
基于超图卷积网络和目标多意图感知的会话推荐算法
2024-02-18 20:50王伦康高茂庭
计算机应用研究 2024年1期
关键词:注意力机制
王伦康 高茂庭
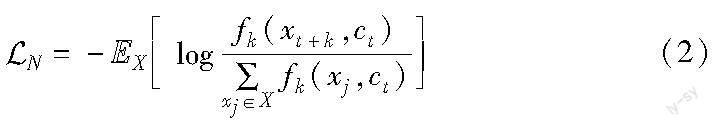

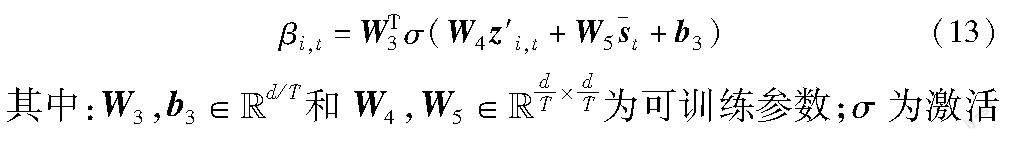
摘 要:当前先进的会话推荐算法主要通过图神经网络从全局和目标会话中挖掘项目的成对转换关系,并将目标会话压缩成固定的向量表示,忽略了项目间复杂的高阶信息和目标项目对用户偏好多样性的影响。为此提出了基于超图卷积网络和目标多意图感知的会话推荐算法HCN-TMP。通过学习会话表示来表达用户偏好,首先依据目标会话构建会话图,依据全局会话构建超图,通过意图解纠缠技术将原有反映用户耦合意图的项目嵌入表示转换为项目多因素嵌入表示,再经图注意力网络和超图卷积网络分别学习目标会话节点的会话级和全局级项目表示,并使用距离相关性损失函数增强多因素嵌入块间的独立性;然后嵌入目标会话中节点位置信息,加权每个节点的注意力权重,得到全局级和会话级会话表示;利用对比学习最大化两者互信息,经目标多意图感知,针对不同的目标项目自适应地学习目标会话中多意图的用户偏好,得到目标感知级会话表示,最后線性融合三个级别的会话表示得到最终的会话表示。在Tmall和Nowplaying两个公开数据集上进行大量实验,实验结果验证了HCN-TMP算法的有效性。
关键词:图神经网络; 会话推荐; 意图解纠缠; 注意力机制; 自监督学习
中图分类号:TP301.6 文献标志码:A 文章编号:1001-3695(2024)01-005-0032-07
doi:10.19734/j.issn.1001-3695.2023.05.0199
Session-based recommendation algorithm based on hypergraph convolution network and target multi-intention perception
Abstract:The current advanced session recommendation algorithms mainly use graph neural network to mine the pairwise transformation relationships of items from the global and target sessions, and compress the target session into a fixed vector representation, ignoring the complex high-order information between items and the impact of target items on user preference diversity. To this end, this paper proposed a hypergraph convolution network and target multi-intention perception for session-based recommendation algorithm HCN-TMP. This algorithm expressed user preference by learning session representation. Firstly, it constructed a session graph based on the target session, and constructed a hypergraph based on the global session. It transformed the original item embedding representation that reflected the users coupling intention into a multi factor embedding representation of the item through intention disentanglement technology. Then, it learned the item representations of the session level and global level of the target session node through graph attention network and hypergraph convolutional network respectively, and used the distance correlation loss function to enhance the independence between the multi-factor embedded blocks. Next, it embedded the node location information in the target session, weighted the attention weight of each node, and got the session representation of the global level and session level. It used comparative learning to maximize the mutual information of the two. Through the target multi-intention perception, it adaptively learned the multi-intention user preferences in the target session for different target items, obtained the session representation of the target perception level. Finally, it linearly fused the three level session representations to obtain the final session representation. This paper carried out the experiments on two public data sets, Tmall and Nowplaying. The experimental results verify the effectiveness of the HCN-TMP algorithm.
Key words:graph neural network; session-based recommendation; intent disentanglement; attention mechanism; self-supervised learning
0 引言
随着互联网信息量爆炸式增长,大量信息涌现在用户面前。由于用户时间和精力有限,无法查看所有信息,推荐系统作为一个重要的信息过滤工具,通过帮助用户推荐其感兴趣的物品,发挥着重要作用。传统推荐算法学习用户模型[1,2]或依赖用户长期行为[3,4]进行推荐,然而在一些匿名推荐场景中,因为用户信息不可知,且只能获取用户短期行为,无法挖掘其历史偏好和长期偏好,导致推荐效果不佳。基于会话的推荐系统(session-based recommendation system,SRS) [5]通过给定用户匿名的连续行为序列预测下一个可能与之交互的项目,因其高效且高实用而引起广泛关注。
SRS的现有工作主要分为传统方法[6~8]、基于序列化的方法[9~12]和基于GNN(graph neural network)的方法。传统方法通过相似性规则[6]或马尔可夫链[7,8]进行建模来预测下一个可能交互的项目,前者严重依赖目标会话中的共现信息,忽略了其他有用信息,后者假设下一个项目完全基于前一个项目,无法捕捉长期的顺序依赖。基于序列化的方法主要通过RNN(recurrent neural network)或其变体方法来挖掘会话的顺序特征,尽管已经取得了显著的性能提升,但这些方法忽略了项目的复杂转换,不足以在会话中获得准确的用户表示。基于GNN的方法将会话构建成图结构,通过在图上传播和更新项目的嵌入表示,经注意力机制融合目标会话中项目的嵌入表示得到最终的会话表示来表达用户偏好,从而捕捉项目复杂的转换关系。
近几年,国内外学者所做SRS的工作结果表明,基于GNN的方法比传统方法和基于序列化的方法具有显著的优势,因此基于GNN的SRS成为主流的研究方向。Wu等人[13]提出了SR-GNN模型,通过门控图神经网络学习会话图中项目的嵌入表示,开创了使用GNN解决SRS问题的先例;Xu等人[14]在GNN模块后应用自注意力机制融合上下文信息去捕捉项目相关性;Yu等人[15]在SR-GNN的基础上,将目标项目的特征通过注意力机制集成到会话表示学习中,取得了更好的效果。以上基于GNN的方法仅考虑目标会话的项目转移关系,忽略来自其他会话的协同信息,导致无法充分挖掘用户偏好。为了解决这个问题,融合协同信息[16~19]的方法被提出,Zheng等人[16]同时考虑目标会话和近邻协同会话,通过双通道SGCN模块学习项目两种类型的嵌入表示;文献[17~19]同时考虑目标会话和全局协同会话,通过构建会话图和全局图学习会话内和会话间的信息,用协同信息增强目标会话,以解决目标会话数据稀疏的问题。一般GNN只能挖掘项目的成对转换关系,忽略了项目的高阶转换关系,文献[20~22]用超图神经网络(hypergraph neural network,HGNN)[23]来学习项目的嵌入表示,从而挖掘高阶信息。此外,用户采用某项目的意图是由该项目多因素决定的,每个交互项都可以被视为耦合意图的结果[24],因此基于意图解纠缠的方法被应用到基于GNN的SRS中[22,25,26]。当前基于意图解纠缠的方法虽然考虑到用户采用某物品的意图是由该物品多因素决定的,有较好效果,但依旧存在问题。目标会话被压缩成固定的会话表示,忽略了目标项目对用户偏好多样性的影响。
在网上购物场景中,给定一个目标会话(A品牌蓝牙耳机、B品牌手机、C品牌蓝牙耳机、C品牌电脑、D品牌手机),在不考虑目标项目的情况下,用户可能有如下三种意图:用户点击了A品牌蓝牙耳机和C品牌蓝牙耳机,可能是想购买蓝牙耳机;用户点击了B品牌手机和D品牌手机,可能是想购买一款智能手机;用户点击了B品牌蓝牙耳机和C品牌电脑,可能对C品牌的商品情有独钟。目标会话中所体现的用户意图是多样的,很难达到精确推荐的目的。当引入目标项目某品牌手机,就能很好地解决这个问题,某品牌手机属于用户意图中某品牌商品和智能手机的范畴,削弱了用户购买蓝牙耳机的意图,缩小了用户意图空间。为此,提出了一种基于超图卷积网络和目标多意图感知的会话推荐算法(hypergraph convolution network and target multi-intention perception for session-based re-commendation algorithm,HCN-TMP)。首先,由于用户采用某项目的意图是由该项目多因素决定的,所以采用基于意图解纠缠的方法将项目嵌入分为多块,假设每块代表一个潜在因素。其次,分别从全局和目标会话中学习项目两个级别的嵌入表示。a)对于全局会话,为每一个会话构建一个超边,一个超边内的项目都彼此相互连接,通过共享项目连接的不同超边构成超图,超图中蕴涵了项目的高阶转换关系,经HGNN学习全局级项目嵌入表示;b)对于目标会话,构建包含目标会话成对转换关系的会话图,通过GNN学习会话级嵌入表示。对于两个级别的嵌入表示,同时使用距离相关性损失函数来促使项目多个嵌入块间有更强的独立性。在得到项目两个级别的嵌入之后,考虑到目标会话中出现在不同位置的项目对用户偏好的影响不同,所以融合项目在目标会话中的位置信息,经软注意力机制分别得到全局级会话表示和会话级会话表示,利用对比学习最大化两种会话表示的互信息。经目标多意图感知,针对不同的目标项目,通过注意力机制感知目标项目与目标会话中项目多因素的相关性,自适应地学习目标会话中多意图的用户偏好,缩小用户的意图空间,得到目标感知级会话表示,以解決上述问题。最后,线性地组合三种类型的会话表示来表达用户最终偏好,进而进行推荐。
1 相关工作
1.1 超图神经网络
与简单图不同,一个超图由多个超边构成,每个超边连接多个节点,用G=(V,E,W)表示,其中,V表示节点集合,E表示超边集合,W表示超边权重的对角矩阵。HGNN通过“节点-超边-节点”模式有效地提取超图上的高阶相关性信息,即先从节点到超边的信息聚合,再从超边到节点的信息传播。文献[23]通过构建超图卷积网络(hypergraph convolution network,HGCN)完成“节点-超边-节点”模式,如式(1)所示。
X(l+1)=σ(D-1/2vHWD-1eHTD-1/2vX(l)Θ(l))(1)
其中:Dv、De分别表示节点和超边度的对角矩阵,起到归一化的作用;H表示超图的关联矩阵;X(l)表示第l层节点的嵌入向量矩阵;Θl表示第l层可训练的参数矩阵;σ表示非线性激活函数。
具体来说,首先初始化节点嵌入表示,记作X(0),并通过参数矩阵转换特征维度;其次,通过左乘HT聚集节点到超边的信息;最后,通过左乘H从超边向节点传播信息。HGNN经L层迭代训练得到最佳的节点嵌入表示X(L)。
1.2 对比学习
自监督学习属于无监督学习的一种,即用于训练的标签源于数据本身,无须另外人工标记。对比学习[27]是自监督学习的一个分支,核心思想是让模型学习如何将正样本和其他负样本区别开,抓住样本的本质特征。在表征学习中,对比学习是通过将同一样本的多种嵌入相互靠近,不同样本的嵌入相互远离来实现的,最大化同一样本多种嵌入的互信息,增强了样本嵌入的鲁棒性。文献[28]提出了InfoNCE,主要用在自监督学习中作为一个对比损失函数,如式(2)所示。
其中:X表示包含正负样本的集合;fk(·)表示一种相似度函数;(xj,ct)表示负样本对;(xt+k,ct)表示正样本对;EX表示整体期望。通过最小化损失函数即可最大化正样本对之间的互信息。
2 模型框架与算法描述
2.1 问题说明
设V={v1,v2,…,vm}为会话中出现过的所有项目组成的集合;s=[v1,v2,…,vn]为按时间戳排序的匿名会话,其长度记为|s|;S={s0,s1,s2,…,s|S|-1}为整个数据库中的会话集,|S|为会话总数。每个项目vi∈V和会话s都被嵌入到相同的向量空间,分别用s∈RApd和xi∈RApd表示,d表示向量的维度。
对于给定的目标会话s0=[v1,v2,…,v|s0|],SRS任务的目标是预测下一个可能交互的项目v|s0|+1。推荐模型生成V中所有项目的偏好分数,选择得分最高的前K个项目进行最终推荐。
2.2 模型框架
基于GNN的SRS任务一般包含图构建、项目嵌入表示学习、目标会话表示生成、预测四步[13]。HCN-TMP算法在以上步骤的基础上增加一个意图解纠缠模块以挖掘项目多因素信息,为学习用户多意图偏好提供条件。
在图构建模块中,由于目标会话中蕴涵的信息有限,所以将全局会话作为协同信息,根据目标会话中项目的成对转换关系构建会话图,根据全局会话的高阶转换关系构建超图。在意图解纠缠模块中,为了对用户多意图偏好建模,经意图解纠缠,将原有反映用户耦合意图的项目嵌入表示转换为项目多因素嵌入表示。在项目嵌入表示学习模块中,为获取两个级别项目多因素的嵌入表示,在会话图中,用GAT(graph attention network)学习目标会话项目的会话级表示;在超图中,用HGCN学习目标会话项目的全局级项目表示,并通过距离相关性损失函数促使项目多因素嵌入块有更强的独立性。在目标会话表示生成模块中,将目标会话中项目的位置信息考虑到注意力权重中,分别融合目标会话中两个级别项目的嵌入表示,得到全局级会话表示和会话级会话表示,并通过对比学习最大化两者的互信息;此外,考虑到目标项目对用户多意图偏好的影响,目标会话项目的会话级表示和目标项目通过目标多意图感知得到目标感知级会话表示,从而缩小用户意图偏好空间。在预测模块中,线性融合全局级、会话级和目标感知级会话表示作为用户偏好向量,经softmax函数预测项目得分,从而进行推荐。算法模型如图1所示。
2.3 图构建模块
1)会话图构建 参考文献[17],为了对目标会话项目的转换关系建模,将目标会话构建成一个会话图。为了模型简单起见,在会话图构建时,忽略入度、出度、自环等多类型的转换关系,只考虑项目的成对转换关系,因此构建无向图。给定目标会话s0=[v1,v2,…,v|s0|],构建会话图G′=(V′,E′)。其中:V′表示出现在目标会话s0中所有项目的集合;E′表示边集合,E′={e′i,j|(vi,vj)|vi,vj∈V′} ,(vi,vj)表示边,即用户在s0中点击vi和vj存在先后顺序,用VS(vi)表示会话图中项目vi的邻居项目。
2)超图构建 在SRS任务中,某些项目被交互通常是先前多个项目联合影响的结果,因此项目转换关系是多对多的,参考文献[21],用超图挖掘项目高阶转换关系。给定全局会话S,构建超图G″=(V″,E″)。其中:V″表示全局会话中所有项目的集合,即V″=V;E″是一个包含|S|个超边的集合,每个会话构成一个超边,每个超边ε∈E″包含多个项目节点,ε={vi|vi∈s|s={v1,v2,…,v|s0|}}。
为每个超边设置一个权重Wεε,所有超边权重构成一个对角矩阵W∈RAp|S|×|S|,整个超图可以用一个关联矩阵H∈RApm×|S|表示,对于一个项目vi∈ε,Hiε定义为
D∈RApm×m、B∈RAp|S|×|S|分别表示节点和超邊度的对角矩阵,用Dii和Bεε分别表示节点和超边的度,Dii=∑|S|ε=1WεεHiε,Bεε=∑mi=1Hiε。
2.4 意图解纠缠模块
当前基于表征学习的SRS任务大多把项目嵌入到一个整体表示中,项目嵌入被视为耦合意图的结果,无法从细粒度的角度挖掘项目背后的不同潜在因素,而用户采用某项目的意图是由该项目多因素决定的,所以参考文献[25],使用意图解纠缠方法对项目嵌入的多因素进行编码。对于一个嵌入表示为xi∈RApd的项目vi,通过意图解纠缠将vi的嵌入表示分为T块,假设每块嵌入表示一个独立与其他块的潜在因素,如式(4)所示。
其中:σ表示激活函数;WTt∈RApd×d/T,bt∈RApd/T表示第t个因素的可训练的参数;ci,t表示项目vi第t个因素的嵌入表示,采用L2正则化防止过拟合。项目vi的嵌入经过解纠缠转换为xi=[ci,1,…,ci,T]∈RApd/T。
2.5 项目嵌入表示学习模块
根据已构建的会话图和全局图,分别通过会话级和全局级项目表示学习部分来获取目标会话项目会话级和全局级的项目表示,并且通过距离相关损失部分提高全局级嵌入表示多个嵌入块的独立性。
2.5.1 会话级项目表示学习
会话图中蕴涵项目成对转换关系,参考文献[17],通过GNN学习会话级项目表示。与文献[17]不同的是,此处对项目T块嵌入表示分开学习,最后融合得到最终的会话级项目表示,从而学习项目多因素的特征。
在会话图中,不同邻居对当前项目的重要性不同,通过GAT将不同的注意力权重分配给邻居以区分其重要性,并将其线性组合。项目vi第t个因素的学习过程如式(5)所示。
其中:αt(vi,vj)表示在第t个因素下项目vj与vi的注意力权重,计算方式如下:
其中:⊙表示向量对应位置相乘;LeakyReLU为激活函数;W1∈RApd/T表示可训练参数。最后,融合项目T块嵌入表示得到最终的会话级项目表示x′i=[c′i,1,…,c′i,T]∈RApd/T。
2.5.2 全局級项目表示学习
超图蕴涵项目高阶转换关系,参考文献[21],通过HGCN学习全局级项目表示。与会话级项目表示学习一样,此处依旧分开学习项目多因素的嵌入,最后融合得到最终的全局级项目表示。
在超图中,采用“节点-超边-节点”的信息传播模式,通过卷积操作聚合并传递图中信息,项目vi第t个因素的信息传播过程如式(7)所示。
在图卷积过程中,去除非线性激活部分和参数矩阵。为了简单起见,将所有权重系数Wεε设为1。参考式(1),图卷积过程的矩阵表达形式为
C(l+1)=D-1HWB-1HTC(l)(8)
信息传播和聚合应用于所有项目的堆叠形式构成了多层HGCN结构,通过L轮迭代形成稳定的模式,项目vi第t个因素的嵌入表示为cLi,t。为了解决因多轮迭代出现过拟合的问题,平均L轮所得的项目嵌入,如式(9)所示。
最后融合项目T块嵌入表示得到最终的全局级项目表示x″i=[c″i,1,…,c″i,T]∈RApd/T。
2.5.3 距离相关损失
在意图解纠缠模块中,为了探究用户多意图偏好,把项目嵌入分成T块,每块表示一个潜在因素。为了更全面且有针对性地描述项目的多特征,就要让项目嵌入的多因素间的独立性更高,采用距离相关损失作为正则化器去缩小每一对因素间的依赖性。因为通过会话图和超图学习了两个级别项目表示,距离相关损失存在于会话级项目表示学习和全局级项目表示学习过程中,距离相关损失函数表示如下:
其中:cos(·,·)表示两个向量的距离相关性函数。
2.6 目标会话表示生成模块
与文献[16~19]在学习目标会话表示之前直接融合多个级别项目嵌入不同,HCN-TMP从三个角度分别学习会话级、目标感知级和全局级会话表示,并通过对比学习最大化会话级和全局级会话表示的互信息,从而减少因项目嵌入融合带来的噪声。考虑到用户采用某项目的意图是由项目多因素决定的,所以分开学习项目的每个因素,更好地捕捉用户关心的主要因素。
2.6.1 会话级与全局级会话表示
参考文献[17],为了得到目标会话的整体表示,与现有着重关注目标会话最后一个项目的方法不同,融合位置信息嵌入,学习每个项目对整个目标会话的影响权重。会话级会话表示与全局级会话表示采用同样的学习方法,下文详细描述会话级会话表示学习过程,对全局级会话表示的学习过程不再赘述。
其次,通过软注意力学习目标会话内每个项目第t个因素的权重,如式(13)所示。
函数。然后,加权融合会话级项目嵌入,得到第t个意图的会话级会话表示s′t,如式(14)所示。
最后,融合T个意图的会话级会话表示得到最终的会话级会话表示s′=[s′1,…,s′T]∈RApd/T。同理,得到最终的全局级会话表示s″=[s″1,…,s″T]∈RApd/T,其中s″t表示第t个意图的全局级会话表示。
2.6.2 目标感知级会话表示
现有基于意图解纠缠的方法都是将目标会话压缩成固定的向量表示,忽略了目标项目对用户偏好多样性的影响。HCN-TMP通过目标多意图感知,即目标多意图注意力机制,自适应学习目标会话中与目标项目相关度更高的多意图用户偏好,为每个目标项目学习一个目标感知级会话表示。
在目标会话的第t个意图中,取目标项目v|s0|+1的嵌入向量,通过非线性转换后,与目标会话的所有项目的会话级嵌入表示内积,经归一化得到项目注意力权重,如式(15)所示。
最后,融合T个意图的会话级会话表示得到最终的目标感知级会话表示s=[s1,…,sT]∈RApd/T。由于数据库中所有项目V={v1,v2,…,vm}都要作为目标项目,vo∈V作为目标项目,目标感知级会话表示为so。
2.6.3 对比学习
将全局级会话表示作为自监督信号,通过对比学习最大化会话级和全局级会话表示的互信息。参考式(2),采用基于标准二分类的InfoNCE作为损失函数,如式(17)所示。
2.7 预测模块
在获取全局级、会话级和目标感知级会话表示后,针对目标项目vo,通过链接和线性变换到向量so来表达用户最终偏好,如式(18)所示。
so=W7[so;s′;s″](18)
其中:W7∈RApd×3d表示可训练参数。
对于目标项目vo,通过项目嵌入xo和用户偏好向量so内积得到项目得分zo:
zo=sToxo(19)
其中:y={y1,y2,…,ym}表示目标会话中真实点击项目的独热编码向量。结合式(10)(17)和(20)的损失函数形成统一的优化目标,如式(21)所示。
LAp=λLAp1+δLAp2+LAp3(21)
其中:λ和δ是两个超参数,控制距离相关损失和对比学习损失的比率。
3 实验与分析
为了评估算法HCN-TMP的有效性,在Tmall和Nowplaying两个公开数据集上进行以下四部分实验:与基线模型的对比实验、消融实验、参数调整实验以及算法在不同长度的会话表现实验。
3.1 数据集与预处理
实验选择Tmall(https://tianchi.aliyun.com/dataset/dataDetail?dataId=42)和Nowplaying(http://dbis-nowplaying.uibk.ac.at/#nowplaying)两个公开数据集。参考文献[13,17]的数据处理方法,过滤掉两个数据集中会话长度为1、项目出现次数少于5次的会话和项目。由于原Tmall数据集中项目数量过大,参考文献[17],筛选出1/64的会话作为最终数据集,并选择最后一天的数据作为测试集,剩余的作为训练集;对于Nowplaying,选择最后两个月的数据作为测试集,剩余的作为训练集。对于会话序列s=[v1,v2,…,vn] ,为了增强会话数据,生成一系列(会话序列,标签),例如 ([v1],v2),([v1,v2],v3),…,([v1,v2,…,vn-1],vn)。数据集内容如表1所示。
3.2 评价指标
实验使用基于排名的P@K和MRR@K两种评价指标对模型进行评价。考虑SRS实验的有效性和在实际生活中的应用,选取K=20。
3.3 对比方法
为验证模型的性能,选择以下算法进行对比:
a)Item-KNN[6]。推荐与目标会话最相似的会话中的项目,相似度定义为会话中项目的共现信息。
b)FPMC[7]。结合矩阵分解和一阶马尔可夫链来捕获序列效果和用户偏好。
c)GRU4Rec[9]。一种基于RNN的方法,利用GRU来捕获会话序列中项目之间顺序的行为。
d)NARM[10]。在GRU4Rec的基础上加入注意力机制,以对用户的主要目的进行建模。
e)SR-GNN[13]。通过门控图神经网络学习会话图中项目的嵌入表示,开创了使用GNN解决SRS问题的先例。
f)GC-SAN[14]。将GNN和多层自注意力网络结合,从而集成上下文信息。
g)TAGNN[15]。引入了目标感知模块,挖掘目标项目与历史动作的相关性,从而改进会话表示。
h)GCE-GNN[17]。通过构建会话图与全局图去学习两个层次的项目表示,以达到全局信息增强目标会话的目的。
i)S2-DHCN[21]。构建线图和超图学习会话间和会话内信息,并使用自监督学习来增强模型。
j)SHARE[20]。利用超图和注意力网络去探究上下文窗口,从而对会话相关的项目表示建模。
k)Disen-GNN[25]。将意图解纠缠技术与门控图卷积层相结合对项目潜在因素进行建模,以估计用户的不同意图。
3.4 參数设置
对于HCN-TMP算法,与文献[13,17]设置算法项目嵌入向量的维度统一为100不同,本文考虑到项目的多因素,把项目嵌入分为T块,所以项目嵌入向量的维度d需要通过参数实验得到。参考文献[13,17],设置批量处理大小为100,可训练参数以均值为0、标准差为0.1的高斯分布初始化,使用初始学习率为0.001的Adam优化器,每三个训练周期衰减0.1,正则化系数为10-5。对于其他影响算法性能的参数(HGCN层数、项目因素数、超参数λ和超参数δ)通过在两个数据集的参数实验得到。对于对比方法,为了公平起见,参数设置与原文献相同。
3.5 结果分析
a)将HCN-TMP与11个对比算法进行对比实验,实验结果如表2所示。从表2可以看出:
(a)基于序列化的方法(NARM和GRU4Rec)基本优于不考虑序列化的传统方法(Item-KNN和FPMC),表明在SRS任务中考虑会话序列信息是十分重要的。
(b)基于GNN的方法比传统方法和基于序列化的方法具有显著的优势,主要原因可能是图结构可以迭代地聚合图中的相邻信息以提取项目之间的成对转换关系,从而获得更好的项目表示。在基于GNN的方法中,仅考虑目标会话项目转移关系的方法(SR-GNN、GC-SAN、SHARE等)效果明显差于考虑协同信息的方法(GCE-GNN和S2-DHCN),说明目标会话以外的协同信息能更好地挖掘用户偏好。
(c)基于目标项目感知的方法(TAGNN)在Tmall数据集上优于所有其他基线方法,可能的原因是目标项目能很好感知用户偏好、挖掘用户意图。但在Nowplaying数据集中,TAGNN相比别的基于GNN的方法效果并不好,说明不同数据集中目标项目对用户意图的挖掘起到的作用不相同。
(d)基于超图建模会话的方法(S2-DHCN和SHARE)优于一般二部图建模会话的方法(SR-GNN、GC-SAN),因为一般图只能挖掘项目的成对转换关系,超图可以挖掘项目的高阶转换关系。基于意图解纠缠的方法(Disen-GNN)效果好于意图耦合的方法(SR-GNN、GC-SAN),因为用户采用某物品的意图是由该物品多因素决定的,Disen-GNN将项目嵌入到多个块中表示不同的因素。
(e)HCN-TMP算法考虑除目标会话以外的全局协同会话,通过超图建模全局协同会话,经多意图目标感知,针对不同的目标项目自适应地学习目标会话中多意图的用户偏好,综合以上方法优势所在,在两个数据集中明显优于所有基线方法。Tmall数据集上比最好的基线方法在P@20上高出16.18%,在MRR@20上高出12.01%;Nowplaying数据集上比最好的基线方法在P@20上高出1.83%,在MRR@20上高出2.02%。由此可见,相比Nowplaying数据集,HCN-TMP对Tmall数据集有更可观的效果,主要的原因可能是目标多意图感知模块对购物类用户多意图场景有更强的针对性。
b)对HCN-TMP算法进行消融实验,以验证每个重要组成部分的有效性。在每个实验中,移除其中一个部分,性能变化程度表明移除部分的重要性程度,分析以下五个模型:HCN-TMP_1表示移除HGCN部分,即不考虑全局协同信息,连带需要移除对比学习部分;HCN-TMP_2表示移除意图解纠缠部分,即项目只用一个整体嵌入表示;HCN-TMP_3表示移除目标感知部分,不考虑目标项目;HCN-TMP_4表示移除对比学习损失部分,即参数δ=0;HCN-TMP_5表示移除距离相关损失部分,即参数λ=0。实验结果如图2所示。
图2实验结果表明,超图能有效地挖掘项目高阶信息;意图解纠缠可以更好地探究用户的多种意图;目标感知通过感知目标项目与目标会话的相关性改进会话表示,提升了模型推荐性能,对于数据集Tmall有更明显的提升效果;对比学习损失和距离相关损失对提高模型推荐性能都是有效的,前者作用更大。
c)对HCN-TMP算法进行参数调整实验,以获取在最优性能下的参数值。HCN-TMP堆叠多个HGCN层来建模超图中的高阶信息,将层数L范围定为{1,2,3,4,5}来研究HGCN层数对推荐结果的影响,结果如图3所示。
图3实验结果表明,Tmall数据集在HGCN层数为1时,P@20和MRR@20都能达到最高,之后随着层数加深效果越来越差,所以层数最终设定为1;Nowplaying在层数为3时P@20达到最高、在层数为2时MRR@20达到最高,之后随着层数加深效果越来越差,由于层数为3时综合效果更好,所以层数最终设定为3。对于Tmall,仅一层就能达到最佳效果的主要原因可能是数据集中的会话较短,一层就可以完成图信息的完全传播,使用过多的层将为表示学习过程带来噪声。
为了研究项目的多因素对实验结果的影响,将项目嵌入块T范围定为{1,2,…,9,10},此处保持项目嵌入的维度不变,对于Tmall数据集,采用项目嵌入维度d=250;对于Nowplaying数据集,采用项目嵌入维度d=100,结果如图4所示。
图4实验结果表明,随着因素数的增加,性能通常会增加,直到达到峰值,然后开始下降。当T=1时,性能很差,表明项目耦合的嵌入表示不足以捕获会话中用户的多种意图,证明了在细粒度级别上意图解纠缠的合理性。Tmall数据集在因素数为5时,P@20和MRR@20都能达到最高,因素数最终设定为5;Nowplaying因素数为7时P@20达到最高、因素数为6时MRR@20达到最高,由于因素数7时综合效果更好,所以因素数最终设定为7。因素数对两个数据集影响是不同的,主要是因为这两个数据集收集于不同的场景,用户意图是由不同场景的不同因素驱动的。
为了使项目多个嵌入块有更强的独立性,HCN-TMP应用了距离相关损失,超参数λ控制训练过程中的距离相关损失权重,大范围内调整λ以获得最佳值权重。参考文献[25],将超参数λ范围定为{0,0.5,5,10,100},基于评价指标P@20研究其對结果的影响,结果如图5所示。图5实验结果表明,设置适当的λ可以提高性能。当λ=0时,即不考虑距离相关损失,两个数据集的性能都相对较差;当λ=5时,在两个数据集上都能达到最佳效果,这表明考虑项目因素独立可以有效地促进嵌入学习,从而提高性能;当λ过大时,会削弱距离相关损失对学习过程的指导作用,导致性能下降。
为了最大化全局级和会话级项目表示的互信息,HCN-TMP应用了对比学习的方法,提出了对比学习损失,超参数δ控制训练过程中的对比学习损失权重。参考文献[21],将超参数δ范围定为{0,0.001,0.01,0.02,0.03,0.05},基于评价指标P@20研究其对结果的影响,结果如图6所示。
图6实验结果表明,当Tmall和Nowplaying数据集的δ分别达到0.03和0.02时模型的性能最佳,表明全局级项目表示能够作为自监督信号,最大化与会话级项目表示的互信息。对于两个数据集,随着δ的增加,模型的性能有所下降,下降的原因可能是联合损失函数之间的梯度冲突。
d)针对数据集中不同长度的会话,对HCN-TMP进行实验,以探究算法对长会话和短会话的影响。长度小于等于5的会话为短会话,剩余的会话是长会话。此处选择TAGNN和GCE-GNN这两个表现最佳的基线方法作为对比方法,结果如图7所示。
图7实验结果表明,在两个数据集上,所有方法在长会话上的性能都高于短会话,主要原因可能是长会话所蕴涵的信息更多,能更好地表达用户的偏好。HCN-TMP在两个数据集的长会话和短会话上都优于对比方法TAGNN和GCE-GNN,说明HCN-TMP能同时处理长项目依赖和短项目依赖问题,主要原因可能是HCN-TMP能根据目标项目自适应地学习目标会话中多意图的用户偏好,缩小用户的意图空间,无论会话长短都能很好地感知用户意图。
4 結束语
本文提出基于超图卷积网络和目标多意图感知的会话推荐算法HCN-TMP,既考虑到通过超图神经网络去捕捉项目之间的高阶转换关系,又考虑到通过目标多意图感知自适应地学习目标会话中多意图的用户偏好,并通过距离相关损失和对比学习损失对SRS任务进行优化,使推荐更加精确。相比基线方法,HCN-TMP虽然有着最佳的效果,但模型的复杂度高、训练时间更久,难以应用于实际应用场景。因此,下一步研究通过简化图神经网络,从而降低模型复杂度。
参考文献:
[1]Wang Xiang, He Xiangnan, Wang Meng, et al. Neural graph col-laborative filtering[C]//Proc of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval.New York:ACM Press,2019:165-174.
[2]Zhu Ziwei, Wang Jianling, Caverlee J. Improving top-k recommendation via joint collaborative autoencoders[C]//Proc of World Wide Web Conference.New York:ACM Press,2019:3482-3483.
[3]Wang Jianling, Caverlee J. Recurrent recommendation with local coherence[C]//Proc of the 12th ACM International Conference on Web Search and Data Mining.New York:ACM Press,2019:564-572.
[4]Wang Jianling, Louca R, Hu D, et al. Time to shop for Valentines day: shopping occasions and sequential recommendation in e-commerce[C]//Proc of the 13th International Conference on Web Search and Data Mining.New York:ACM Press,2020:645-653.
[5]Wang Shoujing, Cao Longbing, Wang Yan, et al. A survey on session-based recommender systems[J].ACM Computing Surveys,2021,54(7):article No.154.
[6]Sarwar B, Karypis G, Konstan J, et al. Item-based collaborative filtering recommendation algorithms[C]//Proc of the 10th International Confe-rence on World Wide Web.New York:ACM Press,2001:285-295.
[7]Rendle S, Freudenthaler C, Schmidt-Thieme L. Factorizing perso-nalized Markov chains for next-basket recommendation[C]//Proc of the 19th International Conference on World Wide Web.New York:ACM Press,2010:811-820.
[8]Shani G, Heckerman D, Brafman R I, et al. An MDP-based recommender system[J].Journal of Machine Learning Research,2005,6(1):1265-1295.
[9]Hidasi B, Karatzoglou A, Baltrunas L, et al. Session-based recommendations with recurrent neural networks[C]//Proc of International Conference on Learning Representations.2016:1-10.
[10]Li Jing, Ren Pengjie, Chen Zhumin, et al. Neural attentive session-based recommendation[C]//Proc of ACM Conference on Information and Knowledge Management.New York:ACM Press,2017:1419-1428.
[11]Tan Y K, Xu Xinxing, Liu Yong. Improved recurrent neural networks for session-based recommendations[C]//Proc of the 1st Workshop on Deep Learning for Recommender Systems.New York:ACM Press,2016:17-22.
[12]Jannach D, Ludewig M. When recurrent neural networks meet the neighborhood for session-based recommendation[C]//Proc of the 11th ACM Conference on Recommender Systems.New York:ACM Press,2017:306-310.
[13]Wu Shu, Tang Yuyuan, Zhu Yanqiao, et al. Session-based recommendation with graph neural networks[C]//Proc of AAAI Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press,2019:346-353.
[14]Xu Chengfeng, Zhao Pengpeng, Liu Yanchi, et al. Graph contextua-lized self-attention network for session-based recommendation[C]//Proc of the 28th International Joint Conference on Artificial Intel-ligence.Palo Alto,CA:AAAI Press,2019:3940-3946.
[15]Yu Feng, Zhu Yanqiao, Liu Qiang, et al. TAGNN:target attentive graph neural networks for session-based recommendation[C]//Proc of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval.New York:ACM Press,2020:1921-1924.
[16]Zheng Yujia, Liu Siyi, Li Zekun, et al. DGTN:dual-channel graph transition network for session-based recommendation[C]//Proc of International Conference on Data Mining.Piscataway,NJ:IEEE Press,2020:236-242.
[17]Wang Ziyang, Wei Wei, Cong Gao, et al. Global context enhanced graph neural networks for session-based recommendation[C]//Proc of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval.New York:ACM Press,2020:169-178.
[18]Chu Fei, Jia Caiyan. Self-supervised global context graph neural network for session-based recommendation[J].PeerJ Computer Science,2022,8(2):e1055.
[19]Deng Zhihong, Wang Changdong, Huang Ling, et al. G3SR: global graph guided session-based recommendation[J].IEEE Trans on Neural Networks and Learning Systems,2022,34(12):9671-9684.
[20]劉高,黄沈权,龙安,等.基于超图网络的产品设计知识智能推荐方法研究[J].计算机应用研究,2022,39(10):2962-2967.(Liu Gao, Huang Shenquan, Long An, et al. Research on intelligent recommendation method of product design knowledge based on hypergraph network[J].Application Research of Computers,2022,39(10):2962-2967.)
[21]Xia Xin, Yin Hongzhi, Yu Junliang, et al. Self-supervised hyper-graph convolutional networks for session-based recommendation[C]//Proc of the 35th AAAI Conference on Artificial Intelligence.Palo Alto,CA:AAAI Press,2021:4503-4511.
[22]Li Yinfeng, Gao Chen, Luo Hengliang, et al. Enhancing hypergraph neural networks with intent disentanglement for session-based recommendation[C]//Proc of the 45th International ACM SIGIR Confe-rence on Research and Development in Information Retrieval.New York:ACM Press,2022:1997-2002.
[23]Feng Yifan, You Haoxuan, Zhang Z, et al. Hypergraph neural networks[C]//Proc of the 33rd AAAI Conference on Artificial Intel-ligence.Palo Alto,CA:AAAI Press,2019:3558-3565.
[24]Ma Jianxin, Zhou Chang, Cui Peng, et al. Learning disentangled representations for recommendation[EB/OL].(2019-10-31).https://arxiv.org/pdf/1910.14238v1.pdf.
[25]Li Ansong, Cheng Zhiyong, Liu Fan, et al. Disentangled graph neural networks for session-based recommendation[J].IEEE Trans on Knowledge and Data Engineering,2023,35(8):7870-7882.
[26]洪明利,王靖,贾彩燕.多通道图注意力解耦社交推荐方法[J].国防科技大学学报,2022,44(3):1-9.(Hong Mingli, Wang Jing, Jia Caiyan. Multi-channel graph attention network with disentangling capability for social recommendation[J].Journal of National University of Defense Technology,2022,44(3):1-9.)
[27]Khosla P, Teterwak P, Wang Chen, et al. Supervised contrastive learning[C]//Proc of the 34th Conference on Neural Information Processing Systems.2020:18661-18673.
[28]Van Den Oord A, Li Yazhe, Vinyals O. Representation learning with contrastive predictive coding[EB/OL].(2019-01-22)[2023-04-01].https://arxiv.org/pdf/1807.03748.pdf.
猜你喜欢
计算机应用(2019年3期)2019-07-31
无线互联科技(2019年9期)2019-07-29
无线互联科技(2019年9期)2019-07-29
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
智能计算机与应用(2019年3期)2019-07-01
电子技术与软件工程(2019年5期)2019-06-20
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
