
学生议论文中的比喻论证作用分析
2024-01-20 05:29:24武阗阗宋子尧程苗苗巩捷甫王士进
中文信息学报 2023年10期
武阗阗,宋子尧,韩 旭,程苗苗,巩捷甫,3,王士进,3,宋 巍
(1. 首都师范大学 信息工程学院和交叉学科研究院,北京 100056;2. 科大讯飞股份有限公司 AI研究院,安徽 合肥 230088;3. 认知智能国家重点实验室,安徽 合肥 230088)
0 引言
自动抽取自然语言中的论辩结构或判断论辩质量的论辩挖掘任务已受到研究者越来越多的关注。然而,现有研究主要关注识别论辩文本中的论证成分或结构[1],对论证方法的研究相对较少。
本文旨在研究比喻在学生议论文中的运用及其论证作用。比喻是常见的语言现象,它可以用具体的喻体来表述抽象的本体。比喻不仅是语言的修辞手法,也是强有力的创造性推理工具[2]。此外,作为一种特殊的比喻形式,隐喻也可以被用作一种论证手段。研究表明,在政治用语中,隐喻比字面用语更能产生情感上的共鸣,并在影响决策方面表现出更强的有效性。如在句子“It’s time tojumpstart the economyand put it to work for the middle-class. ”中,“jumpstart”意为“启动”,让人联想到经济就像一辆故障的汽车,“启动经济”即为“恢复经济”,“jumpstart”比“restore”更富于感染力[3]。比喻的传统性和论证结论的合理性都会对论证的产生和理解有不同的影响[2]。
尽管论辩中比喻的作用已在语言学理论中被广泛讨论,但以往的研究并没有尝试自动分析比喻在论辩挖掘中的作用。本文进行初步尝试,探究比喻在论辩挖掘中的自动分析方法。本文的主要贡献如下:
(1) 构建了一个比喻论证数据集,包含1 220篇学生议论文中的比喻句及其论辩角色。论辩角色分为论点、论据、阐释或者其他。进而,将比喻论点按照作用分为事实论点、价值论点、策略论点三类。初步分析了学生议论文中比喻运用的方式和作用。该数据集为进一步探索比喻论辩作用分析提供基本数据基础。
(2) 提出了比喻论点作用分类任务,并比较了基于预训练语言模型精调和基于提示大语言模型的方法。实验结果表明,基于精调的方法依然具有更好的表现,可作为未来研究的基线系统。
(3) 构建了一个集成比喻识别、论辩角色识别和比喻论点分类的流水线系统,自动分析比喻句的论辩作用。实验结果表明,错误级联问题较为严重,亟待提高流水线系统的能力。
本文初步尝试研究学生议论文中论证方法,并没有涉及隐喻的解释和推理。我们将其留给未来工作进一步探究。
1 相关工作
1.1 论辩挖掘
论辩挖掘是指利用自然语言处理和机器学习等相关技术,挖掘非结构化文本中的论辩性质和结构信息[4]。在不同领域的文本中,论辩信息包含观点、依据以及逻辑过程等[1],挖掘论辩信息具有重要研究意义。Cabrio和Villata提出了一个论辩挖掘流程框架,将任务分为论辩提取和论辩关系预测两个阶段[5]。目前,论辩挖掘任务主要涉及政治辩论、在线辩论、法律文本、议论文、学术类和社交网络等方面[1]。论辩成分通常分为前提和结论,其他分类包括依据、事实和价值等[6]。论辩挖掘任务的主要模型是机器学习模型和基于深度学习的神经网络模型[1]。
本文主要研究学生议论文中的论辩挖掘,已有工作主要围绕论辩结构分析展开。Stab和Gurevych提出了一种分类主张和前提,并识别论证支持关系的方法[7],同时将论证结构建模为树形结构以提取整体论证结构[8]。Wagemans从理论角度分析了隐喻在议论文中作为论点和论据的作用,并结合实例详细说明了隐喻在论证文本中的主张和立场重建[9]。Song等采用自注意力模型建模句子之间的位置和关系,并用于识别学生议论文中的话语元素[10]。Lauscher等将论辩结构信息融入修辞关系挖掘任务中,通过不同层级的BiLSTM模型进行训练,并提出了一个多任务模型,证明论辩结构信息对修辞关系预测有明显提升[11]。黄华新和祝文昇分析了隐喻在科学论证中作为材料前提、连接前提和论证立场的作用,并强调只有在科学论证中合理地使用隐喻才能发挥其积极作用并被接受和认可[12]。目前,还尚未有对学生议论文中的比喻句的论辩分析。
1.2 比喻识别
比喻一般包括明喻和隐喻。明喻是一种直接使用“比如”“像”等喻词比较两种事物的修辞手法。隐喻不使用显性喻词,常用“是”“变成”“成为”等词语来代替喻词,可以帮助我们理解复杂的概念并表达抽象的事物。隐喻识别任务的目标是从文本数据中识别隐喻。目前有三种主要的隐喻理论: Lakoff和Johnson提出的概念隐喻理论(Conceptual Metaphor Theory),认为隐喻是从源域到目标域的概念映射[13];Wilks提出的选择偏好限制理论(Selectional Preference Violation),认为谓语对于论元有一定的选择倾向性,而隐喻则破坏了选择偏好[14];Group提出的隐喻识别程序理论(Metaphor Identification Procedure),认为隐喻是词的字面含义与上下文中的含义不一致而导致的结果[15]。
隐喻识别主要包含句子级、关系级和单词级三种类别。Krishnakumaran和Zhu将隐喻分为名词隐喻、主-谓-宾动词隐喻和形容词-名词隐喻三种[16]。Tsvetkov研究跨语言的隐喻识别,并提出一种基于语义特征的分类器,结合了语义类别、抽象度和命名实体类型[17]。目前多数隐喻数据集的标注工作都是由MIP理论[15]指导完成的,例如,VU Amsterdam隐喻语料库[18]、Mohammad动词隐喻数据集[19]等。
近年来,隐喻识别已成为序列标注任务,Wu等人提出一种基于Word2Vec、POS标签和单词蔟,由CNN和BiLSTM编码的模型[20]。Gao等人将GloVe[21]和ELMo[22]表示连接起来,由BiLSTM编码,利用softmax分类进行隐喻识别[23]。基于Transformer的预训练语言模型,例如,BERT[24]和RoBERTa[25],也在隐喻检测中有很大的积极作用。Zhang等将MIP[16]和SPV[15]两种语言规则转换为语义匹配任务,结合两者提出了MisNet模型,有效地解决了传统隐喻识别失效的问题[26]。Song等将动词隐喻转化为目标词与上下文的关系分类问题[27]。
中文方面的比喻识别工作相对较少。Liu等提出一个神经网络框架来优化比喻句子分类、比喻成分提取和语言建模三个任务,进行明喻检测和本喻体提取[28]。Zhu等提出FECRF(Figure Extraction CRF)模型,在RoBERTa基础上增加CRF层抽取比喻、比拟、借代、夸张、反语、通感、问语、排比、对偶、反复、对比以及引语这十二种修辞手法[29]。
2 数据标注与分析
2.1 标注内容
(1) 比喻句子
比喻是一种广泛存在于日常生活中的语言表达方式,本文主要关注明喻和隐喻。我们以句子为单位,标注每一句话是否为比喻句。本文没有区分明喻和隐喻,包括明喻或隐喻的句子均被视为比喻句。
(2) 论辩角色
参考Burstein等人提出的篇章要素定义和分类[30],将议论文中的论辩角色归纳为以下四类:
论点: 在议论文中,论点是指作者对作文主题表达的主张或观点。比喻论点是指采用比喻的修辞提出论点,例如,表1的句(1),将抽象的“理想”具体化为“沙漠绿洲”,表明理想对人的重要性。

表1 比喻论辩角色表
论据: 在议论文中,论据是指作者为证明论点所提出的依据,通常分为事实论据和理论论据。而比喻论据通常有两种形式: ①直接引用带有比喻修辞的名言、警句或诗句,如表1中的句(2); ②采用比喻的修辞手法对论据进行润色或阐释。
阐释: 在议论文中,阐释是对提出的论点或论据进一步阐述解释的过程。比喻阐释常常采用“作比较、打比方”的方式来证明论点。例如,表1中的句(3)为了论证阅读对我们的重要性,将“人”比成“鸟”,将“阅读”比作“鸟的翅膀”,将“丰富阅读”比作“丰满羽毛”,生动阐释“人需多读书”的观点。
其他: 比喻还可以用于情感增强等其他作用。在议论文中,比喻句能够更好地表达作者的思想,增强文章的感染力,但可能和主旨不直接相关。同时,比喻还能够用于描述风景和事物,例如,表1中的句(4),增强文章的艺术性和生动性。通常这类句子在论证方面并没有直接的作用。
(3) 论点类型
参考Wegemans等人对英文议论文中比喻的角色分类[9],我们进一步将议论文中的比喻论点划分为三种: 事实、价值和策略,以分析比喻论点传递信息的类型。
事实: 指某个实体(事物、人物、事件或行动),具有特定的经验属性。在议论文中,事实也是有争议的论点,并不是一个坚定的事实,但可以通过证据或经验加以证实。例如,表2中的句(1),将“商业化的文化”比作“快餐”,提出“如今的社会已经失去了文化的厚重感”的观点,这个事实论点是可以得到证实的。

表2 比喻论点分类表
价值: 指某个实体(事物、人物、事件或行动)具有特定的价值属性,通常包含作用、特点及褒贬评价。例如,表2中的句(2),作者将“安全”比作“金”和“福”,突出安全的重要性。
策略: 指应执行某项具体行动,通常是作者呼吁应该采取的行动。例如,表2中的句(3),将“梦想”比作“种子”,“实现梦想”比作“成为参天大树”,作者旨在呼吁人们要坚定信念,勇于奋斗,才能实现梦想。比喻策略论点在本文的议论文数据集中也较为常见。
(4) 论辩质量
本文的研究人员根据作文的整体论辩质量进行打分,从整体结构、主题相关性、中心明确性、论据合理性和丰富程度等多个角度切入,最终规定议论文整体论辩质量评分等级为优、良、中。
2.2 数据分析
本文所采用的数据集来源于“乐乐课堂网站”,由两位标注人员一起标注,标注结果的Kappa值为0.732,对于不一致的部分,选用第三位更专业的标注人员进行仲裁得到最终结果。其中包含1 220篇学生中文议论文,共标注2 889个比喻句,其中有1 050个论点句、413个论据句、1 259个阐释句、167个其他类型句。在比喻论点中,有54个事实,586个价值,410个策略。
1 220篇议论文平均每篇有2.37条比喻句。其中,评分为优的作文共有107篇,共包含338个比喻句,平均每篇3.19条;评分为良的作文共有640篇,包含1 488个比喻句,平均每篇有2.33条;评分为中的作文共有473篇,包含1 063条比喻句,平均每篇有2.25条。从比喻句的数量分布来看,得分高的议论文中比喻句的平均数量更多。
为了进一步探究比喻句和论辩质量的相关性,我们计算了所有议论文的论辩质量得分与其包含比喻句的数量之间的皮尔逊相关系数,结果为0.064,优和中的议论文与比喻句数量的皮尔逊相关系数为0.116。此外,本文还计算了比喻论点、比喻论据、比喻阐释和其他类型比喻句的数量与作文评分等级之间的相关性。由表3可知,比喻论点和作文评分等级(优、中)的相关性最大,为0.195,比喻论据次之,而阐述和其他的相关性相比较低。由此可知,比喻论点和议论文评分的相关性是最高的。进而本文又计算了事实论点、价值论点和策略论点与作文评分等级的相关性,如表3所示,策略论点最高,为0.158,价值为0.141,事实论点相关性最差,为0.006。由此可知,议论文写作时,在价值论点和策略论点中合理运用比喻能够提升作文得分。

表3 议论文得分和比喻角色相关性统计表
3 比喻论证分析系统
我们构建了一个比喻论证分析系统,包括3个主要模块。图1展示了该系统的流程图。输入一篇议论文作文,比喻识别模块能够自动识别其中的比喻句,论辩角色识别模块能够识别整篇文章句子级的论辩角色。结合这两个模块的输出,系统能够得到比喻论点。比喻论点作为论点类型分类模块的输入,该模块完成了比喻论点作为价值、事实、策略的三分类任务。

图1 比喻论证分析系统流程图
3.1 比喻识别
本模块将议论文在句子级别分类为: 比喻句和其他句。尝试了基于抽取的FECRF方法[29]和基于精调BERT[24]等预训练语言模型的分类方法。
(1) FECRF
FECRF使用RoBERTa结合CRF层抽取包含比喻、比拟等十二种修辞手法[29]。我们将此模型应用于议论文数据集中比喻和比拟句的自动识别。
(2) 基于精调预训练语言模型的方法
将比喻识别视为二元分类问题,采用预训练语言模型作为基础模型,训练比喻识别器。
3.2 论辩角色识别
本模块将论辩角色分类为论点、论据、阐释和其他。由于流水线系统在论辩角色识别模块中只筛选论点,因此本模块采用BERT等预训练语言模型,训练一个二元分类器,论点标签为1,其余三个论辩角色标签为0,主要评估模型对比喻论点的二分类效果。我们尝试了直接用比喻句作为模型输入以及将比喻句和作文题目进行拼接作为模型输入两种策略。
3.3 比喻论点类型分类
本模块将比喻论点分类为: 价值、事实或策略。尝试了基于精调和基于提示的方法。
(1) 基于精调预训练语言模型的方法
该模块采用BERT等预训练语言模型作为基础模型训练一个比喻论点三分类的分类器。
(2) 基于提示大语言模型的方法
Wei等人[30]提出了一种新的思维链和小样本学习的方法,用于在三种大型语言模型上进行实验。研究结果表明,采用思维链可以提高语言模型对算术、符号和常识推理的处理能力。此外,一些学者证实,在构造提示时,通过提供结构化的样例或标序号的方法,可以使大型模型表现更佳[31]。
我们使用OpenAI的GPT-3(Generative Pretrained Transformer 3)[32]大语言模型,通过构造思维链提示文本,与大型模型进行问答交互,诱导其完成比喻论点的三分类任务。采用了三种提示文本,如表4所示。

表4 用于比喻类型分类的提示文本设计
零样本学习给出论点类型分类以及事实、价值和策略的相应定义,引导模型生成答案。
小样本学习进一步增加了N组示例,每组样本由三个不同类别的句子构成。
小样本思维链学习通过思维链的方式增加了N组示例。
4 实验
4.1 实验设置
数据集被划分为训练集、验证集和测试集。测试集包括100篇议论文,余下数据的80%作为训练数据,20%作为验证数据。
本文采用了准确率(Accuracy)、精确率(Precision)、召回率(Recall)和宏平均F1值(macro-F1)指标对系统进行了评估。
比喻识别模块中,FECRF模块采用RoBERTa-zh-Large作为模型。基于精调BERT的方法采用BERT-Base-Chinese模型实现二分类,比喻句为正样本,其余句为负样本。考虑样本均衡,对负样本做抽样处理。扩充的对比实验模型采用BERT-Large(yechen/BERT-Large-Chinese)(1)https://huggingface.co/yechen/bert-large-chinese、DeBERTa(IDEA-CCNL/Erlangshen-DeBERTa-v2-320M-Chinese)(2)https://huggingface.co/IDEA-CCNL/Erlangshen-DeBERTa-v2-320M-Chinese。BERT-Large是比BERT更大规模的模型,DeBERTa采用比BERT更先进的解耦注意力的训练策略。
论辩角色识别和比喻论点类型分类也使用BERT-Base-Chinese模型作为基础模型。训练时均采用Adam作为优化器,学习率为2e-5。
基于大模型的比喻论点类型分类通过调用GPT3的API进行测试。
4.2 比喻识别结果
我们将FECRF模型与基于预训练语言模型的比喻识别模型进行对比。如表5所示,FECRF识别出的比喻精确率高达92.5%,但召回率较低;而BERT-Base在经过我们的数据集精调之后,精确率低于FECRF,但召回率值为89.5%,远高于FECRF,F1值为78.5%,体现了更好的识别效果。这是因为我们的数据集中有大量隐喻,而FECRF对明喻学习效果很好,对隐喻学习效果不佳。

表5 比喻识别结果对比 (单位: %)
4.3 比喻论辩角色识别结果
我们假设所有比喻被正确识别,以分析比喻论辩角色识别。结果如表6所示,可以看出,主题词的加入并没有使模型分类效果提升。我们的本意是捕捉比喻句与主题之间的关联帮助区分其角色,但从实验数据可得出,主题词帮助作用不大。BERT-Base的F1值最高为67.9%,其余预训练语言模型的效果仅次于BERT-Base。比喻论辩角色分类任务具有极强的挑战性,并且模型只关注比喻句本身可能无法获得更多有效的信息。
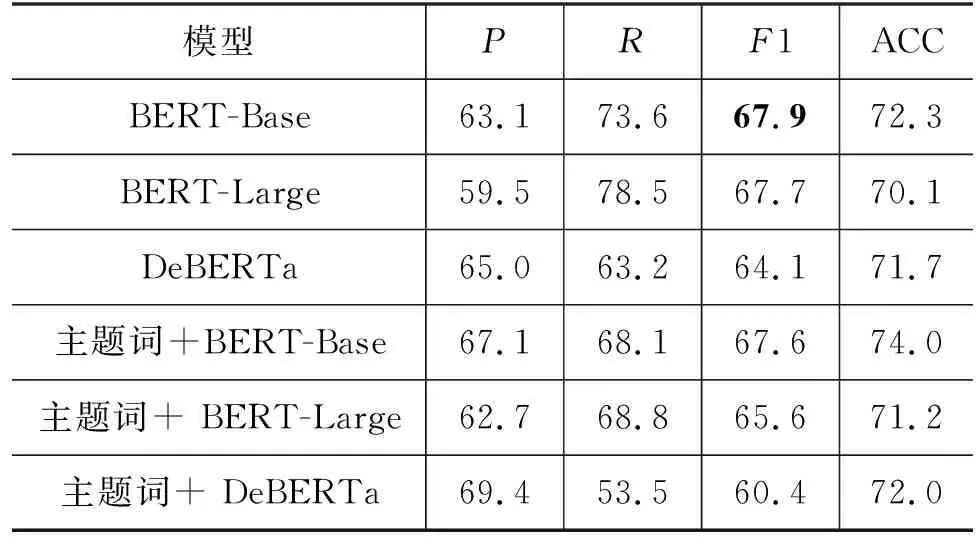
表6 比喻论辩角色识别结果对比 (单位: %)
4.4 比喻论点类型分类结果
我们首先假设比喻句和论点句都被正确识别,将基于精调预训练语言模型的方法和GPT3提示学习的方法进行对比,实验结果如表7所示。

表7 比喻论点类型分类实验结果 (单位: %)
从表7中可以看出,在四个评估指标上,有监督学习的效果依然优于GPT3,其BERT-Large的Macro-F1值高达69.6%,BERT-Base的ACC值高达80.6%。经过分析BERT-Base的错误数据,在144条测试数据中,模型将事实论点预测为价值论点9次,事实论点的数据较少,模型学习效果较差;策略论点预测为价值论点11次,我们观察具体的错误数据发现,一个单一论点可能既包含价值方面的陈述,也会存在策略方面的陈述,但在标注时,标注人员只根据句子中的核心成分定义比喻论点的类型。因此对于一个比喻句论点类型的分类问题,我们的模型依旧存在缺陷,后续的改进会加上句子核心部分的学习。在GPT3模型中,随着一组样本的加入精确率提高5.3%,Macro-F1值提升1.9%;当样本数量由一组增至两组时,macro-F1值降低1.2%,ACC值提升1.3%。随着思维链的加入,一组样本的表现并没有太大进步,但两组样本+思维链学习和两组样本学习相比,精确率提升8.4%,Macro-F1值提升4.7%,说明思维链对大语言模型正确理解任务并推理的帮助很大,并且在思维链模型中,样本数量的增多使模型的效果有较大提升,在样本学习模型中两组样本学习的Macro-F1值却比一组样本学习的差,说明样本的质量和思维链的使用对模型学习的效果具有一定影响。
为了研究比喻在论点中的支撑作用或核心作用对比喻论点分类的效果的影响,本文将测试集按照比喻是否为论点核心分为两部分: 比喻成分为论点核心和比喻成分用于支撑论点。例如,“人生,就像一条有尽头似乎又没尽头的路”这个论点中的比喻成分起到核心作用。在“人生亦如这本险遭埋没的童话: 站对舞台,造就成功”一句中,核心成分在“站对舞台,造就成功”,这是一个策略论点,而前面的比喻成分仅起到支撑论点的作用。
我们发现,比喻在事实论点中通常并不起核心作用,而是起到润色或支撑的作用,而比喻在一个价值论点中通常起到核心作用。从表8的数据中可以看出,当比喻作为论点的核心成分时,预训练语言模型和GPT3的分类效果均要优于比喻作为支撑作用的效果,说明比喻作为论点核心时,机器能够学到更多和比喻论点类型相关的信息。BERT-Large在比喻作为论点核心的数据集上分类效果是最优的,Macro-F1值高达70.8%,BERT-Base的ACC值高达84.1%。当比喻用于支撑论点时,GPT3两组样本学习的ACC值比一组样本提升8.1%。
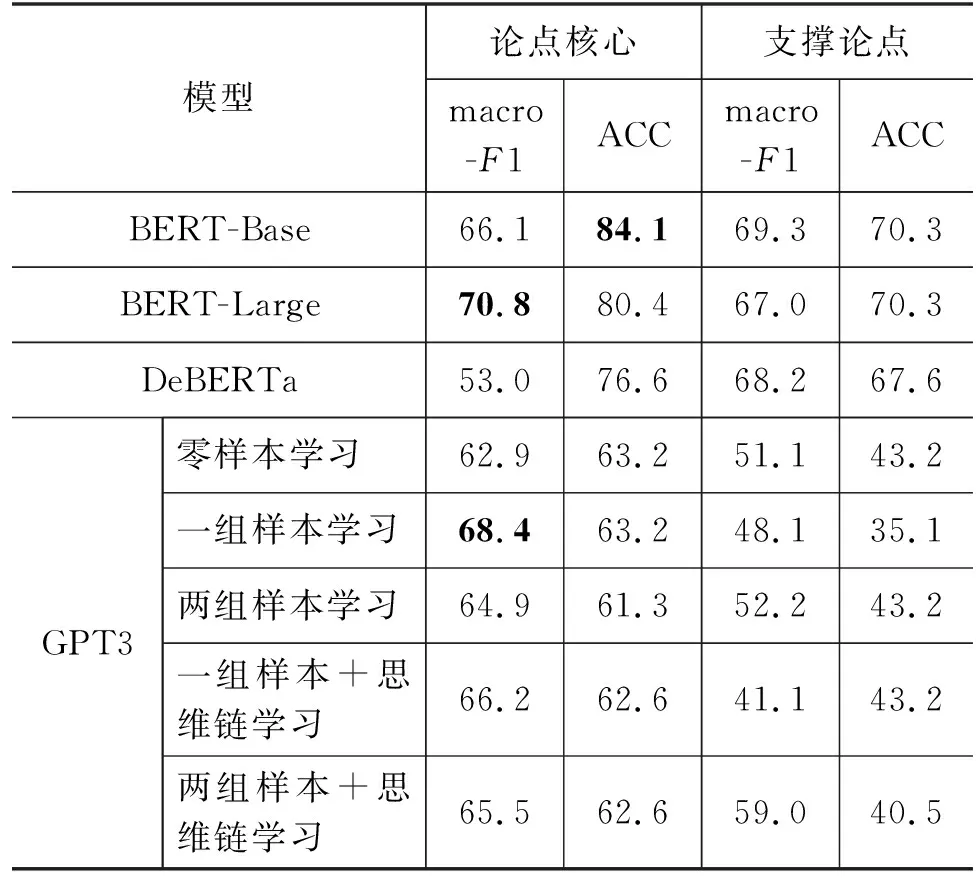
表8 核心/支撑比喻论点分类实验结果 (单位: %)
4.5 端到端流水线系统评价
最后,我们使用自动的比喻识别和论辩角色分类模块,测试流水线系统的性能。比喻识别模块选用基于精调BERT的模型,论辩角色分类模块选用不加主题词的基于精调BERT的模型,论点作用分类模块选用基于精调BERT模型,这三个模型拼成整个流水线系统。经测试,该流水线系统进行比喻论点分类的实验指标如下:P值为44.0%,R值为28.2%,Macro-F1值为34.4%,ACC值为51.4%。由此结果可知,每个环节都起重要作用,该任务具有挑战性,其中最难的模块是比喻论辩角色识别任务,模型在预测时会将论证和论点识别混乱,因此后续需进一步探讨如何使模型更好地区分论证和论点。该任务的数据集存在不均衡的问题,事实比喻论点分布较少,论点多类型问题需要进一步探讨,因此仍然有较大的提升空间。
5 总结
本文主要针对学生议论文中的比喻论证进行挖掘、分析与处理。我们通过数据集构建与分析探讨了学生作文中的比喻论证运用情况。我们发现,在比喻论证中,和作文评分最相关的是比喻论点。因此,本文重点研究比喻论点的作用和分类,结合相关理论,将比喻论点划分为三种类型: 事实论点、价值论点和策略论点。本文提出了比喻论证分析系统,该系统包含三个模块: 比喻识别、论辩角色识别和比喻论点类型分类。实验结果显示,比喻识别和论辩角色识别可以取得中等的识别效果;在比喻论点分类任务中,有监督学习方法通常优于基于大模型的方法,而思维链学习则对大模型处理比喻论点分类任务有一定帮助。由于多步骤错误级联,基于自动识别模块的比喻论点分类流水线系统的表现仍有较大的提升空间。
本文是针对比喻在论辩文本中作用分析的初步尝试。比喻,尤其是隐喻,不仅是修辞手法,也是认知推理过程,我们将在未来工作中进一步融入隐喻解释,考察隐喻的真实含义以帮助论辩角色识别。此外,我们也将考察隐喻的新颖性和创新性,分析它们对论辩质量的影响。在论辩文本生成中,引入比喻的论辩类型或论点类型作为指导信息也有助于生成更有趣的比喻论点。
猜你喜欢
快乐作文(7.8年级)(2022年2期)2022-04-15 23:33:57
文苑(2020年12期)2020-11-19 13:16:26
学生天地(2020年28期)2020-06-01 02:19:04
疯狂英语·新策略(2019年12期)2020-01-04 02:48:04
小学生必读(低年级版)(2016年5期)2016-12-01 06:04:57
作文评点报·低幼版(2016年35期)2016-05-30 10:48:04
作文周刊·高一版(2016年6期)2016-05-09 22:39:57
中共党史研究(2014年1期)2014-04-27 14:33:12
语文知识(2014年11期)2014-02-28 22:01:16
语文知识(2014年11期)2014-02-28 22:01:15
