
基于Spark技术的气象数据分析
2024-02-04 08:01刘丽景刘力维郝婉婷
黑龙江科学 2024年2期
刘丽景,刘力维,王 林,郝婉婷
(1.西安培华学院,西安 710125; 2.西安交通大学,西安 710049; 3.西安市临潼区气象局,西安 710600)
0 引言
随着天气数据类型的不断增多、信息量的增加,社会对气象数据实时获取的要求越来越高,跟踪、统计及收集实时数据对于诸多行业、企业及个人来说都具有较高的实用价值[1]。对于大多数气象数据应用场景来说,建立高效的数据收集、传输、存储及分析系统至关重要。使用现代化的传感器、卫星遥感技术及物联网技术,可实时地收集、传输及发布气象数据。利用流处理技术(Apache Kafka、Spark Streaming和Apache Flink)可实现实时数据的处理及分析[2],基于这些技术可更好地应对气象数据的增多及信息量的增加,为各行各业提供更精准的气象信息,支持决策及应对天气变化。本研究主要基于Kafka和Spark技术,实现对陕西省各城市的气象数据分析与可视化[3],对相对湿度、温度、空气质量、风级等进行多维度可视化,能够支持分析预测未来14 d高低温度变化、未来7 d气候分布及风级等。
系统主要流程包括实时气象数据采集、数据清洗与预处理、数据处理与分析、结构化数据存储、数据可视化等部分,利用网络爬虫技术采集中央气象台的气象数据,将数据发送到Kafka消息队列[4]中。使用Spark技术快速高效分析数据,将分析得到的结果存储在MySQL中,基于Spring Boot框架搭建web系统管理数据并运用Echarts进行数据分析及可视化展示,具体过程如图1所示。
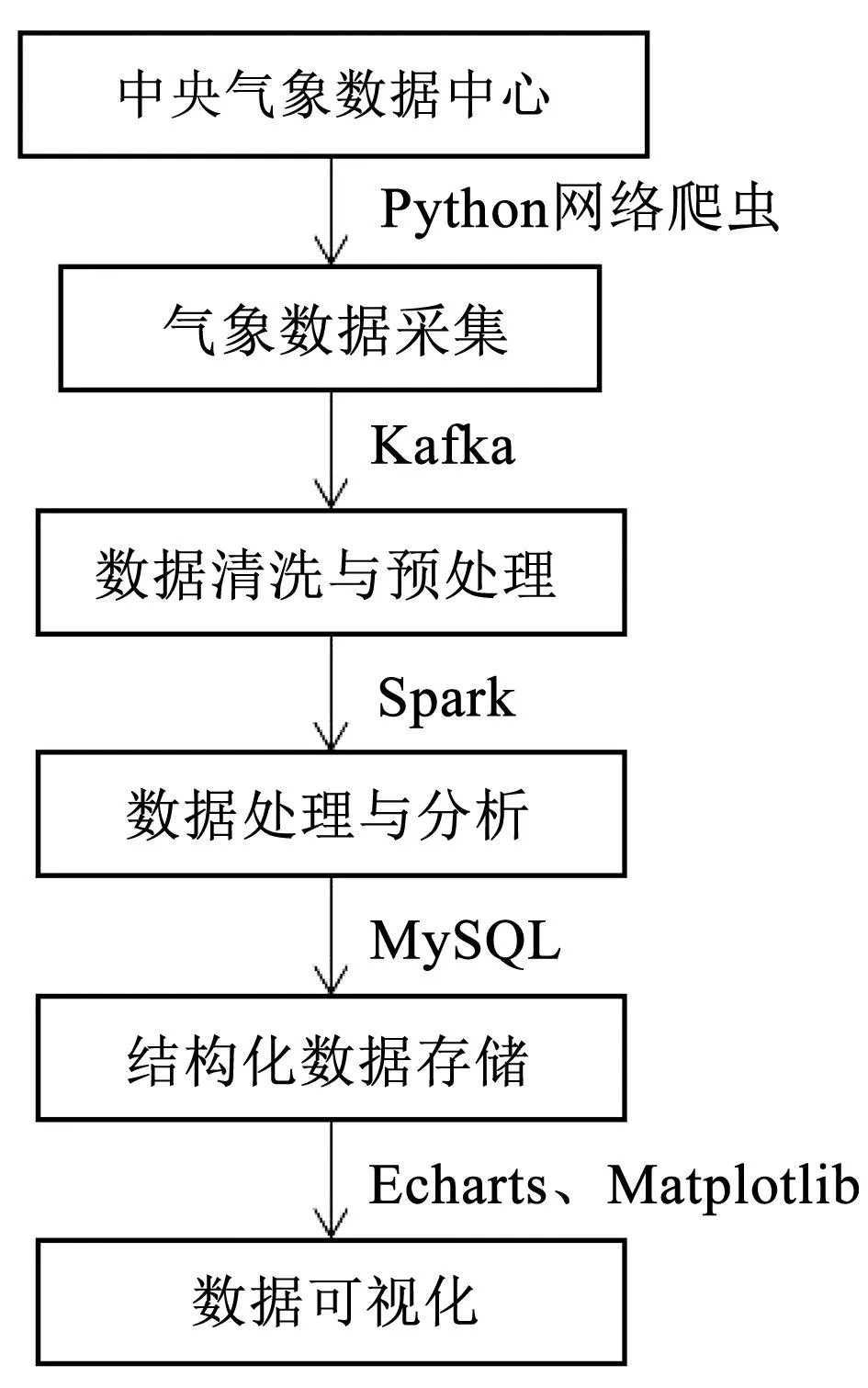
图1 数据分析处理流程Fig.1 Data analysis process
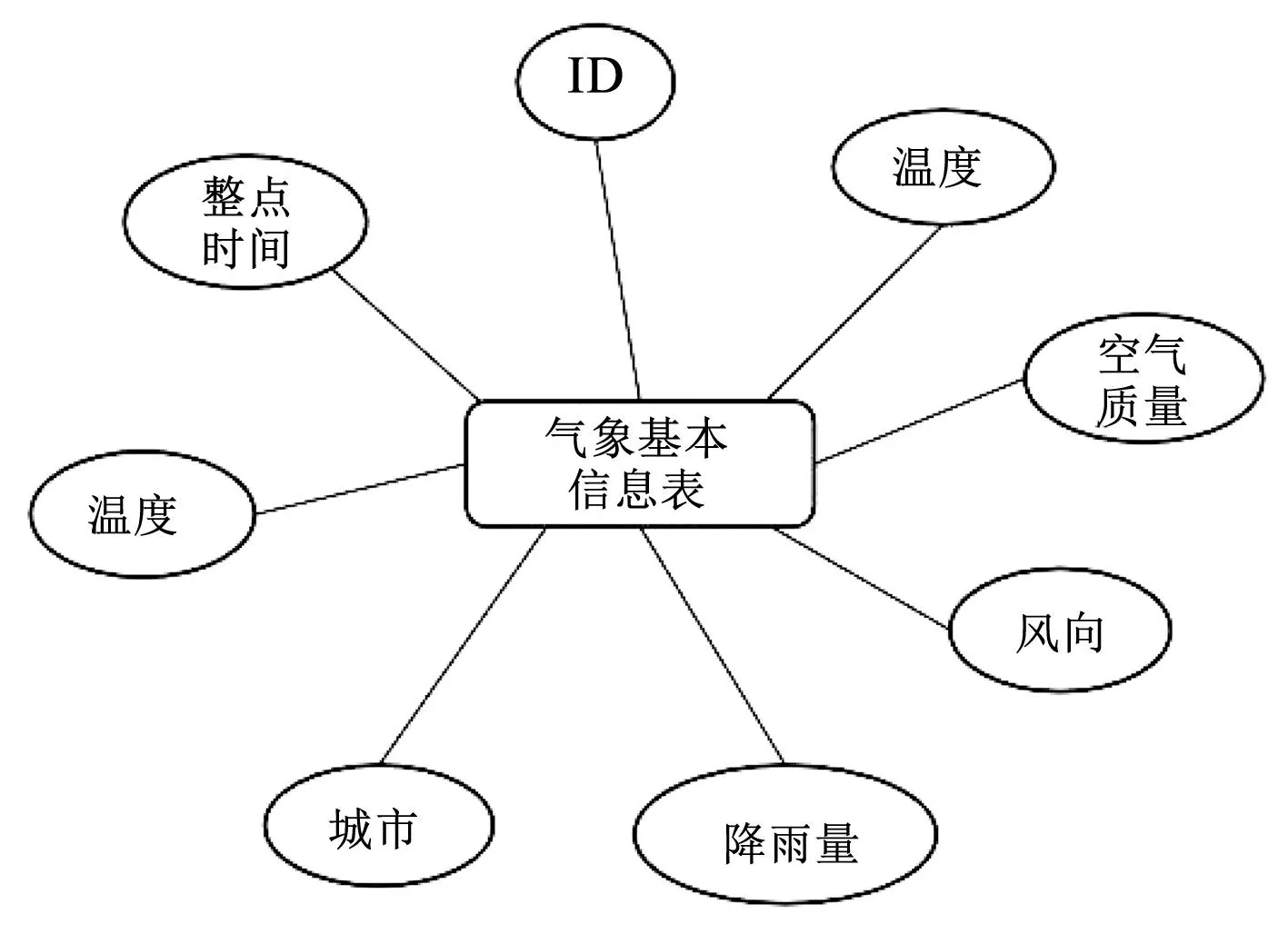
图2 气象基本信息表E_R图Fig.2 Table E_R chart of basic meteorological information
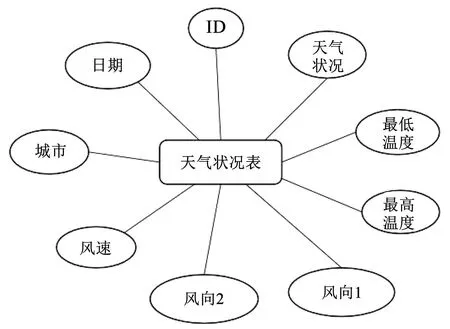
图3 天气状况表E_R图Fig.3 Weather table E_R chart

图4 一天内相对湿度曲线值Fig.4 Relative humidity curve on one day
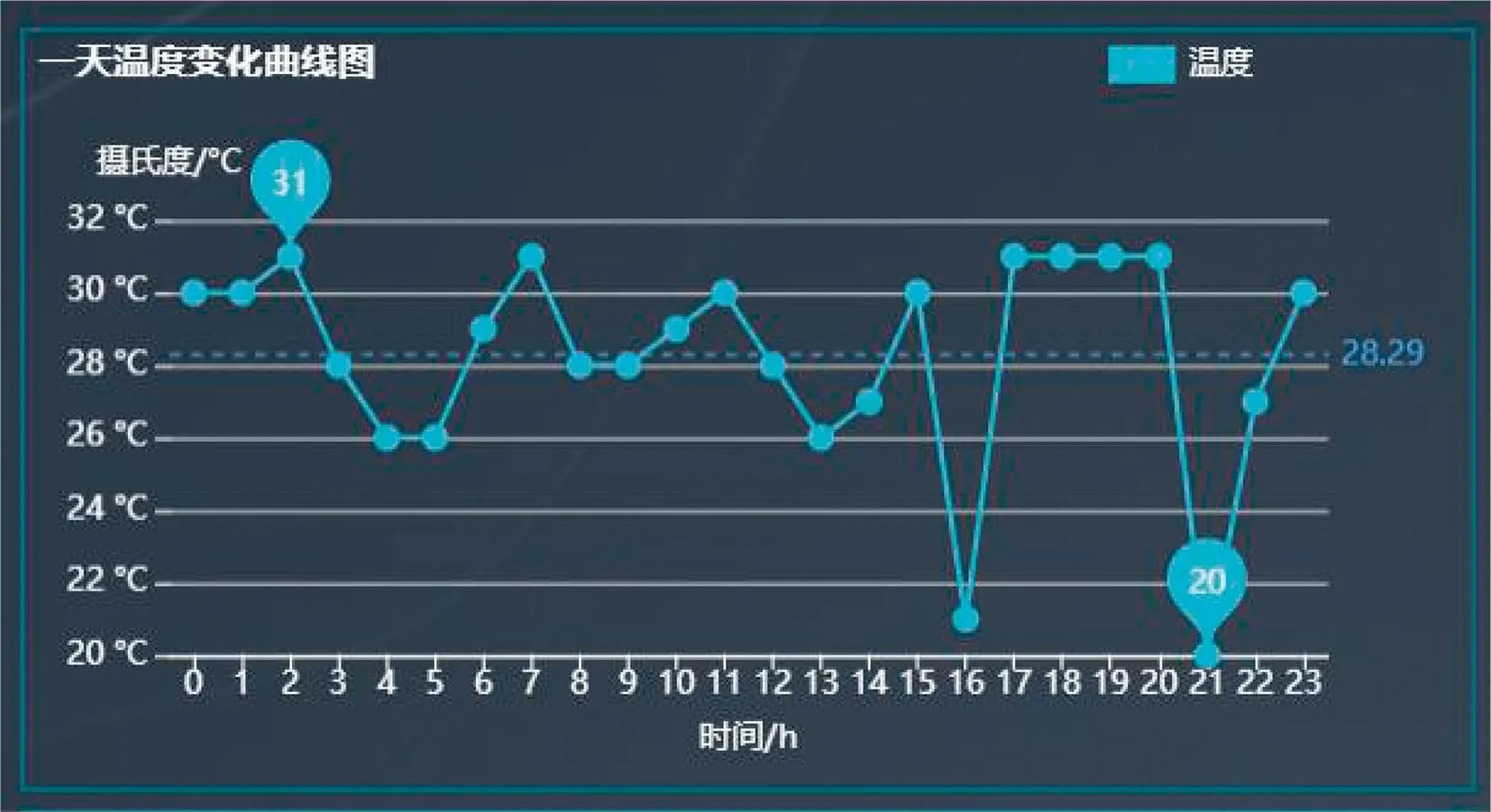
图5 一天内温度曲线值Fig.5 Temperature curve on one day
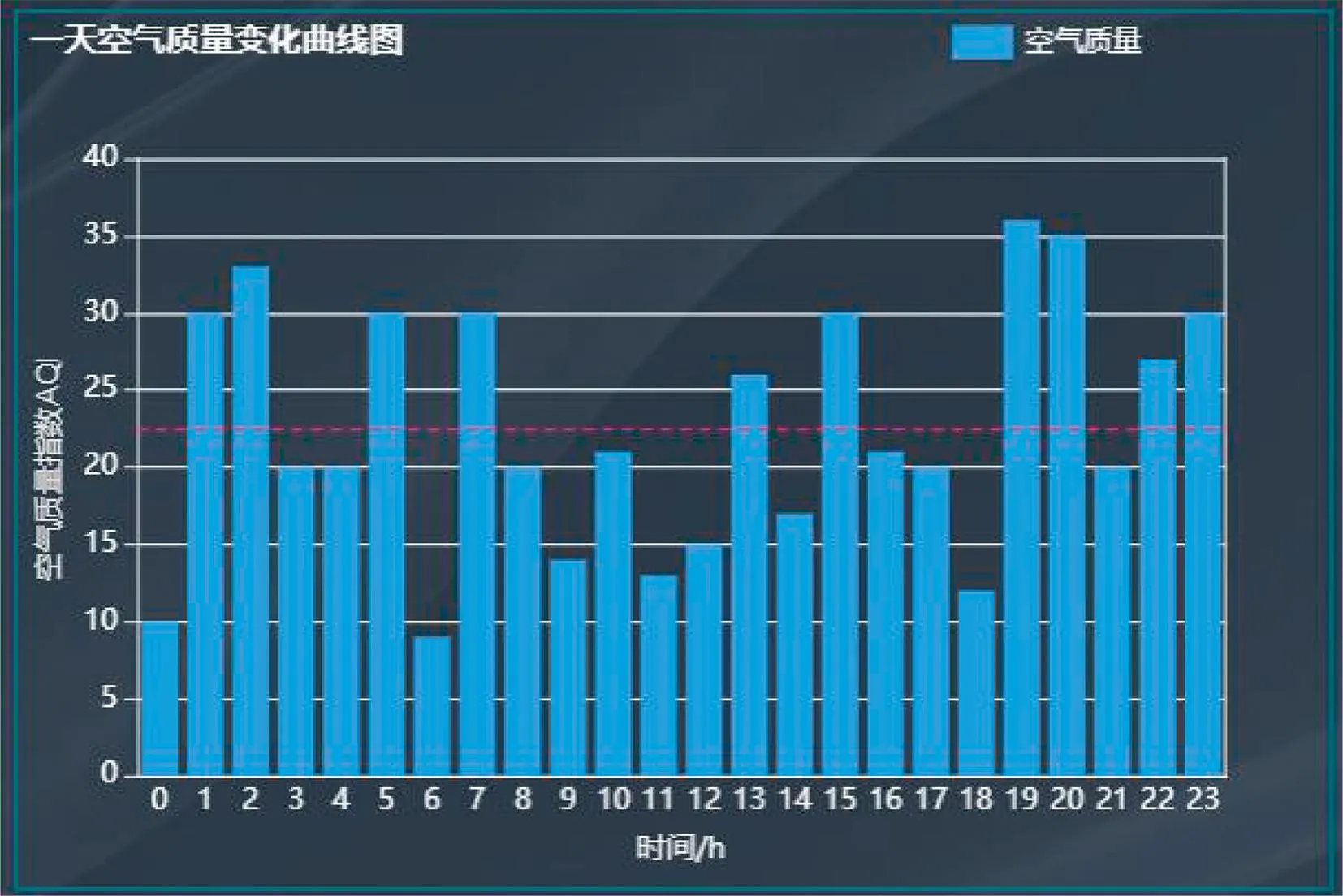
图6 一天空气质量变化Fig.6 Air quality changes on one day
采集陕西省各城市气象数据,数据主要来源于中央气象台官方网站。数据采集流程具体为:获取陕西省及省内各城市的编码,进行记录,分析各城市24 h整点天气页面,分析页面结构、页面源代码等,基于爬虫技术爬取各城市24 h的整点天气数据,将数据打包成JSON格式的消息发送到Kafka队列中。基于爬虫技术快速获取实时数据,设置定时器功能,设定每60 min执行一次爬虫程序,以获取准确的实时数据。爬虫程序将爬取到的数据通过BeautifulSoup库来解析数据,转换为python对象[5]。提取的数据主要包括气温、城市、日期、风速、风向、湿度、降水量、气压等,提取到的数据最终被转换为JSON格式的字符串,以便在Kafka队列中进行传输。
1 Kafka数据传输
经爬虫采集到的气象数据被封装成JSON字符串后发送到Kafka中名为“weather_data”的Topic[6]。Kafka以分布式方式存储数据,数据被复制到多个Broker上,Broker接收并持久化发布到Topic的数据,确保数据的高可用性及容错性。客户端在获取气象数据时,使用Kafka的Consumer客户端订阅“weather_data”这个Topic,Kafka将数据传输给订阅该Topic的客户端,客户端可以按照自己的速率处理数据。整个过程中,Kafka的分布式架构和高吞吐量特性确保了可靠、高效的气象数据传输,保证数据能够准时送达消费者,在数据量增大时也能够处理并存储大规模的气象数据[7]。
2 数据清洗与预处理
数据清洗和预处理是在对数据进行审查及校验过程中发现并纠正数据文件中可识别的错误,按照一定的规则纠正错误或冲突数据。通用的数据清洗与预处理主要包括处理异常数据、重复数值及缺失值等。
1)异常数值。采集的数据往往存在一些异常值,这些异常值可能由于数据采集错误、传输错误等原因导致,会严重影响数据分析结果,因此需要进行异常值处理。常用的异常值处理方法包括删除异常值、替换异常值、截尾等,可提高数据准确性及可靠性。
降雨量数据正常范围应在[0,100],爬取的数据中出现了明显超过正常范围的数值,如178、-1等,基于异常值删除和异常值替换对其进行处理。异常值删除:将降雨量字段中大于100的值删除。异常值替换:对降雨量字段中小于0的值使用0替换。
2)重复值。重复记录与数据采集及传输等原因可能导致数据集中存在部分重复值,即同一时间和地点下有多个数据记录,这样的数据对分析结果有一定的影响,需进行数据预处理。采集到的数据集气压存在重复部分,针对重复的数据采用合并相加取平均值的方式处理。
3)缺失值。由于种种原因,爬取的气象数据可能存在部分缺失的情况,在数据清洗与预处理过程中需对这些缺失值进行处理,以保证数据的完整性及准确性。爬取的数据中温度字段存在缺失值,采用相邻两项相加取平均值的方式进行填充,具体计算方法如公式1所示。
Tn=(Tn-1+Tn+1)/2
(1)
3 实时气象数据分析
在实时气候分析模块需通过Spark SQL分析原始数据集,得到气象基本信息表和天气状况表,用以绘制一天内温度变化、一天内相对湿度变化、一天内空气质量变化、一天风级变化、未来14 d高温低温变化、未来14 d风级变化、未来14 d气候分布等图表。
对于气象基本信息表,需获取原始数据集,将其转换为DataFrame格式,使用Spark SQL从原始数据集中提取整点时间、温度、风向、降雨量、湿度、空气质量及城市字段。整点时间:使用hour函数从日期字段中提取整点时间,例如日期字段为2022-04-13 14∶23∶45,则整点时间为14。风向:使用udf函数将原始数据集中的风向字段转换为英文缩写形式,北风转换为N,东北风转换为NE。空气质量:使用case when函数将空气质量字段划分为优、良和一般三个等级。温度、降雨量、湿度、城市字段直接使用原始数据集中的数据。
对于天气状况表,需从原始数据集中提取日期、气压、温度、降水量、风向及城市字段。天气状况:根据原始数据集中的气压、湿度及降水量字段,使用when函数和otherwise函数来判断天气状况。根据降雨量字段判断:降水量大于100,为大雨;降雨量大于50小于100,为中雨;降雨量大于0小于50,为小雨;降雨量为0,则根据湿度判断。湿度大于60,为阴;小于60则根据气压判断。气压小于1000,为多云,否则为晴天。最高/低温度:选取原始数据集中温度字段和日期字段,将日期字段转化为日期类型yyyy/MM/dd,按照日期和城市分组,使用man/min函数计算每个分组中的最高/低温度。风向1和风向2:将原始字段的风向值除以180°得到一个值,将这个值拆分成两个数,一个为sin值,一个为cos值,用arctan 2函数将这两个数转化为角度,转化后的sin值和cos值分别对应风向1和风向2。城市:使用原始数据集中的城市字段。
4 结构化数据存储
基于气象数据分析结果设计了两张结构化数据库表,即气象基本信息表和天气状况表,根据这两张表中的数据绘制可视化分析图表[8]。对两张表的逻辑结构和物理结构分析如下。
气象基本信息表主要包括ID、温度、空气质量、风向、降雨量、城市、温度、整点时间等属性。逻辑结构设计如下。
物理结构设计如表1所示。
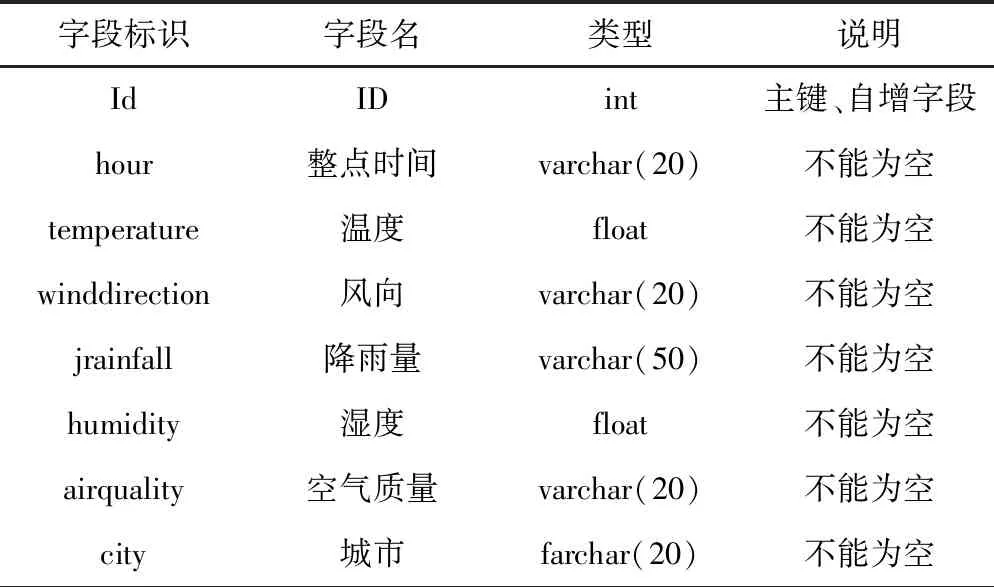
表1 气象基本信息表物理结构
天气状况表主要包括ID、日期、天气状况、最低温度、最高温度、风向1、风向2、风速、城市等属性,逻辑结构设计如下。
物理结构设计如表2所示。
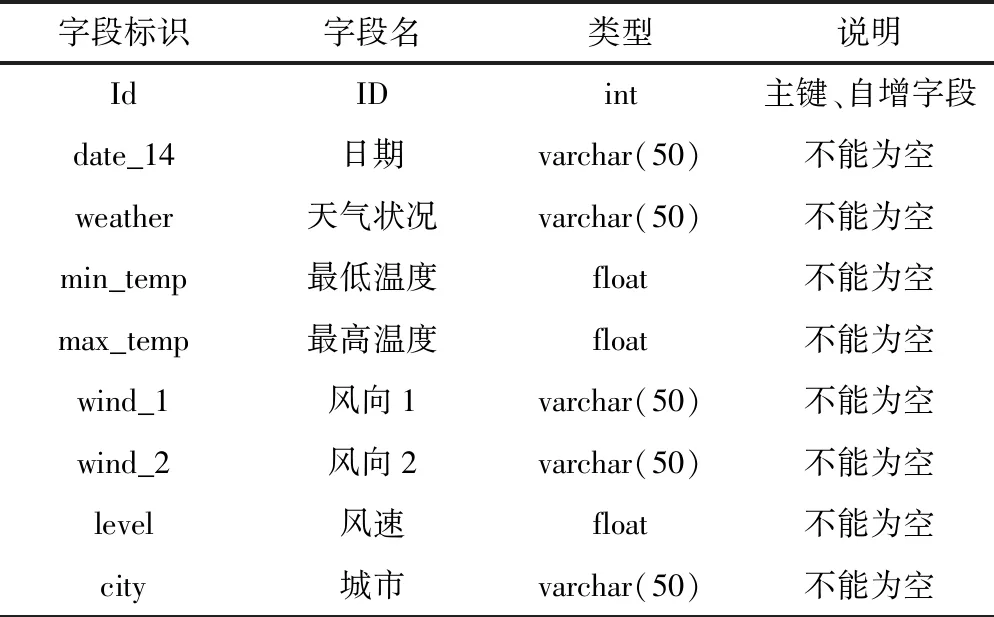
表2 天气状况表物理结构
5 数据可视化展示
数据可视化部分主要对当天的湿度、温度、空气质量、风级等做实时展示,并对未来7 d和14 d的气候分布、温度变化等做出预测。
1)相对湿度曲线。根据天气基本信息表中的整点时间和相对湿度值计算平均相对湿度、最高相对湿度、最低相对湿度的值及其所在的小时数,将一天内24h分布作为X轴,获得的相对湿度作为Y轴,绘制一天内的相对湿度曲线。
2)温度变化曲线。根据天气基本信息表中的整点时间和温度数据,将整点时间作为X轴,温度作为Y轴,绘制一天内的温度变化曲线。
3)空气质量变化。根据天气基本信息表中的整点时间和空气质量数据,将整点时间作为X轴,平均空气质量作为Y轴,绘制一天内的空气质量变化柱状图。
4)风级图。将天气状况数据表中的风向1和风向2转换为角度值,以45°为间隔划分不同的角度区间,计算每个区间内的风速平均值,得到一个包含8个值的列表,使用极区图绘制风向与风速的分布情况,如图7所示。
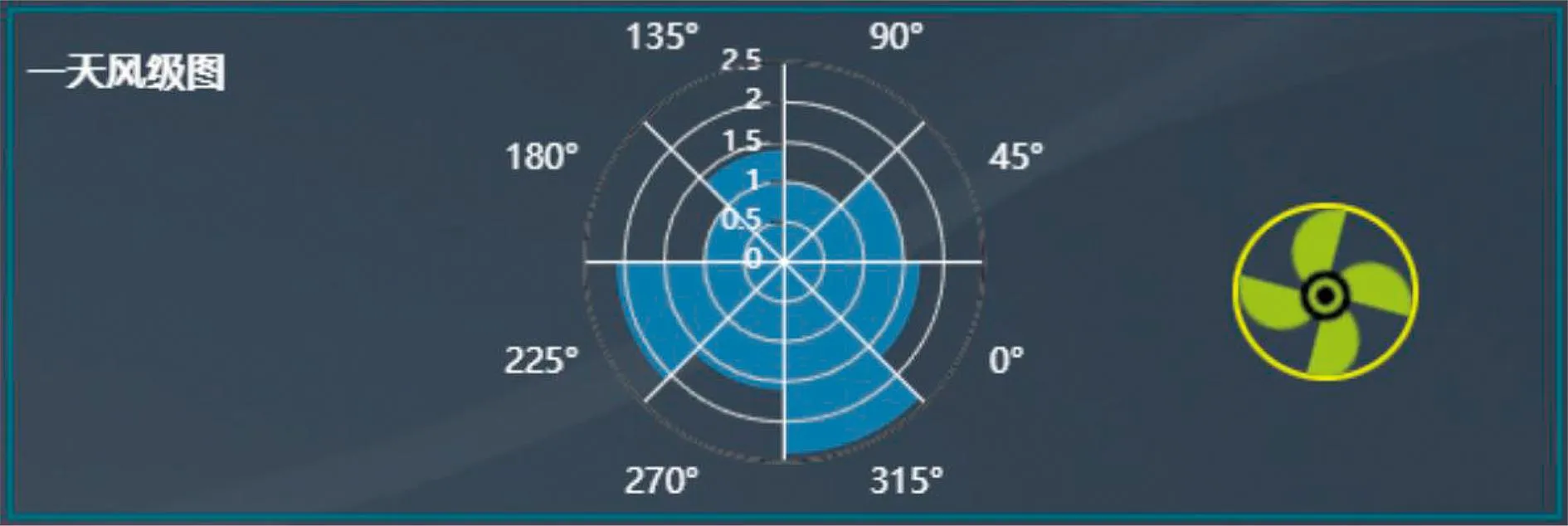
图7 风级图Fig.7 Wind scale chart
5)未来14 d气候分布。在天气状况数据表中获取未来14 d的天气数据,循环对每种天气出现的次数进行计数,并将结果保存在字典中,将字典的键值作为标签,字典的值用于表示饼图中每个扇区的大小,未来14 d气候分布绘制如图8所示。
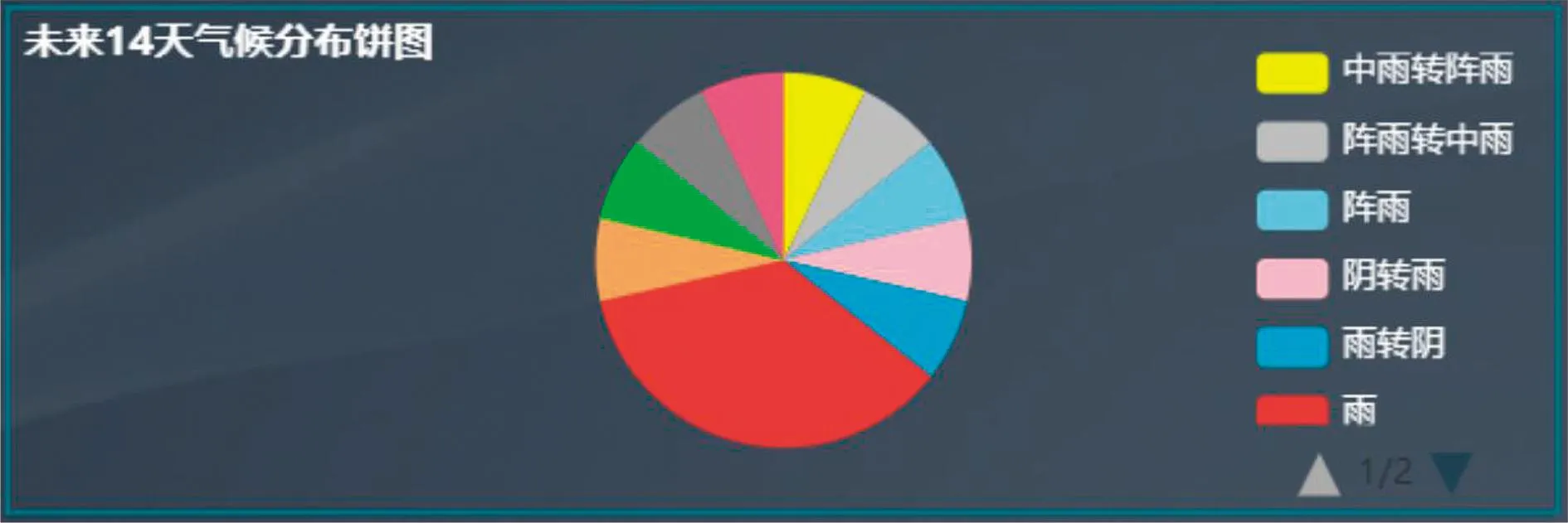
图8 未来14天气候分布Fig.8 Climate distribution in the next 14 days
6)最高和最低温度变化曲线。将天气状况表中的日期、最低气温和最高气温数据提取出来,计算每天的最高/最低温度及最高/最低温度的平均值。利用温度数据绘制高温度曲线、低温度曲线、平均温度虚线,如图9所示。
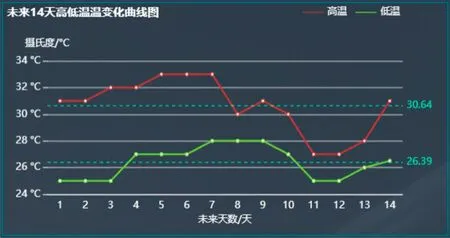
图9 未来14 d高低温曲线Fig.9 Temperature curve in future 14 days
6 结束语
设计了一种基于Spark的实时气象数据分析流程,可实时获取并处理数据,并将数据转化为直观易懂的可视化展示,使人们更好地理解和分析天气情况。对于实时数据的处理,使用Kafka消息系统,Kafka的分布式架构和高吞吐量特性确保了可靠、高效的气象数据传输,保障了数据的准确性,能够处理并存储大规模的气象数据。此设计流程与方法可快速处理分析大规模的气象数据,提供准确的分析结果和强大的可视化功能。应用此设计系统可更好地应对不断增加的气象数据,提供准确的气象信息及预测,为社会各个领域提供有价值的支持和决策依据。
猜你喜欢
China Report Asean(2022年8期)2022-09-02
中学生数理化·七年级数学人教版(2021年4期)2021-07-22
中学生数理化·七年级数学人教版(2021年4期)2021-07-22
物联网技术(2020年12期)2021-01-27
汽车零部件(2017年4期)2017-07-12
学生天地(2017年9期)2017-05-17
小资CHIC!ELEGANCE(2016年26期)2016-12-13
知识经济·中国直销(2016年3期)2016-02-27
初中生世界·八年级(2015年2期)2015-08-04
风能(2015年8期)2015-02-27
