
基于python语言的水体营养状态评价系统的设计
2024-01-30 07:00:20宋盼盼
水利技术监督 2024年1期
宋盼盼,周 猛,肖 莹
(湖北省孝感市水文水资源勘测局,湖北 孝感 432100)
水体营养状态评价是地表水环境质量评价的重要组成部分,是对水体富营养化发展过程中某一阶段的营养状况进行定量描述,通过对代表性指标的监测与调查,判定水体的营养状态,了解其富营养化进程及预测其发展趋势,为水体水质管理及富营养化防治提供科学依据[1]。其本质是按照一定的标准和方法对水环境监测数据进行加工处理,最终形成水体优劣程度的评判结论。
长期以来,水体营养状态评价主要借助于Microsoft Excel、WPS表格或SPSS等常规办公软件的数据处理功能。在具体执行大批量运算时,对软件运行环境、原始数据质量和格式要求较高,尤其是处理大批量数据时效率较低且容易出错,在实际使用中存在一定的局限性。
python是一种面向对象的解释性的计算机程序设计语言,具有简洁、易读、易维护、免费开源、可移植性和可扩展性等特性。经历几十年的发展,Python工具箱现已涵盖数据爬虫、数据分析、深度学习、人工智能和Web开发等技术的常用库和外部工具,可广泛应用于各种交叉学科。近年来,python在水文分析计算、水资源水环境监测与评价领域中应用的案例不断涌现[2-7],为水资源、水环境监测与评价工作开辟了一条更加高效、便捷的途径。笔者采用python语言设计一种可以应用于水体营养状态评价的数据处理系统具有一定的可行性和实用价值。
1 评价方案的选取
常用的水体营养状态评价方法主要有营养状态指数法(卡尔森营养状态指数(TSI)[8]、修正的营养状态指数(TSIM)[9]、综合营养状态指数(TLI)[10])、营养度指数法[11]、模糊聚类数学模型法[12]和评分法[13]等。笔者结合当前水利系统水环境监测与评价工作实际情况,水体营养状态评价方案采用评分法。其主要依据为水利行业标准《地表水资源质量评价技术规程》(SL 395—2007),其中湖泊营养状态评价标准及分级方法源自中国科学院南京地理与湖泊研究所舒金华1990年提出的评分法[14]。
评分法是根据水体营养状态相关评价因子和对应的评价标准,在0~100分的范围内分别赋予各评价参数相应的分值,其分值与水体富营养化程度呈正相关。评价指标为叶绿素a(chl-a)、总磷(TP)、总氮(TN)、透明度(SD)和高锰酸盐指数(CODMn),其中叶绿素a(chl-a)为必评项目。依据水体营养状态评价标准,采用线性插值法将水质项目浓度值转换为赋分值,按公式(1)计算营养状态指数EI,根据营养状态指数确定营养状态分级。水体营养状态评价标准及分级方法见表1[15]。
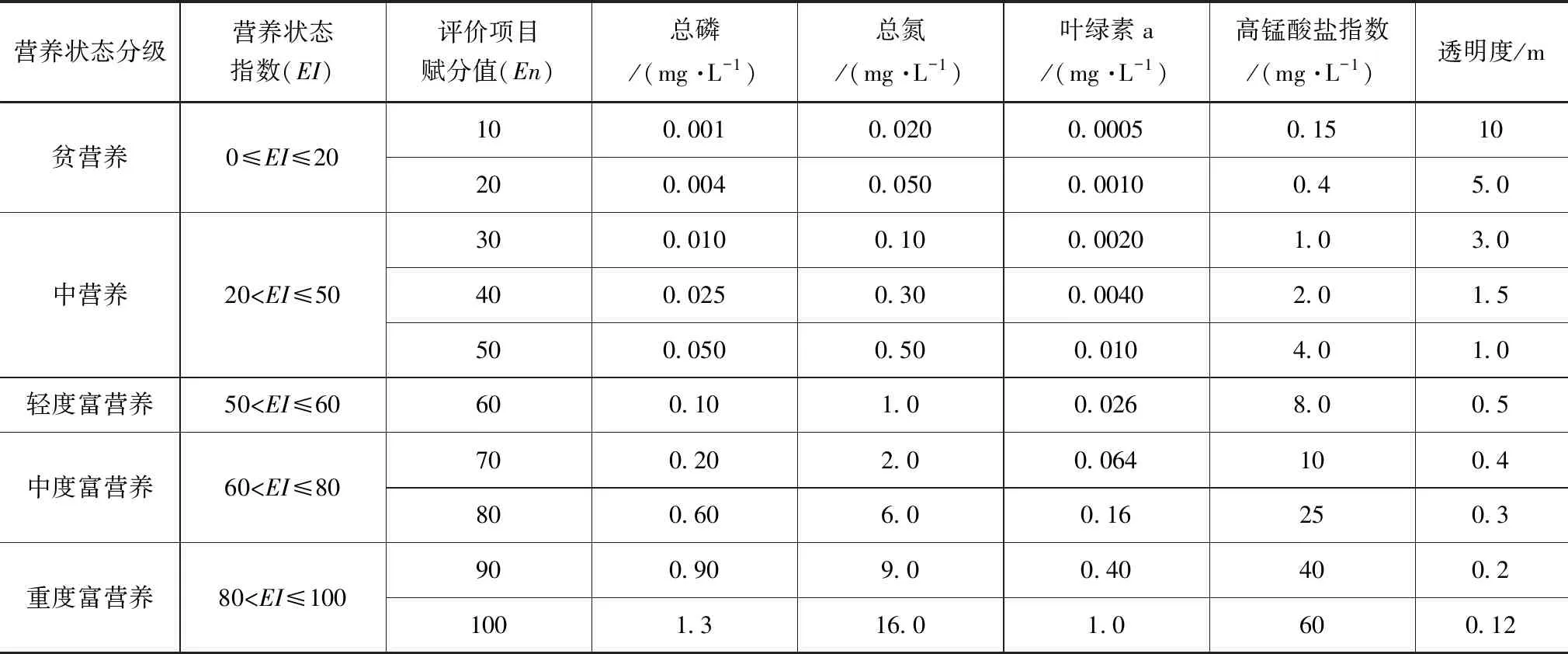
表1 水体营养状态评价标准及分级方法
(1)
式中,EI—营养状态指数;En—评价项目赋分值;N—评价项目个数。
2 工作流程的设计
利用python出色的数据处理能力可以完成对监测数据的预处理,从原始监测数据中提取出需要参评的数据,然后依据水体营养状态评价标准建立项目浓度值与赋分值的函数关系曲线方程,分别按照对应的曲线方程进行赋值运算,再根据运算结果对样品代表的水体进行分级评价,最后对必评项目“叶绿素a”是否参评进行自动复核,输出营养状态分级评价成果。本评价系统使用的所有数据文件均为.xlsx或.xls格式。水体营养状态评价系统工作流程如图1所示。
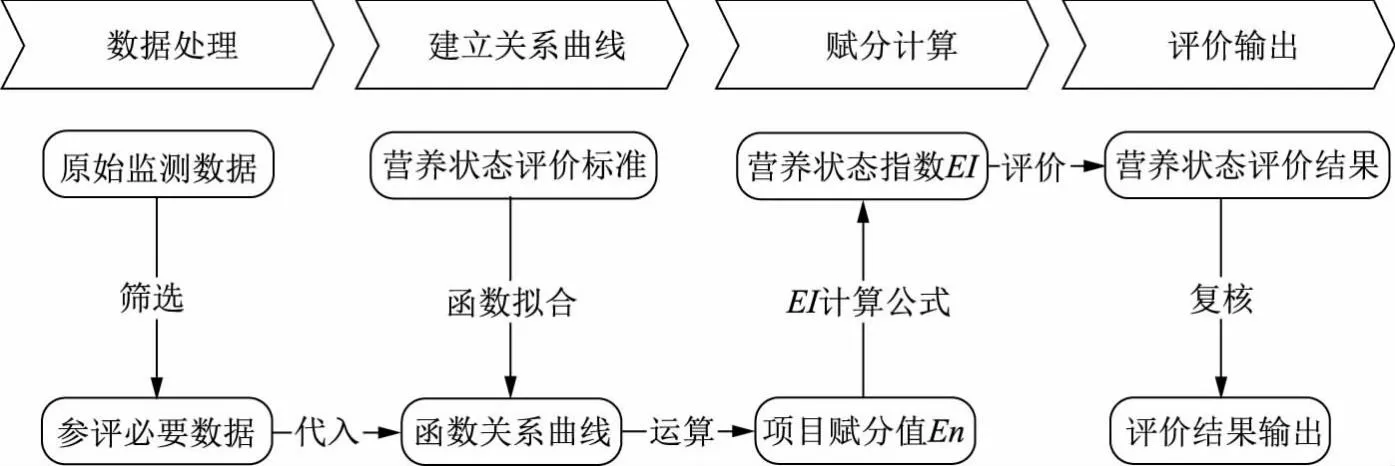
图1 水体营养状态评价系统工作流程
3 主要功能的实现
3.1 数据处理
一般情况下,原始的水环境监测数据包含的信息量较大,为方便后续数据处理,需筛选出水体营养状态相关评价因子。使用pandas模块提取文件“原始检测数据.xlsx”中的样品信息(如“样品编号”“样品名称”“采样日期”等)和评价参数(“高锰酸盐指数”“总磷”“总氮”“叶绿素a”“透明度”)等参评必要数据,生成文件“水体营养状态监测成果.xlsx”。数据处理的主要代码如下:
import pandas as pd
df=pd.read_excel('原始检测数据.xlsx')
df=df.reindex(columns=['样品编号','样品名称',' 采样日期','高锰酸盐指数','总磷','总氮','叶绿素a','透明度'])
print(df)
df.to_excel('水体营养状态监测成果.xlsx',index=False)
3.2 建立关系曲线
根据水体营养状态评价标准及分级方法表中“评价项目赋分值En”和各项指标浓度值的对应关系,可整理成五个独立的分段函数,分别表示叶绿素a(chl-a)、总磷(TP)、总氮(TN)、透明度(SD)、高锰酸盐指数(CODMn)五项指标的浓度值与赋分值En的函数关系。以叶绿素a(chl-a)和透明度(SD)2项为例,其关系曲线分别用python代码表示如下:
#项目"叶绿素a"营养状态指数分段函数
def Eutrophication_index_Chlorophyll_a(x):
if 0.000<=x<0.0005:
return 20000*x+0
elif 0.0005<=x<0.0010:
return 20000*x+0
elif 0.0010<=x<0.0020:
return 10000*x+10
elif 0.0020<=x<0.0040:
return 5000*x+20
elif 0.0040<=x<0.010:
return 5000/3*x+100/3
elif 0.010<=x<0.026:
return 625*x+175/4
elif 0.026<=x<0.064:
return 5000/19*x+1010/19
elif 0.064<=x<0.16:
return 625/6*x+190/3
elif 0.16<=x<0.40:
return 250/6*x+220/3
elif 0.40<=x<1.0:
return 50/3*x+250/3
elif x>=1.0:
return 100
else:
return ""
#项目"透明度"营养状态指数分段函数
def Eutrophication_index_Transparency(x):
if x>=10:
return-2*x+30
elif 5.0<=x<10:
return-2*x+30
elif 3.0<=x<5.0:
return-5*x+45
elif 1.5<=x<3.0:
return-20/3*x+50
elif 1.0<=x<1.5:
return-20*x+70
elif 0.5<=x<1.0:
return-20*x+70
elif 0.4<=x<0.5:
return-100*x+110
elif 0.3<=x<0.4:
return-100*x+110
elif 0.2<=x<0.3:
return-100*x+110
elif 0.12<=x<0.2:
return-125*x+115
elif x<0.12:
return 100
else:
return ""
3.3 赋分计算
将3.1中提取的监测数据分别带入3.2中对应的关系曲线,计算出各项指标对应的赋分值En和样品所代表水体的营养状态指数EI。主要代码如下:
#分别计算各指标富营养化指数En
d=pd.read_excel('水体营养状态监测成果.xlsx')
d['叶绿素a']=d['叶绿素a'].apply(lambda x:Eutrophication_index_Chlorophyll_a(x))
d['总磷']=d['总磷'].apply(lambda x:Eutrophication_index_TP_lake(x))
d['总氮']=d['总氮'].apply(lambda x:Eutrophication_index_TN_lake(x))
d['高锰酸盐指数']=d['高锰酸盐指数'].apply(lambda x:Eutrophication_index_CODmn(x))
d['透明度']=d['透明度'].apply(lambda x:Eutrophication_index_Transparency(x))
print(d)
d.to_excel('水体营养状态评分.xlsx',index=False)
#计算参评项目赋分的平均值EI,结果保留2位小数
d=pd.read_excel('水体营养状态评分.xlsx')
d['EI(营养状态指数)']=d.loc[:,['叶绿素a','总磷','总氮','高锰酸盐指数','透明度']].mean(axis=1)
d=round(d,2)
print(d)
d.to_excel('水体营养状态评分.xlsx',index=False)
3.4 评价成果输出
按照水体营养状态评价标准及分级方法,根据营养状态指数EI确定水体营养状态级别,生成“水体营养状态评价结果.xlsx”。主要代码如下:
def Eutrophication_index_grade(EI):
if 0<=EI<=20:
return "贫营养"
elif 20 return "中营养" elif 50 return "轻度富营养" elif 60 return "中度富营养" elif 80 return "重度富营养" else: return "" d=pd.read_excel('水体营养状态评分.xlsx') d['营养状态分级']=d[' EI(营养状态指数)'].apply(lambda x:Eutrophication_index_grade(x)) print(d) d.to_excel('水体营养状态评价结果.xlsx',index=False) 根据SL 395—2007《地表水资源质量评价技术规程》中5.1.2的规定,“叶绿素a”为必评项目,即“叶绿素a”是否参评直接决定评价结果是否有效。因此,须对项目“叶绿素a”的参评情况进行复核。如未参评,应标注提示信息“叶绿素a未参评!”。必评指标复核的代码如下: def check_Chlorophyll_a(x): if x>=0: return "" else: return "叶绿素a未参评!" d=pd.read_excel('水体营养状态评价结果.xlsx') print(d) d['必评项目复核']=d['叶绿素a'].apply(lambda x:check_Chlorophyll_a(x)) print(d) d.to_excel('水体营养状态评价结果.xlsx',index=False) 为实现评价功能可在任何其他未安装python软件的PC上正常运行,可使用auto-py-to-exe工具可将写好的python代码打包成可执行文件“水体营养状态评价系统.exe”。将待测数据文件“原始检测数据.xlsx”(数据量为10000个样本)置于可执行程序所在的文件夹,运行“水体营养状态评价系统.exe”后,分别生成“水体营养状态监测成果.xlsx”“水体营养状态评分.xlsx”和“水体营养状态评价结果.xlsx”3个xlsx格式文件,软件运行用时约25s。为验证评价的有效性,同时采用传统的excel、wps等软件的函数功能按照线性插值法对案例中部分样品进行营养状态评分和分级评价。结果显示:其评分和分级评价结果与python代码运行结果完全一致,分级评价结果亦完全吻合。水体营养状态评价系统测试结果见表2—4。 表2 水体营养状态监测成果 表3 水体营养状态评分 表4 水体营养状态评价结果 利用python语言将水体营养状态评价方法设计成能在多种平台上运行的水体营养状态评价系统,体现了水环境评价与计算机程序设计学科交叉融合的可行性。基于python语言设计的水体营养状态评价系统可以在很大程度上弥补常规办公软件在数据处理方面的不足,尤其是在处理海量的水环境监测数据时,python语言具有更加便捷、高效、准确的优点,在实际的水环境质量评价工作中具有较高的应用价值。3.5 必评指标复核
4 典型案例的测试



5 结语
猜你喜欢
工会博览(2022年8期)2022-06-30 12:19:30云南化工(2021年6期)2021-12-21 07:31:16中国测试(2021年4期)2021-07-16 07:49:04阅读(科学探秘)(2020年8期)2020-11-06 06:22:48中国果业信息(2019年1期)2019-01-05 17:41:42水利技术监督(2017年6期)2017-12-19 13:28:18生物学教学(2017年9期)2017-08-20 13:22:32电镀与环保(2016年3期)2017-01-20 08:15:31食品工业科技(2014年6期)2014-05-10 06:04:50江苏卫生事业管理(2014年2期)2014-02-28 01:59:36
