
基于ToF红外图像的手部轻量化检测算法设计与优化
2024-02-18 11:17葛晨阳马文彪屈渝立
计算机应用研究 2024年1期
关键词:深度学习
葛晨阳 马文彪 屈渝立

摘 要:嵌入式设备上实现快速精准的手部检测主要面临两个挑战:一是复杂的深度学习网络很难实现实时的手部检测;二是场景复杂性导致基于RGB彩色图像的手部检测算法准确率下降。与主流基于RGB图像的检测技术不同,基于ToF红外图像的轻量化手部检测算法实现了红外图像中手部的精准快速检测。首先,通过自主研发设备采集了22 419张静态红外图片,构建了用于手部检测的红外数据集;其次,通过对通用目标检测算法进行轻量化改进,设计了RetinaHand轻量化手部检测网络,其中采用了MobileNetV1和ShuffleNetV2两种不同的轻量化网络作为模型骨干网络,并提出了一种融合注意力机制的特征金字塔结构Attention-FPN;最后,在红外数据集上与常规方法进行了对比实验,验证了该方法的有效性。
关键词:深度学习; 手部检测; 红外图像; 嵌入式设备
中图分类号:TP391 文献标志码:A 文章编号:1001-3695(2024)01-047-0296-05
doi:10.19734/j.issn.1001-3695.2023.07.0278
Design and optimization of hand lightweight detection algorithm based on ToF infrared images
Abstract:Implementing fast and accurate hand detection on embedded devices mainly face two challenges. Firstly, it is difficult for complex deep learning networks to achieve real-time hand detection. Secondly, the complexity of the scene leads to a decrease in the accuracy of hand detection algorithms based on RGB color images. Unlike mainstream RGB image based detection technologies, this paper adopted a lightweight hand detection algorithm based on ToF infrared images to attain precise and swift hand detection within the infrared images. Firstly, this paper gathered 22 419 static infrared images using this self-engineered equipment, thereby establishing an infrared dataset tailored for hand detection. Subsequently, it enhanced a gene-ral object detection algorithm to create a lightweight hand detection network known as RetinaHand, using two different lightweight networks, MobileNetV1 and ShuffleNetV2, as the backbone network of the model. Furthermore, this paper proposed an attention-enhanced feature pyramid structure called Attention-FPN. This structure integrated attention mechanisms to enhance the detection process. Ultimately, this paper conducted comparative experiments on the infrared dataset against conventional methods to validate the effectiveness of the method.
Key words:deep learning; hand detection; infrared images; embedded devices
0 引言
動态手势作为现代社会人机交互的一种重要方式,在智能车、智能手机、生物医学、机器人等诸多应用领域均呈现了优异的性能[1~4]。作为手势识别的关键步骤,快速、准确的手部检测则是手势识别及分类的重要前提与保障。手部检测是在静态图像或者视频的单帧图像中检测出手部区域,并将其从原图裁剪出来,以用于下一步手部关键点检测[5]。目前基于视觉的手部检测方法多基于RGB彩色图进行分离,但它的弊端在于对光线敏感,例如在暗光环境下,基于RGB的手势操作将会陷入不可用状态或者面临识别准确率下降的问题[6]。而近红外摄像头拍摄的红外图像则可以弥补这一缺陷,尽管通常情况下成像质量不如RGB摄像头,但在各种极端场景下都具有较好的成像能力,非常有利于手部区域的识别和分离。因此研究红外图像的手部检测算法具有十分重要的理论和实际意义。
根据提取特征的方式不同,手部检测可以分为传统方法和基于深度学习的方法。早期的手部检测方法可以分为基于几何特征的方法、基于肤色分割和基于运动信息特征的方法。Utsumi等人[7]使用基于几何结构的手部统计检测方法来识别和跟踪多摄像头下的手部外观,实现了手部的定位,取得了一定的效果。肤色分割的方法利用了手部皮肤颜色与背景颜色不同的原理,利用该颜色差异实现手部轮廓的提取。Wu等人[8]提出一种动态的手部检测算法,利用自组织映射在HSV颜色空间上实现手部检测与分割。Wang等人[9]提出一种不需要分割,并且可以直接基于肤色的手部检测方法。Mittal等人[10]结合形状、皮肤颜色和运动场景信息来构建多级手部检测器,由于缺少强大的特征提取能力,该方法在无约束图像上表现较差。传统的手部检测方法虽然在一定环境下可以实现手部检测,但是精度不高,而且模型的泛化能力较差,无法提取图像中的隐藏特征,无法满足实际需求。
近年来,得益于计算机硬件和人工智能的快速发展,基于深度学习的手势识别算法及技术得到了长足发展。基于深度学习的手部检测技术既克服了传统方法不能充分提取图像特征的问题,又可以实现从端到端的训练,显著提升了手部检测的正确率和速度。2017年,Victor[11]提出了一种基于SSD网络[12]的实时手部检测网络,并在开源EgoHands数据集[13]上进行了测试,结果表明该方法能够实现准确的实时手部检测。2018年,Wang等人[14]提出了一种多尺度的Faster R-CNN方法,以Faster R-CNN[15]为基本框架对不同特征层进行特征融合,提取图像综合特征信息,实现手部的精准检测。2019年,Gao等人[5]提出了一种用于手部检测的深度CNN模型,将深度网络与浅层网络相结合,对SSD网络进行改进,实现了空间中的人机交互。随着MobileNetV1[16]、MobileNetV2[17]、ShuffleNetV2[18]等一系列轻量化网络的提出,通用目标检测网络模型得到了轻量化改进,在保证正确率的情况下模型的计算量也大幅下降。但随着处理数据的不断增多和应用领域智能程度的逐步提高,上述轻量化深度网络已远远不能满足应用场景的性能需求,因此急需发展基于红外图像的轻量级深度学习算法,从而进一步提高手部检测的性能。
针对上述问题,首先采集并构建了用于手势检测的ToF红外数据集,其次,借鉴人脸检测的RetinaFace框架[19],对其中的模块进行了改进和升级,设计实现了轻量化的RetinaHand手部检测算法。
1 轻量化红外图像手部检测算法
本章聚焦ToF相机的主动红外数据采集及相应的深度学习数据集构建。具体地,包括利用自有设备采集红外手部红外图像概况以及基于RetinaHand的手部检测算法。
1.1 ToF红外数据采集
红外图像相对于RGB图像的一个主要优势在于其不受环境光的影响,在各种极端情况下均能清晰成像。另一方面,相比于常规的被动红外图像,基于主动红外光源的图像更清晰,更有利于手部检测[20]。而目前开源的红外数据集较少,因此采集并构建用于深度学习的红外数据集势在必行。图1为所采用的高精度红外相机采集装置,由课题组自主研发,主要包括投射器、红外接收器和彩色摄像头三个组成模块。深度感知模块由投射器和红外接收器共同构成,将散斑图像编码后由投射器发出,红外接收器对经过反射的散斑图接收后解码测距,最终得到红外图和深度图。由于手部检测属于2D目标检测,不需要深度信息,所以只选取红外图来构造数据集。
采集数据在室内和车内两个环境下进行,包含15个不同的采集对象,年龄段分布在20~50岁。考虑多种因素:a)视野中是否有杂物,是否有多人干扰等;b)距离为30~120 cm均匀覆盖;c)采集对象相对摄像头的方位包括上、下、中、左、右;d)穿着短袖或长袖,手部是否佩戴手环、手表等饰物;e)除握拳、手掌、OK、打响指等规定的动作之外,额外加入了一些自由发挥的动作,如做数字六的动作;f)男和女、胖和瘦以及大小手。
1.2 RetinaHand手部检测算法
考虑到移动端的设备计算能力受限,并且要在保证手部检测准确率的情况下兼顾手部检测的速度。针对这一问题,设计了一种单阶段的基于锚框的轻量化手部检测算法RetinaHand,其网络结构如图2所示。
整个算法分为三步。第一步是先验锚框(anchor)的生成及其与目标框(ground truth,gt)的匹配。所有单阶段基于先验锚框的目标检测算法的基本原理可以概括为针对原图的密集采样后的分类和回归,生成锚框是必不可少的一步。锚框的几何意义是相对于原图而言,具体生成需要结合特征图来进行。RetinaHand模型保留三层特征图,每层特征图相对于原图的下采样比例分别是1/8、1/16和1/32。考虑到嵌入式手部檢测网络模型计算规模的局限性,所有的输入红外原图的大小设定为224×224,三层特征图的尺度分别为28×28,14×14,7×7,每一层特征图上的每一个像素点都分别对应了原图上8×8,16×16,32×32的一块区域。对于传统的Faster R-CNN、SSD,以及RetinaNet等算法来说,将会以特征图上的每一个像素点为基准,生成k个不同尺度和长宽比例的锚框,一般取k=9,表示3种不同尺度及宽高比例的锚框。由于构建的手部数据集本身就接近正方形,所以只考虑尺度而忽略宽高比,从而简化锚框的设计,同时在处理数据集的时候,会采取将短边补长的方式,将所有的标注都强制处理为正方形。
锚框的生成是对原图进行密集采样,进一步的工作是为每个样本构建用于监督学习的目标,包括确定目标框相对于锚框的位置以及各个锚框的类别。判断锚框是前景还是背景,若为前景,则需要确定其具体位置。位置是通过计算锚框相对于目标框的偏移来表示的。偏移分为目标框中心点相对于锚框中心点的偏移和目标框宽高相对于锚框宽高的比例转换两部分。需要注意的是,为了消除锚框本身尺度的影响,需要平等地对待所有的锚框。为此,对目标框相对于锚框的中心点位置和宽高进行归一化处理。通过归一化可以消除大锚框和小锚框对偏差的不同敏感度,从而有利于模型的训练学习。另外重要的一步是将目标框的宽高转换到对数空间,相对于锚框的宽高进行变换,目的是避免模型输出的宽高仅限于正值,从而降低了模型的要求和优化难度,通过转换到对数空间可以解决这个问题。
第二步是整个网络从输入到输出的映射过程,输入图像1×224×224首先经过一个由卷积层堆叠所构成的骨干网络进行特征提取,将网络中间各层的特征抽取出来送给接下来的FPN进行处理,这里总共抽取整个骨干网络的后三层特征,对于MobileNetV1×0.25作为骨干网络而言,三层特征图的尺度分别为64×28×28、128×14×14、256×7×7。
第三步是不同特征层的特征融合和最终回归预测。经过FPN特征融合后得到三层特征,每一层都会有大量的先验锚框。为了提高特征的表达能力,此时的特征图还会经过大卷积核构成的特征精炼模块进一步提取特征,扩大特征图的感受野。最后这些特征图分别经过目标框回归分支、置信度分类分支回归出最终的坐标和前景背景的概率。对于本任务而言,如果锚框的总数量为N,模型的分类分支的最终输出是2N,而坐标框回归分支的最终输出是4N,分别代表的是每一个锚框属于前、背景的概率以及如果属于前景,则目标框的中心点相对于锚框的偏置和目标框宽高相对于锚框的宽高的对数转换值。
具体地,在RetinaFace整体框架下,进一步考虑算法的轻量化以及在嵌入式设备中的运行,提出了如下改进:a)改用MobileNetV1-0.25和ShuffleNetV2-0.5两种轻量级网络作为骨干网络;b)改进了特征金字塔结构,设计并实现了一种融合注意力机制的特征金字塔(Attention-FPN);c)使用了不同的损失函数。
1.3 Attention-FPN
特征金字塔作为当前目标检测主流模型中的必备组件,可以有效地提高算法对不同尺度目标的定位能力。对于手部检测任务而言,因为实际场景中被拍摄对象相对摄像头的距离、方位不同而导致手部尺寸变化剧烈,离摄像头近的目标的像素最大可以到400×400,最远的目标大小只有20×20,这就要求目标检测网络对大小目标都有良好的检出能力。而传统FPN是通过将高层特征上采样和底层特征直接相加实现的,本文重新审视了FPN的工作原理以及实现方式,提出了一种融合了Attention思想的改进FPN。
受MobileViT[21]启发,扩展了自注意力机制并引入FPN模块,设计实现了一种融合注意力机制的特征金字塔结构Attention-FPN。图3展示了Attention-FPN的完整实现流程。
其中,query、key和value不再来自同一输入。query来自浅层特征图的非线性变换,而key和value来自经过上采样线性变换的深层特征图。使用注意力机制的融合代替了原始FPN中的逐元素加法操作,该操作可理解为使用深层特征图的加权和来表达浅层特征图中的每个像素,从而将全局信息引入浅层特征图。融合后的特征图同时保留了全局信息和局部信息,有利于模型学习。最后,再次使用自注意力机制对融合后的特征图进行变换,以提高特征的表达能力。相比于传统的逐元素加法操作,自注意力机制的融合更加灵活,适应性也更强,能够更好地捕捉特征之间的关联性,并提高模型的学习能力。
具体操作如下:首先,对深层特征图进行上采样,将7×7的采样变为14×14;接着,使用1×1卷积将通道数与上一层对齐,将256通道映射为128,得到大小为128×14×14的特征图;为了进行Attention操作,借鉴了MobileViT的方法,将特征图进行切片操作,每个切片内的像素进行自注意力运算,然后将得到的结果进行反变换,使其与原始输入特征图具有相同的形状。这样就完成了一次注意力计算过程。
在使用自注意力机制进行特征融合时,操作步骤如下:a)将浅层特征图(query)和深层特征图(key和value)输入到自注意力计算中;b)计算浅层特征图中每个像素与深层特征图中所有像素的关联程度,即权重;c)使用得到的关联权重对深层特征图中的每个像素进行加权求和,得到用深层特征图表示的浅层特征图。自注意力计算公式如式(1)所示。
其中:Q、K、V分别是query、key和value的对应通道切片;dk为K的方差。
1.4 损失函数制定
为了衡量不同的损失函数对检测效果的影响,使用两种不同的损失函数进行训练。网络输出包含预测框的位置信息和当前预测框的置信度两个部分。对于置信度,统一使用focal loss[22];位置信息则分别使用IoU loss[23]和smooth L1 loss[24]。模型训练的损失函数如式(2)所示。
其中:N为所有先验锚框的个数;Lconf为置信度损失;Lloc为位置损失;Nepoch为当前训练的迭代次数;当位置损失使用IoU loss时,α为1/2,當位置损失使用smooth L1 loss时,α为1/3。
2 数据测试与结果分析
2.1 数据集构建
基于1.1节中的采集设备共采集了22 419张原始分辨率为640×480的红外手势静态图片,且每张图片均有检测框标注,图4展示了其中的一些典型样本,包括握拳、手掌等动作。进一步,直接将所有关键点标注的外接矩形作为手部标注框,图5中的黄色方框则为部分手部标注框(参见电子版)。另外,需要说明的是,对于过曝光、欠曝光,以及一些极端距离和方位情况,则需手工设置手部标注框。
在实验阶段,将数据集按照8∶1∶1的比例随机划分为训练集、验证集、测试集,训练、测试尺寸宽高统一设为224×224。需要说明的是,为了进一步提高RetinaHand模型的泛化能力,对训练数据进行了进一步的数据增强,使用了随机亮度和对比度、水平镜像、mosaic[25]增强等数据增强手段。
2.2 评价指标
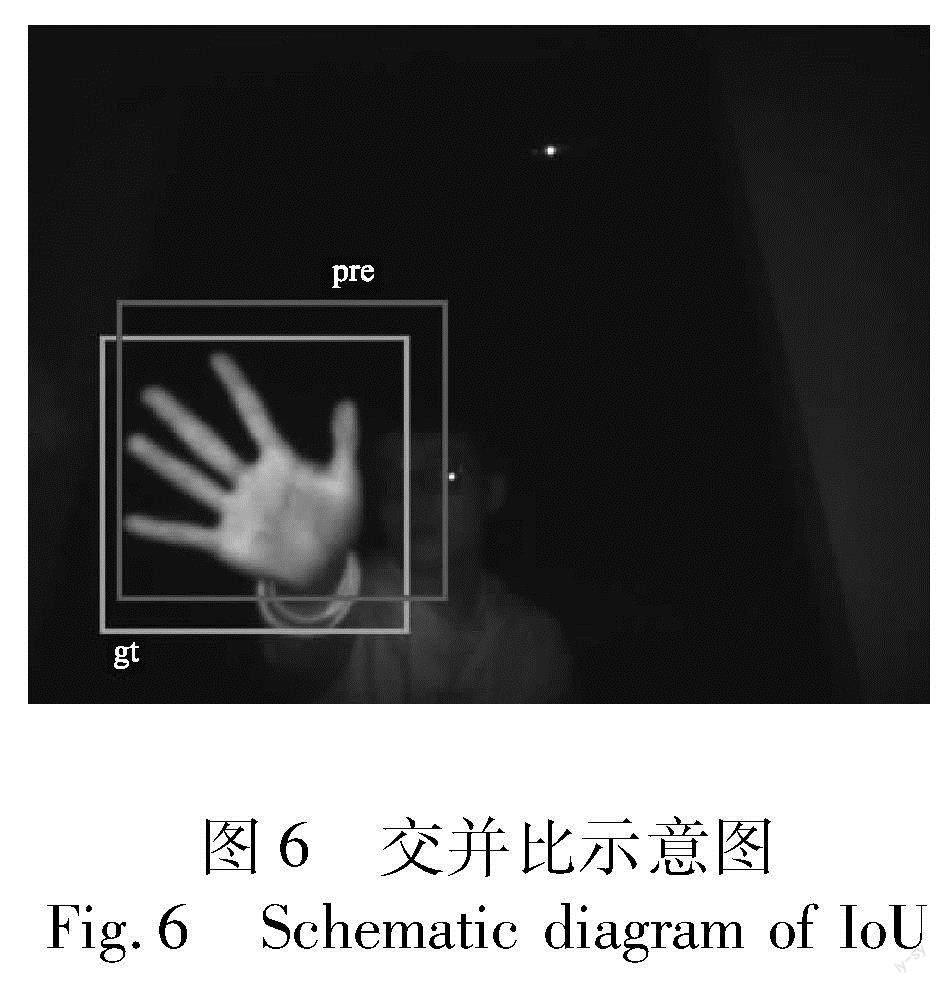
红外图像手部检测的特点有:a)仅需检测手这一类别;b)每幅图里只需检测出一只手,采用不同交并比阈值下的检测正确率acc@IoU进行检测结果评价。交并比(intersection over union,IoU)作为目标检测领域通用的评价指标,是衡量真实目标框和预测目标框之间重叠部分的面积占两者总面积大小的指标,如图6所示,两者重叠面积越大,表示预测框越接近真实框,交并比也就越大。IoU的计算如式(3)所示。
其中:pre表示预测目标框;gt表示真实目标框。具体地,将评测指标定义为在0.5、0.55、0.60、0.65、0.70、0.75、0.80、0.85、0.90、0.95十个IoU阈值下的acc。十个阈值下的平均acc可表示为IoU@0.5:0.95,或者简写为IoU0.5:0.95。具体而言,对于测试集中的每一张待测图片,如果模型预测框和真正框的IoU大于某一阈值,则认为这张图片预测成功,否则预测失败。最后计算测试集中所有预测成功的样本占总样本的比例,作为该阈值下的检测正确率。具体的计算公式为
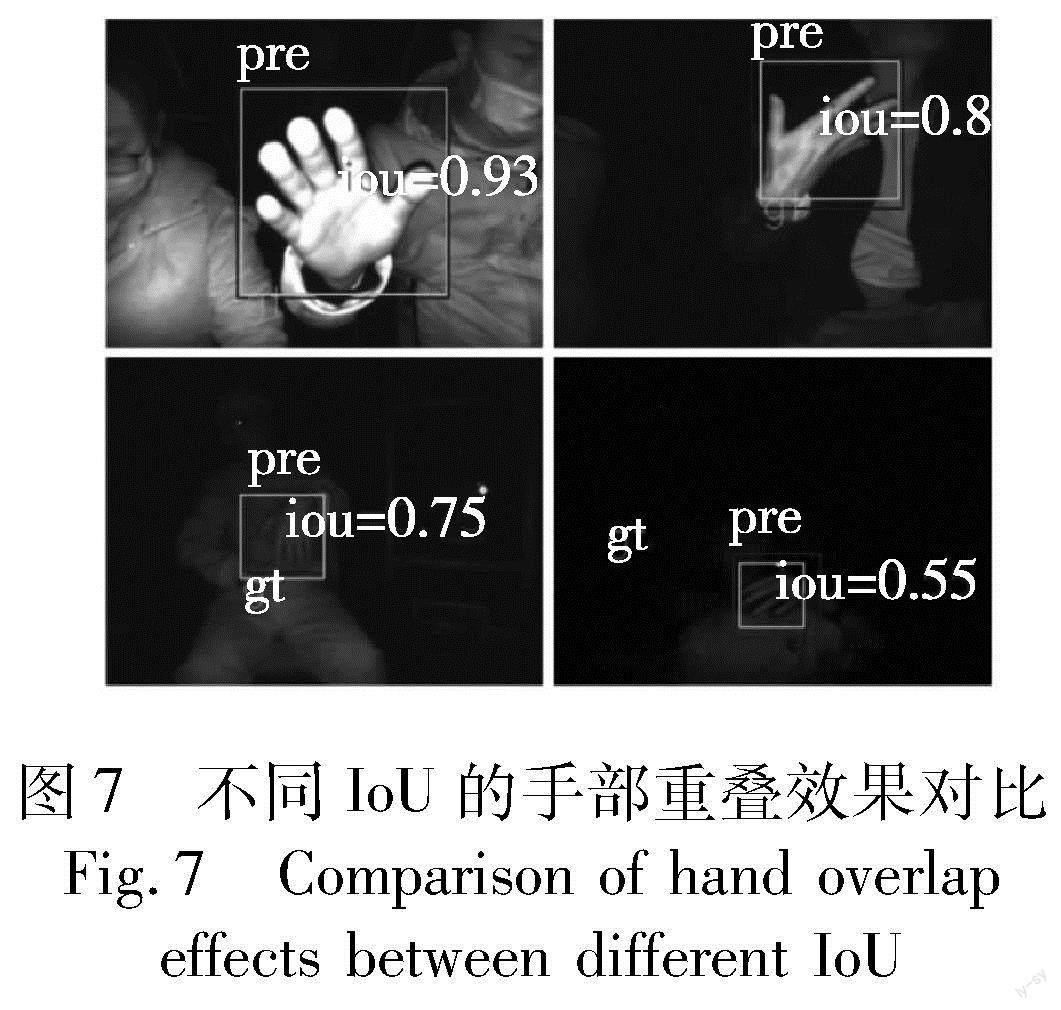
其中:pre和target分别表示预测目标框和真实目标框;IoU为两个目标框之间相交的面积和相并的面积之比,具体计算如式(3)所示;thresh为不同交并比下的阈值;N为验证集图片数。IoU表示模型预测结果和真实结果的重叠度,较大的IoU表示预测更准确。图7展示了不同IoU下的预测框和真实框的重叠效果。当IoU<0.6时,预测框存在多余背景或漏掉前景;当IoU>0.8时,预测框和真实框的重叠度高,误差较小。实际情况下,当IoU>0.5时,手部定位框已经涵盖整个手或大部分手部区域。手部检测的评价指标最小阈值设为0.5,综合考虑0.5:0.95阈值下的检测表现。
2.3 实验结果
本节在具体的RetinaHand手部检测算法中,分别采用MobileNetV1×0.25和ShuffleNetV2×0.5作为骨干网络进行实验,并与已公开的YOLOv5n、YOLOv5s、YOLO-Fastest、CenterNet[26]网络模型的测试结果进行了对比。从表1可以看出,在同一种检测算法下,模型的表现和所用骨干网络的参数量、计算量呈现出很强的相关性,参数量、计算量越大的网络越能够取得更好的表现。其次,三种检测算法中,精度上表现最好的模型为YOLOv5s,参数量和计算量上表现最好的为YOLO-Fastest。从综合衡量速度和精度来看,RetinaHand在速度和精度的均衡性方面优于YOLO-Fastest和CenterNet。
由于手部检测是动态手势识别系统中的第一阶段,且检测的精度和速度直接影响后续的关键点定位和手势分类的准确率,所以将RetinaHand手部检测算法和YOLOv5n、YOLOv5s分别应用到整个动态手势识别的流程中,最终的手势分类准确率结果如表2所示。实验结果表明,手部检测准确率的提高可以提升动态手势识别分类效果。考虑到移动端嵌入式设备计算能力受限,且YOLOv5n的参数量和计算量均远大于提出的RetinaHand网络,本文方法比较适合面向移动端嵌入式设备的部署。红外图像手部检测结果如图8所示。
图9和10进一步展示了在不同的骨干网络和损失函数下,RetinaHand在验证集上的结果。可以发现,与ShuffleNetV2相比,MobileNetV1能更快地达到收敛点,并且稳定后的波动较小。同时,相较于smooth L1 loss,IoU loss能更快地达到收敛点,并且在收敛后的准确率略优。
为了验证Attention-FPN对结果的提升效果,分别在MobileNetV1-0.25框架中采用FPN和Attention-FPN模块进行测试。如表3所示,对比acc@IoU 0.5和acc@IoU 0.5:0.95两个指标可以看出,Attention-FPN模块可以显著提高检测结果的准确度。这一方面也说明了自注意力机制的引入可以很好地弥补CNN模型所缺少的捕捉全局信息以及长距离依赖的能力,展示了Transformer模型在计算机视觉领域的应用价值。
圖8展示了在不同环境、距离、方位、角度下的检测结果。可以看出,对于一些距离较近、特征更明显的场景,置信度较高;而对于距离较远、环境较暗的场景,预测结果的置信度数值普遍偏低。这说明远距离、暗光背景下的难样本是手部目标检测研究面临的主要挑战之一。
除了上述的远距离、暗光背景,对极端距离及角度、运动模糊等复杂背景下的红外图像进行手部检测,也面临检测精度低的问题,部分结果如图11所示。本文手动筛选出测试集中的难样本,构成了一个只包含上述背景下难样本的测试集,并且在该困难样本上验证了各个模型的检测能力,实验结果如表4所示。从结果中可以看出,各个模型在困难样本上的整体表现都有所下降,但是 RetinaHand 的相对下降幅度是最低的,在速度和精度均衡上的优势进一步得到了体现。
3 结束语
本文详细描述了针对动态手势识别中的轻量化手部检测算法的研究。为了支持红外手部检测,创建了一个包含20 000多张静态红外图像的专用数据集。通过对经典通用目标检测算法进行轻量化设计和改进,确保了算法在嵌入式设备上速度和精度的平衡。本文的重点是提出了一种名为RetinaHand的算法模型,该模型可在嵌入式设备上对手部进行实时检测,并通过与四种经典通用目标检测轻量模型进行实验对比,展示了该模型的出色性能。手部检测模块能够在移动嵌入式设备上实现准确、快速和稳定的手部检测,为后续的关键点定位和手势分类提供了基础。
参考文献:
[1]董连飞,马志雄,朱西产.基于车载毫米波雷达动态手势识别网络[J].北京理工大学学报,2023,43(5):493-498.(Dong Lianfei, Ma Zhixiong, Zhu Xichan. Dynamic gesture recognition network based on vehicular millimeter wave radar[J].Trans of Beijing Institute of Technology,2023,43(5):493-498.)
[2]Lahiani H, Neji M. A survey on hand gesture recognition for mobile devices[J].International Journal of Intelligent Systems Techno-logies and Applications,2020,19(5):458.
[3]Riedel A, Berhm N, Pfeiforth T. Hand gesture recognition of method time measurement-1 motions in manual assembly tasks using graph convolutional networks[J].Applied Artificial Intelligence,2022,36(1):2014191.
[4]Yang Zhiwen, Jiang Diang, Sun Ying, et al. Dynamic gesture recognition using surface EMG signals based on multi-stream residual network[J].Frontiers in Bioengineering and Biotechnology,2021,9:779353.
[5]Gao Qing, Liu Jinguo, Ju Zhaojie. Robust real-time hand detection and localization for space human-robot interaction based on deep learning[J].Neurocomputing,2019,390:198-206.
[6]Sharma A, Mittal A, Singh S, et al. Hand gesture recognition using image processing and feature extraction techniques[J].Procedia Computer Science,2020,173:181-190.
[7]Utsumi A, Tetsutani N, Igi S. Hand detection and tracking using pixel value distribution model for multiple-camera-based gesture interactions[C]//Proc of IEEE Workshop on Knowledge Media Networking.Piscataway,NJ:IEEE Press,2002:31-36.
[8]Wu Xiaojuan, Xu Liqun, Zhang Boyang, et al. Hand detection based on self-organizing map and motion information[C]//Proc of International Conference on Neural Networks and Signal Processing.Piscata-way,NJ:IEEE Press,2003:253-256.
[9]Wang Y R, Lin W H, Yang Ling. A novel real time hand detection based on skin-color[C]//Proc of IEEE International Symposium on Consumer Electronics.Piscataway,NJ:IEEE Press,2013:141-142.
[10]Mittal A, Zisserman A, Torr P. Hand detection using multiple proposals[C]//Proc of British Machine Vision Conference.2011.
[11]Victor D. Real-time hand tracking using SSD on TensorFlow[R].[S.l.]:GitHub Repository,2017.
[12]Liu Wei, Anguelov D, Erhan D, et al. SSD: single shot multibox detector[C]//Proc of the 14th European Conference on Computer Vision.2016:21-37.
[13]Betancourt A. EgoHands: a unified framework for hand-based methods in first person vision videos[C]//Proc of IEEE International Conference on Multimedia and Expo.Piscataway,NJ:IEEE Press,2017.
[14]Wang Jinwei, Ye Zhongfu. An improved Faster R-CNN approach for robust hand detection and classification in sign language[C]//Proc of the 10th International Conference on Digital Image Processing.2018:352-357.
[15]Ren Shaoqing, He Kaiming, Girshick R, et al. Faster R-CNN:towards real-time object detection with region proposal networks[J].IEEE Trans on Pattern Analysis and Machine Intelligence, 2017,39(6):1137-1149.
[16]Howard A G, Zhu Menglong, Chen Bo, et al. MobileNets: efficient convolutional neural networks for mobile vision applications[EB/OL].(2017).https://arxiv.org/abs/1704.04861.
[17]Sandler M, Howard A, Zhu Menglong, et al. MobileNetV2: inverted residuals and linear bottlenecks[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2018:4510-4520.
[18]Ma Ningning, Zhang Xiangyu, Zheng Haitao, et al. ShuffleNetV2: practical guidelines for efficient CNN architecture design[C]//Proc of European Conference on Computer Vision.2018:116-131.
[19]Deng Jiankang, Guo Jia, Ververas E, et al. RetinaFace:single-shot multi-level face localisation in the wild[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.2020:5203-5212.
[20]史楊.基于近红外视觉的动态手势交互系统研究[D].合肥:中国科学院技术大学,2011.(Shi Yang. Hand gesture interface system based on near infrared computer vision[D].Hefei:University of Technology,Chinese Academy of Sciences,2011.)
[21]Mehta S, Rastegari M. MobileViT:light-weight, general-purpose, and mobile-friendly vision transformer[EB/OL].(2021).https://arxiv.org/abs/2110.02178.
[22]Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection[C]//Proc of IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2017:2980-2988.
[23]Yu Jiahui, Jiang Yuning, Wang Zhangyang, et al. UnitBox: an advanced object detection network[C]//Proc of the 24th ACM International Conference on Multimedia.New York:ACM Press,2016:516-520.
[24]Girshick R. Fast R-CNN[C]//Proc of IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2015:1440-1448.
[25]Bochkovskiy A, Wang C Y, Liao H Y M. YOLOv4:optimal speed and accuracy of object detection[EB/OL].(2020).https://arxiv.org/abs/2004.10934.
[26]Zhou Xingyi, Wang Dequan, Krhenbühl P. Objects as points[EB/OL].(2019).https://arxiv.org/abs/1904.07850.
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27
中国远程教育(2016年11期)2016-12-27
现代商贸工业(2016年25期)2016-12-26
江苏教育·中学教学版(2016年11期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
考试周刊(2016年94期)2016-12-12
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
