
基于知识图谱的制造资源推荐方法研究*
2024-01-27 06:24:58张冠伟
组合机床与自动化加工技术 2024年1期
刘 阳,张冠伟,王 磊,张 奇
(天津大学机械工程学院,天津 300350)
0 引言
我国制造业自改革开放以来取得了较高水平的发展,但是仍然存在着经济负荷严重、资源消耗大、附加价值低的情况,许多产业制造资源没有统一的管理方法,难以高效利用[1]。李伯虎等[2]提出了云制造的概念,介绍了云制造的内在原理和技术框架,随着云制造的提出,制造企业开始使用云计算、大数据等技术服务和表达各种制造资源,并帮助用户获取质量较高的资源服务,但目前云制造发展尚不完善,技术体系不够完整,企业应对产品加工需求时资源推荐质量仍然不高。
基于知识图谱的制造资源推荐方法能够有效提高资源的利用效率,国内外已经有很多学者对制造资源的推荐方法有所研究,制造资源推荐架构可以总结为,根据用户提出的服务需求和企业内部制造资源构建描述模型,然后通过相关的资源推荐方法,得到满足要求的资源。
在制造资源和需求模型的表达方面,毕筱雪[3]基于语义构建制造资源模型,实现制造资源在云制造环境下的本体建模与服务化封装。吴斌等[4]提出了需求的定义,通过产品将抽象的需求以具象的视觉方式表达出来。于泽源等[5]利用三元组对需求信息进行表达,涵盖基本原理、设计过程、规范标准等不同的需求类型。徐进[6]从三维图档案中抽取零件实体和关系,并将装配设计规范融入到模型中。
在制造资源的匹配和推荐方面,李新等[7]融合领域匹配和功能匹配,解决了云制造环境下资源搜索效率不高的问题。杨娟等[8]将需求和服务之间的匹配划分为原子匹配、扩展匹配和产品匹配,采用了语义相似度和结构匹配算法相融合的循环递归设计方法。殷亮等[9]提出了双层规划模型,并利用改进的遗传算法进行求解,解决资源配置问题。陈映莲[10]从供需双方的利益、匹配的优先级、匹配的质量、双方的满意度4个方面出发,致力于同时提高供需双方的满意度。郑杰等[11]融合神经网络模型,通过智能推荐方法提高推荐的效率和质量。
针对上述问题,构建了一种基于知识图谱的制造资源推荐方法,从制造领域知识图谱的生成、资源的综合推荐两个方面实现该方法的表达,旨在面向产品制造加工,探索制造领域知识图谱的构建方法,并基于所构建的知识图谱进行制造资源的推荐,提高企业服务质量和资源利用率。
1 制造资源推荐方法的整体模型
制造资源推荐方法的整体模型如图1所示,主要包括两个模块。

图1 制造资源推荐方法的整体模型
(1)面向产品加工的制造领域知识图谱构建模块。构建知识图谱的数据来自于企业内部已有数据库、未规划分类的数据资源和实体资源组成的制造资源以及产品制造图纸、文本、数据组成的需求资源,针对相关数据进行信息提取,运用本体建模、知识抽取等技术,获取制造领域信息的知识表达,最后利用图数据库完成知识存储和可视化表达。
(2)基于知识图谱嵌入的制造资源推荐模块。提出一种制造资源双重推荐方法,以构建的制造领域知识图谱为基础,运用知识图谱嵌入实现知识图谱的向量化表示,然后利用相似度排序技术,以基本特征为匹配目标,实现制造资源初步匹配。同时,为提高推荐质量,融合制造资源服务质量推荐指标,完成资源的双重匹配,实现基于需求单元的制造资源的推荐。
2 制造领域知识图谱的构建
知识图谱是一个巨大的知识库,它以统一的规范连接和存储来自世界各地的知识。知识图谱有通用图谱和领域图谱两类,其中,领域图谱面向纵向需求,更多集中于专业领域的研究。知识图谱的构建模式主要可以分为自顶向下和自底向上,自顶向下即模型构建在先,然后将数据填充到模型库中,而自底向上则是优先从数据层入手抽取相关数据。制造领域知识图谱的构建采用自顶向下和自底向上相结合的方法,自顶向下构建制造领域本体作为图谱的模式层,再对企业内部的数据资源进行提取,构建知识图谱的数据层。其中,需要处理的数据可能是结构化的,也可能是半结构化或者非结构化的,对于这样的数据,采用实体抽取和关系抽取的方法进行数据处理,加入到知识库中,最后将三元组信息进行存储,实现知识图谱的表达。
2.1 领域本体模型构建
本体是一种知识表示方法,可以表示概念之间的关系,采用本体构建7步法,表示出需求信息和制造资源的概念及关系,作为制造领域知识图谱的模式层。采用自顶向下的层次结构方法,根据产品制造加工的相关需求,将制造领域知识继续细分为制造资源知识和产品制造加工知识两个概念,其中,制造资源知识继续分为人力资源、设备资源、技术资源、场地资源和外部资源,不同资源再分为不同的设备、技术等,产品制造加工知识继续分为不同的需求知识。建立4种概念间的关系,分别是part-of(局部与整体的关系)、kind-of(父类与子类之间的关系)、instance-of(类与实例之间的关系)、attribute-of(类的属性,包括对象属性和数据属性)。采用protégé本体建模方法整合上述本体模型构建过程,protégé建模界面如图2所示。

图2 protégé建模界面
2.2 实体抽取
采用深度学习的方法对文本型的资源数据进行实体抽取,针对基于知识图谱的制造资源推荐方法的研究,主要进行产品制造需求和企业制造资源的描述文档中实体的识别。进行实体抽取任务时,要准备好训练集、验证集和测试集。进行实体抽取之前,需要对文本进行标注,为模型提供训练集,采用BIO标注方法进行标注,B、I、O分别表示实体的开始、中间字符和尾部字符及其他不属于实体的内容,并建立实体标签用来表示不同类型的实体,文本标注方法如图3所示。
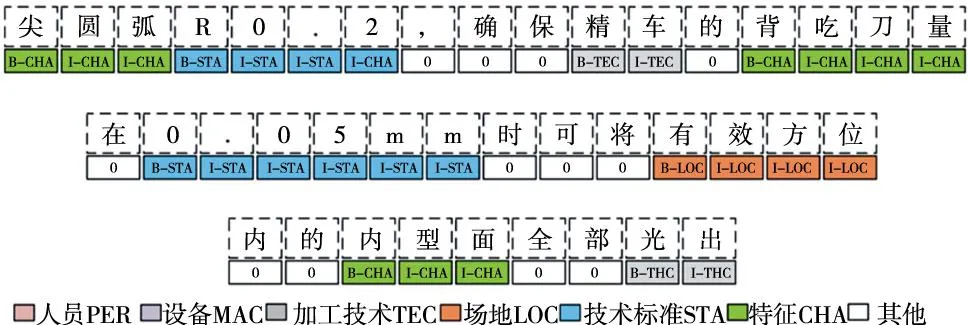
图3 文本标注方法
文本标注预处理之后,需要采用词嵌入技术对文本进行向量化表示。在模型的选择上,采用基于BiLSTM-CRF模型的深度学习方法实现知识的提取,图4为BiLSTM-CRF模型的基本框架,BiLSTM通过将输入序列同时接入前向LSTM和后向LSTM,并将这两个LSTM层共同接入到输出层,可以充分利用输入序列的上下文信息。CRF条件随机场是一种判定模型,它的作用是可以对输出进行分析,寻找其中的联系,用来预测序列。BiLSTM的输入是训练好的词向量,输出是某一单词对应各个类别的分数。
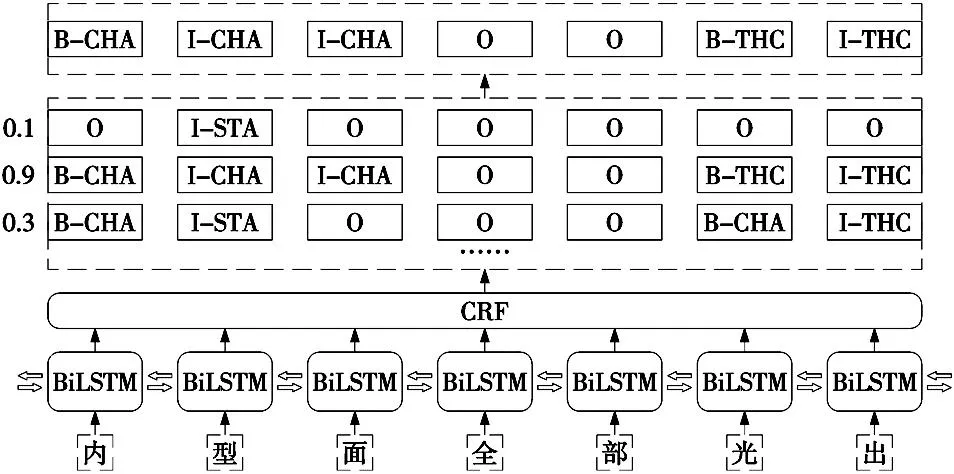
图4 BiLSTM-CRF模型的基本框架
2.3 知识图谱可视化表示
得到实体标签后,通过分类器对实体进行关系识别和建立,此过程可基于开源的机器学习库Scikit-learn实现。由此,便可以得到实体与关系的三元组数据,并基于机械制造领域相关规范完成知识的融合,再使用图数据库Neo4j映射实体间的关系,并得到可视化图谱。
Neo4j是目前使用最为广泛的图数据库,采用Cypher语言,将得到的实体和关系数据存入结构化的CSV文件中,编写Neo4j导入节点和关系程序,可以自动导入数据,实现制造领域知识图谱的生成。
3 基于知识图谱的制造资源推荐
制造资源推荐需要以零件的需求信息为依据,在满足各类设计和加工的条件下,从可选的制造资源范围内选择最为精确合适的制造资源。是制造领域知识图谱应用的重要方式,其推荐质量直接影响到产品的生产加工以及后续的使用。因此本文提出一种双重推荐方法,通过基本特征匹配和资源服务匹配,采用知识图谱嵌入、相似度分析、Qos服务匹配等方法,得到最优的资源推荐,保证制造资源推荐的质量。
3.1 知识图谱嵌入方法
知识图谱由实体和关系构成,为实现产品制造加工需求信息和制造资源信息在知识图谱中的结构化表示,知识图谱的边采用事实三元组的形式进行表达:
T=(h,r,t)
(1)
式中:h代表头实体,t代表尾实体,r代表头尾实体的关系。
知识图谱嵌入可以将知识图谱中的实体和关系表示为低维向量,采用TransE模型实现知识图谱嵌入,将实体和关系映射到同一空间。将关系r看作头实体h向尾实体t的平移操作,该模型的训练目标是通过训练制造领域知识图谱中已存在的三元组,使实体和关系的向量满足h+r-t=0,则该三元组正确性越高。
TransE模型的损失函数定义为:
(2)
式中:γ为超参数,取值预先设定;(h,r,t)表示正确三元组,(h′,r,t′)表示错误的三元组,G表示正确的三元组集合,G′表示错误的三元组集合,d(h+r,t)表示三元组的势能函数,可以将其取为L1或L2范数。
对于正确的三元组,其势能越低,则代表两个实体越接近,而对于错误的三元组,则希望其势能越高越好。从知识图谱中选取尽可能多的实体数据,并抽取其中的三元组,同时需要为实体构造关系索引,以此构建实验所需训练集。因为知识图谱中存在的三元组都是正确的,因此为了模型训练需要,使用替换法获取错误三元组,在训练过程中,随机替换头尾实体,获取错误三元组,即负样本,然后通过随机梯度下降方法,不断对损失函数进行优化,获得合格的嵌入向量。
3.2 制造资源双重推荐方法
制造资源进行加工服务时不仅需要考虑资源的加工属性是否满足制造要求,其服务质量也是重要的考察因素,制造企业不仅要保证产品功能的实现,还要在自身服务质量上不断提升。从目前的研究来看,一般的制造资源推荐只是满足特征的适应度,仅仅考虑资源的加工属性是否满足制造要求,往往只面向产品需求和制造资源之间的特征关系进行匹配,因此,本文提出一种基于制造资源双重推荐方法,使得最终的候选资源在功能属性和服务质量上都有很好的表现。
制造资源双重推荐方法分为两部分,首先是基本特征的匹配过程,基于知识图谱嵌入方法获得实体对的向量表示后,采用向量的相似度计算方法,从制造资源知识图谱中寻找与需求信息知识图谱中某特征的向量相似度较高的资源实体。
在基本特征匹配之后,从企业的历史制造数据库中选取相关已完成的加工任务数据资料,从资源的Qos服务方面出发,利用服务质量指标对候选制造资源集进行评分计算。将Qos服务定义为加工时效PT、成本水平CL、加工质量PQ、满意度S四个指标。资源加工时效表示为:
(3)
式中:Ta表示所选资源完成其加工任务的平均时间,Tave表示所有同类加工资源完成该加工任务的平均时间。
成本水平表示为:
(4)
式中:Ca表示所选资源完成其加工任务的成本,Cave表示企业内所有同类加工资源完成该加工任务的平均成本。
加工质量表示为:
(5)
式中:Qa表示所选加工资源所有加工任务中合格任务的数量,Qe表示完成加工任务总数。
满意度表示为:
(6)
式中:Si表示以往每次产品制造加工得到的用户满意度评分。
利用各资源的Qos参数可构建评价矩阵Q,Q中包含n个制造资源的4项评价指标。
加工质量PQ和满意度S的值均在[0,1]内,可以直接参与计算,而资源加工时效PT和成本水平指标CL需要进行归一化处理,计算方法为:
(7)
式中:PT′和CL′表示归一化处理后的资源加工时效和成本水平指标,P(i)表示历史数据库中所有有加工时间记录的资源个体,Q(i)表示所有有成本记录的资源个体。
采用变异系数法确定各指标的权重系数:
(8)
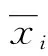
根据变异系数可以得到权重ωi为:
(9)
通过上述方法,对特征匹配得到的候选制造资源进行权重计算,并对4种指标赋权求和得到Qos评分分数,依照得分情况对制造资源进行排名,设立资源选择分数,选择排名最高的一组或几组制造资源作为基于知识图谱的制造资源推荐方法的结果。
4 实例验证
现有一家项目合作企业,利用企业内的一机器人手臂零件的制造任务验证基于知识图谱的制造资源推荐方法,其零件图如图5所示。

图5 机器人手臂零件图
首先根据加工特征以及工艺规则将其加工任务分为不同的任务单元,如表1所示。

表1 零件任务信息
选择制造任务单元RT1铣平面的加工任务,将其特征描述为{平面,铣削,45钢,132.5,Ra6.3},依照第2.1~2.3节中的制造领域知识图谱构建方法,首先构建制造资源本体模型,然后进行知识抽取。
整合企业内部的文本数据和资料,数据示例如表2所示。

表2 数据示例
按照BIO标注方法进行预处理,得到的文本数据集共10 353条,按3∶1∶1分成训练集、验证集和测试集。设置好模型参数,启动模型,进行模型训练,为评价训练效果是否达到预期,设定模型评价指标为准确率、召回率和F1分数。同时为了比较BiLSTM-CRF模型与其他模型的可靠程度,加入HMM模型,用同样的数据集进行实验,得到各实体标签在训练中的准确率、召回率和F1分数如图6所示。

(a) HMM模型 (b) BiLSTM-CRF模型图6 不同模型的实体标签评价指标数值
根据实验结果可以看到,BiLSTM-CRF模型的效果明显好于HMM模型。因此,采用BiLSTM-CRF模型完成知识抽取任务,并将实体和关系导入Neo4j,构建出制造领域知识图谱,其局部示意图如图7所示。
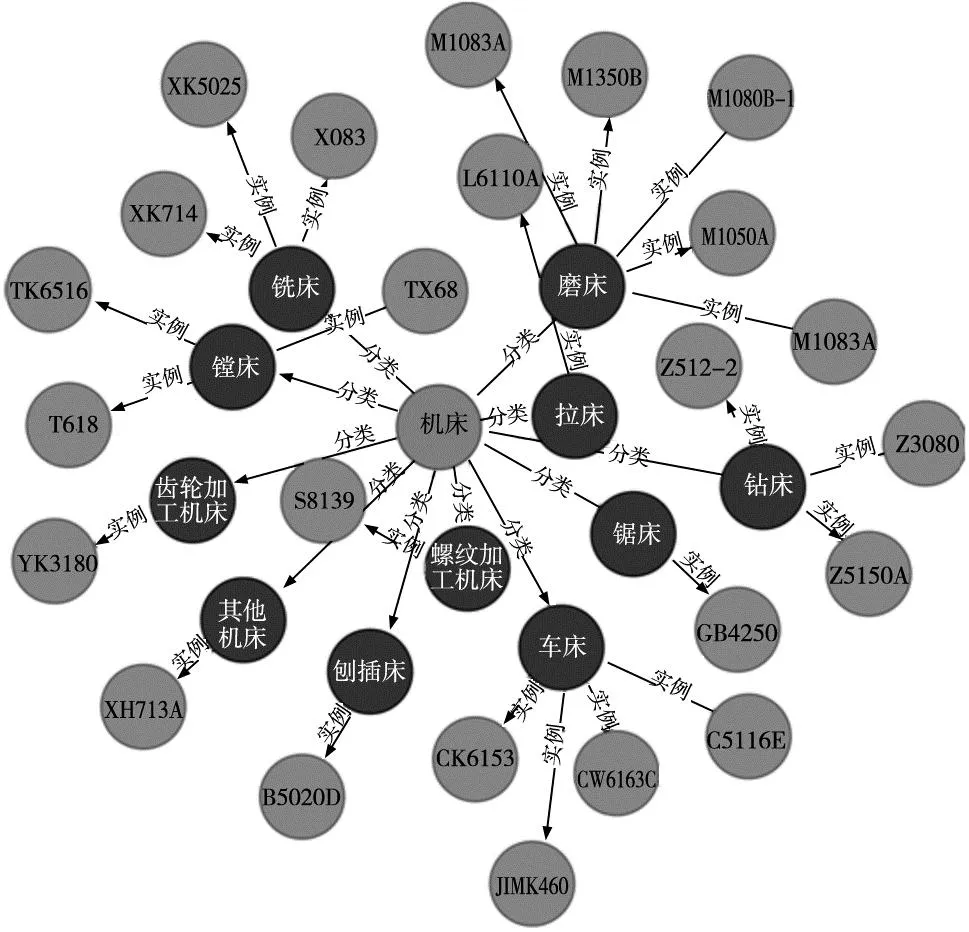
图7 制造资源知识图谱局部示意图
根据知识图谱嵌入方法,利用TransE模型,实现知识图谱的向量化。基于TransE模型得到向量表示后即可通过向量值的计算来衡量各资源特征的相似程度,采用余弦相似度计算方法计算向量之间的相似度,计算公式为:
(10)
式中:n是向量维度值,ai∈A=[a1,a2,…,an],bi∈B=[b1,b2,…,bn]。
在基本特征匹配中,利用不同节点的向量化和相似度计算,得到与需求特征实体训练所得向量相匹配的相似特征向量。以上述任务单元为例,将该特征视作目标特征,通过知识图谱嵌入,得到100维向量,以余弦相似度寻找相似特征向量,以余弦相似度寻找相似特征向量,按照相似度由高到低排序,如图8所示。

图8 相似特征匹配示意图
经过计算后相似特征的向量相似度排序如表3所示,可以看出,符合与目标特征相似的3个制造特征中,特征类型均为外圆,全部符合;材料特征方面,与目标特征一致的是铝合金,然后是45钢;表面粗糙度方面,最为符合的是Ra1.25,第2名的特征为Ra0.32,第3名是Ra3.2;加工精度方面,最符合的是IT7,第2名是IT8;加工路线方面,最为符合的是编号为Z014的特征,第2名为编号Z015的加工路线。在进行选择时,相似特征的相似度越高,则其在制造信息上更符合目标特征,根据此方法选择得到排名较高的若干制造特征,然后根据其连接关系确定制造资源的名称,得到制造资源初步候选集,并进行下一步资源匹配。

表3 相似单元排序信息
设定候选集数量为4,利用所述方法,选择排名前4的制造资源,得到如表4所示的制造资源初步候选集,并统计这些制造资源的加工时效、成本水平、加工质量、满意度指标填入表4中。

表4 制造资源初步候选集
归一化处理后,得到评价矩阵Q′为:
计算得到4种指标的标准差和平均值,再根据式(8)和式(9)计算得出各指标的变异系数和权重,如表5所示。

表5 各指标的变异系数和权重
以权重设立制造资源服务评分函数,计算得权重为{ω1,ω2,ω3,ω4=0.35,0.25,0.18,0.22},对4种指标赋权求和,并依照得分情况对制造资源进行排序,如表6所示。

表6 制造资源服务匹配排序
以任务单元RT1的匹配过程为例,分别计算得到其他任务单元的制造资源服务匹配排名,设立优选目标分数,实现对制造资源初步候选集的筛选,完成基于任务单元的制造资源服务细粒度匹配。
5 结论
针对当前制造资源推荐模型存在的资源信息分散、资源与需求描述方式不统一、资源推荐效率低质量差等问题,提出了一种基于知识图谱的制造资源推荐方法,以供需模型为指导构建本体模型作为知识图谱的模式层,采用自然语言处理中的实体抽取方法从相关数据中提取实体和关系作为知识图谱的数据层,并将知识图谱可视化表达。然后提出了一种制造资源双重推荐方法,采用知识图谱嵌入方法实现知识图谱向量化,通过相似度计算,完成基本特征匹配,并设置了制造资源的Qos服务质量指标,计算各制造资源的服务质量评价分数,对候选资源集中的资源进行排序,得到最合适的资源推荐方案。
该方法适用于云制造模式下的制造资源推荐任务,能充分挖掘企业内部所有数据信息,对其进行规范化整合,还能根据制造要求和服务质量,实现质量更高的制造资源推荐,提高了企业面对产品加工任务的响应速度,使得企业制造加工更加高效准确。未来的研究方向是将构建的知识图谱根据企业的大规模数据进行知识图谱补全和细粒度化工作,使该方法的适用性更强。
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31 08:40:44
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
少先队活动(2020年12期)2021-01-14 01:47:40
中国外汇(2019年18期)2019-11-25 01:41:54
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
哲学评论(2017年1期)2017-07-31 18:04:00
中成药(2017年3期)2017-05-17 06:09:01
领导决策信息(2017年9期)2017-05-04 04:04:49
领导决策信息(2017年9期)2017-05-04 04:04:49
领导科学论坛(2016年9期)2016-06-05 14:59:58
