
基于混合威布尔分布的水稻插秧机的可靠性分析及剩余寿命预测
2024-02-06 01:33文昌俊陈洋洋何永豪陈凡
科学技术与工程 2024年1期
文昌俊, 陈洋洋*, 何永豪, 陈凡
(1.湖北工业大学机械工程学院, 武汉 430068; 2.湖北省现代制造质量工程重点实验室, 武汉 430068)
水稻插秧机作为水稻插秧移栽的主要机械设备,在水稻秧苗移栽期间,由于工作环境差、冲击、疲劳磨损等原因,势必会引起机械性能退化,并随着运行时间的累积最终导致机器失效。因此,正确计算出水稻插秧机的可靠性指标是现代化农业耕作的必然要求,也是水稻插秧机预测性维护所需的重要参考依据。此外,剩余寿命预测对水稻插秧机的维护而言,也具有重要的意义,通过对水稻插秧机进行剩余寿命预测,根据预测结果对水稻插秧机进行预测性维护。
在可靠性工程领域,威布尔分布是最常用的概率分布模型[1],通过形状参数的改变,威布尔模型可以描述失效率上升和失效率下降的产品寿命[2]。蔡文斌等[3]利用三参数威布尔分布,建立抽油杆疲劳寿命预测模型,基于三参数威布尔分布模型和正态分布Basquin模型对HL和HY两种抽油杆进行疲劳寿命预测,结果表明三参数威布尔分布模型比正态分布模型有更高的拟合精度。王谊等[4]针对当前国网用电信息采集系统中电能表可靠性评价不够准确的问题,利用威布尔分布模型,计算出了电能表的不可靠度,实现了威布尔分布理论在电能表评价中的实际应用。乔宏霞等[5]为改善西部盐湖地区混凝土耐久性能,采用威布尔函数建立CaCO3改性混凝土的耐久性退化模型,通过威布尔分布模型计算得出概率密度函数和可靠度函数,确定出纳米CaCO3改性混凝土在硫酸盐境下的最长使用寿命。缪吉昌等[6]基于婴儿培养箱风机的失效数据建立威布尔分布模型,随后利用极大似然法估计出模型参数,最后在其模型基础上对风机进行剩余寿命预测。然而上述文献都是基于单一威布尔分布模型进行计算的,但是水稻插秧机通常包含多个零部件,结构复杂,在水稻插秧期间,受多种应力作用,多种故障机制并存,这种情况下,用单一的威布尔分布模型对其寿命进行拟合会出现较大误差,此外文献也没提及在混合威布尔的基础上对设备进行剩余寿命的预测。
为了解决上述问题,在PZ型水稻插秧机故障数据的基础上,现建立两参数混合威布尔分布模型,其次,采用改进粒子群算法与非线性最小二乘法相结合对其模型的参数进行求解,利用Kolmogorov-Smirnov test以及对比单一威布尔模型和混合威布尔模型与失效数据的拟合效果证明该模型的合理性,然后通过该模型得到水稻插秧机可靠性指标和预防性维修周期,最后在混合威布尔模型的基础上对水稻插秧机进行剩余寿命预测。
1 混合威布尔分布模型
由于混合威布尔模型包含更多参数,所以能够针对较为复杂情况进行数据拟合[7]。假设一组数据样本n服从混合威布尔分布,对应各子分布均服从相同分布,但参数不同,各子分布的权重为w1,w2,…,wm,权重之和为1,各子分布的概率密度函数分别为f1(t),f2(t),…,fm(t),混合威布尔分布的故障概率密度函数f(t)、可靠度函数R(t)和故障概率分布函数F(t)分别为
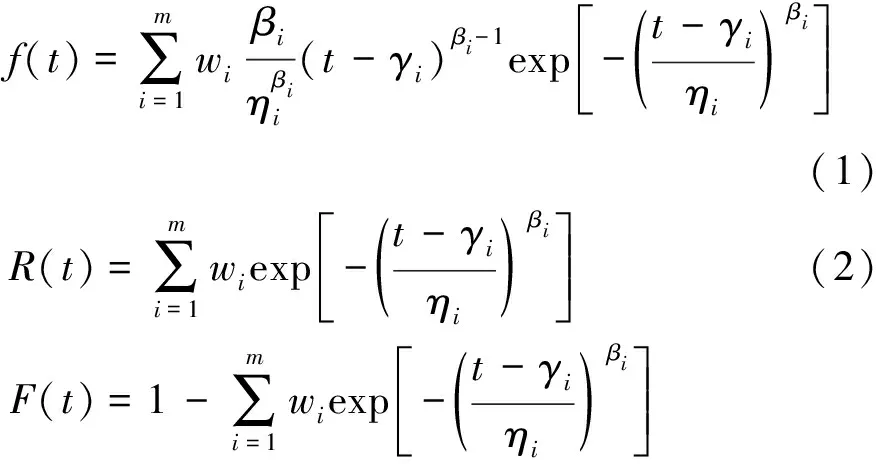
(3)
式中:m为混合威布尔分布模型的重数;wi为第i个子分布权重;βi为第i个威布尔分布的形状参数;ηi为第i个威布尔分布的尺度参数;γi为第i个子分布的位置参数。由于水稻插秧机从零时刻开始使用便有可能出现故障,所以位置参数γ=0,此时为两参数混合威布尔分布。
以PZ型水稻插秧机历史维修数据为例进行试验,共收集到282组故障数据,将282组故障间隔时间按照从小到大顺序进行排序,如表1所示。

表1 水稻插秧机故障数据
将故障时间t与函数值F(t)之间的关系通过式(4)转化为x与y之间的关系,将各点绘制在x-y坐标系中,得到数据点分布图,如图1所示。

图1 失效概率分布变换后的曲线Fig.1 The transformed curve of failure probability distribution
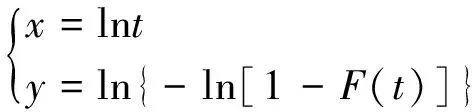
(4)
由图1可知,该曲线存在明显转折,转折前后有明显不同的斜率,如果用一条直线去拟合图中的数据点,误差将会很大,因此不能用单一威布尔分布去拟合这些故障数据,假设数据样本服从两重两参数混合威布尔分布。
2 参数估计及拟合优度检验
2.1 非线性最小二乘法
混合威布尔分布模型较复杂,无法将t和F(t)变换成线性关系,所以不能用线性回归的方法去估计未知参数[8]。非线性最小二乘法通过最小化残差平方和的方法估计参数,在数据的拟合分析方面有着广泛应用。利用非线性最小二乘法,建立两重两参数混合威布尔分布的非线性最小二乘优化模型。将容量为282的水稻插秧机故障数据样本按从小到大的顺序进行排列(t1,t2,…,t282),采用中位秩公式[式(5)]计算可靠度的观测值,即

(5)
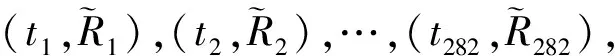
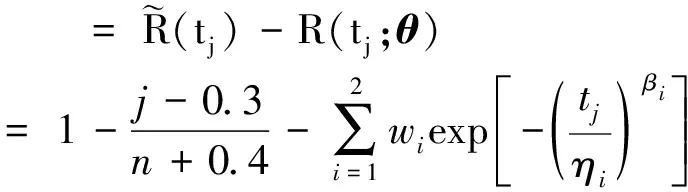
(6)
以残差平方总和最小为目标,构建混合威布尔分布参数估计数学模型为
(7)
式(7)中:g(θ)为混合威布尔分布参数估计模型的目标函数;βupi、βdowni分别为第i个子分布形状参数的最大值和最小值;ηupi、ηdowni分别为第i个子分布尺度参数的最大值和最小值。
式(7)为超越方程组,采用常规方法求解存在诸多困难,最佳途径是使用优化算法,找到一组最优的θ使对应目标函数g(θ)的值最小,此时的θ作为模型中未知参数的估计值。利用改进粒子群算法对式(7)的模型进行求解,将图解法的估计值作为粒子群算法的搜索空间,图解法粗略估计子分布权重w1在[0.3,0.4],尺度参数η1和η2的范围分别在[50,100]、[200,300],子分布形状参数的初始范围并不影响计算过程,先假定子分布形状参数的范围在[0,10],若计算出的子分布形状参的值在取值区间边界,则放宽该边界范围并重新计算。
2.2 改进粒子群算法
粒子群算法是一种基于鸟类群体觅食而提出的一种启发式全局优化算法[9]。粒子通过个体最优解pi和全局最优解pg不断迭代调整自身的位置和速度,从而不断更新候选解,在一个K维的目标搜索空间中,有N个粒子组成一个群体,粒子通过式(8)和式(9)进行更新迭代。
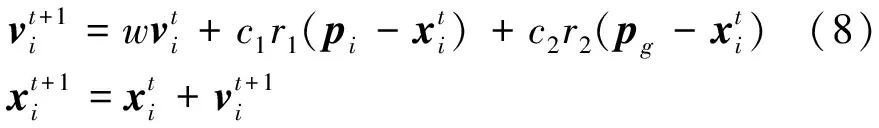
(9)
式中:vit和xit分别为第i个粒子第t次迭代时的速度矢量和位置矢量;w为惯性权重;c1和c2为学习因子;r1和r2是介于[0,1]的随机数。
在标准的粒子群优化算法中,惯性权重w、自身认知c1以及社会认知c2这三者在收敛效果中起着关键作用[10]。惯性权重w代表上一代粒子的速度对当前粒子速度的影响程度,在搜索初期阶段,可以将惯性权重w设置地较大些,保证粒子能够以较快的速度搜索到较好的区域,搜索后期,较小的惯性权重可以增加算法的局部搜索能力,保证粒子能在最优解区域做更精确的搜索。采用线性递减的惯性权重,其表达式为
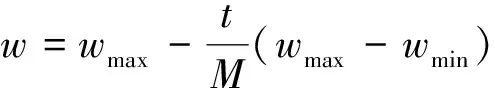
(10)
式(10)中:wmax、wmin分别为w的最大值、最小值;M为最大迭代次数。
在算法初期阶段,自身认知部分应该占优势,采取较大的自身认知c1,较小的社会认知c2,使得算法初期在整个空间进行搜索,保证算法的全局收敛。随着迭代次数的不断增加,自身认知部分c1应逐渐减小,同时,社会认知部分c2应该逐渐扩大,使粒子更关注于社会信息,保持快速收敛。设计的自适应学习因子表达式为
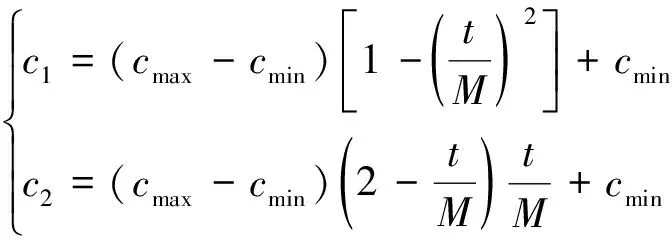
(11)
式(11)中:cmax、cmin分别为c的最大值、最小值。
将遗传算法的选择、交叉和变异操作引入粒子群的优化算法中,得到改进粒子群算法,该算法具有遗传算法全局收敛和粒子群算法收敛速度快的特点,改进粒子群算法的主要步骤如下。
步骤1初始化参数。包括种群个数N,最大迭代次数M,粒子速度和位置的界限,遗传算法和粒子群算法运行时所需参数等。
步骤2计算每个粒子的适应度值。将每个粒子的当前位置作为个体最优位置pi,当前粒子中适应度最小的粒子位置作为全局最优位置pg。
步骤3通过式(8)和式(9)更新粒子的速度和位置,然后检验其速度和位置是否超过边界范围,并计算更新之后每个粒子的适应度值。
步骤4计算平均适应度值,将平均适应度值的一半作为界限,小于此界限的粒子划分到子种群P1里面,其余粒子划分到P2里面。
步骤5子种群P1的粒子适应度值较小,直接复制进入下一代,子种群P2的粒子总维数的3/5分别与个体极值pi和全局极值pg进行交叉、变异操作,子种群P2通过选择交叉、变异之后得到的新子种群P3,计算P3中各个粒子的适应度值。将P2和P3粒子的适应度值进行比较,取适应度值小的一半进入到下一代。
步骤6更新个体极值和全局极值。计算新子代的适应度值,与个体极值和全局极值进行比较,如果新粒子的适应度值比个体极值pi的适应度值小,则更新pi,将当前新粒子的位置赋值给pi。如果新粒子的适应度值比群体全局极值pg的适应度值小。则更新pg,将当前新粒子的位置赋值给pg。
步骤7不断重复步骤3~步骤6,直到目标函数达到收敛精度或者达到最大迭代次数。
2.3 参数估计
在表1中给出的故障数据的基础上,利用改进粒子群算法对式(7)进行求解,改进粒子群算法基本参数:粒子群数目N=30,迭代次数M=50,cmax和cmin分别为2.0与0.5,wmax和wmin分别为0.9与0.4。粒子群算法的基本参数:种群和迭代次数和改进粒子群算法的保持一致,c1和c2为1.494 45,w为0.6,粒子群算法和改进粒子群算法的迭代过程如图2所示,参数估计结果如表2所示。

图2 粒子群算法和改进粒子群算法的优化过程Fig.2 Optimization process of particle swarm optimization and improved particle swarm optimization

表2 粒子群算法和混合粒子群算法的优化结果
在粒子群迭代过程中加入遗传算法的交叉、变异,从而增强了种群的多样性,避免算法陷入局部最优。在收敛速度上,从图2中可发现粒子群算法在迭代至45代左右达到最优值,而改进粒子群算法在迭代至20代左右达到最优值,表明改进粒子群算法比粒子群算法收敛速度更快,在收敛精度上,由表2可知,粒子群算法的收敛精度为0.015 2,而改进粒子群算法的收敛精度为0.014 5,表明改进粒子群算法具有更高的收敛精度,将改进PSO算法求出的参数值:w1=0.326 2,η1=72.821 6,m1=0.889 9,w2=0.673 8,η2=228.839 6,m2=2.050 0作为两参数混合威布尔模型的参数值。
2.4 拟合优度检验
为了验证所选分布模型的合理性,需要进行拟合优度检验。常用的模型检验方法[11]有χ2检验和K-S检验。相较于χ2检验,K-S检验更加精细[12],应用更为广泛。因此采用K-S检验法来检验模型的拟合优度。设总体分布为F(t),F0(t)为某个已知的连续型分布函数,假设检验问题H0:F(t)=F0(t)。
现假设:水稻插秧机的故障数据服从两重两参数混合威布尔分布。
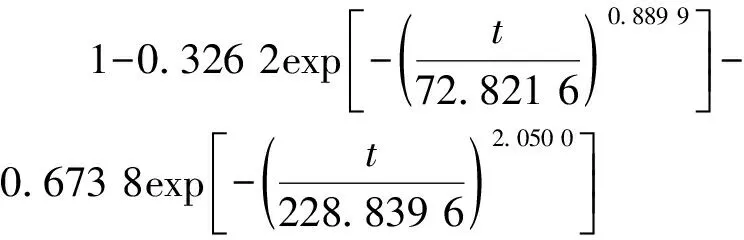
(12)
代入水稻插秧机的282组故障时间数据,详细数据如表3所示。
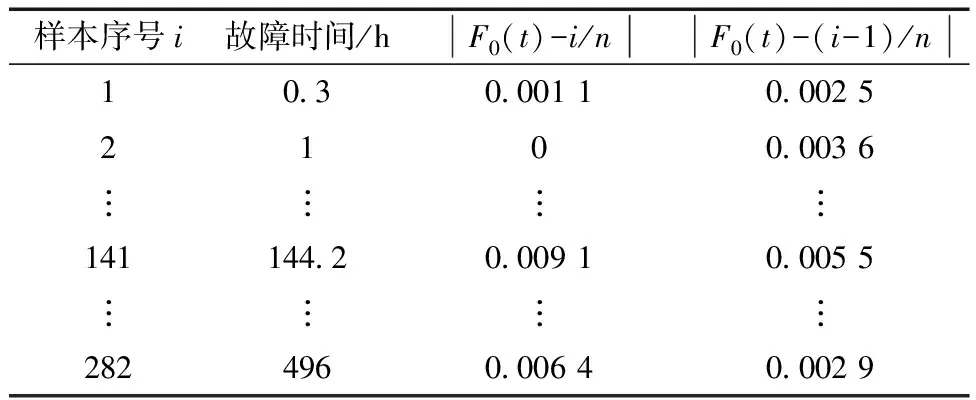
表3 插秧机寿命分布检验
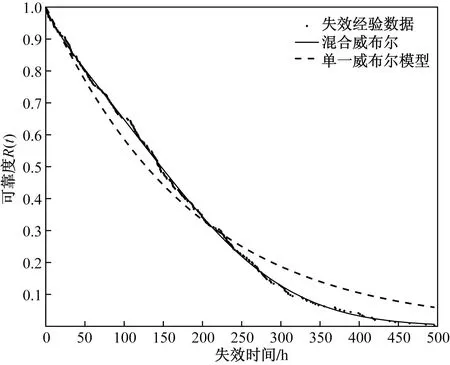
由表3结果可知,柯尔莫哥洛夫的检验统计量Dn=max{|F0(t)-i/n|,|F0(t)-(i-1)/n|}=0.022 8,当故障数据样本量n=282时,取显著水平a=0.05,查K-S临界值表可得d(285,0.05)=0.080 4,d(280,0.05)=0.081 2,通关比较可知Dn=0.022 8 可靠性分析是进行剩余寿命预测的基础[13]。上述结果表明,水稻插秧机故障数据服从两参数混合威布尔分布,将改进PSO算法求出的模型参数代入式(1)、式(2)得到水稻插秧机的故障概率密度函数f(t)、可靠度函数R(t)。绘制故障概率密度函数f(t)与t的关系图,如图3所示。 图3 水稻插秧机失效概率密度曲线Fig.3 Failure probability density curve of rice transplanter (13) (14) 在表1数据的基础上利用最小二乘法计算出单一威布尔模型的可靠度函数为 (15) 单一威布尔模型、混合威布尔模型的可靠度曲线与失效数据拟合效果如图4所示。 图4 水稻插秧机可靠度曲线Fig.4 Reliability curve of rice transplanter 从图4可以看出,混合威布尔分布与水稻插秧机失效数据样本的拟合效果要好于单一威布尔分布,能更准确描述水稻插秧机的失效规律,证明了所选两参数混合威布尔模型的合理性。水稻插秧机的可靠性评价指标包括平均寿命(MTBF)、中位寿命t(0.5)、特征寿命t(e-1)。 (16) 式(16)中:Γ为Gamma函数。 将表2中计算出的模型参数代入式(16)得到该水稻插秧机的平均寿命MTBF=161.75 h,通过式(14)可计算出:t(0.5)=147.14 h,t(e-1)=191.31 h。为了保证插秧机的可靠性,取可靠度R(t)为0.6来计算预防性维修周期,取不同的可靠度代入式(14)进行计算,得到不同可靠度下的水稻插秧机预防性维修周期如表4所示。 表4 不同可靠度下的插秧机预防性维修周期 根据表4可知,水稻插秧机的预防性维修周期随着R(t)的减小而增大,在R(t)为0.6时,预防性维修周期为115.19 h,水稻插秧机的平均寿命MTBF=161.75 h, 115.19 h小于插秧机的平均寿命,表明规定的预防性维修周期较为合理。 在可靠性理论中,具有年龄t的设备从t时刻开始继续使用下去直到失效为止所经历的时间称为具有年龄t的设备的剩余寿命[14],寿命模型能否准确描述产品的寿命分布,剩余寿命是关键,通过对剩余寿命进行预测,可以得知运行时长与剩余寿命之间的具体关系。 假设T是水稻插秧机的失效时间,水稻插秧机已经运行了时间t,那么剩余使用寿命时间为条件随机变量x,其中t (17) 式(17)中:x为剩余寿命时间。 将式(12)代入式(17),计算出水稻插秧机的剩余使用寿命x的可靠度函数Rt(x)为 (18) 现以A、B、C、D四台正在运行的水稻插秧机为例进行剩余寿命预测,A、B、C、D四台水稻插秧机的工作时长t分别为50、100、200、300 h,将t代入式(18)中,可得水稻插秧机剩余寿命可靠度曲线如图5所示。 从图5中可以看出,随着水稻插秧机运行时间的增加,相同可靠度下的剩余寿命相应得减少;运行时间越长,其可靠度曲线越陡,与实际情况相符合,水稻插秧机运行时间越长,受到的磨损、冲击越严重,那么插秧机剩余使用寿命就越低,表明水稻插秧机剩余寿命预测模型的有效性。根据式(18)可计算得到A、B、C、D水稻插秧机的中位寿命分别为129.47、107.21、73.72、54.11 h,即进行插秧机进行预测性维护时,优先对工作年龄达到300 h的D水稻插秧机进行维护。 针对单一威布尔模型不能准确评估含多种失效模式的水稻插秧机,利用两重两参数混合威布尔分布对失效数据进行拟合,通过改进粒子群算法和最小二乘法相结合求解出模型参数。然后通过K-S检验以及比较单一威布尔和混合威布尔的可靠度曲线与失效数据的拟合效果证明了混合威布尔模型的合理性,并利用该模型计算得到相应的可靠性指标,最后在混合威布尔模型基础上对水稻插秧机进行剩余寿命预测,得到水稻插秧机运行时间和剩余寿命之间的对应关系。 研究过程及结果如下。 (1)针对单一威布尔模型不能准确描述多种故障机制并存的水稻插秧机的失效规律,利用混合威布尔模型进行评估,提高评估的准确性。 (2)与传统的粒子群算法相比,利用改进粒子群算法计算得到的参数值更加准确,得到了更准确分布模型。在此模型基础上计算出了水稻插秧机的可靠性指标以及预防性维修周期。 (3)在更准确的混合威布尔模型的基础上计算得到插秧机的剩余使用寿命,便于使用和维修人员安排合理的修理计划。 后续研究过程中,将水稻插秧机分为多个子系统,针对故障多发的子系统分别进行可靠性分析,使得整机的可靠性分析更加准确。3 可靠性分析及剩余寿命预测
3.1 可靠性分析


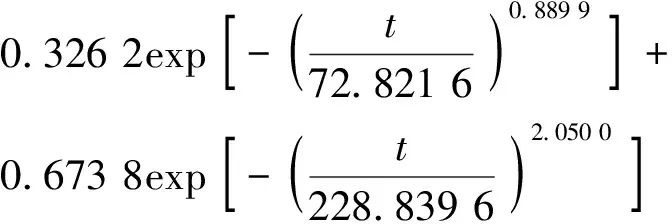

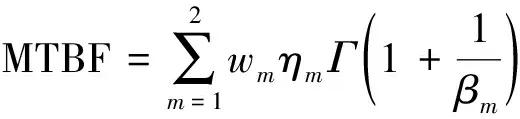

3.2 剩余寿命预测
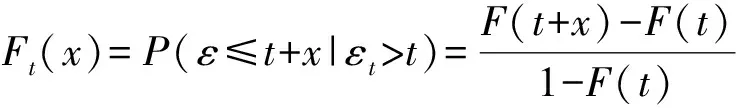
4 结论
猜你喜欢
南方农机(2022年23期)2022-12-01中老年保健(2021年8期)2021-12-02作文评点报·低幼版(2020年3期)2020-02-12幽默大师(2019年4期)2019-04-17幽默大师(2019年3期)2019-03-15华人时刊(2018年17期)2018-12-07幽默大师(2018年11期)2018-10-27幽默大师(2018年3期)2018-10-27数学大王·低年级(2017年9期)2017-09-18奥秘(2017年12期)2017-07-04
