
级联离散小波多频带分解注意力图像去噪方法
2024-02-18 11:17王力李小霞秦佳敏朱贺周颖玥
计算机应用研究 2024年1期
关键词:图像去噪
王力 李小霞 秦佳敏 朱贺 周颖玥
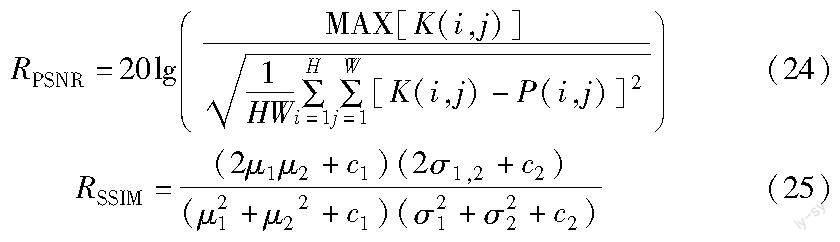
摘 要:针对图像去噪网络中下采样导致高频信息损失和细节保留能力差的问题,设计了一种级联离散小波多频带分解注意力图像去噪网络。其中多尺度级联离散小波变换结构将原始图像分解为多个尺度下的高低频子带来代替传统下采样,能减少高频信息损失。多频带特征增强模块使用不同尺度的卷积核并行处理高低频特征,在子网络每一级下重复使用两次,可增强全局和局部的关键特征信息。多频带分解注意力模块通过注意力评估纹理细节成分的重要性并加权不同频带的细节特征,有助于多频带特征增强模块更好地区分噪声和边缘细节。多频带选择特征融合模块融合多尺度多频带特征增强选择性特征,提高模型对于不同尺度噪声的去除能力。在SIDD和DND数据集上,所提方法的PSNR/SSIM指标分别达到了39.35 dB/0.918、39.72 dB/0.955。实验结果表明,该方法的性能优于主流去噪方法,同时具有更清晰的纹理细节和边缘等视觉效果。
关键词:图像去噪; 高频信息; 级联离散小波变换; 多频带特征增强; 多频带分解注意力
中图分类号:TP391.4 文献标志码:A 文章編号:1001-3695(2024)01-046-0288-08
doi:10.19734/j.issn.1001-3695.2023.06.0245
Cascade discrete wavelet multi-band decomposition attention image denoising method
Abstract:To address the issue of high-frequency information loss and poor detail preservation ability in image denoising networks caused by downsampling, this paper proposed a cascade discrete wavelet multi-band decomposition attention image denoising network. The multi-scale cascade discrete wavelet transform structure decomposed the original image into high and low-frequency sub-bands at multiple scales, replacing traditional downsampling and reducing high-frequency information loss. The multi-band feature enhancement module employed convolutional kernels of different scales to process high and low-frequency features in parallel. By repeating this process twice at each level of the subnetwork, it effectively enhanced both global and local key feature information. The multi-band decomposition attention module evaluated the importance of texture detail components through attention and weighted the detail features of different bands, which helped the multi-band feature enhancement module better distinguish between noise and edge details. The multi-band selective feature fusion module fused multi-scale multi-band features to enhance selective features, improving the models ability to remove noise at different scales. The proposed method achieves PSNR/SSIM values of 39.35 dB/0.918 and 39.72 dB/0.955 on the SIDD and DND datasets, respectively. The experimental results demonstrate that the proposed method outperforms mainstream denoising methods and produces clearer visual effects, such as texture details and edges.
Key words:image denoising; high-frequency information; cascade discrete wavelet transform; multi-band feature enhancement; multi-band decomposition attention
0 引言
图像噪声会显著降低图像质量,因此消除图像噪声对于提高图像的视觉质量至关重要。图像去噪是一个不适定问题,具有很大的挑战性。在高级计算机视觉任务的预处理步骤中,如目标检测和图像分割,图像去噪扮演着重要角色。为了解决这个问题,研究人员开发了基于模型和学习的图像去噪方法。
基于模型的方法采用基于明确定义的图像先验信息或噪声统计模型的优化策略,这些方法具有良好的可解释性和强大的泛化能力。典型的先验信息包括图像域的平滑性、变换域的稀疏性[1,2]、斑块域的非局部自相似性[3,4]和低秩[5]。虽然这些方法都取得了不错的效果,但它们仍存在以下四个缺点:a)需要人工调整参数;b)需要复杂的优化算法才能达到理想的去噪效果;c)保留图像边缘细节特征的能力差;d)无法去除复杂的真实噪声。
在过去十余年,深度学习方法促进了图像处理领域快速发展。相较于传统的图像去噪方法,基于深度学习的方法有很多优点。首先,这些方法通常不需要人工设置超参数或依赖于人类知识的图像先验。其次,它们在去除合成噪声和真实噪声方面都表现得更好。卷积神经网络(convolutional neural networks,CNN)的结构非常适合于同时捕捉浅层和深层图像特征,并且能够从大规模的图像训练集中获得强大的数据推理能力,从而表现出更优的性能。已有的一些方法,例如DnCNN[6]和FFDNet[7],通过引入残差学习和人工设置噪声级别来去除图像中的噪声。然而,这些方法在处理真实噪声方面表现不佳。为了应对这个问题,CBDNet[8]通过使用噪声估计子网络来预测噪声图像作为先验知识,从而去除真实场景中图像的真实噪声。RIDNet[9]则使用了注意力机制来增强高频信息的流动,并使用残差结构减少低频信息的传递,以重建去噪图像中的详细信息。然而,这些方法的计算复杂度较高。InvDN[10]是一种轻量级且可逆的真实图像去噪网络,该网络将噪声图像转换为低分辨率的干净图像和包含噪声的潜在表示,从而实现干净图像的恢复和新噪声图像的生成。CVF-SID[11]中提出了一种关于真实噪声自监督训练去噪方法,能将噪声图像分解成干净图像、信号相关和无关的噪声;同时还引入一种自监督的数据增强策略,以有效地增加训练样本的数量。MaskedTraining[12]引入输入掩码和注意力掩码两种掩码训练方法,通过对输入图像进行随机像素掩盖,并在训练过程中重建缺失信息,有效提高了去噪模型的泛化能力。MIRNetv2[13]通过使用多尺度残差块、结合密集连接块和全局残差学习来保留图像细节。但是,以上这些方法无法在具有复杂纹理和结构的区域中精细地保留图像边缘细节特征。引入注意力机制可以帮助网络更准确地区分信号和噪声,并更好地恢复图像的细节和纹理信息。目前,许多研究已经在这方面作出了重要的贡献。例如,Hu等人[14]将注意力机制引入到图像分类任务中,提出了显式建模通道间相互依赖关系的网络,提高了网络性能。Woo等人[15]提出了即插即用的卷积块注意力模块(convolutional block attention module,CBAM),通过最大池化和平均池化分别在信道空间维度提取全局图像特征。尹海涛等人[16]提出了局部和非局部的混合注意力机制的去噪模型,能自适应调整特征通道并有效刻画图像中的局部和非局部特征。Qin等人[17]提出了多频谱通道注意力框架,是一种融合频域分析和注意力机制的尝试。
目前通用的图像去噪任务架构使用噪声图像和干净的目标图像对进行训练,并对加性高斯白噪声(additive white Gaus-sian noise,AWGN)等合成噪声图像进行处理,获得了良好的视觉质量。然而,真实图像去噪仍然是一个具有挑战性的任务,真实图像噪声来源于相机系统中的处理步骤,如马赛克、伽马校正和压缩多样化。近年来,研究人员试图通过对真实噪声进行建模,构建基于CNN的去噪模型来处理真实世界的噪声图像。典型的CNN真实图像去噪方法采用編码器-解码器网络结构,然而编码器-解码器网络结构中重复的下采样操作会对图像高频信息造成严重的破坏,无法重构出高质量的图像。图像信息主要分为低频信息和高频信息两部分。低频信息包含了原始图像的主要内容,而高频信息则包含了水平、垂直和对角线细节,能够清晰地表现图像的纹理特征。这些信息不仅对于图像去噪至关重要,也是其他视觉任务的关键。引入小波变换(wavelet transform,WT)[18]可以进一步提高图像去噪的性能。小波变换具有多分辨率分析和时频域逐步细分的功能,可以将特征映射分解为不同频率以作进一步处理。通过将图像中的高频信息从低频信息中分离出来,小波变换可以大大减少CNN中下采样造成的信息损失。此外,小波变换是可逆的,在图像处理中也得到了广泛的应用。Sun等人[19]提出级联离散小波变换模块,该模块充分利用了不同的频率分量,通过替换现有的池化操作,提高了图像分类任务的准确率。Liu等人[20]通过使用小波变换代替U-Net[21]中下采样操作,利用正交化方法保留更多的信息。徐景秀等人[22]提出一种改进小波软阈值函数方法,通过对阈值的选取方式和阈值函数进行改进来提升去噪后的图像质量。陈清江等人[23]基于小波变换和CNN的优势将图像进行尺度为1的小波分解,得到高频分量和低频分量分别输入网络进行训练,能有效去除噪声。Duan等人[24]应用双树复小波变换设计了一种卷积小波神经网络,该网络具有抑制特定噪声和保持特征结构的能力。尽管基于小波的去噪方法取得了成功,但仍存在一些局限性:a)固定的小波滤波器选择和有限的分解级别可能无法捕捉到所有尺度上的信号特征;b)当噪声水平较高时或处理复杂的真实噪声时,去噪性能可能会恶化,因为噪声在小波分解过程中可能会通过不同的子带传播;c)现有方法将所有频率信息直接混合,或直接丢弃高频信息,导致不同频率信息相互作用产生伪影和失真,以及无法保留图像边缘细节特征等问题,特别是在具有复杂纹理和结构的区域。
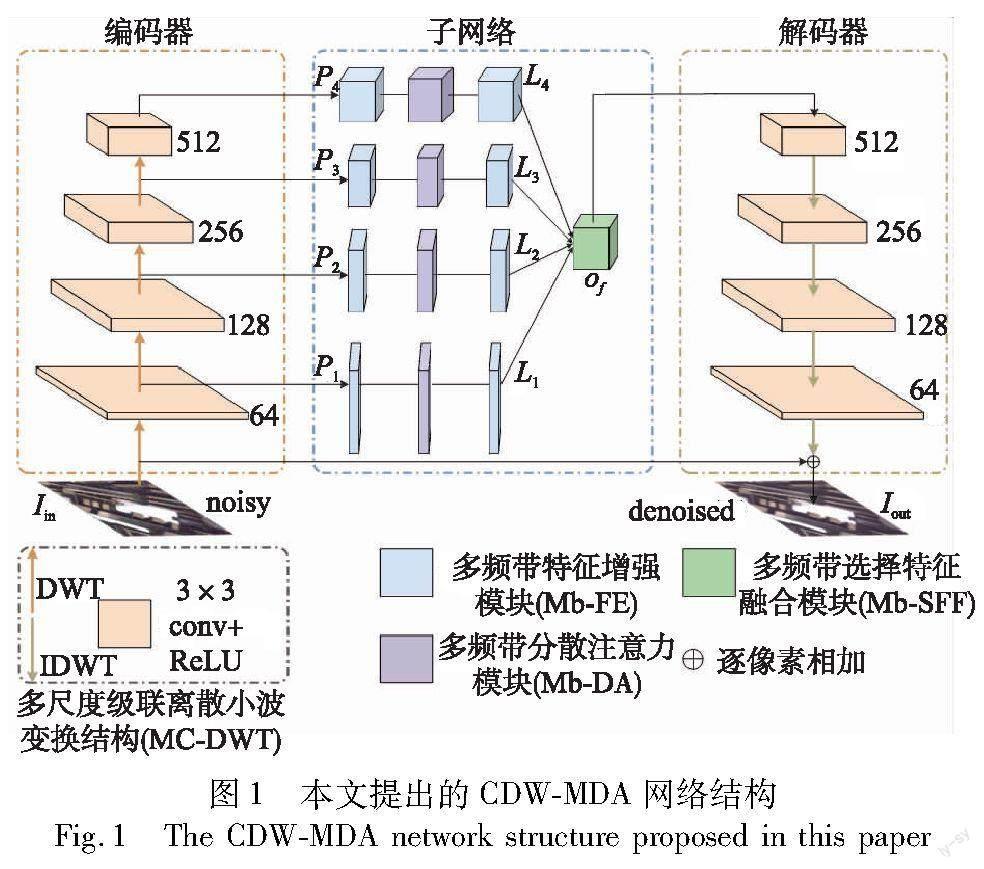
针对以上问题,本文提出了一种级联离散小波多频带分解注意力(cascaded discrete wavelet multi-band decomposition attention,CDW-MDA)图像去噪网络,该网络结合了模型可解释性强和CNN学习能力强的优点,采用编码器-子网络-解码器结构,包括多尺度级联离散小波变换(multi-scale cascaded discrete wavelet transform,MC-DWT)结构、多频带特征增强(multi-band feature enhancement,Mb-FE)模块、多频带分解注意力(multi-band decomposition attention,Mb-DA)模块以及多频带选择特征融合(multi-band selective feature fusion,Mb-SFF)模块。
具体来说,本文在编码器和解码器阶段采用离散小波变换(discrete wavelet transform,DWT)和逆离散小波变换(inverse discrete wavelet transform,IDWT)代替了U-Net结构中的下采样和上采样操作,以减少下采样操作造成的高频信息损失并增大感受野。此外,通过级联DWT和卷积块,将输入图像分解成多尺度频带,其中低频子带包含了原始图像的主要信息,而高频子带包含了水平、垂直和对角线细节信息。在子网络阶段,本文设计了多频带特征增强(Mb-FE)模块、多频带分解注意力(Mb-DA)模块和多频带选择特征融合(Mb-SFF)模块。首先,将不同尺度下的频带信息输入Mb-FE模块,以提取不同频带的全局和局部特征。然后,Mb-DA模块对不同尺度下各频带的特征进行注意力加权,提高空间特征的冗余度和丰富度,并增强每个子带的鉴别信息,从而有效地保留重要的图像细节和抑制噪声。Mb-SFF模块由粗到精融合级间多尺度多频带特征和单一尺度下的多频带特征,同时保持了高频带与低频带信息的互补特性。最终,将多频带特征信息通过IDWT操作转换为线性结构信息,重构出高质量的图像。实验结果表明,在合成噪声和真实噪声图像数据集上,本文去噪方法的性能优于目前主流的去噪方法。
1 提出方法
本章提出了一种级联离散小波多频带分解注意力(CDW-MDA)图像去噪网络。首先,整体介绍了网络结构的数学模型和使用的损失函数,然后详细描述了所提出的网络中的多尺度级联离散小波变换(MC-DWT)结构、多频带特征增强(Mb-FE)模块、多频带分解注意力(Mb-DA)模块以及多频带选择特征融合(Mb-SFF)模块。
1.1 CDW-MDA图像去噪网络结构
如图1所示,CDW-MDA网络采用编码器-子网络-解码器的结构。在编码器阶段,将输入的噪声图像进行级联DWT和卷积块操作,获取四个尺度下的高低频带特征。本文采用DWT和IDWT代替U-Net中下采样和上采样操作,以减少下采样操作造成的高频信息损失。整个编码器过程中的数学模型表达式如式(1)~(3)所示。
P1=F1Con(F1DWT(Iin))(1)
P2=F2Con(F2DWT(F1Con(F1DWT(Iin))))=F2Con(F2DWT(P1))(2)
Pn=FnCon(FnDWT(Pn-1)) n=1,…,4(3)
其中:Pn表示提取的第n级高频子带和低频子带特征图;Iin∈RApH×W×C是输入的噪声图像;H、W和C分别代表输入图像的高、宽和通道数;FnDWT(·)和FnCon(·)分别表示第n级DWT输出和卷积块输出,根据实验经验,本文中n取4。
然后,将编码器中提取到的不同尺度频带特征P1、P2 、P3 和P4分别送入子网络中每一级的多频带特征增强(Mb-FE)模块,增强全局-局部高低频关键特征信息,抑制噪声影响。随后将增强的高频子带和低频子带特征图送入多频带分解注意力(Mb-DA)模块,捕捉分解的高低频子带中的关键细节,以充分提高空间域特征的冗余度和丰富度,从而有效地保留重要的图像边缘细节特征。Mb-FE的低噪声特性可以使Mb-DA更好地捕捉圖像高低频特征,Mb-DA的高低频特征注意力可以帮助Mb-FE更好地区分噪声和边缘细节。本文在每一级的Mb-DA后叠加一个Mb-FE来构建子网络,生成特征图L1、L2、L3和L4。最后,将L1、L2、L3和L4送入多频带选择特征融合(Mb-SFF)模块融合多尺度高低频带特征,得到特征图Of。整个子网络的数学模型表达式如式(4)~(7)所示。
L1=F″Mb-FE(F1Mb-DA(F′Mb-FE(P1)))(4)
L2=F″Mb-FE(F2Mb-DA(F′Mb-FE(P2)))(5)
Ln=F″Mb-FE(FnMb-DA(F′Mb-FE(Pn)))(6)
Of=FMb-SFF(L1,…,L4)(7)
其中:F′Mb-FE(·)和F″Mb-FE(·)分别表示每一级的第一和第二次Mb-FE的输出;FnMb-DA(·)表示第n级的Mb-DA的输出;FMb-SFF(·)表示Mb-SFF操作;Of为输出的特征图。
在解码器中,Of通过卷积块和IDWT输出得到预测残差图像Ires,将Ires和Iin相加就得到去噪后的图像Iout。整个解码器的数学模型表达如式(8)(9)所示。
Ires=F1IDWT(F1Con…(FnIDWT(FnCon(Of))))(8)
Iout=Ires+Iin(9)
其中:FnCon和FnIDWT分别表示第n级的卷积块和IDWT操作;Ires是级联卷积和IDWT后得到的残差图像;Iout为去噪后的输出图像。
为了提高CDW-MDA网络在图像去噪任务中的有效性,本文选择L2损失来优化整个网络。给定训练集{Inoisy,Iclean}N包含N对噪声图像和相应的干净图像,CDW-MDA可以通过Adam[25]优化得到合适的参数,计算过程为式(10)
其中:L和Θ分别表示网络的损失函数和参数集;HCDW-MDA(Inoisy)是CDW-MDA去噪网络的数学表达式;Iclean为干净图像。
1.2 多尺度级联离散小波变换(MC-DWT)结构
二维DWT可以将原始图像Y分解为低频子带、水平高频子带 、垂直高频子带和对角线高频子带的组合,四个子带图像的像素尺寸是输入图像尺寸的一半,如图2所示。本文使用由低通滤波器和高通滤波器组成的Haar小波[18]分解输入图像Y,如式(11)所示。
其中: fLL为低通滤波器; fLH、 fHL和fHH为三个高通滤波器。
由于四种滤波器的正交性,在下采样过程中不会出现信息损失,这意味着利用IDWT可以完全重建目标图像。二维DWT和IDWT的计算步骤如式(12)(13)所示。
FDWT(Y)=[fLL*Y)↓2,(fLH*Y)↓2,(fHL*Y)↓2,(fHH*Y)↓2]=
[YLL,YLH,YHL,YHH](12)
Y=FIDWT(YLL,YLH,YHL,YHH)(13)
其中:FDWT(·)表示DWT计算;FIDWT(·)表示IDWT计算;*为卷积运算;↓2为二分降频采样。
本文使用Haar小波分解,将一个复杂的CNN训练图像去噪问题转换为一个简单的CNN训练多个尺度小波子带的问题。图1展示了在每一级小波变换后插入一个3×3 conv+ReLU卷积块,可以减少特征映射的通道数,并提高特征映射的带间独立性。每个卷积块右侧标注了通道数,且没有池化。对于最后一个卷积块的最后一层,仅采用3×3 conv对残差结果进行预测。总之,MC-DWT结构取代了传统U-Net中的上采样和下采样,从而避免了信息损失。DWT的时频域逐步细分特性还有助于保留图像细节和纹理信息。
1.3 多频带特征增强(Mb-FE)模块
针对直接混合高低频信息导致去噪效果不佳的问题,本文提出了一种多频带特征增强(Mb-FE)模块,用于增强全局和局部的高低频关键特征信息,并抑制噪声影响。在CDW-MDA的每一级子网络阶段,重复使用两次Mb-FE模块。具体来说,Mb-FE模块可以看作是一个双支路四层残差密集块(residual dense block,RDB),前面每层的输出使用跳跃连接与当前层的输出相连,并输入到下一层,以提高网络的表达能力和性能。在Mb-FE高频子带支路中,采用小的3×3卷积核以更好地保留图像细节信息,而在Mb-FE低频子带支路中,采用较大的5×5卷积核以获取更多的上下文信息,从而更好地增强低频特征。此外,每个卷积层都去除了批次归一化 (batch normalization,BN)和池化,只保留了ReLU,以更好地保留细节特征。
如图3所示,令Mb-FE模块中高频子带和低频子带的特征输入分别为P0H和P0L,高频子带特征图在经过三层3×3 conv和ReLU运算后的特征图分别为P1H、P2H和P3H,融合P1H后的局部特征圖为P4H,如式(14)所示。
P4H=conv[concat(P0H,P1H,P2H,P3H)](14)
其中:concat(P0H,P1H,P2H,P3H)表示将特征图P0H、P1H、P2H、P3H进行通道拼接;conv表示1×1卷积运算,用于融合局部特征。最终的输出PoutH为融合后的局部特征图P4H和高频子带输入特征P0H进行逐像素相加,如式(15)所示。
PoutH=P0H+P4H(15)
同理,低频子带特征图在经过三层5×5 conv和ReLU运算后的特征图分别为P1L、P2L和P3L,融合P3L后的局部特征图为P4L,如式(16)所示。
P4L=conv[concat(P0L,P1L,P2L,P3L)](16)
其中:concat(P0L,P1L,P2L,P3L)表示将特征图P0L、P1L、P2L、P3L进行通道拼接;conv表示1×1卷积运算,用于融合局部特征。最终的输出PoutL为融合后的局部特征图P4L和低频子带输入特征P0L进行逐像素相加,如式(17)所示。
PoutL=P0L+P4L(17)
1.4 多频带分解注意力(Mb-DA)模块
X=softmax([FC(GAP(M[i,:,:,:]))]) i=1,2,3(19)
显然,X是对M的注意力权重。最终的纹理特征如式(20)所示。
其中:⊙为点乘运算;c为向量的维度。
最终,通过将原始特征LL和生成的纹理特征拼接起来,以获得更全面、更具区分性的输出特征表示,如式(21)所示。
output features=concat(textural features,LL)(21)
1.5 多频带选择特征融合(Mb-SFF)模块
受文献[13]的启发,本文引入了一个非线性过程来融合多尺度特征,即多频带选择特征融合(Mb-SFF)模块,如图5所示。与文献[13]不同的是,本文是针对DWT分解的四个尺度下的子带特征图进行融合。Mb-SFF接收来自四个携带不同尺度子带信息的输入。首先将这些多尺度特征用一个元素级和组合表示,如式(22)所示。
L=L1+L2+L3+L4(22)
然后,在L的空间维度上进行全局平均池化(GAP),得到通道元素特征向量S。S经过一个1×1 conv和ReLU的卷积层生成一个紧凑的特征向量Z。Z通过四个并行的通道放大卷积层(每个尺度一个)得到四个特征描述子V1、V2、V3和V4,每个描述子的维度为1×1×C。应用softmax函数产生V1、V2、V3和V4对应的注意力激活算子S1、S2、S3和S4,这些激活算子用来自适应地重新校准多尺度特征L1、L2、L3和L4。特征重新校准和聚集以获得输出特征Of的计算过程,如式(23)所示。
Of=S1·L1+S2·L2+S3·L3+S4·L4(23)
2 实验
2.1 训练集与测试集
对于合成噪声去噪任务,本文使用一个大型数据集DIV2K[26]作为训练数据集,该数据集由800幅高分辨率图像组成。在训练过程中,大小为256×256的图像补丁从其原始完整版本中随机裁剪,并在图像上添加特定噪声水平(σ=15,25,50)的加性高斯白噪声(AWGN)进行合成噪声去噪评价。使用SeT12[6]和BSD68[27]数据集对灰度图像进行去噪评价;选择CBSD68[27]和McMaster[28]数据集对彩色图像进行去噪评价。
对于真实图像去噪任务,本文使用SIDD数据集[29]进行训练,该数据集是由五部智能手机在室内捕捉不同的噪声水平场景下采集的,包含320对图像用于训练,1 280对图像用于测试。本文使用SIDD和DND数据集[30]对真实图像去噪进行评价。在训练和测试中,所有裁剪得到的补丁大小都是256×256。
2.2 实验细节
CDW-MDA网络使用的深度学习框架为PyTorch 1.8和CUDA 11.1,所有的实验都是在Ubuntu 18.04.5版本,两张NVIDIA GTX3080 GPU的环境下进行。真实噪声训练和合成噪声训练的批次大小为16,补丁大小为256。在训练过程中,学习速率初始设置为1E-4,使用余弦退火策略[31]来稳定降低学习速率,并用L2损失和Adam优化器(β1=0.9,β2=0.999)来优化网络参数。CDW-MDA网络使用了四个不同的特征尺度,通道数分别为64、128、256和512,DWT分解级别为4,每一级别下的Mb-FE和Mb-DA数量分别为2和1。
2.3 评价指标
本文用峰值信噪比(peak signal-to-noise ratio,PSNR)和结构相似性(structural similarity,SSIM)[32]两个指标来定量分析模型的去噪性能。PSNR越高,SSIM越接近1,表明去噪后的图像更接近ground truth,模型去噪效果更好。PSNR和SSIM的公式为式(24)(25)
其中:W表示宽度;H表示高度;P(i, j)表示去噪图像(i, j)位置处的像素值;K(i,j)表示ground truth图像(i,j)位置处的像素值;μ1和μ2分别表示图像K和P的均值;σ1和σ2分别表示图像K和P的方差;σ1,2表示图像K和P的协方差,且c1=0.01和c2=0.02为常数。
2.4 实验结果与分析
2.4.1 灰度图像去噪
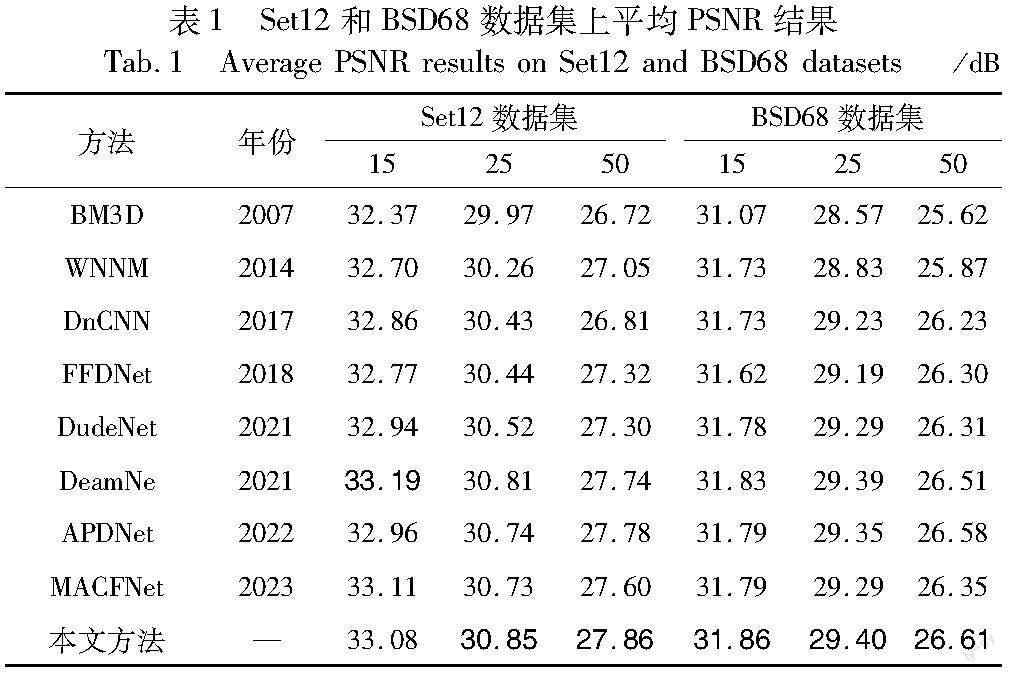
为了进行客观评价,将具有不同噪声水平σ=15,25,50的相同噪声AWGN添加到ground truth图像中以获得噪声图像。对于灰度图像去噪,本文将CDW-MDA的实验结果与一些最新的去噪方法进行了比较,包括BM3D[3]、WNNM[33]、DnCNN[6]、FFDNet[7]、DudeNet[34]、DeamNet[35]、APDNet[36]和 MACFNet[37]。表1展示了這些方法在Set12和BSD68数据集上平均PSNR结果。各表中加粗代表所列方法中的最优指标。可以看出,本文方法的定量结果多为最优或次优。在复杂噪声下,本文模型优于所列图像去噪方法,主要是因为CDW-MDA网络架构能更深入地挖掘高频信息。
图6展示了来自Set12数据集中的图像Barbara在σ=50下不同方法的视觉去噪结果对比,子图题中数字表示PSNR。BM3D和WNNM在一定程度上保留了图像的结构,但不能很好地去除噪声。DnCNN和FFDNet使边缘过于平滑,混淆了前景和背景。DeamNet和APDNet虽然去噪效果很好,但在去噪过程中纹理和细节保留的效果较差。相比之下,本文方法可以产生更清晰的桌布纹理细节,而且没有产生模糊,恢复后的图像保留了更多的纹理细节信息。
2.4.2 彩色图像去噪
对于彩色图像去噪,本文将CDW-MDA的实验结果与一些最新的去噪方法进行了比较,包括CBM3D[3]、DnCNN、FFDNet、ADNet[38]、DudeNet、DeamNet、APDNet和MACFNet。表2展示了这些方法在CBSD68和McMaster数据集上的平均PSNR结果。可以看出,本文方法在McMaster数据集上取得了最好的结果,在三种不同的噪声水平下,相较于DeamNet的PSNR增益分别为0.06 dB、0.09 dB和0.05 dB。总的来说,本文方法可以在大多数情况下获得最高的PSNR,这是因为CDW-MDA网络架构同时关注了图像的全局和局部信息。
图7展示了来自CBSD68数据集中的图像在σ=50下不同方法的视觉去噪结果对比,从去噪图像和放大局部图可以看出,本文方法能够在保持图像特征纹理的同时降低噪声。
2.4.3 真实噪声图像去噪
真实噪声图像的去噪是一个极具挑战性的问题,因为真实噪声通常具有信号依赖性,并且在空间上随相机的特性而变化。为了评估本文方法对真实噪声图像的去噪性能,采用SIDD验证数据集和DND基准数据集作为测试数据集。由于DND不提供可训练的数据集,ground truth图像也不公开,去噪后的图像和结果只能通过在线系统获得,所以本文将去噪图像提交到DND官方网站以获得结果。
本文将实验结果与一些最新的去噪方法进行了比较,包括BM3D[4]、DnCNN[6]、FFDNet[7]、CBDNet[8]、RIDNet[9]、HI-GAN[39]、COLA-Net[40]、MHCNN[41]和VDIR[42]。在实验中,本文使用相应原文提供的预训练模型,并参考其在线系统和论文中报告的结果。表3显示了SIDD验证数据集上的定量结果,可以看出,本文方法在现有方法上获得了最高的PSNR和SSIM值,与目前最好的方法相比,PSNR增益为0.06 dB,SSIM值提高了0.004。表4显示了DND基准数据集上的定量结果,本文方法同样获得了最高的PSNR和SSIM值,与目前最好的方法相比,PSNR增益为0.09 dB,SSIM值提高了0.002。定量实验结果表明,与其他七种去噪方法相比,本文CDW-MDA对于真实噪声图像具有更好的去噪性能。
图8、9展示了来自SIDD数据集中不同方法的视觉去噪结果对比。传统算法BM3D的视觉效果稍微优于DnCNN,但是两者的去噪效果和边缘信息保留能力有限。CBDNet和RIDNet的去噪效果有所提升,但是有残余噪声和伪影。相比之下,本文方法能在去除噪声的同时保留更多的文字和白色条纹细节,因此具有更好的视觉效果。
图10展示了来自DND数据集中不同方法的视觉去噪结果对比,由于石柱表面的雕刻凹凸不平,使图像中的噪声很难去除,上述方法都不能在去除噪声和保留边缘结构的问题上保持平衡。而本文方法可以更巧妙地恢复纹理和结构,并获得更清晰的图像。综合实验指标结果和视觉对比效果来看,本文方法在实际图像去噪中具有一定优势。
2.4.4 消融实验
本文在McMaster数据集(σ=25)上进行消融实验来验证所提出模块的有效性,结果如表5所示。首先,使用传统的具有跳连接的编码器-解码器网络结构(encoder-decoder,ED)作为基准网络,即不将图像分解为不同频率的特征,而是从整个图像中提取特征。MC-DWT是CDW-MDA中的关键结构,如果没有此结构,专为高频和低频特征设计的Mb-FE和Mb-DA模块就会失效。由实验1可知,基准网络结果最差,实验2在实验1的基础上加入MC-DWT结构,整体性能有所提升,获得了0.11 dB增益。对比实验3~6可知,Mb-FE、Mb-DA、Mb-SFF分别获得了0.25 dB、0.32 dB、0.16 dB的增益,说明这三个模块都可以提高去噪性能。由实验6可得,组合Mb-FE、Mb-DA和Mb-SFF相较于基准网络获得了1.4 dB的增益,并且达到了最佳的去噪效果。
为了验证网络结构中DWT分解级别参数n和有无BN层情况下模型的去噪性能,本文在Set12数据集(σ=25)进行组合消融实验,结果如表6所示。由表6可得,当网络结构中无BN层且n为4时,取得了最高的PSNR和SSIM值。在n取值相同下,无BN层的PSNR和SIMM值比有BN层平均分别高出0.026 dB、0.002,这是因为BN通常对每个通道进行归一化,会导致去噪模型过度平滑图像,从而损失一些边缘细节信息。在无BN层的情况下,n=4时的PSNR和SSIM值比n=3和n=5分别高出0.06 dB/0.002、0.14 dB/0.003,而在有BN层的情况下,n=4时的PSNR和SSIM值比n=3和n=5分别高出0.05 dB/0.003、0.14 dB/0.005。从以上消融实验结果可知,参数n的选取对于模型的去噪性能影响更大,n越大时导致图像的低频信息更多地参与重构,产生过度平滑的结果,从而导致模型的去噪性能下降。同时,较大的分解级数也会增加模型的复杂度和计算开销。因此,实验中选择参数n=4且无BN层作为模型的初始设置。
3 结束语
本文基于DWT在图像去噪中的应用,提出了一种用于图像去噪的级联离散小波多频带分解注意力(CDW-MDA)网络。由于MC-DWT的结构设计引入DWT,能减少一般下采样造成的频率信息损失,Mb-FE用于增强高频和低频的关键特征信息,Mb-DA关注不同频带分量的特征,可以在强噪声下的复杂场景中还原更丰富的纹理细节,Mb-SFF的融合机制充分利用了级间的多尺度高低频特征,提高了模型对于不同尺度噪声的去除能力。实验结果表明,CDW-MDA 在PSNR/SSIM性能指标以及视觉效果方面相比现有的方法更优,在去噪效果和细节保留之间有着更好的平衡。未来的研究将致力于模型泛化能力更强、更轻量级的网络以提高模型的实际应用价值,并拓展到其他图像去模糊和图像超分辨等低级视觉任务中。
参考文献:
[1]张绘娟,张达敏,闫威,等.基于改进阈值函数的小波变换图像去噪算法[J].计算机应用研究,2020,37(5):1545-1548,1552.(Zhang Huijuan, Zhang Damin, Yan Wei, et al. Wavelet transform image denoising algorithm based on improved threshold function[J].Application Research of Computers,2020,37(5):1545-1548,1552.)
[2]王科俊,熊新炎,任桢.高效均值滤波算法[J].计算机应用研究,2010,27(2):434-438.(Wang Kejun, Xiong Xinyan, Ren Zhen. Highly efficient mean filtering algorithm[J].Application Research of Computers,2010,27(2):434-438.)
[3]Dabov K, Foi A, Katkovnik V, et al. Image denoising by sparse 3D transform-domain collaborative filtering[J].IEEE Trans on Image Processing,2007,16(8):2080-2095.
[4]邢遠秀,李军贤,王文波,等.基于非局部自相似序列集的一类视频图像盲去噪算法[J].电子学报,2021,49(8):1498-1506.(Xing Yuanxiu, Li Junxian, Wang Wenbo, et al. Blind video image denoising based on nonlocal self-similarity series sets[J].Acta Electronica Sinica,2021,49(8):1498-1506.)
[5]李小利,杨晓梅,陈代斌.基于块和低秩张量恢复的视频去噪方法[J].计算机应用研究,2017,34(4):1273-1276,1280.(Li Xiaoli, Yang Xiaomei, Chen Daibin. Patch-based video denoising using low-rank tensor recovery[J].Application Research of Computers,2017,34(4):1273-1276,1280.)
[6]Zhang Kai, Zuo Wangmeng, Chen Yunjin, et al. Beyond a Gaussian denoiser: residual learning of deep CNN for image denoising[J].IEEE Trans on Image Processing,2017,26(7):3142-3155.
[7]Zhang Kai, Zuo Wangmeng, Zhang Lei. FFDNet: toward a fast and flexible solution for CNN-based image denoising[J].IEEE Trans on Image Processing,2018,27(9):4608-4622.
[8]Guo Shi, Yan Zifei, Zhang Kai, et al. Toward convolutional blind denoising of real photographs[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2019:1712-1722.
[9]Anwar S, Barnes N. Real image denoising with feature attention[C]//Proc of IEEE/CVF International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2019:3155-3164.
[10]Liu Yang, Qin Zhenyue, Anwar S, et al. Invertible denoising network:a light solution for real noise removal[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2021:13365-13374.
[11]Neshatavar R, Yavartanoo M, Son S, et al. CVF-SID:cyclic multi-variate function for self-supervised image denoising by disentangling noise from image[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2022:17583-17591.
[12]Chen Haoyu, Gu Jinjin, Liu Yihao, et al. Masked image training for generalizable deep image denoising[C]//Proc of IEEE/CVF Confe-rence on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2023:1692-1703.
[13]Zamir S W, Arora A, Khan S, et al. Learning enriched features for fast image restoration and enhancement[J].IEEE Trans on Pattern Analysis and Machine Intelligence,2022,45(2):1934-1948.
[14]Hu Jie, Shen Li, Sun Gang. Squeeze-and-excitation networks[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2018:7132-7141.
[15]Woo S, Park J, Lee J Y, et al. CBAM: convolutional block attention module[C]//Proc of European Conference on Computer Vision.Berlin:Springer,2018:3-19.
[16]尹海濤,邓皓.基于混合注意力的对偶残差去噪网络[J].激光与光电子学进展,2021,58(14):139-148.(Yin Haitao, Deng Hao. Dual residual denoising network based on hybrid attention[J].Laser & Optoelectronics Progress,2021,58(14):139-148.)
[17]Qin Zequn, Zhang Pengyi, Wu Fei, et al. FcaNet: frequency channel attention networks[C]//Proc of IEEE/CVF International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2021:783-792.
[18]Shensa M J. The discrete wavelet transform: wedding the a trous and Mallat algorithms[J].IEEE Trans on Signal Processing,1992,40(10):2464-2482.
[19]Sun Jieqi, Li Yafeng, Zhao Qijun, et al. Cascade wavelet transform based convolutional neural networks with application to image classification[J].Neurocomputing,2022,514:285-295.
[20]Liu Pengju, Zhang Hongzhi, Zhang Kai, et al. Multi-level wavelet-CNN for image restoration[C]//Proc of IEEE Conference on Compu-ter Vision and Pattern Recognition Workshops.Piscataway,NJ:IEEE Press,2018:773-782.
[21]Ronneberger O, Fischer P, Brox T. U-Net:convolutional networks for biomedical image segmentation[C]//Proc of International Conference on Medical Image Computing and Computer-Assisted Intervention.Berlin:Springer,2015:234-241.
[22]徐景秀,張青.改进小波软阈值函数在图像去噪中的研究应用[J].计算机工程与科学,2022,44(1):92-101.(Xu Jingxiu, Zhang Qing. Research and application of an improved wavelet soft threshold function in image denoising[J].Computer Engineering & Science,2022,44(1):92-101.)
[23]陈清江,石小涵,柴昱洲.基于小波变换与卷积神经网络的图像去噪算法[J].应用光学,2020,41(2):288-295.(Chen Qingjiang, Shi Xiaohan, Chai Yuzhou. Image denoising algorithm based on wavelet transform and convolutional neural network[J].Journal of Applied Optics,2020,41(2):288-295.)
[24]Duan Yiping, Liu Fang, Jiao Licheng, et al. SAR image segmentation based on convolutional-wavelet neural network and Markov random field[J].Pattern Recognition,2017,64:255-267.
[25]Kingma D P, Ba J. Adam:a method for stochastic optimization[EB/OL].(2014-12-22).https://arxiv.org/pdf/1412.6980.pdf.
[26]Agustsson E, Timofte R. Ntire 2017 challenge on single image super-resolution: dataset and study[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition Workshops.Piscataway,NJ:IEEE Press,2017:126-135.
[27]Martin D, Fowlkes C, Tal D, et al. A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics[C]//Proc of IEEE International Conference on Computer Vision.Piscataway,NJ:IEEE Press,2001:416-423.
[28]Zhang Lei, Wu Xiaolin, Buades A, et al. Color demosaicking by local directional interpolation and nonlocal adaptive thresholding[J].Journal of Electronic Imaging,2011,20(2):023016.
[29]Abdelhamed A, Lin S, Brown M S. A high-quality denoising dataset for smartphone cameras[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2018:1692-1700.
[30]Plotz T, Roth S. Benchmarking denoising algorithms with real photographs[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE Press,2017:1586-1595.
[31]Loshchilov I, Hutter F. SGDR: stochastic gradient descent with warm restarts[EB/OL].(2016-08-13).https://arxiv.org/pdf/1608.03983.pdf.
[32]Setiadi D R I M. PSNR vs SSIM:imperceptibility quality assessment for image steganography[J].Multimedia Tools and Applications,2021,80(6):8423-8444.
[33]Gu Shuhang, Zhang Lei, Zuo Wangmeng, et al. Weighted nuclear norm minimization with application to image denoising[C]//Proc of IEEE Conference on Computer Vision and Pattern Recognition.Pisca-taway,NJ:IEEE Press,2014:2862-2869.
[34]Tian Cunwei, Xu Yong, Zuo Wangmeng, et al. Designing and trai-ning of a dual CNN for image denoising[J].Knowledge-Based Systems,2021,226:106949.
[35]Ren Chao, He Xiaohai, Wang Chuncheng, et al. Adaptive consistency prior based deep network for image denoising[C]//Proc of IEEE/CVF Conference on Computer Vision and Pattern Recognition.Piscata-way,NJ:IEEE Press,2021:8596-8606.
[36]Jiang Bo, Lu Yao, Wang Jiahuan, et al. Deep image denoising with adaptive priors[J].IEEE Trans on Circuits and Systems for Vi-deo Technology,2022,32(8):5124-5136.
[37]Yu Jiaolong, Zhang Juan, Gao Yongbin. MACFNet: multi-attention complementary fusion network for image denoising[J].Applied Intelligence,2023,53:16747-16761.
[38]Tian Chunwei, Xu Yong, Li Zuoyong, et al. Attention-guided CNN for image denoising[J].Neural Networks,2020,124:117-129.
[39]Vo D M, Nguyen D M, Le T P, et al. HI-GAN:a hierarchical gene-rative adversarial network for blind denoising of real photographs[J].Information Sciences,2021,570:225-240.
[40]Mou Chong, Zhang Jian, Fan Xiaopeng, et al. COLA-Net:collaborative attention network for image restoration[J].IEEE Trans on Multimedia,2021,24:1366-1377.
[41]Zhang Jiahong, Qu Meijun, Wang Ye, et al. A multi-head convolutional neural network with multi-path attention improves image denoi-sing[C]//Proc of Pacific Rim International Conference on Artificial Intelligence.Berlin:Springer,2022:338-351.
[42]Soh J W, Cho N I. Variational deep image restoration[J].IEEE Trans on Image Processing,2022,31:4363-4376.
猜你喜欢
科技与创新(2016年14期)2016-07-23
电脑知识与技术(2016年14期)2016-06-30
电脑知识与技术(2016年8期)2016-05-19
哈尔滨理工大学学报(2015年5期)2016-01-19
科技视界(2015年29期)2015-10-19
软件导刊(2015年6期)2015-06-24
现代电子技术(2014年8期)2014-09-27
现代电子技术(2014年8期)2014-09-27
现代电子技术(2014年13期)2014-07-09
