00:00程钰颖陈文波来洒洒
中国土地科学 2024年12期



关键词:撂荒耕地;影响机理;驱动机制;随机森林;系统动力学模型
耕地作为人类生存、发展与繁荣的基础,肩负着维护生态平衡、确保粮食自给自足、驱动经济增长及维系社会稳定的多重使命。然而,在城镇化与工业化的推动下,城市扩张,人口激增,对土地资源的需求急剧上升,为耕地资源的可持续利用带来了前所未有的挑战,加强耕地保护成为了刻不容缓的时代课题[1]。中共二十大报告指出,必须全方位夯实粮食安全根基,坚守十八亿亩耕地红线[2]。为夯实粮食安全基础,不断提高土地利用率,各地大力整治耕地撂荒,但由于各种原因,耕地撂荒现象依然存在[3]。精准且迅速地获取撂荒耕地的信息,识别长期撂荒耕地,探讨其成因与驱动机制,是耕地撂荒治理需要解决的基础性问题[4]。
精准识别撂荒耕地是研究驱动机制的前提,对于制定耕地保护相关政策至关重要[5]。目前,国内研究多依赖传统调查手段收集撂荒耕地信息,相较之下,利用遥感影像技术进行数据获取的研究较为缺乏,且传统的目视解译和数理统计分类方法效率低下[6]。为了突破这一瓶颈,需要创新遥感技术与算法。马尚杰等[7]利用遥感图像抽样统计计算小地物扣除系数,评估霍邱县冬季耕地撂荒情况,此方法过于依赖于卫星影像的分辨率和质量,识别精度和效率都有待提高。韦中晖等[8]分析了耕地各种覆盖类型的NDVI季相变化规律,并构建多时相协同变化检测模型,对鹿泉区的耕地撂荒状态进行了识别,但识别过程中只采用了NDVI一个综合信息变量,难以保证识别精度。1997年MITCHELL[9]提出了机器学习算法,这一算法通过计算机不断学习积累经验,提升处理效率与性能。近年来,凭借其强大的自适应和自学习的并行信息处理能力,在遥感影像分类研究中得到广泛应用[10]。其中人工神经网络、决策树、支持向量机和随机森林等方法在多项研究中展现出优秀的分类性能,成为研究者们关注的焦点[11],并被用于撂荒耕地识别。如ALCANTARA等[12]通过TIMESAT时间序列分析工具得到不同物候的指标,在此基础上采用支持向量机算法进行分类,实现了中欧和东欧撂荒耕地的识别。丘陵和山区受土地贫瘠、地形陡峭、农业基础设施薄弱、地理位置偏远等影响,耕地撂荒现象较严重[13]。对于气候复杂,地块破碎、图像视觉特征模糊的山区,由于难以满足其监测需求,相关研究成果较为缺乏[14]。谷晓天等[15]利用Landsat8OLI影像数据和DEM数据,对人工神经网络、决策树、支持向量机和随机森林4种机器学习方法的分类效果进行对比。研究显示,随机森林方法在分类精度和处理效率上具有显著优势,适用于复杂地形区土地利用信息高效提取。
耕地撂荒是自然、社会、制度等多方面因素的作用结果,是土地利用和土地覆被变化的重要研究议题,研究撂荒耕地的驱动机制对于理解土地资源的合理利用、保障粮食安全和推动农业可持续发展具有重要意义[16]。国内外对耕地撂荒影响因素和驱动机制的研究大多基于Logistic回归模型和Tobit回归模型。田玉军等[17]通过二分类Logistic回归模型分析了宁夏南部山区农业劳动力析出对耕地撂荒的影响;PRISHCHEPOV等[18]通过Logistic回归模型发现苏联解体造成社会制度变化会导致耕地撂荒面积增加,龙明顺等[19]运用二元Logistic和Tobit回归模型分析山区耕地细碎化对农户放弃耕作行为的影响,谢花林等[20]运用Tobit和Logic模型,分析兴国县不同代际农户对耕地撂荒行为的影响。由于耕地撂荒影响因素十分庞杂,而Logistic和Tobit回归模型能考虑的变量有限,难以揭示影响机制。而系统动力学模型通过系统内部的反馈循环和因果链,能够综合考虑多种因素及其相互影响关系,有助于更全面的理解撂荒耕地的动态演变和机制[21]。
本文选取典型山地区江西省芦溪县为研究区域,运用随机森林法精准识别地类,进而识别撂荒耕地;通过构建撂荒耕地的系统动力学模型,探析撂荒耕地系统中不同影响因素,揭示驱动机制。本文不但可为撂荒耕地的快速精准识别提供方法参考,也可为耕地保护和粮食安全政策保障提供决策参考。
1研究区及数据源
1.1研究区概况
芦溪县隶属江西省萍乡市,位于江西省西部、萍乡市东部,介于东经113°49′~114°16′,北纬27°24′~27°46′,属亚热带湿润性季风气候,气候温和,光照充足,四季较为分明。海拔63~1912m,全域土地面积为961km2,主要的土地利用类型为林地和耕地,耕地主要分布在西北部,呈现条带状。芦溪县地形以丘陵为主,地势从西北向东南逐渐升高,南部的武功山脉构成一道自然屏障。复杂的山地地形和丘陵地貌限制了芦溪县农业机械化的发展,增加了耕作难度,加之近年来围绕武功山的旅游业迅猛发展,第三产业逐渐成为芦溪县经济发展的重要推力,耕地撂荒现象比较普遍,具有典型性和代表性。
1.2数据及预处理
考虑到不同季节的遥感影像能够捕捉耕地利用状况的季节性变化,对于识别撂荒耕地至关重要[22]。本文选取芦溪县无云、质量良好且不同季节的遥感影像,包括2013年10月12日、2014年2月1日、2015年10月18日、2016年12月6日的Landsat卫星影像、2017年2月14日、2018年10月12日、2019年9月22日、2020年5月19日、2021年9月21日、2022年9月6日和2023年10月16日的Sentinel-2A卫星影像。社会经济数据来源于2015—2023年江西省统计年鉴和芦溪县国民经济和社会发展统计公报,并通过线性插值法填补空缺数据,该方法通过假设两个已知数据点之间的变化是线性的来估算中间未知点的值,在统计学中有广泛应用[23]。
2研究方法
本文根据研究目标确定地物分类体系,分析不同地类的影像特征,构建初选特征因子集,运用随机森林特征优选算法进行特征优选。以此为基础,构建研究区训练样本集,运用随机森林分类方法得到2013—2023年各年土地利用分类,采用混淆矩阵法对分类结果进行精度验证。接着,通过对比分类结果提取出研究时段内撂荒耕地的时空分布信息。最后,使用系统动力学模型分析耕地撂荒驱动机制。
2.1随机森林法
2.1.1土地利用特征因子集构建
提升分类精度的关键在于合理地选取多样化的特征因子[24]。本文选取具有明显统计差异,能够有效区分不同地类的特征作为识别地类的特征因子,包括光谱特征、形状特征、植被特征和纹理特征。(1)光谱特征因子:影像光谱特征作为地物判读和分类的物理基础,是识别地类的直接依据[25]。因此,本文选取蓝、绿、红、近红外波段作为初选光谱特征因子。(2)形状特征因子:不同地类的形状特征不同,可以辅助识别地类,耕地斑块轮廓通常接近于矩形,边缘线条流畅清晰,而自然植被、小型集水区等形状更为复杂多变[26]。因此,本文选取长宽比和形状指数作为初选形状特征因子。(3)植被特征因子:植被特征能够较为直观地反映出自然植被与农作物物候特征的差异,是地物分类的关键参考指标[27]。因此,本文选择了归一化植被指数(NDVI)、比值植被指数(RVI)、差值植被指数(DVI)、土壤调节植被指数(SAVI)、增强型植被指数(EVI)、绿度植被指数(GNDVI)作为初选植被特征因子。(4)纹理特征因子:纹理特征可以充分利用遥感影像的高空间分辨率捕捉地物表面的结构和模式,提高对地物复杂性和多样性的识别能力[28]。灰度共生矩阵(GLCM)方法是一种广泛使用的描述影像纹理特征的方法,有助于解决影像“同物异谱”和“异物同谱”现象[29]。因此,本文选择对比度、相关性、熵、同质性作为初选纹理特征(表1)。
本文利用随机森林算法计算所有特征变量的重要性和贡献度,结果如图1。
按照初选特征因子重要性程度由高至低依次将特征输入至随机森林模型中,结果见图2。随着特征数量的增加,分类精度逐步提高,至14个特征时达到顶点。
特征数量不足时,分类精度较低,而数量过多时会增加运行成本[30]。进一步分析发现,当输入模型的特征数量从10增加至14时,分类精度虽有所提升,但幅度不大,而运行时间却随着特征数量的增加显著增长。综合分析可知,当输入特征数量为10时,模型在保持较高分类精度的同时,也实现了高效益。基于此,对特征因子进行精简可得撂荒耕地优选特征为NDVI、MSAVI、RVI、EVI、蓝波段、红波段、GNDVI、绿波段、DVI和对比度。
2.1.2地物分类
由LEOBREIMAN于2001年提出的随机森林分类算法,运用集成学习的思想,将多个决策树组合为一个复合模型,是一个以决策树为基本单元的高效分类方法[31]。当输入训练样本时,每棵树独立地对输入的样本进行分类,最终通过多数投票的方式,选择得票最多的类别作为预测结果;在构建每棵树的过程中,约1/3的数据不会被用于训练,这些数据称为袋外数据,可以用来评估模型的准确性。与单棵决策树相比,随机森林具有更好的泛化能力,能够减少过拟合的风险,即使在样本量较小的情况下也能保持稳定性,并且易于实现,分类效果通常较好,在识别地类时具有明显的优势[32]。
2.1.3精度验证
混淆矩阵是评估分类结果精度的指标[33]。本文构建验证集样本的真实类别与预测类别的混淆矩阵,通过计算总体精度(OA)、Kappa系数(K)、精确度(P)、召回率(R)、F1分数,度量模型的效果。
OA是指在遥感图像解译或分类中,分类结果与真实情况一致的比例,其值越接近1,模型的整体表现越好[34];P是指模型预测为正类中实际为正类的比例;R是指模型成功识别出的正类样本占所有实际正类样本的比例;F1分数是精确度和召回率的平衡指标,F1分数越接近1表示模型在平衡准确率和召回率方面表现越好[35]。计算如式(1)—式(4)。
2.2系统动力学模型
系统动力学是1958年J·W·FORRESTER教授提出的系统仿真方法。这是一种基于系统思维的计算机模拟方法,它将自然科学中的系统论、控制论、信息论等理论与经济学相结合,通过信息反馈的概念来分析社会经济系统,不仅能分析研究信息反馈系统,也有助于认识并解决系统问题[21]。
本文模拟在保护十八亿亩耕地红线的背景下,假设前提为不考虑重大耕地政策的影响,空间边界为芦溪县,基期年为2015年,数据时段为2015—2023年,时间步长为1a,系统边界为人口子系统、气温子系统、经济子系统、生产条件子系统,系统内容主要包括影响耕地撂荒的各因素及其相互作用机制。根据系统结构、反馈机制以及反馈回路,采用表函数法和线性回归法等统计分析方法确定模型参数值,构建相关方程,绘制存量流量图。运用Vensim软件,不断调整修正,使模拟结果接近芦溪县撂荒耕地现状,并进行灵敏度验证,计算公式为:
式(7)中:S为输出变量Y对变化参数X的灵敏度;DX和DY为t时间内X和Y因参数调整而产生的变化值。当S(t)<1时,表明该参数为非敏感性因子;当S(t)≥1时,表明该参数为敏感性因子。
3结果与分析
3.1土地利用分类结果及精度验证
本文采用优选出的特征组合,结合研究区的实际情况,将土地利用类型分为耕地、林地、裸地、建筑用地和水域5类,选取空间上均匀分布的图斑作为训练样本,并根据各地类的面积比例确定训练样本数量,建立训练样本库。本文选取芦溪县的训练样本面积分别为耕地22.87km2,林地103.07km2,裸地12.36km2,建筑用地15.13km2,水域3.24km2,其中验证样本占训练样本的17.65%。
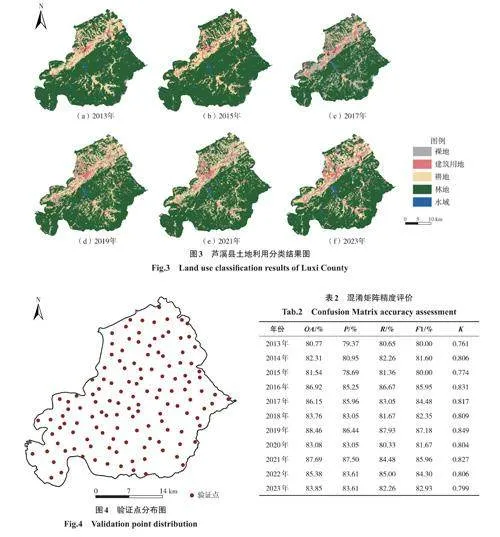
运用随机森林分类方法得到研究区2013—2023年各年土地利用分类结果(图3)。
从图3中可以看出,试验区土地利用类型以林地和耕地为主,两者合计约占总面积的80%;建筑用地约占试验区总面积的7%左右,其分布总体分散、相对集中,随时间呈扩张趋势。
为确保分类的可靠性,对结果进行精度检验。在研究区内选择均匀分布的130个验证样本点(图4)。通过目视解译确定这些图斑的地类,利用混淆矩阵计算总体分类精度、精确度、召回率、F1分数和Kappa系数(表2),总体分类精度介于80.77%~88.46%,精确度介于78.69%~87.50%,召回率介于80.33%~86.67%,F1分数介于80.00%~87.18%,Kappa系数介于0.761~0.849。
3.2撂荒耕地识别
本文采用2011年土地整理与土地储备国际研讨会所确立的标准,将连续两年及以上未耕作的耕地定义为撂荒耕地[37]。基于2013年的土地分类结果,识别出转为裸地或林地的耕地,并利用土地报批数据剔除非农化转用的耕地,将此耕地归类为“休耕/撂荒”状态;然后,根据时间尺度进一步判断,若“休耕/撂荒”状态的持续时间大于等于两年,则判定此耕地为撂荒,反之则判定为休耕。同时以2015年芦溪县的撂荒耕地图层为基准,提取撂荒时间长度的耕地信息。
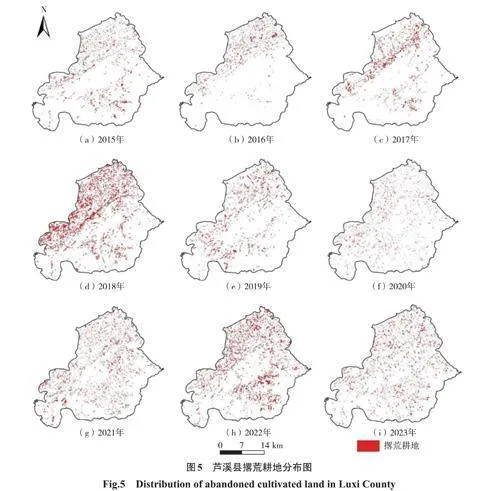
得到2015—2023年芦溪县的撂荒耕地面积依次为31.02km2、20.13km2、34.98km2、98.21km2、35.85km2、21.54km2、48.38km2、74.94km2、40.87km2,其空间分布如图5。整体来看,这段时间内撂荒耕地面积没有呈现出稳定的上升或下降趋势,而是经历多次波动,在2018年撂荒耕地面积达到最高,为98.21km2。2016年撂荒耕地面积最少,为21.54km2。从空间上看,撂荒耕地主要分布在芦溪县西北部和新泉乡,呈现碎小分散的图斑。
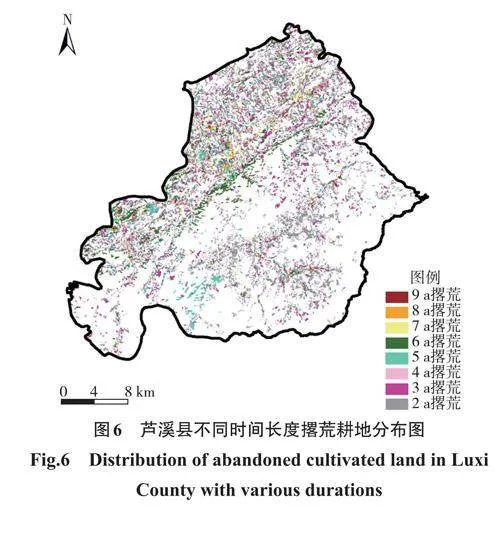
统计不同撂荒时间长度的撂荒耕地面积,如图6。2015—2023年共有224.41km2土地发生过撂荒。撂荒时间长度为2a的耕地面积最大,为88.83km2,占总撂荒面积的39.58%,主要集中在南部新泉乡附近,其次是撂荒时间长度为3a和5a的耕地,撂荒面积为49.30km2和32.29km2,占总撂荒面积的21.87%和14.39%,分别分布在芦溪县的西北部和南坑镇、张佳坊乡,撂荒总时间长度为9a的耕地面积为3.36km2,占总撂荒面积的1.48%,主要分布在芦溪县西北部。由此可见,长期撂荒多发生于芦溪县西北部,而新泉乡的土地撂荒时长较短。
3.3撂荒耕地影响机制分析
3.3.1撂荒影响因素分析
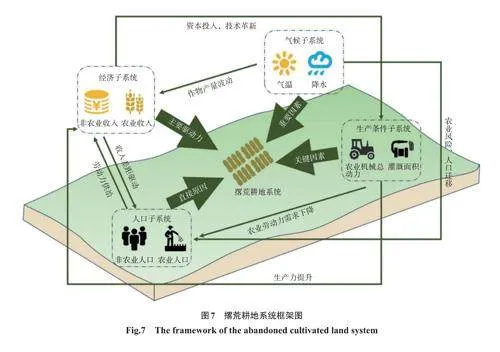
社会经济要素变化是撂荒的主要驱动力,耕地撂荒基本都可归结为宏观经济层面的变化[37];劳动力析出是撂荒的直接原因,劳动力在持续析出过程中农户无暇顾及所有土地,最终部分土地被撂荒[38];生产条件是撂荒的关键因素,农田基础设施条件改善和机械化发展提高了农业产出效率,减少了对耕地的需求,导致部分耕地因缺乏经济动力而被撂荒[13];气候因素是撂荒的重要因素,极端气候和不稳定的降水模式会导致农作物产量波动,增加农业生产风险,从而减少耕地的经济吸引力[39]。
这些子系统并非孤立存在,而是通过相互作用和协同,形成一个有机的整体。(1)随着城镇化、工业化进程的发展,我国农村人口数量呈现逐渐减少的趋势[17],同时,第二、第三产业尤其是近年来芦溪县旅游业的飞速发展,使得城乡收入差距扩大,促使农村农业劳动力流出,导致一些质量较低的耕地被撂荒。(2)农民的收入主要来源于农业和非农业两个渠道。一方面,若外出务工成为农民的主要收入来源,农民更倾向于离开农村去城市工作;另一方面,化肥和农药价格等农业成本的上升以及自然灾害的发生,导致耕地的收益降低,促使部分农民放弃耕作。(3)经济水平提高带来了农业技术提高,而农业技术的进步允许人们在更少的土地上实现更高的粮食产量,减少对劳动力的需求,增加了耕地撂荒的风险。(4)气候变化可能导致农业生产条件恶化,影响粮食产量和农民收入,导致农业劳动力减少,从而增加耕地撂荒的风险。
撂荒影响因素系统的构成以及主要作用机制如图7。
3.3.2耕地撂荒机制模拟
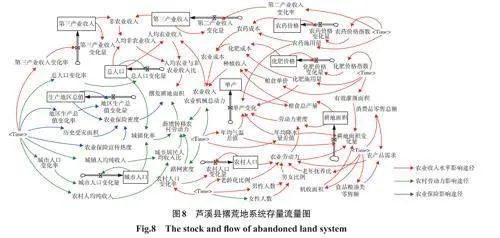
存量流量图是系统动力学中的一个核心概念,能够将系统的结构和行为可视化,清晰地展示了系统中的“存量”和“流量”的关系,识别系统中的反馈回路,为理解复杂系统的行为提供了一种结构化的方法[40]。通过对系统框架图的适当拓展与延伸,得到了撂荒耕地的存量流量图,如图8。
限于篇幅,列出部分主要模型系统方程:
(1)农业保险密度=10.539+0.072×地区生产总值+0.658×历史受灾面积+0.52×农业保险宣传热度。
(2)粮食单产变化量=17265.9-18.826×农药施用量-23.748×劳动力密度-0.561×化肥施用量+480.511×年均气温差值+0.476×年均降水量差值。
(3)种植收入=粮食单价×粮食总产量。
(4)耕地面积变化量=75.884+0.0014×农业劳动力-49.596×年均气温差值-0.238×年均降水量差值-6.003×有效灌溉面积+2.074×机收面积。
(5)耕地面积=INTEG(耕地面积变化量,141.22)。
(6)农业劳动力=2.23+0.039×老龄化比例+1.289×男女比例-0.297×老年抚养比+0.074×农村人口+43.887×农产品需求-2.653×农业机械总动力。
(7)新增转移劳动力=-7318.74+3851.59×城乡居民人均收入比+5033.11×城镇化率+756.624×路网密度。
(8)撂荒耕地面积=272.255-4.644×农业保险密度+0.014×新增转移农村劳动力-8855.18×人均农业与非农业收入比。
为确保模型能够准确地反映系统的行为模式,对模型进行历史仿真检验。选取2015—2023年具有代表性的农业保险密度、耕地面积、粮食产量和撂荒耕地面积作为检验的变量。研究认为历史性检验误差在-10%~10%都是合理的[41],可以说明模型模拟结果的准确性。各变量的历史性检验误差范围在-8.25%~8.95%(表3),说明本文建立的撂荒耕地的系统模型具有较高的合理性,能够较好地模拟耕地撂荒过程。
从模型中选取11个关键参数进行灵敏度分析,将每个参数逐年增加和减少10%,计算得到2015—2023年各参数的灵敏度值,再求其平均值,得到11个变量的平均灵敏度(表4)。除城乡居民人均收入比和老龄化比例2个指标的灵敏度较高外,其余指标的灵敏度均小于0.1,说明这些参数的变化对于系统的影响非常小,并且11个参数灵敏度均小于1,表明构建的系统动力学模型具有可靠性和稳定性,能够满足建模要求[42]。
根据模拟结果,将影响因素转化为三条途径:
(1)农业收入水平影响途径。农业劳动力受人口结构和农产品市场的共同影响,一般而言,老龄化程度越严重、男性劳动力比重越低,抚养比越高,农业劳动力数量越少[43],而社会对农产品需求的增加会激励更多劳动力投入农业生产,反之则会使农业劳动力过剩,进而减少农业从业者数量。农业劳动力,结合当地的气候环境和生产条件,对耕地规模起着关键性作用。耕地提供种植空间,劳动力密度影响劳动效率,气候决定作物生长环境,化肥和农药的使用直接关系到作物的健康生长,4者共同决定了农业产量。耕种收益的高低和耕作成本的多少决定农民的农业收入,农业收入与非农业收入的比是影响耕地是否撂荒的关键经济因素,如果农业与非农业收入比过低,意味着从事农业的收益远低于其他行业,降低农民耕种土地的积极性,农民可能会减少耕种面积甚至放弃耕种。
(2)农村劳动力影响途径。社会经济结构和基础设施建设水平是影响新增转移农村劳动力的重要因素。城镇化率的提高通常意味着更多的就业机会和更高的收入潜力,促使农村劳动力向城市转移;城乡居民人均收入比反映了城乡之间经济水平的差异,若这一比例过高,会吸引更多的农村人口向城市迁移以寻求更高的收入;农业机械总动力的提升意味着对人力的依赖减少,促使更多农村劳动力转向其他行业或地区寻找就业机会;交通条件的改善降低了农村与城市的交通距离和成本,为劳动力转移提供了便利。4个因素相互作用,共同推动了农村人口向城市迁移。随着新增转移农村劳动力的增加,农业生产中的劳动力减少,部分耕地因此被闲置,增加了撂荒现象。
(3)农业保险影响途径。农业保险的覆盖率受宏观经济规模、历史自然灾害发生频率以及宣传强度的共同影响。地区生产总值是衡量经济实力和居民收入的关键指标,它决定了居民对农业保险的购买力,影响农业保险的密度;自然灾害频发会增加农业生产的不确定性和风险,农民为保障生计,更倾向于购买农业保险来分散这些风险;农业保险的宣传是提升公众对保险重要性认知的关键环节,一旦农民对其价值及风险保障功能有了充分的了解,他们将更倾向于选择投保,从而提升保险产品的购买率。农业保险能够有效缓解了自然灾害和市场波动等不可预见因素对农民造成的经济损失,降低了他们因高风险而放弃耕作的意愿,减少了耕地撂荒。
4结论和讨论
4.1结论
本文以2015—2023年的芦溪县为研究对象,利用随机森林识别地类,在此基础上提取撂荒耕地信息,并构建芦溪县撂荒耕地系统动力学模型,模拟人口、经济、农业生产能力以及耕地撂荒之间的相互作用,主要结论如下:
(1)利用随机森林算法对特征因子进行优化选择,并识别土地利用类型的方法,该方法的总体精度范围在80.77%~88.46%,精确度在78.69%~87.50%,召回率在80.33%~86.67%,F1分数在80.00%~87.18%,Kappa系数在0.761~0.849,表明其在实际应用中具有较高的可靠性和准确性,提升了耕地撂荒识别的效率和效果。
(2)2015—2023年,芦溪县撂荒耕地面积呈现出明显的波动性,2018年撂荒面积最大,达98.21km2,2016年年撂荒面积最小,为20.13km2,从空间角度来看,研究区的撂荒耕地地块破碎,主要集中在芦溪县西北部和新泉乡,从时间角度来看,在新泉乡耕地多发生长时间的撂荒,西北部的耕地撂荒的时间相对较短。
(3)系统动力学模型对芦溪县2015—2023年的耕地变化过程的仿真结果显示,各变量的历史性检验误差范围在-8.25%~8.95%,除2个指标的灵敏度较高外,其余指标的灵敏度均小于0.1,具有较高的拟合精度。表明构建的系统动力学模型能够有效模拟耕地撂荒过程。
(4)耕地撂荒是经济、人口、生产条件和气候等多个变量共同影响的结果,这些因素形成了一个相互作用的系统,对撂荒耕地的影响主要总结为三个途径:农业收入水平影响途径,农业劳动力影响途径,农业保险影响途径。
4.2讨论
我国粮食需求量巨大而人均耕地占有量有限这一国情决定了耕地保护的极端重要性,快速、精准的识别撂荒耕地能够有效监控耕地撂荒,为制定农业政策提供重要的数据支持。现有技术在识别山区撂荒耕地时,常面临识别精度和时效性不足、特征选择以及多源数据融合难等挑战[10]。与已有识别撂荒耕地的方法比较[6-8],随机森林分类方法具有高精度和强鲁棒性[31],能够在撂荒耕地识别中表现出更优异的性能。本文通过随机森林分类方法识别典型山区芦溪县土地利用类型,取得了较高的精度,并在此基础上提取撂荒耕地,验证了其在撂荒耕地监测中的有效性和实用性。
当前,我国耕地保护面临新形势和新变化,需要正视国际复杂形势对耕地保护的影响,防止耕地撂荒。目前对耕地撂荒机制研究仍然存在不足,使用系统动力学模型能够通过构建系统反馈结构,综合考虑多种影响因素及其相互作用,模拟撂荒耕地的动态演变过程,提供更全面和深入的机制分析。基于此,本文在提取撂荒耕地信息的前提下,利用系统动力学模型模拟耕地撂荒机制,为理解耕地撂荒的复杂过程,指导土地资源的合理配置和制定政策提供科学依据。芦溪县作为一个地形复杂且近年来旅游业迅速崛起的山区县,耕地撂荒具有典型性代表性,研究结果可以为其他类似区域耕地保护提供参考。
本文构建的系统动力学模型提出的农业收入水平、农业劳动力和农业保险三个影响撂荒耕地的途径,与已有研究成果同中有异。孙晶晶等[44]、田玉军等[17]、张禹书等[45]分别证实了农业收入水平、农业劳动力和农业保险对撂荒耕地的影响。农业政策、自然地理条件对撂荒耕地的影响在不少研究中得到证实,本文限于农业政策难以量化进入模型,自然地理条件如高程、坡度等在模型时间步长内通常不会出现显著变化,故并未讨论二者对撂荒耕地的影响。此外,本文在识别撂荒耕地时政策上只考虑了耕地非农化,并未考虑生态退耕、农业产业结构调整(如耕地种植果树、苗木等行为)等其他非粮化行为的影响。鉴于国家采取了严格的政策措施坚决遏制耕地非粮化,其对研究结果的影响相对有限。
目前学术界对于撂荒耕地的定义尚未达成共识,除本文采用的定义外,还有“耕地闲置一年以上”“耕地荒芜一季或一季以上”等[46],内涵有较大差异。考虑到轮休制度的存在,将闲置时间少于两年的耕地定义为撂荒耕地可能带来误判,本文采用了“将连续两年及以上未耕作的耕地定义为撂荒耕地”的定义。对撂荒耕地的不同定义会导致识别时标准不一致,影响识别结果。在遥感数据方面,由于Sentinel-2A卫星数据在2016年以前不可获取,因此2015年和2016年的撂荒耕地识别采用Landsat卫星数据。Landsat卫星数据具有较长的重访周期和较低的空间分辨率,使得对耕地变化的监测不够及时和精确,影响当期撂荒耕地识别精度,但对2016—2023年的总体识别精度影响有限。
猜你喜欢
安徽农学通报(2017年1期)2017-02-15 17:49:06
软件(2016年7期)2017-02-07 15:54:01
广西民族研究(2016年5期)2017-02-06 01:24:43
现代管理科学(2017年2期)2017-01-24 20:35:26
南水北调与水利科技(2016年6期)2017-01-06 13:43:27
电脑知识与技术(2016年23期)2016-11-02 23:25:12
现代经济信息(2016年22期)2016-10-26 13:25:58
经营者(2016年12期)2016-10-21 09:44:43
商场现代化(2016年17期)2016-07-11 18:29:25
中国市场(2016年24期)2016-07-06 04:16:15
