
基于改进K-means 与机器视觉的档案数据分析技术
2024-01-24 10:10崔雨晴
电子设计工程 2024年2期
崔雨晴
(济宁市第一人民医院,山东 济宁 272000)
医院的健康管理信息平台是信息化建设的重要组成部分,也是对传统健康管理业务流程的再造[1-4]。根据国外经验,医院信息化投入通常占总收入的5%,而我国的平均水平仅约为2%。创建一套完善、周密及个性化的健康数据分析系统,其目的在于辅助建立有序、健康的生活方式,进而降低疾病风险;而一旦出现临床症状,则可通过智能化就医服务,尽快接受诊断治疗[5-9]。
基于上述应用背景,文中面向医院的健康信息管理平台设计了医疗档案的数据分析算法。该方法基于机器视觉技术(Machine Vision,MV)实现对门诊记录和检验报告等信息的提取,再使用K-means算法对提取的信息进行归类分析,从而提升健康信息管理平台的数据管理效率,并规范了相关的业务流程。
1 理论分析
1.1 聚类算法设计
该算法的应用场景为医疗信息系统相关档案的初步自动归类分析。所选择的聚类算法是适用于医疗档案这类大数据应用场景的K-means 算法[10-13]。在使用该算法前,首先,要确定医疗档案的类别数量,即k值;然后,在迭代过程中,以每个档案样本到聚类中心的距离之和最小作为最佳聚类方案。其基本步骤描述如下:
1)在n个样本中,选取k个样本{z1,z2,…,zk}作为所有样本的初始聚类中心。
2)遍历n个样本,对于第i个样本xi,得到与其距离最近的聚类中心zv,同时将该样本分配到zv对应的类别uv中。
3)根据平均法,重新分配类别中心。
4)根据式(1)计算所有样本到聚类中心的距离D:
5)判断D的收敛情况,若D不收敛,则重复步骤2);否则,返回分类结果,如式(2):
根据医疗档案信息管理系统的需求,聚类方法应准确反映不同档案样本间的内在结构,且类内的样本也需尽可能相似。由于该场景下的数据结构复杂,传统K-means 算法的分类效果受初始聚类中心的影响较大。因此,文中建立了新的指标评价体系。
记聚类空间为K={X,R},其中X是数量为n、类别为c的样本集合,R为实数集合。设样本的最小类间距为b,类内距离为w,聚类距离为baw,聚类离差距离为bsw,则第j类和第i个样本下各指标的计算方法如下:
综合式(3)-(6)的相关指标,文中在划分聚类时使用的最终指标BWP 的定义如下:
1.2 图像采集与处理
为了提升数据的采集效率,该医疗档案信息系统还引入了机器视觉的图像处理相关方法[14-16]。该方法可以自动识别患者的门诊记录、诊断报告等信息,进而实现数据的快速录入。系统视觉处理模块如图1 所示。
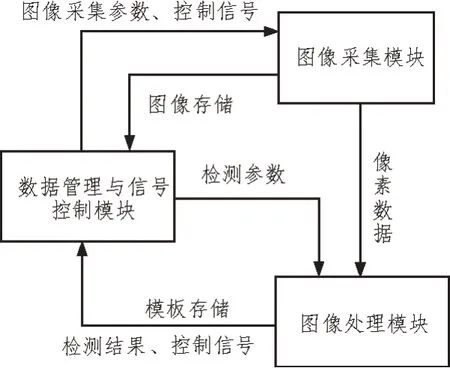
图1 系统视觉处理模块
视觉处理模块主要包括三个部分:图像采集模块、图像处理模块以及数据管理与信号控制模块。其中,图像采集模块主要对医疗信息系统中的相机、光源等设备的曝光时间、触发频率、环境亮度和照射角度等参数进行调整,以保证医疗档案采集的清晰度。图像处理模块的主要流程如图2 所示。

图2 图像处理模块的工作流程
在进行图像降噪[17-19]时,采用了邻域平均法。记f(i,j)为相机采集的含有噪声的图像,g(i,j)为降噪处理后的图像,则有:
图像配准是指将采集的图像通过平移、旋转等操作,完成几何矫正,文中采用基于邻域搜索的模板匹配法来进行配准。首先在标准模板中选取两个小区域模板T0、T1,并将二者的中心分别设为(x0,y0)和(x1,y1);记P(X,Y)为(x0,y0)与(x1,y1)连线的中心线,M(x,y)为降噪后图像的中心点坐标,则可以得到坐标间的对应关系为:
式(9)中,(x′,y′)为降噪后图像M绕原点O旋转角度θ后的坐标,并记该点为M′,其坐标计算公式为:
其中,γ为OM连线与平面直角坐标系中x轴的夹角。其计算公式如下:
最终,可以得到配准的平移量为:
图像差分是将配准后的图像进行差分,进而获得差值图。其可描述两幅图像之间的差异,从而为提取有效的患者档案信息提供基础。假设系统预置的模板图像灰度矩阵为T,配准后的图像记为S,插值图像记为E,则有:
基于插值图像,即可最终完成相关的医疗档案信息提取。
2 方法实现
2.1 实验平台设计
在使用医疗信息系统进行档案管理时,由于患者人数多、提取的信息结构复杂且获取的数据量也较大,此时若采用传统的K-means 算法进行数据处理,不仅迭代过程难以收敛,算法的相关指标也无法令人满意,因此文中仍基于机器视觉的相关理论,搭建算法仿真的GPU 并行计算平台。
GPU 是计算机上用于图像处理的微处理器,根据计算机视觉体系下的计算特点,该处理器适用于文中所述的计算密集型场景。CUDA(Compute Unified Device Architecture)是NVIDIA 公司开发的面向GPU的并行计算平台,基于该平台实现医疗信息管理系统的相关机器视觉计算任务与K-means的并行化处理。
为了满足医疗机构现有数据分析系统的接口要求,需要在CUDA 中按照Host 端、Device 端进行数据结构体设计。Host 端主要包含Data 结构体。该结构体的具体描述如表1 所示。
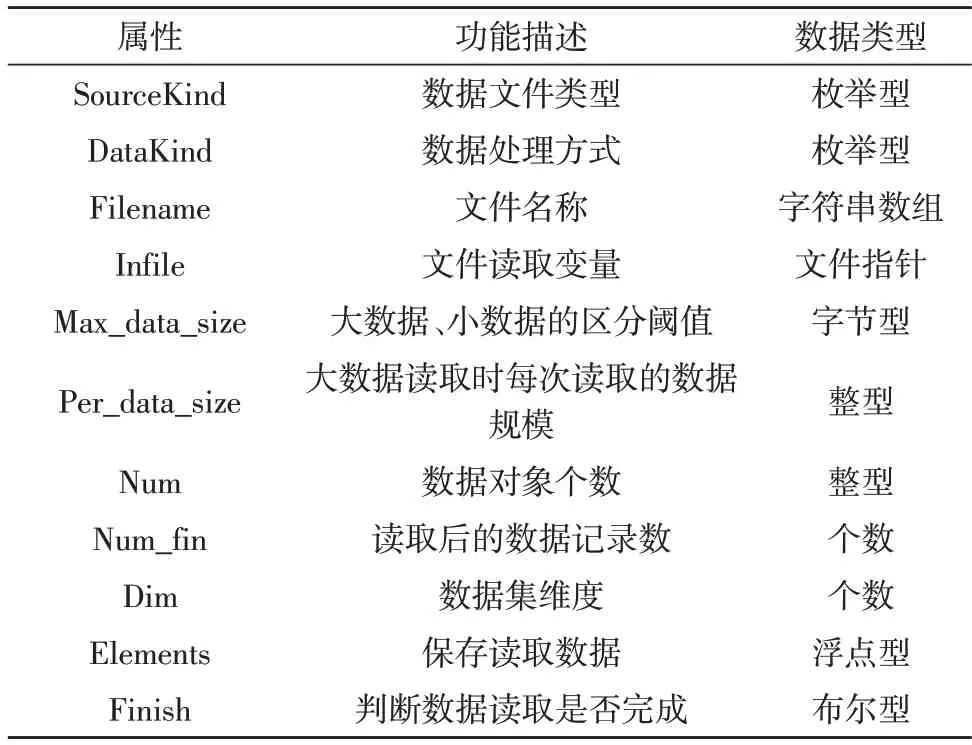
表1 Data结构体属性设计
相较于Host 端,Device 端的数据结构相对简单,所有的结构体均为一维数组。每个结构体的功能描述如表2 所示。

表2 Device端结构体属性设计
在进行K-means 算法设计时,由于不同时间、不同地点医疗信息系统采集的数据规模是不同的。因此文中对于不同的数据集规模,分别设计了不同串行、并行的K-means 算法。具体的描述如表3 所示。
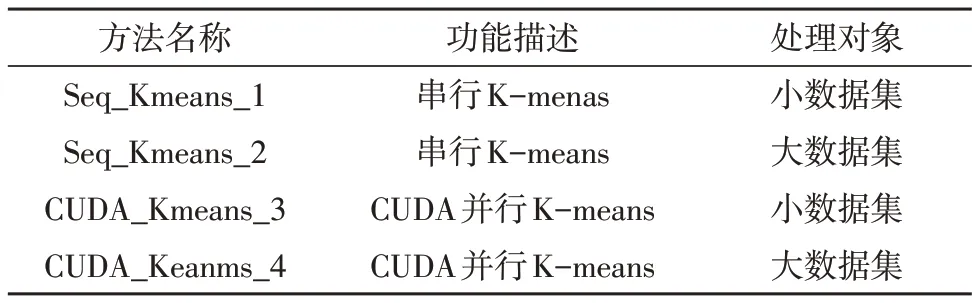
表3 系统内设计的聚类算法和处理对象
根据K-means算法的基础理论和改进的K-means算法描述,在CUDA 中设置该算法的相关参数,如表4所示。

表4 改进K-means算法的参数
文中使用的算法硬件仿真平台与CUDA 平台的相关参数,如表5-6 所示。

表5 算法仿真硬件平台

表6 CUDA的相关参数
2.2 实验测试与评估
基于上文所述的相关图像处理方法共提取了七个数据集,不同数据集的标签维度数、提取的时间如表7 所示。
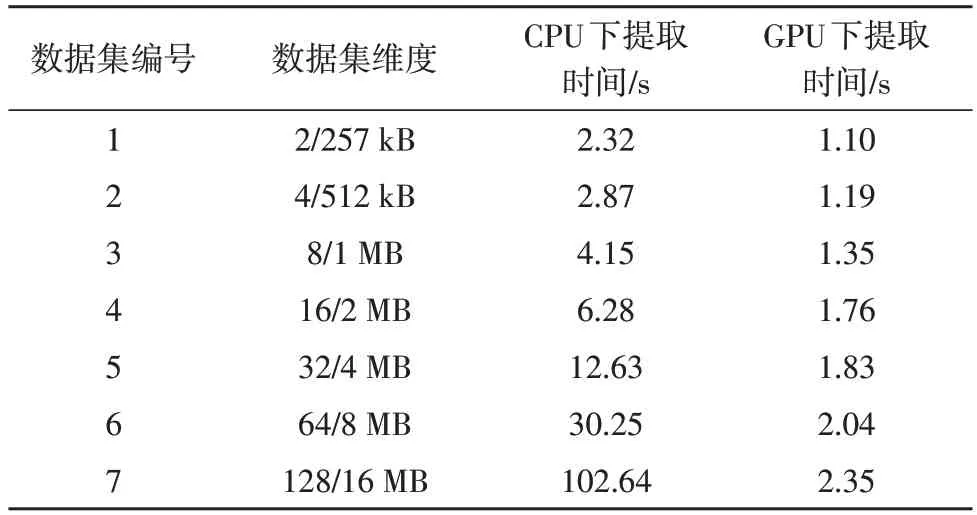
表7 数据提取结果
从表7 中可以看出,图像处理算法在GPU 上的运行速度是显著优于CPU 的。而在CPU 中,数据的提取效率会随着数据维度的提升而降低,在并行的GPU 计算模式下,提取时间的增加速度则小于CPU中的速度。
在完成数据提取后,选取编号为6 的数据集(64/8 MB)作为测试样本,并对改进后的K-means 算法在CUDA 中的运行效率进行评估。评估结果如表8 所示。

表8 不同k值下的运行时间
由表8 可知,不同的k取值会影响K-means 算法的运行效率。在CPU 中进行聚类实验时,算法的运行时间会随着k取值的变大而显著增加;而在GPU中进行计算时,运行时间随k取值的变化则并不明显。对比两个算法,当k取值为16、32 时,GPU 的运行时间分别下降了76.79%和82.49%。由此说明,Kmeans 算法越复杂,GPU 下的计算优势便愈发明显。
最后,在编号为7 的数据集上对上文所述的聚类算法BWP 评价指标体系进行了评估。经前期标注,已探明该数据集的最佳分类数k为16。在测试时,使用现在常用的CH、DB、KL 等聚类评价指标体系作为对比。测试对比结果如表9 所示。

表9 不同指标体系下的聚类效果
从表9 可以看出,CH、DB 算法无法在具有多个类别时正确识别样本的类别数量。而KL 与所提BWP 指标均能帮助K-means 算法正确识别出样本的类别数,但后者正确聚类的样本占比提升了4.88%。
3 结束语
文中面向医疗信息管理系统设计了一套基于机器视觉的档案信息提取算法,并引入改进的Kmeans 算法对提取的档案信息进行了聚类分析。在实现相关算法时,文中还使用了基于GPU 的CUDA计算平台,提升了算法的计算效率。未来,随着医疗信息化程度的不断提升,所提数据分析方法将有更广泛的应用。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
制造技术与机床(2018年12期)2018-12-23
电子制作(2018年18期)2018-11-14
知识经济·中国直销(2018年8期)2018-08-23
电子测试(2017年15期)2017-12-18
雷达学报(2017年6期)2017-03-26
数学学习与研究(2017年3期)2017-03-09
电气化铁道(2016年4期)2016-04-16
中国老区建设(2016年1期)2016-02-28
电子设计工程(2015年6期)2015-02-27
