
图书馆馆藏的人工智能比对服务
2024-01-31 06:02曾元显
新世纪图书馆 2023年11期
曾元显
0 引言
近年来数字化技术的蓬勃发展,已获得许多机构的广泛认可和采用。拥有独特内容的图书馆或是典藏机构,已陆续建立了数字化档案服务。数字化的典藏,不仅让使用者便利地随时随地查询、取用,更成为其学习、创意的重要来源。
除了传统的图书馆大量地导入数字化馆藏服务,非传统图书馆机构也纷纷加强其独特典藏数位服务。例如,台湾科学教育馆将其自1974 年以来保存的超过12 000 份全台湾中小学科学展览获奖作品,数字化后放置在其网站(https://twsf.ntsec.gov.tw/);高级中等学校图书馆辅导团则建立中学生网站,保存并分享自2008 年以来大约110 000 份台湾中学生小论文比赛获奖的作品。这些独特资料的数字化分享,除了典藏的目的外,更重要的是其具有学校教育、学生学习的意义。
虽然立意良好,但这些典藏有被误用的情形。由于科学竞赛或是写作竞赛每年都会举行,这些典藏文章的部分或是全部的内容偶尔会出现在不同年份的竞赛作品中。这类抄袭案件并不罕见,而且一旦发生,就会对这些教育竞赛造成严重损害。
相似性比对被认为是检测这些作品有否异常的有效措施。然而商用比对系统不仅价格高昂,其客制化也不容易,因而阻碍了其部署与应用。在本文中,我们运用人工智能(Artificial Intelligence, AI)技术,采用相关的开源或是自由软件,展示学校实验室即可实作出来比对服务,用于检测待归档作品和典藏档案的相似内容。实际应用于上述两个教育网站典藏资料的比对,可以帮助发现抄袭40 年前旧作之情形。透过AI 技术的自动比对,可以更快、更明确地指出不同作品间的异同之处,甚至比专家找出更多雷同作品。而比对结果反馈回学校,让师生可从实际的活动中学习教训,提升学术伦理素养的教育。
在下面的章节中,我们将先介绍相关的人工智能技术,再简要说明利用开源软件建置的比对系统架构,进而列出实际的比对案例与异常比例,最后提出相关建言,供图书馆与典藏机构参考,并提及未来的挑战。
1 人工智能的相关技术
近十多年来,云端技术兴起强化了计算机运算力、大数据时代提供巨量的训练资料,以及机器学习算法的精进与突破,使得人工智能在计算机视觉、语音辨识、自然语言的理解与生成、语意比对等方面,有了突破性的进展,并被广泛应用于搜寻引擎、智能型手机、自动驾驶等系统,逐渐融入到人们的日常生活中。这些人工智能新技术包含嵌入矢量、Transformer、语言模型、语意比对等,对信息检索的学术理论与实务经验,带来很大的变革,其原理简述如下。
1.1 嵌入矢量
矢量空间模型(Vector Space Model, VSM)是经典的传统信息检索方法(Salton, 1989)[1]。其将语料中每份文件的重要词汇(有主题意义的词汇),都视为矢量中的一个维度,而将词汇在文件中的出现次数(Term Frequency, TF)以及在整个语料中出现篇数的倒数(Inverse Document Frequency, IDF)两者相乘(TF×IDF),做为该维度的权重。如此n 篇文件的语料库若共有m 个词汇,就形成一个m × n 的矩阵,其中每一行矢量代表一篇文件,而每一列矢量则对应到一个重要词汇。依矢量余弦公式(cosine),可计算任意两文件或是两词汇的相似度。
另一种VSM 的表示法,则跟语料无关,单纯以“独热编码”(one-hot encoding)表示。亦即m 个词汇,每个词汇都占一个维度,该词汇在该维度上的值为1,其余为0。例如,假若全部词汇只有三个:政治、经济、运动,则其独热表示法,分别为[1,0,0]、[0,1,0]、[0,0,1]。其优点是:(1)词汇跟其矢量的对应,只需简单的查表即可;(2)很多机器学习算法,只能做二分法,亦即侦测一个词汇有出现(以1 表示)或没出现(以0 表示),因此需要用到独热编码。
上述两种VSM 表示法的问题,在于用个别词汇作为矢量的维度,当有不同词汇却语意相近时,因属不同维度,也无法增加其相似度,造成词汇不匹配问题(vocabulary mismatch)。例如:“宇宙”跟“太空”,以VSM 表示的话,其相似度为0。因此,在1990 年左右,隐含语意索引法(Latent Semantic Indexing, LSI)被提出[1],其运用线性代数的奇异值分解(Singular Value Decomposition, SVD)方法,将m × n 的矩阵降维转换出d × d 的主题矩阵,其中d < m且d < n。亦即,语料C 被降维,并以新的矩阵来近似整个语料,如下式:
个别文件(或词汇)的矢量仍可从这个降维的矩阵算出近似值,依此亦可算出任意两篇文件(或是任意两个词汇)的相似度。此种降维的做法,让语意相近的文件(词汇),被转换对应到同一维度,解决了前述词汇不匹配的缺点,如图1 范例所示 。

图1 降维矩阵范例
图1中语料C矩阵有“星际大战”等5篇文件,若只搜录7 个词汇,各词汇出现的次数(或权重)表示在公式(1)等号左边的矩阵。等号的右边有三个矩阵,分别为词汇到主题的U 矩阵、主题矩阵 Σ、主题到文件的V 矩阵。从 Σ 对角线矩阵可知,此语料C 其实只有两个主题比较重要(姑且称为“动作科幻”“文艺爱情”两个主题),且重要程度分别为12.4 与9.5。
在图1 的例子中若再多收纳两个新词汇T8(宇宙)、T9(太空),且其在这五篇文件出现的情况分别为:T8=[5,0,0,0,0]与T9=[0,4,5,0,0],则此两词汇的矢量余弦公式cosine 相似度为0;但若将其矢量转换到主题空间,亦即各自乘以缩减后的V 矩阵,如下:
则转换后的词汇矢量T8*=[2.81, 0.63]、T9*=[5.18, 0.52],其cosine 相似度高达0.99,表示词汇T8 与T9 属于同一主题的讯息相当明确。在此例中,因为乘上V矩阵而转换后的矢量,即为其嵌入矢量。
一个词汇(或是文句、概念)的嵌入矢量,也可以运用神经网络学习而得。如图2,将C矩阵的资料送入学习,可得出如上述将五维词矢量转换成二维词矢量的功能,此五份文件的嵌入矢量为图2 神经网络连结上的权重所示。亦即,五份文件的独热表示法,可以透过机器学习转换成其嵌入矢量,而此嵌入矢量来自于学习后的权重:
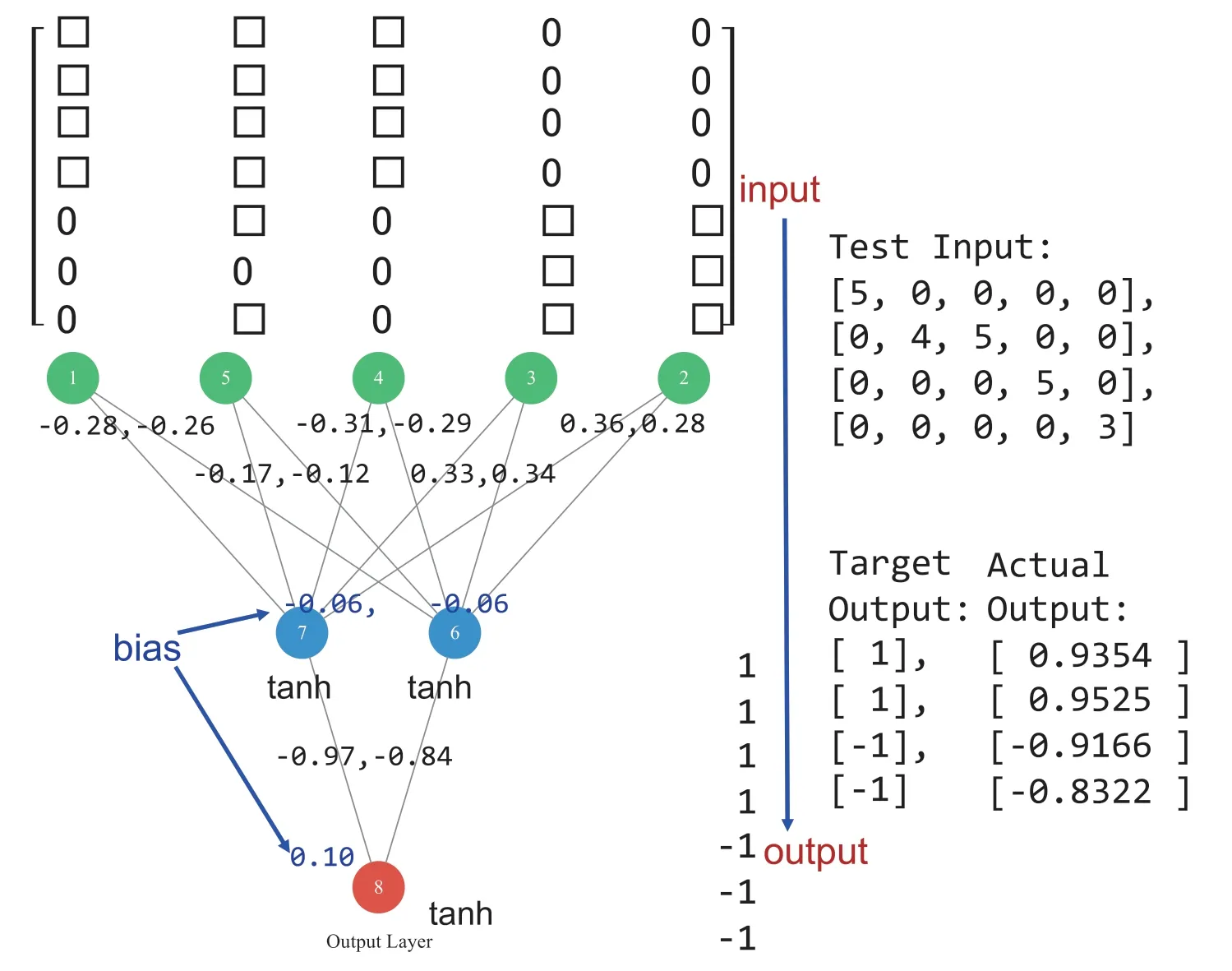
图2 透过神经网络的学习,可将五维的整数词矢量,转成二维的实数词矢量
在图内中间两个神经元的输出值,相当于公式(2)或(3)的二维矢量;亦即相同主题的五维整数矢量输入,会有相似的二维实数值输出。
1.2 Transformer
上述只有两层、五个输入的神经网络,只能处理比较简单的两个概念问题。为了处理更复杂的语意概念,可以使用更多的人工神经元,加深、加广神经网络使用的层数及输入个数。
2017 年Vaswani 等学者提出了Transformer编译码器(encoder-decoder)或称为转换器的深度神经网络架构[2],如图3。其运用可以平行运算且能够处理长距离依赖(long-distance dependency)的自我注意力机制(self-attention),取代需要循序运算的递归神经网络(recurrent neural network),而在自然语言处理领域,开启了突飞猛进的时代。
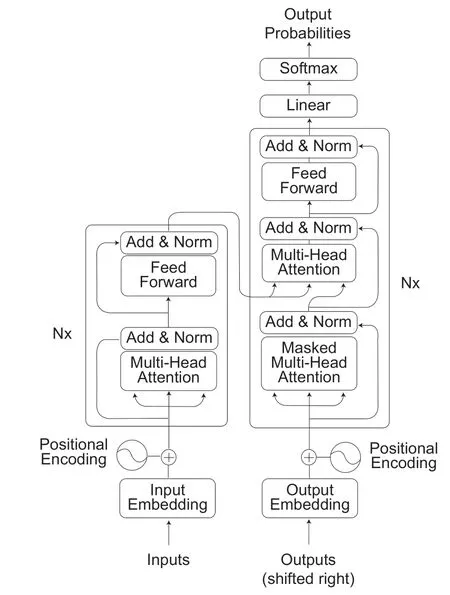
图3 Transformer 架构[2]
Transformer 中的多重注意力(multi-head attention)对最后的成效是极为重要的运算机制。其让每个注意力专注于不同面向,例如有的注意力关注在动词与其发起者或是作用对象的信息交流而抓住了文句的重点,有的则让代名词注意到其所代表的主词而缓和了指代消解(Coreference Resolution)的问题等。
除了具备多重注意力机制,Transformer 还运用Byte Pair Encoding(BPE)解决词汇量不够与未知词问题、引入位置编码以学习词汇的顺序与距离、采用layer normalization 与residual connection 以增进网络的学习效率和稳定性,而在语言理解与生成上,得到很好的成效。
1.3 语言模型
许多自然语言处理的任务中,都需要建构一个准确的语言模型(language model)。亦即在获知前t 个字词后(t 可以是1、3,甚至是100、2000 等长度),需要准确估计下一个字词的条件机率:
例如,从语音讯号辨识出“mao zhuo lao shu”四个音及前三个字“猫捉老”之后,下面的条件机率应该要符合:
依照常识,在自然语言的表达上,“猫捉老鼠”比起“猫捉老树”应有较大的机率。此种条件机率没有标准答案,只要相对合理即可。
建构此语言模型的过程,称为语言建模(language modeling)。然而语言建模过去很难做得好,亦即“估计下一个字词的条件机率”不易做得准确。以语料库C=(猫跳, 狗跃, 猫奔, 狗跑, 跑车)为例,用此极小(五个字句)的语料库拟训练出P(跳|猫)等条件机率,应用传统方法“最大似然估计”(maximum likelihood estimation)可得出:
等数据,因为在C 中猫出现2 次,而猫跳、猫奔各出现1 次。但是条件机率:
亦即(狗跳, 狗奔)两词的机率都为0,因为他们都没有在语料库C 中出现过。换言之,用C 训练出来的语言模型,几乎不会产生(狗跳, 狗奔)的词句。但事实上,不仅C 中有类似的概念(狗跃, 狗跑),于一般语言常识上也应该允许该词汇的出现。
显然传统的方法不够好,其缘由为离散空间的字词表达方式(discrete space word representation),亦即将猫、狗、跳、跃、奔、跑、车各字视为完全不同的概念(如同前述VSM 表示法),导致类似的概念无法类推,且训练语料中没有的字句,便难以估计其条件机率。
有鉴于此,神经机率语言模型于2000 年左右被提出(Bengio, Ducharme, Vincent, & Jauvi,2003),其将各个字词w 以n 维实数矢量V(w)表示,亦即每个字都是n 维连续空间上的一个点,此种称为连续空间的字词表达方式(continuous space word representation), 与前述嵌入矢量类似。当神经机率语言模型从语料库学习完后,V(猫)在连续空间上会近似于V(狗)、V(跳)会近似于V(跃)、而V(奔)会近似于V(跑),因而可用于推论出语料库中不存在的词汇。
如图4 的范例所示,每个字词可以是二维空间中任意连续坐标上的一点,当训练完后猫的坐标(-1.1,0.8)接近于狗的坐标(-0.9,1.0),跳(1.2,-1.1)近似于跃(1.1,-0.8),依此类推。那么语料库原有的(猫跳,猫奔)会有较高的机率值(例如0.45),而语料库中没有的(狗跳, 狗奔)也可在连续空间中推论出其机率值(例如0.35),而不再等于0 了。而车则因为与猫、狗较不相似,难以类推,使(车跳、车奔)这些字词的机率较低,但也并非完全不可能出现。
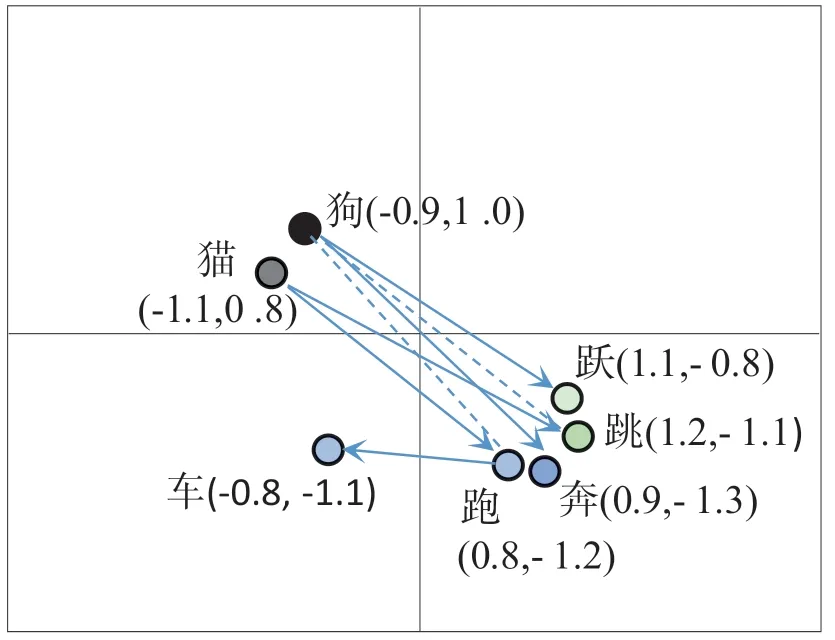
图4 在二维连续空间中表示字词矢量关系之示意图
这种以连续空间表示字词的矢量表示法,降低了训练语料无论大小,都无法穷举所有语言现象的困扰;而且透过神经网络的学习,可以学出“类似概念有近似矢量”的表达方式,亦即嵌入矢量的概念。
将一群离散的物件进行嵌入转换后,除了容易进行相似度计算、推论原先不存在的关系外,也可以从极大量资料中,训练出品质较佳的嵌入矢量(称为预训练模型, pre-trained model),而可以分享给其他类似的任务进行微调(fine-tuning)运用。
Transformer 是一个建构语言模型的优良架构,可以轻易地扩展其规模来学习更大的训练资料、容纳更长的输入字符串,而能将输入转成优良的嵌入矢量,来代表输入的语意。Transformer 的编码器被Google 采用为善于理解语言的BERT(Bidirectional Encoder Representations from Transformer),而其译码器被OpenAI 采用为善于生成文字的GPT(Generative Pretrained Transformer)。即便都只用了Transformer 的一半架构,BERT 跟GPT 也都发展出了很好的嵌入矢量转换器,并且演变成大型的预训练语言模型。
1.4 语意比对
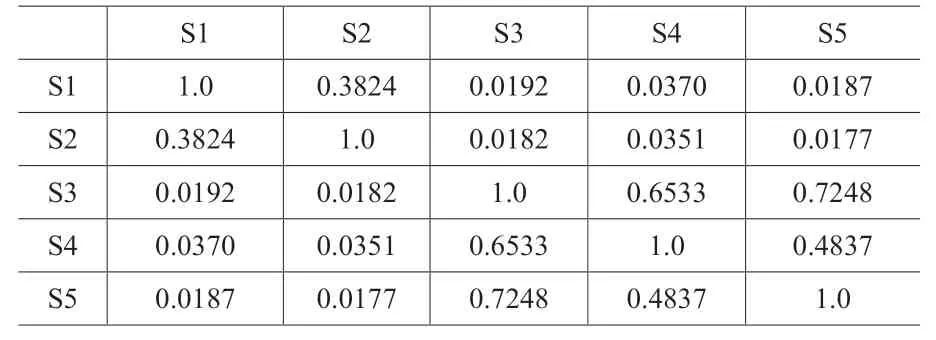
使用大型的预训练语言模型,可以有效地进行下游自然语言处理或是信息检索的任务,如:语意比对、问答、分类等。以下面五个句子为例:
S1=“我的儿子!他猛然间喊道,我的儿子在哪儿?”
S2=“我的小孩呢!他突然高声说:我的孩子在哪里?”
S3=“若未于2 周内完成中、高风险弱点修补或防御因应,公司系统网站将依资安规范下架”
S4=“因应中、高风险弱点修补的防御,假设两周内不能完成,将依资安规定关闭公司系统的网站”
S5=“若未于2 周内完成中、高风险工事修补或防御因应,本司系统防务将依军安规范不予下放”
以传统字符串比对方式(将文句切割成单字词以及双字词),计算这五句彼此之间的相似度,结果如下:
?
而以嵌入矢量,计算这五句彼此之间的相似度,程序码如下:
通过运行程序计算,其结果如下:
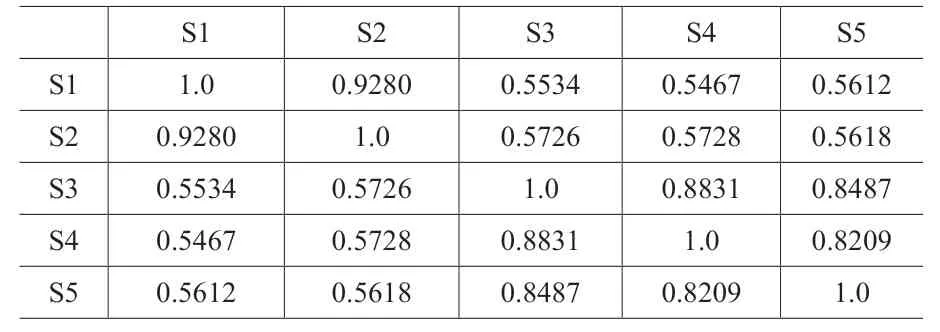
?
可以看出,S1 跟S2 只是同义词置换,但字符串相似度仅约0.3824 而很难被视为同样意思的文句;但其嵌入矢量相似度达0.9280,接近1.0,两者有相当高的语意相似度。S3 跟S4之间也做了类似同义词的置换或是改写,而S3与S5 句型一样,只是一个在讲公司的资安,一个在讲司或处单位等级的军事安全,两个句子所处的主题领域不同。但是以字符串相似度而言,S5 比S4 更相似于S3,这是不正确的;而以嵌入矢量的相似度而言,S4 比S5 更相似于S3,这是我们想要的结果。此例显示AI 技术运用于语意比对,有其优势。
2 比对服务建置
对于文本比对,Foltýnek 等学者,将其分成五种样态[3]。
(1)逐字拷贝:亦即简单将别人的文字,拷贝到自己的文章内。
(2)语法拷贝:文字拷贝后,仅代换同义词、技术词汇等,而保留语法。
(3)语意拷贝:进一步改写拷贝来的文句,或拷贝其他语文的文字再自动翻译。
(4)构想拷贝:在结构或概念上抄袭别人的著作。
(5)找人代写:将别人的写作,误导为出自己手。
比对技术的相关文献已有提出各种方法,来侦测各类抄袭样态。其中以资讯检索的矢量空间模型,来进行字符串上的比对(lexical match),最广为运用,且成效良好,而机器学习、人工智能技术则最有潜力运用在各类型抄袭样态上。
虽然在侦测方法上,有很多研究在处理语意拷贝等较难辨识的抄袭样态,但实务上,各种抄袭比对系统,大多针对逐字拷贝的抄袭样态进行侦测。这是因为逐字拷贝的样态不容易否认,而语意拷贝的样态即使被侦测出来,可能还需其他方式佐证,否则很难认定为抄袭。如前面的S3 与S4 这两个句子,除非有更多且连续的语意相似句,单就一句语意相似,不易证明其有抄袭情形。有了上述的概念,侦测文件相似的系统,架构设计如图5。
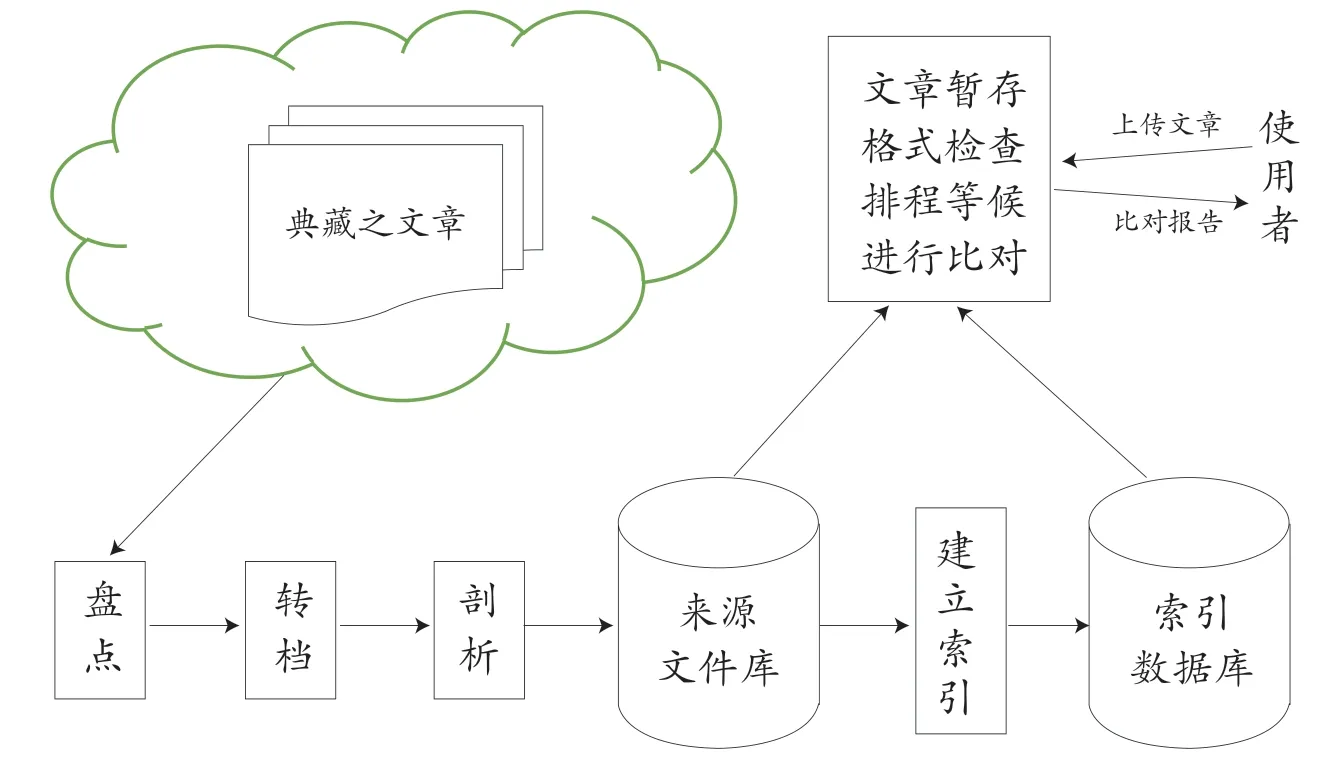
图5 比对服务系统架构
典藏单位将历届作品之PDF 档案汇出,由比对系统转档为纯文字,然后储存到来源文件库,透过比对核心系统建入索引数据库。使用者将待检验之作品上传到比对系统,比对系统先撷取文字后,将其与索引数据库中的作品进行比对,并产生比对结果报告。图5 中使用到的自由/开源软件,列举如下:
(1)影像文字档解析:
A.Tesseract: https://github.com/tesseract-ocr/tesseract;
B.LSTM 为基础的OCR 引擎,支援达116 种语言。
(2)档案文字解析:
A.Apache Tika: https://tika.apache.org/;
B.可解读出数位档案的文字内容,超过1000 种档案格式,包括:PDF、PPT、XLS、Word、RTF 等。
(3)搜寻引擎:
A.Elasticsearch: https://www.elastic.co/elasticsearch/;
B.基于开源的Lucene 的分散式全文搜寻引擎。
(4)断句、断词:
A.Python的各种开源套件,如NLTK等。
以上软件工具搭配我们发展过的技术,建立起实用的比对系统:
(1)曾元显,概念性标题产生方法,专利号:ZL 2008 1 0127624.4.;
(2)曾元显,相似文件的自动侦测方法,专利号 : I 317488.;
(3)曾元显,渐进式关联词库之建构方法,专利号: I 290684 .;
(4)曾元显,中文数位文件之自动摘要方法,专利号: I 288335.;
(5)曾元显,数字文件关键特征的自动撷取方法,专利号:ZL 00 1 22602.9.。
以科教馆为例,其历年来累计12 194 篇作品PDF 档,但其中有2 506 篇的内容全部为影像文字档。为了自动辨识影像中的文字,我们采用开源的OCR(Optical Character Recognition)工具 Tesseract,将2 506 篇影像全部自动辨识成数位文字后,连同其他全文档案共12 194 篇历届作品建入索引,一同作为后续作品的比对来源。
3 比对服务案例
将上述系统应用于科教馆及中学生网站的典藏比对上。在2021 年10 月科教馆收到的276 篇全台科展的作品中,本系统除了成功检测出41 篇科教馆已知的延续性作品,也额外找出13 篇先前未知的雷同作品。
而在2022 年3 月至5 月间,29 个县市(区)举办的地区科展中,共有5111 篇作品纳入比对。相似度门槛值设定为0.5,这样设定既能够有效地发现复制贴上的文句,也可以看到经过改写的文句。我们将比对后的状况定义为四种类型,状况名称及其操作型定义如表1 所示。
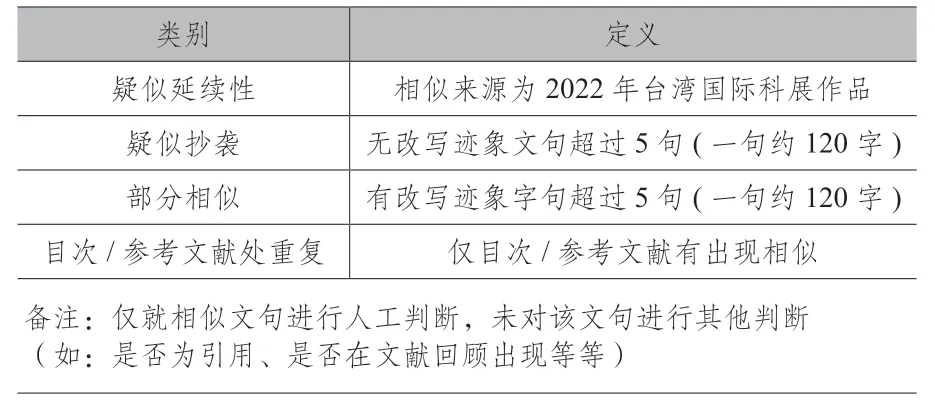
表1 县市科展比对情况定义
此次比对,相似对数总共有 449 对,疑似抄袭总共有 102 对。比例约102/5097= 2%,其中更有抄袭40 年前旧作之情形。
有2022 年的参赛作品档案“生物/A15国小组-生物科-叶子比一比-常见植物叶片的分类与观察.pdf”与1982 年的作品档案“7641_092.pdf,作品名称:排排叶子”,共计有7 段文句雷同(比例:23.33%)。然而这类型的扫描文献档,若非先行通过OCR 技术将其转换成文字档进行相似度比对,以人工审查实难发现雷同之文件。由于生物、物理、化学等基础科学知识并不会随时间大幅改变,若未能察觉2022 年作品雷同1982 年作品,后续可能会不断有跟40 年前旧作雷同之现象,实非科学展览活动所乐见。
而针对11 万篇中学生网站小论文得奖作品的重复性比对,以人工检视最相似的前500 对,结果如表2 所示。在疑似抄袭他人作品的 109对中,其抄袭的样态统计如下:

表2 中学生小论文11 万篇最相似前500 对统计结果
(1)疑似抄袭之年级分布为:高三(59%)、高二(26%)、高一(15%);
(2)疑似被抄袭年级分布为:高三(45%)、高二(38%)、高一(17%);
(3)疑似抄袭相隔期数比例:1 期(46%)、2 期(15%)、抄袭同期(12%);
(4)疑似抄袭同校作品的比例为 47%。
高年级生可能有争取得奖的压力,因而囫囵吞枣,甚至铤而走险地使用别人的文字,充当自己的内容。
4 结语
图书馆或典藏机构的数位馆藏,以传承、公益、知识传播、教育为目的,虽然易于被使用,但也易于被滥用,引入相似性比对服务,有其必要。相似性比对服务不仅可在纳入典藏以前,对文献进行相似性检测以发现异常,对于过去典藏的作品也可以进行回溯性检测,以盘点重复典藏。现今人工智能技术虽然便于发展出成效良好的比对服务,但其误用,也令人担忧。研究发现,现成的7 种AI 生成文字的侦测器,都对非英语为母语的作者存在偏见,亦即非英语母语者写的TOFEL 作文,容易被侦测为是AI 生成的文章,而近似程度的美国八年级学生写的作文,则不容易被误判为AI 生成的文章。显示目前AI 的生成技术,较AI 的侦测技术成熟。未来学生或甚至成人若大量运用AI生成文章而有欺骗行为,将较以往更难防范。相关的技术与规范,宜及早规划,以因应人工智能时代的来临。
猜你喜欢
新世纪智能(语文备考)(2021年4期)2021-08-06
新世纪智能(语文备考)(2019年3期)2019-01-12
航空知识(2018年1期)2018-04-16
航空知识(2017年9期)2017-12-07
航空知识(2017年1期)2017-03-17
小学生导刊(高年级)(2016年11期)2016-11-14
工业设计(2016年8期)2016-04-16
中央社会主义学院学报(2016年6期)2016-03-01
航空知识(2014年11期)2014-11-21
