
面向持久化键值数据库的自适应热点感知哈希索引
2024-02-18 08:13王楠吴云
计算机应用研究 2024年1期
关键词:自适应
王楠 吴云
摘 要:针对现有键值数据库存储系统缺乏热点意识,导致系统在高度倾斜的工作负载下性能较差且不可靠,提出了一种自适应热点感知哈希索引模型,该模型基于key值摘要信息实现了一个高性能哈希表。首先,利用key的摘要信息代替key值,压缩key的存储空间,优化哈希表中桶的数据结构;其次,利用CPU的数据级并行技术以及CPU cache line,对哈希表的探查操作进行优化;最后,为解决摘要信息导致key值无法精准比较,需要额外磁盘I/O的问题,设计了一种自适应key值调度算法,该算法根据当前可用内存大小、哈希索引负载以及访问热点情况动态地调整key值的存储位置。在YCSB仿真数据集上进行了实验,实验表明,相较于最先进的哈希表,自适应热点感知哈希索引在相同内存使用率的情况下,将速度提升至1.2倍。
關键词:持久化键值存储;自适应;热点感知;哈希索引
中图分类号:TP391.9 文献标志码:A 文章编号:1001-3695(2024)01-035-0226-05
doi:10.19734/j.issn.1001-3695.2023.04.0188
Adaptive hot-aware hash index for persistent key-value databases
Abstract:In view of the lack of hotspot awareness in existing key-value database storage systems,which leads to poor perfor-mance and unreliability under highly tilted workloads,this paper proposed an adaptive hot-spot aware hash index model,which implemented a high-performance hash table based on key summary information.Firstly,the paper used the abstract information of key to replace the key value,compressed the storage space of key,and optimized the data structure of the bucket in the hash table.Secondly,the paper optimized the probe operation of hash table by using the data level parallel technique of CPU and CPU cache line.Finally,in order to solve the problem of extra disk I/O due to the inaccurate comparison of key values caused by summary information,this paper designed an adaptive key scheduling algorithm,which dynamically adjusted the storage location of key values according to the current available memory size,hash index load and access hotspot.Experiments on YCSB simulation datasets show that the adaptive hot-spot aware hash index is up to 1.2 times faster than the most advanced hash table for the same memory usage.
Key words:persistent key-value store;self-adaptation;hot spot perception;hash index
0 引言
早期的索引技术是基于人类经验构造的启发式数据结构[1],常见的索引结构有哈希表[2]、平衡/前缀树(如B树[3]、tire树以及mass tree等)、跳表(skip list)、日志合并树[4](log structure merge tree,LSM-Tree)等。由于数据查询条件的多样性,不同的索引结构有着不同的设计实现与应用场景。其中哈希表因其超快的读写速度成为了键值数据库存储系统中最常用的索引结构,如Redis[5]、Memcached[6]等内存键值数据库存储系统。特别是当上层应用程序不需要范围查询时,哈希表的性能直接影响了系统插入、删除、更新、查询等基本操作的性能[7]。哈希索引常用于对海量数据的高效检索或者对热点数据的缓存。热点问题是现实应用场景中常见的问题,在文献[8~12]中已被广泛研究。有许多解决方案用于解决集群范围内的热点问题,例如一致性哈希[13]、数据迁移[14~16]和前端数据缓存[17~20]等。此外,单机热点问题也得到了很好的解决。例如,计算机体系结构利用分层存储布局(例如:磁盘、RAM、CPU缓存)来缓存频繁访问的数据。然而,键值数据库存储系统内部的热点问题通常被忽视。且在如今的实际生产环境中,工作负载愈加复杂多样化,即使在单个工作负载中,这些特征也会随着时间的推移而变化。
然而现有的哈希索引结构通过相同的策略来管理所有的键值对,缺乏热点意识,无法感知外部工作负载的规律,也无法动态调整自身结构以提升性能,导致它在高度倾斜的工作负载下性能较差且不可靠。例如在传统的基于链式冲突的哈希索引中,热点key与冷key随机放置在碰撞链表中,因此它们的访问成本是相同的。即假设有N个键值对存储在一个包含B个桶的哈希表中,每个桶的冲突链表的平均长度为L=N/B。在冲突链中检索一个key的内存平均访问次数为1+L/2,其中1代表哈希表中桶的查找。在一个理想的热点感知哈希索引中,查询一个key所需的内存访问次数应该与这个热点成负相关,即越频繁访问的key,它的访问代价越低。
虽然可以通过扩大哈希表(即通过重新哈希)以减少冲突链的长度,从而减少内存访问次数,然而内存有限,哈希表的长度无法无限扩展,对于两个连续的rehash操作,第二个操作需要两倍的内存空间,但只带来一半的效率(就链长度减少而言),且重新哈希的代价不小。于是研究人员提出了许多缓存友好的索引结构,例如利用CPU的cache加速对热点数据的访问(即以64 Byte大小的cache line为单位),然而对于大多数服务器而言,CPU的cache大小约为32 MB,然而整个内存大小可以超过256 GB,导致只有0.012%的内存可以被缓存,远低于现实应用场景中的热点比率。
研究人员通过研究发现,如果哈希表不存在任何哈希冲突,那么热点问题将不复存在,因为它的所有操作都可以达到 O(1)的时间复杂度。于是最小完美哈希的核心思想就是構建一个没有冲突的哈希表,然而它无法支持插入操作。随着人工智能技术的发展,研究学者们认为机器学习模型的本质是一个映射函数,故可以使用机器学习模型代替哈希函数,学习key和value之间CDF分布关系,从而有效地压缩key的存储空间并减少哈希冲突,然而结果却是机器学习模型的计算代价太过昂贵,无法有效提升哈希索引的性能。
Hot-Ring[21]使用链地址法解决哈希冲突,并将碰撞链表替换为有序环结构,通过移动头部指针靠近热点项来提供对热点项的快速访问。它还应用了一种轻量级策略来解决运行时的热点漂移问题。为显著提高该结构在并发场景下的吞吐量,Hot-Ring在设计上全面采用无锁结构,例如基于原子的读-拷贝-更新(read-copy-upadate,RCU)[22]和危险指针[23]比较(CAS)。这种方法依旧没有从根源上解决热点问题,它只支持冲突链上的单热点问题;它为了支持对哈希索引的无锁访问使用了链表结构,需要使用额外内存空间存放指针,并且指针的访问效率较低,这种方法适用于哈希冲突非常严重以及将数据主要存放于内存中的场景,但对于将哈希索引应用到对慢速设备中数据进行索引的场景,该方法的性能存在巨大瓶颈。
BitHash[24]提出了一种基于位图的哈希优化方案,使用数据分块的设计,提取键的公共前缀,从而压缩键的存储空间,并在数据块内通过层级位图的设计避免冲突,最终提供高效范围查询的能力。这种方法由于使用了布隆过滤器作为辅助结构,导致它无法应对哈希索引的删除场景,且该方法的性能不尽如人意。
综上所述,所有现有的方法都只能在一定程度上缓解热点问题,为了解决上述模型存在的问题,本文提出一个自适应热点感知哈希索引模型。本文主要贡献如下:
a)针对哈希索引使用内存空间有限,导致哈希冲突概率较高的问题,提出了一种key值压缩方案,利用简要key值摘要信息代替key值本身,优化哈希表中桶的数据结构,有效增大了哈希索引的可用内存空间,从根源上极大地避免了哈希冲突,提高哈希索引的访问效率。
b)针对开放寻址法的线性探查代价会随着哈希索引负载因子的提高而增大的问题,提出了一种探查优化方案,利用CPU的SIMD指令以及cache优化哈希索引在探查过程中的查找比较操作,避免在使用开放地址法解决哈希冲突时因多次探测造成的效率下降问题。
c)针对摘要可能导致key值比较不准确,需要额外访问磁盘的问题,设计了一种自适应key值调度算法,根据当前可用内存大小、哈希索引负载以及访问热点情况动态地调整key值的存储位置。
1 本文方法
以往传统键值数据库存储系统主要将数据以key-value pair的形式存储在磁盘之中,并在内存中为key建立合适的索引结构,保存key值本身以及value的元信息(如value在磁盘中的存储地址以及大小等信息),使得系统可以根据key快速精准检索对应的value的元信息,然而这种哈希索引的方式需要付出大量的内存空间用于保存key值本身,导致哈希索引可用的内存急剧减少,尤其是当key值非常大时,使得哈希索引,不仅从根源上增大了哈希冲突的概率,使得哈希索引的效率不尽如人意;还导致哈希桶中无法存放key值本身,只能存放指向key值的指针,使得空间浪费且性能较低。本文提出的自适应热点感知哈希表尽量使用定长且精简的key值摘要信息替代key值本身,即只在内存中存放key的摘要信息,将key值放入慢速存储设备。牺牲一定的准确性,获取极大的内存使用率,从而增大哈希索引的可用内存量,从根源上极大减少了哈希冲突概率,并且对哈希桶的结构布局进行了优化;且利用CPU SIMD指令以及cache保证模型在负载因子较高时的稳定性能。当遇到摘要信息相同,但key值不相同时,该模型会将摘要信息相同的所有key全部调入内存,保证极端情况下模型的性能。并根据一定的策略识别热点数据,将热数据的key移入内存。
1.1 模型概述
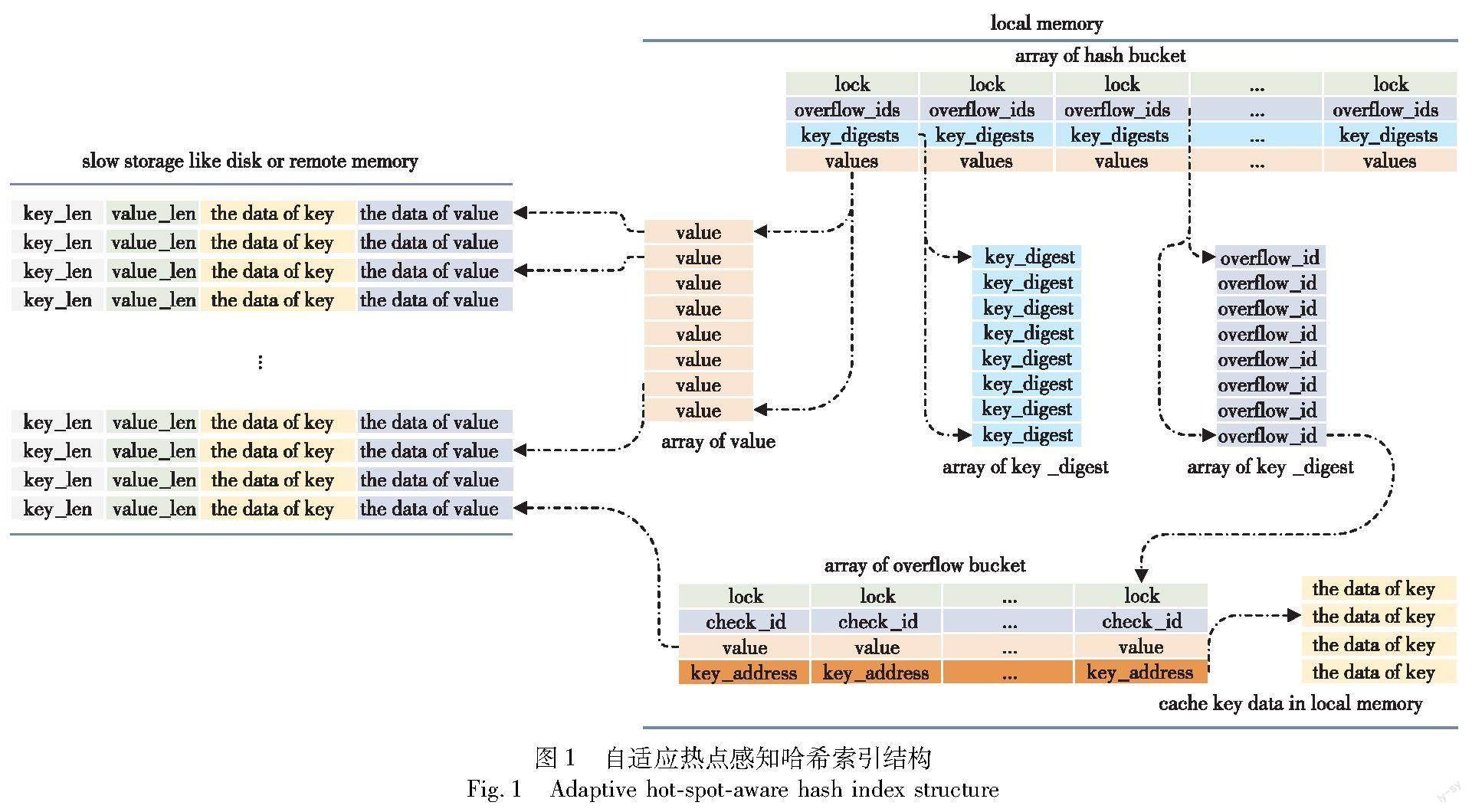
自适应热点感知哈希索引模型底层的数据结构是自适应热点感知哈希表。图1展示了自适应热点感知哈希表的结构,为使得哈希表的性能最大化,哈希表使用空间紧凑的哈希桶数组作为底层基本数据结构。假设哈希桶数组的长度为N,每个哈希桶的大小与机器的cache line对齐(即单个哈希桶的大小为cache line大小的倍数)。其中哈希表中存放value代表的是key-value pair的元信息,该元信息包含键值对在磁盘中的起始地址、key的大小、value的大小等信息。哈希表中key代表的含义是key的摘要信息。例如将(good luck to you ,thank)键值对插入键值数据库存储系统时,其中good luck to you的摘要为66,键值对的元信息为meta,模型会将(66 ,meta)插入自适应热点感知哈希索引。
该模型使用开地址法作为取模冲突的解决策略,即key的hash值对N取模相同时使用线性探测,最大的探测距离设置为MAX_HOPS。使用链地址法作为哈希碰撞的解决策略,即每个hash值相同的key使用溢出桶保存,并在哈希桶中使用overflow_id指向该溢出桶,溢出桶中也使用check_id表示该溢出桶属于那个hash值,溢出桶中包含key_address(指向key在内存中的存储位置)以及键值对元信息;该模型使用墓碑标记法作为删除策略,每次删除数据时只需要简单地将对应位置的key_digest值置为DELETED即可。使用细粒度锁作为自适应热点感知哈希索引的并发解决方案,即在每个哈希桶中存放一个锁。并充分利用x86系统的MESIF protocol协议,保证对短于一个字的内存读写的原子性,使得本文提出的哈希表能够在查找阶段支持无锁并发。
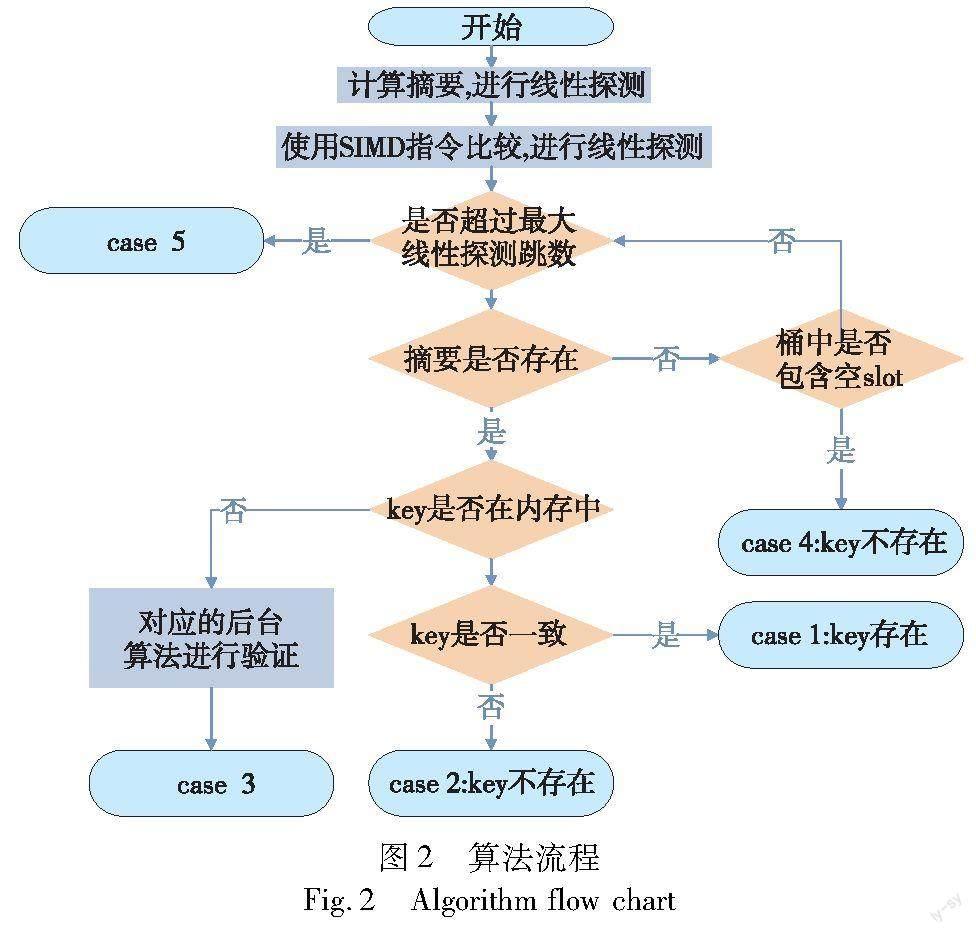
图2展示了自适应热点感知索引查找、插入、删除算法的运行流程。首先需要判断在合理的跳数内能否在哈希桶数组中查询到指定的摘要信息;随后判断摘要对应的key值本身是否存在内存中;最后验证key值是否一致。
1.2 查找算法
如图2所示,先计算出需要查找key的哈希值,为了后续有效地查找、插入、删除,并通过(hash & 0x7fffffffffffffff) + 1)计算出key值摘要信息,确保摘要一定恒大于0,一定不等于0xffffffffffffffff。因为摘要为EMPTY(0)代表该位置为空,摘要值为DELETED(0xffffffffffffffff)代表该位置存在过元素,但被删除了;该自适应热点感知哈希表使用细粒度锁解决并发冲突;随后从目标桶开始进行线性探测,在每个桶内使用SIMD指令快速比对桶内摘要信息,直到遇到以下五种情况:
case 1:哈希表中存在多个有相同摘要的键值对,根据本文模型方法,此时它们对应的键全部在内存中,且需要查找的key存在,直接返回该key对应的value元信息即可。
case 2:哈希表中存在多个有相同key_digest的键值对,根据论文模型方法,此时它们对应的键全部在内存中,但是需要查找的key并不存在,直接返回false。
case 3:哈希表中存在一个摘要,且与需要查找key的摘要相同,此时无法判断哈希表中的键是否与key一致(可能存在hash(key1)=hash(key2)=key_digest,但是key1不等于key2的情况),此时只需要将该摘要对应的meta返回即可。后续由上层应用根据meta信息从慢速设备中读取真正的real_key-real_value对,如果real_key与key相同,那么返回real_value,否则说明键值对不存在(对慢速设备中键值对的索引而言,索引本身只会存放value元信息,value数据是存放在慢速设备中,所以一次慢速设备的访问必不可少)。为了避免外界对该索引的恶意访问(即哈希表中存在key1,它的摘要为key_digest,但是用户频繁访问的摘要也为key_digest的key2),导致慢速设备的不必要访问,降低了整个系统的性能,所以模型需要将访问过程中所有摘要相同的key值全部调入内存。
case 4:探查过程中遇到了存在空闲位置的哈希桶,说明需要查询的key值不存在,返回false。
case 5:查找过程中超过了线性探测允许的最大跳数,即需要查询的key值不存在,返回false。
1.3 插入算法
插入算法基于查找算法实现,故插入流程和查找流程一样也有五种不同的情况。以下使用具体五个插入例子进行介绍,下面的插入依次进行。
a)向哈希表中插入(key1,value1),key1的摘要值為key_digest1,且哈希表中没有摘要key_digest1,此时进入case 4,查找到空闲位置插入即可。为避免后续哈希表的性能下降,故优先选择摘要为DELETED的位置进行插入,随后将key_digest1以及key1-value1 pair的元信息插入即可。
b)向哈希表中接着插入(key2,value2),key2的摘要值也为key_digest1,由于上面流程中哈希表内已经存在了一个摘要为key_digets1的键,但key_digest1不存在有效溢出桶,此时进入case 3,故首先为该key_digest1分配一个新的溢出桶,接着记录上一个摘要为key_digest1的(key1,value1)的数据,并假设该操作为更新操作,直接更新当前key_digest1的key-value pair,随后启动后台线程,检查假设是否成立。
算法1 后台插入算法
输入:新的key值new_key,新的value值new_value,需要检查的old_value元信息(记录了在慢速设备中key的值以及value的值),溢出桶数组overflow_buckets,已经分配了的溢出桶id new_overflow_bucket_id,该溢出桶属于哪个key_digest
auto overflow_bucket=overflow_buckets[new_overflow_bucket_id];
unique_lock(overflow_bucket->lock);//获取溢出桶,并加锁
overflow_bucket->check_id=key_digest;/*为溢出桶设置属于的对象*/
//get old_key from slow storage;//从慢速设备中获取old_key值
if(new_key==old_key)/*如果new_key与old_key相同,那么说明是更新操作*/
if(update num exceed threshold)/*如果该key更新操作超过了一定的阈值,那么将key从慢速设备中调入内存*/
insert key new_value into overflow_bucket;
else
overflow_bucket->check_id=-1;
recycle overflow_bucket;//回收溢出桶
return;
allocate another_overflow_bucket and its id is another_overflow_bucket_id;//如果是新增操作,那么再次分配一个溢出桶
another_overflow_bucket->check_id=key_digest;
overflow_bucket->key=new_key,overflow_bucket->value=new_value
another_overflow_bucket->key=old_key,anothrer_overflow_bucket->value=old_value;//
overflow_bucket->next_id = another_overflow_bucket_id;
如果检查为更新操作,且更新操作超过了一定的比例,为避免后续对该key的持续更新,导致系统出现不必要的磁盘I/O与后台线程开销,那么会将当前key值本身调入内存;否则如果为新增操作,那么会再次分配一个新的溢出桶,并将key1,key2值全部调入内存,避免后续无法精准对比导致磁盘I/O以及后台线程的开销。
c)向哈希表中接着插入(key1,value3),此时进入case 1,即哈希表存在key_digest1,且已经将摘要为key_digest1的所有key值全部调入内存,并且比较发现key1已经存在,所以可以直接更新key1对应的value值即可。
d)向哈希表接着插入(key3,value4),进入case2,即哈希表存在key_digest1,且已经将摘要为key_digest1的所有key值全部调入内存,并且比较发现key3不存在,所以可以判断key3为新增操作,直接将key3插入溢出桶即可。
e)case 5代表插入失败,此类情况只有在负载因子过高的情况下有极小的概率会出现,但由于自适应热点感知哈希表对key值本身所占用的内存进行压缩,增大了哈希桶数组的数量,有效减少了取模冲突的概率,使得插入失败的概率几乎忽略不计。算法也可通过调整MAX_HOPS参数值避免此类情况。
1.4 删除算法
删除算法是基于查找算法实现的,故删除流程也有五种不同的情况,由于其中case 1、case 2、case 4、case 5都可以准确地判断key值是否存在,故可以直接进行删除操作,而case 3只能判断摘要存在却无法判断key值是否存在,即哈希表中存在摘要为key_digest的键,且需要删除键del_key的摘要也为key_digest,但无法判断哈希表中存在的键是否与del_key一致。虽然这种情况的概率非常之低,如工业哈希函数能够保证单个key为16 Byte时100 GB的测试中只有332次的哈希碰撞。但模型依然需要实现一个完善的解决方案。
模型会为key_digest分配一个新的溢出桶,接着记录摘要为key_digest的(key1,value1)的数据,并假设key1与del_key一致,直接删除当前key_digest的key-value pair,随后启动后台线程,检查假设是否成立。为避免后续线程立即查找key1,模型需要对key_digest的溢出桶进行加锁,并在后台线程执行完毕后才会进行解锁。检查算法的伪代码如算法2所示。
算法2 后台删除算法
输入:需要删除的key值del_key,需要检查的old_value元信息(记录了在慢速设备中old_key的值以及value的值),溢出桶数组overflow_buckets,已经分配了的溢出桶id new_overflow_bucket_id,该溢出桶属于哪个key_digest,del_key属于哪个哈希桶bucket,在哈希桶中的位置pos。
auto overflow_bucket=overflow_buckets[new_overflow_bucket_id];
unique_lock(overflow_bucket->lock);//获取溢出桶,并加锁
overflow_bucket->check_id=key_digest;/*为溢出桶设置属于的对象*/
get old_key from slow storage;//从慢速设备中获取old_key值
if(del_key==old_key){/*如果del_key与old_key相同,那么说明删除正确*/
insert old_key null into overflow_bucket;
Un_Lock(overflow_bucket->lock);
//将溢出桶中的old_key标记为已删除,并解锁桶
unique_lock(bucket->lock);
bucket->overflow_ids[pos]=-1;
bucket->key_digets[pos]=DELETED;
recycle overflow_bucket;/*尝试将del_key所在哈希桶中的元素标记为已删除,并回收溢出桶*/
return;}
insert old_key old_value into overflow_bucket;/*删除错误,发生哈希冲突,将(old_key,old_value)调入内存*/
如果假设成立,那么先將溢出桶中的键值对标记为删除状态,随后将该键所在哈希桶的位置标记为删除,并回收溢出桶;如果假设不成立,说明发生了哈希碰撞,为避免后续应用连续针对该缺陷对系统进行攻击,导致不必要的磁盘I/O与系统后台线程启动,那么此时需要将所有摘要为key_digest的所有key全部调入内存。
2 实验
2.1 实验环境
本文所有实验均在Intel Xeon Gold 5220 CPU@2.20 GHz、64 GB内存、72核心的Linux系统中完成,该型号CPU 的L1数据/指令cache大小分别为32 KB、L2 cache大小为1 024 KB、L3 cache大小为25 344 KB、cache line大小为64 Byte、支持AVX512指令。算法实现语言为C++。设置插入key的大小恒为16 Byte,value大小恒为8 Byte,key的摘要大小为8 Byte。
2.2 数据集
为了评价提出的自适应热点感知哈希索引的性能和泛化能力,本文参考阿里巴巴第四届全球数据库竞赛以及YCSB数据集构建了6个测试数据集,分别测试索引的单线程下新增、查找、删除、热点更新、热点查找性能以及多线程下操作性能。该数据集覆盖了实际应用场景下常见的工作负载,能够综合全面地考量模型在复杂多变的实际工业应用场景下的表现性能。
a)Workload A:单线程负载,插入测试,随机插入1千万条键值对。
b)Workload B:单线程负载,热点混合测试,随机插入1千万条键值对,随后查找1千万次,最后删除1千万次。其中删除操作中有75%的操作具有热点特征,即大部分的操作集中在少量的key上。
c)Workload C:单线程负载,泛化能力测试,插入1千万条键值对,随后顺序查找所有元素,顺序更新所有元素,按照75%的热点比例查找1千万次以及更新1千万次。最后热点删除1千万次数据。最后顺序删除所有数据。
d)Workload D:多线程负载,读写测试,每个线程分别写入1千万条数据,并随后顺序读取所有数据,随后更新数据。
e)Workload E:多线程负载,更新删除测试,分别写入1千万条数据,并多线程对所有的元素进行删除操作。
f)Workload F:多线程负载,热点读写混合测试,每个线程以75%:25%的读写比例调用64 M次,其中75%的读访问具有热点的特征,大部分的读访问集中在少量的key上面。
2.3 实验结果分析
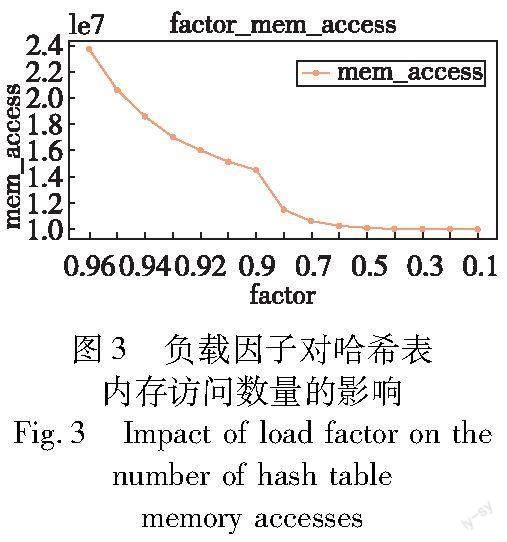
2.3.1 负载因子对哈希表的影响
图3展示了自适应热点感知哈希表使用不同的负载因子,在Workload A上内存访问数量的变化趋势。其中当负载因子为0.97时,哈希表超过了线性探查允许的最大跳数,导致插入失败。当负载因子为0.1~0.6时,基本只需要一次内存访问即可插入成功。随着负载因子的增加,单次操作所需的内存访问数量急剧上升,到最后负载因子为0.9时,每增加0.01的负载因子,内存访问数量都会成线性递增。负载因子较高导致哈希桶数组中空槽的数量减少,从而使得哈希表的单次操作需要多次key值的比较操作。
2.3.2 SIMD指令对哈希表的影响
如图4所示,展示了当负载因子为0.96时,在Workload B上进行实验,实验结果表明,相较于使用FOR LOOP进行查找的哈希索引而言,使用SIMD指令进行快速查找的哈希索引单次操作能够平均减少30%的时间。FOR-LOOP性能较差是因为该方式需要对哈希桶中的key值直接比较,需要if else语句判断比较结果,而CPU的分支预测技术有可能会导致指令流水线的失败;且当key值较大且负载因子较高时,需要大量的字符串比较操作,会相当耗时;如果key值没有直接存放在哈希桶中时,更需要额外的指针操作取到key值本身,导致内存的随机访问,造成cache失效。而SIMD指令利用数据级并行技术,可以使用几条指令即可对多个数据进行并行比较,且通过位运算代替了if else命令,极大限度地保证了指令流水线的正常运行。
2.3.3 cache line 对齐对哈希表的影响
如图5所示,展示了在Workload B上cache line对齐对哈希表操作的影响,实验结果表明,cache line对齐能有效提升20%左右的性能。cache line对齐是因为CPU访问内存的最小粒度为cache line大小,如果哈希桶的大小不对齐cache line时,会导致不必要的内存访问。如哈希桶虽然大小仅为63 Byte,但却未对齐cache line,那CPU需要读取内存两次,分别将该桶放置在两个缓存行中;因CPU cache保证了短于一个字大小的内存具有原子性,导致并发条件下对两个独立哈希桶的操作可能无法实现真正的并行;最后SIMD指令要求比较的数必须在一个cache line中。
2.3.4 自适应热点感知哈希索引与最新哈希表的性能对比
std::unordered_map:C++标准库中自带的哈希表。
ska::flat_hash_map:搜索性能非常好,特别是对于少量的条目,但是内存使用率非常高。
ska::bytell_hash_map:类似谷歌的absl::flat_hash_map。插入和擦除非常快,查找速度还可以。内存使用率相当好。
robin_hood::unordered_flat_map:对于整数的查找、插入和删除非常快,迭代相对较慢。
ankerl::unordered_dense::map:robin_hood的升级版,目前速度最快的哈希表实现,通过结合robin_hood::unordered_flat_map的思想并使用简单的std::vector作为存储,搜索速度非常快,但是删除一个元素可能相对较慢,它需要两次查找,因为映射始终保持一个密集存储的向量。
表1展示了在使用内存量相同的条件下,在Workload C上进行实验,自适应热点感知哈希表与最先进的哈希表的性能对比结果。实验结果表明,自适应热点感知哈希索引由于对key值的压缩,增大了哈希桶数组的大小,有效减少了哈希沖突,在插入、查找以及热点更新操作拥有更高的性能,相比最先进的哈希表,提升了接近20%的性能。但当遇到顺序删除以及顺序更新的操作时,由于key值摘要导致key值无法精准比较,即使使用后台线程以及提前预判尽可能地减少性能损耗,额外的磁盘I/O确认依然导致此类型的操作存在性能瓶颈。
2.3.5 多线程并发性能
图6展示了本模型在Workload D、Workload E、Workload F三种负载下1 线程到 16 线程吞吐量的实验结果,实验表明在热点操作为主的Workload F中,模型可以基本达到线性加速比。本模型使用细粒度锁作为并发冲突解决方案,即在每个桶中存放一个锁,可以简单有效地提升哈希表的并发性能。本实验中锁使用自定义实现的细粒度锁,并基于x86系统使用MESIF protocol协议,具有较强的memory order保证特性,在搜索操作的探查阶段并不加锁。
3 结束语
本文探讨了负载因子、SIMD指令、cache line对齐对哈希表性能的具体影响,并意识到现有的哈希索引性能较低且缺乏热点意识的根本原因是内存有限,导致哈希冲突加剧,且使用统一的策略来管理所有的键值对,故提出了自适应热点感知哈希索引模型。本文将提出的模型在YCSB仿真数据集上与最新哈希表进行对比实验,并表现出了较大的性能提升。
目前该自适应热点感知哈希索引模型只适用于对慢速设备中的数据进行索引,无法将其应用在如Redis、Memcached等内存键值数据库存储系统中。因此在接下来的研究中,可以探索一种用于解决内存键值数据库存储系统热点问题的模型。
参考文献:
[1]蔡盼,张少敏,刘沛然,等.智能数据库学习型索引研究综述[J].计算机学报,2023,46(1):51-69.(Cai Pan,Zhang Shaomin,Liu Peiran,et al.A review of research on intelligent database learning index[J].Chinese Journal of Computers,2023,46(1):51-69.)
[2]Maurer W D,Lewis T G.Hash table methods[J].ACM Computing Surveys,1975,7(1):5-19.
[3]Graefe G.Modern B-tree techniques[J].Foundations and Trends in Databases,2011,3(4):203-402.
[4]ONeil P,Cheng E,Gawlick D,et al.The log-structured merge-tree(LSM-tree)[J].Acta Informatica,1996,33:351-385.
[5]Carlson J.Redis in action[M].[S.l.]:Manning Publications,2013.
[6]Fitzpatrick B.Distributed caching with Memcached[J].Linux Journal,2004(124):72-76.
[7]邓莹莹.布谷鸟哈希表的优化及其应用[D].南京:南京邮电大学,2021.(Deng Yingying.Optimization and application of cuckoo hash table[D].Nanjing:Nanjing University of Posts and Telecommunications,2021.)
[8]Atikoglu B,Xu Yuehai,Frachtenberg E,et al.Workload analysis of a large-scale key-value store[C]//Proc of the 12th ACM SIGMETRICS/PERFORMANCE Joint International Conference on Measurement and Modeling of Computer Systems.2012:53-64.
[9]Cooper B F,Silberstein A,Tam E,et al.Benchmarking cloud serving systems with YCSB[C]//Proc of the 1st ACM Symposium on Cloud Computing.2010:143-154.
[10]Harter T,Borthakur D,Dong S,et al.Analysis of{HDFS}under HBase:a Facebook messages case study[C]//Proc of the 12th USENIX Conference on File and Storage Technologies.2014:199-212.
(下转第253页)
(上接第230頁)
[11]Huang Qi,Gudmundsdottir H,Vigfusson Y,et al.Characterizing load imbalance in real-world networked caches[C]//Proc of the 13th ACM Workshop on Hot Topics in Networks.2014:1-7.
[12]Jung J,Krishnamurthy B,Rabinovich M.Flash crowds and denial of service attacks:characterization and implications for CDNs and Web sites[C]//Proc of the 11th International Conference on World Wide Web.2002:293-304.
[13]David K,Eric L,Tom L,et al.Consistent hashing and random trees:distributed caching protocols for relieving hot spots on the World Wide Web[C]//Proc of the 29th Annual ACM Symposium on Theory of Computing.1997:654-663.
[14]Cheng Yue,Gupta A,Butt A R.An in-memory object caching framework with adaptive load balancing[C]//Proc of the 10th European Conference on Computer Systems.2015:1-16.
[15]Dabek F,Kaashoek M F,Karger D,et al.Wide-area cooperative sto-rage with CFS[J].ACM SIGOPS Operating Systems Review,2001,35(5):202-215.
[16]Taft R,Mansour E,Serafini M,et al.E-store:fine-grained elastic partitioning for distributed transaction processing systems[J].Procee-dings of the VLDB Endowment,2014,8(3):245-256.
[17]Fan B,Lim H,Andersen D G,et al.Small cache,big effect:provable load balancing for randomly partitioned cluster services[C]//Proc of the 2nd ACM Symposium on Cloud Computing.2011:1-12.
[18]Jin Xin,Li Xiaozhou,Zhang Haoyu,et al.Netcache:balancing key-value stores with fast in-network caching[C]// Proc of the 26th Symposium on Operating Systems Principles.2017:121-136.
[19]Li Xiaozhou,Sethi R,Kaminsky M,et al.Be fast,cheap and in control with SwitchKV[C]// Proc of the 13th USENIX Symposium on Networked Systems Design and Implementation.2016:31-44.
[20]Mattson R L,Gecsei J,Slutz D R,et al.Evaluation techniques for sto-rage hierarchies[J].IBM Systems journal,1970,9(2):78-117.
[21]Chen Jiqiang,Chen Liang,Wang Sheng,et al.Hot-Ring:a hotspot-aware in-memory key-value store[C]//Proc of the 18th USENIX Conference on File and Storage Technologies.2020:239-252.
[22]Desnoyers M,McKenney P E,Stern A S,et al.User-level implementations of read-copy update[J].IEEE Trans on Parallel and Distributed Systems,2011,23(2):375-382.
[23]Michael M M.Safe memory reclamation for dynamic lock-free objects using atomic reads and writes[C]// Proc of the 21st Annual Sympo-sium on Principles of Distributed Computing.2002:21-30.
[24]王天宇,徐云,王彪.基于位圖的键值存储哈希优化[J].计算机应用研究,2023,40(7):2106-2110.(Wang Tianyu,Xu Yun,Wang Biao.Optimization of key value storage hash based on bitmap[J].Application Research of Computers,2023,40(7):2106-2110.)
猜你喜欢
计算机应用(2016年12期)2017-01-13
中国教育信息化·基础教育(2016年11期)2016-12-27
软件导刊(2016年11期)2016-12-22
科技视界(2016年26期)2016-12-17
科教导刊·电子版(2016年26期)2016-11-21
汽车科技(2016年5期)2016-11-14
中国新通信(2016年16期)2016-10-18
科教导刊·电子版(2016年21期)2016-08-23
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年13期)2016-06-29
