
基于双图注意力的多领域口语语言理解联合模型
2024-01-20 05:29:16贾旭,彭敏
中文信息学报 2023年10期
贾 旭,彭 敏
(武汉大学 计算机学院,湖北 武汉 430072)
0 引言
多领域口语语言理解(Multi-domain Spoken Language Understanding,MSLU)是对话系统的重要组成部分[1-3]。日常生活中常用的语音助手,如Siri等,都依靠语言理解模块识别用户的指令。MSLU任务主要包含两个子任务,分别是多意图识别(Multi-intent Detection)和槽填充(Slot Filling)。其中,多意图识别任务可以看作句子分类任务,确定用户对话的目标。槽填充任务则看作序列标注任务,可以获得语句中的重要信息。如表1所示,对话语句“我想吃烤鸭,全聚德在哪?电话是多少?”,对应的意图分别是Request.餐馆.电话和Request.餐馆.地址。“全聚德”分别对应槽“B-餐馆.名称I-餐馆.名称I-餐馆.名称”。

表1 多领域口语语言理解示例
意图和槽之间存在很强的关联性,现有方法通常采用联合模型同时解决两个任务[1-3]。早期的联合模型通过共享编码器,使用不同的意图解码器和槽解码器完成意图识别和槽填充任务。模型在反向传播过程中,通过更新共享参数的形式,隐式实现联合学习[4]。为了更好地利用意图特征,部分工作基于槽门[5-6]和堆栈[7]形式,利用意图信息指导槽填充任务,提升了槽填充的准确率。然而,这些方法仅利用了意图信息提升槽填充任务的准确率,在意图识别任务中缺少对槽信息的引入[8]。因此,最近的模型通过交互模块,建立意图和槽之间的双向关联,同时提升了模型在两个任务上的表现[8-10]。在真实场景中的MSLU任务,用户的对话语句包含多个意图[11]。面对多意图识别的任务,现有模型将其看作多标签分类任务。通过引入图注意力网络(Graph Attention Network,GAT)[12],模型能够建模多意图和槽之间的关联特征,在多意图识别任务中获得了显著的性能提升[13-14]。
尽管上述方法在MSLU任务中取得了很好的效果,但这些方法仍是将多领域任务看作单领域任务的堆叠,忽略了多领域任务中的领域关联问题。一方面,现有研究只是将所有的意图和槽看作完全独立的标签,忽略了领域内和领域间的细粒度关联特征。如图1所示,现有方法均无法建模图中意图和槽细粒度标签之间的关联(图1中虚线表示)。因为这些方法认为意图Request.餐馆.电话和Request.餐馆.地址是完全不同的两个标签,忽略了两者之间存在的领域关联。另一方面,现有图模型方法[10,13-14]在建模意图和槽之间的关联时,只是粗糙地在预测的意图和槽之间进行连接,导致模型学习了冗余的错误信息。
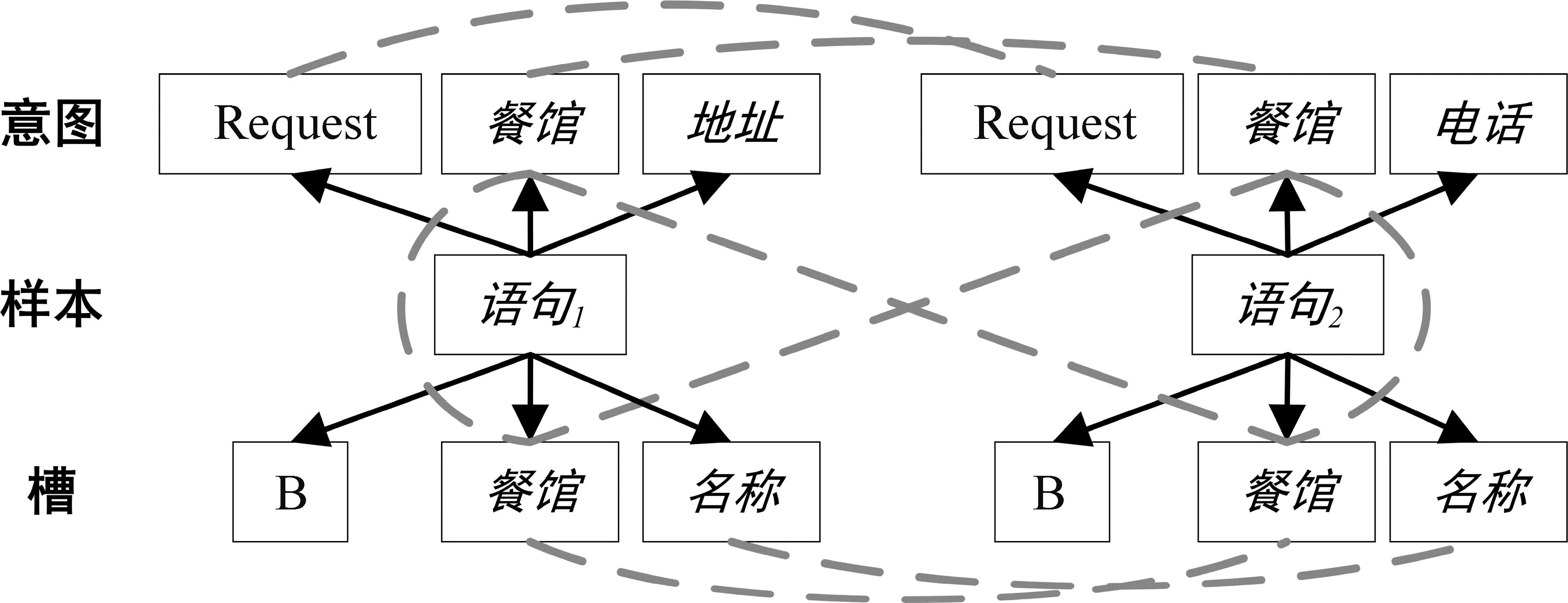
图1 意图和槽之间存在的细粒度关联
针对上述问题,本文提出细粒度标签图和领域相关图的双图注意力联合模型DualGAT(Dual Graph Attention Network)解决多领域口语语言理解任务。具体来说,细粒度标签图建模意图和槽标签切分后的细粒度特征,获得标签和对话上下文之间更细粒度的关联关系。领域相关图利用意图和槽之间的领域信息,仅建模领域内的意图和槽之间的关联,剔除了领域无关的冗余和错误信息。同时,本文优化图方法的建模过程,极大地提升了模型的训练速度。本文主要的贡献如下:
(1) 提出双图注意力模型DualGAT,建模细粒度标签图和领域相关图注意力网络,捕获MSLU任务中标签间的细粒度关联关系。通过优化图模型的建模过程,提升模型训练速度。
(2) 本文在两个公开的中文多领域对话数据集CrossWOZ和RiSAWOZ上与现有模型进行比较。实验结果表明,本文提出的模型在槽填充F1、意图识别准确率和句子准确率上均显著优于现有模型。进一步实验说明了本文模型各模块的作用和计算效率,同时也说明本文模型与预训练语言模型有更好的兼容性。
1 相关工作
本文通过构建联合模型和图注意力网络解决多领域口语语言理解任务中的多意图识别和槽填充任务,下面简要介绍现有工作如何通过联合模型和图模型解决意图识别和槽填充任务。
口语语言理解任务的目的是根据用户对话语句,识别用户目标,并对语句中的重要信息进行标注[1-2]。口语语言理解任务包含两个子任务: 意图识别和槽填充。其中,意图识别可以看作句子分类任务,识别用户的意图或目标。槽填充可以看作序列标注任务,对语句中的内容进行标注,不同的内容用不同的槽进行标注[3-4]。因为意图和槽存在很强的关联性,现有方法会采用基于编解码框架的联合模型,使用一个模型同时完成两个任务。早期的工作通过意图和槽解码器共享编码器参数的形式,隐式地联合两个任务,同时提升了两个任务的表现[15]。因为相较于槽填充任务,意图识别的准确率更高,所以部分工作开始显式地利用预测出的意图指导槽填充任务[5-6]。Goo等人[5]提出槽门模型,使用门机制将与槽相关的信息从预测的意图中筛选出来,提升了槽填充任务的表现。Qin等人[7]对语句中的每个词分别预测意图,再将每个词预测出的意图信息与槽信息拼接,显著提升了模型在两个任务上的表现。然而上述工作仅考虑了意图到槽的单向连接,忽略了意图与槽之间的双向关系[16]。E等人[8]通过建模意图和槽之间的双向循环网络,在一定程度上解决了意图和槽之间的双向关联问题。Qin等人[9]则利用自注意力机制,构建交互模块,使得意图和槽之间的信息进行交换,解决了意图和槽之间的双向关联问题。为解决中文问题,Teng等人[17]和朱展标等人[18]针对中文问题引入了中文字词特征融合模块,提升了模型在中文口语语言理解上的表现。
在真实场景中,用户的对话通常横跨多个领域,涉及多个意图内容[11]。目前主流的方法都是将多意图识别看作多标签分类任务。不同于单意图任务中意图和槽之间一对多的关系,多意图任务中需要考虑多对多的关联关系。为了建模多意图和槽之间的关联,Qin等人[13]建立了自适应的意图-槽交互图,使用图注意力网络推理两者之间的关联关系。Zhu等人[10]在之前方法[7]的基础上,建模了语句中的词、对应的意图和槽之间的关联,并利用正则化优化了图结构,进一步提升了图模型的表现。针对图方法推理速度慢的问题,Qin等人[14]使用非自回归的方法建模了全局-局部图,显著提升了模型的计算效率。然而上述这些方法仅将多领域任务中的意图和槽看作完全独立的标签,忽略了标签之间的领域关联关系。为此,本文提出双图注意力联合模型,分别建模意图和槽之间的细粒度关联和领域关联,解决多领域任务中意图和槽标签之间的关联问题。
2 模型
本节介绍细粒度标签图和领域相关图的双图注意力联合模型DualGAT(Dual Graph Attention Network)解决多领域口语语言理解任务,结构如图2所示。模型包括基于Top-k网络的编解码框架、细粒度标签图和领域相关图。首先,编码器将用户的语句编码后分别输入Top-k网络和细粒度标签图,Top-k网络通过预测语句中的意图个数完成多意图识别任务;模型将所有的意图和槽切分为细粒度的分片,通过分片之间的关联关系建模细粒度标签图;领域相关图通过将预测出的意图及其对应领域的槽进行关联,减少领域无关的冗余或错误信息。
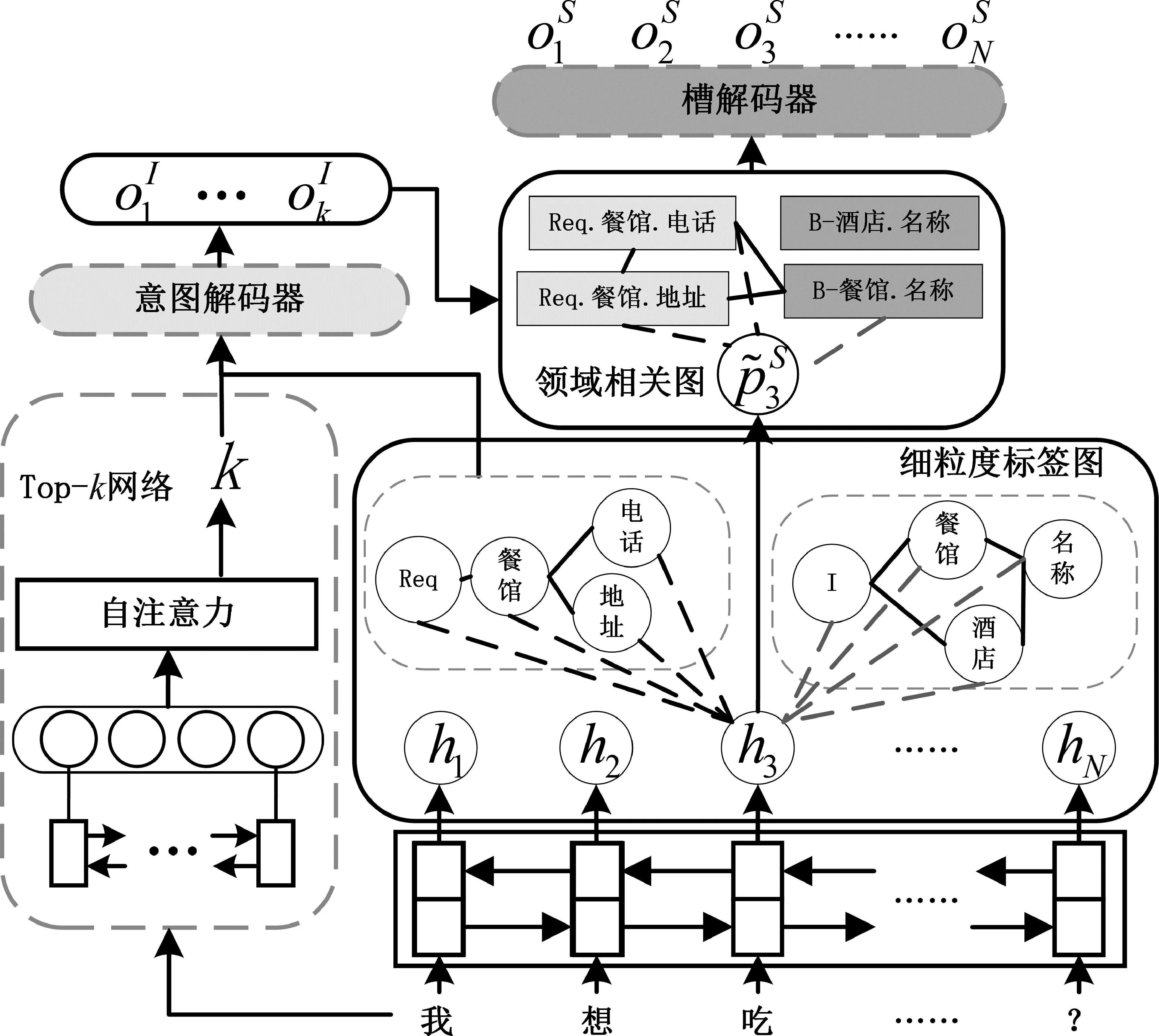
图2 DualGAT模型框架图
2.1 基于Top-k网络的编解码框架
本文模型以基于Top-k网络的编解码结构为基础框架,联合解决多意图识别和槽填充任务。不同于之前方法将多意图识别看作多标签分类任务,本文对Top-k网络[19]进行优化,使用自注意力机制[20]提升模型预测意图个数的准确率。
给定用户语句U=(w1,w2,…,wN),其中,wi表示第i个字,N表示语句长度。使用双向LSTM作为模型的编码器,对用户语句进行编码,获得H=(h1,h2,…,hN)。H∈N×d,d表示隐状态的维度。在解码阶段,使用单向LSTM作为意图识别和槽填充的解码器。在每个解码t步,解码状态gt通过之前的解码状态gt-1和对齐的隐状态ht计算得到。
其中,W1、b1、W2、b2表示可训练参数,y表示意图和槽输出的概率。
在Top-k网络中,同样使用独立的编码器[19]获得Hk∈N×d,并捕获相互间的注意力权重。使用LSTM解码后得到最终的意图个数k,如式(4)所示。
其中,Q,K,V由Hk经过线性变换得到。函数topk的详细信息可参考Top-k网络[19]。“||”表示拼接符号。
2.2 细粒度标签图
在多领域口语语言理解任务中,领域内和领域间的意图和槽存在许多细粒度的关联关系。例如,B.餐馆.名称和B.餐馆.推荐菜都属于餐馆领域,而B.餐馆.名称和B.景点.名称虽然不属于同一领域,但都是关于名称。之前的工作将这些不同的意图和槽都看作完全相互独立的标签,所以无法捕获这些标签之间领域内或领域间的细粒度关联特征。本文通过建模细粒度标签图,属于同领域的标签均具有相同的领域分片节点,如餐馆节点,通过捕获语句上下文的语义,使这些标签具备餐馆领域内的特征。对领域不同的标签,若存在相同内容的分片节点,如名称节点,同样通过捕获语句上下文的语义,使这些标签均具备名称的领域间特征。本文构建细粒度标签图GP=(VP,EP),其中V表示节点,E表示边。
对图中的节点,将意图和槽进行细粒度的切分,得到细粒度分片节点VP。其中,意图和槽的细粒度分片节点并没有进一步区分,例如,意图Request.餐馆.电话和槽B-餐馆.名称切分后的分片节点是Request、B、餐馆、电话和名称。分片节点餐馆在意图和槽中具有相同的表达。相较于将意图和槽切分后的节点建立两个不同的图,本文将所有节点建模在同一张细粒度标签图内,能够利用显卡的并行能力,减少图中重复节点的计算,提升模型效率。本文使用嵌入函数和线性层,对细粒度标签图中的节点进行初始化。HP=f(emb(VP)),其中,HP∈NP×d,Np表示图中节点个数。为建模用户语句和细粒度标签之间的关联关系,本文将语句中的上下文同样作为节点放入细粒度标签图中。细粒度标签图中的初始化节点表示为:

(5)
对图中的边,设计细粒度标签图的连接矩阵为EP∈(N+NP)×(N+NP),主要包括三种类型的边: ①细粒度分片之间的连接,将同属于一个意图或槽的两个分片节点进行连接,表示为其中或者和表示真实的意图和槽,在图2细粒度标签图中用实线表示)。因为这种连接不会随着对话语句产生变化,所以该过程仅初始化一次,无须重复计算,能够提升模型的计算效率。②语句和细粒度意图之间的连接。将语句中的第i个字节点与所有的细粒度意图节点进行连接,从而捕获语句上下文中的语义信息和细粒度意图之间的关联,表示为其中在图2的细粒度标签图中用黑色虚线表示)。语句与细粒度意图之间关联的输出结果用表示。③语句和细粒度槽之间的连接。类似于②连接,将语句中的第i个字节点与所有的细粒度槽节点进行连接,从而捕获语句中上下文的语义信息和细粒度槽之间的关联,表示为其中在图2的细粒度标签图中用虚线表示)。语句与细粒度槽之间关联的输出结果用表示。细粒度标签图的输出和分别用来预测意图和槽。
2.3 领域相关图
为建模多领域口语语言理解任务中预测出的多意图和槽之间多对多的关联关系,现有模型会建立意图-槽图[10,13-14],通过图结构建模两者之间的关联关系。但是因为这些模型将所有意图和槽看作相互独立的标签,所以只能粗糙地连接所有预测的意图和槽。这不仅使得模型需要计算很多冗余的关联,而且错误的意图和槽之间的连接,会造成模型学习的注意力产生偏差。本文基于细粒度标签图,通过意图和槽之间的领域关联,构建领域相关图GR=(VR,ER)。将预测的意图、槽和语句上下文均建模为图中的节点,因此领域相关图包含NI+NS+N个节点,其中NI和NS分别表示意图和槽个数。遵循之前的方法[14]得到预测意图嵌入EI∈NI×d和槽嵌入ES∈NS×d,对领域相关图节点进行初始化。领域相关图的初始化节点表示为:
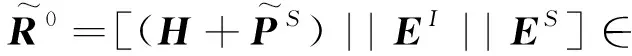
(6)
对图中的边,设计领域相关图的连接矩阵为ER∈(N+NI+NS)×(N+NI+NS),主要包括三种类型的边: ①意图和槽的连接。意图和槽之间存在很强的关联性,在多领域任务中将领域关联看作两者之间重要的连接中介。因为将用户的对话限定于特定领域时,语句的意图和槽都是该领域对应的意图和槽。所以在领域相关图中,仅将预测出的意图和其所属领域的槽相连。这不仅能减少意图和槽之间的冗余连接,也能避免模型学习到错误的特征,表示为其中表示第r个领域,在图2领域相关图中用实线表示)。②语句和意图连接。将语句中的第i个字节点与预测得到的意图进行连接。表示为其中j∈yI,yI表示预测出的意图,在图2的领域相关图中用虚线表示)。③语句和槽连接。类似于②连接,将语句中的第i个字节点与对应领域的槽进行连接,表示为其中在图2的领域相关图中用虚线表示)。构建的领域相关图中,节点之间的边受到对应领域的影响,所以相较之前的图方法连接边更少,有助于模型训练过程中的计算效率提升。
2.4 图注意力网络
本文使用图注意力网络[12]对已构建的图进行推理计算。本节阐述模型如何使用图注意力网络对已构建的图进行计算。
其中,M表示头数,Ni表示第i个节点的邻居节点。a和W表示可训练参数。
在细粒度标签图中,图信息在第l层的聚合过程定义为:
(9)


2.5 联合训练
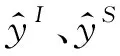
L=LI+LS+Lk
(13)
3 实验结果与分析
3.1 数据集
本文在两个公开的多领域中文对话数据集CrossWOZ-SLU[21]和RiSAWOZ-SLU[22]上对模型进行验证。按照论文中提供的源码得到语句、意图和对应的槽。不同的是,源码中仅保留语句中的单意图,本文将语句中包含的所有意图都保留作为多意图的样本,同时剔除数据集中的系统对话和不包含槽值的语句。为与原数据集区分,本文将新数据集称为CrossWOZ-MSLU和RiSAWOZ-MSLU(后续分别简写为CrossWOZ和RiSAWOZ)。因为数据集中的所有语句均来自人-人真实对话,所以比MixATIS[13]等连词拼接的多意图数据更自然,更贴近真实场景。数据集的统计结果如表2所示。CrossWOZ拥有更多的多意图语句,多意图语句占比超过20%,而且数据集样本中句子的平均长度更长。RiSAWOZ则有更多的数据样本,领域跨度更大,因此包含更多的意图和槽的种类。
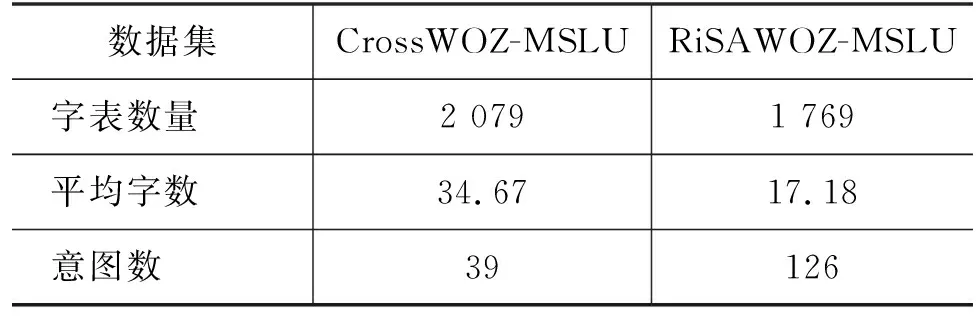
表2 CrossWOZ和RiSAWOZ数据统计
3.2 对比方法和参数指标
本文将DualGAT模型和以下模型进行比较:
(1)Slot-GatedAtten[5]: 模型设计了一种槽门机制,通过槽门筛选与槽相关的意图信息,指导模型完成槽填充任务。
(2)SF-IDNetwork[8]: 模型设计了ID和SF网络,通过循环机制将意图和槽特征进行交互。本文选择ID-First模型。
(3)Stack-Propagation[7]: 模型预测字级别的意图,再将预测的意图表示与槽表示拼接。
(4)MIATIF[19]: 模型提出Top-k网络,通过预测语句中的意图个数解决多意图识别任务。
(5)MLWA[17]: 模型使用字级别和句子级别的词适配器,将中文词信息与字信息对齐,在中文口语语言理解中获得了显著的性能提升。
(6)AGIF[13]: 模型构建意图-槽图结构建立多意图和槽之间的关联,解决多意图问题。
(7)GL-GIN[14]: 模型提出全局和局部图,建模多意图和槽关联。同时,模型使用非自回归的方法,提升了模型的训练速度。
(8)GAIR[10]: 模型提出建模候选意图和槽之间的关联图,并利用真实样本对图建模过程进行正则化,提升了模型在中文任务中的表现。
因为数据集中包含多意图,对于单意图识别的模型,本文使用多标签分类方法[13]预测最后的意图。本文使用槽F1、意图准确率、句准确率分别评测槽填充、意图识别和整个句子的模型表现。本文模型字嵌入的维度是64,编码器和解码器的隐单元分别是256和128。本文使用Adam优化器优化模型中的参数。Dropout为0.5。在所有对比模型中,多意图识别的阈值均设置为0.5。
3.3 主要结果
本文使用改进的Top-k网络预测语句中意图的个数,预测的准确率在CrossWOZ和RiSAWOZ上分别超过98%和94%。表3展示了实验结果,本文得到以下结论:
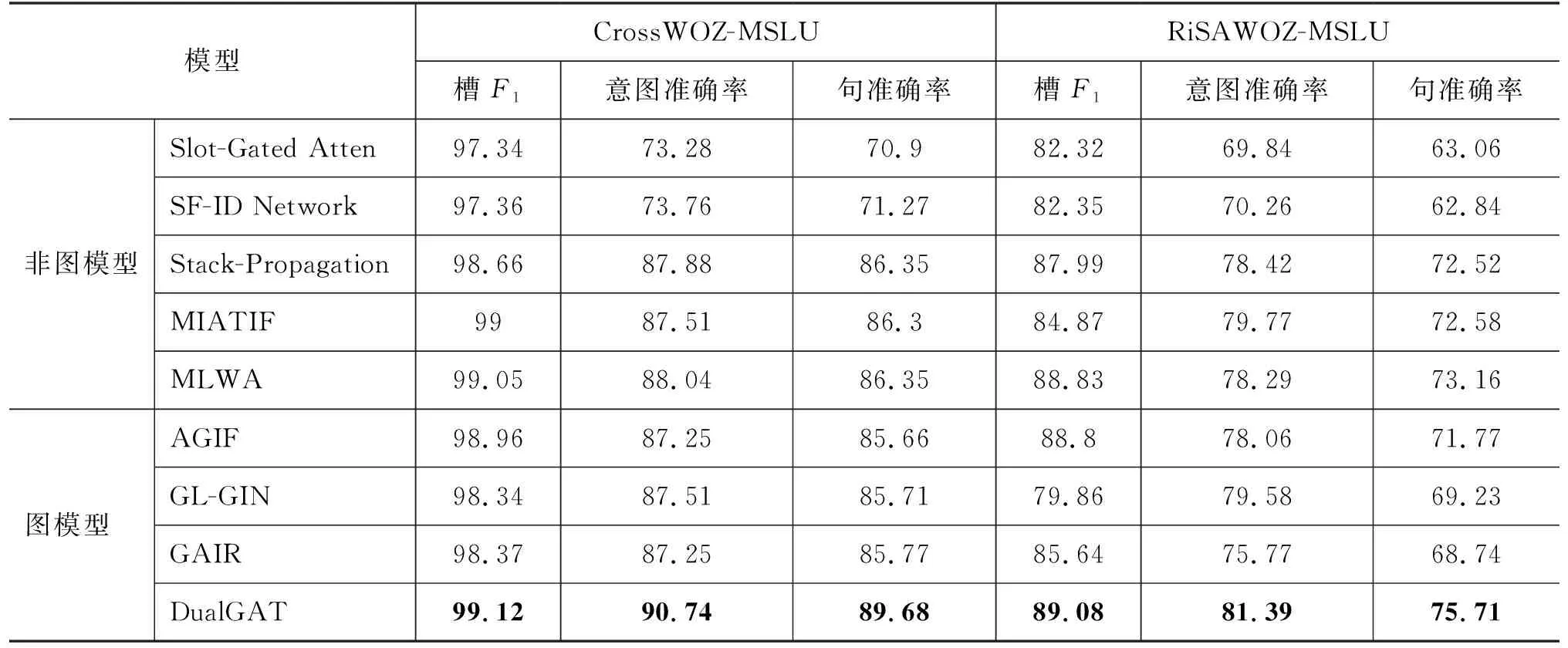
表3 DualGAT和对比模型在2个数据集的表现 (单位: %)
(1) 本文提出的DualGAT在两个数据集上的性能全面超越了现有的模型,尤其是在意图识别准确率和句准确率上。在对比模型中,MLWA因为融合了中文字和词特征,相较于其余模型获得了最好的效果。在CrossWOZ数据集上,本文提出的DualGAT在槽F1和意图准确率上比MLWA提升了0.07%和2.7%,在RiSAWOZ数据集上则分别高了0.25%和3.1%。因为DualGAT能够在细粒度标签图和领域相关图中学习到更多意图和槽之间的关联关系,因此模型在句准确率上也提升很大,在2个数据集上分别提升了3.33%和2.55%。模型在槽F1上的提升较小,主要原因是中文对话中语句偏长,许多字不对应具体的槽,使得模型不预测槽也能获得较高的准确率。
(2) 本文提出的模型与最新的图模型GAIR相比获得了显著的性能提升。在CrossWOZ数据集上,DualGAT相比GAIR在3个指标上分别提升了0.75%、3.49%和3.91%;而在领域更多的RiSAWOZ数据集上,则获得了更明显的3.44%、5.62%和6.97%的提升。这是因为在CrossWOZ数据集中,有超过20%的样本具有多个意图。而RiSAWOZ仅有8%左右的多样本,反而拥有更多的领域、意图和槽种类,所以能对多意图建模的图模型,在多领域任务中无法处理意图和槽标签之间更细粒度的关联关系,使得模型表现不佳。DualGAT的细粒度标签图能够建模多领域中的意图和槽之间的关联,领域相关图将无关的槽进行了剔除,使得模型在多领域的数据集上获得了更好的表现。
3.4 进一步研究
为了进一步说明本文所提模型的有效性,本文对模型进行了消融实验,同时对模型与预训练语言模型的兼容性、可视化分析和计算效率进行了研究。
3.4.1 消融实验
本节对DualGAT进行了消融实验,探索模型中提出的细粒度标签图和领域相关图的有效性,实验结果如表4所示。首先,将模型中的细粒度标签图和领域相关图均消去。通过观察,模型在3个指标上都出现显著的性能下降,意图准确率和句准确率下降最明显。在CrossWOZ数据集上意图准确率下降3.17%,句准确率下降3.7%;在RiSAWOZ数据集上分别是2.58%和3.71%。这表明本文提出的细粒度标签图和领域相关图在多领域任务中,能够建模意图和槽之间细粒度的关联关系,当去除双图注意力后,模型的下降最为明显。
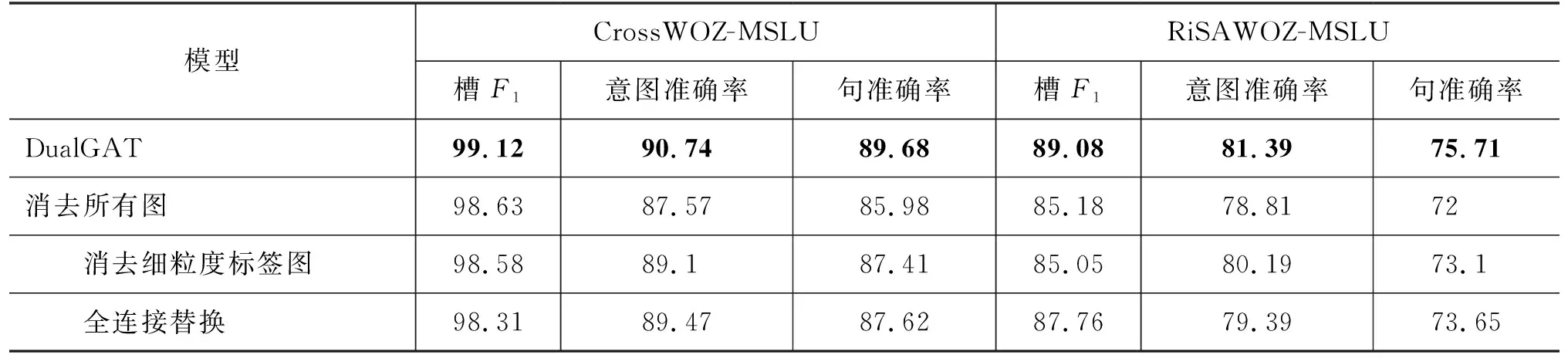
表4 消融实验结果 (单位: %)
其次,本文消去了模型中的细粒度标签图。模型也出现了明显的下降,在两个数据集上句准确率分别下降2.27%和2.61%。细粒度标签可以建立用户对话语句中的上下文和意图、槽细粒度分片标签之间的关联特征。消去细粒度标签图后,模型无法建立上下文语义和标签之间的细粒度关联,所以模型依然只能捕获标签之间独立的关联。尤其在更多的领域、意图和槽标签的RiSAWOZ数据集上,下降更为明显,槽F1下降了4.03%,意图准确率下降了1.2%。
最后,本文替换了领域相关图中预测意图和槽之间的领域关联,改为预测意图和所有槽之间全连接。在两个数据集上句准确率均下降了2.06%。替换全连接后,模型只能建立预测意图和所有槽的连接,会导致模型很难捕获正确的关联关系,所以导致在两个数据集的槽F1和意图准确率上均有明显下降。
3.4.2 DualGAT与预训练模型兼容性
为了说明DualGAT与预训练模型的兼容性,本文用预训练语言模型[23]替换模型中的上下文编码器,称为BERT+DualGAT。在本文中,使用全词掩码的中文BERT(1)https://huggingface.co/hfl/chinese-roberta-wwm-ext。对比模型包括BERT和BERT+MLWA,如图3所示。从结果中观察到,BERT+MLWA的效果相较于BERT的表现提升很小。因为两个模型都是从语义角度增强了模型表现,无法很好解决多领域任务中存在的挑战。BERT+DualGAT获得了最好的表现,相较于BERT在两个数据集的句准确率上分别提升了3.28%和2.91%。这表明本文提出的模型能为BERT提供语义信息之外的特征,进一步提升了预训练模型在多领域任务中的表现。
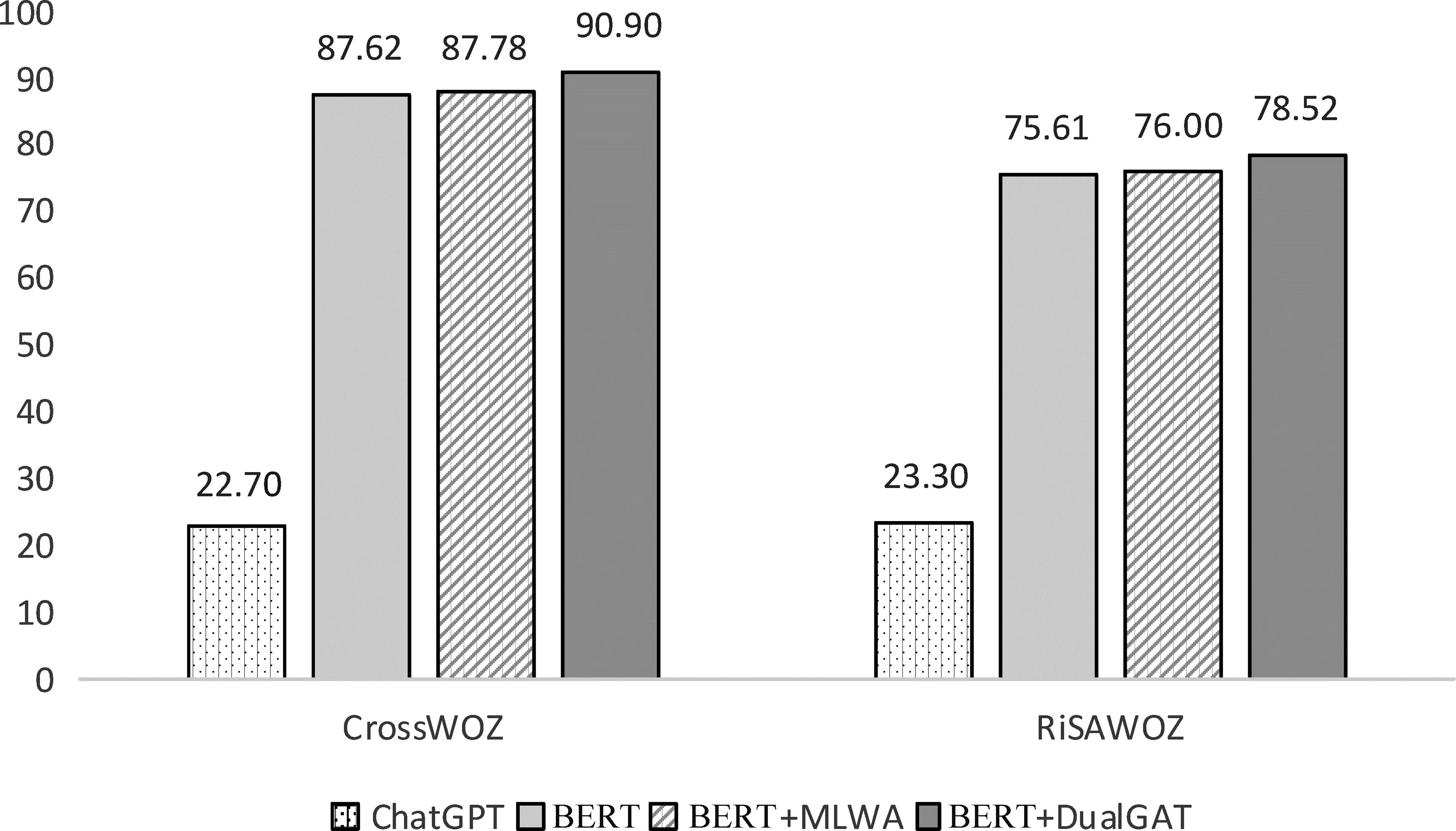
图3 模型与预训练模型兼容性
最近ChatGPT在各项自然语言处理任务中均获得了显著的效果,并引起了学术界的广泛关注。现有研究[24]也利用ChatGPT对意图识别和槽填充任务进行了测试。本文利用该研究中的提示内容,在CrossWOZ和RiSAWOZ数据集上进行了测试,结果如图3所示。从图中看到,ChatGPT在两个数据集上的表现均远低于现有方法,这与文献[24]中的结果基本保持一致。通过对生成的错误内容进行分析,本文发现ChatGPT无法完全理解用户的语句,同时也会生成许多语句中不存在的槽值。因此当前无法在下游任务进行微调的通用语义理解的预训练语言模型,无法完全解决MSLU任务中的多意图识别和槽填充问题。
3.4.3 可视化分析
为了进一步说明细粒度标签图和领域相关图的有效性,本文将DualGAT、消去细粒度标签图和消去领域相关图的DualGAT的输出结果进行了可视化,如图4所示。本文将“全聚德”看作整体,观察输出的意图标签,标签和连接线的深浅表示注意力权重。DualGAT的输出主要对应意图Request.餐馆.地址和Request.餐馆.电话。同时,全聚德和标签餐馆、地址和推荐菜之间也存在关联,这是因为细粒度标签图建立了“全聚德”与细粒度标签之间的关联关系。为了进一步验证,本文还输出了“吃”的注意力权重(在图4中用虚线表示),除了与对应意图之外,“吃”更关注餐馆、名称和推荐菜。因为“吃”经常会涉及餐馆领域,后面会跟餐馆的名称或推荐菜,所以两者之间存在很强的关联性。作为对比,消去细粒度标签图的结果显示,“全聚德”更关注意图中包含电话的标签。这是因为上下文中与电话关联更高,而模型没有学习到“全聚德”对应的细粒度标签的内容,因此受到上下文影响后,注意力会分散。
因为DualGAT预测到准确意图后,根据领域相关图,消除了“全聚德”与其余领域的关联,所以在槽识别中,模型更关注正确的槽标签。相反,消去领域相关图的模型虽然也能够预测出对应的正确标签,但是由于没有优化意图和槽之间的关联关系,所以模型依然有较高的注意力在其他领域的标签上。
3.4.4 计算效率
在构建细粒度标签图和领域相关图时,本文学习GL-GIN[14],使用非自回归的方法进行建模,并优化了建图的过程,减少了冗余的连接计算,提升了模型的推理速度。为了比较本文的模型与其他图模型的计算效率,在相同的系统环境下,使用相同的超参数统计了所有图模型完成一次训练数据集训练所需的时间,如表5所示。实验结果表明,相较于最新的图模型GAIR,DualGAT实现了33.1倍和14.0倍速度的提升。相较于同样使用非自回归方法的GL-GIN,本文提出的模型依然提速2.1倍和1.6倍。这说明将细粒度标签图的构建过程放在模型初始化阶段,同时减少图中的连接关系,提升了模型的运算效率。

表5 图模型计算效率对比
4 结论
本文提出细粒度标签图和领域相关图的双图注意力联合模型DualGAT(Dual Graph Attention Network)解决多领域口语语言理解任务。模型建模细粒度标签图,捕获意图和槽之间的细粒度关联。领域相关图利用意图和槽之间的领域关联信息,过滤意图和槽之间冗余和错误的连接,提升模型的句准确率。实验结果表明,本文提出的模型在两个公开的中文数据集上相较于已有的模型,性能获得了显著提升,进一步的实验说明了本文模型各模块的作用和计算效率,同时也用实验说明本文模型与预训练语言模型有更好的兼容性。
猜你喜欢
红外技术(2022年11期)2022-11-25 03:20:40
法律方法(2022年2期)2022-10-20 06:42:20
福建基础教育研究(2022年4期)2022-05-16 08:48:40
高技术通讯(2021年1期)2021-03-29 02:29:24
法律方法(2021年3期)2021-03-16 05:56:58
新世纪智能(语文备考)(2020年4期)2020-07-25 02:28:50
电脑与电信(2018年11期)2018-02-16 05:41:32
作文评点报·低幼版(2017年44期)2017-11-16 08:24:58
信息安全研究(2016年3期)2016-12-01 06:06:41
语文知识(2014年4期)2014-02-28 21:59:52
