
大场景双视角点云特征融合语义分割方法
2024-01-22 10:27:16孙刘杰曾腾飞樊景星王文举
中国图象图形学报 2024年1期
孙刘杰,曾腾飞,樊景星,王文举
上海理工大学出版印刷与艺术设计学院,上海 200093
0 引言
在人工智能领域,为了更好地实现计算机对点云数据中场景的理解,点云语义分割作为三维点云数据的目标检测、点云分类等项目的基础技术,是目前三维计算机视觉研究的重要内容之一。同时,由于点云分割技术是计算机进行场景理解的关键手段,在自动驾驶、机器人和增强现实(augmented reality,AR)等诸多领域都得到了广泛应用。对于该问题的研究成为了当前的热点。
点云语义分割是指对点云场景中的点进行逐点分类操作,即对点云中每个点均判断其所属于的类别并最终据此进行分割整合。通常,根据应用场景的不同可以将点云语义分割技术分为两大类:小场景点云语义分割和大场景点云语义分割。其中,小场景点云语义分割只对室内点云场景或是小规模的点云场景进行语义分割操作;而大场景点云语义分割则将算法的部署环境换为室外的大场景点云数据,通常对驾驶场景或是城市场景进行点云的分类与整合。
相比于小场景点云语义分割,大场景点云语义分割的应用范围更广、实用性更强,广泛应用于驾驶场景理解、城市场景重建等领域。但同时,由于数据量大、点云数据情况复杂等原因,大场景点云语义分割任务也更加困难。
由于大场景点云语义分割任务的特殊性,通常在算法中会涉及到点云降采样策略,以此来降低数据总量减少计算成本,进而能在计算资源有限的条件下进行更全面的点云特征提取。根据算法基于降采样后点云特征的不同视角,可以将现有基于深度学习的大场景点云分割算法分为四大类,分别为:基于直接点云数据的方法,代表方法有PointNet(deep learning on point sets for 3D classification and segmentation)系列(Qi 等,2017a)、RandLA-Net(efficient semantic segmentation of large-scale point clouds)(Hu 等,2020)、AF2S3Net(attentive feature fusion with adaptive feature selection for sparse semantic segmentation network)(Cheng 等,2021)等方法。基于点云伪图像的方法,代表方法有SqueezeSeg(convolutional neural nets with recurrent crf for realtime road-object segmentation from 3D LiDAR point cloud)(Wu 等,2018)、SqueezeSegv2(Wu 等,2019)、RangeNet++(fast and accurate LiDAR semantic segmentation)(Milioto 等,2019)、TORNADO-Net(multiview total variation semantic segmentation with diamond inception module)(Gerdzhev 等,2021)、KPRNet(improving projection-based LiDAR semantic segmentation)(Kochanov 等,2020)等方法。而随着点云语义分割项目的发展,基于体素的方法、基于多种点云特征融合的方法逐渐成为研究热点,接下来分别简要概述。
基于体素的方法中,典型算法有VoxelNet(endto-end learning for point cloud based 3D object detection)(Zhou 和Tuzel,2018)、PolarNet(an improved grid representation for online LiDAR point clouds semantic segmentation)(Zhang 等,2020)、CA3DCNet(an effective 3D framework for driving-scene LiDAR semantic segmentation)(Zhu 等,2021)等。其中最具代表性的方法之一是VoxelNet,该方法采用将点云数据按笛卡尔直角坐标系进行方形体素分割的思路,使用方形体素块来代表局部点云特征,从而在降采样的同时保证点云数据的几何结构。而Polar-Net、CA3DCNet则针对体素化策略提出了改进,都采取了柱状体素化策略。其中CA3DCNet 使用柱状体素的同时采用了非对称卷积策略进行点云特征提取,在计算成本与分割精度方面都具备优势。基于体素的方法能够在保留点云几何特征的同时进行大范围的快速降采样,能够解决由大场景点云数据量庞大所带来的降采样难题,但是仍存在边缘点云特征损失等问题。
基于多种点云特征融合的方法中,典型算法有MPF(multi projection fusion for real-time semantic segmentation of 3D LiDAR point clouds)(Alnaggar 等,2021)、AMVNet(assertion-based multi-view fusion network for LiDAR semantic segmentation)(Liong 等,2020)、RPVNet(deep and efficient range-point-voxel fusion network for LiDAR point cloud segmentation)(Xu 等,2021)等。其中RPVNet 融合了直接点云特征、方形体素特征、距离伪图特征3 种点云特征,并在不同的分支之间添加了特征交互,获得了较优秀的分割精度,但庞大的网络结构使其牺牲了一些计算速度。尽管复杂的网络结构与几何运算会带来计算成本的增加,基于多种点云特征融合网络构建思想仍具备优势,能够将多个降采样视角下的点云特征相结合从而弥补不同降采样策略所带来的损失。就目前大场景点云语义分割方法的发展趋势而言,多种点云特征融合是点云特征提取策略的重要途径之一。
综上,在众多算法中,使用多种降采样视角下点云特征融合的思想构建算法,通常能够获取更高的分割精度。目前的大场景点云语义分割算法仍具有很大的提升空间,重点在于分割结果准确率的提升。
为了减少点云特征在降采样下的损失,进一步提取点云特征的语义信息从而提升分割精度,本文提出了双视角点云特征融合语义分割方法(doubleview feature fusion network for LiDAR semantic segmentation,DVFNet),通过双视角点云特征融合与上下文特征构建的策略,取得了一定的成果。本文的主要贡献包括:1)提出了一种双视角点云特征融合模块(double-view feature fusion module),能够有效融合两种降采样视角下的点云特征,减少单个降采样策略所带来的点云特征损失;2)为了进一步提取点云特征的上下文语义信息,提出了一种基于非对称卷积的点云特征整合模块(feature integration based on asymmetric convolution),通过非对称卷积与点云多尺度上下文特征重构(multi-scale dimension-decomposition context modeling)对点云特征进行标签优化;3)基于上述两个模块,设计了双视角点云特征融合语义分割方法(double-view feature fusion network for LiDAR semantic segmentation,DVFNet),并应用于大场景雷达点云数据集,获得了较高的分割准确率。
1 双视角点云特征融合语义分割方法
1.1 网络整体结构
为了解决大场景的数据环境下,点云语义分割精度低的问题,本文提出了一种新的直接点云特征与柱状体素特征相结合的方法DVFNet。具体网络结构如图1所示。
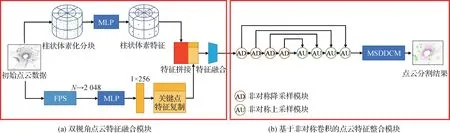
图1 本文方法结构总览Fig.1 The overview of DVFNet
本文方法由两部分组成:双视角点云特征融合模块(图1(a))和基于非对称卷积的点云特征整合模块(图1(b))。在降采样特征提取阶段,提出了双视角点云特征融合模块(图1(a)),包含双视角点云特征提取结构与特征融合器,通过使用柱状体素化策略与最远点降采样策略分别获取不同视角下的点云特征,再通过特征拼接的方式,对提取到的点云特征进行特征结合。最终将结合后的点云特征输入特征融合器中实现特征降维与融合的操作。在特征整合阶段,提出了基于非对称卷积的点云特征整合模块(图1(b)),包含特征预处理结构与多尺度点云上下文特征增强结构,通过非对称点云特征处理与多尺度上下文特征整合的操作,实现了点云特征的增强与重构。
1.2 双视角点云特征融合模块
提出的双视角点云特征融合模块实现了点云柱状体素特征与直接点云特征相融合的操作,由双视角点云特征提取结构与特征融合器组成。
1.2.1 双视角点云特征提取结构
双视角点云特征提取结构以柱状体素化策略与最远点采样策略为基础,具体结构如图2 所示。其中,N表示输入点云中包含的点数量,N′表示柱状体素特征中包含的特征数量。
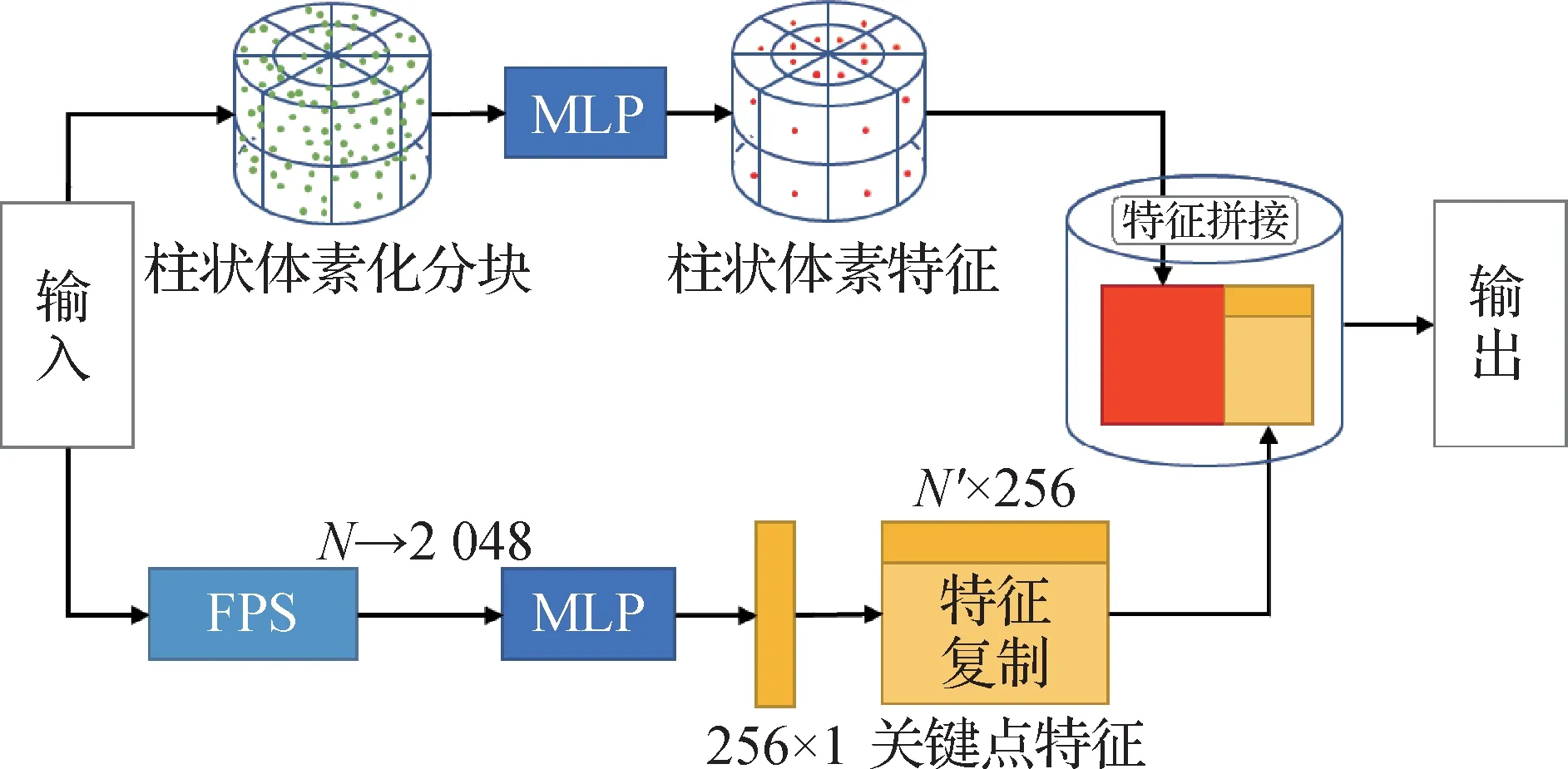
图2 双视角点云特征提取结构的实现方法Fig.2 The implementation of double-view feature extraction
如图2 所示,为了弥补柱状体素化带来的点云特征损失,使用通过最远点采样获取的点云特征与体素特征进行结合。双视角点云特征提取模块共由两个降采样分支组成。柱状体素特征提取分支首先根据极坐标系将点云数据划分为柱状体素(cylindrical partition),并使用线性层进行体素内局部特征提取操作。假设点集S={p1,…,pn},其中p表示点集中包含的单个点,并且p=(px,py,pz),每个点都包含坐标信息。首先,将点p的笛卡尔坐标转化为极坐标,具体为
那么,第i,j,k个柱状体素块的特征提取过程可以表示为
式中,r,θ,h分别为点云极坐标系中极径、极角、高度上的柱状体素分块阈值,MLP表示使用线性层对特征进行处理,fea则为最终提取的特征。
选择柱状体素特征的原因在于,柱状体素化策略作为代表性的点云降采样策略之一,具有计算速度快、数据量减小显著以及点云特征保留完整等特点,在诸多点云任务中得到了广泛的应用。
在大场景点云语义分割领域,点云数据集通常使用车载LiDAR 激光雷达进行数据采集工作。这就导致在近处的物体所占据的视场角要比远处的物体大得多,体现为近处的物体包含的点云数据量要远远高出远处的物体。因此大场景点云数据集中,点云数据的分布是不均匀的,距离激光雷达近的区域点云分布密集,而远处的区域点云分布稀疏。
为了对大场景条件下的点云数据进行处理,常用的降采样策略有:距离图像投影、鸟瞰图像投影、方形体素化和柱状体素化等。其中,距离图像投影与鸟瞰图像投影都是将三维点云数据转化为二维图像的处理方法。尽管这两种降采样策略能够显著减少点云数据量,并且能在二维图像上对物体类别进行较为精确的分割,但是在三维点云投影过程中不可避免地会产生深度损失,同时,二维分割结果逆投影至三维点云标签的过程中也会存在误差,这会在一定程度上影响最终的分割效果。而方形体素化策略与柱状体素化策略则通过以网格形式对点云场景进行区域划分的方式进行降采样操作。相比于VoxelNet(Zhou 和Tuzel,2018)中提出的方形体素化策略,柱状体素化策略在降采样的均匀性上更具优势。两种体素化策略如图3所示。
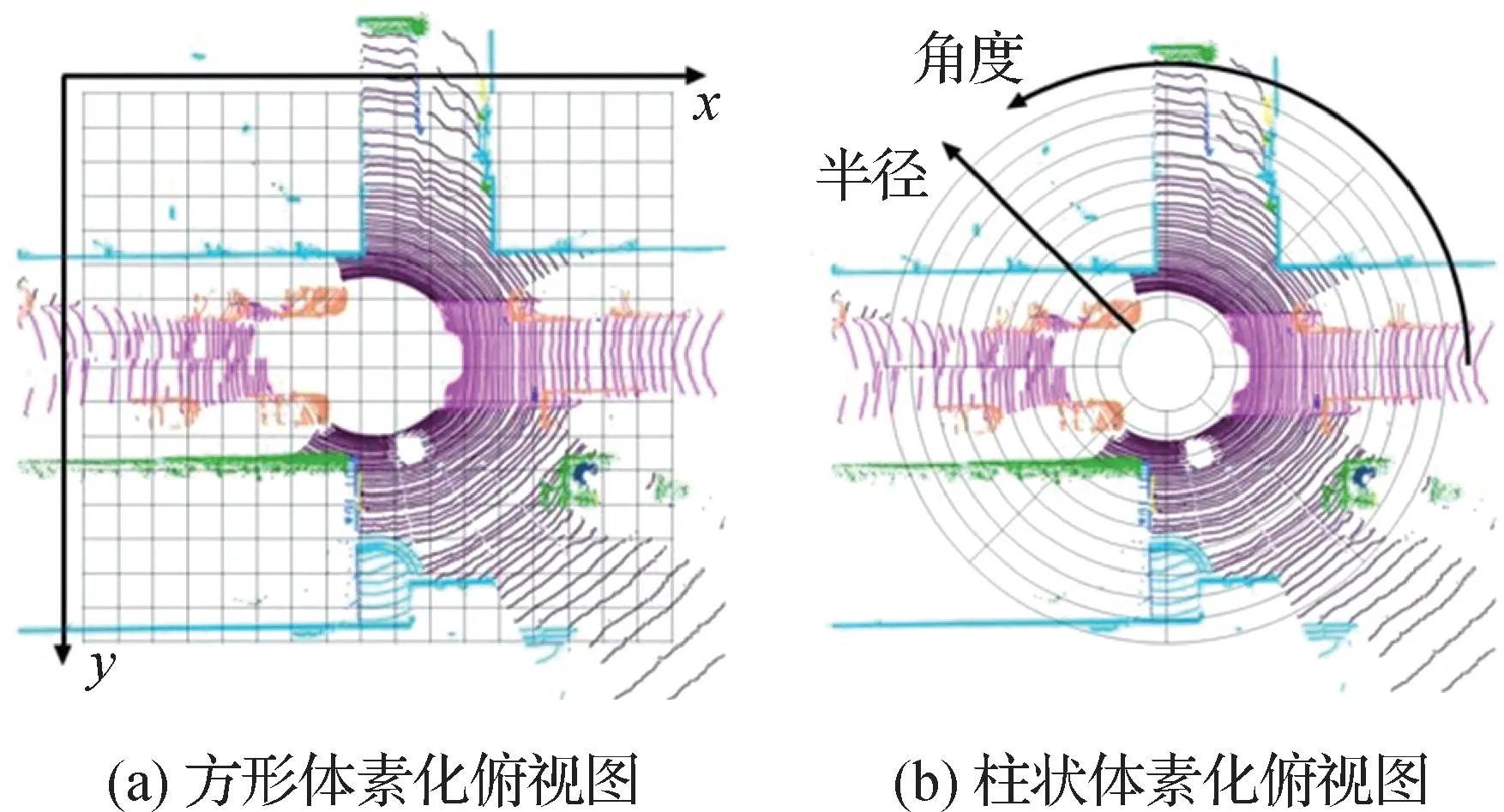
图3 两种体素化策略示意图Fig.3 Two kinds of 3D voxel partition
如图3(a)所示,方形体素化策略根据点云数据建立3D笛卡尔直角坐标系,并通过坐标划分来实现点云数据的均匀分块。而柱状体素化策略则通过以LiDAR 激光雷达为原点建立极坐标系的方式,如图3(b)所示,采用相同的视场角度与分割间距在极坐标的两个维度上进行区域划分,以此得到圆弧状的体素块。圆弧状的体素块具有近小远大的特点,体素块的覆盖范围会随着距离的远近而变化,是一种特殊的划分方式。
如果采用均匀的方形体素化策略,可能会导致近处的体素内包含的点数量远远高出远处体素内点的数量,这样的降采样方式会带来特征提取不均匀的问题。而柱状体素化策略中,柱状体素具有近小远大的特点,在大场景点云近密远疏的特性下,能够在一定程度上保证每个体素包含点的数量较为均匀,从而能够做到均匀降采样。
关键点特征提取分支则首先对点云数据进行最远点采样操作(farthest point sampling),共采样2 048个关键点。点q到点集S的距离定义为
式中,d(q,S)表示点q到点集S中所有点距离的最小值。假设最远点采样已有采样点集Sk={p1,…,pi-1},共包含i-1 个点,现需从点集S-Sk中采集第i个点,则采集过程为
如式(4)所示,选取点集S-Sk中与点集Sk距离最远的点作为第i个点。使用这种采样方式采集的关键点分布均匀,能够较好地保留点云几何特征。采样后使用全连接层对关键点特征进行提取,获得维度为256 × 1 的全局性点云特征,并将其扩充为与柱状体素特征维度相适配的特征向量,将两种降采样策略下的特征进行拼接,最终将形成的点云特征映射到柱状体素视角中去。
关键点特征分支的重要性在于,通过最远点采样法采集的关键点均为点云场景中相互分布距离最远的点,这意味着关键点会充分分布在点云场景的所有区域,包括边缘区域,从而减少场景边缘、点云数量较为稀疏区域的信息损失。因此,使用关键点进行特征提取不存在区域导致的特征提取不充分的问题,这恰巧是柱状体素特征中欠缺的部分。
柱状体素化策略着力于提取单个体素内的局部点云特征,尽管柱状体素在远处的体素体积较大,但点云场景中远处分布稀疏的点仍可能会导致体素内点的数量较少。由于生成体素特征的阶段不能进行跨体素特征提取,这些体素中的点在计算过程中将无法获取其与周围点的几何关系,从而导致特征提取不充分。
使用最远点采样获取的关键点特征与柱状体素特征进行结合,能够很好地弥补在体素化过程中所损失的点云特征,从而在一定程度上保留点云场景的几何信息。同时,全局性的关键点特征缺少点云局部特征,而柱状体素特征中包含的点云局部信息能够弥补这一点。值得一提的是,关键点的数量相对较少,因此使用繁重的卷积层以及大尺寸的特征层来表征关键点特征是不必要的,本文使用了单维的全局性特征向量则能够在减少计算成本的同时表述关键点的特征信息。
双视角点云特征提取结构的优势在于,结合了两种不同降采样策略下的点云特征,从而在一定程度上避免了降采样所带来的点云特征损失。
1.2.2 特征融合器
双视角点云特征提取结构能够获取两个降采样视角下的点云特征并加以结合,从而实现特征互补及特征增强的操作,但是这个模块的问题在于只实现了特征提取与特征拼接,并没能将两种点云特征充分融合,同时两种点云特征的拼接带来了特征维度增加的问题,如果直接针对此特征进行计算会导致后续计算成本升高。针对这一现象,本文提出了一种特征融合器,具体结构如图4所示。
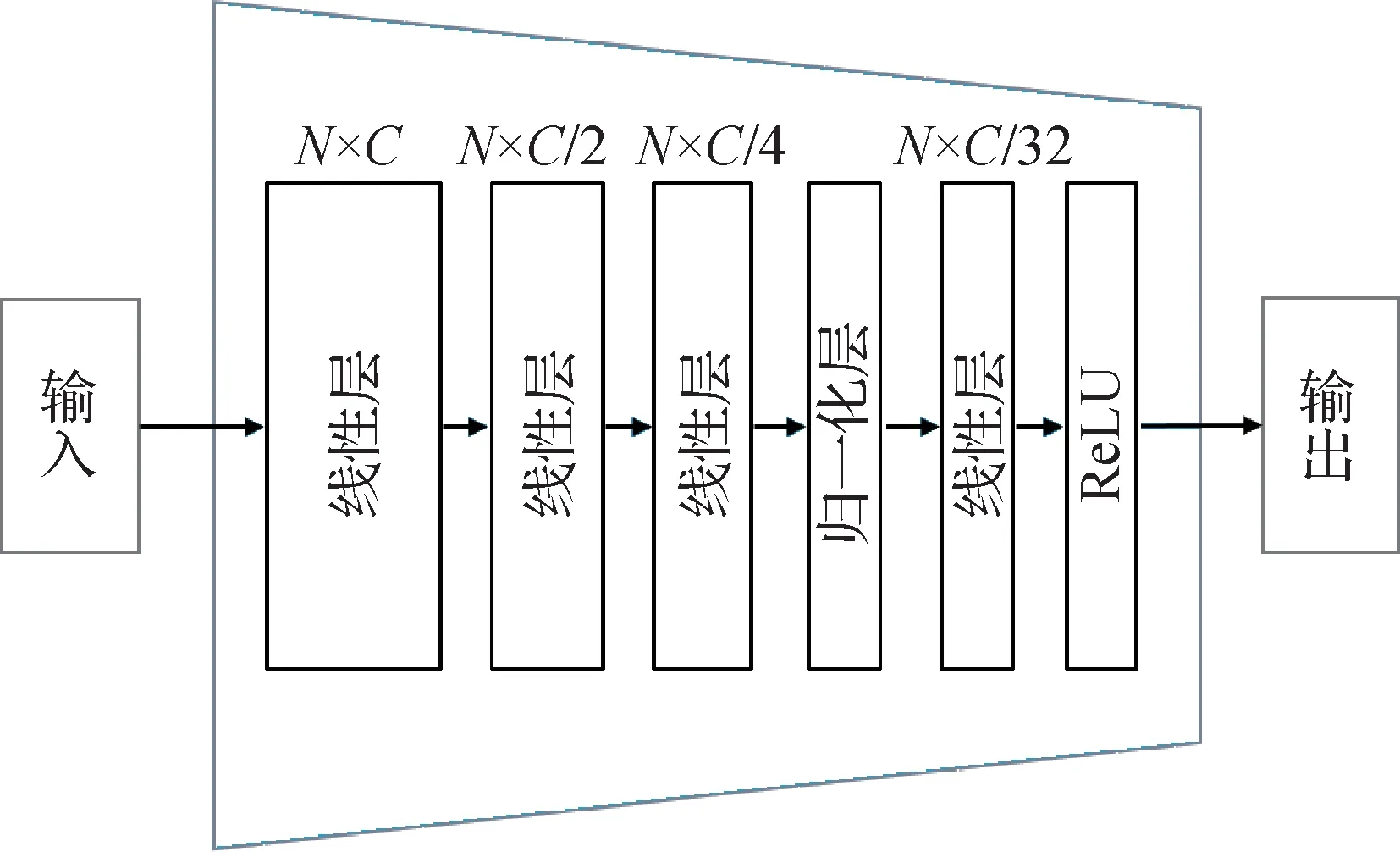
图4 特征融合器结构Fig.4 The feature fusion block
如图4 所示,N表示输入点云特征的数量,C表示点云特征的维度,即特征通道数。特征融合器由线性层、归一化层和ReLU(rectified linear unit)激活函数层组成。
线性层用于特征融合与维度压缩。选择线性层而非卷积层的原因在于,线性层由其全连接的特性,能够充分进行跨特征通道的特征提取操作,实现单个点特征通道方向的特征融合与特征优化,从而解决特征拼接带来的特征融合不充分的问题。在特征融合器中,线性层只针对特征通道数进行压缩,避免了点特征数量的减少,保证了点云特征几何结构的完整性。
归一化层则能够使得特征分布更加均匀,能够预防特征值分布变化而引起的梯度爆炸问题,从而实现加快训练速度和提升训练稳定性。假设特征通道数为m,第i通道处特征值为xi,那么归一化层的计算方式为
式(5)求出所有特征均值μ,式(6)依据μ求出特征方差σ2,式(7)通过特征归一化的操作获取特征,加入ε是保证不会出现分母为0 的情况,式(8)中通过缩放变量γ和平移变量β改变特征值的分布情况,从而获取最终归一化后的特征值。在特征归一化的过程中,为了对一维的点云特征进行处理,选择了batchnorm1d作为归一化层的实现函数,式中缩放变量γ初始值选取为1,平移变量β初始值选取为0,并在训练过程中根据特征情况改变此两种超参数的取值,从而保证特征分布的均匀性。
ReLU 激活函数层是一种分段线性函数,会将小于0 的输入值置为0,而大于0 的输入值则直接输出。在特征融合器的最后添加ReLU 激活函数的目的在于,通过矫正负特征值以保证输出点云特征的合理性。
1.3 基于非对称卷积的点云特征整合模块
提出的基于非对称卷积的点云特征整合模块由点云特征预处理结构与多尺度点云上下文特征增强结构组成。
在特征预处理阶段,贯彻了大部分点云语义分割网络的设计思想,采用了基于非对称卷积的类U-Net(Ronneberger 等,2015)结构。与传统点云分割方法的不同之处在于,此结构采用了一种非对称残差块(Zhu 等,2021),分别运用了尺寸为3 × 1 × 3与1 × 3 × 3 的卷积核先后对点云特征进行卷积,以结合不同维度上的点云特征,使提取得到的信息具有多维度的几何特征。本结构中采用了4 层非对称降采样与4 层非对称上采样相结合,能够实现点云特征的提取并生成初步的分割结果,为下一步的整合操作进行准备。
RecoNet(tensor low-rank reconstruction for semantic segmentation)(Chen 等,2020)中针对图像语义分割提出了一种基于张量分解重构理论的上下文信息提取策略,而在点云语义分割任务中上下文特征同样关键。因此,在特征整合阶段,延用了张量分解重构理论,为了结合上下文特征对点云特征进行整合操作,提出了多尺度点云上下文特征增强结构。点云语义分割任务与图像语义分割任务一个显著的不同之处在于,点云特征的单个特征位置中包含的信息量更大。而本文方法中结合了两种不同降采样视角下的点云特征,在特征的复杂性上更有提升,因此上下文特征中包含的语义信息也更为丰富。在点云语义分割任务中,提取上下文信息能够辅助判断单个位置的点标签是否符合上下文包含的语义信息,从而进行标签的优化。因此,在大场景、双降采样视角的特征背景下,提取上下文信息对点特征进行整合则显得更为重要。
多尺度点云上下文特征增强结构如图5所示。
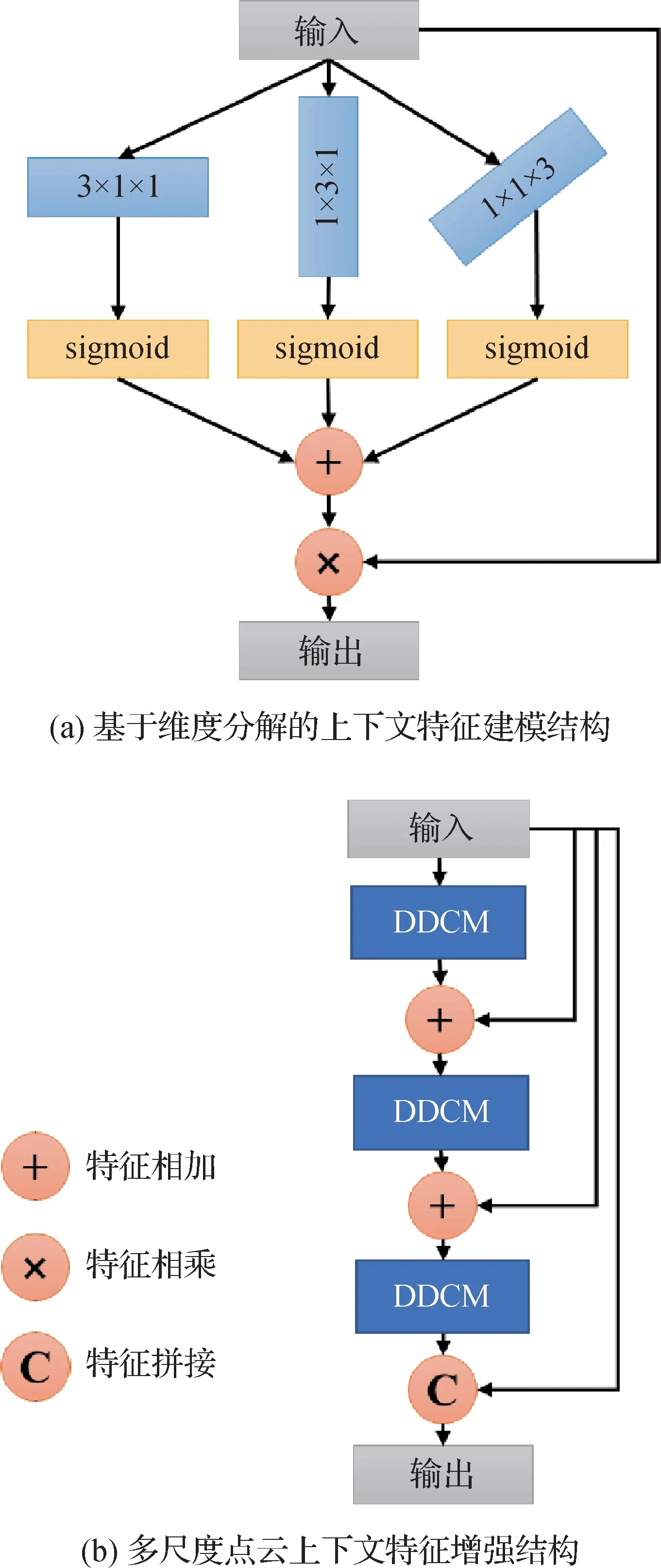
图5 点云上下文特征增强的实现方法Fig.5 The implementation of context feature extraction for point cloud((a)context feature modeling structure based on dimension decomposition;(b)multi-scale point cloud context feature enhancement structure)
如图5(a)所示,基于维度分解的上下文特征建模结构(dimension-decomposition context modeling)采用了多维度卷积的策略,使用3 种不同尺寸的低维卷积核分别对点云数据进行处理。此种策略的优势在于,可以提取单个点的上下文信息在不同方向上的几何特征,从而根据单个点的上下文信息获取3 个维度上的权重值,对其加以融合后,使用上下文权重对输入的点云特征加以整合。同时,由于大部分待分割的目标都具有水平或是竖直方向的几何特征,如直立地面的行人、呈现近似长方体的车类目标等,多维的卷积能够更优秀地提取不同目标的几何特点,从而进行区分。
假设输入点云特征为F,尺寸为C×H×W,那么计算过程为
式中,vc,vh,vw分别为3 个维度上的低阶张量,即图5(a)中的3 个不同维度的卷积核,sig表示sigmoid激活函数,那么Ac,Ah,Aw分别为经过运算后得到的3 个维度中上下文权重。在式(10)中,将提取到的上下文权重Ac,Ah,Aw求和,得到总的上下文权重,最终将点云特征F与上下文权重进行相乘操作,得到整合后的点云特征F′。
但是面对大场景点云复杂的特征环境,仅使用基于上下文信息的权重进行特征整合显得有些单薄,主要体现在两个方面。首先,在使用根据上下文信息所提取的特征权重对点云特征进行优化的过程中,在上下文语义信息不明显的情况下,会出现部分点云特征损失的现象。此外,单尺度下的上下文特征增强中容易存在误差,若点周围已存在分割误差的情况,使用上下文特征进行增强反而可能导致误差扩散的现象。
针对上述问题,本文方法通过叠加基于维度分解的上下文特征建模结构,实现了多尺度的特征整合,使得到的特征语义性更强、误差情况更少。本文提出了多尺度点云上下文特征增强结构(multiscale dimension-decomposition context modeling),如图5(b)所示,采用多尺度上下文特征提取的策略对点云特征进行多次增强操作。为了避免在特征增强的过程中出现误差情况,在每一次增强过后均与原先的点云特征进行求和,并在输出前与原先点云特征进行拼接,以此来弥补特征增强所带来的潜在特征损失。
2 实验结果与分析
2.1 实验数据与环境
本节首先介绍实验的相关环境,然后提供相关算法与本文算法在SemanticKITTI 数据集(Behley等,2019)上的实验结果对比,最终通过消融实验来表明本文算法各模块的有效性。SemanticKITTI 是为点云分割提供的大场景驾驶场景数据集,由KITTI 视觉公司提出,在德国使用Velodyne-HDLE64雷达采集。此数据集由22 个场景组成,在训练和验证中共使用了19个类别。在22个场景中,共使用43 552 组完整的 3D 扫描数据,每组点云中的点数量均在10万以上,这使其成为公开可用的最大点云分割数据集之一。本次实验使用的相关环境如下:python3.8,pytorch1.4.1,cuda11.1,Ubuntu18.04,Nvidia GeForce GTX2080Ti GPU,spconv2.1.2,选择SemanticKITTI 点云语义分割数据集进行实验。实验表明,本文方法能够达到63.9%的分割准确率,在现有算法中处于领先地位。
2.2 可视化结果分析
在可视化阶段,实验选取了SemanticKITTI 数据集中6 个代表性的点云场景,每个场景内均包含轿车、道路、人行道、植被、楼宇和栏杆等代表性点云类别。为证实本文方法的有效性,实验中对具有不同特点的点云类别进行了整理,主要包括轿车、道路、人行道、植被、楼宇和栏杆等类别。包含这些区域的点云场景可视化实验结果图像如图6 所示。每个区域中,本文方法成功分割区域及CA3DCNet 方法分割有误的区域均由红色方框标出,并在图6 右侧对框内场景细节进行了放大展示。
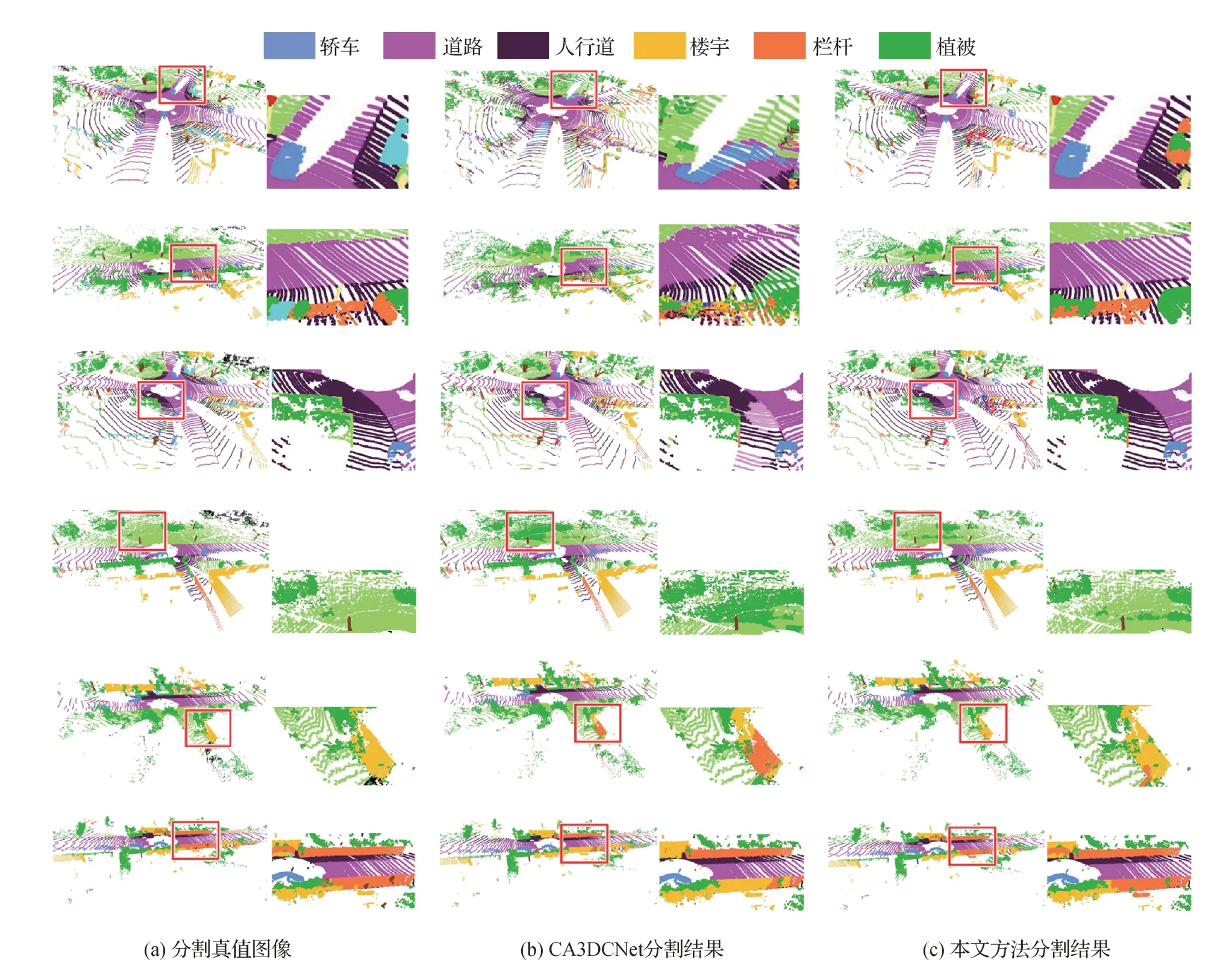
图6 点云场景可视化结果Fig.6 The visualization of point cloud data((a)ground truth;(b)CA3DCNet;(c)ours)
如图6 第1 行所示,轿车、道路等类别的点云物体在较小范围内同时出现的情况下,本文方法能够成功区分道路与轿车,并且将周围的其他类别物体精确分割,而CA3DCNet 方法则存在将待分割轿车及道路相混淆,从而导致周边类别分割不准确的问题。这是因为本文方法中包含点云特征整合模块,能够通过上下文语义特征对单个位置的点云特征进行增强,以此来实现近距离类别物体的区分。在图6 第2 行中,CA3DCNet 错误地将道路与其他类别进行混淆,而本文方法可以得到较精确的结果。
图6 的背景区域内,常出现的物体类别为人行道、植被、楼宇和栏杆等,通常情况下,这些类别的物体距离点云采集中心距离较远。在图6第3行中,在人行区域内当道路与人行道形态相似、距离较近时,本文方法也能对两个类别进行区分,而CA3DCNet方法则存在将人行道类别点云误判为道路类别的现象。图6 第4 行中,CA3DCNet 方法在分割的过程中出现了将大量其他地面类别的点云误判为植被的现象,而本文方法则能够精确地将二者区分。这主要是由于本文方法中包含了双视角点云特征融合模块,在降采样阶段减少了点云特征的损失,并将远距离的稀疏点云中包含的信息加以保留。在图6第5行中,CA3DCNet 方法存在将大面积的楼宇与栏杆类别相混淆的问题,而本文方法能够较精确地对两种类别进行分割,类似的情况也出现在图6 第6行中。
2.3 性能指标比较
在点云语义分割任务中,评价指标通常使用均交并比(mean intersection over union,mIoU)、频权交并 比(frequency weighted intersection over union,FWIoU)(Behley 等,2019),两者均展示了点云分割的准确程度,由交并比(intersection over union,IoU)(Behley 等,2019)计算得来,交并比表示某个类别中点云分割的准确程度。
通过交并比IoU 可得出频权交并比FWIoU 和均交并比mIoU 的计算方法。假设pij为算法将类别为i的点预测为类别为j的点的数量,可以得出频权交并比FWIoU和均交并比mIoU的计算式,具体为
式中,k表示共有k+1 个类别标签。因此计算所得的频权交并比FWIoU 为每个类别物体出现占比与该类交并比的乘积之和,即考虑到点云组成占比的分割精确度,而均交并比mIoU 为平均每个类别的预测准确率,即点云分割的整体准确率。
实验收集了目前已开源的大场景点云语义分割算法在SemanticKITTI 点云语义分割数据集验证集上的分割精度,包括PointASNL(Yan 等,2020)、SBKI(Gan 等,2020)、RandLA-Net(Hu 等,2020)、PolarNet(Zhang 等,2020)、SqueezeSeg(Wu 等,2018)、SqueezeSegV3(Xu 等,2020)、FusionNet(Quan等,2021)、MinkU-Net(Choy 等,2019)、SPVCNN(Tang 等,2020)、CA3DCNet(Zhu 等,2021)。共展示了数据集中19个类别分割效果,如表1所示。
如表1 所示,本文算法在本次的实验环境中,相比于其他已开源的算法,具有第2 高的FWIoU 准确率与最高的mIoU 准确率,这表明本文算法具有优势。其中,SPVCNN 方法(Tang 等,2020)拥有最优的FWIoU 准确率,但在mIoU 准确率方面表现一般,这主要是因为FWIoU 根据点云物体在数据集中的所占比例而调整每个类别所占权重。SPVCNN 方法采用了更大尺寸的体素,因此针对大体积点云物体时表现更好,在对行人等小类别物体进行分类时则精度较低。本文方法则能在这些类别的物体中保持较为稳定的分割水平。尽管在模型大小方面,本文算法中的神经网络包含的参数量最多,但是本文算法着重于分割精度的提升,并在多个类别中都取得了分割精度最高的成绩。针对轿车、卡车等大型车辆类别,本文算法能够取得较高的分割精度,但是相比于CA3DCNet(Zhu 等,2021)等方法,精度稍有下降,这是因为轿车与卡车的几何结构以长方体为主,在整合阶段的预处理结构中已经得到较为完整的分割结果,因而在后续上下文特征建模结构中可能会产生物体标签负优化的情况。而在个体较小、形态较为复杂的单车、摩托和行人等类别中,相较于其他方法,本文算法取得了更优秀的精度,这得益于点云特征整合模块对上下文特征进行了建模并将邻域信息加以融合,从而实现了针对小物体边缘点标签的优化。此外,针对楼宇、栏杆、植被等处于点云场景边缘、点云分布较为稀疏的类别,本文算法中双视角点云特征融合模块既保留了点云场景的几何结构,还通过关键点的采集提取了场景的全局特征,从而实现了这些点云类别的高精度分割。
同时,本文算法具有泛用性,在nuScenes数据集(Caesar 等,2020)中,本文方法也取得了较好的分割效果,在同等实验环境下相比单独使用柱状体素化策略的CA3DCNet 方法提升了0.7%的准确率,实验结果如表2所示。

表2 基于nuScenes验证集的分割结果准确率对比Table 2 Comparison of accuracy of segmentation results based on nuScenes validation set/%
2.4 消融实验
为了证实所提出各结构的有效性,在SemanticKITTI 点云语义分割数据集验证集上进行了消融实验,实验结果如表3所示。
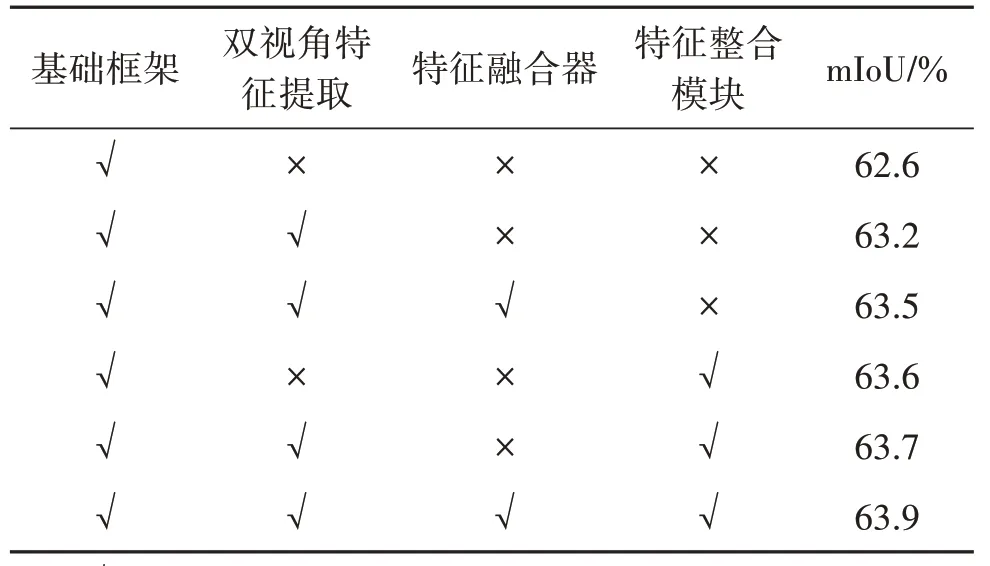
表3 SemanticKITTI验证集下DVFNet组件消融实验结果Table 3 Ablation studies for components of DVFNet on SemanticKITTI validation set
表3 中,基础框架表示仅使用单一视角柱状体素特征,不包含特征融合整合结构的分割方法。在添加双视角点云特征提取结构后,分割精度提升了0.6%,可知关键点特征对柱状体素点云特征能够起到补充作用,使得点云特征包含的信息更加丰富。加入特征融合器之后,双视角点云特征融合模块得以完整落实,分割精度相较于基础框架提升了0.9%。而在仅加入点云特征整合模块的情况下,得益于此模块的点云标签优化作用,分割精度相较于基础框架提升了1%。同时采用双视角点云特征提取结构与基于非对称卷积的特征整合模块的情况下,分割精度进一步提升,总提升量达到1.1%。最终,采用本文方法的双视角点云特征融合模块与基于非对称卷积的特征整合模块,分割精度达到了63.9%。由表3 中的实验结果可知,本文提出的各结构均具备优越性和必要性,并且在应用过程中展现出优秀的分割效果。
3 结论
提出了一种针对大场景点云环境的双视角点云特征融合语义分割方法,包含双视角点云特征融合模块与基于非对称卷积的点云特征整合模块。双视角点云特征融合模块由双视角点云特征提取结构与特征融合器构成。双视角点云特征提取结构通过将柱状体素特征与全局性关键点特征进行结合,在一定程度上避免了体素化所带来的特征损失。特征融合器通过特征维度压缩,实现了计算成本的降低和双视角点云特征的进一步融合。实验结果表明,双视角点云特征融合模块能够减少大场景点云边缘物体信息的损失,从而提升点云场景中边缘物体类别的分割精度;基于非对称卷积的点云特征整合模块,由点云特征预处理结构与多尺度点云上下文特征增强结构组成。点云预处理结构采用非对称卷积算子构建了类U-Net 结构,实现了点云特征的多维度提取与高精度上采样。多尺度点云上下文特征增强结构通过使用从点云上下文特征中提取的权重对点云特征进行优化,并使用跳跃连接和特征拼接的手段减少了特征增强过程中的信息损失。实验证明,基于非对称卷积的点云特征整合模块能够有效针对小尺寸物体进行分割,如行人、单车、摩托等类别均取得了较优秀的分割水平。同时,将多种大场景点云语义分割方法进行对比,在平均准确率等方面,本文算法均具有一定优势,最终在SemanticKITTI 数据集上取得了63.9%的平均分割精度。
综上所述,基于双视角点云特征融合结构的分割方法在点云语义分割任务中具有一定的优势。后期的工作可以尝试加入其他降采样视角下的点云特征,如在点云特征融合结构中加入伪图像类别的降采样点云特征。从使用多种点云特征弥补降采样损失的角度来进一步优化,能够作为该算法以后的改进方向。
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
电子制作(2018年19期)2018-11-14 02:37:08
自动化学报(2017年11期)2017-04-04 02:52:58
现代语文(2016年21期)2016-05-25 13:13:44
新校长(2016年8期)2016-01-10 06:43:59
大连民族大学学报(2015年2期)2015-02-27 08:28:11
噪声与振动控制(2015年4期)2015-01-01 07:08:21
商事法论集(2014年1期)2014-06-27 01:20:42
中国中医药现代远程教育(2014年16期)2014-03-01 04:28:46
食品科学(2013年8期)2013-03-11 18:21:31
