
基于数据库标签感知分片的制造过程测量数据分布式存储*
2024-01-25 05:44王佺珅张爱梅
机电工程 2024年1期
王佺珅,张爱梅
(郑州大学 机械与动力工程学院,河南 郑州 450001)
0 引 言
近年来,制造业向着数字化、信息化方向高速发展。测量技术已然成为现代制造业发展的重要保障,也成为反映制造业技术先进性的关键指标[1-2]。特别是各种传感器和数据采集装置在测量过程中大量使用,测量数据开始呈现出规模性、分散性和高速性的特征,这些数据对于保障机械设备的加工质量有着重要的意义[3-4]。
复杂零件加工有多个测量工序,需要多种工序测量仪器协同配合来完成测量任务。在传统的零件测量过程中,测量人员以零件测量传递卡形式记录各个工序仪器测量的数据[5]。由于数据保存的方式混乱,造成数据采集不完整、实时性差,无法从相关测量数据中获取有用的信息来进一步指导生产。
嵌入式平台具有高实时性、节能性和拓展性等优势,能够满足测量数据的采集与存储需求,特别适用于工业自动化、医疗设备、环境监测等领域[6],其已成为在线测量设备的主流选择。
保敬成[7]提出了一种应用于便携式测量仪器的数据库,实现了嵌入式设备对测量数据的简单存储目的,并提供了人机接口;但由于数据存储格式单一,导致嵌入式数据库与上层应用数据格式对接困难。阳深等人[8]在嵌入式Linux平台中设计了便携式谱仪放射性核素数据库,解决了便携式谱仪无法进行存储的问题;但是其没有对仪器数据的远程共享进行讨论。肖贺等人[9]在嵌入式系统中使用SQLite数据库存储各类气象要素数据和要素名;但是其存在存储结构灵活性低、可拓展性差的弊端。WANG Jian-tao等人[10]研究了嵌入式仪器数据库系统中基于块的多版本B+-Tree应用,通过工业应用验证了该数据库在数据存储和访问方面表现良好,满足嵌入式设备对高可靠性和实时性能的要求。
以上研究都是在解决独立测量仪器数据存储的问题,并没有对多个测量仪器的协同存储与数据交换进行探讨,在测量场景应用中会出现下列问题:1)对大批量数据的存储查询能力较弱,无法适应在线测量密集的读写场景;2)对不同工序测量节点,嵌入式设备协同存储和查询汇总困难;3)存储结构不够灵活,难以满足多变的测量需求。
鉴于上述问题,笔者在嵌入式平台中搭建基于MongoDB数据库的零件在线测量分布式存储集群,按照测量仪器相应的测量工序对零件存储模型进行简化;使用标签感知的零件数据布局方法,实现测量数据在多个测量仪器中的分布式存储和高效的统计分析目的。
1 在线测量存储集群总体设计
1.1 功能需求分析
零件的测量涉及被测特征,例如圆度、直径、角度等[11]。根据被测特征制定测量工序,确定使用的仪器组合,如气动量仪、激光量仪和视觉量仪等。
为了满足测量数据的存储和查询分析,更好地适应不同的存储需求和测量场景,零件的在线测量应具备实时采集、多仪器协同、分类存储和远程查询聚合等特征。笔者基于嵌入式平台,运用分布式数据库技术,建立零件在线测量分布式存储集群。
具体功能要求如下:
1)按照不同测量工序进行实时分类存储,便于查询管理;
2)存储时可以灵活拓展、变更数据库内的测量信息,适应不同类型和规模的测量需求;
3)支持高效的条件查询和聚合,实时监控零件的制造信息;
4)根据零件编号对所有测量节点内的工序数据进行汇集统计,构建零件信息表。
1.2 总体设计
笔者按照零件在线测量功能需求设计的总体架构如图1所示。
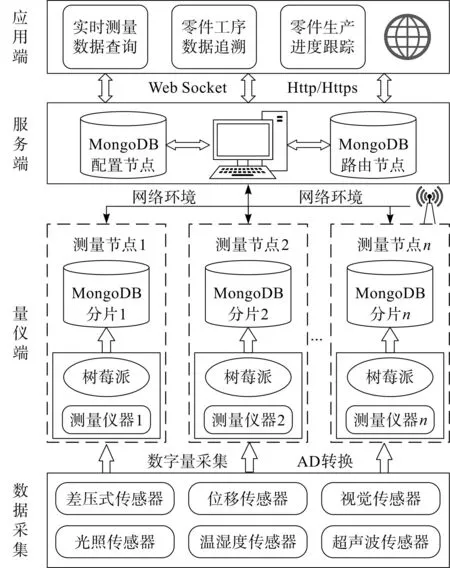
图1 零件在线测量存储集群总体架构Fig.1 Overall architecture of part on-line measurement and storage cluster
由图1可知:零件在线测量分布式存储集群由量仪端、服务端和应用端三层架构组成。
在量仪端,搭载树莓派的测量仪器和与之相连的传感器组成了在线测量存储集群的一个测量节点。笔者将MongoDB数据库移植到树莓派中,作为该测量节点的存储分片;对零件的某个测量工序进行测量时,传感器采集的测量数据通过PyMongo接口实时保存到相应测量节点的数据库分片中,可以根据零件的测量工序拓展测量节点的数量,形成存储集群。
笔者将服务端和每个测量节点通过工业路由连接在同一个局域网内,使服务端作为整个在线测量存储集群的控制中心,分发存储和查询请求。
应用端通过远程连接服务器,可以访问整个分布式测量存储集群中所有测量节点的数据,进行实时测量数据查询、零件工序数据追溯和生产进度跟踪等应用工序。
2 测量数据分布式存储研究
2.1 MongoDB集群架构
MongoDB是一种非关系型数据库,其具有动态的数据模式,可以根据测量任务和测量场景的转变调整文档中记录的格式,实时更新接入仪器的测量信息。这种根据需求自由存放不同结构数据的方式在关系型数据库系统上是无法实现的[12]。
MongoDB的分布式集群架构如图2所示。
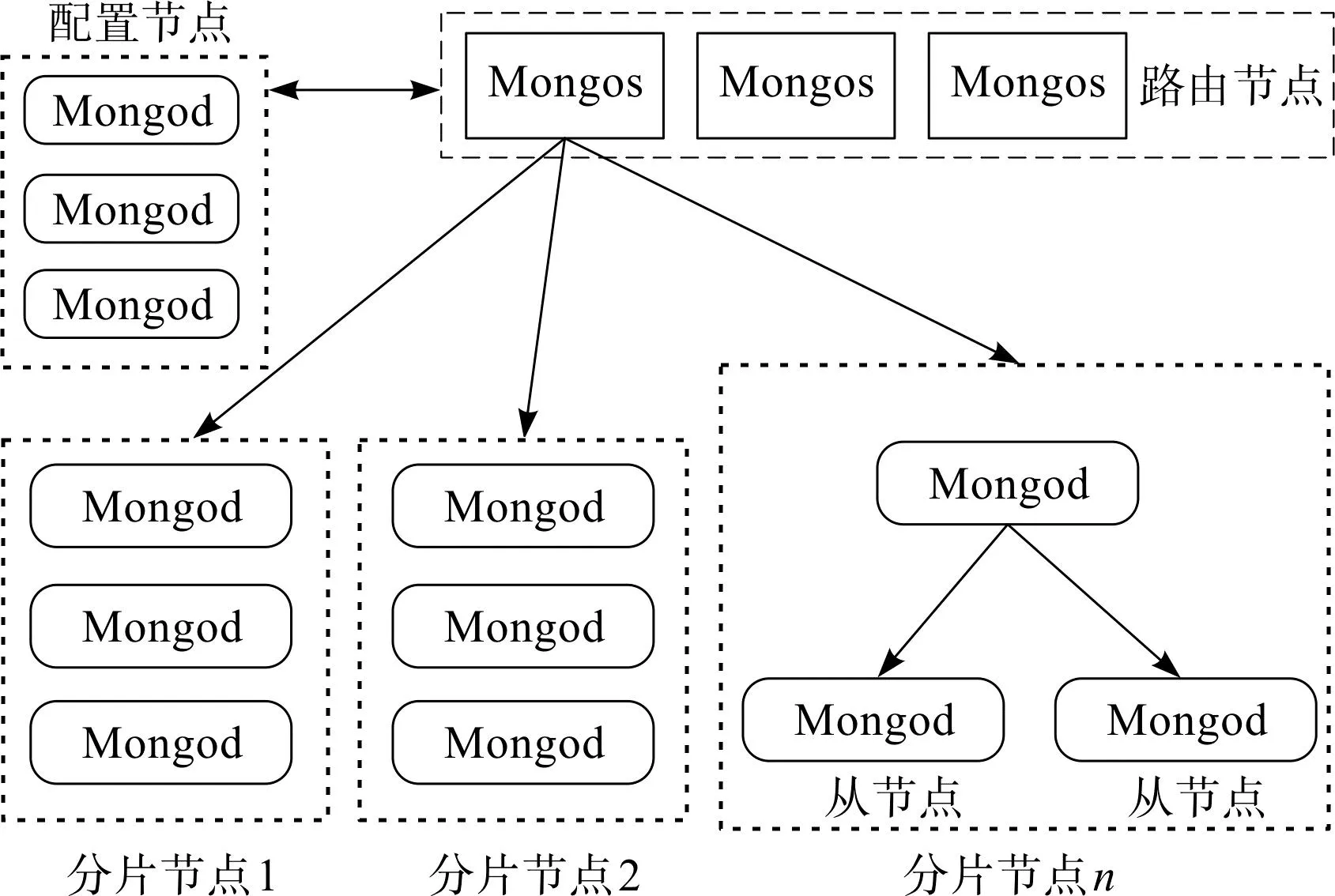
图2 MongoDB集群架构Fig.2 MongoDB cluster architecture
由图2可知:分片集群由分片节点(shard)、配置节点(config)和路由节点(Mongos)组成,每类节点都可以部署单个或者多个嵌入式平台。
分片节点部署在测量节点内,用于存储真正的测量数据,并提供最终的数据读写访问,节点中添加多个Mongod实例,保证零件数据存储集群的可靠性,节点数量可以根据零件测量工序数量进行拓展。配置节点用于保存分片集群中的分片策略和路由表等元数据。路由节点是MongoDB分片集群的访问入口,用于处理来自应用端的查询聚合等操作,并确定这些数据在分片集群中的存储位置。
2.2 测量数据存储模型设计
MongoDB中存储模型有内嵌和关联两种设计模式[13]。内嵌是将所有相关的实体放在一个集合内,关联则是将相关的实体放在不同的集合存储。
测量数据在存储时一般为一对一或一对多的关系,且数据存储到数据库集合内几乎不再修改,适合采用内嵌文档的方式进行存储,这样能够提高大规模数据聚合性能[14]80。
内嵌设计的零件测量数据存储模型如图3所示。
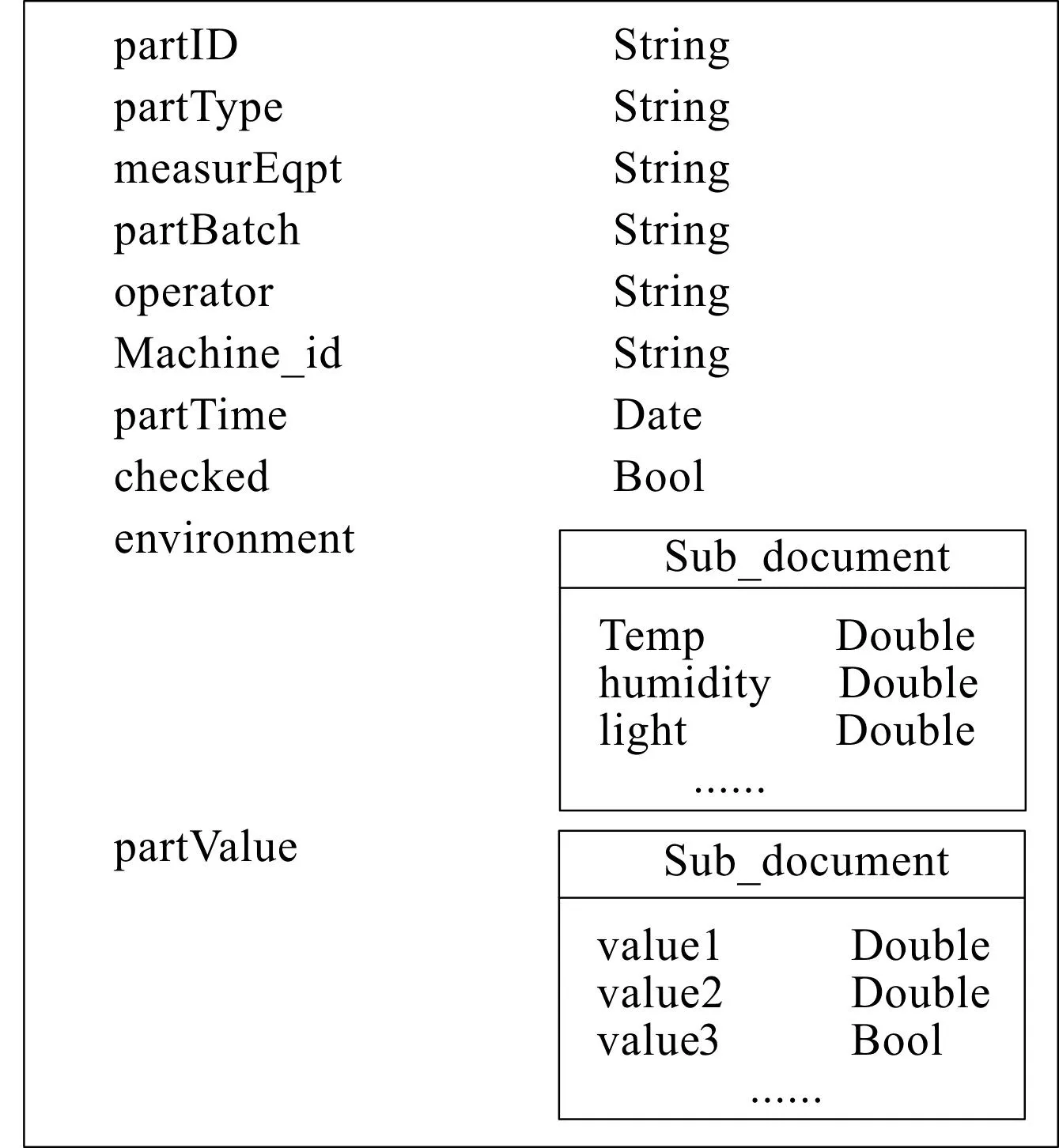
图3 零件测量数据存储模型Fig.3 Part measurement data storage model
存储模型的零件编号(partID)可以作为区分不同被测对象的唯一标识,测量环境(environment)和测量结果(partValue)以子文档的形式内嵌在测量文档中,和其余属性一同构成了零件测量数据存储模型。
活塞零件实物如图4所示。

图4 活塞零件实物图Fig.4 Physical drawing of piston parts
在生产过程中活塞零件具有多个测量工序,具体的测量工序流程图如图5所示。
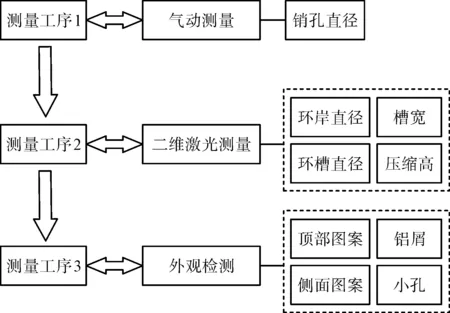
图5 活塞测量的工序流程图Fig.5 Process flow chart of piston measurement
由图5可知:活塞检测过程中存在着大量的测量参数,需要由多个测量节点协同完成测量任务。按照现有方法将大量工序数据存放在一个数据库,不仅不方便零件工序管理,而且大量复杂数据涌入会导致数据库性能下降。
为了减轻存储负载,方便零件在不同工序数据的分类存储和工艺能力评估,可以根据测量工序对活塞零件的测量数据进行拆分简化,拆分方法如图6所示。
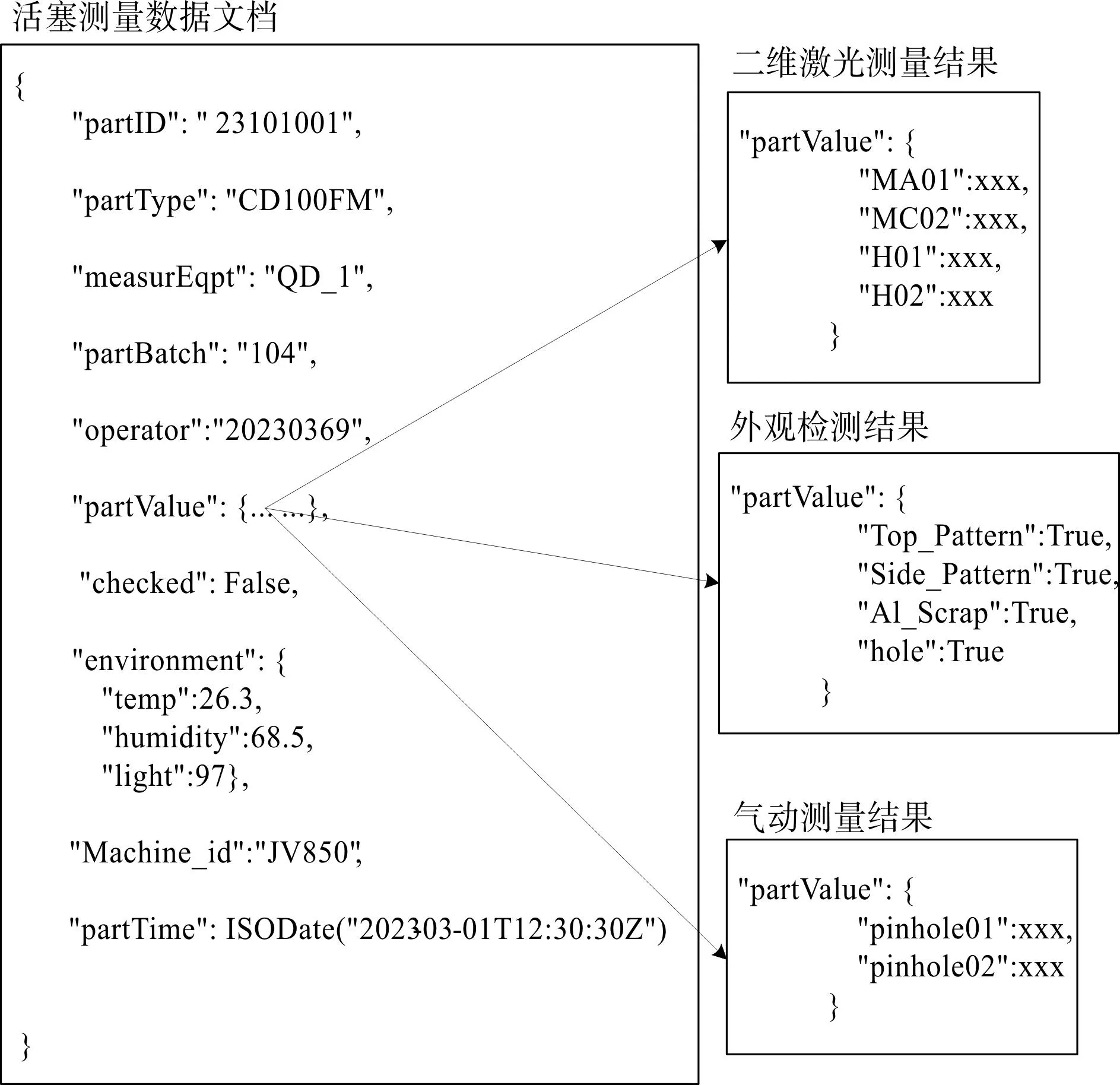
图6 活塞测量存储文档拆分Fig.6 Piston measurements store document splits
由图6可知:零件的唯一编号partID、零件类型partType、测量节点measurEqpt、零件批次partBatch、测量人员编号operator、测量结果partValue、测量时间partTime、测量环境environment、测量标记checked和生产机器编号Machine_id为每一个测量工序的共同属性。
在进行测量时,笔者仅需将测量结果partValue按照测量节点的工序内容进行拆分,即可得到活塞零件在外观检测、二维激光测量、气动测量三种测量工序下的存储模型。
2.3 测量数据存储布局设计
数据库分片是将一个数据量庞大的逻辑数据库均匀划分为多个物理数据库,将数据分片合理地部署在多个测量节点中。这样可以更好地应对大数据存储和客户端带来的高并发请求[15],有利于多个测量仪器的协同存储和拓展。
MongoDB可以根据具体的存储查询需求选择合适的分片方式进行数据布局。默认的分片方式为范围分片,范围分片是先将数据插入到主分片,再转移到其他分片,这会导致嵌入式平台内测量数据分布不均衡,存储集群性能下降。
哈希分片可以使数据在集群中相对均匀分布[16]72,但在线测量场景下的客户端查询需求多为范围查询,而哈希分片为了均匀存储会将数据随机分散到不同的分片中,这会造成范围查询效率降低[17]。
针对两种分片的优点和局限性,笔者在范围分片的基础上加入了标签感知分片机制,按照测量工序给测量节点创建标签,根据标签将工序数据分发到相应的测量节点,实现零件在不同工序数据的分类存储目的。
基于标签感知的分片集群如图7所示。
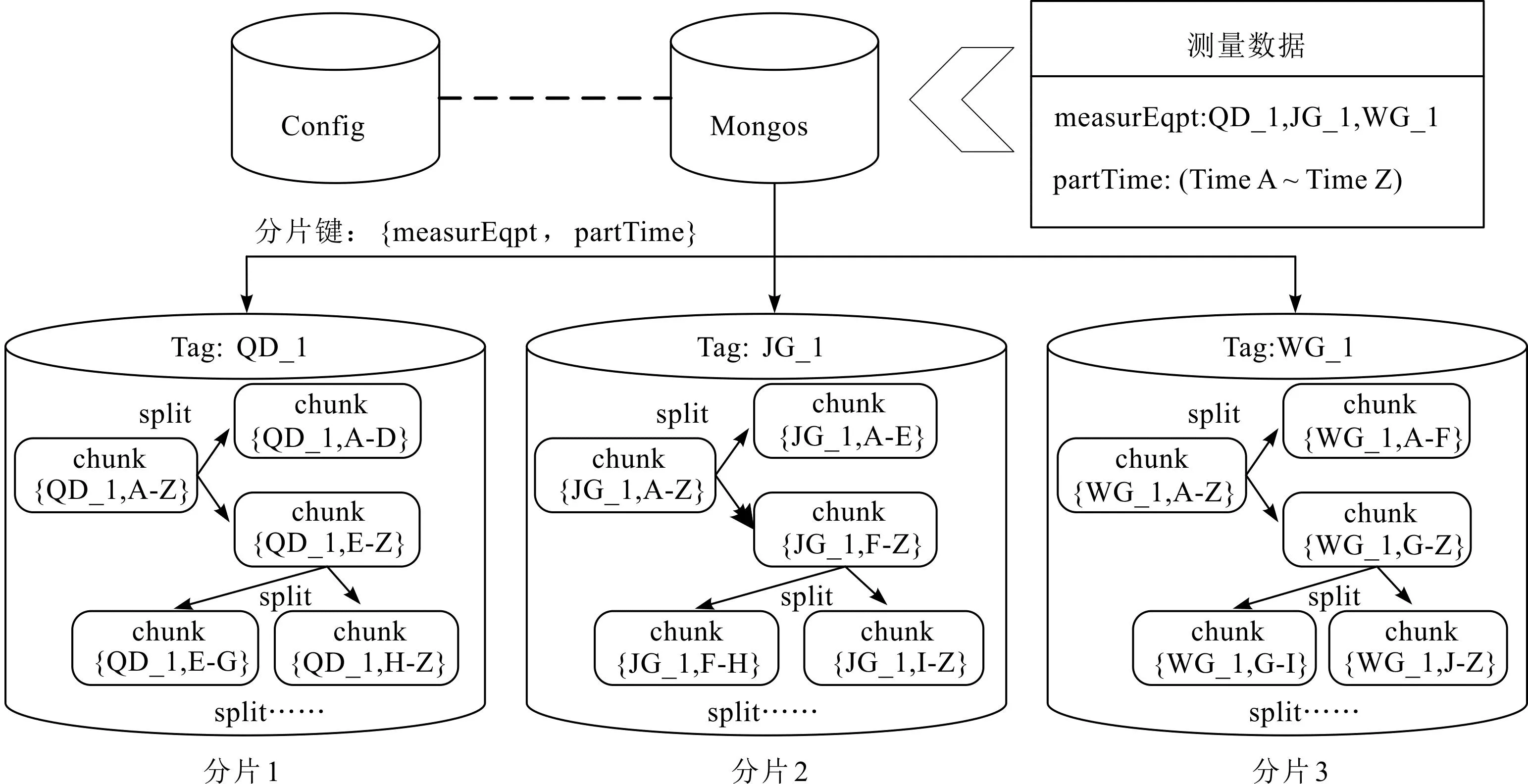
图7 基于标签感知的分片集群Fig.7 Tag-aware sharded clustering
为了在查询时路由节点可以直接定位到相应的测量节点,避免跨节点查询产生的广播效应,笔者选择measurEqpt字段作为范围分片复合片键的第一部分。
partTime是零件的测量时间戳,每测量一次就会递增,因此可以将其视为高基数和细粒度键,作为范围分片复合片键的第二部分。
对于测量节点发出的存储请求,路由节点通过标签感知将测量数据按照工序标签分发到指定的测量节点上。一旦分片中单个数据块内的对象数量增加,就可以根据测量时间进一步拆分,从而避免分片集群出现写入热点,确保数据的均匀分布,使仪器数据库集群协同查询更加高效,有效监控零件的制造信息。
3 性能测试与分析
为验证多个测量节点组成的在线测量分布式存储集群的数据存储、查询和聚合性能,笔者针对上文提出的存储布局进行了一系列测试。在测量环境下,使用三个测量节点测量2.4×105个零件,每个零件有三道测量工序,生成7.2×105条测试数据。
3.1 测试环境
测试环境由三台搭载树莓派3B+开发板的测量仪器、一台服务器和一个远程客户端组成,配置情况如表1所示。
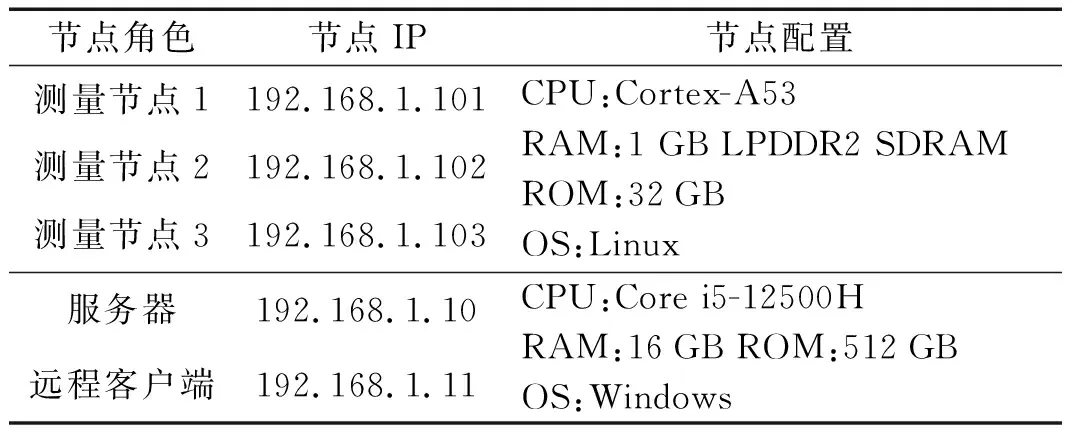
表1 存储集群节点配置表Table 1 Store the cluster node configuration table
搭载树莓派3B+的测量仪器实物如图8所示。

图8 搭载树莓派的测量仪器Fig.8 Measuring instruments equipped with Raspberry Pi
图8中,每台测量仪器都是一个测量节点,三台数字化量仪分别配置为存储相应测量节点的数据库分片。服务器用作查询路由和配置服务器,远程客户端负责发送查询和聚合请求。
3.2 数据存储查询测试
为了验证2.3节中提出的基于标签感知的范围分片布局策略是否合理有效,笔者将其在测试环境中与常用的两种分片方式进行对比,分别是:基于细粒度键测量时间{partTime}的哈希分片[16]72和基于“升序键+搜索键”{measurEqpt, partTime}的范围分片[14]80-81。
3.2.1 存储布局测试
为了便于观察,笔者统一设置分片集群数据块大小为1 MB,对使用不同分片方式的存储集群分别插入7.2×105条测量记录。数据分布情况如表2所示。
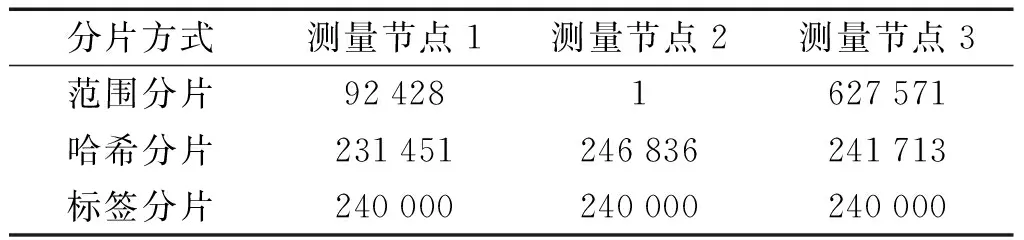
表2 不同分片方式的数据分布情况Table 2 Data distribution for different shards
由表2可知:范围分片中大量数据会存储在分片集群的主节点内,这容易导致某个测量节点嵌入式平台由于负载过高而宕机。
虽然哈希分片在每个节点存储的数据不是完全相同,但是可以保证数据的相对均匀。标签分片按照工序标签提前指定了数据存放的测量节点,数据在每个节点中均匀分布,存储集群达到负载均衡。
3.2.2 查询性能测试
针对测量仪器数据的查询需求,笔者在测试中对零件质量监控和追踪过程中可能会出现的查询场景进行了设计。
查询语句如表3所示。

表3 测量环境下的常用查询Table 3 Common queries in a measurement environment
表3中,query1可以查询出单测量工序在一段时间内测量温度在某个范围的记录;query2可以查询出单测量工序在一段时间内同种类型零件某个测量值在一段区间内的记录;query3可以查询出某个测量员在一段时间内同批次零件的测量记录;query4可以查询出在一段时间内同种类型、同批次零件在所有测量节点内的记录。
每当数据量增加1.2×105条时,笔者使用PyMongo接口生成客户端,访问存储集群的路由节点,分别查询表3中query1~query4,并计算出响应时间。
测试结果如图9所示。
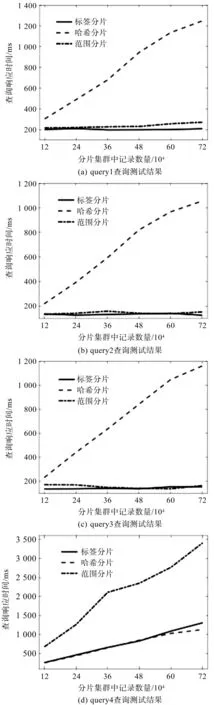
图9 查询性能对比图Fig.9 Comparison of query performance
由图9可知:在单测量节点查询请求query1~query3中,随着数据量的增加,标签分片的响应时间在125 ms~208 ms范围内表现稳定;范围分片在133 ms~271 ms之间有小范围波动;哈希分片的响应时间呈现明显的线性上升趋势,响应速度在218 ms~1 248 ms范围内。
测量数据达到7.2×105条时,标签分片的查询性能对比哈希分片最高提升了88.15%。多节点查询请求query4中,随着数据量的增加,哈希分片和标签分片的响应时间在257 ms~1 308 ms之间缓慢上升;范围分片有明显的上升趋势,从678 ms上升至3 410 ms,数据量为7.2×105条时,标签分片性能提升了61.64%。
观察表2中数据分布可以推断,由于大量数据在范围分片过程中涌入了一个测量节点,其余两个测量节点只有少量或者没有数据,这导致单个嵌入式系统中分片节点在查询时负载过高,所以在测试中范围分片的表现明显弱于标签分片和哈希分片。
通过不同分片方式的存储查询性能测试可以看出:引入标签感知机制的在线测量分布式存储集群在零件数据存储查询测试中表现出色,其做到负载均衡的同时,能够对客户端发出的多种查询请求做出毫秒级响应。
3.3 数据的聚合性能测试
在构建零件信息表时,客户端需要请求服务端的路由节点对分散在不同测量节点数据库中的零件工序数据进行聚合[18],针对跨分片协同的数据聚合,可以使用聚合管道(aggregation pipeline)操作。聚合管道是基于处理流水线的概念,待处理数据进入多级管道,对其依次进行分组、过滤和变换输出格式等操作[19]。
笔者在测试环境中对多个测量节点内的7.2×105条测量数据进行聚合管道操作,以验证存储集群是否满足跨节点协同聚合需求。
存储集群多节点数据聚合代码和结果演示如图10所示。

图10 数据聚合演示Fig.10 Data aggregation demo
图10(a)为聚合管道JavaScript代码,笔者在聚合管道中执行match和group操作,对一定范围内分散在不同测量节点中的同一零件测量数据进行筛选、聚合。经过project操作重塑文档后,执行out操作将零件数据聚合结果存放到指定集合内,聚合结果可视化如图10(b)。
笔者分别对标签分片集群内1×104、3×104、5×104、7×104、1×105个零件进行聚合管道操作,在对照组中对聚合操作进行了排序优化。
测试结果如图11所示。
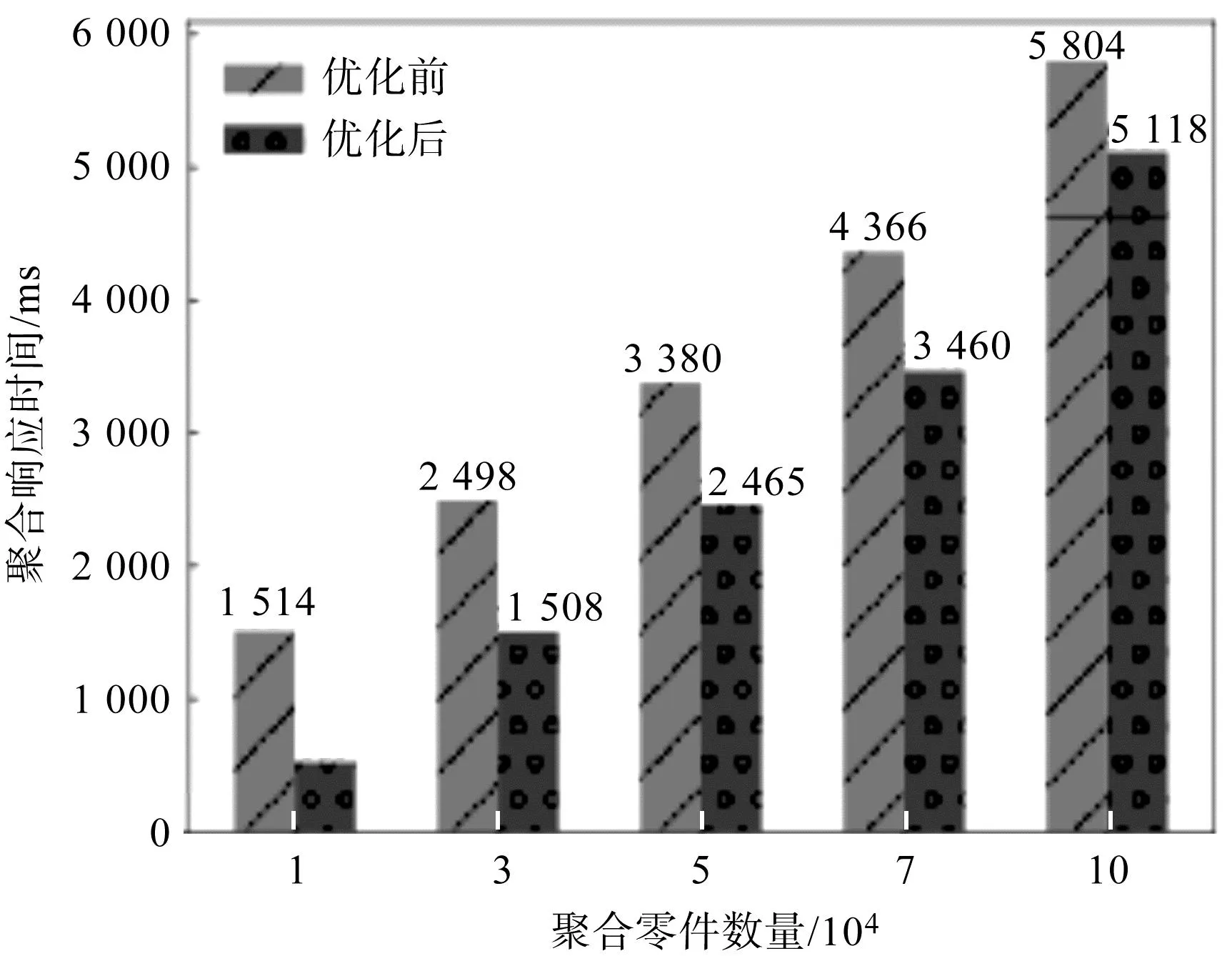
图11 零件数据聚合表现Fig.11 Parts data aggregation performance
从图11可以看出:随着聚合数量的增加,响应时间呈现上升趋势,排序优化后集群的聚合性能平均提升了32.87%;对测量节点集群中1×105个零件数据进行汇总时仅需5 s左右。
以上结果证明,基于嵌入式平台的零件在线测量存储集群拥有较好的协同聚合性能。
3.4 系统对接
该方法在某活塞制造企业测量数据与制造执行系统(manufacturing execution system,MES)对接工作中已得到成功应用,可以为MES系统提供实时的生产数据,支持企业的生产和决策过程。
笔者将仪器存储集群的路由节点Mongos与MES系统后端通过IP端口远程连接,根据数据需求使用数据库接口对路由节点内的元数据进行请求,测量信息以JSON格式返回。
存储集群测量节点数据监控功能如图12所示。
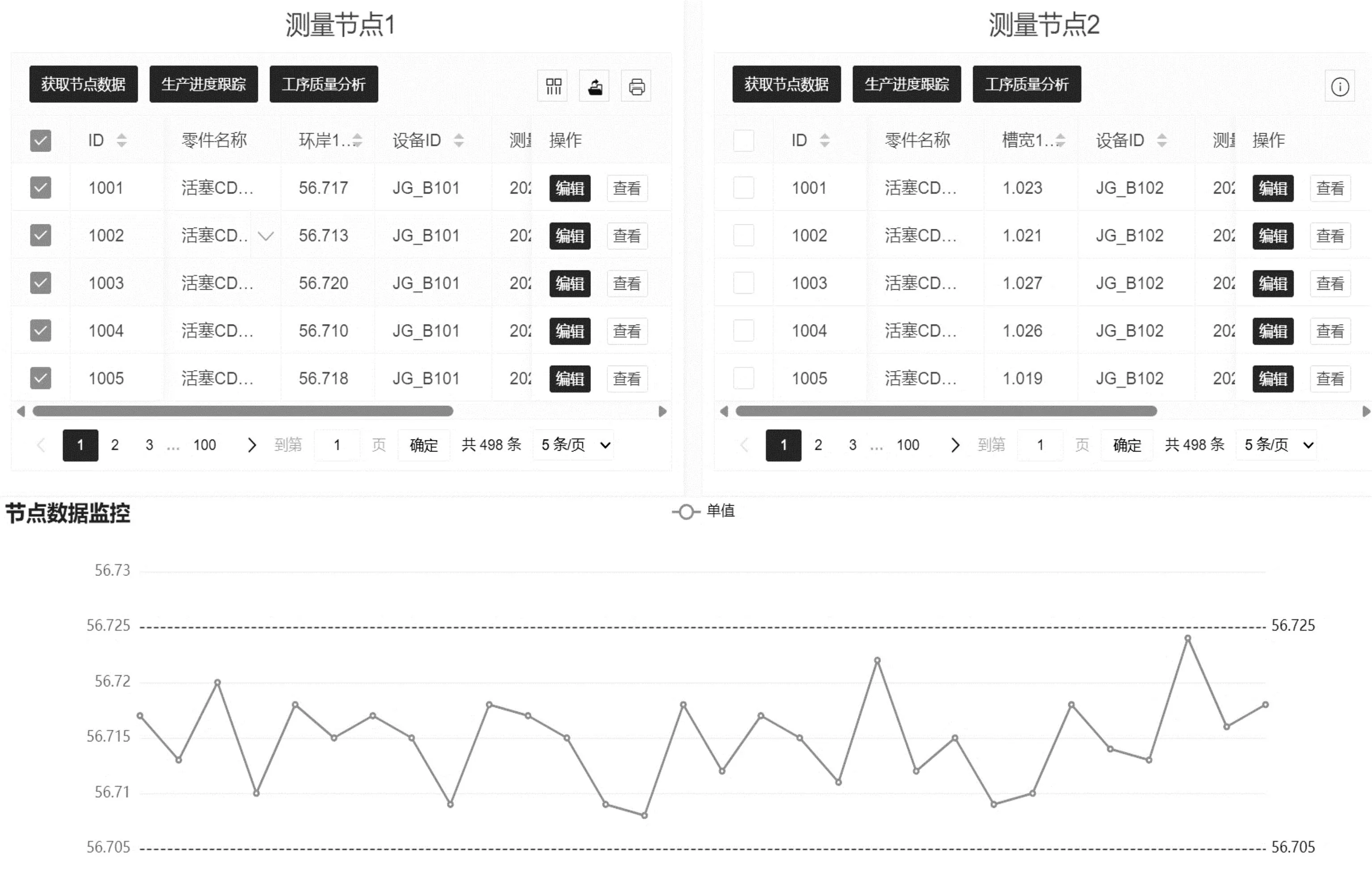
图12 测量节点数据监控Fig.12 Measurement node data monitoring
在图12演示的测量节点监控界面中可以看到:使用表3中的查询语句即可对单个或多个测量节点内的测量数据进行监测与质量分析。
零件数据聚合报表功能演示如图13所示。
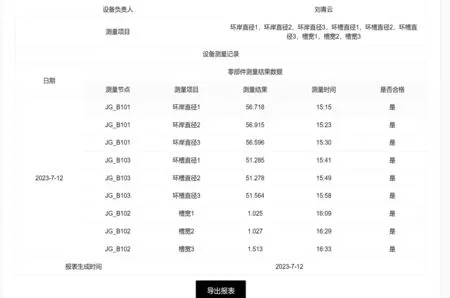
图13 零件数据聚合报表Fig.13 Parts data aggregation report
笔者根据汇总需求执行相应聚合操作,可以构建零件信息表。通过与仪器存储集群对接,企业可获得高度可扩展、灵活和实时的生产数据管理和分析能力,从而提高生产效率,增强决策支持。
4 结束语
零件测量数据的重要性在制造领域中是不可忽视的,但现有仪器数据存储方法不足以支撑多个测量仪器数据的协同测量与数据交换。
为此,笔者提出了一种基于多个嵌入式测量仪器的零件在线测量分布式存储与数据查询聚合方法;利用零件测量工序简化了存储模型,引入基于标签感知分片的数据存储布局方法,使用多个测量仪器节点对零件工序数据进行了分类存储,完成了存储集群与应用端的数据交换。
研究结论如下:
1)在计算能力有限的嵌入式系统中移植非关系型数据库,使用标签感知策略进行了数据布局,实现了存储集群的负载均衡目的,搭建的成本低且稳定性好;
2)集群中数据量达到7.2×105条时,单节点查询响应速度最快为125 ms,多节点查询响应速度为1 308 ms,聚合1×105个零件数据需要5 s左右,能够实现快速监控零件生产信息的目的;
3)研究结果为多个测量仪器测量数据的协同存储与共享提供了解决方案,具有较高的通用性。
在后续的研究中,笔者将利用集群强大的存储与共享能力,利用机器学习算法对零件测量数据进行挖掘分析,为零件制造过程提供指导。
猜你喜欢
词学(2022年1期)2022-10-27
昆钢科技(2022年2期)2022-07-08
数学物理学报(2020年5期)2020-11-26
广东通信技术(2020年10期)2020-10-26
石材(2020年4期)2020-05-25
建材发展导向(2019年10期)2019-08-24
火控雷达技术(2018年4期)2019-01-15
铁道通信信号(2018年2期)2018-04-18
电镀与环保(2016年3期)2017-01-20
工程建设与设计(2016年1期)2016-02-27
