
GPS数据驱动的车辆跟驰行为建模与分析
2024-02-06 01:35李轶群石家继陈淼申薇赵建东
科学技术与工程 2024年1期
李轶群, 石家继, 陈淼, 申薇, 赵建东*
(1.河南交通投资集团有限公司, 郑州 450000; 2.河南中原高速公路股份有限公司航空港分公司, 郑州 450000;3.北京交通大学交通运输学院, 北京 100044)
车辆跟驰是道路交通中一种常见的车辆驾驶行为,对车辆跟驰行为进行建模研究,能为缓解城市交通拥堵、提高交通安全性和通行能力、优化交通控制策略等奠定基础。因此,采用城市道路交通上的时空车辆轨迹数据进行跟驰建模研究,能更好地研究中国城市道路交通流的特性,同时对分析车辆微观交通行为和道路交通的正常运行具有重要意义。
1953年,跟驰模型概念首次被提出[1],早期对车辆跟驰行为的研究主要是以数学公式和交通流理论为基础的理论驱动模型为主。随着大数据及智能交通技术的发展,数据驱动跟驰模型应运而生。数据驱动跟驰模型[2]是以实际车辆轨迹数据为基础,通过各种非参数统计分析和机器学习等方法,对数据进行训练和学习,进而对数据的内在机理进行分析。在数据驱动跟驰模型的数据源中,NGSIM轨迹数据[3]是各数据驱动跟驰模型的首选,从支持向量回归到各种深度学习跟驰模型,多通过NGSIM轨迹数据实现模型的训练和测试。
Wei等[4]提出一种基于支持向量回归的跟驰模型,在宏观上再现了不同拥堵传播模式。邱小平等[5]选用基于最小二乘支持向量机(least squares support vector machines,LS-SVM)算法建立了符合中国道路交通流特征的车辆跟驰模型,采用NGSIM数据进行仿真,该模型能精确模拟车辆的跟驰行为,同时挖掘各变量间的隐藏联系。Zhang等[6]采用加权混合核函数和粒子群优化算法,将驾驶行为考虑在驾驶决策中,以支持向量回归为基础以及加权混合核函数和粒子群优化算法设计出一种驾驶决策模型。张兰芳等[7]针对地下快速路提出基于驾驶行为的支持向量回归车辆跟驰模型,模型完善了支持向量回归(support vector regression,SVR)跟驰模型对实际驾驶行为模拟的缺陷,以扩展跟驰模型在不同交通流环境下的适用性。
但支持向量回归模型对于大规模训练样本难以实施,且预测的精度有限。近年来,深度学习的快速发展引起了交通流领域研究者的广泛关注,国内外学者提出了各类深度学习跟驰模型。同时由于神经网络在时间序列处理方面具有优越性而在跟驰模型研究中得到广泛应用。Zhou等[8]提出基于递归神经网络的车辆跟驰模型,模型考虑了连续历史时间序列数据,故能够捕获到驾驶者的反应时间及预测能力,但是该模型最多只考虑了2 s左右的历史数据。针对“浅层”神经网络难以处理连续时间内车辆速度、位置等多元数据的问题, Wang等[9]采用NGSIM(US-101)车辆轨迹数据,提出了一种长短期记忆网络中的基于门控循环单元神经网络的跟驰模型,仿真结果显示预测精度明显完善,验证了长短期记忆网络在车辆跟驰行为建模上的适用性。在此基础上,Huang等[10]采用NGSIM(US-101)数据提出了基于长短期记忆网络建立跟驰模型,该模型与驾驶记忆结合,针对非对称驾驶行为,重现交通流特征。在国内学者的研究中,孙倩等[11]采用实际高速公路上的跟驰试验数据,提出了一种基于长短期记忆(long short term memory, LSTM)神经网络方法的车辆跟驰模型,该模型的预测精度更加完善,同时能够很好地消散交通流中的扰动,抗干扰和稳定性较好。Lin等[12]提出改进采样机制和互联的长短期记忆网络结构结合的模型,通过队列生成方面分析,克服了传统训练方法中的时间、空间误差传播的问题,提高了跟驰行为预测的精度。
研究表明,长短期记忆神经网络具有记忆效应作用,可以很好地记忆下一时刻对上一时刻信息的依赖关系。因此采用长短期记忆神经网络的方法建立跟驰模型具有一定的优势。然而,目前对于LSTM模型的参数选取的研究,大多采用遍历网格搜索算法,存在开销大的缺点[13],同时LSTM网络的神经元数量、学习率和迭代次数难以确定。而粒子群算法作为优化算法,具有求解精度高、收敛速度快等优点,在优化应用中应用频率高,针对以上问题,现将粒子群优化(particle swarm optimization, PSO)算法应用到LSTM网络的优化,以提高LSTM网络在处理跟驰时间序列数据时的有效性和精确性。采用在合肥市城市道路上进行的25辆车跟驰试验中采集的高精度全球定位系统(global positioning system,GPS)数据,训练和测试基于深度学习的LSTM车辆跟驰模型,通过PSO算法优化LSTM网络参数,利用多种模型对跟驰实验数据预测进行对比实验,以验证所建立的PSO-LSTM模型的有效性和合理性。
1 数据预处理
1.1 数据简介
跟驰数据来自合肥市某路段上开展的25辆车的车辆跟驰试验,数据采集时间为上午10:00—12:00,试验路段全长3.2 km,路段内无红绿灯。由于该路段位于郊区,且每个方向至少有3条行车道,因此不受实验范围外其他车辆的干扰。该试验在两种试验设置下共开展了3组实验,使用其中一组数据。高精度差分GPS设备被安装在所有的试验车内,每隔0.1 s记录车辆的轨迹信息,包括:试验时间、车辆的横向位置、纵向位置、车辆行驶路程以及行驶速度。所用的基础数据为S3试验数据,主要数据字段列表如表1所示。

表1 数据字段列表Table 1 Data field list
1.2 数据筛选与处理
1.2.1 数据平滑处理
采用最小二乘平滑滤波的方法,对速度进行平滑滤波处理。滤波器系数的设置:采用3阶多项式,窗口宽度选用11个单位长度。部分速度数据进行滤波处理前后的速度与加速度对比如图1、图2所示。最小二乘平滑滤波法不仅极大程度上对原始数据的特性进行了保留,同时在原始数据发生强烈抖动的位置,对曲线进行了很好的平滑处理。处理后的曲线图更加符合车辆的运动性能,同时也与真实的速度和加速度曲线更加接近。
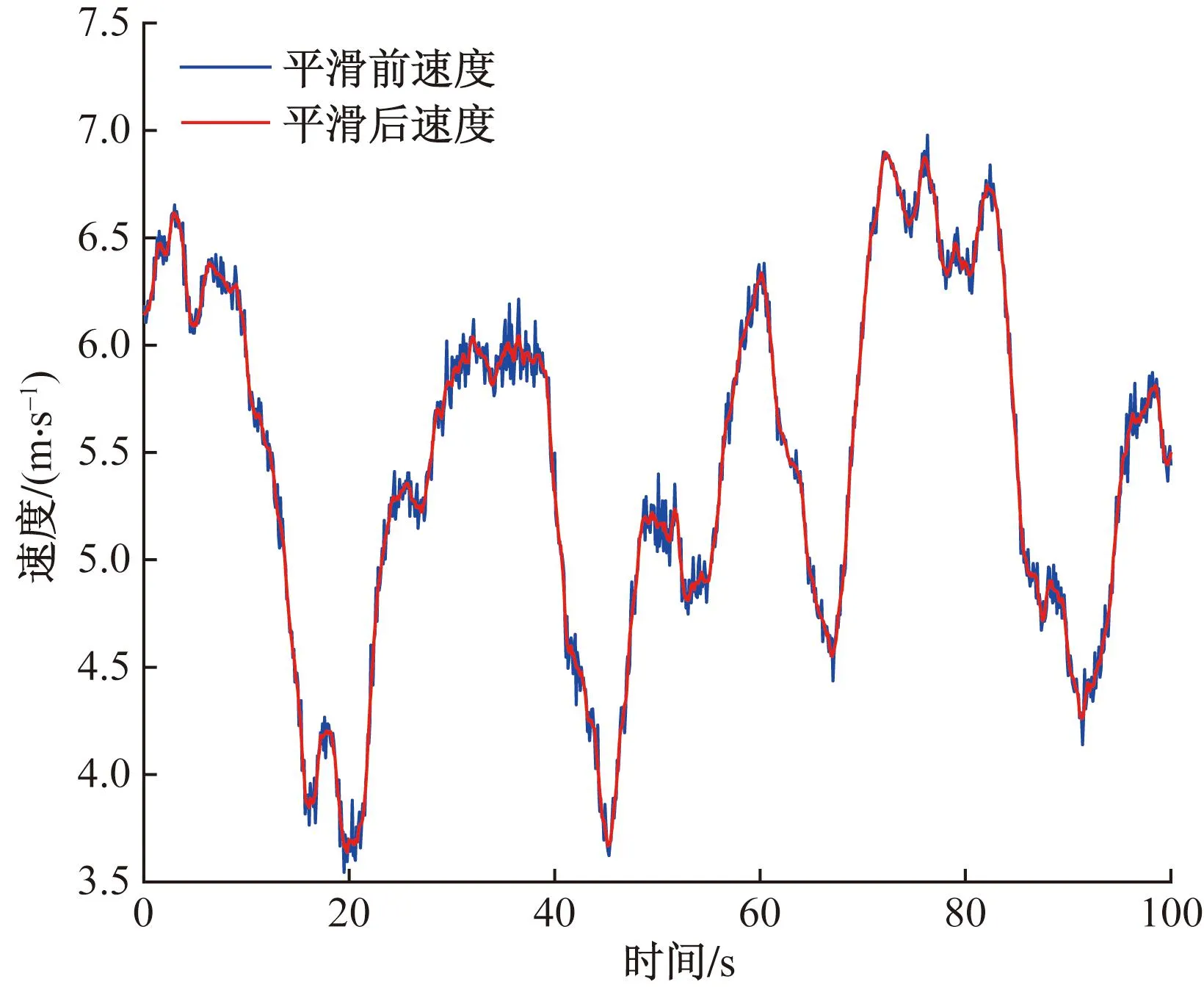
图1 速度数据平滑结果图Fig.1 Smoothed speed data results
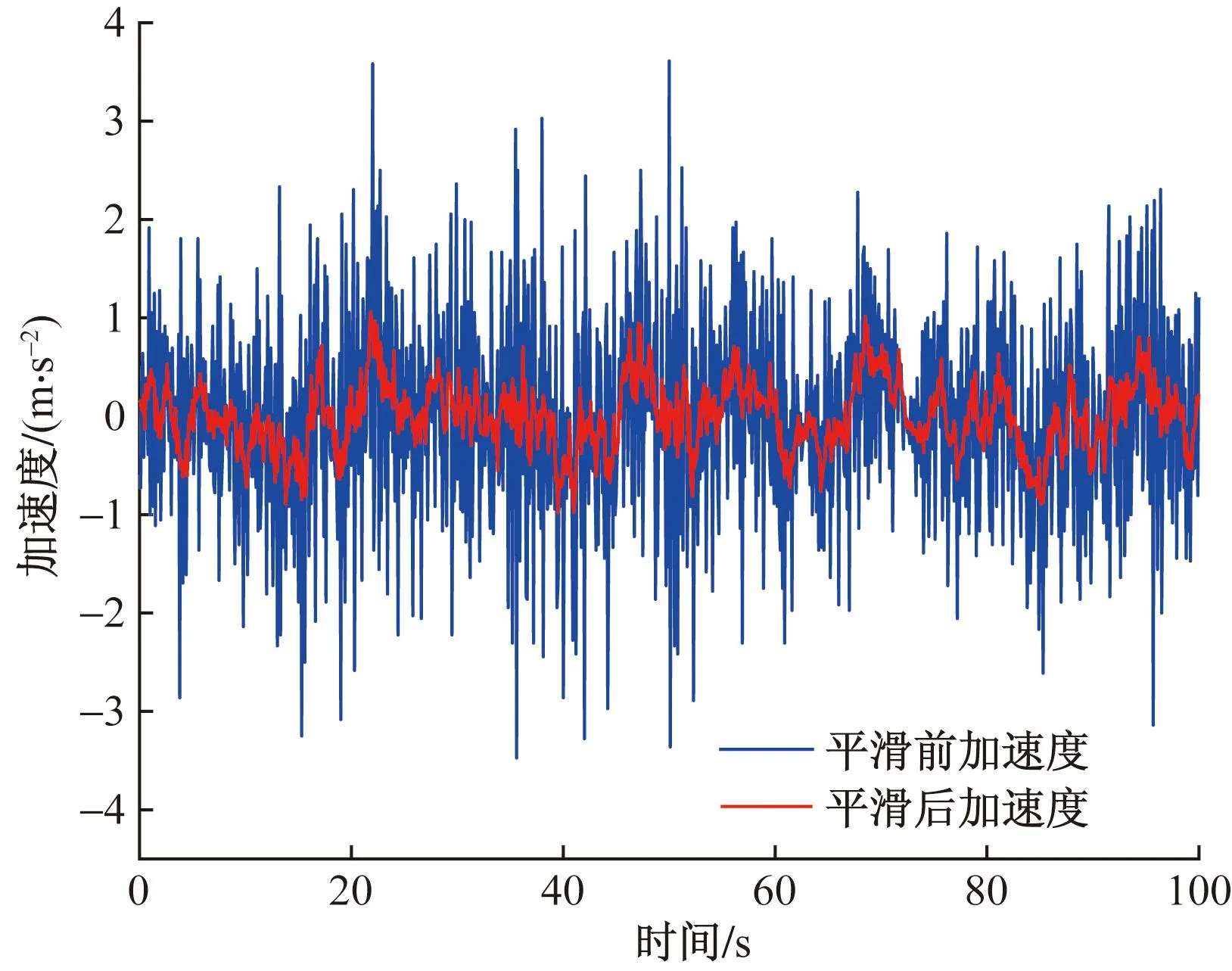
图2 加速度数据平滑结果图Fig.2 Accelerated speed data smoothing result
1.2.2 跟驰车队筛选
根据Zhou等[8]的研究,判断跟驰车对应满足试验车辆与目标车辆保持在同一车道,并且两车处于稳定的跟驰状态等准则。根据每组试验中跟驰状态较好的前五辆车制定跟驰片段提取规则如下。
(1)确保前后车辆处于稳定的跟驰状态(前后车相对速度差绝对值小于2.5 m/s)。
(2)确保目标车和跟随车在相同车道上行驶(设置前后车的横向距离绝对值小于2 m)。
(3)排除车辆处于拥挤交通流或判定为后车的跟驰行为已解除状态(前后车的跟驰间距为3~33 m)。
(4)避免在跟驰过程中车辆跟驰时间过短,从而保证前后车处于稳定的跟驰状态(去除跟驰片段持续时间小于15 s的片段)。
1.3 跟驰行为特性分析
1.3.1 速度特性分析车辆驾驶行为的随机特征直接表现在跟驰前后车辆的速度差异[14],在车辆的跟驰过程中,后车速度和加速度行为受到前车驾驶行为的刺激影响和约束作用。图3展示了跟车过程中,后车随前车速度变化的时序过程,其中速度差为前车速度与后车速度的差值。如图3所示,后车速度变化趋势与前车基本保持一致,可以看作是前车在时间维度上带有“随机误差”的滞后。跟驰前后车辆速度差在零值附近随时间呈现稳定波动变化,这表明了多数情况下,为节省时间,驾驶员希望在跟车过程中,尽量保持与前车相同速度进行跟随。而速度差的波动性,是因为驾驶员对车辆速度、间距等驾驶行为特征参数的感知反应的滞后性、判断差异和操作误差等因素[15]。
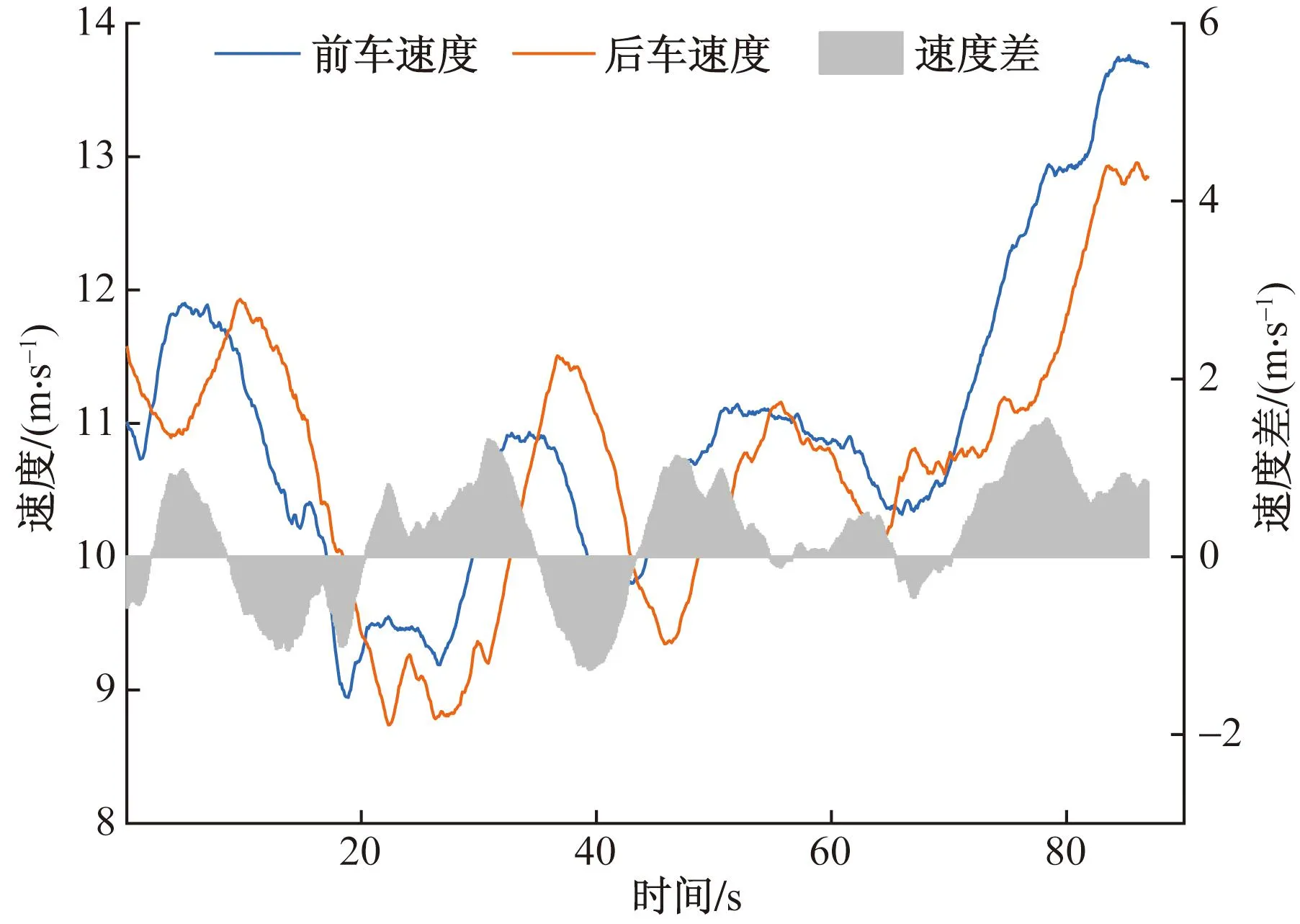
图3 速度-时间关系图Fig.3 Velocity-time relationship
1.3.2 加速度特性分析加速度是反映车辆微观驾驶行为特征的重要指标,通过划分后车速度区间,分别对跟驰车辆的正、负加速度的均值进行统计。如图4所示,在稳定跟车过程前,车辆主要通过加速来靠近前车。在稳定跟驰过程中,正加速度和负加速度呈现相近的波动特征。但是相比于正加速度,在相同速度区间下,负加速度绝对值普遍更大,这表明在跟驰过程中,减速行为比加速行为更加剧烈。

图4 加速度-速度关系图Fig.4 Accelerated velocity-velocity relationship
1.3.3 相对速度-跟驰间距关系分析
如图5所示,跟车过程中,稳定跟驰阶段两车相对速度大部分处于区间[-1,1] m/s,且主要集中于0 m/s附近,这是因为为了节省时间,后车会尽量与前车保持最小安全跟驰间距,因此后车速度会在前车速度附近变动。图5中两段跟车属于较完整的跟车阶段,可以发现,当驾驶员想要跟车的情况下,后车会持续靠近前车,直到达到驾驶员期望的距离时,后车速度会与前车车速保持平衡;当前车开始加速时,而后车驾驶员不再想进行跟车时,两车的距离越来越大,此时跟车阶段结束。
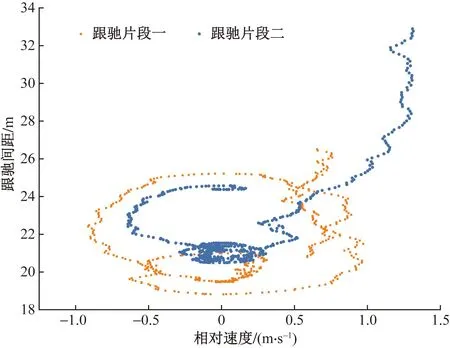
图5 跟驰间距-相对速度关系图Fig.5 Car following distance-relative velocity relationship
1.3.4 加速度-相对速度关系分析如图6所示,相对速度与后车加速度之间呈现明显的负相关关系,并且关于原点对称。尤其在区间[-1,1] m/s,这种变化十分明显。深入观察该图的变化,可以发现其并不严格遵循当相对速度为负值,后车加速度为正;在相对速度为[-1,1] m/s,存在较多不符合规律的散点。进一步分析产生该现象的原因:在现实的驾驶过程中,当前车运动状态突然发生改变时,后车驾驶员需要一定的反应时间。当前后车相对速度发生改变时,后车驾驶员需要通过两车之间的跟驰间距发生变化后,才能做出一定的反应。
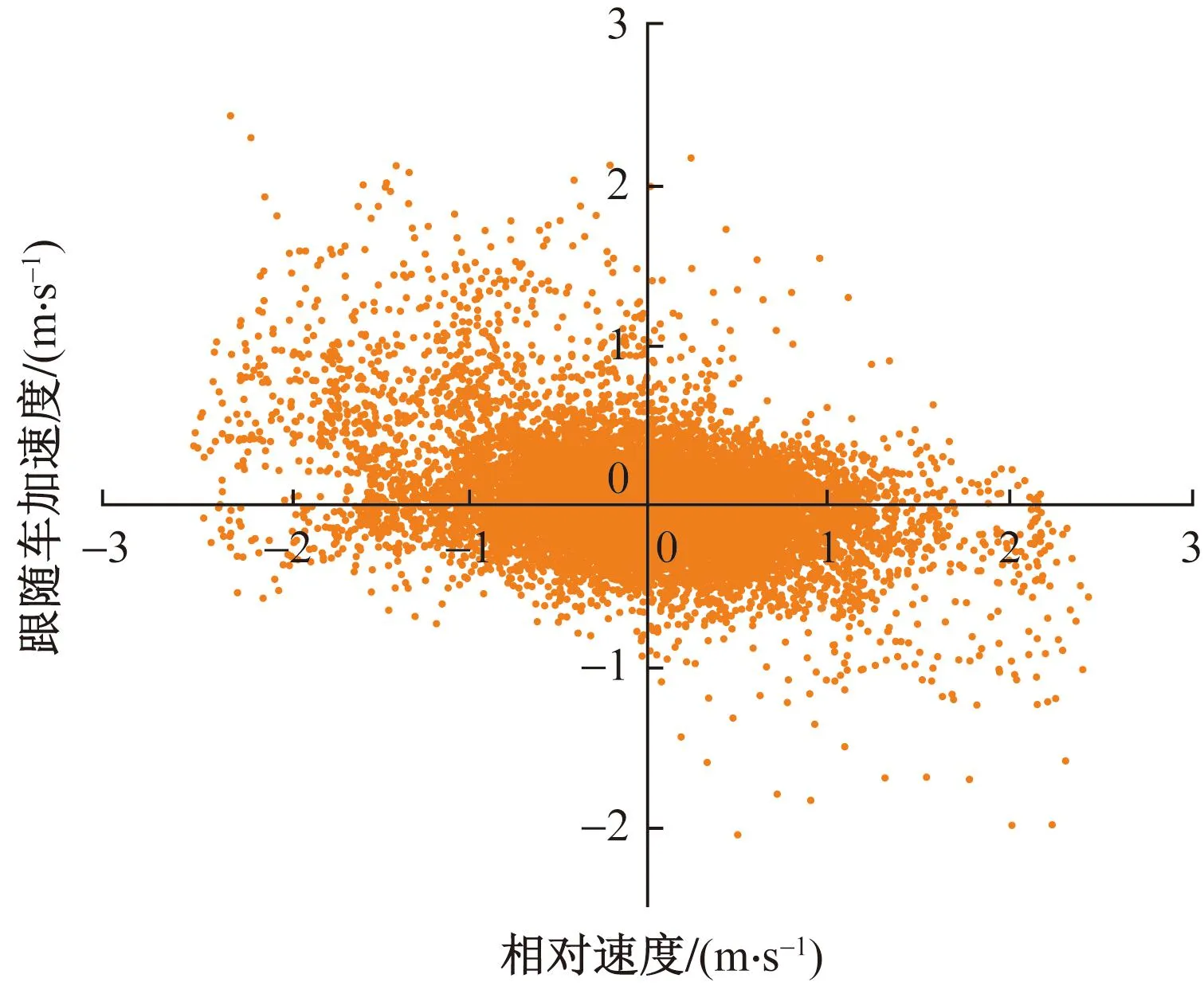
图6 跟随车加速度-相对速度关系图Fig.6 Following car acceleration-relative speed relationship
2 LSTM模型
2.1 模型结构
长短期记忆网络(LSTM)是基于循环神经网络(recurrent neural network,RNN)的一种深度机器学习神经网络。LSTM神经网络引入了长期记忆单元,能有选择性地从传入神经网络获取信息。
LSTM网络主要包括遗忘门、输入门和输出门,各部分计算公式[12]如下。
(1)遗忘门。
ft=σ(Wf[ht-1,xt]+bf)
(1)
式(1)中:ft是遗忘门控,会读取上一个单元结果的输出信息ht-1和当前t时刻单元输入信息xt,通过Sigmoid层σ给每个处于细胞状态Ct-1中的数字,输出一个在[0,1]区间的值;其中数值1表示记忆保留,0表示记忆完全遗忘;Wf为遗忘门的权值向量;bf为偏置向量。
(2)输入门。
it=σ(Wi[ht-1,xt]+bi)
(2)
(3)
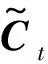
(3)记忆细胞。
(4)
(4)输出门。
Ot=σ(Wo[ht-1,xt]+bo)
(5)
ht=Ottanh(Ct)
(6)
式中:Ot为t时刻输出门值;Wo、bo为单元可能学习的权重和偏置向量。
2.2 LSTM车辆跟驰模型
基于上述LSTM网络结构,搭建如图7所示的数据驱动的车辆跟驰模型。其中通过Spearman相关性检验,确定跟驰模型输入变量为前车速度、当前时刻的车头间距和上一时刻的车头时距,即x=[v1(t),d(t),ht(t-1)];模型输出变量为后车速度,即y=[vF(t)]。
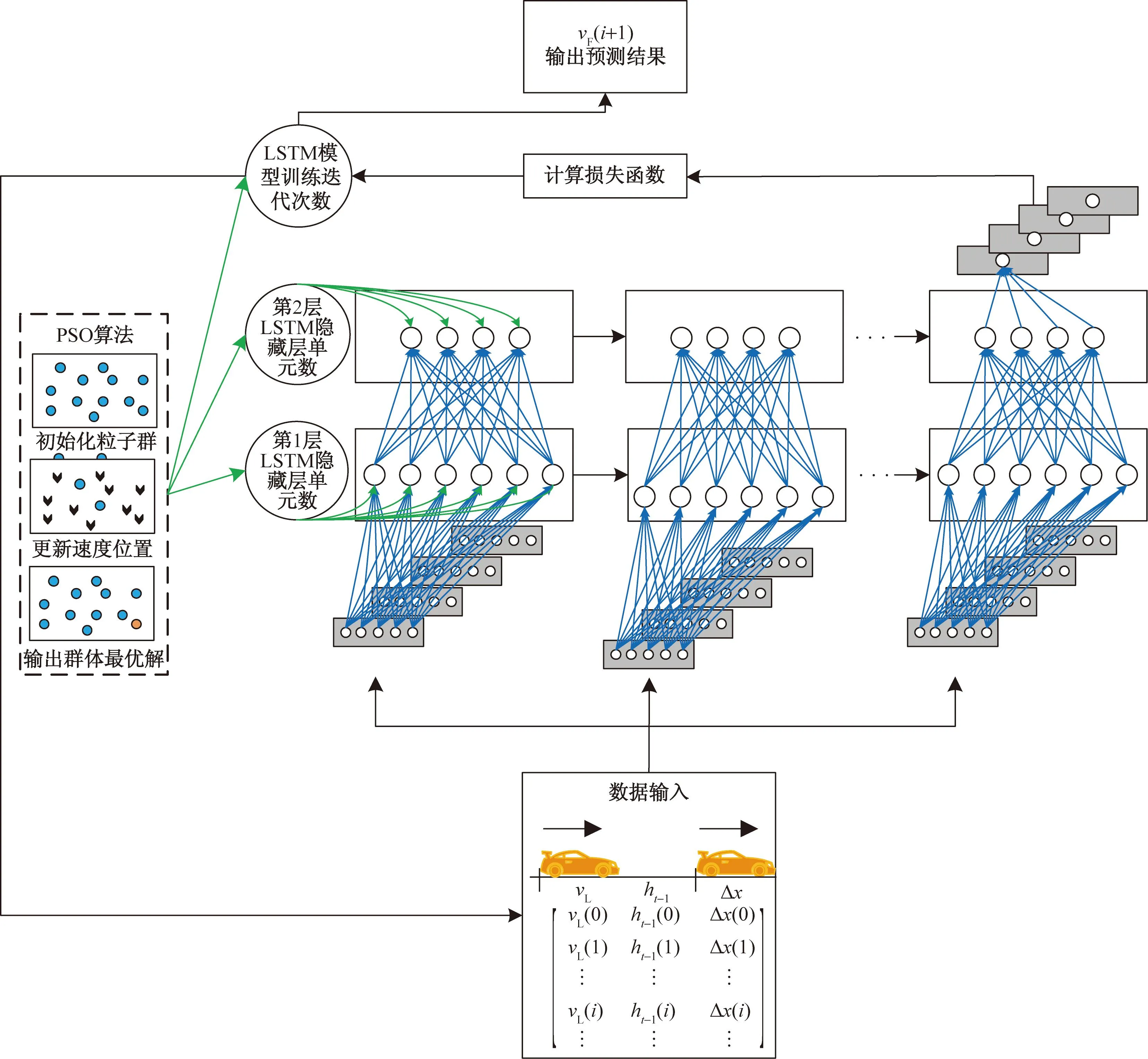
vF(i+1)为跟驰车速度;vL为当前车速度,vL(0),vL(1),…,vL(i)为0~i个跟驰车对的前车速度;ht-1为上时刻车头时距;ht-1(0),ht-1(1),…,ht-1(i)为0~i个跟驰车队的上一时刻车头时距;Δx为车头间距; Δx(0),Δx(1),…,Δx(i)为0~i个跟驰车对的车头间距
2.2.1 模型结构设计
(1)LSTM层数设置。将LSTM层数设置为两层时,能够很好地达到预测精度和学习效率两者之间的均衡。其中LSTM第一层设置神经元数目为h1,LSTM第二层设神经元数目为h2,Dense全连接层负责输出预测的后车速度数据,神经元设置的数目为1。
(2)Dropout层设置。为避免模型出现过拟合问题,在构建LSTM模型时选择在LSTM层之间添加Dropout层,从而达到正则化的目的,防止出现过拟合。模型中设置了两层Dropout层,第一层随机失活概率设置为0.4,代表神经元将以40%的概率失活,第二层随机失活概率为0.1。
(3)激活函数。通过在LSTM层传递activation参数来添加激活函数,分别实验测试Sigmoid、tanh和ReLU激励函数在预测模型中的效果,最终选择表现最好的tanh函数。
(4)优化器和损失函数。选择tanh作为激励函数,相应地将平均绝对误差(mean absolute error, MAE)作为目标损失函数。使用相同的试验条件,对目前常用的深度学习训练优化器进行深入验证,实验结果显示Adam优化器在效率和损失误差方面都显示出了良好的性能。同时由于Adam运算效率高,实现简单,且对内存的需求小,能高效地处理实际应用中的深度学习问题,所以选用Adam为模型优化器。
2.2.2 模型超参数
(1)隐藏层units数。在units数目为190时,与其他数量的神经元相比,模型测试误差更小,而再增加隐藏层units数目,模型训练时间也会增多,并且测试误差变得更大。因此选择units数量设置为190。
(2)迭代次数epoch。随着迭代次数的增加,模型预测精度和误差表现性能越好。但是迭代次数达到270次后,再增大迭代次数,模型性能下降,同时训练时间消耗大,模型可能出现过拟合现象。因此,将模型最优迭代次数设置为270次。
(3)Batch size批次大小。为同时保证数据处理效率和模型运行时间合理,根据实际训练环境确定batch size取值为300。
(4)Learning rate学习率。模型选择Adam优化器,该优化器自定义初始learning rate为0.000 1,通过自适应的方法每一轮将自动更新各个参数的学习率,使得在每次迭代中,学习率都会在合适的范围里,并且参数变动是比较稳定。
3 PSO-LSTM优化跟驰模型
LSTM模型对后车速度进行预测,其问题的核心是模型的训练过程。模型训练的目标在于找到一组最优参数值,使模型得到最精确预测结果。然而,由于模型参数设置具有不确定性、多样性和相关性,从而模型参数的确定过程非常复杂。为进一步提升模型的性能,采用PSO算法对LSTM模型超参数进行优化,构建PSO-LSTM模型,以获得较优的参数组合。
粒子群算法(PSO)最早是由Eberhart和Kennedy提出,是一种群体智能优化算法,其思想是:每一个粒子有一个决定着它们飞行方向和距离的速度及一个适应度值,通过群体中个体之间的信息共享来寻找最优解[16]。
首先在给定范围内将迭代次数和隐藏层神经元数随机进行初始化,以此作为模型初始参数。采用预测值的平均绝对百分比误差作为适应度函数。具体优化流程如图8所示,其中PSO参数设置如下。
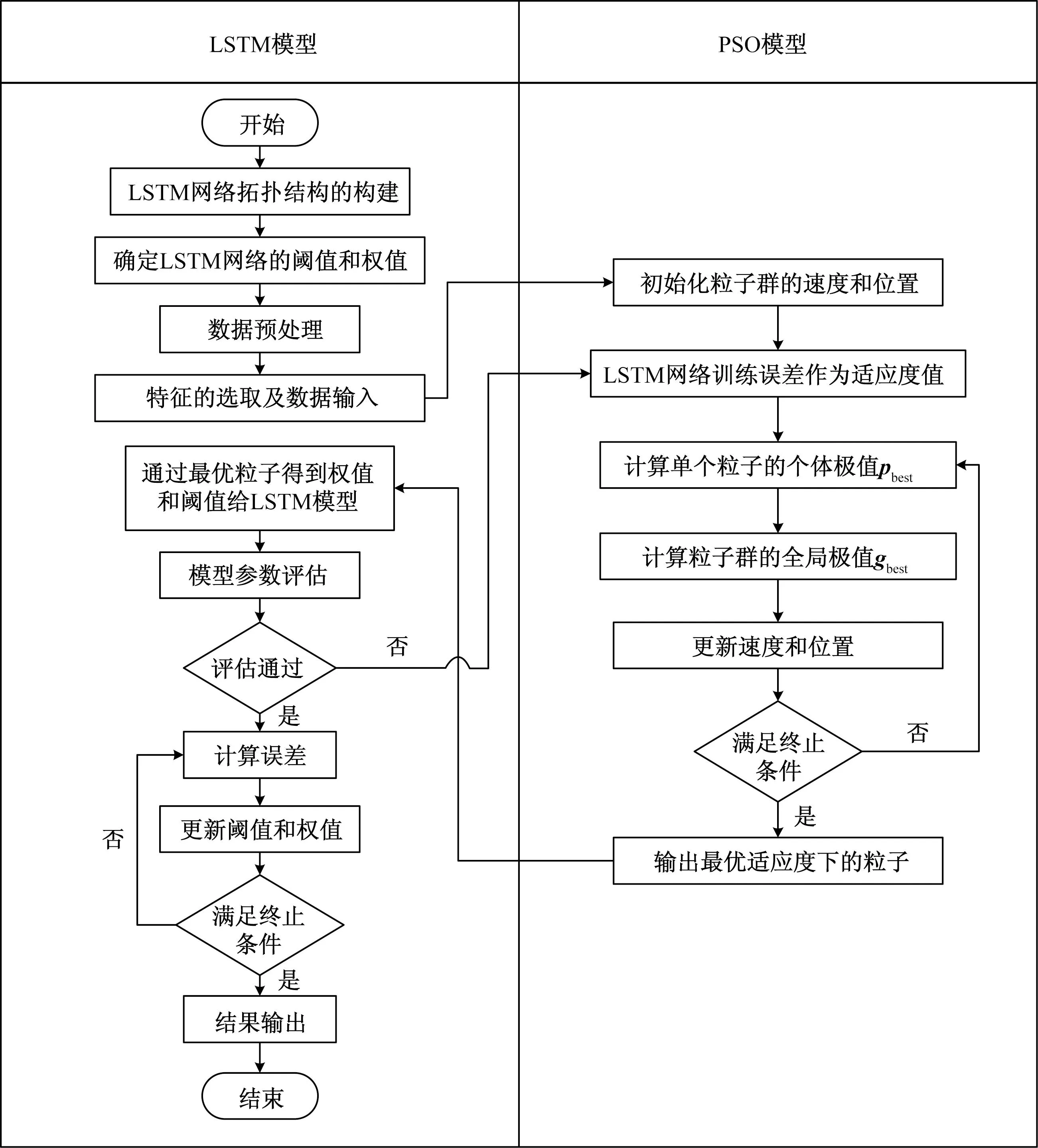
图8 PSO-LSTM模型建模流程图Fig.8 PSO-LSTM modeling process
种群数量为10,迭代次数为15,学习因子为c1=c2=2,惯性权重取w=0.5,粒子xi0(h1,h2,n)中参数取值范围是[10,400],[10,400]和[10,400],速度的取值范围分别为[-45,45],[-45,45]和[-20,20]。
4 实证分析
通过建立跟驰车对筛选规则,得到了6万条跟驰数据,按照7∶1∶2的比例将数据集划分为训练集、验证集和测试集。对所有输入数据进行归一化处理,以便于模型训练。同时选取均方误差(mean-square error,MSE)、均方误差(root mean squared error,RMSE)、平均绝对百分比误差(mean absolute percentage error,MAPE)、MAE、R2作为评价模型预测精度指标。
PSO-LSTM模型中粒子群全局最优参数稳定在h1=131,h2=184,n=374。将最优参数组合输入到LSTM模型中,训练LSTM神经网络,其预测效果如图9和表2所示。与基础LSTM模型相比,优化后PSO-LSTM模型的MAPE下降了1.52%,MAE下降了7%,MSE下降了5.61%,RMSE下降了9.68%。PSO-LSTM模型预测结果符合原始后车速度的变化趋势,模型输出后车速度的预测准确率达99.35%,这证明了LSTM神经网络能够学习到后车速度的变化规律,即PSO算法优化的LSTM神经网络预测得到的跟驰轨迹能较好地贴合实际跟驰轨迹。
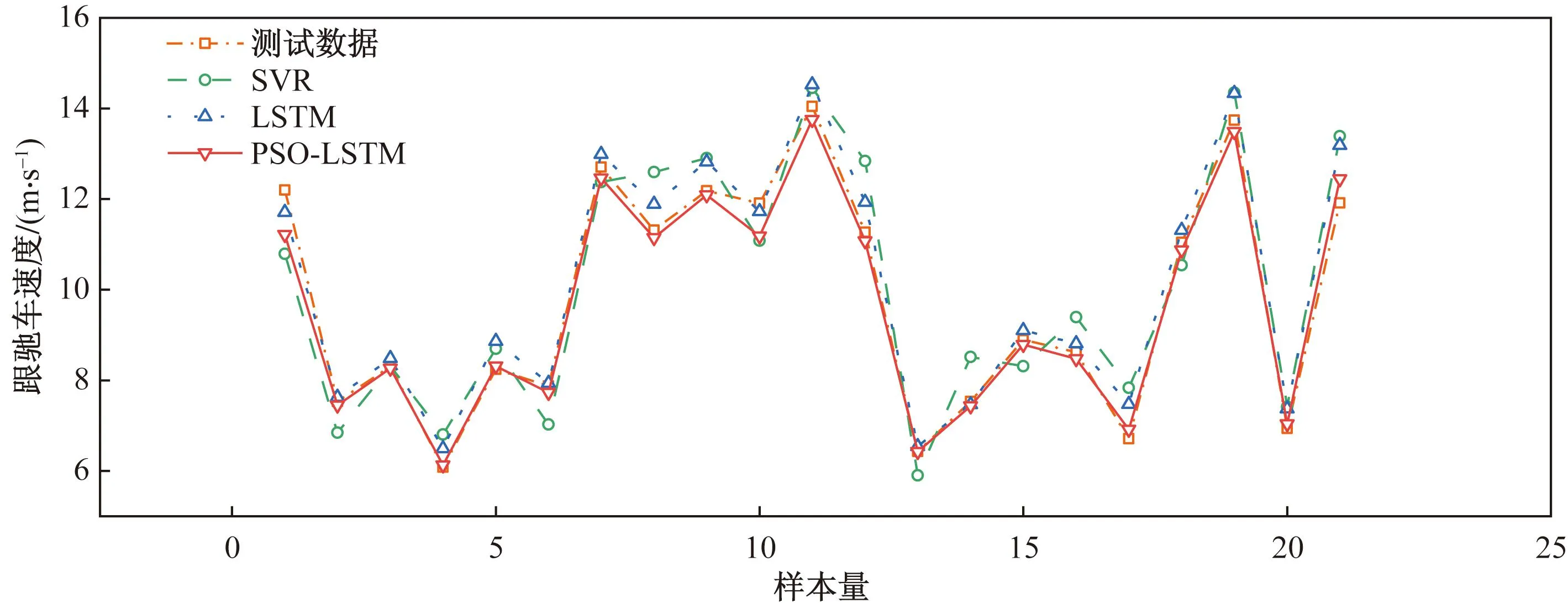
图9 不同跟驰模型预测效果对比图Fig.9 Car following model prediction effect comparison

表2 模型性能对比结果
为进一步评估所提模型性能,选取支持向量回归模型SVR进行对比。模型具体设置:采用Gauss径向基函数作为核函数,使用Grid Search方法对参数C和gamma进行参数优化,其中C=200,gamma=0.6。
最后得到评估指标如表2所示,结果表明基于深度学习的PSO-LSTM神经网络预测效果更为准确,各项误差更小,预测精度更高,同时节省了模型训练时间。这主要是由于传统机器学习在本质上仍属于线性拟合,而LSTM神经网络能衍生更深层次网络,从而能够较好地从时序数据中提取出数据特性,并且在LSTM单元中对价值信息进行记忆,在模型建立过程中,能更深层地利用数据信息,从而得到预测精度高结果。从运行时间上来看,在LSTM网络训练中,通过简单地GPU设置,大大减少了模型训练时间。
5 结论
得到的主要结论如下。
(1)针对跟驰试验数据,建立了一套数据清洗规则和一套跟驰对筛选规则。针对GPS数据进行速度、路程、加速度变化规律分析,结合分析结果确定使用最小二乘平滑滤波的方法进行速度平滑滤波。
(2)针对处理后的跟驰数据,对驾驶特征行为进行了研究,如加速度、速度以及跟驰参数之间的特性关系等,以加强对交通的本质问题进行探讨。
(3)构建了基于传统机器学习的SVR模型和基于深度学习的LSTM数据驱动跟驰模型。通过实例验证表明,LSTM模型整体预测效果高于SVR模型,
其中预测误差指标MAPE较SVR降低了60.02%。同时其通过简单地GPU设置,节省了近10倍的时间,大大提高了模型的训练速度。总的来说,LSTM模型较传统机器学习的SVR表现出更优越的预测性能。
(4)从超参数设置角度对LSTM模型进行优化,建立了PSO-LSTM模型。优化后的PSO-LSTM模型其误差指标MAPE下降了1.52%,MAE下降了7%,MSE下降了5.61%,RMSE下降了9.68%。
猜你喜欢
当代水产(2022年6期)2022-06-29
小猕猴智力画刊(2022年4期)2022-05-25
中学生百科·大语文(2021年4期)2021-05-12
电子制作(2019年19期)2019-11-23
汽车观察(2018年12期)2018-12-26
金桥(2018年4期)2018-09-26
劳动保护(2018年8期)2018-09-12
发明与创新(2016年5期)2016-08-21
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
