
噪声指导下过滤光照风格实现低光照场景的语义分割
2024-02-18 18:46罗俊宣士斌刘家林
计算机应用研究 2024年1期
关键词:注意力机制
罗俊 宣士斌 刘家林
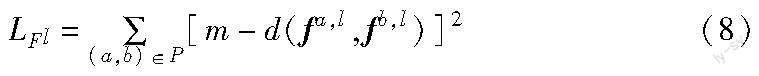
摘 要:低光照图像分割一直是图像分割的难点,低光照引起的低对比度和高模糊性使得这类图像分割比一般图像分割困难很多。为了提高低光照环境下语义分割的准确度,根据低光照图像自身特征,提出一种噪声指导下过滤光照风格的低光照场景语义分割模型(SFIS)。该模型综合利用信噪比作为先验知识,通过指导长距离分支中的自注意力操作、长/短距离分支的特征融合,对图像中不同噪声的区域采用不同距离的交互,并设计了一个光照过滤器,该模块从图像的整体风格中进一步提取光照风格信息。通过交替训练光照过滤器与语义分割模型,逐步减小不同光照条件之间的光照风格差距,从而使分割网络学习到光照不变特征。提出的模型在数据集LLRGBD上优于之前的工作,取得了较好的结果。在真实数据集LLRGBD-real上的mIoU达到66.8%,说明所提出的长短距离分支模块和光照过滤器模块能够有效提升模型在低光照环境下的语义分割能力。
关键词:语义分割;低光照;注意力机制;域自适应
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)01-050-0314-07
doi:10.19734/j.issn.1001-3695.2023.06.0285
Filtering illumination style under guidance of noise to achieve semantic segmentation of low-light scenes
Abstract:Low-light image segmentation is always the difficulty of image segmentation.The low contrast and high fuzziness caused by low light make this kind of image segmentation much more difficult than general image segmentation.In order to improve the accuracy of semantic segmentation in low light environment,this paper proposed a semantic segmentation model of low light scene with filtering light style under noise guidance (SFIS) according to the characteristics of low-light image.The model comprehensively used signal-to-noise ratio as prior knowledge,and adopted different distance interaction for different noise regions in the image by guiding the self-attention operation in the long distance branch and the feature fusion of long/short distance branches.This paper also further designed an illumination filter,which was a module that further extracted the illumination style information from the overall style of the image.By alternately training the illumination filter and the semantic segmentation model,the lighting style gap between different lighting conditions was gradually reduced,so that the segmentation network could learn illumination invariant features.The proposed model outperforms the previous work on the dataset LLRGBD and achieves the best results.The mIoU on the real dataset LLRGBD-real reaches 66.8%,it shows that the proposed long and short distance branch module and the illumination filter module can effectively improve the semantic segmentation ability of the model in low light environment.
Key words:semantic segmentation;low light;attention mechanism;domain adaptation
0 引言
語义分割作为计算机视觉中的一项重要分支,其目的是根据目标邻域特征,针对每个像素进行分类,最终得到一个具有像素级的语义标注图像。大多数网络模型主要是在良好的环境下提高精度,并没有考虑到不利的环境条件,比如过度曝光和曝光不足、噪声等导致的图像退化。现有的语义分割模型主要是在光照良好的白天图像上进行训练,由于网络模型受训练集分布的限制,往往对光照的变化不具有鲁棒性。低光照图像会产生较多噪声,而且对低光照图像的标注也较为困难,现有模型的性能主要受限于低曝光和缺乏真实标签。本文专注于低光照环境下的语义分割。
LISU模型[1] 先利用分解网络将低光照图像分解为光照分量和反射分量,然后利用联合学习网络同时学习恢复反射信息和分割反射图,最终实现低光照室内场景下的语义分割。付延年[2]提出了可见光与红外融合图像的语义分割方案,从而改善了夜间场景的分割精度。另一方面,针对低光照图像的恢复问题,大多数方法主要是利用神经网络学习操纵颜色、色调和对比度等来增强低光照图像,而最近的一些工作进一步考虑了低光照图像中的噪声。Liu等人[3]提出了RUAS模型,以Retinex理论为基础,建立了反映低光照图像内在曝光不足结构的模型。Xu等人[4] 提出了一种基于频率的低光照图像分解与增强模型。Xu等人[5]提出了利用噪声自适应地考虑低光照图像中的不同区域,以实现空间变化增强。但简单地将现有分割模型的前端加一个低光照增强网络,并不总能提高低光照图像分割网络的模型精度,而且还会带来更多的计算和内存消耗。
为了提高分割模型对光照变化的鲁棒性,也有许多域适应方法被提出,以使白天训练的模型适应夜间,而无须夜间域中的真实标签。在模型MGCDA[6]与DANNet[7]中应用图像迁移网络来风格化白天或夜间的图像并生成合成数据集,然而,风格迁移网络并不能充分利用分割任务的语义嵌入,也增加了推理时间。Dai等人[8]提出利用黄昏图像作为中间目标域,将白天场景上训练的语义模型渐进地适应夜间场景。这些方法不仅需要额外的训练数据,而且训练过程复杂[9]。Wang等人[10]提出了域自适应方法FADA,通过学习域不变特征来实现特征级自适应,将鉴别器与分割模型一起训练,以便鉴别器最大化源域和目标域之间的差异,而分割模型学习最小化差异。Isobe等人[11]提出了一个协作学习框架来实现无监督的多目标域适应,将所有其他域都转换为当前目标域的风格以进行进一步训练。张桂梅等人[12]提出SG-GAN方法对虚拟数据集GTA5进行预处理来代替原有数据集。Lee等人[13]提出了FIFO模型,将图像的雾条件视为其雾风格,学习雾不变特征的雾天场景分割模型。大多数现有的低光照语义分割模型往往忽略了高噪声区域对模型性能造成的不利影响。另一个存在的问题是,只有在理想情况下,风格才独立于其内容,如果直接更改图像的整体风格,会使图像的内容信息产生部分损失。
针对上述问题,本文提出了一种新的域自适应方法。因为低光照图像的不同区域中的特征差距较大,低信噪比区域的局部信息往往已经严重丢失,而高信噪比区域中仍然可以具有合理的特征信息,所以需要自适应地考虑低光照图像中的不同区域。为了实现这种长、短距离的自适应,本文在特征提取器中设计了两个分支操作,长、短距离分支分别基于Transformer结构[14]和卷积残差块[15],将信噪比图作为一种先验知识,从而指导这两个分支的特征融合。另一方面,为了减小图像内容信息上的损失,本文设计了一种可学习的光照过滤器,根据特征图所计算的Gram矩阵作为输入,尝试从图像的整体风格中进一步提取与光照风格相关的信息,学习将不同光照条件的信息区分开。语义分割模型在训练过程中缩小不同光照风格信息的差距,最终得到语义分割网络的光照不变特征。本文的贡献可以总结如下:a)在分割网络的浅层特征中设计了长、短距离分支来自适应地考虑低光照图像中的不同区域,并利用信噪比图进一步修改了自注意力操作;b)设计了一个光照过滤器,用于低光照图像的语义分割;c)提出了一种新的域自适应框架,在LLRGBD数据集上的实验表明,该框架优于现有方法,取得了最好的分割效果。
1 相关概念
1.1 低光照图像的语义分割
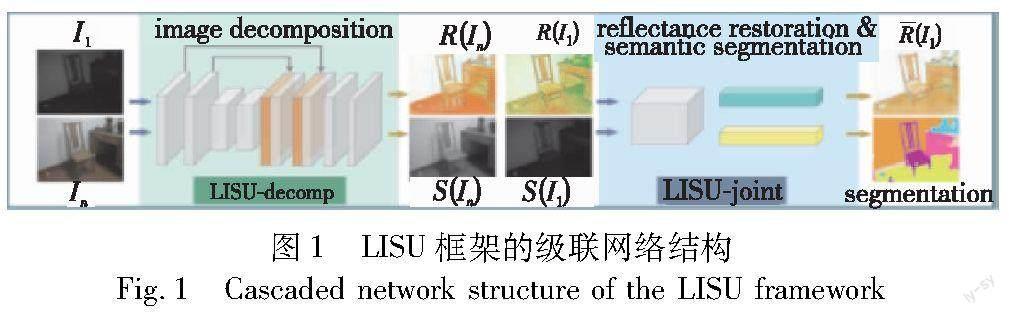
针对真实低光照室内场景的语义分割问题,Zhang等人[1]提出了一种级联框架LISU,用于弱光室内场景理解。根据Retinex理论研究了颜色恒常性,并进一步发展为解决图像的固有分解问题。如图1所示[1],框架由两部分组成:a)无监督分解网络LISU-decomp,将RGB图像分解为相应的光照图和粗反射图;b)编码器-解码器网络LISU-joint,以多任务方式学习反射图的恢复和语义分割。将来自两个任务的特征图融合在一起,以进行更紧密的联合学习。
采用级联结构的LISU网络模型,其语义分割结果严重依赖于分解网络的效果,而且同時学习恢复反射信息和分割反射图加重了特征提取器的负担。LISU也没有考虑到低光照环境下噪声的影响。图2[1]显示了LISU的错误实例,其中第一行是反光材料造成的白点,第二行显示了边界上的故障分割。(a)为输入的低照度图像;(b)为LISU-decomp输出的反射图;(c)和(d)分别为LISU-joint输出的恢复反射图和分割图;(e)是分割标签。红色矩形表示感兴趣的区域(参见电子版)。如图2所示,即使是LISU恢复后的反射图依然还有不小的噪声,而且由于光照不均匀,部分反射材料在局部图像中会引起过度曝光,此时图像部分的局部信息丢失严重。由于局部信息的失真,在可见度较低区域的边缘上甚至还可能出现分割故障。
1.2 风格迁移
风格迁移被用于研究图像内容以外的风格。文献[16]的研究表明,特征图所映射的Gram矩阵可以作为图像风格的表示,并能够通过近似对应的Gram矩阵将图像的风格迁移到另外一张图像上。Luan等人[17]提出的摄影风格转换的深度学习方法也进一步证明了Gram矩阵的有效性。李鑫等人[18]提出了一个内容语义和风格特征匹配一致的风格迁移网络。特征图的Gram矩阵记为G∈RApC×C,用来表示特征图C个通道之间的相关性。对于G中的每个元素Gi,j=aTiaj,表示第i个特征图通道与第j个特征图通道之间的相关性,其中ai与aj分别表示第i与第j个特征图通道的向量表示。分别计算基准图像和目标风格图像的特征图的Gram矩阵,以两个图像的Gram矩阵的差异最小化为优化目标,不断调整基准图像,使风格不断接近目标风格图像。
1.3 域自适应
域自适应方法是迁移学习的一种,通常用来解决不同领域数据分布不一致的问题。本文工作也与域自适应相关,因为两者都将模型适应于未标记的目标域。语义分割的域自适应方法可以根据执行自适应的级别进行分类,分为输入级别[19]、特征级别[10]和输出级别[20]。本文模型SFIS特别与学习域不变特征的特征级自适应有关。该类别中的大多数现有方法的主要目标是希望特征提取器针对源域和目标域数据集所提取的特征尽可能相近,鉴别器用于判断提取的特征属于哪个域,将鉴别器与分割模型一起训练,以便鉴别器最大化源域和目标域之间的差异,而分割模型学习最小化差异。SFIS与这些方法有类似的想法,但正如展示的那样,在SFIS中是通过缩小光照风格信息之间的差距来使特征提取器学习到光照不变特征。
2 噪声指导下过滤光照风格的低光照分割模型
本文模型基于域自适应方法,对图像中不同的噪声区域采用不同距离的信息交互,并通过光照过滤器从图像的整体风格中提取光照风格并学习区分它们。语义分割网络和光照过滤器模块会交替训练,最终使编码器学习到光照不变特征。
2.1 模型总体架构
现有的LISU模型并没有考虑到低光照环境下噪声的影响,由于光照不均匀,部分反射材料在局部图像中会引起过度曝光,此时图像部分的局部信息丢失严重。针对这类问题,本文引入了长短距离分支模块的方法,对图像中不同的噪声区域采用不同距离的信息交互,在高噪声区域采用长距离的自注意力操作,在低噪声区域采用短距离的卷积操作,从而避免高噪声区域带来的不利影响。
另一方面,由于LISU网络模型采用的是级联结构,其语义分割结果严重依赖于分解网络的效果,而且同时学习恢复反射信息和分割反射图加重了特征提取器的负担。本文基于域自适应方法,使语义分割网络最小化不同域间的风格差异。以往基于风格迁移的网络模型往往是直接对图像整体风格进行迁移,但图像的整体风格也会受到光照以外因素的影响,所以这种方式会导致部分的内容信息被更改。针对这个问题,本文采用将光照视为风格的方法,设计了一个光照过滤器来过滤大部分内容信息,从图像的整体风格中提取光照风格,从而减小风格迁移中图像内容信息上的损失。
SFIS模型主要包括语义分割网络中的长短距离分支模块和光照过滤器模块,其中,长、短距离分支分别基于Transformer结构和卷积残差块。如图3所示,上下两部分语义分割网络的权重参数共享,网络在训练阶段的输入数据为一对图像,低光照图像Ia与正常光照图像Ib。对于其中给定的一幅输入图像I∈RApH×W×3,本文首先计算图像I对应的信噪比图S∈RApH×W,将S作为掩码来遮蔽高噪声的区域块,从而指导长距离分支中自注意力的计算,还会作为权重来指导长、短距离分支的特征融合。将图像Ia与Ib分别输入上下两部分分割网络后,得到的第一层特征图会分别进入长距离分支和短距离分支。对于融合后的特征和其下一层特征(图3中的橙色虚线框,参见电子版),将计算这两层特征图的Gram矩阵表示图像的整体风格,并将其上三角部分的向量表示ua,l、ub,l作为光照过滤器Fl中第l层的输入,来提取光照风格信息fa,l、fb,l。光照过滤器学习将不同的光照风格信息区分开,而语义分割网络不断缩小不同光照风格信息的差距,分别对应图3中的LFl与Llfsm。光照过滤器模块和语义分割网络会交替進行训练,最终使其编码器学习到光照不变特征,在测试阶段只依靠语义分割网络。
2.2 长短距离分支
在低光照图像的不同区域中,噪声和可见度等特征差距较大,对于极暗区域,由于相邻的局部区域可见度较弱且多为噪声,局部信息不足以分割像素,而长距离中光照较好的区域中仍然可以有合理的特征信息。例如在图2的中下方极暗区域很难辨别出物体,但旁边的床头墙壁等特征信息有利于识别出该物体的类别。在图2中的过度曝光区域也是同理。所以需要自适应地考虑低光照图像中的不同区域,而Transformer结构通过全局自注意力机制能很好地捕获长距离的依赖关系,这在许多的高层级任务[21,22]和低层级任务[23,24]中都得到了证明。低光照图像中低信噪比的区域往往信息丢失严重,本文在信噪比低的区域中,利用长距离分支考虑长距离范围内的非局部图像信息进行交互;在信噪比较高区域中,利用短距离分支考虑短距离范围内的局部图像信息就足够了。信噪比也会作为权重,高噪声区域的权重将会降低,从而避免高噪声区域带来的不利影响。
如图4所示,首先需要根据式(1)计算输入图像I∈RApH×W×3的信噪比图S∈RApH×W,将其按照特征图F∈RAph×w×C的大小进行重新调整后得到S′∈RAph×w,进一步分解成块(与特征图F相同的分解方式)。然后根据式(2)利用阈值将得到的值视为掩码,遮蔽掉极低信噪比的块,从而根据式(4)利用信噪比图S′指导长距离分支中自注意力的计算,进一步根据式(6)指导长短距离分支的特征融合。在长距离分支中,需要将特征提取器得到的第一层特征图F分解成块。假设每一个块的大小为p×p,那么特征图F可以分解为m块,m=(h/p)×(w/p),即Fi∈RApp×p×C,i∈{1,…,m}。这些块将会被进一步拉平为一维向量,并被输入到Transformer进行自注意力的计算,由于自注意力计算中输出的块序列维度大小与输入序列的维度大小相同,所以将输出的序列重新拼接为特征图Fl∈RAph×w×C。对于短距离分支,采用的就是基本的残差块,其输出特征与输入特征的大小也会保持相同,即Fs∈RAph×w×C。特征图Fl,Fs则根据式(6)融合为特征图Fm。
2.2.1 信噪比图
如图4所示,网络模型需要先估计输入图像的信噪比图S。与以往传统的去噪方法[25,26]类似,本文将噪声视为空间域上相邻像素之间的不连续过渡。噪声分量可以建模为噪声图像与对应无噪声图像之间的距离。信噪比图像的具体计算方法如下:对于给定的一幅输入图像I∈RApH×W×3,首先计算图像I的对应灰度图,即Ig∈RApH×W,然后根据式(1)计算信噪比图S∈RApH×W。
其中:denoise代表传统的去噪方法,本文采用均值滤波;abs代表绝对值;N是估计的噪声图。
2.2.2 信噪比图指导自注意力
在原始的Transformer结构中,自注意力的计算是在所有块中进行的,所以不管图像区域的噪声水平如何,都会与之计算相应的注意力。但在低光照图像的不同区域中,特征差距较大,极低信噪比的区域往往已经被噪声严重污染,所以极低信噪比区域的信息是不准确的。本文用信噪比图来指导自注意力的计算。
图5显示了信噪比图指导自注意力的计算过程。给定一张输入图像I∈RApH×W×3,计算得到的对应信噪比图为S∈RApH×W。首先需要将信噪比图S重新调整大小S′∈RAph×w,从而使信噪比图能够与特征图F相匹配。然后同样地,按照分解特征图F的方式,将S′分解为m块,再计算每个块中信噪比的平均值,即Si∈RAp1,i∈{1,…,m},将这些值拼接为一个向量Sv∈RApm。向量Sv在Transformer的自注意力计算中主要起到掩码的作用,从而避免极低信噪比区域中噪声的影响。Si中第i个元素的掩码值为
其中:s是设置的阈值。然后将Sv复制m份,堆叠成一个矩阵S′v∈RApm×m。在自注意力计算最后的softmax部分,利用掩码将信噪比极低的块过滤掉。假设多头自注意力中的头数为B,那么Transformer中第i层中的第b个头自注意力的计算Attentionb可以表示为
将特征图F拆分得到的Fi∈RApp×p×C,i∈{1,…,m}打平成一维向量,LN为归一化层,通过式(5)即可得到q,k,v∈RApm×(p×p×C)。
q=k=v=LN([F1,…,Fm])(5)
2.2.3 信噪比图指导特征融合
对于长距离分支得到的特征图Fl∈RAph×w×C和短距离分支得到的特征图Fs∈RAph×w×C,本文将信噪比图作为一种先验知识,指导这两个分支的特征融合。对于重新调整大小的信噪比图S′∈RApH×W,进一步将其值归一化到[0,1],并将归一化后的S′作为权重来融合Fl和Fs。长距离分支与短距离分支特征图的融合可以通过式(6)计算。
Fm=Fs×S′+Fl×(1-S′)(6)
2.3 光照过滤器
Gram矩阵可以作为图像的风格表示已经在许多工作中得到了证实[16,17]。但只有在理想情况下,风格才独立于其内容,而图像的整体风格也会受到光照以外的因素甚至图像内容的影响,如果直接更改图像的整体风格,会使图像的内容信息产生一定程度的损失。低光照图像与正常光照图像的主要差别来自于光照,本文将光照视为风格,从整体风格中进一步提取光照风格信息,只对光照风格进行迁移修改,从而减小图像内容信息上的损失。值得注意的是,光照过滤器模块不是直接将特征图作为输入,而是将特征图的整体风格表示作为输入,通过过滤掉图像的大部分内容信息,更专注于图像的风格。这样,风格表示可以看做是编码本文先验知识的硬连线层[27]。
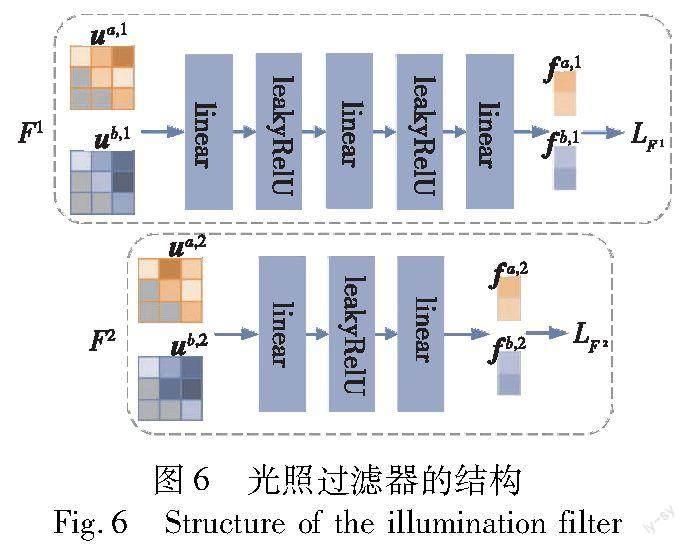
将特征图的Gram矩阵记为G∈RApC×C,用来表示特征图C个通道之间的相关性。对于G中的每个元素Gi,j=aTiaj,表示第i与第j个特征图通道之间的相关性,其中ai与aj分別表示第i与第j个特征图通道的向量表示。由于Gram矩阵是对称的,所以只需要将Gram矩阵的上三角部分的向量表示作为光照过滤器模块的输入。
如图6所示,光照过滤器中的两层模块由包含Leaky ReLU激活函数[28]的多层感知器实现。分割网络编码器对于低光照图像Ia与正常光照图Ib所提取的特征图(图3中的橙色虚线框),将对应层所计算的Gram矩阵的上三角部分的向量表示ua,l、ub,l作为该模块的输入,尝试从整体风格中进一步提取与光照相关的风格信息fa,l、fb,l。光照过滤器模块根据式(8)中的LFl损失学习将不同光照条件的风格信息区分开,而语义分割模型在训练过程中根据式(10)中的 Llfsm(fa,l,fb,l)损失缩小不同光照风格信息的差距,最终使语义分割网络的编码器学习到光照不变特征。
用Ia、Ib来表示小批量数据中的一对输入图像,Fl表示光照过滤器中第l层模块,ua,l、ub,l分别表示对应Gram矩阵上三角部分的向量表示,Gram矩阵是由输入图像的对应层特征图所计算得到的。那么对应图像的光照风格信息可以由式(7)得到。
fa,l=Fl(ua,l),fb,l=Fl(ub,l)(7)
光照过滤器的作用是通过得到的光照风格信息fa,l与fb,l,让分割网络了解到输入图像Ia、Ib在光照条件方面的不同。为此,光照过滤器会学习光照风格信息的映射空间,使不同光照条件的光照风格信息彼此远离。对于给定小批量数据中每个图像对的集合P,光照过滤器中每个层Fl的损失函数设计如下:
其中:m是超参数,代表边界;d(·)代表余弦距离。
2.4 分割网络损失函数
语义分割网络使用一对图像进行训练,包括一张低光照图像和一张正常光照图像,分别用于语义分割、光照不变性的学习和不同光照但同一场景下的一致性分割预测。
2.4.1 分割损失
对于语义分割的学习,本文采用像素级的交叉熵损失函数应用于单个图像。具体来说,分割损失由式(9)计算。
其中:pci表示预测的像素i属于类别c的概率;M是定义的类别集;n是像素的总个数。
2.4.2 光照风格匹配损失
对于给定小批量数据中的一个图像对,分割网络学习使光照风格信息之间的距离尽可能接近,从而使特征提取器学习到光照不变特征,所以光照风格损失与光照过滤器所得到的光照风格信息相匹配。分别用fa,l与fb,l来表示光照过滤器每个层Fl所得到的光照风格信息,那么光照风格损失可以通过以下损失进行计算:
其中:dl和nl分别代表光照风格信息的维数和特征提取器中第l层特征的空间大小。
2.4.3 一致性损失
同一场景下的低光照图像和正常光照图像之间有高度重叠的语义信息,所以对应语义分割的预测结果应当是尽量相同的,所以本文利用损失函数鼓励网络模型预测相同的分割图。用Pai∈RApc和Pbi∈RApc分别表示针对图像的每个像素i,分割网络所预测的类别概率向量,其中c为类别数。一致性损失强调所有像素Pai和Pbi的一致性,可以通过下面的损失函数来计算:
其中:KLdiv(·,·)代表KL散度。一致性损失与式(10)光照风格匹配损失具有相同的目标,但是在网络模型的预测层,通过更强制的手段学习光照不变特征,鼓励模型预测相同的分割图,更积极地对齐两种域。而且一致性损失与式(9)中的分割损失是彼此互补的,因为式(11)中的概率分布进一步提供了分割损失所使用的类标签之外的信息。
最终,分割网络的整体损失如下:
L=Lce+λfsmLlfsm+λconLcon(12)
其中:λfsm和λcon是用来平衡的超参数。
3 实验与结果
3.1 数据集
LLRGBD[1]是一个低光照室内场景数据集,由一个大规模合成数据集LLRGBD-synthetic和一个称为LLRGBD-real的小规模真实数据集组成,针对每一个图像对,还提供了相应的深度图。数据集LLRGBD包含室内场景的一对低光照和正常光图像,其中共有32个室内场景,真实标签共包括13个类别。合成的LLRGBD-synthetic数据集中总共包含了29 K×2张图像,图像分辨率为640×480,并按90%~10%的比例随机分为训练集和测试集。真实数据集LLRGBD-real中共包含515对640×480分辨率的低/正常光照图像,其中使用415对图像作为训练集,100对图像作为测试集。
3.2 实验细节
本文利用PyTorch[29]实现了网络模型的整体框架,并在具有Quadro RTX 8000 GPU的Linux系统上进行了训练和测试。在模型的训练阶段,将所有图像的大小调整为320×240,并且没有采用任何的数据增强。对于LLRGBD-synthetic数据集,模型训练50个epoch,在LLRGBD-real数据集上训练300个epoch。
为了避免光照过滤器冷启动,前100轮只训练光照过滤器,然后对于每个小批量的数据交替训练语义分割网络和光照过滤器。整体网络结构采用ResNet-101[15]为骨干网的RefineNet-lw[30]作为本文的分割网络,将两层特征图的Gram矩阵作为光照过滤器的输入,分割网络由SGD训练,动量为0.9,编码器的初始学习率为6E-4,解码器为6E-3,两个学习率都通过0.5次多项式衰减降低。两个光照过滤模块使用Adamax[31]进行训练,初始学习率分别为5E-4和1E-3,将光照风格信息的维度设置为64。超参数λfsm、λcon和m分别设置为5E-7、1E-4和0.1。
3.3 定量分析
表1、2分别在LLRGBD-synthetic和LLRGBD-real数据集上比较了本文模型和现有方法的定量结果。本文在LLRGBD-synthetic数据集上与SegNet[32]、U-Net[33]、LISU[1],还有域适应方法FIFO[13]和SePiCo[34]的分割精度进行了比较,进一步在LLRGBD-real数据集上还与DLv3p[35]和其变体DLv3p-joint的分割精度进行了比较。其变体DLv3p-joint采用LISU的改进策略,通过联合学习进一步恢复反射图,详细信息可以参考文献[1]。本文的主干网络为基于ResNet-101的RefineNet-lw。FIFO模型的主干网络采用的也是RefineNet-lw,对于SePiCo,本文采用的是 ResNet-101实现的DeepLab-V2作为主干网络SePiCo(DistCL)的对比模型。为了比较的公平性,对于FIFO模型,并没有进一步采用合成的低光照图像作为补充域。
如表1、2所示,本文方法在两个数据集上的性能都优于现有的模型。评估指标主要包括总体精度 (OA)、平均精度(mAcc)、平均交并比(mIoU)。LISU模型是当前LLRGBD数据集上性能最好的模型,由于SFIS采用的是域自适应方法,本文进一步比较了最新的两种域自适应模型FIFO和SePiCo。实验结果表明,在低光照环境下的图像上,SFIS优于之前的方法。相较于较好的域自适应方法FIFO,本文模型SFIS在LLRGBD-synthetic数据集上的mIoU提升了2.9%,在LLRGBD-real数据集上的mIoU提升了2.6%。这些提升很可能是由于SFIS进一步利用了低光照图像中的噪声信息。
本文还进一步与在合成数据集LLRGBD-synthetic上预训练的LISU模型进行了比较,最终在LLRGBD-real数据上的定量结果如表3所示。本文预训练的SFIS模型在真实数据集LLRGBD-real上的结果远优于LISU (pre-trained)模型,OA、mAcc和mIoU分别提升了10.1%、11.5%、14.6%。本文的预训练模型相较于原模型的mIoU提升了2.6%。
表4进一步列出了一些网络的详细定量比较,包括每个类别的IoU以及整体的mIoU,其中最好的结果用粗体显示。SFIS在墙壁、椅子、书籍等物体上的分割精度要明显优于其他模型。
3.4 定性结果
本节可视化了部分对比模型的语义分割结果,包括当前LLRGBD数据集上表现最好的模型LISU,以及域自適应方法中较好的模型FIFO。图7中显示了定性比较的结果,可视化了它们与本文方法的预测图。虽然在网络模型的推理阶段并不需要正常光照图像,但为了更好地可视化比较,图中依然显示它们。对于低光照图像中物体的语义分割效果,LISU模型的输出结果还是相对较差的,FIFO模型的输出结果相比前者来说更平滑一些,但在物体边缘部分的拟合效果还不够完善。SFIS的语义分割预测图在物体边缘部分,比如椅子、家具、杯子等较小物体的边缘,其拟合效果要明显优于前两个模型。
3.5 消融實验
通过从模型中删除不同的组件,考虑了几种消融设置。“ours w/o L”表示去掉了长距离分支,分割网络中只保留卷积操作;“ours w/o S”表示去掉了短距离分支,保留长距离分支和信噪比图指导的自注意力操作;“ours w/o A”表示去掉了信噪比图指导的自注意力操作;“ours w/o IF”表示去掉了光照过滤器,只用分割网络进行训练和测试。表5总结了相应消融结果,与所有的消融设置相比,完整框架设置在三个指标上都取得了最高分数。实验结果显示了信噪比图指导的自注意力操作、长短距离分支和光照过滤器的有效性。
4 结束语
本文针对室内低光照环境下的语义分割进行了研究,提出了一种新的解决方案。在低光照图像中,不同区域拥有不同的噪声,为了避免高噪声区域的影响,本文采用了两个不同距离的分支操作。利用信噪比图指导长/短距离分支的特征融合,进一步指导长距离分支中自注意力计算,只让高信噪比的区域参与自注意力计算。另一方面,提出了光照过滤模块,从图像的整体风格中进一步提取光照风格信息,通过减小不同光照风格信息之间的差距和分割损失来训练分割网络,从而使分割网络学习光照不变特征。实验表明,本文方法在低光照环境下取得了较好的分割效果。接下来,本文会在更多更具有代表性的数据集上进行测试,并调整网络模型,探索高噪声区域自注意力的计算方式。
参考文献:
[1]Zhang Ning,Nex F,Kerle N,et al.LISU:low-light indoor scene understanding with joint learning of reflectance restoration[J].ISPRS Journal of Photogrammetry and Remote Sensing,2022,183:470-481.
[2]付延年.面向自动驾驶的可见光和红外图像语义分割算法研究[D].杭州:浙江大学,2021.(Fu Yannian.Research on visible and infrared images semantic segmentation for autonomous vehicles[D].Hangzhou:Zhejiang University,2021.)
[3]Liu Risheng,Ma Long,Zhang Jiaao,et al.Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement [C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2021:10556-10565.
[4]Xu Ke,Yang Xin,Yin Baocai,et al.Learning to restore low-light images via decomposition-and-enhancement[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2020:2278-2287.
[5]Xu Xiaogang,Wang Ruixing,Fu C W,et al.SNR-aware low-light image enhancement [C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2022:17693-17703.
[6]Sakaridis C,Dai Dengxin,Van Gool L.Map-guided curriculum domain adaptation and uncertainty-aware evaluation for semantic nighttime image segmentation[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2020,44(6):3139-3153.
[7]Wu Xinyi,Wu Zhenyao,Guo Hao,et al.DANNet:a one-stage domain adaptation network for unsupervised nighttime semantic segmentation [C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2021:15764-15773.
[8]Dai Dengxin,Gool L V.Dark model adaptation:semantic image segmentation from daytime to nighttime[C]//Proc of the 21st International Conference on Intelligent Transportation Systems.Piscataway,NJ:IEEE Press,2018:3819-3824.
[9]Gao Huan,Guo Jichang,Wang Guoli,et al.Cross-domain correlation distillation for unsupervised domain adaptation in night time semantic segmentation[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2022:9903-9913.
[10]Wang Haoran,Shen Tong,Zhang Wei,et al.Classes matter:a fine-grained adversarial approach to cross-domain semantic segmentation[M]//Vedaldi A,Bischof H,Brox T,et al.Computer Vision.Cham:Springer,2020:642-659.
[11]Isobe T,Jia Xu,Chen Shuaijun,et al.Multi-target domain adaptation with collaborative consistency learning[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2021:8183-8192.
[12]张桂梅,潘国峰,刘建新.域自适应城市场景语义分割 [J].中国图像图形学报,2020,25(5):913-925.(Zhang Guimei,Pan Guofeng,Liu Jianxin.Domain adaptation for semantic segmentation based on adaption learning rate[J].Journal of Image and Gra-phics,2020,25(5):913-925.)
[13]Lee S,Son T,Kwak S.FIFO:learning fog-invariant features for foggy scene segmentation[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2022:18889-18899.
[14]Vaswani A,Shazeer N,Parmar N,et al.Attention is all you need[C]//Proc of the 31st International Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2017:6000-6010.
[15]He Kaiming,Zhang Xiangyu,Ren Shaoqing,et al.Deep residual lear-ning for image recognition[C]//Proc of IEEE Conference on Compu-ter Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2016:770-778.
[16]Gatys L A,Ecker A S,Bethge M.Image style transfer using convolutional neural networks[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2016:2414-2423.
[17]Luan Fujun,Paris S,Shechtman E,et al.Deep photo style transfer[C]//Proc of IEEE Conference on Computer Vision and Pattern Re-cognition.Piscataway,NJ:IEEE Press,2017:4990-4998.
[18]李鑫,普園媛,赵征鹏,等.内容语义和风格特征匹配一致的艺术风格迁移[J].图学学报,2023,44(4):699-709.(Li Xin,Pu Yuanyuan,Zhao Zhengpeng,et al.Content semantics and style features match consistent artistic style transfer[J].Journal of Graphics,2023,44(4):699-709.)
[19]Pizzati F,Charette R,Zaccaria M,et al.Domain bridge for unpaired image-to-image translation and unsupervised domain adaptation[C]//Proc of IEEE/CVF Winter Conference on Applications of Computer Vision.Piscataway,NJ:IEEE Press,2020:2990-2998.
[20]Luo Yawei,Zheng Liang,Guan Tao,et al.Taking a closer look at domain shift:category-level adversaries for semantics consistent domain adaptation[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2019:2507-2516.
[21]Han Kai,Wang Yunhe,Chen Hanting,et al.A survey on vision transformer[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2022,45(1):87-110.
[22]Khan S,Naseer M,Hayat M,et al.Transformers in vision:a survey[J].ACM Computing Surveys,2022,54(10):1-41.
[23]Chen Hanting,Wang Yunhe,Guo Tianyu,et al.Pre-trained image processing transformer[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2021:12299-12310.
[24]Wang Zhendong,Cun Xiaodong,Bao Jianmin,et al.Uformer:a general U-shaped transformer for image restoration[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2022:17662-17672.
[25]Buades A,Coll B,Morel J M.A non-local algorithm for image denoi-sing[C]//Proc of IEEE Computer Society Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2005:60-65.
[26]Dabov K,Foi A,Katkovnik V,et al.Image denoising with block-matching and 3D filtering[M]//Nasrabadi N M,Rizvi S A,Dougherty E R.Image processing:algorithms and systems,neural networks,and machine learning.[S.l.]:SPIE,2006:606414.
[27]Ji Shuiwang,Xu Wei,Yang Ming,et al.3D convolutional neural networks for human action recognition[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2012,35(1):221-231.
[28]Maas A L,Hannun A Y,Ng A Y.Rectifier nonlinearities improve neural network acoustic models[C/OL]//Proc of the 30th International Conference on Machine Learning.(2013).https://ai.stanford.edu/%7Eamaas/papers/relu_hybrid_icml2013_final.pdf.
[29]Paszke A,Gross S,Massa F,et al.PyTorch:an imperative style,high-performance deep learning library[C]//Proc of the 33rd International Conference on Neural Information Processing Systems.Red Hook,NY:Curran Associates Inc.,2019:article No.721.
[30]Nekrasov V,Shen Chunhua,Reid I.Light-weight RefineNet for real-time semantic segmentation [EB/OL].(2018-10-08).https://arxiv.org/abs/1810.03272.
[31]Kingma D P,Ba J.Adam:a method for stochastic optimization[EB/OL].(2017-01-30).https://arxiv.org/abs/1412.6980.
[32]Badrinarayanan V,Kendall A,Cipolla R.SegNet:a deep convolutional encoder-decoder architecture for image segmentation[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2017,39(12):2481-2495.
[33]Ronneberger O,Fischer P,Brox T.U-Net:convolutional networks for biomedical image segmentation[M]//Navab N,Hornegger J,Wells W,et al.Medical Image Computing and Computer-Assisted Intervention.Cham:Springer,2015:234-241.
[34]Xie Binhui,Li Shuang,Li Mingjia,et al.SePiCo:semantic-guided pixel contrast for domain adaptive semantic segmentation[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2023,45(7):9004-9021.
[35]Chen L C,Zhu Yukun,Papandreou G,et al.Encoder-decoder with atrous separable convolution for semantic image segmentation[C]//Proc of European Conference on Computer Vision.Berlin:Springer,2018:833-851.
猜你喜欢
计算机应用(2019年3期)2019-07-31
无线互联科技(2019年9期)2019-07-29
无线互联科技(2019年9期)2019-07-29
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
电子技术与软件工程(2019年5期)2019-06-20
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
