
融合局部与全局特征的DCE-MRI乳腺肿瘤良恶分类
2024-01-22 10:27:36赵小明廖越辉张石清方江雄何遐遐汪国余卢洪胜
中国图象图形学报 2024年1期
赵小明,廖越辉,张石清,方江雄,何遐遐,汪国余,卢洪胜
1.杭州电子科技大学计算机学院,杭州 310018;2.台州学院附属医院(台州市中心医院),台州 318000
0 引言
乳腺癌(breast cancer,BC)是全球女性中最普遍的癌症,其患癌死亡率仅次于肺癌(DeSantis 等,2019)。在乳腺肿瘤诊断影像分析中,由于病变的多样性和复杂性,放射科医生很难准确检测和分析病变区域(施俊 等,2020)。另外,医生进行诊断时往往具有自身主观性,并且会耗费巨大精力,误诊的情况时有发生。
临床调查显示,与乳腺X 光线检查和超声检查相比,动态对比增强磁共振成像(dynamic contrastenhanced magnetic resonance imaging,DCE-MRI)在检测乳腺癌方面具有更高的灵敏度(Zhang 等,2019)。此外,由于乳腺癌早期发现可以有效降低死亡率,因此迫切需要一种计算机辅助系统来自动诊断乳腺肿瘤DCE-MRI 影像良恶性,以协助医生进行早期诊断,并在临床实践中制定相应的治疗方案。近年来,深度学习(LeCun 等,2015)备受研究者的关注,并在多个领域取得成功。其中,卷积神经网络(convolutional neural network,CNN)(Krizhevsky 等,2017;Salama和Aly,2021)是代表性的深度学习方法之一。CNN 可以自动地从输入图像中提取出高层次的特征表示,不需要进行手工设计,节省了大量时间和人力(Radosavovic 等,2020)。因此,近年来研究者开始将CNN 应用于乳腺癌自动诊断,大大提高了乳腺癌诊断的准确性(陈弘扬 等,2021)。Antropova 等人(2018a)提出了一种基于4 维动态增强磁共振图像(DCE-MRI)的乳腺肿瘤良恶性分类方法,通过结合递归神经网络(recurrent neural network,RNN)与预训练的卷积神经网络来捕捉二维图像特征以及DCE-MRI 中的时间信息。最终,该方法的AUC(area under the curve)值达到了0.88。Maicas等人(2019)采用教师—学生课程学习策略(teacherstudent curriculum learning strategy)来训练一个3DDenseNet,用于乳腺肿瘤DCE-MRI 影像诊断,最终获得了0.91 的AUC 得分。Ha 等人(2019)开发了一种14 层卷积神经网络算法来根据DCE-MRI 特征预测乳腺癌分子亚型,该算法通过在网络浅层加入残差连接和在网络深层加入多分支卷积层来学习更加复杂的特征映射。最终,该方法准确率为70%,AUC值为0.85。然而,CNN 由于有着局部相关性和权值共享的归纳偏置,存在着感受野受限的缺陷。因此,CNN 只能提取局部特征,缺乏对全局信息的建模能力(邢素霞 等,2023),从而导致CNN 在乳腺肿瘤方面的分类性能受到一定的限制。
最近,有学者开始将Transformer(Vaswani 等,2017)基础上发展起来的视觉Transformer(vision Transformer,ViT)(Dosovitskiy 等,2021)方法应用于图像分类任务,并取得了不错的效果。Gheflati 和Rivaz(2021)使用ViT 对乳腺超声影像进行分类,取得了86.7%的准确率以及0.95 的AUC 得分。Chen等人(2022)首先利用局部ViT 块来分别提取乳腺两侧不同X 线照片特征,再将它们级联起来输入到全局ViT 块中进行乳腺良恶性肿瘤分类,AUC 分数最终达到了0.784。可见,ViT 能够捕捉整幅影像中的全局信息,并且其自注意力机制能够帮助模型关注更加有意义的区域。
由此可见,CNN 只关注捕捉图像局部特性,而ViT 可以捕捉图像全局特性。考虑到这种CNN 与ViT 在特征学习方面的互补性,本文提出一种新的融合CNN 与ViT 的局部—全局跨注意力融合网络(local global cross attention fusion network,LGCAFN),用于实现乳腺肿瘤DCE-MRI 影像诊断。LG-CAFN 方法具有两个特点。1)LG-CAFN 能够将CNN 局部特征捕捉能力和ViT 全局建模能力结合起来,从而使其学习到的深度特征不仅包含全局信息,而且还包含许多局部细节信息;2)在融合CNN 和ViT 学习到的特征时,引入Non-local 注意力模块(Wang 等,2018)进行跨注意力融合,从而得到更加丰富的高层语义信息,用于乳腺肿瘤DCE-MRI 影像分类。此外,目前对于乳腺肿瘤DCE-MRI 影像诊断的研究工作相对较少,并且受到病人隐私、数据标注耗时费力等因素影响,公开而可用的乳腺DCEMRI 数据集非常缺乏(Mahmood 等,2020)。为此,本文收集了232 名良恶性乳腺肿瘤病例DCE-MRI影像,其中有147 名恶性肿瘤病例,85 名良性肿瘤病例,用于评估所采用各种方法的乳腺肿瘤DCEMRI 影像分类性能。在收集的DCE-MRI 数据集上的实验结果表明了所提出LG-CAFN 方法的有效性。
1 数据集介绍
1.1 数据收集
收集的术前DCE-MRI 影像数据来自于中国浙江省台州市中心医院(台州学院附属医院),选取了 2018 年1 月至2022 年9 月间232 例乳腺癌病例,并且所有选取的病例都经过了病理检验确认。
图1展示了良性和恶性病例的DCE-MRI影像说明。每个病例都有3 种序列影像:造影前序列、造影后序列和减影序列。造影前序列是在注射造影剂前扫描得到;造影后序列是在注射造影剂后扫描得到;减影序列是将造影后序列影像减去造影前序列影像得到。两名资深放射科医生检查所有样本,以便只保留乳腺肿瘤边界清晰的病例。
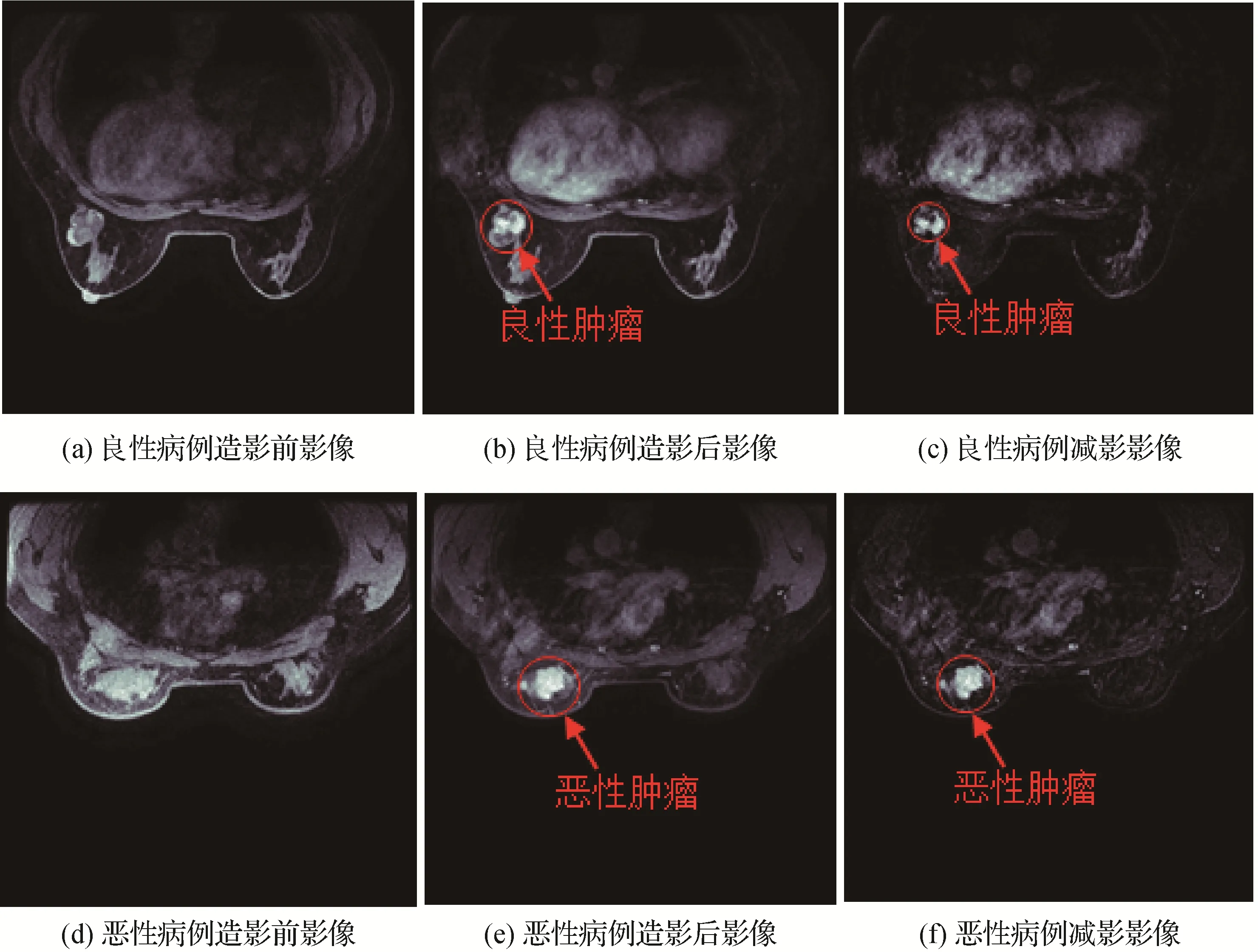
图1 良恶性病例DCE-MRI影像说明Fig.1 An illustration of DCE-MRI images for benign and malignant cases((a)pre-contrast image for benign case;(b)post-contrast image for benign case;(c)subtraction image for benign case;(d)pre-contrast image for malignant case;(e)post-contrast image for malignant case;(f)subtraction image for malignant case)
在收集的232 例病例(29 274 幅影像)中,包括147 例恶性肿瘤病例(21 369 幅影像)和85 例良性肿瘤病例(7 905 幅影像),患者年龄为25~65 岁,平均年龄45 岁。台州市中心医院机构评审委员会已批准本研究,并放弃知情同意。表1 展示了数据集中所有病例的病理检验结果。
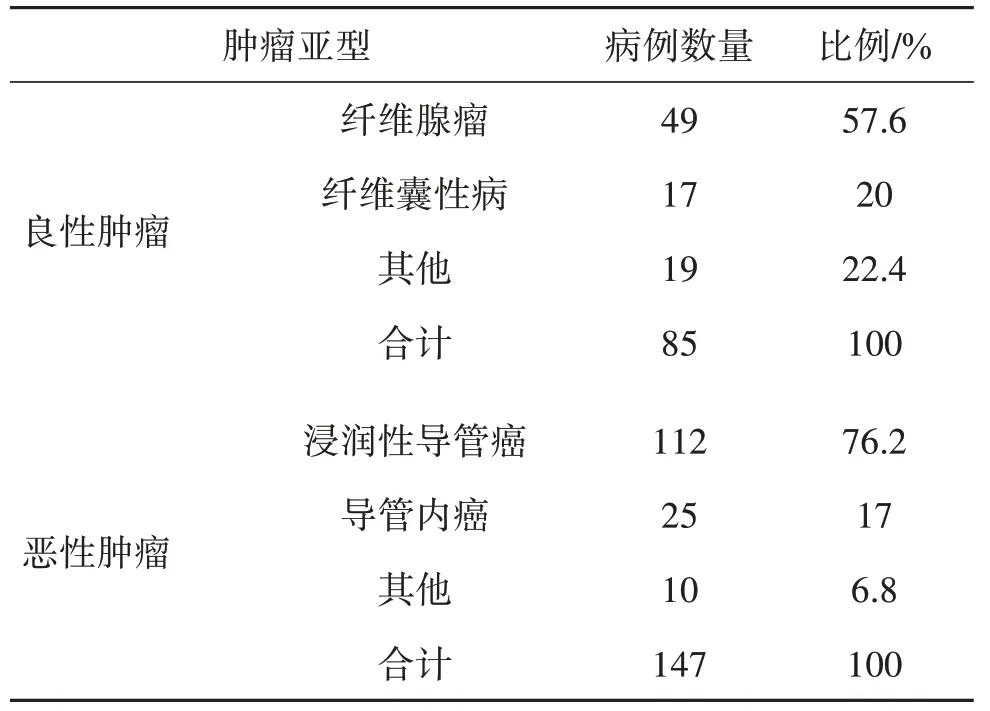
表1 乳腺良恶性肿瘤的病理检验结果Table 1 Pathological examination results of benign and malignant breast tumor
整个数据集按7∶1∶2 的比例随机划分成3 个固定的子集:训练集、验证集和测试集。其中,训练集由166 个病例(20 434 幅影像)组成,包括61 个良性的病例(5 559幅影像)和105个恶性的病例(14 875幅影像)。验证集由19 个病例(1 989 幅影像)组成,包括7 个良性病例(408 幅影像)和12 个恶性病例(1 581 幅影像)。测试集则由47 个病例(6 851 幅影像)组成,包括17个良性病例(1 938幅影像)和30个恶性病例(4 913幅影像)。
1.2 数据预处理和标注
原始乳腺DCE-MRI 影像通常保留为DICOM(digital imaging and communications in medicine)格式,需要专业的阅读软件显示。为此,本文将DICOM 格式转换为RGB 格式。然后采用z-score 方法进行数据归一化,使其平均值为0、标准偏差为1。
在影像标注方面,每个病例都请两位临床经验超过10 年的放射科医生进行标注以得到包含乳腺肿瘤区域影像范围。然后,标注结果再由一位具有20 多年经验的放射科医生进行验证。由于乳腺DCE-MRI 影像还包括肺、心、肝等其他器官,因此需要将乳腺区域与其他器官分离。为此,放射科医生用最小长方体框手工标注所有肿瘤,每个肿瘤区域都被一个感兴趣区域(region of interest,ROI)覆盖并标记出来。
2 LG-CAFN网络结构设计
CNN 网络只关注图像中局部特征学习,而ViT网络更多地关注图像中全局特征学习(Peng 等,2021)。这表明CNN 和Transformer 网络在特征学习任务上具有潜在的互补性。受此启发,本文提出了一种局部—全局跨注意力融合网络(local global cross attention fusion network,LG-CAFN)。它整合了CNN 和Transformer 网络在特征学习方面各自优势,用于分类乳腺良性和恶性肿瘤。为此,采用典型的SENet(squeeze-and-excitation network)(Hu 等,2018)作为CNN子网络,将ViT作为Transformer子网络。
所提出的LG-CAFN 网络架构示如图2 所示。LG-CAFN 包含两个不同的分支:一个是局部CNN 子网络(即SENet),用于捕捉图像局部特征信息;另一个是全局Transformer 子网络(即ViT),用于捕获图像全局特征信息。由于从这两个分支中提取的特征图尺寸通常不能匹配,从而导致它们不能直接输入到下游的跨注意力融合模块。
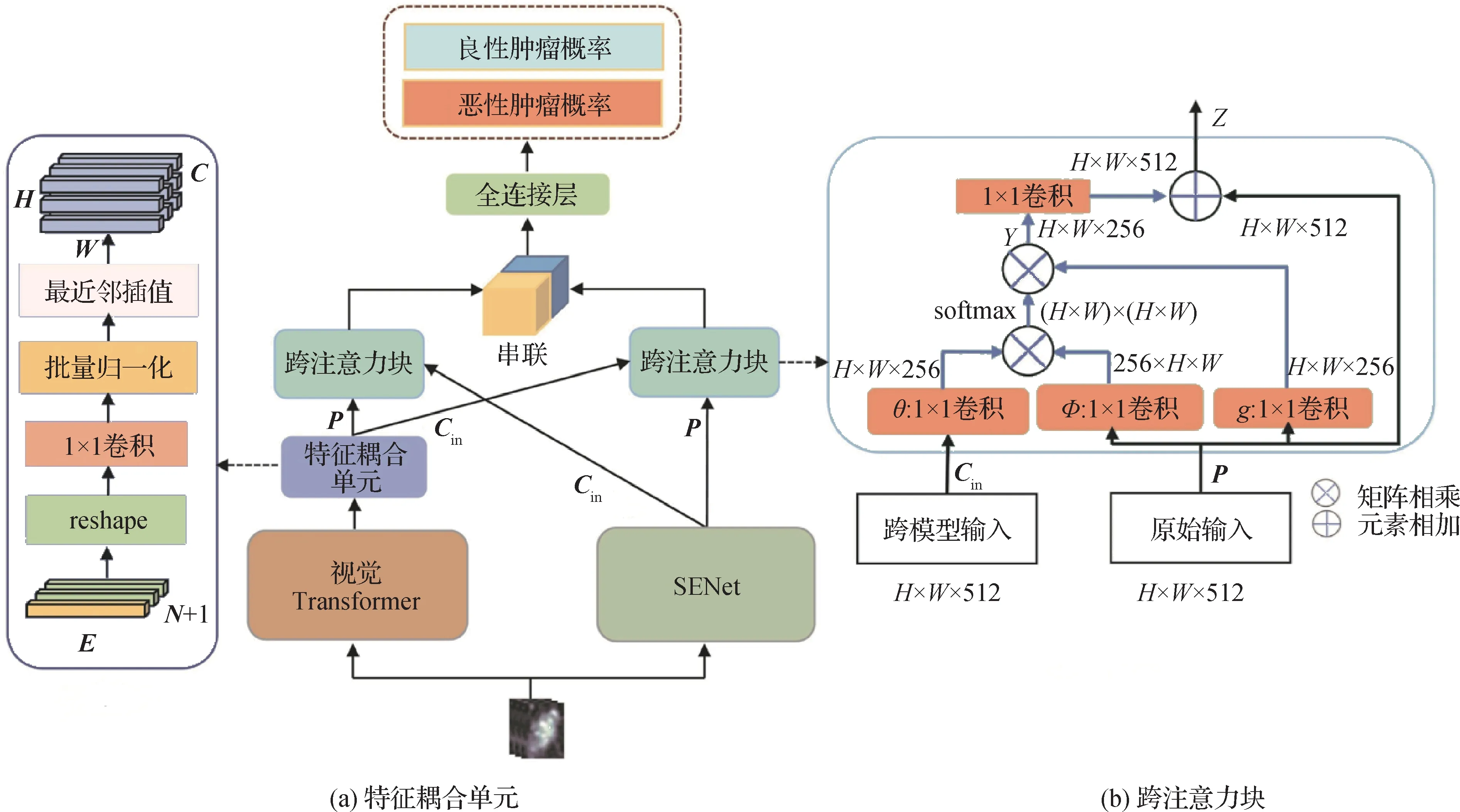
图2 提出的LG-CAFN架构示意图Fig.2 An illustration of the proposed local-global cross attention fusion network(LG-CAFN)architecture
为此,采用一个特征耦合单元(feature coupling unit,FCU)(Peng等,2021)来解决这两个分支之间的特征尺寸不一致问题,如图2(a)所示。对于跨注意力融合模块,采用Non-local 神经网络(Wang 等,2018)中Non-local 注意力模块作为基本模块,因为它具有良好的捕捉长距离信息依赖能力。然而,原始Non-local 注意力模块只计算一个单独输入所产生特征图上任意位置之间的依赖关系。为了解决这个问题,将Non-local 注意力模块中的单独输入扩展为两个不同输入,包括一个原始输入和一个跨模型输入,如图2(b)所示。这样,跨注意力融合模块可以计算来自两个不同输入特征图之间的自注意力,从而有效地融合来自SENet 子网络的局部特征信息和ViT 子网络的全局特征信息,获得具有判别力的图像特征,用于后续乳腺良恶肿瘤分类。
LG-CAFN 中的3 个关键部分:局部CNN 和全局ViT 分支结构、特征耦合单元以及跨注意力融合,具体表述如下。
2.1 局部CNN和全局ViT分支结构
局部CNN 分支采用SENet50来捕捉图像中局部特征信息,因为SENet50 能够通过其自身的局部通道注意力机制有效地学习局部特征信息。此外,与其他典型的CNN 模型,如ResNet50(residual network 50)(He 等,2016)相比,SENet50(Hu 等,2018)通常表现出更好的分类性能。值得注意的是,原始SENet50将产生2 048维特征。为了减少SENet50输出特征维度,采用原始SENet50前两个阶段(stage-1,stage-2)作为本文局部CNN 子网络。SENet50 中每个阶段都是由一定数量的残差块(residual block)(He 等,2016)和SE 块(SEblock)(Hu 等,2018)组成。每个残差块由1 个1 × 1 卷积、1 个3 × 3 卷积和一个1 × 1 卷积组成。每个SE 块由1 个全局平均池化层(global average pooling,GAP)、2 个全连接层和sigmoid 激活函数构成。本文将SENet50 中阶段1(stage-1)和阶段2(stage-2)中残差块和SE 块的数量分别设定为3 和4。最后,采用这两个阶段的SENet50输出特征维度是 1 024维。
全局ViT 分支包含一定数量的编码器层。每个编码器包括2 个LayerNorms、1 个多头自注意力模块(multi-head self-attention,MSA)和1 个多层感知机(multi-layer perception,MLP)。残差连接用于自注意力层和MLP。本文采用7 层ViT(ViT-7)作为全局ViT 分支,因为ViT-7 表现最佳。最后,ViT-7 输出特征维度为768维。
2.2 特征耦合单元
为了解决SENet 和ViT 输出特征图维度不匹配问题,采用特征耦合单元(feature coupling unit,FCU)来实现,如图2(a)所示。具体来说,SENet 输出特征图尺寸是C×H×W,其中C,H,W分别是通道、高度和宽度。然而,ViT 输出特征维度是(N+1)×E,其中N,1,E分别代表图像分块(image patch)数量、人工设计类别向量和图像嵌入(embedding)维度。为了使得SENet和ViT输出特征图维度相匹配,首先将ViT 特征维度重塑(reshape)为然后,通过1 个1 × 1 卷积来对齐SENet 特征图通道大小。接着,使用批量归一化层(batchnorm,BN)来实现特征图归一化预处理。最后,采用最近邻插值法(nearest neighbor interpolation)(Jiang 和 Wang,2015;Khandelwal 等,2021)来对齐SENet 特征图空间尺度,从而实现SENet 和ViT 输出的特征维度一致性。
2.3 跨注意力融合
为了融合来自CNN 分支和ViT分支输出的特征图,设置一个跨注意力融合模块,如图2(b)所示。该模块有两个输入特征图:原始输入P∈RH×W×512和跨模型输入Cin∈RH×W×512,其中H、W和512 分别代表特征图的高度、宽度和通道数。跨模型特征注意力的计算为
式中,ci和pj分别是输入Cin和P在位置i和j的特征。θ(x)、φ(x)和g(x)是3 个简单线性投影。softmax函数用来计算ci和pi之间的相关性分数。所得结果yi是一个加权相关性汇总,即输入P中所有位置与跨模型输入特征中位置i之间的相关性。矩阵Y由yi组成,它集成了P和Cin的所有位置之间的关系,而最终输出Z是Y和P的元素相加。
3 实验及结果分析
3.1 实验设置
实验环境采用深度学习框架PyTorch(Paszke 等,2019),在NVIDIA RTX 3090(24 GB)GPU 上进行。训练时,使用了数据增强策略,如数据翻转、数据缩放、数据剪切和改变对比度等,来加强模型的泛化能力。由于乳腺组织一般结构不具有旋转不变性,因此没有采用图像旋转来进行数据增强。每一个批次数量(batchsize)设定为32。训练epoch 次数设为100,损失函数为交叉熵(cross-entropy)损失函数,优化算法选择随机梯度下降算法(stochastic gradient descent,SGD)(Liu等,2020)。为了降低数据量不足的缺点,采用迁移学习方法来初始化深度学习模型参数。所有使用的深度学习模型网络参数都是采用ImageNet(ImageNet large scale visual recognition challenge)数据集上预训练好的模型参数来初始化,然后采用微调策略进行迁移学习。
3.2 评价指标
采用准确率、灵敏度、特异性和AUC等4种常用评价指标来对所有模型的性能进行综合评价。
3.3 与其他方法对比
为了验证乳腺肿瘤DCE-MRI 3 种序列(造影前序列、造影后序列、减影序列)的有效性以及模型的鲁棒性,本文设置了两组实验(实验1和实验2)来评估所有使用方法的性能。具体实验设置如下:
1)实验1。对于每个病例,获得1个造影前序列和8 个造影后序列来进行第1 组实验。具体的做法是将这9 个序列在通道维度上进行拼接,以得到最终网络输入尺寸为9 × 96 × 96。
2)实验2。对于每个病例,获得1个造影前序列和8 个造影后序列以及它们对应的减影序列来进行本组实验。最终网络输入尺寸为17 × 96 × 96。
为了评价本文方法的有效性,采用下列方法用于性能比较。
1)VGG16(Visual Geometry Group 16-layer network)(Simonyan 和Zisserman,2015)。VGG16 是一种深度卷积神经网络,由16 个卷积层和3 个全连接层组成,以更深更窄的网络结构取代以往更宽更浅的网络结构。
2)ResNet50(He 等,2016)。ResNet50 是一种深度卷积神经网络,由50 个卷积层和全连接层组成,其中引入了残差模块来解决深度网络退化问题。
3)SENet50(Hu 等,2018)。SENet50 结构是ResNet50 改进版,通过引入“压缩—激励”模块来进一步提升网络性能。
4)Vision Transformer(Dosovitskiy 等,2021)。Vision Transformer(ViT)是一种基于自注意力机制的图像分类模型,使用Transformer 编码器来提取特征,并通过多头注意力机制进行全局感知,从而实现对图像的分类。
5)Swin-Transformer(Liu 等,2021)。Swin-Transformer 是一种基于移动窗口的Transformer,通过分组局部注意力机制和跨组特征共享来更好地处理图像。
6)RegNet(regularized network)(Radosavovic 等,2020)。RegNet 使用一种基于强化学习的方法,通过对神经网络结构超参数进行搜索和学习,自动地学习到一个可行的神经网络结构空间,有效地减少人工设计神经网络的工作量。
7)ConvNeXt(convolutional next)(Liu 等,2022)。ConvNeXt 按照ViT 训练策略在CNN 网络结构上进行优化,并使用了分组卷积、逆瓶颈层和更大的卷积核尺寸来构建整个网络结构。
8)MobileViT(mobile vision Transformer)(Mehta和Rastegari,2022)。MobileViT 是一种轻量化的结合CNN 和Transformer 的高效网络模型,其将CNN 局部特征提取用Transformer 全局特征提取代替,得到更加强大的特征信息提取能力。
表2 展示了两组实验的对比结果。其中,ViT-7代表7 层ViT 模型,Swin-S 为swin-Transformer-small。由于DCE-MRI 影像具有高灵敏度和低特异性的特点(Antropova 等,2018b),本文将准确率(accuracy)和 AUC 作为主要评价指标进行比较,而其他评价指标可以作为参考。从表2 的结果中,可以得出以下几点结论:
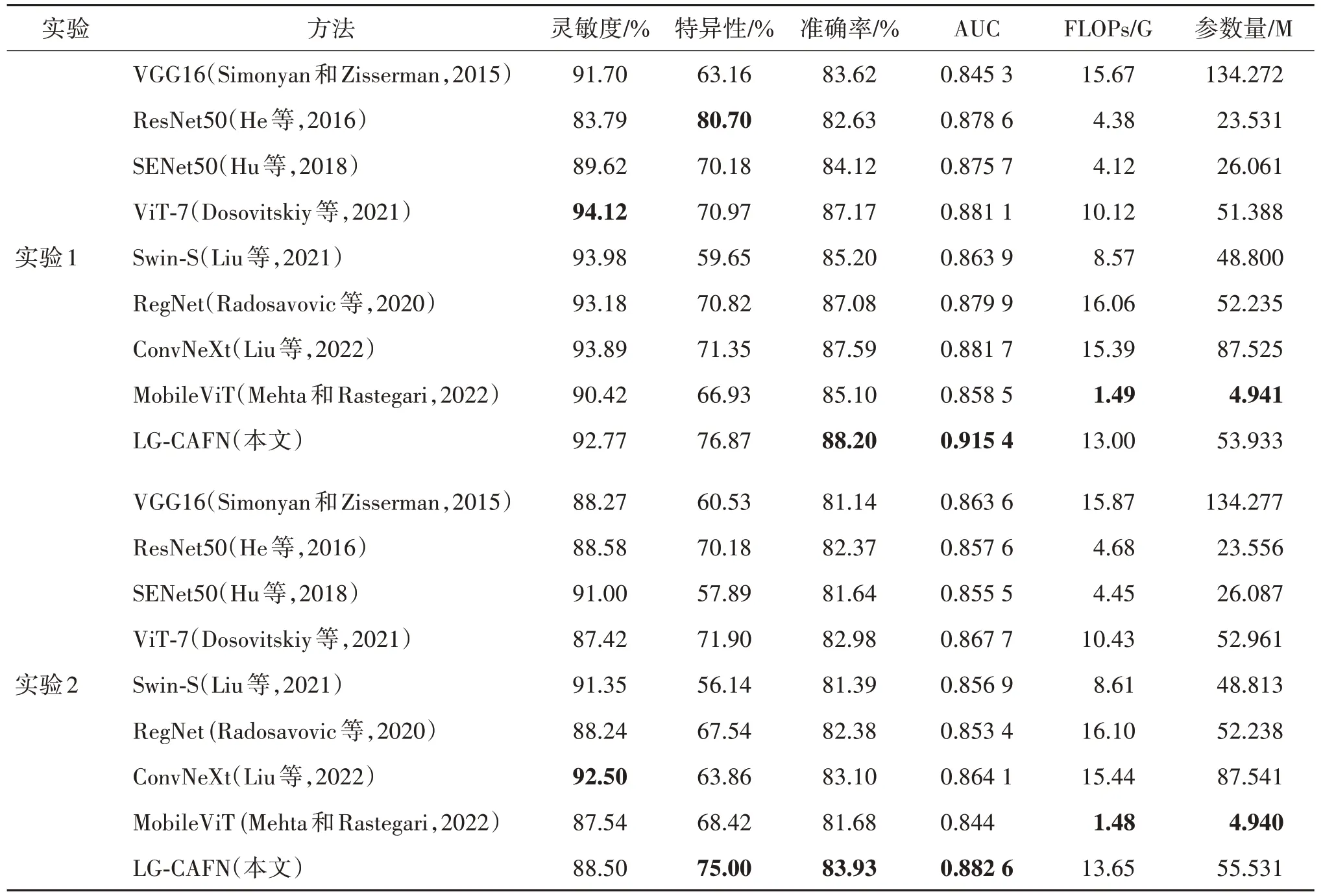
表2 不同方法在两组实验中的性能比较Table 2 Performance comparison of different methods in two sets of experiments
1)在所有使用的分类方法中,LG-CAFN 在两组实验中的主要评价指标,如准确率及AUC 值,都取得了最高的性能。具体来说,LG-CAFN 在实验1 中的准确率为88.20%,在实验2 中为83.93%。其相应的AUC 值在实验1 中为0.915 4,在实验2 中为0.882 6。这表明LG-CAFN 在乳腺肿瘤良恶性分类任务上优于其他方法。此外,ConvNeXt(Liu 等,2022)在两组实验中取得的准确率和AUC 值仅低于本文方法,得益于其使用了分组卷积、逆瓶颈层和更大的卷积核尺寸。
2)ViT-7(Dosovitskiy 等,2021)在实验1 中取得的灵敏度最高,为94.12%,比本文方法(92.77%)高1.4%。然而其特异性仅为70.97%,比本文方法(76.87%)低6%左右;ConvNeXt 在实验2 中的灵敏度最高,为92.5%,比本文方法(92.77%)高4%。然而其特异性仅为63.86%,远低于本文方法(75%)。在特异性方面,本文方法也取得了优秀的表现,在实验1 中仅低于ResNet50 约4%,且在实验2 中取得了最好的结果。
3)LG-CAFN 的参数 量(Params)和计算 量(FLOPs)平均为54.5 M和13.3 G。本文方法是通过融合SENet50 和ViT-7 得到的,因此,较于SENet50和ViT-7 来说,参数量和计算量略高于二者。但是,本文方法在实验1 中的Acc 以及AUC 上取得的性能指标分别是88.20%,0.915 4;在实验2中为83.93%和0.882 6,明显优于SENet50 和ViT-7。此外,由于MobileViT(Mehta 和Rastegari,2022)是一种轻量化的网络模型,其参数量以及计算量都为最低,平均为4.94 M和1.475 G。
4)在实验1 中没有减影序列的情况下,模型性能优于实验2 中的加入减影序列。这表明减影序列不能有效提高乳腺肿瘤分类任务的性能。这可能是由于减影序列是通过减去造影前序列和造影后序列实现,将会丢失肿瘤部分特征信息,不能为乳腺肿瘤分类提供有效的判别信息。
为了直观地理解和分析基于深度学习模型决策过程,采用梯度加权类别激活图(gradient-weighted class activation map,Grad-CAM)(Selvaraju 等,2017)来可视化这些深度模型中最后一个卷积层的学习特征表示,如图3 所示。Grad-CAM 可以解释为图像中每个位置对网络预测输出的贡献分布,一个区域获得分数越高,即说明这个区域对模型的预测输出贡献越大,其在可视化结果中颜色越深。从图3 中可以看出,基于CNN 的模型,例如VGG16、ResNet50、SENet50、RegNet 和ConvNeXt 得到的类激活图中深色区域基本集中于图像局部,而基于Transformer 的模型,例如ViT-7、Swin-S 和MobileViT 得到的类激活图中深色区域则分布在图像全局。此外,与这些模型相比,LG-CAFN 所产生的类激活图能够很好地融合局部和全局的信息,使得深色区域分布得更加合理。
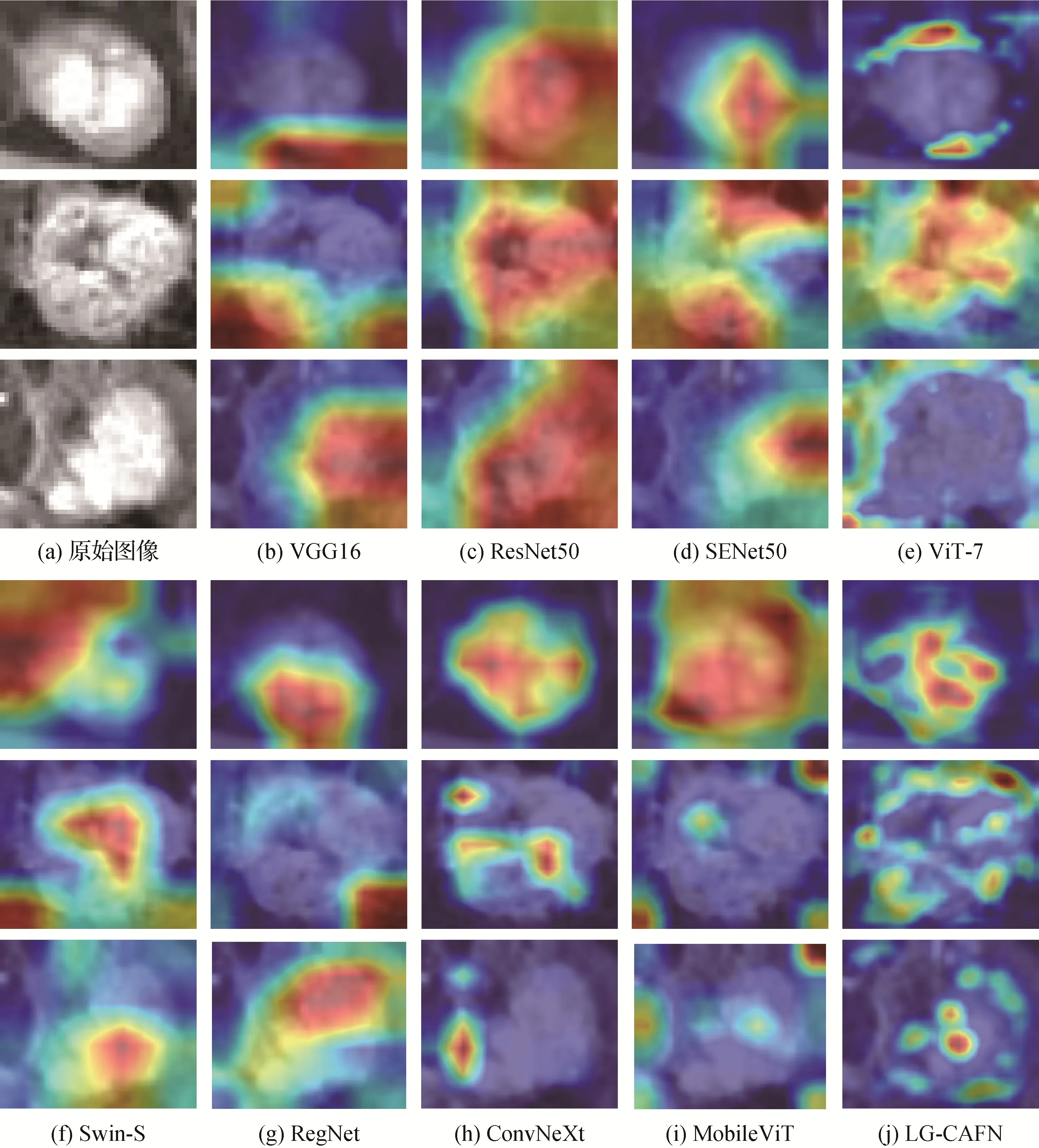
图3 不同模型中学习到的特征表征的可视化结果Fig.3 The visualization results of learned feature representations in different used models((a)original images;(b)VGG16;(c)ResNet50;(d)SENet50;(e)ViT-7;(f)Swin-S;(g)RegNet;(h)ConvNeXt;(i)MobileViT;(j)LG-CAFN)
3.4 消融实验
为了验证本文LG-CAFN 方法的有效性,表3 列出了3 种不同融合方法的性能比较,如特征层融合、决策层融合和本文LG-CAFN 方法。特征层融合是将SENet50 和ViT-7 输出特征图直接串联起来,然后将其输入一个RBF(radial basis function)核的支持向量机(support vector machine,SVM)(Wang 等,2008)分类器,从而实现对乳腺良性和恶性肿瘤分类。决策层融合是采用最大值运算规则将SENet50和ViT-7分别获得的分类概率中最大值作为最终分类概率。从表3可以看出,LG-CAFN 在实验1和实验2中都表现最好。与特征层融合和决策层融合相比,LGCAFN 方法取得了最高的准确率、特异性以及AUC得分。
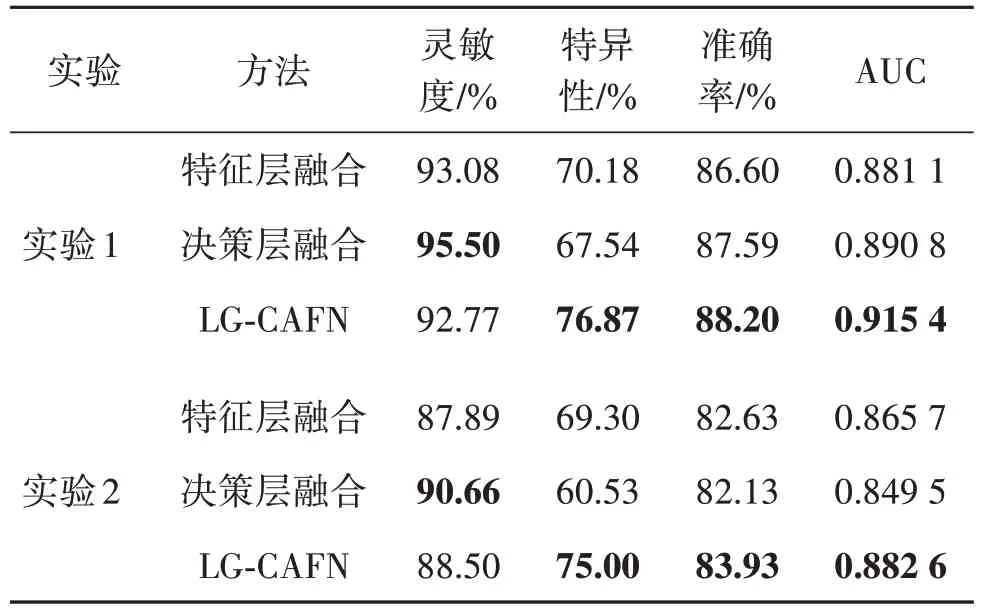
表3 不同方法融合SENet50和ViT-7时的性能比较Table 3 Performance comparisons of different fusion methods when integrating SENet50 and ViT-7
另外,在两组实验中,决策层融合方法能够得到最高灵敏度95.5%和90.6%,平均比LG-CAFN 高3%。图4(a)(b)分别显示了两组实验中不同方法融合SENet50 和ViT-7 时获得的ROC 曲线比较。图4(a)(b)的结果表明,LG-CAFN 方法可以有效地融合SENet 获得的局部特征信息和ViT 获得的全局特征信息,从而产生比SENet50 和ViT-7 更有效的特征表示用于肿瘤分类任务。这证明了本文提出的LGCAFN 方法比SENet50和ViT-7更有优势。主要原因是LG-CAFN 使用的跨注意力融合模块能够计算来自两个不同输入特征图之间的自我注意力,以便共同学习来自SENet50 局部特征信息和来自ViT-7 全局特征信息。
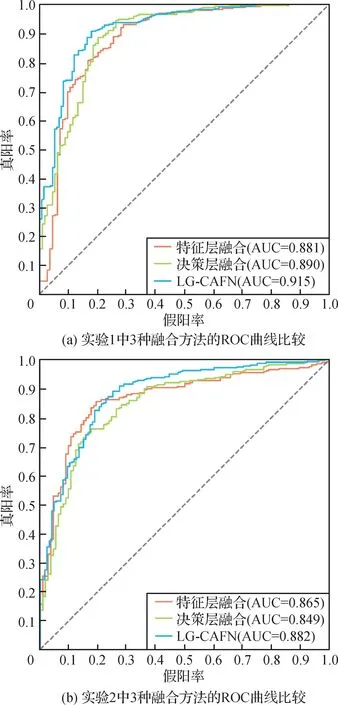
图4 两组实验的不同融合方法的ROC曲线比较Fig.4 Comparisons of the ROC curves of three fusion methods in two sets of experiment((a)comparison of ROC curves for the three fusion methods in experiment 1;(b)comparison of ROC curves for the three fusion methods in experiment 2)
4 结论
为了充分利用CNN 网络局部特征学习能力以及ViT 网络全局特征学习优势,本文提出了一种局部—全局跨注意力融合网络LG-CAFN,以提升DCEMRI 乳腺肿瘤影像良恶性分类性能。在收集的DCE-MRI 数据集实验结果表明,LG-CAFN 在两组实验中取得的准确率和AUC 明显优于其他方法。同时,对于模型特征表征可视化结果增强了LG-CAFN分类结果的可解释性,进一步表明了LG-CAFN 的有效性。实验结果表明,LG-CAFN 模型能够有效提高DCE-MRI乳腺肿瘤良恶性诊断准确率和效率。
虽然LG-CAFN 模型在DCE-MRI 乳腺肿瘤影像诊断中取得了优异性能,但是该方法仍然有一些局限性。首先,本文方法假阴率(即漏诊率)较低,但假阳率(即误诊率)较高,在实验1 和实验2 中分别为23.2%和25%。原因在于:1)良性乳腺肿瘤中有部分肿瘤尺寸极小,很难进行识别。同时,也受到DCE-MRI 影像高灵敏度和低特异性特点的影响。2)受到良性肿瘤病例数不足的影响。同样地,这些原因也是乳腺良恶性肿瘤诊断难点。其次,在网络参数量和计算量方面,本文方法仍然有可以优化的地方,例如:使用可以代替自注意力机制的其他注意力方法,以减少参数量和计算量。
在接下来的工作中,一方面,考虑与医院进行进一步合作,利用LG-CAFN 方法帮助医生进行临床诊断并且扩展到其他医学图像诊断任务中,如乳腺超声影像、计算机断层扫描(computed tomography,CT)影像等;另一方面,在今后的研究方向上,考虑将LG-CAFN 模型扩展到DCE-MRI 乳腺肿瘤影像自动分割任务中,辅助医生更加高效地进行临床诊断。
猜你喜欢
数学物理学报(2022年4期)2022-08-22 04:07:12
数学物理学报(2022年2期)2022-04-26 14:08:04
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
中国生殖健康(2019年5期)2019-01-06 09:16:36
金桥(2018年4期)2018-09-26 02:24:54
传媒评论(2017年3期)2017-06-13 09:18:10
妈妈宝宝(2017年2期)2017-02-21 01:21:22
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
中国医学科学院学报(2015年5期)2015-03-01 04:03:43
中国卫生(2014年5期)2014-11-10 02:11:26
