
中国式现代化新征程中的少数民族学生语言能力与发展
——基于学段差异的国家通用语言水平计量分析
2024-01-30 03:07武小军
西华大学学报(哲学社会科学版) 2024年1期
武小军 王 璐
西华大学文学与新闻传播学院 四川成都 610039
党的二十大为“中国式现代化”赋予了科学内涵,习近平总书记强调“中国式现代化既有各国现代化的共同特征,更有基于自己国情的鲜明特色”[1]。国家通用语言文字在中国式现代化进程中具有重要的意义,推广普及国家通用语言文字是铸牢中华民族共同体意识的重要途径,可以为加快建设高质量教育体系、推进教育强国建设提供基础性支撑[2],有利于各民族共同走向现代化、实现共同富裕、实现物质文明和精神文明的协调统一及构建和谐的语言生态[3]。对此,学界认为,只有国家通用语言文字才能提升全民的文化素养和科技能力,进而推进新时代的中国式现代化[4],要发挥基础教育阶段语文课程在推广普及国家通用语言文字等方面的优势,在积极的言语实践活动中提升国民语言文化素养,进而增加全社会参与中国式现代化的意识和能力[2]。民族地区各级学校是国家通用语言文字推广普及的一个重要阵地,少数民族学生的国家通用语言水平事关铸牢中华民族共同体意识、促进民族地区经济文化现代化发展的大局,学界对此主要从两个方面予以关注,一是少数民族学生国家通用语言文字水平状况调查分析,如刘海红等[5]、龙红芝等[6]对藏族学龄前儿童群体的国家通用语言能力的考察研究;马翠英[7]、何雅臻[8]对东乡族、维吾尔族等民族中小学生的国家通用语言使用现状的调查研究等;二是民族地区提升国家通用语言文字教育效率的策略研究,如成园园等[9]基于CIPP 评估模型对国家通用语言文字在新疆和田县推广情况的分析,并针对性提出了民族地区优化国家通用语言文字推广的策略。学界虽然产出了一些研究成果,但对于民族地区最重要的受教育群体—义务教育阶段学生的国家通用语言水平现状研究仍显不足。基于此,本文以民族地区处于义务教育阶段的一至九年级中小学生为研究对象,以学生所在年级学段为考察基点,通过量化分析其国家通用语言水平的学段差异,深入研讨少数民族学生国家通用语言学习状况,找出存在的问题,以利于民族地区学校提高语文教学质量,助力实现民族地区国家通用语言水平的高质量发展和乡村振兴。
一、调查设计与抽样样本
为准确描述和分析少数民族学生国家通用语言水平的基本状况,笔者专项设计了调查语料,拟定了调查方式,确定了语言数据计量方法,选定民族区域,实施抽样调查。调查时间为2022 年6 月至9 月。
(一)调查设计与计量方法
1. 抽样区域选择
选取四川省甘孜藏族自治州巴塘县、九龙县以及云南省丽江市宁蒗彝族自治县作为调查区域。选取理由是:以上三地均为民族地区,共同隶属于西南藏彝民族走廊,是典型的少数民族聚居地。其中,巴塘县主要为藏族聚居区,九龙县属藏、彝族杂居区,宁蒗县属彝族聚居区,三地的民族类型表现出鲜明的藏族-藏彝族-彝族分布特征;这条民族过渡带从语言扶贫到乡村振兴,其社会经济文化教育发展互有差异,通过选点比较,可看出不同区域的语言共性和差异性。
2. 语料设计
选择人教版一年级下册《四个太阳》一文作为基础考查语段①。选取原因主要有两点,一是该文篇幅短小、字词易懂,能够满足各学段学生学习实际;二是该文包含的国家通用语言知识点全面,既涉及基础的声母、韵母、声调、变调、语调,还涉及轻声、儿化等。其中,声母考察词语为“落(叶)”“(温)暖”“春(天)”“彩(色)”等(考察鼻音、边音、平翘舌音发音);韵母考察词语为“(邀)请”“因(为)”等(考察前、后鼻韵母发音);声调考察词语为“(春)天”“(清)凉”“彩(色)”“(落)叶”等(考察阴平、阳平、上声、去声的声调);变调主要涉及“一”“不”变调、上声变调,“一”变调考察词语为“一片”“一年”“单一”等,上声变调考察词语为“水(果)”,“不”变调考察词语为“不”和“不够”;语调部分主要考察学生的停顿(语法停顿、逻辑停顿)及升、降调等,语句“高山、田野、街道、校园,到处一片清凉”考察语法停顿,语句“春天的太阳/该画什么颜色呢?”考察逻辑停顿和升调,语句“哦,画个彩色的。”考察降调;轻声和儿化考查词语为“什么” “小伙伴儿”等。
3. 数据获取与计量
在三县的县城和乡村学校抽样选点,在选定学校的一至九年级,按每个年级随机抽取1 个班级,在选定的班级中随机抽取1 组学生,让学生用普通话读出考查语段,由课题组成员录音记录。通过整理录音,对考察字、语句等逐项标记发音,运用R 4.3.0 统计软件对少数民族学生在声母、韵母、声调、变调、轻声、儿化以及语调等的偏误情况进行数据处理与分析。偏误的确定以国家通用语言的标准语音作为参考,与标准音不符合的发音计为偏误。
(二)抽样样本
调查共获得924 份录音材料,对所回收的样本进行筛选,剔除了发音不清的样本,九年级及回族、苗族、羌族样本因数量太少,也未纳入统计,筛选后总样本量为842 份,样本有效率91.13%。有效样本中,男性416 人,占比49.4%,女性426 人,占比50.6%;藏族学生样本487 人,占比57.8%,彝族学生样本355 人,占比42.2%;样本的县域分布为巴塘县299 人、九龙县345 人、宁蒗县198 人,分别占比35.5%、41%、23.5%。依据教育部《民族中小学汉语课程标准(义务教育)》(以下简称《课标》)[10]学段划分标准,将一、二年级划为第一学段,三、四年级划为第二学段,五、六年级划为第三学段,七、八年级划为第四学段。样本各学段的人数与占比分别为第一学段(188 人,22.3%)、第二学段(190 人,22.6%)、第三学段(223 人,26.5%)、第四学段(241 人,28.6%),各学段样本占比较为均衡,符合研究需要。
二、研究结果与分析
依据偏误统计数据,以学段为切入点,从差异性检验及组间差异两方面对数据进行量化分析,同时结合学生所属民族、所在城乡学校和不同居住地(县域)等社会变量对学生发音偏误情况进行分析,以此揭示不同学段学生的国家通用语言水平状况。
(一)总偏误次数的方差分析及学段组间差异
对各学段学生在语音朗读过程中出现的偏误进行计数,得到了学生总偏误次数的数据。对该数据进行方差齐性检验得出,莱文方差齐性检验的显著性为0.456,大于显著水平0.05,说明样本数据之间的方差是齐次的,因此可以使用单因素方差分析的方法。以学生的学段为自变量,以学生的偏误总数为因变量进行单因素方差分析,具体结果见表1。

表1 总偏误次数方差分析结果
从表1 中可以看出,组间平方和是29.475,组内平方和是1706.705,其中组间平方和的F 值为4.847,显著性是0.002,小于显著水平0.05。数据证实了学段对学生的偏误次数具有显著性影响,即在95% 置信区间内不同学段的学生在偏误次数上存在显著差异。偏误次数可以反映出国家通用语言水平,因此可以认为民族地区中小学生国家通用语言水平存在着学段上的差异。
从表1 方差分析结果中的F 值和显著性来看,组间至少有一组与其他组有显著性差异。为进一步探究组间差异,使用LSD 多重比较法进行成对比较,具体结果见表2。
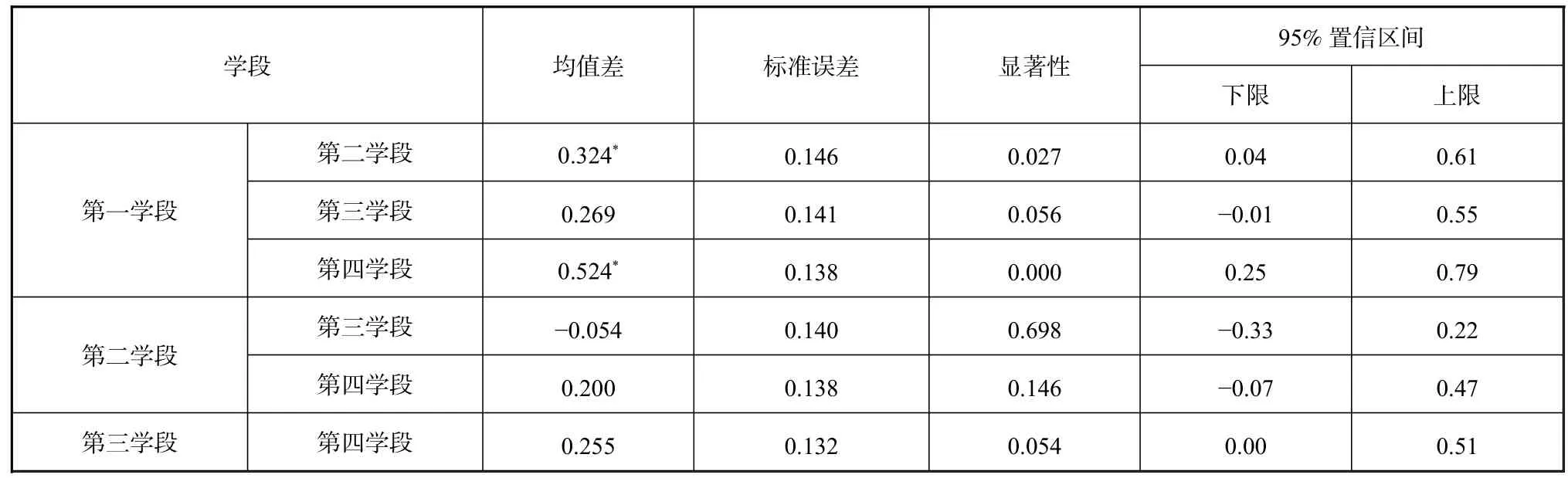
表2 总偏误次数的学段多重比较结果
表2 显示,第一学段与第二学段的均值差为0.324,对应的显著性为0.027(p<0.05),因此得出结论: 第一学段与第二学段均值之间有显著差异。此外,第一学段与第四学段的均值差为0.524,对应的显著性为0.000(p<0.05),表明第一学段与第四学段均值之间也存在显著性差异。
(二)各语音项偏误次数的方差分析及学段组间差异
对各学段学生语音朗读过程中在语音项上出现的偏误进行计数,得到了学生各语音项偏误次数的数据。为了解各语音项的偏误次数是否会因为学生学段的不同而发生变化,本研究以学生的学段为自变量进行方差分析检验。由于因变量(结果变量)不止一个,所以使用多元方差分析(MANOVA)对它们同时进行分析。对学生的多个因变量进行多元方差分析时,采用cbind 函数将声母、韵母、声调、变调偏误次数等因变量合成一个矩阵,学段为四水平的自变量。
从表3 的分析结果可看出:F 值为12.588,显著性为2.2e-16(p<0.05),故拒绝原假设,即学生学段不同,各因变量存在显著差异。以学段为自变量,以各语音项的偏误次数为因变量进行单因素方差分析,结果表明,除声调方面不存在显著学段差异外,其余语音项都存在显著的学段差异。

表3 各语音项偏误次数的多元方差分析
经检验,数据满足方差齐性。为进一步比较分析不同学段之间各语音项偏误次数均值的差异情况,特采用方差齐性的多重比较法(LSD),表4 是以学生的学段为自变量对学生声母、韵母、变调、语调、轻声、儿化偏误次数进行的成对比较,此处只呈现语音项中有显著学段差异的结果。
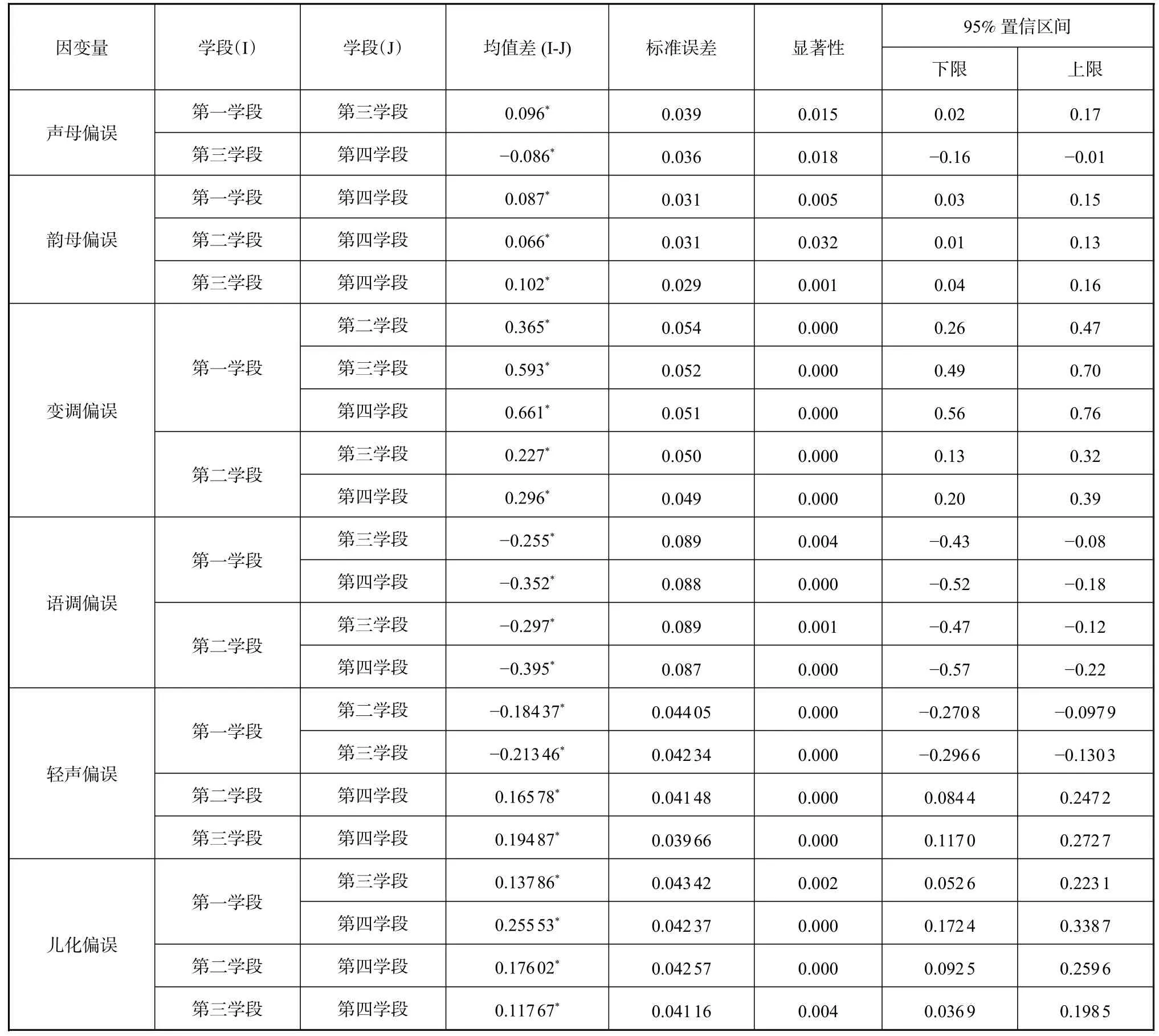
表4 各语音项偏误次数的学段多重比较结果
表4 结果显示:第一学段和第二学段的学生在变调、轻声方面存在显著差异,第一学段和第三学段的学生在声母、变调、语调、轻声和儿化方面存在显著差异。第一学段和第四学段的学生在韵母、变调、语调、儿化方面存在显著差异,第二学段和第三学段的学生在变调、语调方面呈现显著差异,第二学段和第四学段的学生在韵母、变调、语调、轻声、儿化方面存在显著差异,第三学段和第四学段的学生在声母、韵母、轻声、儿化方面呈现显著差异。
对上述存在显著差异的学段进行计数,可以发现:第一学段和第二学段、第二学段和第三学段出现显著差异次数最少,仅出现两次。第三学段和第四学段、第一学段和第四学段出现四次显著差异,第一学段和第三学段、第二学段和第四学段出现五次显著差异。综合来看,学段相邻的学生在各语音项偏误次数出现显著差异次数较少,也就是说发音出现的偏误情况相差不大;相隔两个或三个学段在各语音项偏误次数出现显著差异的次数较多,发音出现的偏误情况相差较大。
(三)不同学段的偏误趋势
为了更好地观察各学段少数民族学生在不同语音项上的发音偏误情况,本研究分学段计算了各语音项偏误次数的均值,根据计算数据绘制了不同学段的发音偏误趋势图(见图1)。
据图1,不同学段偏误趋势如下。第一,韵母部分(主要是前后鼻韵的区分)的偏误均值整体较高,在第三学段出现了小幅上升,但是整体上呈现出随着学段的上升而下降的趋势。第二,儿化的偏误均值也处于较高水平,偏误次数均值趋势随着学段的上升而小幅下降。第三,变调的偏误次数均值随着学段的上升发生了大幅下降,第一学段的偏误均值是0.71,第四学段的偏误均值为0.05。第四,基础声调偏误均值以及声母偏误均值都处于较低水平,偏误均值趋势图都呈现随着学段的上升而下降的趋势。随着学段的提升,学生的语音练习时长会相应增加。学习时间的多少对学习者的交际熟练程度有影响,学习时间越长,就越接近母语水平[11],学习时长增加后学生的语音偏误会减少,所以以上几种偏误趋势都属于常规的偏误趋势。
本研究在调查统计中出现了与常规趋势不同的特殊情况。即随着学段的上升,学生的语调偏误均值和轻声偏误均值均呈现出上升的趋势。第一,语调偏误均值在第三学段和第四学段分别为0.97 和1.07,相较于第一学段(0.72)和第二学段(0.68)出现大幅度的上升。这可能与高学段学生的语速较快有关,由于考察文本对于高学段学生而言较为简单,所以在朗读文本的过程中高学段学生朗读流畅且语速较快。语速较快就可能导致部分学生在该停顿的地方未出现停顿,所以偏误均值在第三学段和第四学段出现了上升的情况。第二,轻声偏误在第二学段和第三学段的偏误均值相较于第一学段和第四学段出现了约0.2 的上升,这可能与语流音变及句调有关。因为轻声设置的考查词语为“什么”,整个句子是升调,所以考察词语在发音时可能受句调的影响产生偏误。对升调偏误次数及轻声偏误次数进行皮尔森相关性检验,声调偏误与轻声偏误的皮尔森相关性为0.173,双侧显著性为0.00。这一数据表明,升调偏误次数和轻声偏误次数之间存在正相关关系,这意味着学生在轻声上的偏误是受句子升调的影响,从而产生了与常规趋势不同的变化趋势。
《课标》对每个学段学生的语言知识和语言技能提出了要求。其中,对第一至第三学段学生的要求是“能读准声母、韵母、声调,正确认读音节”[10]“要掌握‘一’‘不’变调,初步了解三声变调”[10]。从图1 来看,第一至第三学段的学生声母、声调的偏误均值从整体数值来看都处于较低状态,韵母只有前后鼻音韵尾的区分存在问题,其余韵母在给定文本朗读的过程中未见偏误。因此综合来看,第一学段至第三学段的少数民族学生已基本掌握了“一”“不”变调和三声变调,能基本读准声母、韵母和声调。对于第四学段,《课标》要求学生“掌握三声变调,了解常见变调规则。能用正常的语速和标准的语音、语调朗读课文”[10]。从图1 来看,第四学段的变调偏误均值为0.02,从均值可以看出,学生在该学段已经掌握了三声变调。同时,在朗读文本的过程中,第四学段学生的语音、语调发音都比较标准。可以说,少数民族学生的国家通用语言水平已经达到了《课标》学段课程目标的要求。
(四)不同学段学生语音与社会变量的相关性
箱线图是统计学中常用于显示数据分布情况的方法,对数据没有任何限制,常用于异常值的检测、数据的偏态和尾重的判断以及多数据分布间的比较等[12]。本研究采用R 做分组箱线图来分别观察城乡因素、居住地因素、民族因素对不同学段的学生语音偏误分布情况的影响。
1. 城乡学生学段与语音偏误
从图2 可以看出,第二、三、四学段偏误次数分布整体情况较为稳定,表现为最大值低于中性条件。从p 值来看,处于第二学段、第三学段、第四学段的学生在偏误分布上不存在显著的城乡差异,处于第一学段的学生p 值为0.012,这说明民族地区处于第一学段的学生在发音偏误方面存在着显著城乡差异。从中位数(箱体中的粗线)来看,第一学段中乡村学生的偏误中位数显著高于县城,其余学段的城乡偏误分布都比较平均。第一学段中,县城学生偏误分布集中于上四分位数,这说明第一学段的县城学生偏误次数集中在高段水平,且学段内部差异较大。从均值来看,第一学段的乡村学生偏误均值为4.175,县城学生偏误均值为3.571,乡村学生的偏误均值显著高于县城学生,其余学段的乡村学生与县城学生偏误均值相差不大。

图2 各学段学生城乡差异箱线图
总体来说,第一学段学生存在显著的城乡差异。在第一学段县城学生的偏误中位数较低,但内部差异较大;乡村学生的偏误中位数高,但内部差异较小;其余学段没有显著差异且偏误次数分布整体情况较为稳定。
2. 不同居住地(县域)学生学段与语音偏误
本文选取的三个调查点分别是巴塘县、九龙县、宁蒗彝族自治县。其中,巴塘县和九龙县都隶属四川省甘孜藏族自治州,巴塘县位于甘孜藏族自治州西部,九龙县位于甘孜州东南部。宁蒗彝族自治县隶属云南省丽江市,位于云南省西北区域,北邻四川省,地处横断山脉小凉山腹地。
从图3 中可以明显看出,不同居住地(县域)中各学段学生的偏误次数分布情况比较复杂。从p 值来看,一至四学段的学生在三县的p 值分别为0.019、1e-05、1.2e-07、8.3e-06,即三县在各学段偏误分布上都存在显著差异。从箱体位置和中位数上看,第一学段中九龙县学生的偏误分布高于其余两县;第二学段中巴塘县和宁蒗县的学生偏误分布整体高于九龙县;第三学段中巴塘县学生的偏误分布高于九龙县和宁蒗县;第四学段中巴塘县学生的偏误分布高于九龙县和宁蒗县,且内部差异较大。第一学段的宁蒗县、九龙县、巴塘县的均值分别为2.786、4.140、3.701;第二学段的均值分别为3.290、2.860、4.027;第三学段的三县均值分别为2.750、3.095、4.063;第四学段的均值分别为2.576、3.270、3.911。从此次调研结果来看,在所选定的区域中,宁蒗县学生的国家通用语言习得情况比巴塘、九龙两县的学生要好。
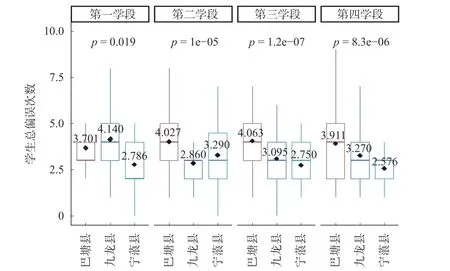
图3 各学段学生居住地(县域)差异箱线图②
3. 不同少数民族学生学段与语音偏误
本次调查中样本民族主要为彝族和藏族,以民族为自变量对学生偏误次数分布进行观察,判断民族因素对各学段学生发音偏误分布的影响情况,具体结果见图4。
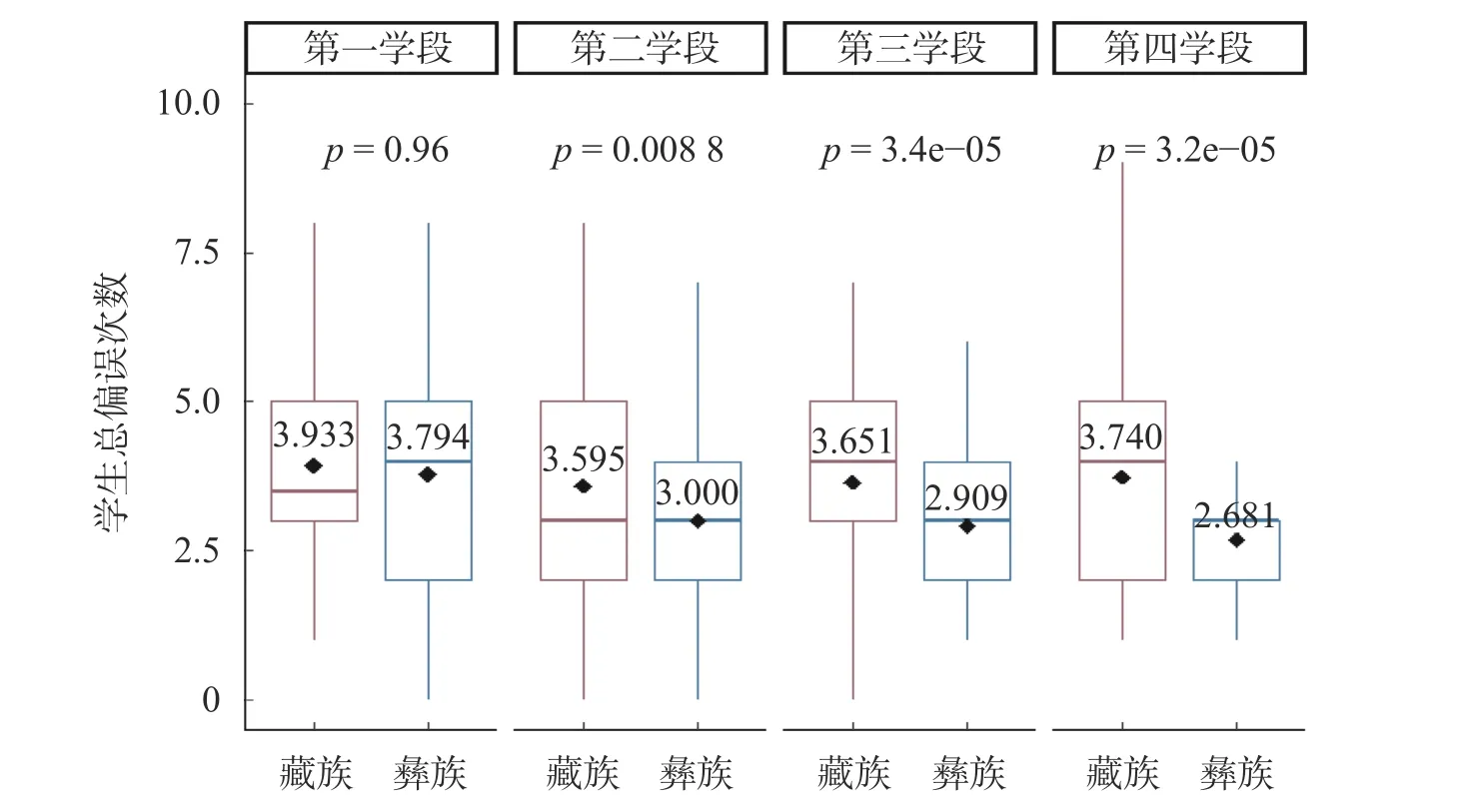
图4 各学段学生民族差异箱线图
从图4 中的p 值来看,藏彝族学生在第一学段的p 值为0.96(p<0.05),不存在显著差异,第二、三、四学段的p 值分别为0.0088、3.4e-05、3.2e-05,说明显著性差异主要发生在第二、三、四学段。从箱体位置及中位数上看,在有显著差异的第二、三、四学段中,藏族学生的偏误次数分布高于彝族学生,也即是说,相比于藏族学生,彝族学生较少出现偏误。第二学段藏族学生的偏误均值为3.595,彝族学生偏误均值为3.000,第三学段的藏、彝族学生的偏误均值分别为3.651、2.909,第四学段藏、彝族学生的偏误均值为3.740、2.681,进一步比较其均值,发现彝族学生的偏误均值低于藏族学生。从此次调研结果来看,在所选定的区域中,彝族学生的国家通用语言水平高于藏族学生。
结语
本文依据偏误调查统计数据,以学段为研究切入点,通过差异性检验,认为民族地区不同学段学生在国家通用语水平上存在显著性差异。其中,第一学段和第三学段、第二学段和第四学段出现的显著性差异最为明显;通过对不同社会变量进行各学段的比较,发现城乡因素、所在县域(居住地)、所属民族等因素对各学段学生的偏误分布具有影响,其中,三县学生在各个学段上都存在显著差异,第二、三、四学段存在显著的民族差异,第一学段虽然没有呈现出民族差异,但却存在明显的城乡差异。上述研究结论可以为民族地区各级学校统筹不同学段的国家通用语言教学与学习提供参考依据,即教学中除注重民族学生国家通用语言水平的整体提高外,还应特别注重有效提高第一学段学生尤其是乡村学校第一学段学生的国家通用语言水平,为后续各学段的延续学习奠定良好的国家通用语言学习基础。
国家通用语言文字是中国式现代化新征程下国民教育的重要基础工具,少数民族学生的国家通用语言水平关乎民族人口科学文化素质提升、民族地区走向现代化的大局。我们应充分正视少数民族地区不同学段学生的国家通用语言学习特征及差异反馈,针对性弥补语言教学中的薄弱环节,切实提升少数民族学生的国家通用语言能力水平,进而推动民族地区基础教育的高质量发展。
注释:
① 考查时对选定的《四个太阳》语段略作了改动,增添了“单一”“一年”等词。
② 统计数据存在上四分位数(第75 百分位数)或者下四分位数(第25 百分位数)与中位数(第50 百分位数)数值相同的情况,所以图中的中位数(箱体中的粗线)会出现与上四分位数或下四分位数重叠的现象,例如第一学段的巴塘县、宁蒗县的箱体中粗线便无法显现,后图同。
猜你喜欢
福建基础教育研究(2020年3期)2020-05-28
海外华文教育(2017年8期)2017-11-07
海外华文教育(2016年4期)2017-01-20
新课程研究(2016年4期)2016-12-01
文学教育(2016年33期)2016-08-22
高中生学习·高三版(2016年1期)2016-05-30
中学生数理化(高中版.高二数学)(2016年4期)2016-03-01
中学历史教学(2016年12期)2016-03-01
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
数学年刊A辑(中文版)(2014年4期)2014-10-30
