
中英双语政治论辩挖掘任务数据集建设
2024-01-20 02:22:18张霄军周静狮
中文信息学报 2023年10期
张霄军,周静狮
(1. 西交利物浦大学 人文社科学院,江苏 苏州 215123;2. 广东省安全智能新技术重点实验室,广东 深圳 518055;3. 西交利物浦大学 智能工程学院,江苏 苏州 215123)
0 引言
论辩挖掘(Argument Mining)的主要任务是从非结构化文本文档中自动检测、分类和提取论点,以便为机器学习及深度学习模型提供结构化数据[1]。它是计算论辩中一个重要的任务,而计算论辩作为情感计算的子任务, 在自然语言处理诸多下游任务中越来越受到重视。这是因为论辩挖掘以创新的方式处理来自网络的信息,特别是来自社交媒体的信息,具有潜力非凡的应用价值。论辩挖掘系统可以对专业报纸文章、政府报告、法庭判决记录、在线社交网络内容中的论点、决策、评论等进行大量的定性分析,为社会和政治科学领域的决策者和研究人员提供前所未有的自动化工具,为企业市场营销创造新的前景。在林林总总的论辩挖掘应用场景中,政治论辩挖掘关注的是政治话语和评论,但政治话语不同于法庭记录和用户评价的“直接”陈述事实、表述诉求或者发表褒贬,而是充斥着外交辞令、政治表达和演讲修辞。这对论辩挖掘任务而言是一个挑战——系统得兼顾语用(Pragmatics)而非单纯语义(Semantics)去理解政治话语。
受制于训练语料资源稀缺,论辩挖掘在中文政治领域的实验研究仍属于空白地带。外交作为政治的窗口,外交文本中的外交辞令、外事问答以及外宣公告都蕴含着丰富而微妙的政治论辩技巧,在外交领域开展政治论辩挖掘研究具有现实意义和应用价值。“多语外交对话语料库”是一个在建的基于中国外交部例行记者招待会和外交部新闻发言人表态和电话答问的中外多语转录文本的多语问答语料库,其例行记者招待会和新闻发言人电话答问实录文本是构建对话式中文政治论辩挖掘任务数据集的理想数据来源,其新闻发言人表态文本则是构建单篇式中文政治论辩挖掘任务数据集的理想数据来源。鉴于不同语言在表达政治观点时的语用方式不同,如中文表达相对委婉谨慎,而英文表达相对直接大胆,双语平行政治论辩语料将会有助于系统更好地理解原文,因此该语料库又可以从跨语言论辩挖掘的角度提供新的中文政治论辩挖掘任务及数据集。
1 现有的政治论辩数据集
根据石岳峰等[2]的综述,目前用于政治论辩的论辩挖掘任务数据集主要有三个: USElecDeb60To16[3]、the UK 2015 Political Election Corpus[4]和The American Presidency Project[5]。也有研究者[6-8]自建小规模论辩语料库从不同视角设计不同论辩挖掘任务进行研究。
USElecDeb60To16数据来源为美国总统竞选辩论委员会网站(Commission on Presidential Debates(1)https://www.debates.org/,目前该网站数据已经更新至2020年特朗普与拜登总统竞选辩论会。),包含自1960年肯尼迪与尼克松总统竞选辩论会至2016年克林顿与特朗普总统竞选辩论会全文转写,以及副总统竞选全文转写, 共计39篇转写文本。Haddadan等人[3]将其切分为6 601个话轮(Speech Turns)共计34 013个句子和676 227个词例。人工标注两种论辩成分——“主张(Claims)”和“举证(Premises)”,其中,标注主张16 087项,标注举证13 434项,共计29 521项。他们将这些标注好论辩成分的句子分成三个数据集: 训练集(含13 894个论辩标记)、验证集(含6 577个论辩标记)和测试集(含9 050个论辩标记),设计了两个分类的论辩挖掘任务: 论辩句检测和论辩成分识别。
Lippi和Torroni[4]选择英国星空新闻频道(Sky News)2015年4月2日7位英国首相候选人的论辩节目,截取其中三位候选人(卡梅伦、克莱格和米利班德)的386个视频片段(卡梅伦122段视频、克莱格104段视频、米利班德160段视频)并将其转写为实录文本,转写文本共9 666个词例(卡梅伦3 469词、克莱格2 849词、米利班德3 348词)。人工只标注视频片段是否包含主张,设计的论辩任务也只涉及待检测论辩句是否包含主张。
Menini等人[5]的数据也是美国总统竞选辩论,但只选取1960年肯尼迪和尼克松的竞选辩论文本。数据集来源并非美国总统竞选辩论委员会网站,而是美国总统竞选项目(The American Presidency Project(2)https://www.presidency.ucsb.edu/)。该项目不仅收集历届美国总统的竞选辩论文本,还收集任何与总统竞选相关的可公开获取的政治文本,如白宫新闻中心发布的声明、记者招待会实录等文本。因此该数据集包含881篇文本逾160万词例(肯尼迪约81.5万词例、尼克松约83万词例)。根据美国史专家的建议,他们将这些文本分为五个主题,“古巴(Cuba)”“裁军(Disarmament)”“医疗健康(Health-Care)”“最低工资(Minimum Wage)”和“失业(Unemployment)”,抽取各个主题文本中的论辩对共计19 888对(“古巴”4 229对、“裁军”2 508对、“医疗健康”3 945对、“最低工资”6 341对、“失业”2 865对)。从中随机抽取1 907组论辩对,人工标注每组论辩对的关系(“支持(Support)”“反对(Attack)”和“无关(No relation)”),论辩挖掘任务设定为论辩关系预测。
Duthie和Budzynska[6]的数据集来源于英国议会会议事录(UK Hansard(3)http://hansard.millbanksystems.com/),他们抽取了撒切尔夫人主政时期(1979—1990)的90篇实录文本,每篇文本均由一位英国议会议员发问开头,然后是某位大臣的回答,接下来进入辩论环节。论辩挖掘任务主要针对“听众喜好判断(Ethos Mining)”,即听众对说话者有一个先验的认知,如果听众认为说话人是个“好人”,那对说话人的观点会积极回应并支持,反之,如果听众认为说话人是个“坏人”, 那他对说话人的观点会进行攻击[7]。“听众喜好判断”就是根据听众对说话人的回应表达(Ethotic Sentiment Expression, ESE)来预测该听众对说话人的观点是支持还是反对。语料标注内容包括“说话者(Speaker)”“目标(Target)(4)即ESE所指的内容或者观点。”“喜好支持(Ethotic Support, +ESE)”“喜好反对(Ethotic Attack,-ESE)”。他们选取60篇文本做训练集,剩余30篇文本做测试集。数据集共标注638句ESE(反对的有469句,支持的有169句),涉及149位说话者和188项ESE所指观点,共计90 991词例。
Cano-Basave和He[8]将说服性论辩(Persuasive Argumentation)识别应用于政治论辩。该研究用到了两种语料: 说服性文本语料(Persuasive Essays, PE)和政治辩论语料(Political Debates, PD),前者用到了说服性文本语料库[9],后者用到了美国总统竞选项目语料库。说服性文本论辩识别任务数据集标注项包括“主张(Claim)”“举证(Premise)”“正向论辩(ForStance)”“负向论辩(AgainstStance)”“支持(SupportRel.)”和“反对(AttackRel.)”。他们应用“语义框架网络(FrameNet(5)https://framenet.icsi.berkeley.edu/fndrupal/)”来解析从两个语料库中选择的90篇说服性文本和20篇政治论辩文本的所有句子,得到每个句子各个成分的语义框架并将其投射到数据集各个标注项。
Visser等人[10]选择了美国总统竞选项目中有关2016年希拉里·克林顿和特朗普之间的电视论辩视频内容,包括期间共和党、民主党以及总统候选人之间的各种论辩视频及其转写文本。他们也将短视频平台Reddit(6)https://www.reddit.com上那段时间发布的竞选短视频评论文本纳入其语料库the US2016 Corpus中。这样,整个语料库就是由US2016tv和US2016reddit两部分语料构成,每一部分包括共和党语料US2016R1(分为US2016R1tv和US2016R1reddit)、民主党语料US2016D1(分为US2016D1tv和US2016D1reddit)和候选人语料US2016G1(分为US2016G1tv和US2016G1reddit),其中字母R、D和G分别指代“共和党(the Republican primaries)”“民主党(the Democratic primaries)”和“候选人(the General election)”,数字“1”指的是只收集了以上三种辩论的第一轮辩论内容。该语料库及其子语料库均发布在AIFdb语料库网站(7)www.corpora.aifdb.org[11]上,可以公开获取。整个语料库共计97 999词例(其中电视竞选辩论58 900词例、短视频评论文本39 099词例)。在论辩内容标注上,他们选择10.5%的电视竞选辩论文本和10%的短视频评论文本作为标注样本,标注项包括: “论辩单元(Locution)”“话轮转换(Transition)”“言语行为(Illocution)”“观点主张(Proposition)” “接受(Inferences)”“冲突(Conflicts)”和“重述(Rephrase)”。每项标注均由5位标注者在论辩标注平台OVA(8)www.ova.arg.tech上独立完成,最后达成一致,最终在标注样本中产生了8 099个“观点主张”标记、2 754个“接受”标记、823个“冲突”标记和620个“重述”标记。他们并未设定特定的论辩挖掘任务,但是说明了该数据集的潜在应用场景,如为深度学习在论辩挖掘中的应用提供资源、为实证的文本分析研究提供量化数据等。
Guo等人[12]的工作虽然并不是直接的论辩挖掘,但他们所使用的语料库是解密的外交文本,是将政治论辩具体化为外交论点挖掘的有用资源。他们的工作是利用美国国家档案局(The U.S. National Archives)解密的1973—1977年间外交文档来完成外交事件抽取和预测。这些文档每篇都有一个主题编码(TAGS),如MNUC指的是“军事与国防事务-核武器使用(Military and Defense Affairs-Military Nuclear Applications)”,VS指的是“南越(Vietnam (South))”等。这些主题编码方便文档按照主题分类,Menini等人[5]的政治论辩挖掘任务就是基于主题分类进行的。
以上是对目前政治论辩挖掘领域所使用的数据集的一个综述,可以看出来,这些数据集和语料都是英语单语的,尚没有发现其他语言的政治论辩挖掘任务中可以利用的数据资源,跨语言政治论辩挖掘研究也属于学术空白。
2 外交对话多语语料库建设
“外交对话多语语料库”建设的初衷其实并不是为了政治论辩挖掘任务,而是为了面向国际关系研究、外交语言研究、外事翻译研究以及对话机器翻译研究的多语平行语料库。在建设过程中,笔者越来越感觉到外交内容挖掘的重要性,并论证了将该语料库应用于中文外交(政治)论辩挖掘任务的可行性,提出在该语料库基础上标注中文政治论辩挖掘任务数据集的想法。
我国外交部自2011年起就将例行记者招待会实录文本及其外文翻译分别公开发布在外交部中外文网站上。截至2022年10月1日,已有2 739篇中文、英语、法语、西班牙语、阿拉伯语和俄语的例行记者招待会平行实录文本公开发布。数据规模相当大,目前中文文本达到957万汉字,英语文本已经达到627万英语词例,法语文本达到793万词例,西班牙语文本达到810万词例,阿拉伯语文本和俄语文本规模也都在500万词例以上。此外,外交部就某个特定外交事件的发言人表态和就某个重大外交事件的中外媒体吹风会等实录文本及其外文翻译文本也在外交部网站公开发布,语料库数据规模仍在不断增加。外文翻译均由外交部翻译司专业译员完成,翻译质量可以保证,因此,这个语料库首先是一个质量上乘的大规模多语平行语料库,可以直接应用于外事翻译研究和面向特定领域的多语种机器翻译使用。其次,外交部例行记者招待会充满唇枪舌战,没有充分的准备和高超的话语技巧是很难胜任外交部发言人这个职位的,因此,该语料库又是一个研究外交语言和外交话语策略的有力资源。还有,问答内容都是有关我国外交事务的,从彼此的一问一答之中,可以窥见我国在地缘政治、国际冲突、国内矛盾以及国际合作等事件中的态度和立场,是研究国际关系的第一手素材。
记者招待会都是以问答的形式进行,即“记者提问+新闻发言人回答”的模式,有时会有记者的追问,新闻发言人一般会有补充回答,总之,都是一问一答。一般来说,一个问答可以视为一个话轮,因为下一个问答的内容就是另外一个对话主题了,所以话轮分界比较明显。目前,对于话轮主题的标记集已经制定完成,由“国际冲突(IC, International Conflict)”“国际合作(GC, Global Cooperation)”“地缘政治(GP, Geopolitics)”“国内矛盾(DC, Domestic Contradiction)”“体育文化(PC, PE and Culture)”“民生经济(CE, Civilian Economy)”五个标记集构成,每个标记集下面有若干子集,每个主题类型都赋予一个独一无二的标记。话轮的其余元语言标记(问答日期、提问者、回答者等)均已标注完成,话轮切分也已全部完成,其中中文文本共切分为22 344个话轮。
由于我国和英美国家的政治体制不同,在中文政治论辩挖掘领域没有可以应用的辩论文本,所以中文政治论辩挖掘研究尚没有公开发表的研究成果。尽管外交部例行记者招待会上的问答实录不能完全体现中文政治论辩的全部特征,但外交智慧就体现在一问一答之间,外交立场就建立在唇枪舌战之中,政治态度就蕴含在每个话轮之中。基于这样的语料库,我们可以设计独具特色的中文政治论辩挖掘任务,并开发相应的任务数据集。
中文外交辞令中很少直接说“不”或者“是”,这就很难给论点贴上“支持”或者“反对”的标签,这对于论辩挖掘任务而言就是一大挑战了。例如,图1的话轮中抽取到的问话人“澳亚卫视记者”的观点是括号中的“在当前世界经济放缓的背景下,中国不愿推出更多经济刺激措施,给美支持国际经济增长带来更大压力”,但中国外交部发言人,即说话者“赵立坚”的话语中并不能直接抽取出对上述观点持“支持”或者“反对”的举证,甚至感觉有些“答非所问”。实际上,“答非所问”就是一种外交辞令,因为无论外交部发言人直接回复“是的,中方不愿意”或者“不,中方已经推出了相关举措”,都会给别有用心的外媒留下口实或者引发下一个追问。实际上,澳亚卫视记者的提问“中方对此有何回应?”预设了“中国不愿推出更多经济刺激措施”和“美国支持国际经济增长”两种观点。此时,发言人既需反驳前一种观点,又要驳斥后一种预设。所以,发言人在阐述了中国的负责任经济举措之后,立即转向“反观美国”,对第二种预设予以充分且强有力的驳斥。

图1 表示“主张”的论辩句标注示例(中文)
鉴于不同语言在表达政治观点时的语用方式不同,如中文表达相对委婉谨慎而英文表达相对直接大胆,双语平行政治论辩语料将会有助于系统更好地理解原文,因此可以从跨语言论辩挖掘的角度提供新的中文政治论辩挖掘任务及数据集。Toledo-Ronen等人[13]已经验证了多语言论辩挖掘的可操作性,但缺乏真实的对应的多语文本,他们只能使用机器翻译生成其他五种语言的“准平行文本”来进行训练和测试。Eger等人[14]也是采用机器翻译的方法来完成跨语言论辩挖掘任务的。Liu等人[15]利用汉英双语平行语料库实现了双语对话推荐系统,此方法可以借鉴到双语论辩挖掘任务中来。Shimizu等人[16]则是实现了利用英语标注来提高日语图片问答系统性能的生成任务,但该方法可否迁移到论辩挖掘任务中来还需要实验验证。无疑,“外交对话多语语料库”中高质量多语平行语料可以为跨语言对话式政治论辩挖掘任务提供数据支持。
3 中文政治论辩挖掘任务数据集
论辩挖掘任务一般可以分为三种: 论辩对识别、论辩关系预测和论辩数据评估。为了方便顺利开展这些论辩挖掘任务,一般需要对论辩数据集进行加工标注,最基本的标注内容就包括主张和举证。我们从“多语外交对话语料库”中随机选择200篇中文及其对应的200篇英语例行记者会实录文本进行论辩标注,这400篇实录文本包含1 536个话轮。
我们定义“主张”为主观性、询问式、结论性话语,定义“举证”为客观性、陈述式、解释性话语。“举证”话语是“主张”话语的证据和例示。图1和图2是我们的一些标注示例: 图1是“主张”的标注示例,图2是“举证”的标注实例,这两个例子均出自同一个“话轮”——2022年9月22日外交部例行记者会话轮1(BiDAM-20220922-ZH/EN-T1-CE)。根据Visser等人[17]的论辩标注体系(Annotating Argument Scheme),只要满足有主语、有谓语就可以进入论辩句标注序列,间接引语和直接引语如果是句子,那就要纳入到论辩句识别的范畴。当援引某种说法时,这种说法本身一般是结论性的,应该标注为“主张”,但援引本身又是例证,所以整个援引句又是“举证”。值得注意的是: 句号不能作为汉语句子的句界标记,因为句号句并不是一个汉语句子。实际汉语文本中句号的使用常常带有随意性,因此句号句不具备当作基本语法单位的资格[18]。宋柔[19]认为汉语句子的句界不会出现在标点句的句内,只能出现在两个标点句之间。这会给汉语句子完全句法分析带来困扰,同样也会给汉语论辩句句界检测带来挑战。

图2 表示“举证”的论辩句标注示例(中文)
这1 536个话轮由3位标注者共同标注完成,但每个话轮都由至少两位标注者进行独立手工标注,标注质量评估指标为内部标注一致性(Inner-Annotation Agreement, IAA),一般用卡帕检验(Kappa test)公式[20]进行验证。我们在句子层观察到论辩句标注一致性达到了85%,κ=0.63;在论辩构件层观察到的标注一致性达到了67%,κ=0.51。这说明在政治文本中标注论辩句时,有时候标注者很难达到一致。在这个话轮中,一个争论的焦点是英语文本中“The US, however, is another story.”该不该标注为“主张”,两位标注者认为不应该标注,一位标注者认为应该标注。经过协商沟通最终达成一致——不标注。因此,在这个话轮中总共标注了7句表示“主张”的论辩句和9句表示“举证”的论辩句,如表1所示。
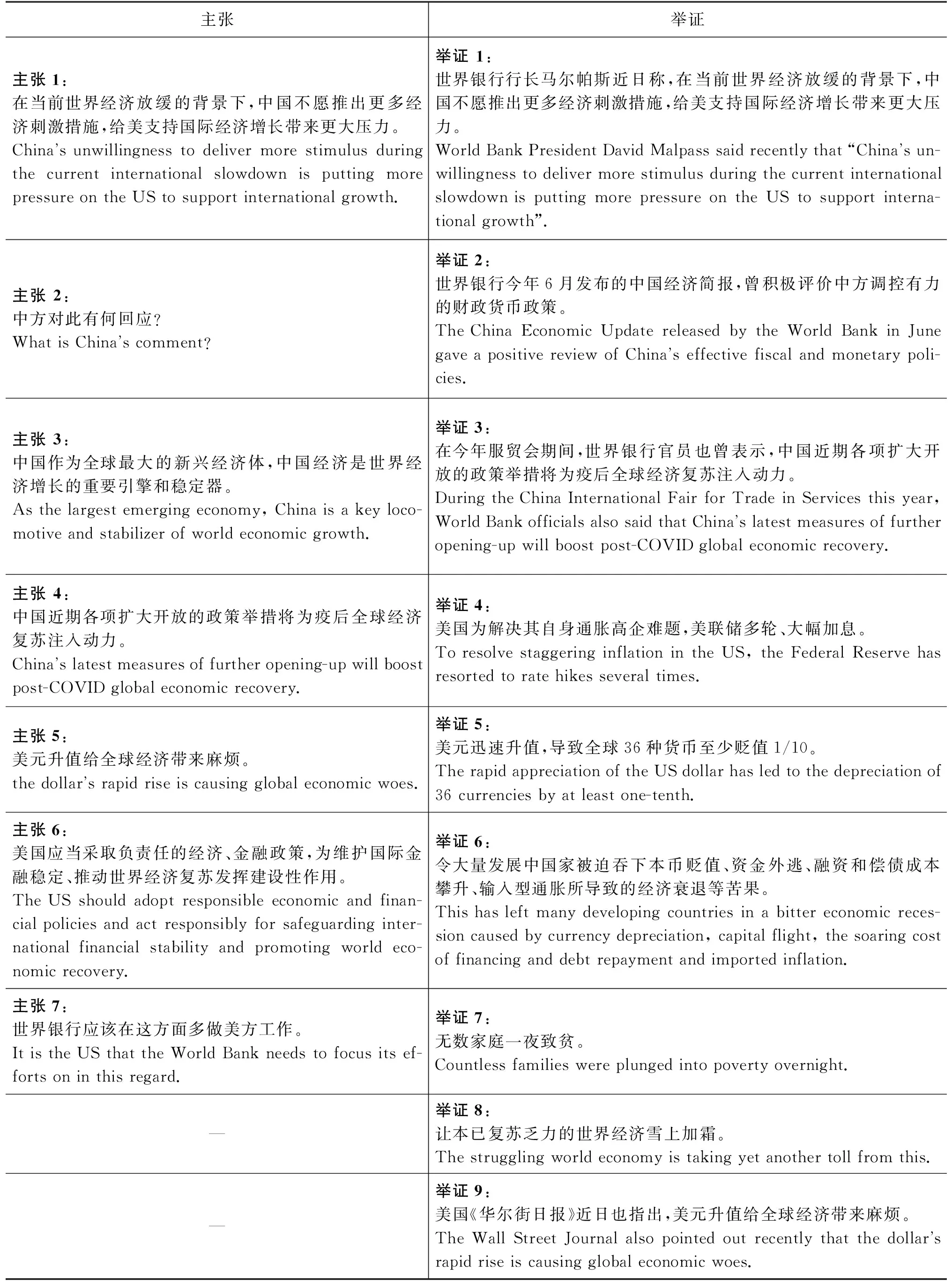
表1 论辩句标注示例话轮中的“主张”和“举证”
我们标注了每个话轮中各个论辩句之间的关系,发现在同一话轮之中,除了“主张”与“举证”之间的“支持”“反对”与“无关联”这三种关系外,提问部分和回答部分的“主张”和“举证”之间还存在“蕴含”关系,如表1中的主张1和举证1之间就是蕴含关系;回答部分的“主张”有时与提问部分的“主张”也存在“支持”或者“反对”的关系,如表1中回答部分的主张4及主张6就和提问部分的主张1之间构成“反对”关系。同时,作为对提问问题的回应,回答部分的论辩句中的某些“主张”和/或“举证”与提问部分作为问题的“主张”之间构成“回应”关系,如表1中的主张3~7都是对提问部分主张2的“回应”。这样,我们就得到了示例中各个“主张”句及其“支持”“反对”“蕴含”和“回应”四种关系(“无关联”关系不包括在内)的论辩关系表(表2)。

表2 示例话轮中 “主张”和“举证”的关系
从表2可以看出,外交部发言人提出的第6条和第7条“主张”竟然获得了与之剑拔弩张、针锋相对的外媒提问者的第一条举证的“支持”。也就是说,发言人既通过举证(举证2~3)驳斥了提问者对己方主张(主张3~4)的责难,又通过举证(举证 4~9)反驳了对方主张(主张1)中的谬误,还通过己方的主张(主张6~7)获得了对方举证(举证1)的支持,体现了高超的外交才能,展示了精妙的外交论辩口才。
在我们选择的400篇外交部例行记者会实录文本标注中,共标注了12 288个论辩句(5 376个“主张”论辩句和6 912个“举证”论辩句)。Haddadan等人[3]指出在政治论辩文本中“主张”是多于“举证”的,因为辩论者在论辩时有时不举证。但我们的数据集并非严格意义上的论辩题材,更像是政治问答题材,所以“举证”数目多于“主张”数目是可以理解的。我们将这些标注好的语料提取出来作为中文政治论辩挖掘实验的数据集,命名为“中英双语外交论辩挖掘数据集(Chinese-English Bilingual Diplomatic Argumentation Mining dataset, BiDAM)”。表3是该数据集的一些统计数据,如话轮平均长度和“主张”以及“举证”的平均长度等。

表3 “中英双语外交论辩挖掘数据集”统计信息
鉴于外交部例行记者会问答内容大都涉及对国际国内重大事件的态度和观点,论辩信息挖掘和情感态度分析这两类计算问题在这个领域就有了相辅相成的密切关联,因此我们对抽取出来的中英文论辩句均进行了情感分析计算。中文情感分析器使用的是SnowNLP(9)https://github.com/isnowfy/snownlp,情感极性区间为[0,1],抽取语句情感极性均值为0.83,情感倾向整体以褒扬为主;英语情感分析器使用的是TextBlob(10)https://github.com/sloria/TextBlob,情感极性区间为[-1, 1],抽取语句情感极性均值为0.67,情感倾向整体以中性偏褒扬为主。归一化处理之后,全部抽取出来的论辩句情感极性均值为0.75,整体情感倾向偏褒扬。这与我们的外交语篇分析结果一致,我国外交发言人倾向于展示积极、正向的态度,很少直接提出反对观点或者对提问者的主张进行直接抨击,这也是我国外交话语区别于他国外国话语的一大特征。
4 未来研究计划
接下来我们将利用BiDAM数据集进行中文政治论辩挖掘任务[21-24]的实验,以期验证该数据集的可用性,同时探索跨语言论辩挖掘的有效性。此外,在论辩挖掘领域用以训练有监督学习算法的标注语料库严重匮乏,我们尚有大量未经标注的语料,可以利用BiDAM来训练有监督学习算法,为自动标注论辩语料提供研究资源。我们在面向论辩挖掘任务的同时考虑到情感计算方向与其紧密联系,因此在面向论辩挖掘的同时,数据集也可用作情感分类任务。
猜你喜欢
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
湘潮(上半月)(2019年12期)2019-05-22 06:21:00
湘潮(上半月)(2019年8期)2019-05-22 06:01:58
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
海外华文教育(2016年1期)2017-01-20 08:21:58
人民中国(日文版)(2016年10期)2016-08-23 11:21:06
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
语言与翻译(2015年4期)2015-07-18 11:07:45
领导文萃(2015年4期)2015-02-28 09:19:03
民族古籍研究(2014年0期)2014-10-27 08:24:34
