
采用多尺度视觉注意力分割腹部CT和心脏MR图像
2024-01-22 10:27:38蒋婷李晓宁
中国图象图形学报 2024年1期
蒋婷,李晓宁
1.四川师范大学计算机科学学院,成都 610101;2.吉利学院智能科技学院,成都 641423;3.可视化计算与虚拟现实四川省重点实验室,成都 610066
0 概述
在计算机辅助诊断和治疗中,医学图像准确而快速的语义分割起着至关重要的作用。例如在放射性治疗中,精准勾画病变区域可以帮助射线精确照射癌变组织,同时减少对健康组织的伤害(郑光远等,2018)。在临床实践中,自动化的器官肿瘤分割,使得医生摆脱费时费力的枯燥工作,从而提高诊断和治疗的效率(Litjens 等,2017)。迄今为止,各种各样的分割方法已经广泛应用于各种器官和组织的语义分割,例如脑部肿瘤(Feng 等,2020)、肝脏(Li 等,2018)、肺部(Gaál等,2020)等。然而,目前医学图像分割任务仍然面临着数据集稀缺、标签不足以及分割效果不佳等问题。
深度学习的快速发展引起了诸多研究者对基于神经网络的方法的热切关注。其中,Ronneberger 等人(2015)提出了一种名为U-Net 的方法,这是一种以全卷积网络为基础的方法,采用对称的编码器—解码器结构,融合来自高分辨率到低分辨率的特征,能够很好地提取医学图像的语义信息。Chen 等人(2018)提出了DeepLab,该网络使用深度卷积网络、空洞卷积和全连接网络进行语义分割,空洞卷积用于密集特征提取和增大感受野,有效改善了卷积的感受野小导致图像提取信息少的问题。随后,一系列以U-Net 为基础的变种网络(殷晓航 等,2021)相继提出,如UNet++(Zhou 等,2018)整合了不同深度的U-Net,VNet(Milletari 等,2016)探索了3D 医学图像的分割,nnU-Net(no new U-Net)采用极简模型取得了优异的分割结果(Isensee 等,2021),UNet3+在UNet++的基础上使用全尺寸的跳跃连接(Huang等,2020)等。
卷积神经网络(convolution neural network,CNN)在计算机视觉(computer vision,CV)领域具有广泛的应用,是因为其具有低计算量、平移缩放不变性等特点。然而,卷积运算固有的感受野小,难以捕获长远距离的信息,因此,这类方法有着不可避免的缺点。与CNN 不同,基于自注意力(self-attention,SA)机制的Transformer(Vaswani 等,2023)能够有效地建模全局特征,并且具有很好的泛化能力。在多个图像领域(如图像识别、图像配准、图像分割等)都取得了先进的性能(Chen 等,2021a;Dosovitskiy 等,2021;Zheng 等,2021),但它们具有高计算量且忽视图像内部重要二维结构的缺点,使得在CV领域直接使用Transformer 不能充分发挥它的潜能。视觉Transformer(vision Transformer,ViT)(Dosovitskiy 等,2021)被提出用于图像处理,引发了将Transformer应用于图像领域的研究热潮。迄今为止,众多结合Transformer 的医学图像分割网络已经相继提出。Chen 等人(2021b)提出TransUNet,它结合CNN 和Transformer 作为U 型结构的编码器,通过Transformer 对全局的强大建模能力,获取图像上下文特征;在解码阶段,TransUNet 采用级联上采样(cascaded up-sampling,CUP)来恢复至输入分辨率,最后通过跳跃连接来融合不同分辨率的图像,以弥补上采样时信息的缺失。然而,TransUNet 只是在CNN中简单插入Transformer 结构,没有充分发挥Transformer 的优势。Cao 等人(2021)在Swin Transformer(Liu 等,2021b)的基础上提出了Swin-UNet,采用移动视窗的方式大幅度减少计算量。然而,使用线性投影(linear projection)的自注意力机制,将图像视为一维序列,被证明在处理图像时存在欠考虑的情况(Wu等,2021)。
如今,已有结合CNN 和Transformer 的研究(Cao 等,2021;Chen 等,2021a;Chen 等,2021b)被用于医学图像处理领域,然而,这些方法都忽略了图像固有的维度信息,而将图像特征简单地视为自然语言处理(natural language processing,NLP)的1D token;其次,这些基于自注意力机制的模型,所具有的二次计算复杂度对处理高分辨率的医学图像来说太过昂贵;最后,ViT 使用固定长度线性向量方式实现的位置编码限制了对可变分辨率图像的支持。
虽然已经有研究提出了构建长距离依赖的大核卷积(Hu 等,2019;Park 等,2018),但直到最近才将其集成到Transformer 中。Guo 等人(2022b)提出名为VAN(visual attention network)的一种基于视觉注意力机制的网络,将可分解的大核卷积融入注意力机制,从而实现在图像分割和图像分类任务中的先进性能。随后,Guo 等人(2022b)更进一步地将多个视觉注意力联合起来,类似多头注意力,以在不同尺度捕捉图像语义特征,从而实现在语义分割任务中最先进的性能。此外,Ding 等人(2022)提出Rep-KLNet(re-parameterization large kernel network),使用卷积核大小为31 的大卷积去替换多头自注意力(multi-head self-attention,MHSA)机制,从而能够大幅扩大感受野并显著提升性能。Trockman 和Kolter(2022)提出ConvMixer,通过将Transformer 中基本模块替换为深度方向卷积,显示了基于卷积注意力的强大能力。
为了克服上述挑战及困难,已有部分模型采用了大核卷积作为视觉注意力机制,用以捕获图像长远距离的上下文特征(Hu等,2019;Park等,2018;Ding等,2022)。这些模型通过使用较大的卷积核来捕捉长远距离特征,并且具备低计算成本的优势。除此之外,它们在自然图像分割和分类方面也表现出色(Guo等,2022a,b)。与先前的研究不同,本文则尝试探索将视觉注意力应用于医学图像分割中的可能性。
本文借鉴了TransUNet 和视觉注意力机制(Guo等,2022a,b)的思想,提出一种基于多尺度的视觉注意力网络。该网络在补丁嵌入部分使用重叠的卷积运算,即卷积型补丁嵌入(convolutional patch embedding)(Wu 等,2021),直接向Transformer 输 入2D token,而不是将其展平为1D token,保留了图像原本的二维结构。在注意力机制中,采用以大核卷积为主的视觉注意力,减少计算量的同时兼顾长远距离依赖和局部信息交互(Li 等,2021;Guo 等,2022b)。此外,类似多头注意力机制,本文也采用相似的方式去集成视觉注意力。实验结果表明,本文网络能够得到更精准的分割效果,在性能比较上,取得明显优势。
1 方 法
1.1 网络概述
本文网络结构如图1 所示,采用U 型网络结构,由编码器、解码器和跳跃连接3 部分组成。编码器由1 个卷积干、3 个补丁嵌入和4 组重复多次(重复次数分别为2、2、4、2)的Transformer 模块组成;解码器由4 个卷积上采样组成。在编码阶段,网络对图像进行下采样,每经过1 个补丁嵌入层,图像分辨率减半,通道数递增;在解码阶段,网络对图像进行上采样,每经过1个补丁嵌入层,图像分辨率不变,通道数随之递减。之后,编码阶段和解码阶段的图像特征通过跳跃连接进行融合,以弥补上采样过程中信息的缺失,进而对图像语义进行精确分割。最后,通过一个分割头,输出最后的分割结果,即预测标签。具体而言,整个过程可以描述为:输入原始图像x∈RH×W×C,经过编码器和解码器,最后输出预测结果x∈RW×H×classes。其中,W和H分别表示图像的宽度和高度,classes表示预测器官类别数。
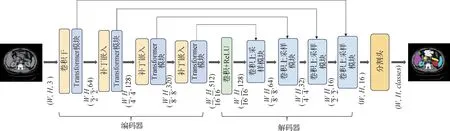
图1 本文所提网络构架Fig.1 The proposed network architecture
1.2 卷积干
在前期视觉处理中,Xiao 等人(2021)提出了卷积干(convolutional stem)的概念,旨在增强Transformer 的稳定性。Chen 等人(2022)也发现首层补丁嵌入的缺陷,他们通过冻结补丁嵌入层参数,解决训练时不稳定的问题。卷积干的结构如图2 所示,包含一个步长为2、卷积核为3 × 3 的卷积运算;一个步长为1、卷积核为3 × 3 的卷积运算;两个归一化层和GELU(Gaussian error linear unit)激活函数。
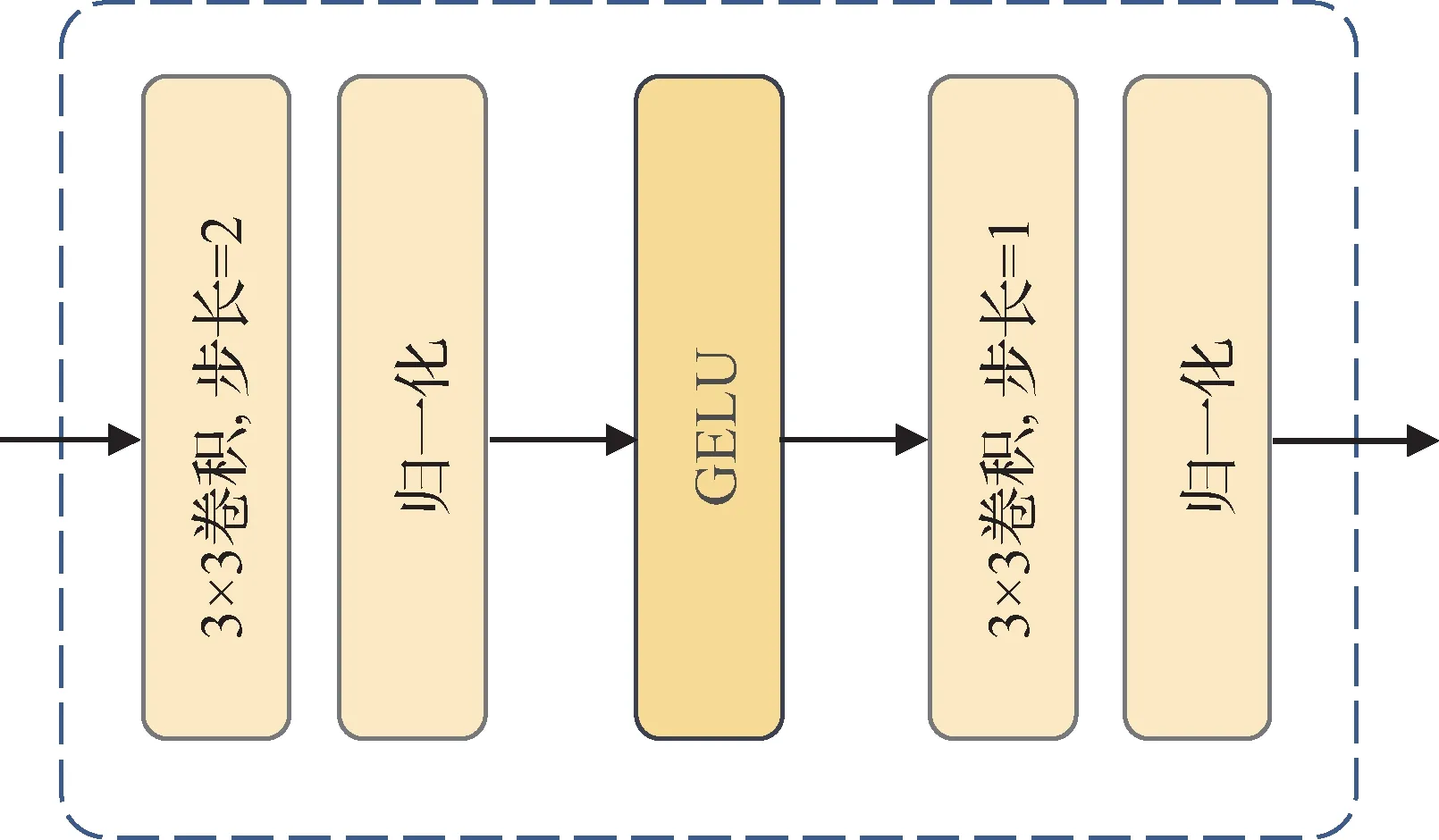
图2 卷积干Fig.2 Convolutional stem
传统上,Transformer 首先采用补丁嵌入对图像早期处理。但如Xiao 等人(2021)所述,首个补丁嵌入是将超低通道数(通常是3)的原始图像转换为较高通道数图像,其实施的大卷积核和大步长与CNN的典型结构背道而驰,这一定程度上导致Transformer 对超参数设置敏感,难以优化。相对而言,其余补丁嵌入层的卷积核和步长较小。因此,本文首个Transformer 模块采用卷积干,其余Transformer 模块仍然保留补丁嵌入。
1.3 Transformer模块
Transformer 模块包括归一化层、视觉注意力层以及多层感知机(multi-layer perceptron,MLP)层,并通过两次残差连接的方式连接,如图3 所示。连续的Transformer模块可以表示为
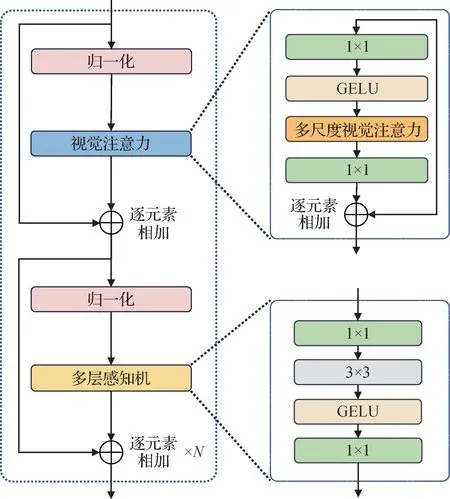
图3 Transformer模块Fig.3 Transformer block
1.3.1 多尺度视觉注意力
本文采用多尺度卷积(multi scale convolution,MSC)作为视觉注意力来捕获全局上下文信息。其主要由3 部分组成:一个5 × 5 的深度方向的卷积(depth wise convolution,DW-C)来捕获局部信息;一组深度方向条状卷积来捕获多尺度上下文信息;一个1 × 1的点方向的卷积用来整合不同通道之间的特征,最后再采用残差连接的方式连接起来,如图4所示。
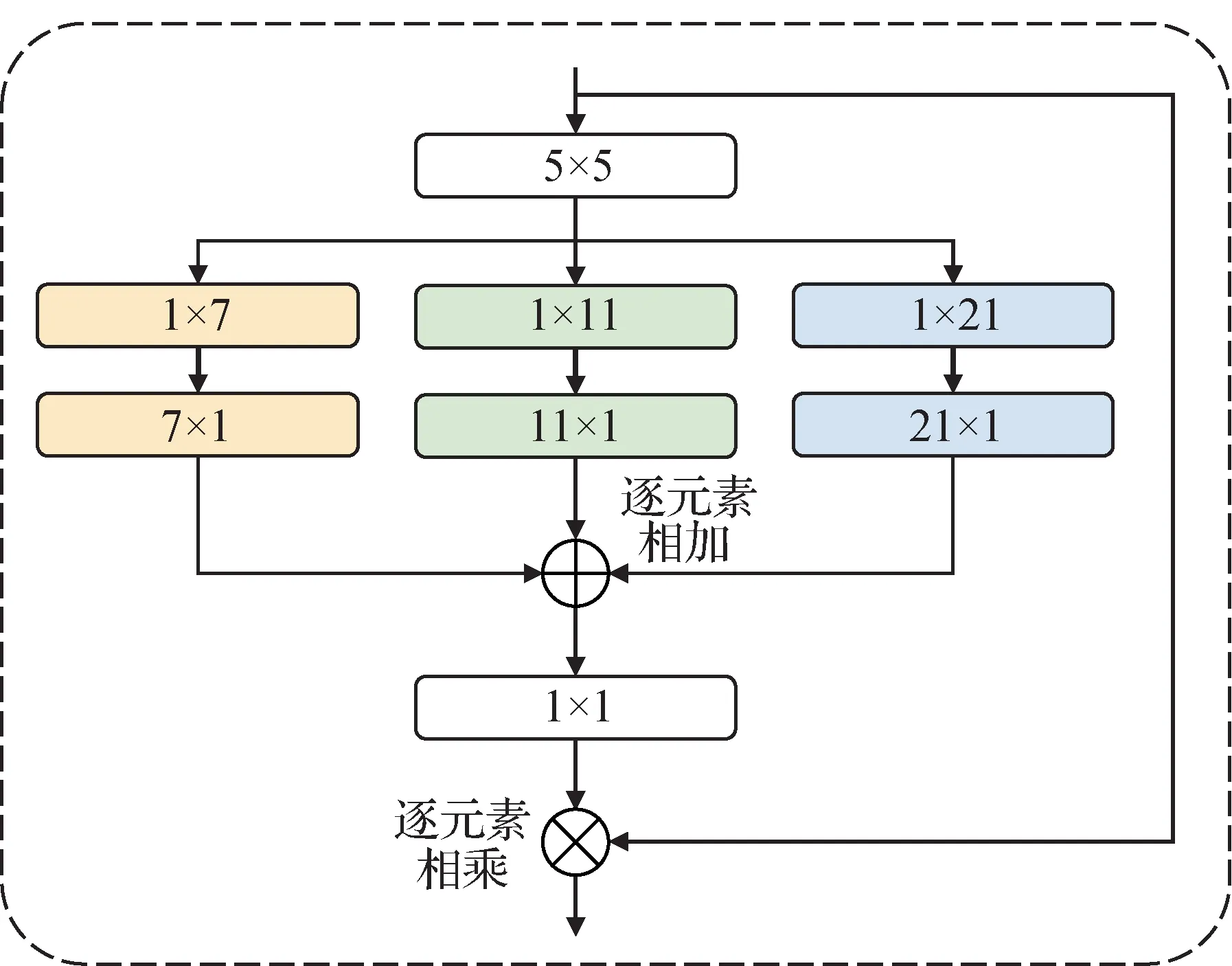
图4 多尺度视觉注意力Fig.4 Multi scale vision attention
为了弥补条状卷积在捕捉特征时的不足,本文使用多尺度分支结构,并且使用k× 1 和1 ×k的条状卷积近似于一个k×k的大核卷积。其中多条分支分别采用1 × 7 和7 × 1 的条状卷积对,1 × 11 和11 × 1 的条状卷积对以及1 × 21 和21 × 1 的条状卷积对。条状卷积属于轻量级卷积,可以减少计算开销。多尺度注意力可以表示为
式中,fAtt和fOut分别表示多分支条状卷积对的输出和多尺度注意力的输出,F表示输入的特征,DW-C(·)表示深度方向卷积,表示多尺度注意力,C1×1(·)表示点方向卷积,⊗表示逐元素相乘。
1.3.2 多层感知机
多层感知机作为流行的结构,在Transformer 和CNN 中广泛使用。已有研究(Liu 等,2021a;Tolstikhin 等,2021)对多层感知机进行优化,使其更加适配CV 任务。如图3 所示,本文采用类似Liu 等人(2021a)的多层感知机结构。多层感知机的输入和输出均为2D tokens,其组成结构包含两个点方向卷积、GELU 激活函数和卷积核为3 × 3、填充为1、步长为1 的深度方向卷积。其中,点方向卷积类似于ViT 中全连接层,而额外的深度方向卷积用于捕捉图像局部特征。多层感知机可描述为
式中,F表示输入特征,PW-C(·)表示点方向卷积。
1.4 补丁嵌入
ViT 中补丁嵌入机制将图像划分成多个具有位置编码的线性tokens 序列,但以这样实现的方式,存在两个缺陷。1)没有考虑相邻切片存在的局部关联;2)位置编码极大限制了对可变分辨率图像的输入。受Chu等人(2023)和Wu等人(2021)的启发,本文采用一种卷积型补丁嵌入,将图像划分为多个重叠的2D 切片,保证获取图像长距离依赖的同时,增强切片之间的局部联系。由于这类卷积操作隐含切片宝贵的位置信息,因此,位置编码可以从架构中安全地移去,增强模型对输入可变分辨率图像的适配性。
形式上,该操作定义为给定输入x∈RH×W×C,执行一个步长为O、填充为P、卷积核大小为S的卷积运算,输出的尺寸为
得到输出x′∈RH′×W′×C′后,再进行归一化。适当地设置步长大小(分别是4、2、2)有助于划分图像时在一定程度上重叠,从而对局部上下文进行建模。
1.5 卷积上采样模块
如图5所示,本文采用两个步长为1且卷积核为3 × 3 的卷积、两个归一化操作、两个ReLU(linear rectification)激活函数和一个上采样所组成,并与来自编码器的特征进行拼接。来自编码器的图像特征和解码器的图像特征以上述方式能够融合在一起,减少在图像级联上采样过程中,图像信息的丢失,保证恢复到原始分辨率图像的精准度。
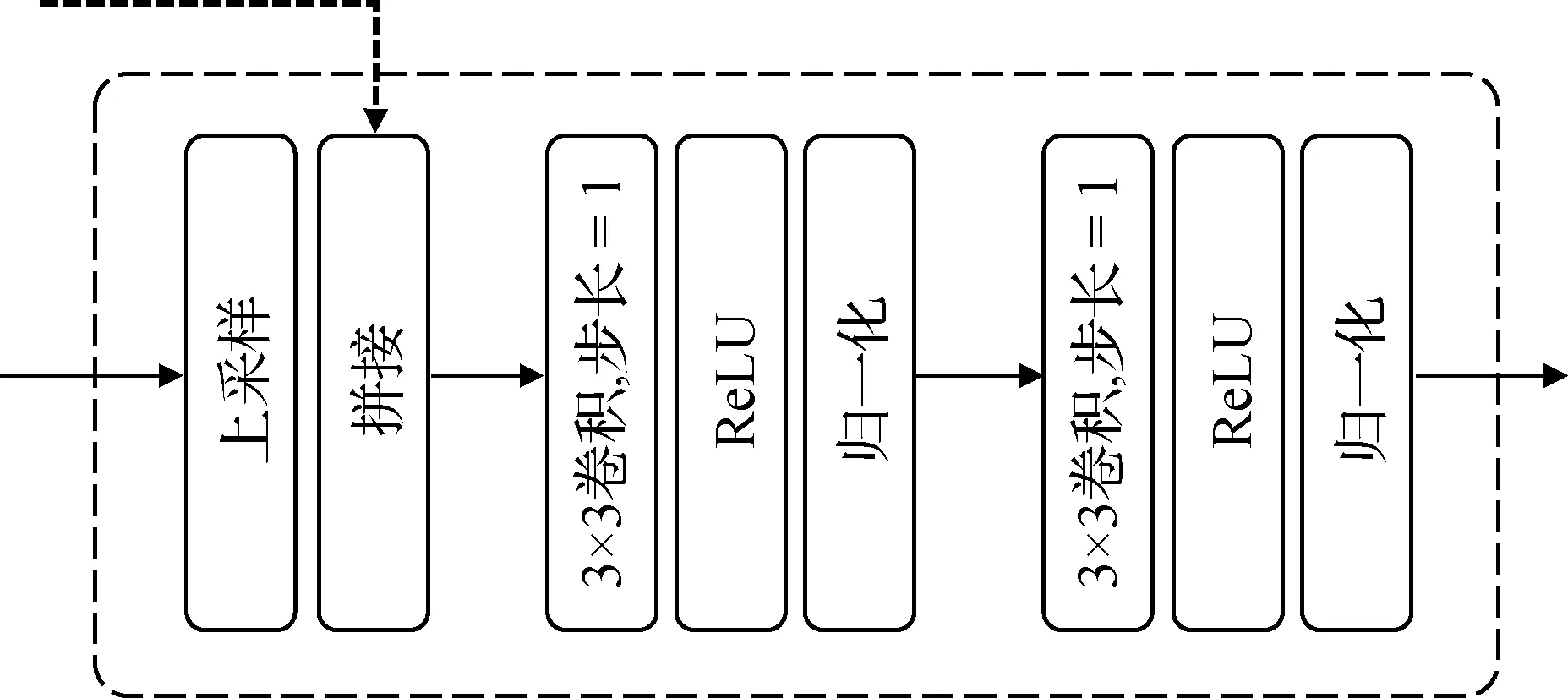
图5 卷积上采样模块Fig.5 Convolutional upsampling block
1.6 损失函数
本文采用交叉熵损失函数(cross entropy loss function)和Dice 损失函数(Dice loss function)来衡量真值标签和预测标签之间的误差。
交叉熵损失函数用来评估分割过程中对每个像素点的分类预测,度量两个概率分布间的差异信息,其值越小,表明网络的预测效果越好。具体为
式中,C为标签,yi指是否为类别i,若为该类别yi=1,否则yi=0;pi是指样本i属于类别C的概率。
Dice损失函数用于预测分类图像和真实标签之间的差异,是由1减去Dice 相似性系数所得,取值范围为[0,1]。具体为
式中,|X∩Y|表示真实图像与预测图像的交集,|X|和|Y|分别表示各自的元素个数。
网络的总损失函数为两者相加。具体为
2 实 验
2.1 实验数据集与评估方法
本文使用Synapse 多器官分割数据集(synapse multi-organ segmentation dataset,Synapse)(https:// www.synapse.org/#!Synapse:syn3193805/wiki/)、自动心脏诊断挑战数据集(automated cardiac diagnosis challenge dataset,ACDC)(https://www.creatis.insa-lyon.fr/Challenge/acdc/)以及四川大学华西医院心内科提供的心脏分割的数据(Department of Cardiology,West China Hospital,Sichuan University,DCWC)(Zheng 等,2022)。其中,DCWC 使用训练在ACDC的模型直接测试。Synapse 包含30 组腹部增强CT(computed tomography)扫描图像,每组由85~198 个大小为512 × 512 像素的切片组成,原始体素分辨率 在0.54 mm × 0.54 mm × 2.5 mm 到0.98 mm ×0.98 mm × 5.0 mm 范围内。Synapse 包含腹部8 个主要器官:主动脉(aorta)、胆囊(gallbladder)、左肾(left kidney)、右肾(right kidney)、肝脏(liver)、胰腺(pancreas)、脾脏(spleen)、胃(stomach),以及各器官对应的标签。该数据集划分为包含18 组病人的训练集和12 组病人的测试集。ACDC 包含100 组病人的心脏磁共振成像(magnetic resonance imaging,MRI)图像。每组MRI 图像均由医学专家标注了心脏的3 个组织:左心室(left ventricle,LV)、右心室(right ventricle,RV)和心肌(myocardium,Myo)。该数据集随机分为70 组用于训练、20 组用于测试、10 组用于验证。DCWC 是由25 个患者的心脏MRI图像组成的数据集,本文不进行训练,直接用于测试不同模型的性能。这3 个数据集均在输入网络前,被重采样至分辨率224 × 224像素。
本文采用两个常用的分割评价指标:Dice 相似性系数(Dice similarity coefficient,DSC)和Hausdorff 距离(Hausdorff distance,HD )。DSC 很好地描绘了预测结果和标签之间的重叠程度,越接近1,表明预测精度越高;HD则用于描述预测结果和标签之间的边界距离情况,越接近0,表明性能越好。这两个评价指标从预测值与标签的内部填充程度、外部边界情况两个方面定性定量地分析了性能。
2.2 实验设置细节
本文实验均于Python 3.6,PyTorch 1.7.1,CUDA 11.4 的实验环境上运行。为了公平起见,所有网络的学习率设置为0.01,采用随机梯度下降法(stochastic gradient descent,SGD)优化器进行训练,动量设置为0.000 1,默认批量大小为24,每次实验迭代150轮。采用交叉熵损失函数和Dice 损失函数的超参数均设置为0.5。所有实验均在32 G 的Nvidia Tesla V100上完成。
2.3 实验结果
2.3.1 在Synapse数据集的实验结果
本文将所提方法与较先进的方法在Synapse 数据集的分割结果进行对比,实验结果如表1 所示。本文方法的平均DSC 为80.36%,超过了Swin-UNet。尤其对于胰腺和胃,其分割性能较TransUNet有较大提升,分别提升了11.36%和11.25%。与基线模型TransUNet 相比,有6 个器官的分割精度都有所提高。表1 列出了不同方法所需的参数量,UNet 由于其简单的网络结构所需参数量最少,而相比于本文的基线模型,本文方法的参数量是TransUNet 的1/6.88。其在Synapse 的可视化结果如图6 所示,并用深红色圆圈对图中部分图像错分割或未分割的区域进行了标注。
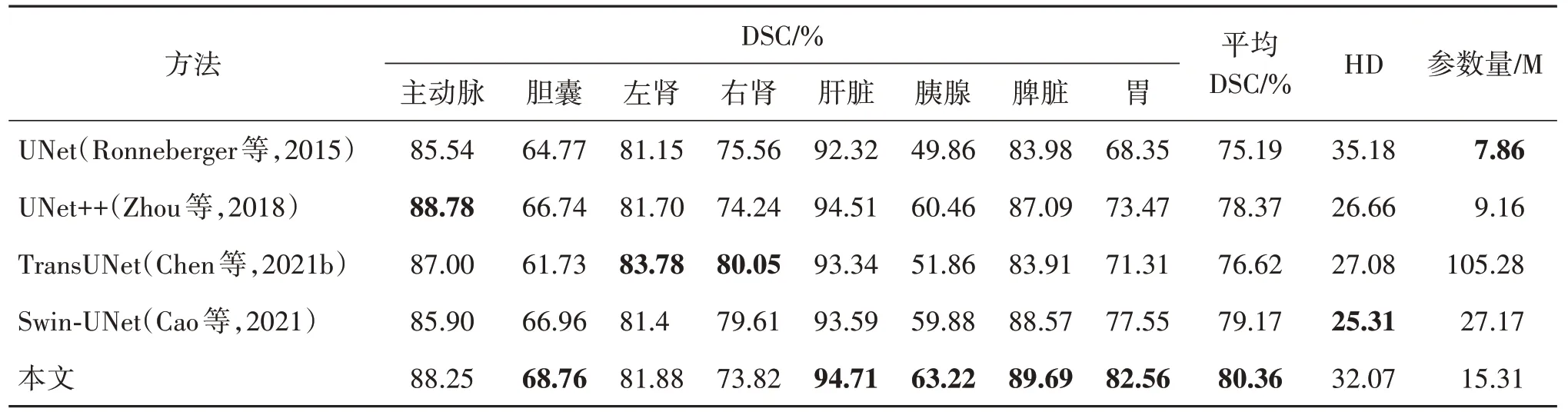
表1 不同方法在Synapse数据集的分割精度及参数量Table 1 Segmentation accuracy and params of different methods on Synapse dataset
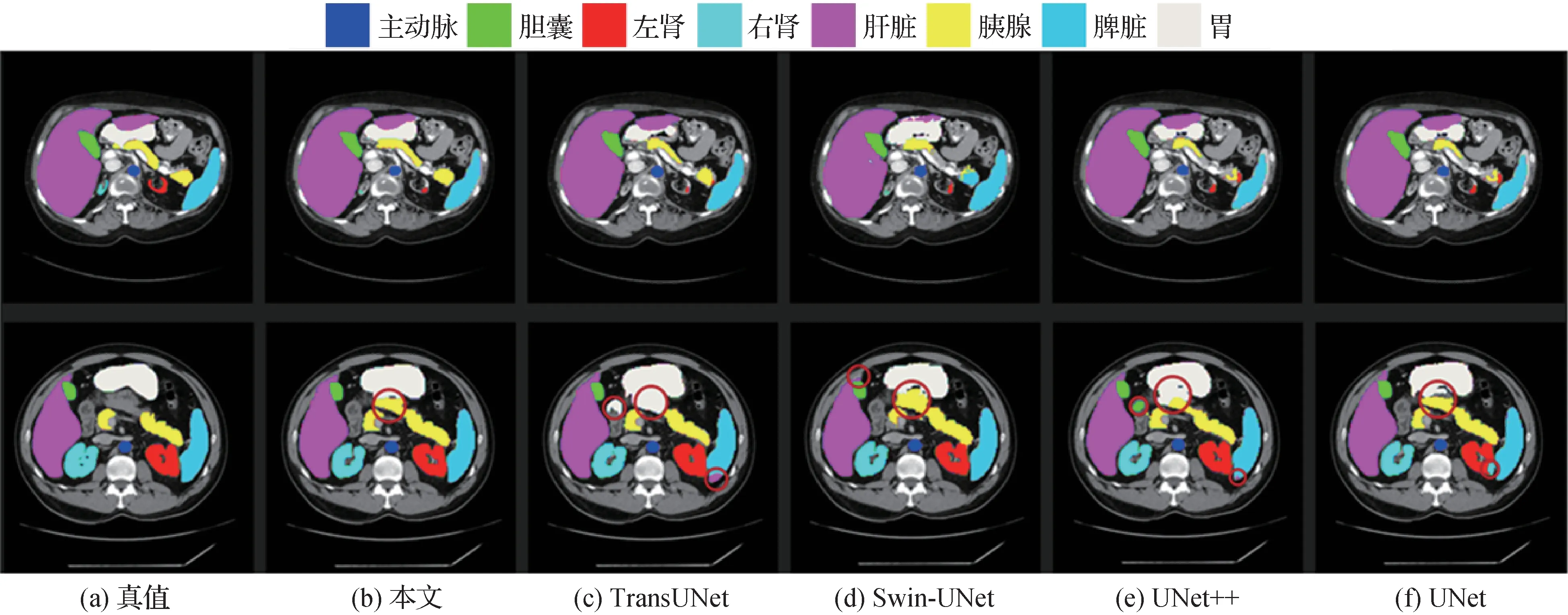
图6 不同分割方法在Synapse数据集预测的可视化结果Fig.6 Visualization results of different methods on Synapse dataset
2.3.2 复杂度分析
本文对复杂度进行分析,假定多尺度视觉注意力的输入和输出有着相同的分辨率H×W×C,k1,k2,k3分别是多尺度卷积的核大小,k0为深度方向卷积核大小,则有
对于不采用条状卷积而采用深度方向卷积的视觉注意力,假定卷积核不变,则有
式中,WQ,WK,WV分别为查询矩阵参数、键矩阵参数和值矩阵参数,heads为注意力头的数量。
由式(11)(13)(15)得,若输入图像分辨率为112 × 112 × 32,heads为1,且k0为5,k1、k2、k3分别为7、11、21。则有
由此可见,多尺度卷积注意力对于减轻计算开销具有明显优势。
2.3.3 在ACDC和DCWC数据集的实验结果
将本文方法与当前较先进的方法在ACDC 数据集的分割结果进行对比,其结果如表2 所示。本文方法的平均DSC 为91.06%,超过其他对比的方法,并且右心室、心肌和左心室的DSC 值都高于之前的方法,其可视化结果如图7所示。
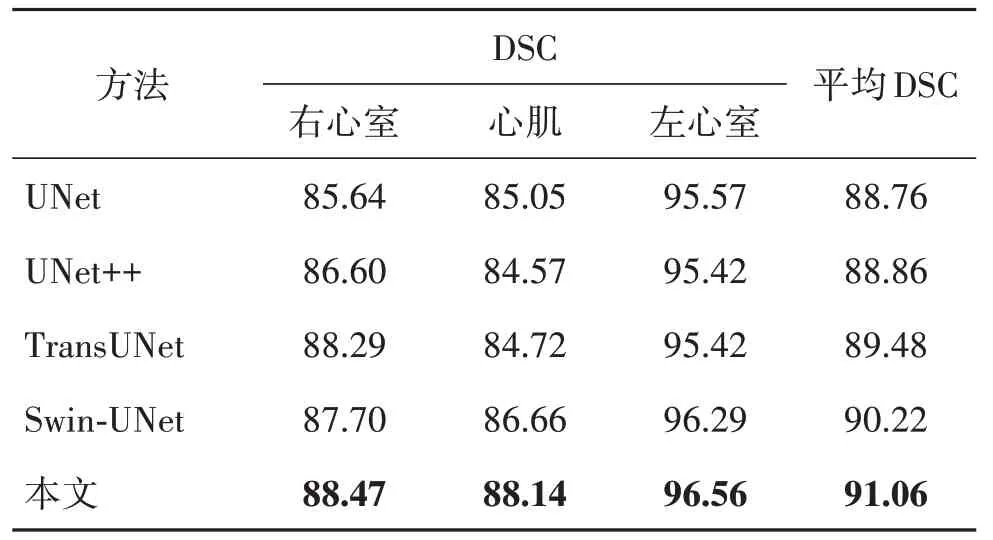
表2 不同方法在ACDC数据集的分割精度Table 2 Segmentation accuracy of different methods on ACDC dataset/%
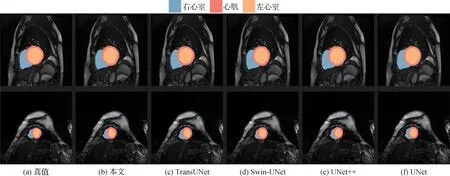
图7 不同分割方法在ACDC数据集预测的可视化结果Fig.7 Visualization results of different methods on ACDC dataset
为了验证网络的泛化能力,使用DCWC 在ACDC 数据集的训练文件上进行测试。实验结果如表3 所示,其可视化结果如图8 所示,用红色圆圈标注图中部分错分割和未分割的区域,从图中可知,所有方法对右心室都欠分割,相比而言,本文方法的分割效果相对较好。从分割精度和可视化结果可得,所有方法在DCWC 上的分割效果都不如在ACDC 上的分割效果,原因可能是ACDC 和DCWC 两个数据集虽然都是MR 图像,但是不同的成像设备会造成不同程度的噪声,虽然人眼看来差异不大,但是对于计算机来说则未必如此。在具有不同噪声的数据上进行测试,本文方法的平均Dice 是80.29%,超过了其他方法,说明本文方法有较好的泛化能力和鲁棒性。
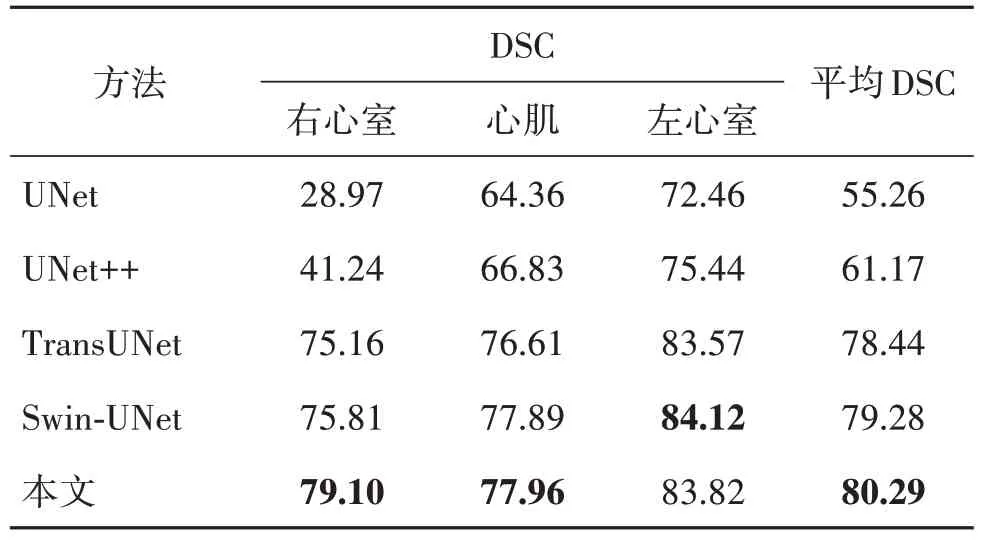
表3 不同方法在DCWC数据集的分割精度Table 3 Segmentation accuracy of different methods on DCWC dataset/%
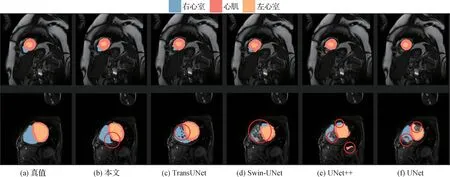
图8 不同分割方法在DCWC数据集预测的可视化结果Fig.8 Visualization results of different methods on DCWC dataset
2.4 消融实验
为了探索不同因素对网络的影响,本文设置不同的变量在Synapse 多器官分割数据集上进行消融实验。消融实验包括:1)不同图像分辨率对网络性能的影响;2)分支数量对网络性能的影响;3)卷积干对网络性能的影响。
2.4.1 输入网络的图像分辨率对分割结果的影响
分别将输入网络的图像分辨率设置为低分辨率224 × 224 像素和高分辨率320 × 320 像素。如表4所示,分辨率增大,DSC有些许提升,但效果不明显。然而随着分辨率的提高,网络所需计算开销就增大。考虑硬件条件的限制和模型性能的发挥,本文选择224 × 224像素作为网络的输入。

表4 输入分辨率的消融实验Table 4 Ablation study on the impact of the input size of images
2.4.2 分支数量对分割结果的影响
在视觉注意力中,分别使用1个卷积核大小为7的条状卷积对分支、2 个卷积核大小分别为7 和11的条状卷积对分支以及3个卷积核大小分别为7、11和21 的条状卷积对分支。实验结果如表5 所示,随着使用分支数量的增多,模型性能总体呈现线性提升。结果表明,使用多尺度视觉注意力,有能力捕捉不同尺度的语义信息,并且多个集成在一起,能进一步强化网络在图像上的建模能力。

表5 不同分支数量的消融实验Table 5 Ablation study on the impact of the different branches
2.4.3 卷积干对分割结果的影响
表6 是分别采用卷积干和补丁嵌入的消融实验结果。从实验结果看,将Transformer 早期阶段的模块设置为卷积干,有助于其表现得更好,显著提高模型的优化稳定性(Xiao 等,2021)。这是由于补丁嵌入所使用的卷积核较大,随机性较高,从而导致网络发挥不稳定(Li 等,2022)。

表6 使用卷积干和补丁嵌入的消融实验Table 6 Ablation study of using convolutional stem or patch embedding
3 结论
本文提出了一种新颖的以视觉注意力为主干的医学图像分割网络,它是以Transformer 为主干的编码器和以卷积上采样构成的解码器共同组成的U型网络,并采用跳跃连接的方式将下采样时的特征和上采样时的特征进行融合,来弥补上采样时的信息损失;同时,采用多尺度视觉注意力来捕获多尺度的上下文语义信息,不仅能学习图像局部信息,也能对长远距离进行上下文建模。首先,采用条状卷积避免直接将图像转换为一维序列输入Transformer 模块;条状卷积属于轻量级卷积,极大减少了参数量和浮点数运算量。其次,根据实验结果,虽然绝大部分器官的分割精度都有所提升,但部分器官的提升不明显甚至有下降的情况,可能的原因是各器官差异很大,网络不是对所有的器官都有相同的增益。最后,由于部分器官的位置特殊性和体积太小等因素,网络对这部分器官的特征提取能力还有待进一步提高,未来将继续深入研究如何提高这部分器官的分割效果。
致谢:感谢四川大学华西医院心内科陈玉成教授课题组提供临床数据用于验证网络泛化能力。
猜你喜欢
新生代(2019年11期)2019-11-13 09:28:19
新生代·上半月(2019年6期)2019-09-10 16:56:02
数学物理学报(2019年3期)2019-07-23 01:15:40
新教育时代·教师版(2019年3期)2019-03-11 06:30:12
学与玩(2018年5期)2019-01-21 02:13:06
文苑(2018年18期)2018-11-08 11:12:30
家庭影院技术(2018年9期)2018-11-02 05:31:32
幼儿画刊(2018年7期)2018-07-24 08:25:56
自动化学报(2017年5期)2017-05-14 06:20:52
成都信息工程大学学报(2017年6期)2017-03-16 03:04:32
