
数据分析抢先机:图书馆大数据资料的活化与加值应用
2024-01-31 06:02曾淑贤吕宝桂洪伟翔
新世纪图书馆 2023年11期
曾淑贤 吕宝桂 洪伟翔
0 引言
21 世纪是信息爆炸的时代,各行各业都因为信息科技的发展,展开了前所未有的改变与革新,其中大数据一词更随着信息科技的发展成为热门话题与发展趋势。当前,大数据在生活中已不再是一个陌生的词汇,事实上大数据的时代已经来临,而所有人都是贡献相关数据的其中一员。Intel Data Centric 高峰论坛(2020)指出,从手机、智慧家电到政府与企业的电子系统,各种数据、实时资料不断地被创造及累积,社会大众正用难以想象的速度创造海量的数据。2016 年全球民众共产生1.61ZB 的资料量(1ZB 等于1,000 亿GB),而至2025 年更将成长至163ZB,是2016 年的10 倍。有鉴于资料的爆炸式增长,如何更有效地进行资料分析与活化数据资料的应用亦为各界关注的焦点。
图书馆向来在信息处理与信息传播的环节中扮演重要的角色,随着时代的演进,图书馆不断地进行蜕变与转型,从图书馆1.0、图书馆2.0 逐渐步入图书馆3.0、图书馆4.0。在图书馆4.0 中,强调的是一个可以分析信息,并提供读者个人化、差别化、智慧化服务的智慧图书馆[1]。在图书馆中,存在着各种不同形式的数据资料,有书目资料、读者借阅资料、活动参与资料、电子资源使用资料等各式不同的数据资料,美国公共图书馆协会(American Library Association,ALA)、博物馆和图书馆服务研究所(Institute of Museum and Library Services,IMLS)、图书馆杂志(Library Journal)等组织,都在积极搜集和分析图书馆数据资料。广义而言,大数据资料可以是质性的资料或量化的资料;可以是结构化的资料、半结构化的资料或非结构化的资料;亦可以是一手资料(primary)、二手资料(secondary)或是三手资料(tertiary)等[2]。George, Hass 和Pentland 亦指出:大数据资料的搜集系从生活中各种来源而取得,包括网络信息的点击、行动载具的交易、使用者产出的内容、社群媒体或是商业交易等,全都属于大数据资料的来源[3]。随着各式各样资料大幅的累积与成长,传统的资料分析维度与大数据资料的分析结果是不可相比拟的,因此各行各业皆积极的搜集与进行各种大数据资料的分析,期望能藉由大数据的分析,洞悉行业未来的发展趋势。
在图书馆中,大数据资料的搜集大致可分为五种类型,包括数位存取纪录(数据库、电子书、电子期刊、网站登入纪录等)、流通纪录(图书资料借阅、馆际互借纪录等)、工作站使用纪录(共享空间计算机借用纪录等)、图书馆利用纪录(利用教育、工作坊等参与纪录),以及参考服务纪录等,上述这些资料皆是图书馆中常见也是图书馆能着手进行搜集与整理的相关资料。本文以图书馆大数据服务平台的资料搜集、分析与应用为主题,分别就大数据平台建置,以及数据资料的活化运用与加值分析进行分享。
1 图书馆大数据服务平台建置
1.1 跨县市合作,汇整各地区大数据资料
因应数据分析的趋势,为了解台湾民众的阅读全貌与阅读兴趣,2020 年起,汉学研究中心(以下简称本中心)开始着手进行“图书馆大数据服务平台建置计划”(以下简称大数据平台)。大数据平台以台湾省22 个县市,约600 间公共图书馆的读者去识别化借阅纪录资料(以下简称读者阅读兴趣资料)为核心,进行台湾省首个图书馆大数据平台的建置。为搜集各县市公共图书馆去识别化之读者阅读兴趣资料,以Nicholson(2006)提出之书目探勘(Bibliomining)架构为基础,规划各县市公共图书馆读者阅读兴趣资料提供之格式[4]。
Nicholson(2005)的书目探勘架构,将书目探勘的资料格式区分为三个部分。(1)作品相关资料(data about a work):书名、作者、主题标目等与作品本身相关的资料,可由书目纪录(机读格式纪录)、Dublin Core 信息或内容管理系统等取得。(2)使用者相关资料(data about the user):使用者资料须考量使用者的隐私议题,应以去识别化方式纪录,并可采取人口统计(demographic surrogate)方式,以地区、区域等统计指标替代个人信息,降低机敏性。(3)服务相关资料(data about the service):此资料为使用者与作品的关联,包含日期、时间、地点及使用方式等信息。
基于上述Nicholson 的书目探测架构,将读者阅读兴趣资料定义为三大部分,分别为书目信息、借阅信息与馆藏信息,所需资料由各图书馆的书目记录、馆藏记录与流通记录中萃取并去识别化,所涵盖的资料栏位信息内容分别是:(1)书目信息:书名(正题名、副题名)、作者、出版社、出版年、版本、国际标准号码(ISBN、ISSN、ISRC 等)、分类号,以及作品语言等;(2)借阅信息:借阅者类型、加密ID、出生年、借阅年月日时间,以及归还年月日时间等;(3)馆藏信息:图书馆识别码、馆藏号、馆藏地、典藏区域、馆藏类型,以及部册号等。
完成资料格式的订定后,透过讨论会议的方式,邀集各市县公共图书馆代表针对资料格式的细节进行讨论,并于会议中确认由本中心代表与图书馆自动化系统厂商洽谈,统筹资料传输程序开发事宜,节省重复开发,同时达资料之一致性;另档案格式与传输方式,则以JSON(结构化的文字资料交换格式)作为档案格式,透过SFTP 加密方式每月以系统排程方式定期传输至本中心大数据平台。
1.2 规划资料清理与整合流程,整并各县市资料
完成大数据平台建置的基础工程后,即进入数据资料的清理与整合步骤。ETL 为大数据清整经常规划的流程,分别代表撷取(Extract)、转换(Transform)与载入(Load),是为了将多个资料来源的资料整并至一笔资料所进行的程序[5]。参考Bala、Boussaid 与Alimazighi 之大数据资料处理流程[6],在大数据平台中的ETL程序,由各县市图书馆上传的资料(JSON)进行档案的拆解,并转入资料暂存区,并依据资料清整规则,进行书目资料的正规化及清理、馆藏类型的辨别、图书分类号的标准化,借阅时间的标准化等转换程序,最后将清整完成的数据资料载入至大数据平台数据库中,以待后续各项分析应用(如图1 所示)。
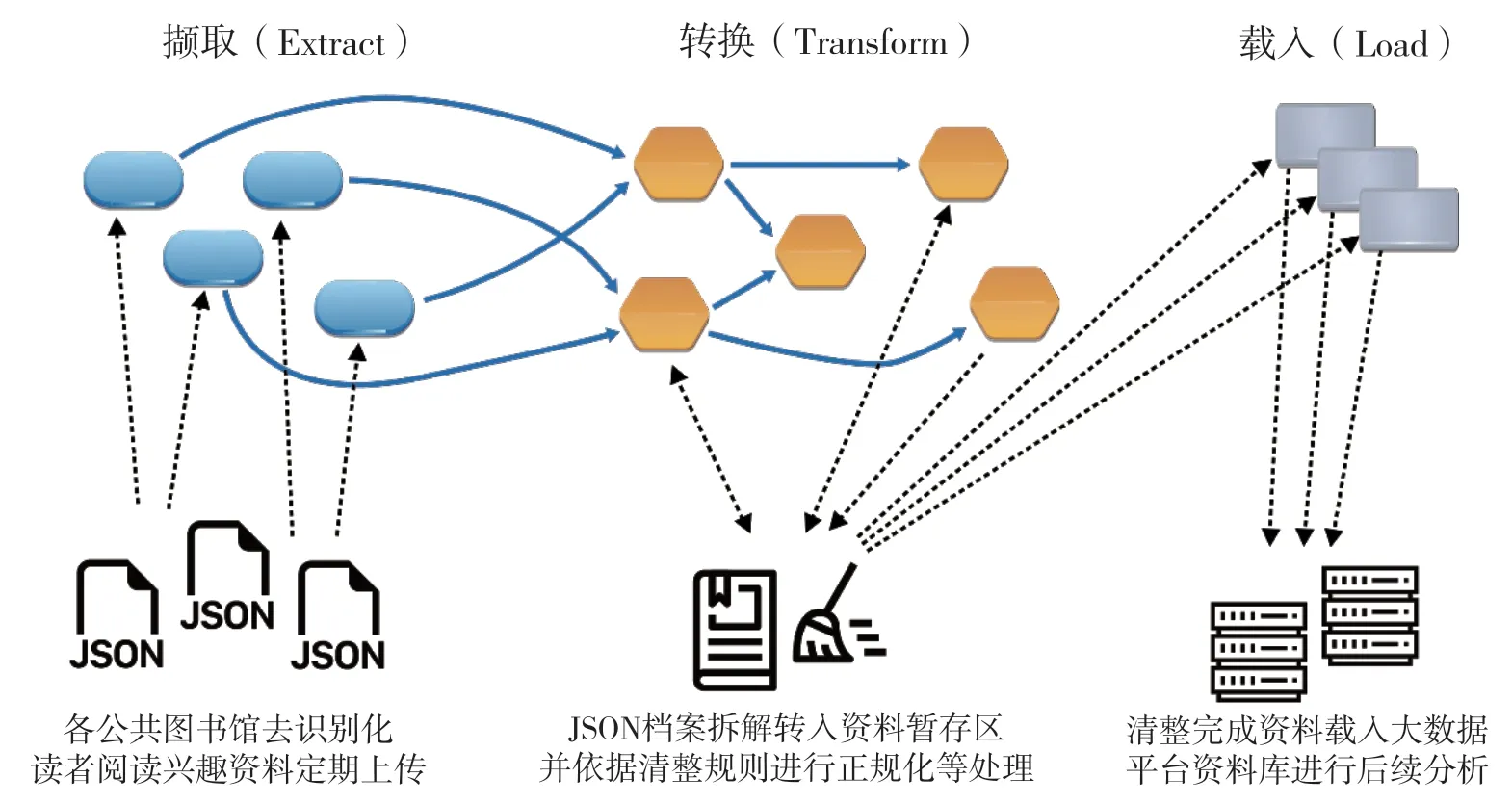
图1 大数据平台ETL 流程图
由于大数据平台搜集之读者阅读兴趣资料来自各县市公共图书馆,其资料质量皆各不相同,在资料整并上亦有其困难度。在资料清整流程规划上,率先处理省辖市立公共图书馆的读者阅读兴趣资料,作为系统标竿书目,并以标准号码(如ISBN、ISSN 等)为键(Key)值,无标准号码者由系统建立虚拟号码代替。资料处理过程,先比对该图书馆该笔书目是否曾完成清整,若曾完成清整即直接对应至系统标竿书目,不再重复处理;若未曾清整则依资料清整规则进行各栏位之正规化处理,并进行ISBN、ISSN 等标准号码之拆解,其中有标准号码者,与标竿书目进行比对,决定是否建立新书目或对应至已有书目,而无标准号码者以书名(100%)、作者(80%)、出版年(100%)的模糊逻辑条件,决定是否建立新书目或对应至已有书目。资料转入与清整流程如图2 所示。
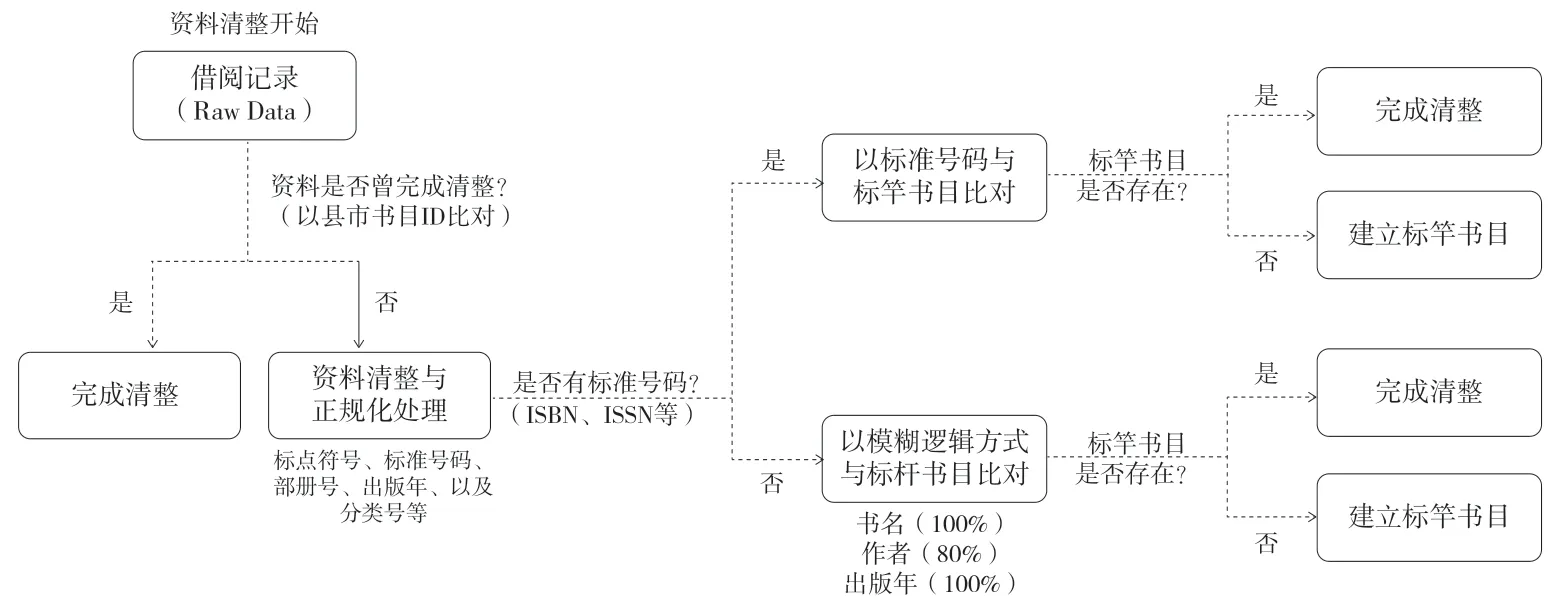
图2 大数据平台资料清整流程
在资料清整的部分,分别进行了标点符号、标准号码、部册号、出版年及分类号等栏位资料的清理,因资料由各公共图书馆之图书馆自动化系统书目纪录(机读格式)取得,故可能包含诸多不必要的标点符号,因此在正题名、副题名、作者、出版社等栏位,进行不必要标点符号的清除;在标准号码与部册号的部分,进行正规化,让资料具有一致性;出版年的部分,则确认资料的合理性;分类号进行类号层次的解析,以对应后续图书分类分析。详细信息如表1 所示。

表1 大数据平台资料清整规则简表
1.3 定义资料代码对应与资料转入
为利于资料之分析,大数据平台中定义有各项资料代码,包含图书馆与典藏地、馆藏类型、图书分类、适读年龄、排行类别定义等之对应,以汇整各县市不同来源之资料(详见表2)。在资料转入部分,于2022 年底,共计转入读者阅读兴趣资料6750 余笔,其中去识别借阅资料约6085 万笔、去识别预约资料约665 万笔(部分县市图书馆因自动化系统转换,资料尚未完全转入大数据平台)。

表2 大数据平台资料代码对应简表
2 数据资料的活化运用与加值分析
Goulub 和Hansson 归纳大数据于图资领域的数据分析,包含书目计量(bibliometrics)、资料分享(data sharing) 与资料庋用(data curation)三种主要应用类型[7]。Kamupunga和Chunting 透过问卷调查116 位图书馆馆员在工作情境中大数据之应用,调查解果显示公共图书馆适用的数据分析技术包含:协助快速取用资源的应用程序(26.58%)、视觉化(26.04%)、统计(17.95%)、资料探勘(15.28%)及机器学习(14.15%)[8]。Ball 认为在大数据科技的协助之下,可以创造更多有价值与创新的服务,研究透过文献回顾的方式,将各种图书馆应用大数据的服务与实务案例归纳为资料作为服务(data as sources)、资料分析(data analyses),以及资料视觉化(data visualization)三种类型。相关实务案例如:美国哈佛大学图书馆(Harvard University Library)将该馆1200 万笔的馆藏Metadata 发布于网络上公开取用;英国联合信息系统委员会(Joint Information System Committee)和英国高等教育统计局(British Higher Education Statistics Agency)合作建置Heidi Plus 大数据平台,便利各项信息的取得,同时协助回答电子期刊订阅与使用、学生经常使用的图书馆空间等图书馆相关问题;美国布鲁克林公共图书馆使用Tableau 作为资料视觉化工具,取代过时的报表系统,以运用各项资料的分析,进行更好的决策[9]。
Yang 使用大数据技术分析韩国大学图书馆15 年800 万笔的读者借阅纪录,并以杜威图书分类法(DDC)为架构,分析图书馆读者使用馆藏的情形[10]。Galyani-Moghaddam 和Taheri 为探索公共图书馆读者的阅读兴趣,研究以伊朗德黑兰12 至18 岁读者使用在线图书馆之流通纪录为研究资料,透过读者借阅资料的计量分析,了解读者在不同馆藏主题借阅的占比、不同性别的阅读喜好,以及最受读者欢迎的图书借阅排行[11]。
综观国际图书馆大数据技术之运用,多为了解图书馆读者之使用习惯与阅读兴趣。为进一步掌握台湾民众的阅读喜好,本中心运用2022年搜集之大数据资料,进行2022 年台湾阅读风貌之分析,分别就全民的阅读力、不同年龄与不同性别读者的阅读兴趣,以及各类型图书的借阅排行榜等项目进行资料之整理与分析。另为增进各县市政府对于图书馆的建设与重视,也运用相关数据进行县市整体阅读力之评量,以了解各县市的阅读概况与阅读力表现。在大数据平台上,则透过资料视觉化的工具,呈现各种分析结果,让数据资料可以更为活化的进行呈现与展示。
2.1 数据统计分析,展现全民阅读力
为呈现全民阅读力,本中心运用大数据平台之数据资料,并加入“公共图书馆统计系统”搜集各馆之各项营运数据,以呈现民众于2022年在图书馆进馆总人次、借阅图书总人次、借阅图书总册数、累计办证数、借阅电子书册数、网站资源使用次数等各项阅读力指标上之表现(详见表3)。而透过阅读兴趣资料之分析,则可进一步掌握各年龄层读者的借阅比例(详见表4),亦可了解不同性别读者于各类型图书的阅读喜好(详见表5),强化图书馆在不同年龄层、不同性别的阅读活动规划与推动。
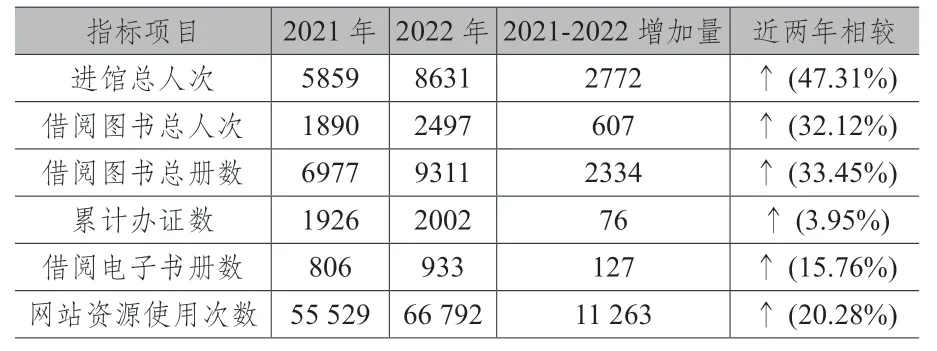
表3 近两年全民阅读力消长概况
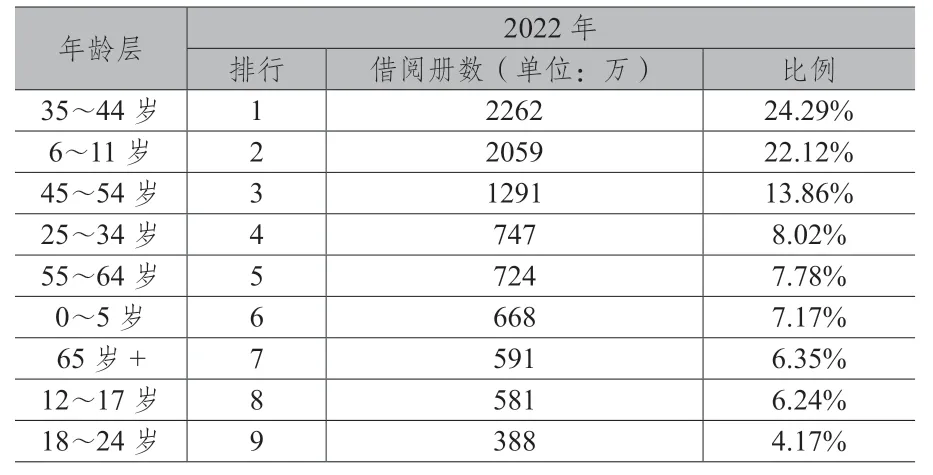
表4 不同年龄层读者借阅册数排行
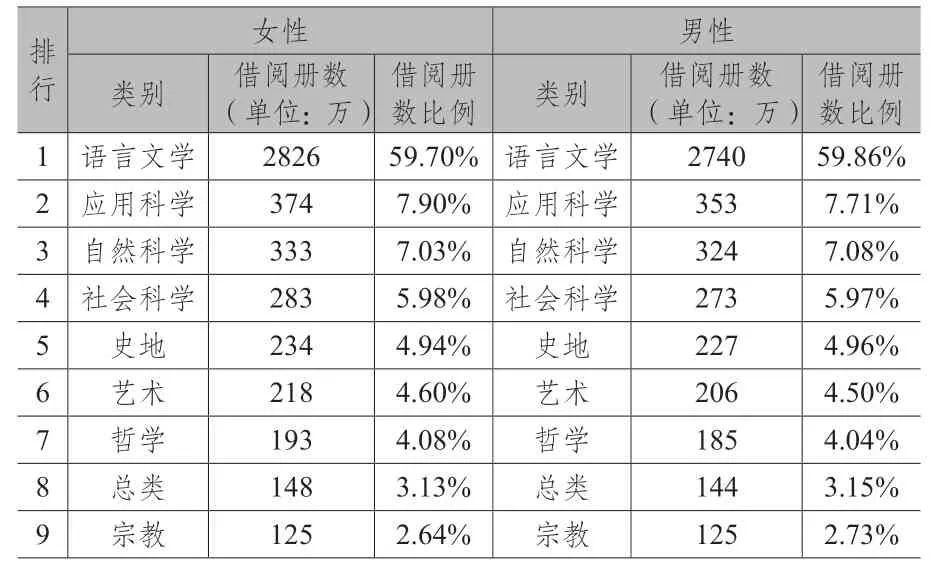
表5 不同性别读者借阅图书类别排行
2.2 读者阅读兴趣资料分析,了解民众阅读兴趣
大数据平台搜集读者阅读兴趣资料,经过各项资料的清整程序后,即可进行民众阅读兴趣之分析。本中心依据图书馆给予中文图书之图书分类号,筛选、统计图书的借阅次数,编制总类、哲学类、宗教类、自然科学类、应用科学类、社会科学类、史地类、语言文学类及艺术类等图书借阅排行榜,并将武侠小说、漫画书、0~5 岁婴幼儿图书、6~11 岁学童图书及电子书另予立类分析。藉由各类型图书借阅排行之分析与呈现,可供图书馆及出版社掌握读者的阅读偏好,作为图书馆阅读推广、馆藏采购及出版社策订出版方向参考。
2.3 数据活化运用,提升各县市图书馆资源建设之重视
为提升各地对于图书馆建设之重视,以提升民众的文化素养,参考图书馆杂志(Library Journal)星级图书馆(Star Libraries,https://www.libraryjournal.com/story/stars-faq)之评比方式,计算各项阅读力指标每位居民平均拥有或使用数(per capita),以了解各县市于图书馆事业发展与阅读素养扎根之推动成果。在县市阅读力表现的评比上,分别以各县市公共图书馆之馆藏建设、馆藏利用、到馆人次、持证比例、投入经费、馆舍面积、网站使用与补助争取等为指标,计算各县市“人均拥书册数”“人均借阅册数”“人均到馆次数”“民众持证比例”“人均资源投入经费”“人均馆舍使用面积”“人均网站使用次数”及“县市补助争取标准分数”等数值,并以馆藏建设占25%、馆藏利用占25%、到馆人次占15%、持证比例占10%、投入经费占10%、馆舍面积占5%、网站使用占5%及补助争取占5%,加总算出每个县市的总分,作为检视图书馆在培育民众阅读力的重要指标。
2.4 视觉化呈现多面向资料,协助阅读活动与阅读推动策略规划
为利于各项数据资料的视觉化呈现,在大数据平台中,搭配Tableau 视觉化工具,将各项数据资料以可交互式的方式,呈现于大数据服务平台。开放民众浏览的为借阅类别、借阅年龄与借阅性别的互动报表,可藉由点选地图上的县市,进行互动之操作。而大数据平台之后台,则开放各县市公共图书馆进行账号之申请,登入后可进一步浏览该县市之互动数据,协助县市了解各区域或各乡镇市之借阅情况、各类别之热门借阅排行榜等信息。同时,另设计有各种交叉分析的互动报表,可以性别、年龄、图书类别等条件进行交叉分析,各种分析结果可协助图书馆更为了解并掌握县市读者的阅读现状、分布及喜好。
2.5 办理台湾阅读风貌记者会与出版年度报告书
为扩大数据资料分析的效益与展现各县市阅读推动的成果,本中心于2023 年3 月29 日办理“ 2022 年台湾阅读风貌及全民阅读力年度报告”发布记者会。记者会中由曾淑贤主任解析2022 年台湾民众阅读力及阅读兴趣,并从公共图书馆的营运服务统计分析全民阅读力。而为鼓励各县市于阅读推动上的努力,也藉由颁发“整体阅读力表现绩优城市”“阅读力分项表现绩优城市”等132 个奖项,来促进各县市对于图书馆事业之重视与引起各县市相互激励之效果。在展示民众的阅读兴趣与阅读成果方面,同时于本中心设置常态展览,同时也出版年度报告书,寄送各县市公共图书馆,提供典藏阅览。
3 结语
因应图书馆运用数据分析之趋势,本中心与台湾省各县市公共图书馆携手合作,以公共图书馆去识别化读者阅读兴趣资料为核心,并辅以各项图书馆营运统计数据,建置台湾省图书馆界第一个大数据服务平台。藉由阅读兴趣资料之分析,并运用资料视觉化、互动等不同的呈现方式,帮助各县市图书馆乃至各界,更了解民众的阅读需求与兴趣,并进一步规划与发展各项更能贴近读者需求及创新的服务,同时也将台湾整体图书馆事业发展与台湾阅读的风貌,透过系统平台的设计,将各项阅读重要的成果与数据展示给各界参考。
未来,在现有的基础下,本中心将持续导入各县市公共图书馆读者阅读兴趣资料,并进行资料的清整与分析作业的优化。同时,也将导入资料探勘与运用人工智能等技术,开发读者阅读资料推荐服务,为读者推荐阅读资源,并透过与专家学者合作之方式,进一步运用搜集之资料进行相关研究,为图书馆事业发展与全民阅读风气之提升产生助益。
猜你喜欢
统计科学与实践(2022年1期)2022-07-23
都市人(2022年3期)2022-04-27
环球时报(2020-01-13)2020-01-13
智富时代(2018年9期)2018-10-19
智富时代(2018年9期)2018-10-19
戏剧之家(2016年15期)2016-08-15
中共党史研究(2013年7期)2013-04-27
中国民间疗法(2012年1期)2012-07-27
全国新书目(2009年1期)2009-04-13
全国新书目(2006年9期)2006-05-26
