
基于多传感器融合的协同感知方法
2024-01-21 13:15王秉路周天飞
雷达学报 2024年1期
王秉路 靳 杨 张 磊 郑 乐 周天飞
①(西安建筑科技大学信息与控制工程学院 西安 710399)
②(北京理工大学信息与电子学院 北京 100081)
③(西北工业大学自动化学院 西安 710129)
④(北京理工大学计算机学院 北京 100081)
1 引言
协同感知是自动驾驶领域中的一个关键问题,它允许自动驾驶车辆通过车载传感器收集环境信息并通过车对车(Vehicle-to-Vehicle,V2V)无线通信技术与其他车辆进行实时共享,从而实现更强大和全面的环境感知能力[1-3]。协同感知任务的目标是利用多个车辆作为移动传感器网构建高精度的多点观测场景表征,以增强车辆在车队协同、交通流优化、自动驾驶辅助和自动驾驶等应用场景下的感知能力[4]。相对于传统的单车智能,多车协同感知可以更好地应对复杂的交通场景,提高自动驾驶系统的决策准确性和行驶安全性。
早期的研究主要基于单一传感器模式,如仅使用激光雷达[5-14]或仅使用相机[15,16]进行环境感知。然而,这些单模态方法未能充分利用两种传感器的互补优势,限制了感知系统的性能。例如,基于纯激光雷达的方法可能会忽略相机传感器捕捉到的细粒度视觉细节,这些细节对于一些特殊情境的目标检测和识别至关重要。此外,相机可以捕捉到颜色、纹理和形状等物体的视觉特征,这些特征对于识别特定类别的目标非常有帮助,如识别交通标志或行人。另外,基于纯相机的方法虽然能够提供丰富的语义信息,但通常缺乏对于精确目标定位至关重要的准确深度信息,这导致了在三维环境感知方面的一些挑战,如避免碰撞或进行高精度的车道保持,而激光雷达能够提供准确的距离和深度测量。此外,在低光或恶劣天气条件下,相机可能受到限制,而激光雷达(Light Detection and Ranging,LiDAR)能够继续提供有用的几何信息,因此在这些场景中具有独特的优势[17]。
为了克服单传感器的局限性,近年来,研究人员开始探索基于多传感器融合的感知方法[18-23]。这些方法旨在将LiDAR和相机的优势结合起来,以获得更全面、准确的环境感知。PointPainting[19]首次将图像上的语义信息附加到激光雷达点上实现不同模态的点级融合。BEVFusion[20,21]探索了适合多模态特征融合的统一表示,即将LiDAR模态和相机模态转换到一个共享的鸟瞰(Bird’s Eye View,BEV)空间实现融合。
先前的研究已经证明了融合LiDAR和相机数据的优势,包括改进的目标检测、增强的场景理解以及在具有挑战性的环境条件下的稳健性能。然而,当涉及多车协同感知任务时,在多模态融合方面的探索仍然非常有限。最近提出的HM-ViT[24]是多车协同感知在多模态融合方面的初期探索,它假设每个车辆只能获取任意一种模态,并基于此设定来实现不同车辆之间的异构模态融合。
尽管现有文献中已有大量关于多模态的研究,但在协同感知领域中,对于多模态交互的深入探讨仍显不足。为了更全面地利用不同类型传感器的互补优势,本文构建了一个多模态融合的基线系统,作为实现协同感知的基础框架。该基线系统采用了一种集成激光雷达和相机数据的方法,通过将两种传感器的数据融合到同一表示空间中,能够利用激光雷达提供的精确深度信息和相机提供的丰富视觉特征,实现更准确、更稳健的环境感知。在构建该基线系统时,本文考虑了多种不同的融合策略,并进行了深入的分析。首先,采用了通道级拼接和元素级求和方法,这两种方法简单直观,能够将来自不同传感器的特征直接拼接在一起,形成一个统一的特征表示。虽然这种方法在某些情况下能够取得良好的性能,但它也有一定的局限性,主要表现在不能充分考虑到不同传感器数据之间的相关性。为了解决这一问题,本文进一步探索了基于注意力机制的融合方法,这种方法能够自适应地调整不同传感器数据的权重,从而更好地捕捉它们之间的相关性。通过多头自注意力机制,所提算法能够在不同的传感器特征之间建立复杂的关联,从而实现更精细的融合。在OPV2V[8]数据集上的实验结果表明,这种基于注意力机制的融合方法相比传统的融合方法,在协同感知任务中展现出更优越的性能和更强的鲁棒性。
2 传统协同感知范式回顾
考虑了一个具有N个智能网联车的协同感知场景,其中每个车辆配有车载传感器(LiDAR或相机)获取局部观测数据(3D点云或图像)并通过无线通信网络进行交互和协作。具体来说,假设A={a1,a2,...,aN}为所有N个车辆的集合,集合中的第i个车辆ai为中心车辆,则与其进行协作的其他车辆集合定义为J={aj}j∈[N]{i}。传统的协同感知范式主要由特征提取、特征融合以及检测头网络组成。假设车辆ai的局部观测数据为Oi,首先,特征提取负责根据Oi提取相应的中间层特征表示Fi:
然后,车辆ai将自身的特征Fi与来自其他车辆的特征{Fj}j∈J通过特征融合获得更全面的特征表示Hi:
最后,将融合后的特征Hi送入检测头网络生成预测结果Yi:
然而,现有的协同感知范式存在一些局限性。首先,模态的单一性忽略了其他模态所提供的有用信息。其次,现有特征融合策略都相对简单,通常是简单的平均或者加权平均,这可能会导致某些重要的特征在融合过程中被淡化或丢失。这些局限性为进一步的研究和优化提供了机会。
3 多模态融合的协同感知方法
本节,对所提出的多模态融合协同感知框架进行了概述。图1展示了该框架的核心组成部分,涵盖多模态特征提取、多模态特征融合以及检测头网络。各组成部分共同协作,实现LiDAR与相机数据的有效整合,充分挖掘二者的互补性,以提高V2V场景下的感知准确性。
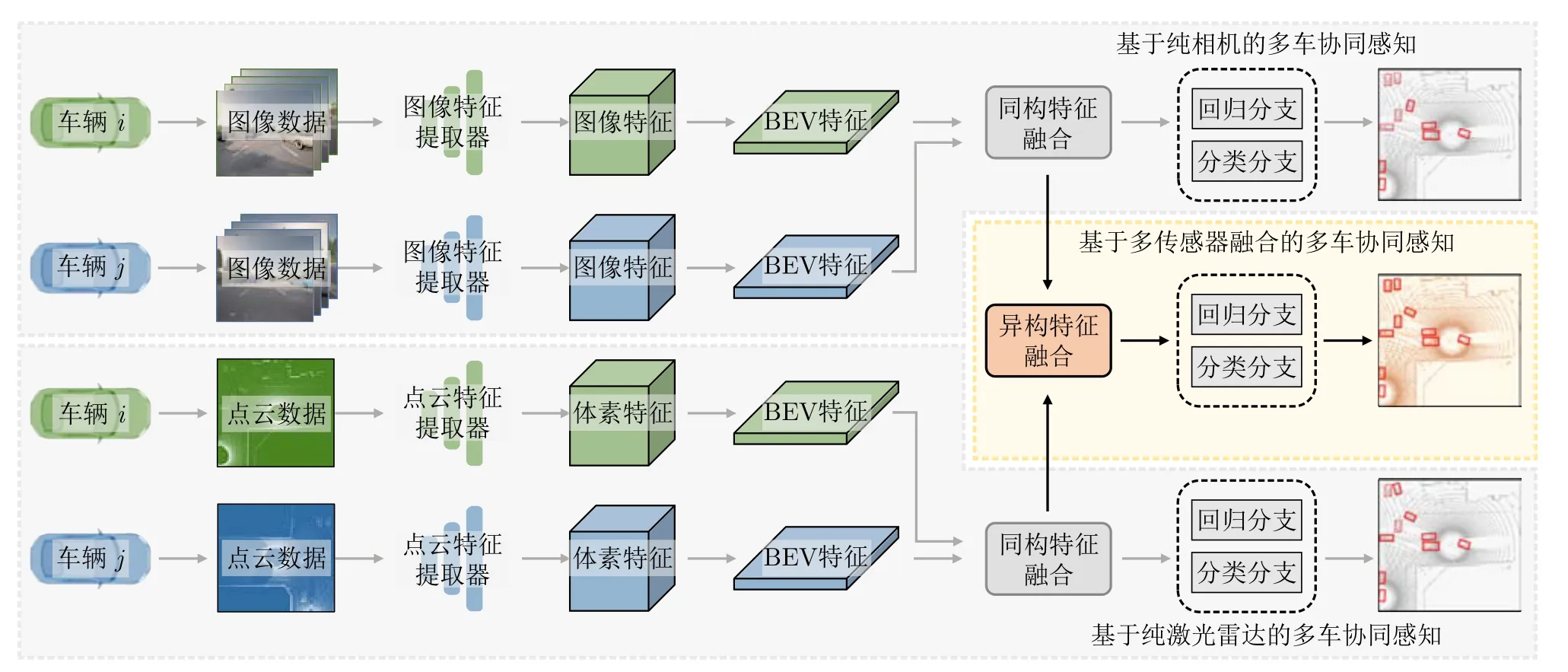
图1 多传感器融合的协同感知框架Fig.1 Multisensor fusion collaborative perception framework
3.1 多模态特征提取
为了捕捉和保留来自不同模态的独特线索,本文使用单独的分支进行特征提取并生成统一的BEV表示。
对于多视角图像数据,本文采用CaDDN (Categorical Depth Distribution Network)[25]架构,该架构包含4个主要模块:编码器、深度估计、体素变换和折叠,确保从输入图像中捕捉到尽可能丰富和准确的信息。为了将2D图像特征和3D点云特征这两种异构特征进行融合,需要显式地预测图像特征中每个像素的深度来将2D平面提升到3D空间,最终转换到统一的BEV空间。以车辆ai为例,首先,编码器模块对原始的输入图像Ii ∈Rh×w×3进行初步的特征抽取,生成维度为X×Y×D的图像特征该过程可以表示为
然后,深度估计模块为每个像素预测出一个深度概率分布P,可以表示为
该分布反映了该像素的深度信息。之后,体素转换模块将先前抽取的特征从2D投影到3D空间。它根据所有可能的深度分布和图像的校准矩阵,生成的相应的3D体素特征:
最后,折叠模块将3D体素特征合并到一个高度平面上
BiI其中,为生成的BEV特征图,H和W表示图像BEV网格的高度和宽度,C表示通道数。该过程可以有效地获取语义丰富的视觉特征。
在处理点云数据时,由于其特有的稀疏性与三维结构,直接利用传统的3D卷积网络很可能引发计算和内存的巨大开销。为了有效而高效地从这种数据中提取特征,本文将PointPillar[26]作为点云数据的特征提取器。首先,对于给定的3D点p ∈R3,其在柱状坐标系中的位置可以被定位为p=(i,j,l)。这里,i和j分别是二维网格的x和y坐标,而l表示其垂直方向上的高度。然后,将这三维空间划分为一系列均匀间隔的柱状结构。形式上,这种划分可以表示为
其中,Wpillar和Hpillar分别表示柱状体在x和y方向上的宽度和高度。通过这种方式可以将复杂的3D数据转换为2D的结构,每一个柱子内的点共享相同的高度信息。随后,所有柱状体沿其高度方向被压平,生成一个伪图像。对于柱状体内的所有3D点,其对应的3D特征为
(其中,Np是柱体中点的数量,Cp是点云特征的维度)被转化为2D柱体特征
其中,φ(·)是转换函数,用于将柱体内所有的点转换为该柱体的整体表示。最后,通过一系列二维卷积对Fpillar进行进一步的特征编码与整合,得到维度为H×W×C的BEV特征其维度与图像BEV特征相同。
3.2 多模态特征融合
随着从激光雷达和相机中提取的BEV特征的获取,特征融合环节成为关键。在这一阶段,各车辆首先对自身的BEV特征进行压缩编码,然后向中心车辆发送。当中心车辆成功接收来自所有其他车辆的BEV特征后,将这些多模态信息进行有策略的融合,生成一个更为全局和详尽的场景表示。该融合过程主要涉及两个关键步骤:同构特征融合与异构特征融合。其中同构特征融合主要处理来自相同传感器类型的信息,而异构特征融合则旨在结合不同类型传感器的信息,充分挖掘不同模态之间的互补性。
3.2.1 同构模态特征融合
在多模态间的特征融合中,同构特征的融合显然比异构特征更为直观和简单,因为它们来自相同的数据源,共享相似的特性和分布。针对这一特点,本文为图像BEV特征和点云BEV特征分别设计了不同的融合策略,以更直接的方式整合同一模态下的多源信息。
首先,受文献[16]的启发,本文采用了元素级的最大化操作来融合不同车辆的图像BEV特征。其背后的原理是:在多车协同的环境中,某些车辆观察到的某些特征可能比其他车辆更为明显或清晰。而通过比较每个车辆的图像BEV特征,并采用元素级的最大值,可以确保最终融合的特征包含了所有车辆观察到的最显著特点。具体来说,当中心车辆收到其他车辆发送的图像BEV特征时,会逐元素地将其与自身的图像BEV特征进行逐元素比较,然后选取最大值作为融合结果。该过程可表示为
其中,max(·)操作是逐元素执行的,这种方式确保融合后的特征继承了多个车辆中最为显著和丰富的部分。
对于点云BEV特征,本文遵循文献[8]利用自注意力机制进行融合。点云BEV特征的融合首先涉及构建本地图的构建。本地图连接了来自不同车辆但处于相同空间位置的特征向量。在这个过程中,每个特征向量被视为一个节点,两个特征向量之间的边用于连接来自不同车辆的相同空间位置的特征向量,这样的连接不仅有助于融合来自不同数据源的信息,同时也为后续的自注意力机制处理提供了基础。
然后,对该本地图应用自注意力机制进行点云BEV特征融合。自注意力机制的核心在于其能够赋予不同特征向量以不同的权重,这些权重反映了特征之间的相互依赖关系。在点云BEV特征的情境下,这意味着每个特征点不仅被其自身属性所定义,还受到周围特征点的影响。具体而言,对于每个车辆的点云BEV特征将该二维特征图展开为维度为M×C的一维特征向量,其中M=H×W。接着,该特征向量会被转换成查询(Q)、键(K)和值(V)3部分,进而通过自注意力公式计算得到更新后的特征向量这一过程可以描述为
其中,dk是键向量的维度,softmax(·)函数则确保所有权重加起来为1。最后将更新后的特征向量变换为原始维度H×W×C。按照以上方式更新所有车辆的BEV特征并堆叠起来得到融合结果RH×W×3C。
通过多源同构模态特征的融合,所得到的融合特征更好地整合和表达了来自多个车辆相同传感器的观测信息,从多个角度捕获了环境细节的丰富性和多样性。同时,这也为后续进行异构特征融合奠定了坚实基础。深度融合不同传感模态之间的互补信息可以进一步丰富环境描述,充分发挥各类传感资源的价值。
3.2.2 异构模态特征融合
在异构模态融合阶段,本文整合了不同模态的融合BEV特征,以利用激光雷达和相机数据之间的互补信息。本文采用3种常见的融合策略:通道级拼接、元素级求和以及Transformer融合,以有效地组合模态并生成综合表示。具体来说,给定融合后的图像特征和点云特征融合过程如下:
(1) 通道级拼接融合。通道级拼接是一种直观且广泛应用的特征融合方法。这种方法主要依赖于特征的空间一致性,即相同的空间位置上来自不同模态的特征被认为是相关的。在通道级拼接融合中,首先将图像和点云特征沿通道维度拼接,得到一个维度为H×W×4C的特征张量Bcat。然后将拼接后的特征送入两个卷积层进行进一步处理。其中,第1个卷积层用于捕捉空间关系并从拼接数据中提取有价值的特征。随后,第2个卷积层将通道维度降低到C来进一步细化融合特征。
(2) 元素级求和融合。元素级求和旨在保持空间结构的同时融合两种模态的互补信息。在逐元素求和融合模块中,首先将LiDAR特征送入一个1×1卷积层对通道维度进行降采样。然后,对图像特征和变换后的LiDAR特征进行逐元素相加,得到融合特征Bfused∈RH×W×C。这种元素及求和的特征融合策略确保了两种模态对最终融合结果的贡献是相等的。
(3) Transformer融合。近年来,Transformer[27]架构在自然语言处理领域取得了很大的成功,尤其是在捕获序列数据中的长距离依赖关系方面。在多模态融合中,Transformer因其卓越的性能和对长距离依赖关系的处理能力而受到广泛关注[28]。特别是,其内部的自注意机制为不同模态特征之间的相互作用和交互提供了一个强大的框架。在异构模态特征融合的过程中,每种模态的特征都可视为一个“序列”,其中每个“元素”都代表着空间信息的一部分。
首先,将图像和点云的BEV特征沿通道维度连接,形成一个联合特征张量
考虑到原始的Transformer的结构不包含关于元素位置的任何信息,需要为此联合特征添加位置编码,确保模型能够识别特征在空间上的位置
接着,为了捕获两种模态之间的复杂交互,本文引入了多头自注意力机制。这种机制使模型能够为不同模态的每个部分分配不同的权重,多头的设计可以使模型从多个角度或来捕捉不同模态特征之间的相关性
然后,通过前馈网络进一步强化模型的非线性处理能力
最后,为确保模型的稳定性并维持特征规模,在每一步后都采用了残差连接和层归一化技术得到最终的融合特征
整体来说,这种基于Transformer的融合策略允许算法充分考虑和利用两种模态之间的复杂交互和依赖关系,从而为下游任务提供一个高度丰富和代表性的特征表示。
3.3 检测头网络
检测头网络负责根据融合特征来预测目标的类别和位置。该网络包含3个反卷积层,这些层负责上采样特征图,从而为后续的类别和位置预测提供更细粒度的信息。之后是检测头中的两个分支:类别预测分支和边界框回归分支。类别预测分支为每个锚框输出一个分数,指示该锚框内是否存在某一特定类别的对象,以及存在的概率。这些输出分数经过激活函数处理后,可以转化为各个类别的概率分布。另一方面,边界框回归分支则负责细化目标的位置信息。它为每个锚框预测4个值,这4个值代表中心位置的偏移量以及框的宽度和高度的变化。通过这些预测值,可以校正锚框的位置,使其更紧密地围绕目标对象。综合两个分支的输出,检测头网络输出每个锚框中目标类别和调整后的位置信息。
4 实验
4.1 实验设置
本文实验是在OPV2V[8]数据集上进行的。OPV2V数据集汇集了由仿真框架OpenCDA[29]以及CARLA[30]模拟器所模拟的LiDAR点云与RGB图像的大量数据。数据集总计11464帧,主要分为两个子集:CARLA默认城镇子集和Culver City数字城镇子集。其中,CARLA默认城镇子集占10914帧,按6764帧、1980帧和2170帧的比例分为训练、验证和测试3部分。该子集覆盖了不同复杂程度的多种场景,为协同感知模型提供了充足的训练与评估数据。相对而言,Culver City子集只有550帧,但其目标在于评估模型在现实世界场景的泛化表现,特别是那些对模型感知能力构成挑战的实际城市环境。
在实现细节方面,所提算法基于PyTorch框架,并在配有24 GB RAM的NVIDIA RTX 4090 GPU的PC上进行训练。在训练过程中,随机选择了一组能够在场景中建立通信的车辆,并规定每个车辆的通信范围为70 m。同时,点云的范围被设定为沿x,y与z轴的[-140.8,14.8]×[-40,40]×[-3,1]。体素的分辨率为0.4 m。为了提升训练数据的多样性,采用了一系列数据增强技术,如随机翻转、±0.05范围内缩放以及±45°范围内旋转。利用Adam优化器对模型进行训练,设定模型的初始学习率为0.002,批量大小为2。此外,利用了基于验证损失的早停策略以防止模型过拟合。本文算法的详细架构和其他参数如图2所示。

图2 模型详细架构与参数细节Fig.2 Detailed model architecture and parameter specifics
性能评价指标方面,本文采用了标准的评价指标来评估算法的性能,即平均精度(Average Precision,AP)。平均精度是一种常用的目标检测性能指标,用于衡量算法在不同交并比(Intersection over Union,IoU)阈值下的准确性。在计算平均精度时,需事先设定交并比IoU的阈值,即预测框和真值框的重合面积占预测框和真值框面积总和的比例,如果大于设定阈值则认为检测正确。本文分别计算模型在IoU阈值为0.5和0.7时的AP值,即AP@0.5和AP@0.7。这两个指标能够提供对算法在不同严格程度下的性能评估,从而更全面地衡量算法在目标检测任务中的表现。
根据不同的异构模态融合策略,本文构建了3个版本的多模态融合模型:“Ours-C”表示通道级拼接融合,“Ours-S”对应于元素级求和融合,“Ours-T”代表Transformer融合。此外,为了更全面地验证所提多模态融合模型的效果,本文算法还与多种现有先进算法进行了对比,包括Cooper[5],F-Cooper[6],V2VNet[7],AttFuse[8]以及CoBEVT[15]。
除了考虑所有车辆都可以同时获得点云和图像两种模态的数据这种一般场景以外,本文还考虑了更加现实和复杂的异构模态场景。在这种异构模态场景下,每个车辆只能获取点云和图像中的任意一种模态,用于模拟所提算法在各种模态缺失情况下的性能表现。
4.2 定量实验
在表1中,本文将多种SOTA算法在OPV2V数据集上的表现进行了综合对比。首先,所有的协同感知算法都在不同场景的不同指标上显著优于单车感知(No Fusion),这表明多车之间的相互协作有利于彼此更好地感知周围环境。其次,可以发现前期融合(Early Fusion)策略在大多数情况下均表现优于后期融合(Late Fusion)。这表明在不考虑通信带宽的情况下,数据在初期的融合能够更好地保留原始场景信息。值得注意的是,本文算法采用不同融合策略的3种实现版本(即元素级求和融合(Ours-S)、通道级拼接融合(Ours-C)和Transformer融合(Ours-T))的性能在所有对比算法中均具有较强竞争力,尤其是使用了Transformer架构的多模态融合模型Ours-T,在两种IoU阈值下均取得更高的AP分数。尽管在Default子集中,Ours-T在AP@0.7指标上略低于CoBEVT[15],但在更具挑战性的Culver City子集中,其在AP@0.5和AP@0.7两个指标上均领先于其他所有对比算法。
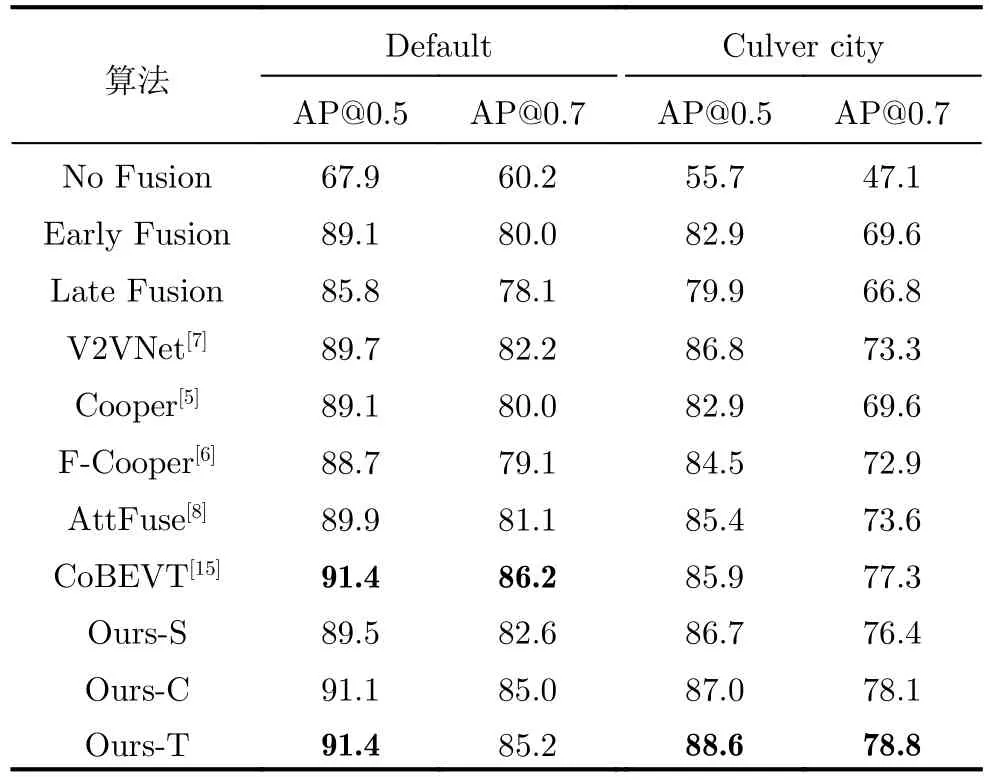
表1 与SOTA算法的综合性能对比(%)Tab.1 Comprehensive performance comparison with SOTA algorithms (%)
表2展示了本文算法在异构模态场景中的性能比较。其中,Camera-only表示所有车辆只能获取图像数据。而LiDAR-only表示所有车辆只能访问点云数据。此外,还考虑了Camera-only与LiDARonly混合的情况:Hybrid-C表示所有车辆中一半只能获取图像数据(包括中心车辆),另一半只能获取点云数据;与之不同的是,Hybrid-C表示一半数量的车辆只能获取点云数据。从表2可以看出,纯图像模式(Camera-only)下的性能明显较低,特别是在Culver City场景中的AP@0.7,只有8.6%。这可能是由于单一的图像模态无法很好地提供3D检测所需要的信息,因为根据2D图像预测在3D空间中的深度信息本身就存在一定的不确定性。而纯点云模式(LiDAR-only)的性能则明显优于Cameraonly,主要是因为3D点云可以提供准确的场景深度测量,因此更适用于3D目标检测任务。进一步考虑到异构模态的混合情况,Hybrid-C和Hybrid-L都表现出了相对较好的性能。特别是在中心车辆只能获取点云数据的情况下(Hybrid-L),其性能接近LiDAR-only,说明中心车辆的数据模态在V2V协同检测中起到了关键的作用。而对于Hybrid-C,尽管其性能略低于Hybrid-L,但仍然明显优于Camera-only,这表明即使在一半车辆只能获取图像数据的情况下,点云数据的存在仍然能大大增强系统的检测性能。表2的实验结果验证了所提算法在不同的异构模态场景下都具有相对稳健的性能,特别是在模态数据丢失的情况下。此外,这也再次突显了点云数据在V2V协同检测任务中的重要性,以及中心车辆对整体检测性能的影响。

表2 所提算法不同异构模态场景下的性能对比(%)Tab.2 Performance comparison of the proposed algorithm under different heterogeneous modal scenarios (%)
定位误差是现实场景中需要考虑的复杂因素之一。为了分析模型对定位误差的鲁棒性,本文从高斯分布中分别采样坐标噪声(σxyz ∈[0,1.0] m)和角度噪声(σheading∈[0°,1.0°]),并将其添加到准确的定位数据上来模拟定位误差。图3给出了所提多模态融合算法(Ours-T)与其他两种单模态方案(LiDAR-only,Camera-only)在不同定位误差情况下的性能对比。可以看出,随着定位噪声的增加,3种模型的性能整体均趋于下降,尤其是纯点云模式(LiDAR-only)对定位误差最敏感:当误差增加到0.2时,性能下降超过4%;误差为0.4时,下降超过10%。相比之下,纯图像模式(Camera-only)受定位误差较小,性能下降平缓。其主要原因是LiDAR数据提取的三维几何特征对坐标轴的偏移比图像提取的视觉特征更加敏感。此外,由于多模态融合模型Ours-T中包含一定的冗余信息使其不会过于依赖某种单一模态,因此其在保持较高性能的同时对于定位误差具有较强的容忍能力。
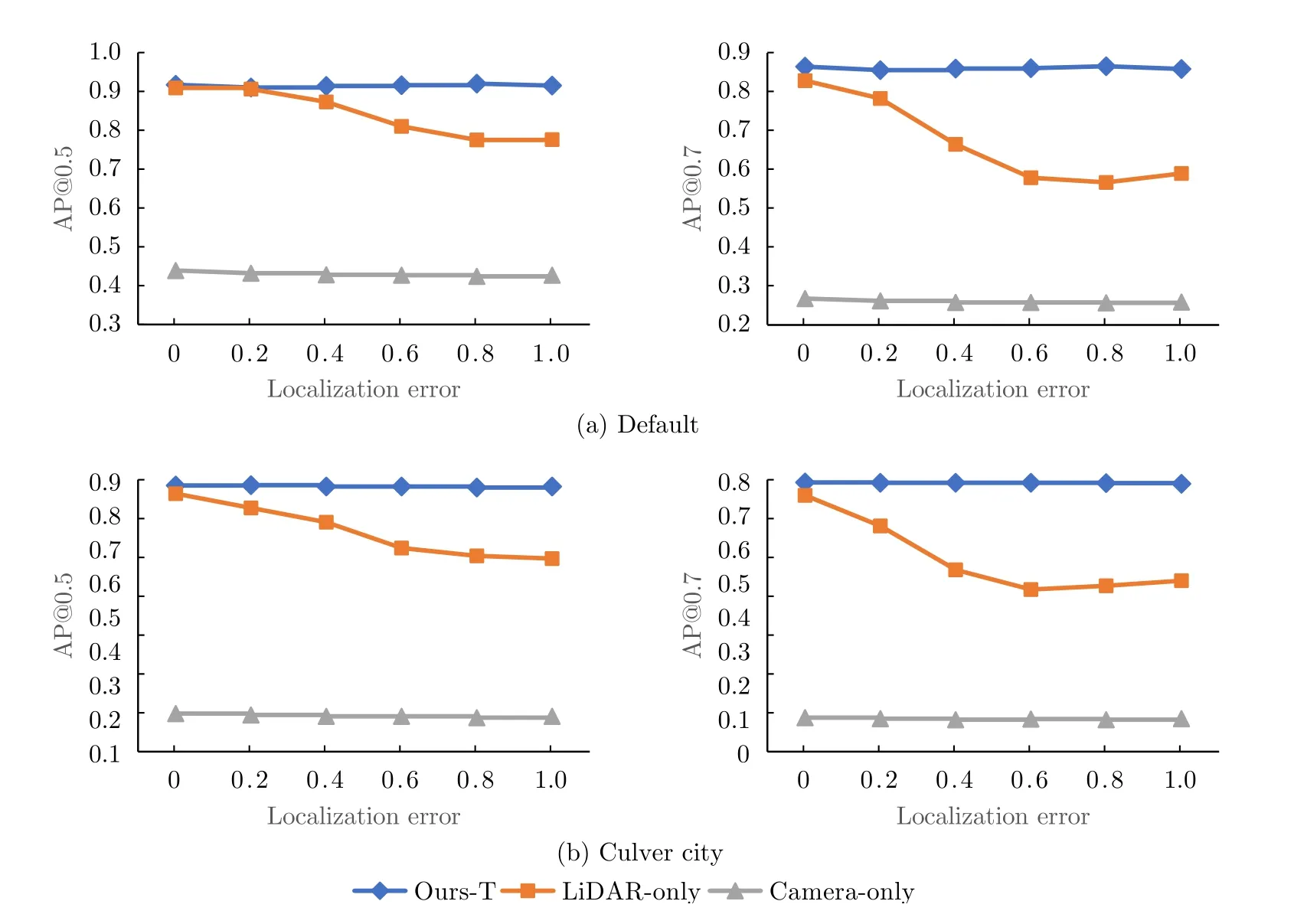
图3 定位误差对模型性能的影响Fig.3 Impact of positioning error on model performance
4.3 定性实验
图4展示了3种不同方案在OPV2V数据集上的可视化检测结果。如图4所示,纯相机和纯激光雷达模型会在不同程度上受到语义模糊和不确定性等因素的影响,从而导致漏检和误检等问题。相比之下,本文提出的多传感器融合模型在检测精度和鲁棒性方面有了显著改进。通过利用激光雷达和相机模式的互补优势,融合模型有效地解决了单个传感器的局限性,实现了更精确、更可靠的物体检测。
5 结语
本文提出并实现了一种集成激光雷达和相机数据的多模态融合协同感知基线系统,该系统突破了单一传感器模式的限制,有效地融合了两种传感器的优势,为实现更精确、更稳健的环境感知奠定了基础。特别地,本研究首次深入探讨了几种先进的融合策略在多模态协同感知任务中的适用性和有效性,尤其是引入了基于注意力机制的融合方法,这一创新策略在提高感知系统准确性和鲁棒性方面表现出色。这种方法通过多头自注意力机制,在不同传感器特征之间建立了复杂的关联,提高了融合的精细度,并在OPV2V数据集上展现出卓越的性能和鲁棒性。此外,在更具挑战性的异构模态场景下的实验再次验证了多模态融合的有效性,这也为现实世界中实际应用提供了一种经济可行的方案。未来的工作将集中在进一步优化融合策略,并探索V2V协同感知中更多传感器模态的应用潜力,以进一步推动自动驾驶和智能交通系统的发展。
利益冲突所有作者均声明不存在利益冲突
Conflict of InterestsThe authors declare that there is no conflict of interests
猜你喜欢
科学大众(2020年23期)2021-01-18
汽车观察(2019年2期)2019-03-15
小太阳画报(2018年3期)2018-05-14
阅读与作文(小学低年级版)(2016年12期)2016-12-22
少年博览·小学低年级(2016年9期)2016-11-24
中国卫生(2016年5期)2016-11-12
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
汽车文摘(2015年11期)2015-12-02
上海电机学院学报(2015年4期)2015-02-28
生物进化(2014年2期)2014-04-16
