
基于并行计算的网络舆情数据分析方法研究
2024-01-24 10:10韦芬
电子设计工程 2024年2期
韦芬
(西安航空职业技术学院,陕西西安 710089)
随着媒体技术与传播形式的不断演变,目前已进入了数字化信息时代。数字化媒体基于互联网及移动通信技术,向互联网用户提供各种数字化形式的信息。当前数字化媒体的种类繁多,例如信息流媒体、网络社区、微博与门户网站等,这类媒体可便于用户交流意见和发表观点,但也会引发舆情危机,导致谣言或不实信息病毒式蔓延。因此,进行快速、精准的网络舆情数据分析及预警已成为当前学校思政管理与网络信息监控部门的首要任务[1-3]。
分析网络舆情数据的思路是将文本信息送入服务器后台,由算法或人工对信息进行判断。其中,由于人工审核速度慢且成本高,所以无法满足用户在实时信息流平台中进行交流的需求;而传统算法虽然审核速度快,但普通服务器有时难以承载当前海量的信息流数据,因此会出现宕机、服务器卡顿等现象。然而随着大数据及云服务器技术的发展,海量数据的采集、存储与分析也成为可能。因此,该文使用并行计算手段,依托于并行云服务器构建网络舆情数据分析平台,进而建立完善的舆情预警及引导机制。
1 基于并行计算的网络舆情分析
1.1 Hadoop平台
Hadoop 平台[4-7]是由Google 公司设计、基于Java语言开发的分布式数据处理架构。其兼容性较强,且拥有良好的跨平台属性,使用者无需了解分布式计算架构即可调用API 接口实现数据的分布式存储与管理。Hadoop 平台架构如图1 所示。

图1 Hadoop平台架构
Hadoop 架构主要由管理层节点与任务层节点组成。该平台主要包含两大核心模块,分别为负责文件存储的HDFS(Hadoop Distribute File System)及负责数据并行计算的MapReduce。
1)HDFS 分布式文件系统
HDFS 是一种分布式文件存储系统,该系统支持大吞吐量的数据交换及超大型文件的存储。其成本较低、容错率高,且支持数据回滚,故可有效保证数据存储的安全性。
HDFS 架构通常使用主从机体系结构,由一个NameNode 和多个DataNode 混合节点组成,如图2 所示。其中,NameNode 节点负责主机管理的任务,其可管理文件命名空间,同时也能受理从节点的管理请求。而DataNode 节点则为从机存储节点,该节点可将文件加以存储,并与NameNode 节点进行交互。

图2 HDFS架构
2)MapReduce 编程模型
MapReduce 是一种分布式的编程模型,该模型可对海量数据进行并行处理,且其容灾率较高。MapReduce 解决分布式问题的思路是将大型的计算任务小型化、分解化,并将分解后的子问题进行集中计算。此外,该算法主要依靠Map 与Reduce 函数来实现。
对于输入系统的大型数据而言,MapReduce 会将数据分解成若干个小数据块,并形成多个键值文件。同时,将其输入至Map 子函数中,该函数便会对键值数据进行过程处理与排序,形成的中间值能够缓存至HDFS 系统中,然后再不断送入Reduce 函数中进行处理,最终便可得到处理结果。MapReduce架构如图3 所示。

图3 MapReduce架构
1.2 舆情数据文本处理算法
舆情数据的特点即情绪化和主观化,因此该数据包含的文本信息通常存在较大的关联。分析舆情数据的第一步是对该数据进行分类,该文使用卷积神经网络(Convolutional Neural Networks,CNN)对数据进行训练,并得到分类结果。
CNN[8-11]是自然语言处理领域中常见的算法之一,该算法首先应用于图像处理领域。而在国外学者发现其可对文本数据进行有效分析后,便被应用至自然语言处理领域。CNN 算法由输入层、卷积层、池化层及全连接层几个部分组成,如图4 所示。

图4 CNN结构
输入层:当使用CNN 模型处理文本数据时,首先需要将输入数据转换成为词向量,再将词向量转化为二维矩阵。输入层的输入过程如下:
式中,xinput为文本输入,w表示文本中的词向量,youtput1表示该层的输出结果。
卷积层:该层为CNN 中的数据处理结构,其主要是对词向量进行卷积计算,进而完成词向量特征的抓取。卷积的计算过程为:
式中,Mi为数据源,youtput1和youtput2分别为卷积层的输入与输出数据,kij为卷积窗口,bj为卷积层的偏置量,f则为卷积层的激活函数。
池化层:该层对卷积层数据进行下采样,主要是对输入数据进行采样,再对输出特征值进行削减,进而增强网络的特征判断能力。池化过程可表征为:
式中,Pooling()为池化算法,youtput2和youtput3为池化层的输入及输出数据,f为池化层的激活函数。
虽然CNN 模型具备的结构可对文本特征进行提取,但该结构无法获取上下文数据的含义。因此为了增强其数据处理能力,该文将CNN 模型与BiLSTM(Bi-directional Long Short-Term Memory)模型结合,使其具备双向性,便可提取文本全局特征,从而提高分类的准确性。
BiLSTM 也被称为双向长短时神经网络[12-13],该网络能进行双向学习,进而得到文本的前后含义,其网络结构如图5 所示。基于CNN 与BiLSTM 的网络结构如图6 所示。

图5 BiLSTM网络结构
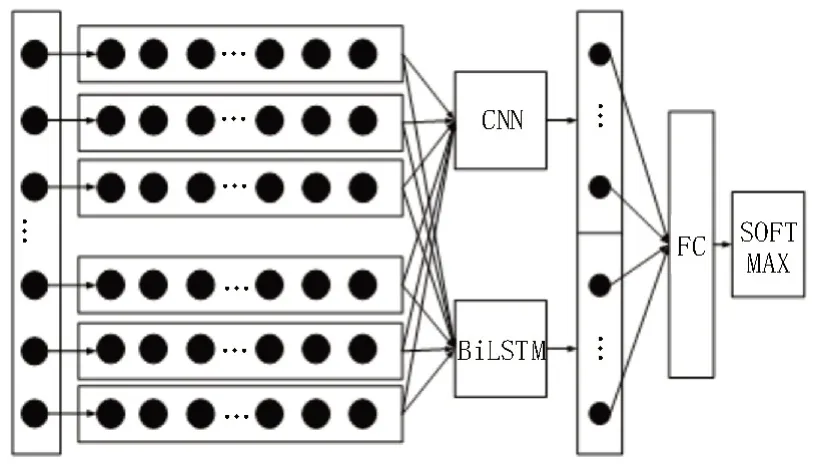
图6 CNN-BiLSTM网络结构
由图6 可知,模型首先对输入的文本数据进行分层,将词向量转换为矩阵;之后再使用CNNBiLSTM 算法进行分类,即采用CNN 提取局部优势,利用BiLSTM 获取文本全局特征;最终便可对特征加以合并,进而输出结果。
1.3 基于Hadoop的网络并行化计算
卷积神经网络与BP 神经网络的求解方式相似,也是串行的计算过程。该计算过程由三个步骤组成,分别为数据前向传递、更新权重后的后序传递及网络权重值参数的调整。该文使用累计BP 算法[14]进行数据的并行训练。数据训练的并行计算过程如图7 所示。

图7 并行计算过程
总体程序的主要执行流程为:
1)数据经过打包,形成DataSet 样本数据包文件,同时从CNN-BiLSTM 为卷积神经网络模型接收数据[15-16]。
2)数据预处理,首先将DataSet 样本存入HDFS并行存储结构,同时将原始的CNN-BiLSTM 模型存入HDFS。
3)进入MapReduce 进行处理,且分多轮进行,Map 算子的输入和输出均为键值,输入键为文本的偏移量,输入值为文本的实际内容。输出键则为占位符,输出值为迭代后的CNN-BiLSTM 模型值。通过该算法程序,可大幅提升数据处理时的速度。
2 仿真测试
2.1 实验环境
实验在PC 机平台进行,使用四台服务器搭建了具有四个节点的Hadoop 架构,其中一台服务器为主节点,其余三台则为从节点。服务器的具体配置如表1 所示。
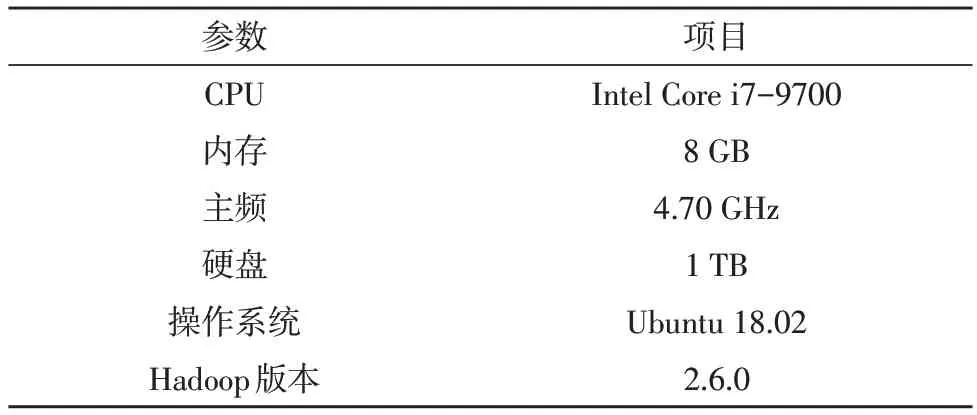
表1 实验软硬件环境配置
2.2 数据集
数据集选择清华大学的中文新闻数据集合THUCnews。该数据集包括财经、游戏、房产、生活等10个类别的新闻数据,且在每个类别中选择10 000条文本,并按照3∶1 的比例将数据划分为训练集与测试集。
2.3 分类性能测试
文中对算法的分类性能进行测试,分类所使用的指标为准确率、召回率及F1 值。对比算法选择CNN、BiLSTM、SVM,所有算法对同样的数据样本进行训练,之后在测试集中进行验证。测试结果如表2所示。

表2 测试结果
由表2 可知,各个算法在体育、政治、教育、游戏类目的新闻均能实现文本分类。但该文使用CNNBiLSTM 算法,在分类的同时加入了提升上下文含义的训练。故在分类结果中,该文算法的准确率、召回率与F1 值在对比算法中均为最优,充分证明了该文算法的性能优势。
2.4 并行计算测试
此外,该文将算法部署在Hadoop 并行计算集群中,为验证Hadoop 集群对算法计算时间和速度的影响,分别将算法布置在单机,双机及四机平台中,以算法开始运行至迭代完成所耗费的时间为指标,计算结果如表3 所示。

表3 并行计算效果测试
从表3 中可以看出,当数据量为1 000 条时,单机与集群的训练时间大致相当,这是因为训练数量较少时,集群计算的优势发挥并不突出;当数据量增至5 000 条时,双机与四机的集群优势逐渐显现;而当数据量增加至10 000 条时,四机优势较为明显,这说明在计算量较大时,并行计算集群能够显著提升数据训练速度。
3 结束语
该文研究了一种基于并行计算的网络舆情数据分析方法。针对传统舆情数据处理系统分析速度慢,准确率较低的问题,设计了一套网络舆情数据分析系统。该系统分为并行计算系统及文本分类算法。文本分类算法将CNN 网络与BiLSTM 网络相结合,使算法具备更强的分类能力。而并行计算系统使用Hadoop 集群,有效提升了舆情数据的训练速度。系统的整体综合性能较好,部署在并行集群中有效地提升了运行速度。
猜你喜欢
成都信息工程大学学报(2022年4期)2022-11-18
北京航空航天大学学报(2021年9期)2021-11-02
汽车工程(2021年12期)2021-03-08
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
电信科学(2017年6期)2017-07-01
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
中国民政(2016年24期)2016-02-11
电测与仪表(2015年22期)2015-04-09
