
多层级特征增强聚合的遥感图像细小水体提取
2024-01-17 08:57孟月波刘光辉
探测与控制学报 2023年6期
孟月波,王 静,刘光辉
(西安建筑科技大学信息与控制工程学院,陕西 西安 710055)
0 引言
水体提取作为遥感图像地物分割中的一个重要任务,包含对河流、湖泊、坑塘及水库等丰富类型的提取,在水资源监测和自然灾害评估等方面具有重要作用[1]。目前高分辨率遥感图像水体提取方法在特征简单的大中型水体上呈现出较优的提取结果,但对于纹理、轮廓、光谱特征各有差异的细小水体提取的性能较差。细小水体是小尺度水体及细长狭窄水体的总称,在遥感图像中展现出多样的属性和细节信息[2],具有像素占比较少、特征不明显等特点。其中细小水体特征不明显主要表现在外部边界不清晰、纹理特征不突出、与邻近背景相似度高。因此,在遥感图像中可以捕获到的目标有效特征少且目标容易受到相似目标和其他地物阴影等背景噪声的干扰,这使得细小水体的精确提取更具挑战性。传统遥感图像水体提取方法处理流程繁琐且特征表达能力弱,难以满足不同区域细小水体提取对精度的要求。
随着深度学习的不断发展,深度卷积神经网络凭借其较强的深层次特征提取能力及非线性拟合能力被广泛应用于语义分割领域,在遥感图像水体提取方面取得了诸多研究成果[3-4]。文献[5]运用FCN提取水体相比传统算法取得最优解,但由于下采样路径多次池化操作逐渐降低输入特征图的分辨率,且细小水体自身空间分布较少,导致目标细节信息不断减少甚至消失,提取精度明显下降。文献[6-7]针对细节信息损失致使细小水体分割结果变差的问题,提出了改进的U-Net编解码网络,通过强化下采样结构和改变跳跃连接方式增强低维特征信息,弥补空间信息的损失,但细小目标很难通过跳跃连接恢复,从而影响细小水体预测结果。文献[8]在跳跃连接中添加残差卷积结构实现特征提取,增强中间层特征表达,但其直接在整张特征图上进行操作,未考虑细小目标的空间位置信息。文献[9]设计了中间层特征切分上采样模块用于自然图像分割,通过扩大区域内的目标提高其关注度,但特征提取能力欠佳,且网络结构过于冗余造成模型参数量较大。因此,本文认为结合特征切分从空间维度上放大细小目标,并设计高效轻量的重点区域特征提取结构是解决遥感图像细小水体有效信息提取量少的有效思路。
由于遥感图像中细小水体形状特征多变,纹理空间特征丰富,浅层特征无法满足细小水体的精准提取。文献[10]采用普通卷积作为骨干网络提取图像特征,但受限于卷积计算,小范围感受野不利于充分利用图像全局上下文信息进行特征捕获及更深层次的特征叠加,故选取性能优异的骨干网络挖掘稳定深层特征是细小水体精确提取的前提。文献[11-12]将编码器编码特征输入到4个不同扩张率的并行扩张卷积中进行学习,提取更丰富的深层次上下文特征,但膨胀率过大使得相邻像素无法参与运算,不利于图像连续信息的提取,导致细小水体分割效果较差,如何更好地利用空洞卷积进一步获取深层次语义特征是改善细小水体分割效果的关键问题。
细小目标亮度、轮廓等信息特征响应弱,易于地面其他相似物体相混淆是影响细小水体分割精度和实际效果的关键问题之一。一方面,文献[12-13]提出利用注意力机制增强网络对弱目标信息的感知,抑制图像噪声信息,但不同层级特征语义信息都有差异,仅将关注机制应用于单层特征图而忽略了不同层级特征的重要性,无法发挥其最大优势。另一方面,解码阶段将具有较高语义信息的高层特征与富含空间细节的低层特征进行特征聚合,获取更具有判别力的特征表达。文献[14]通过拼接操作聚合不同层级特征,但简单的聚合方式并未充分利用高低层特征之间的互补性,且额外噪声会干扰高层水体语义特征的表达。文献[15]设计特征聚合模块,通过对直接拼接后的特征辅以全局池化操作,生成全局上下文优化特征聚合过程,但其未考虑高低层特征之间的语义差距,直接利用低层特征帮助高层特征恢复图像细节,造成有用信息的丢失和无用信息的冗余,从而使网络模型的性能下降。
基于以上分析,本文基于U型网络提出一种多层级特征增强聚合的遥感图像细小水体语义分割方法(multi-level feature enhancement aggregation network,MLEA-Net),旨在充分保留遥感图像中的空间细节信息,同时获取高质量的语义上下文信息,改善最终输出特征图的质量,提高遥感图像细小水体的分割精度和效果。
1 相关研究工作
1.1 U型网络
U型网络采用编解码结构学习特征的丰富层次表达,编码部分对输入图像进行特征提取,解码部分将编码端输出特征图通过上采样还原至原图尺寸,结合跳跃连接融合多尺度特征信息,提供高低特征图的同时加速模型收敛。U型网络利用特殊对称结构在高分辨率图像中获取局部特征,在低分辨率图像中捕捉全局特征,实现端到端分割,被广泛应用于遥感影像水体提取任务。U型结构如图1所示。
1.2 CSPDarknet53特征提取
遥感图像中细小水体具有形状特征多变,纹理空间信息丰富等特点,其深度特征利用不足不能较好地满足细小水体的识别与提取。深度卷积神经网络CSPDarknet53[16]引入了CSP-Resblock_body模块,通过截断梯度流的方式防止过多重复梯度信息,既增强了网络对目标特征的学习能力,又解决了深层次网络带来的计算瓶颈问题,大幅节省计算内存的消耗;同时合理的卷积层数量设计使其感受野可覆盖更大的图像面积。所采用的CSPDarknet53由stem,stage0-stage4组成。stage0-stage4分别对应5个CSP-Resbody模块,5个模块中分别由1,2,8,8四个小的残差块组成,其中利用3×3卷积代替maxpool层实现下采样。另外网络前端的stem由1个3×3的卷积层组成。CSPDarknet53网络及CSP-Resbody模块如图2所示。
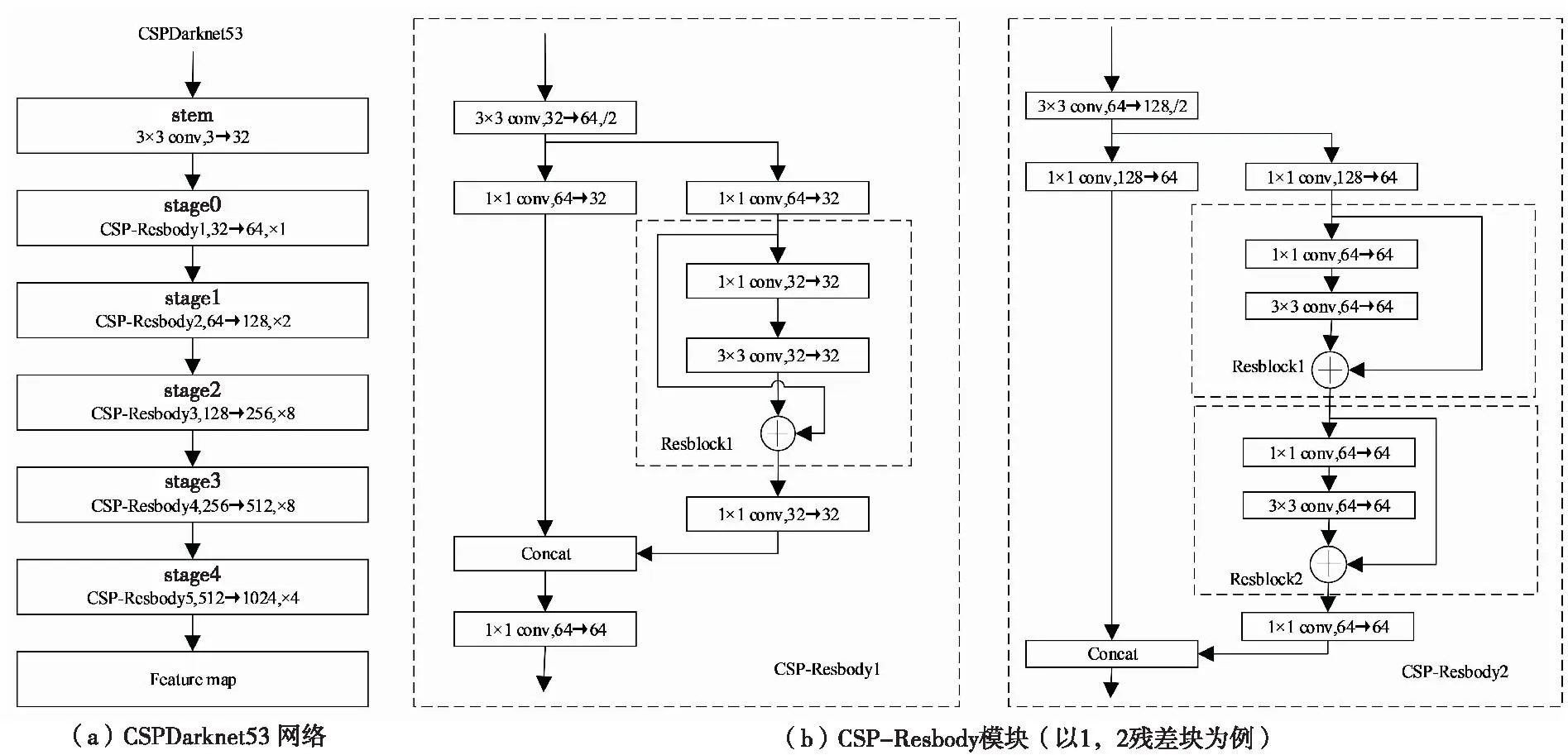
图2 CSPDarknet53 网络结构及CSP-Resbody模块Fig.2 CSPDarknet53 Network and CSP-Resbody module
图2(a)为CSPDarknet53的网络结构,图2(b)为CSP-Resbody模块,该模块在保持原来Bottleneck的基础上,利用卷积的方式将输入的特征分为两个部分,其中一部分做ResNet的残差卷积,另一部分为1×1卷积,最后与另一部分进行cat拼接操作,与单分支残差块相比,获取了更丰富的梯度融合信息且降低了计算量。
1.3 非对称卷积块
与普通卷积相比,非对称卷积块[17](asymmetric convolution block,ACB)用两个一维非对称卷积分别从水平和垂直方向对方核卷积进行特征增强,减轻冗余信息对捕获代表性特征的影响,然后将3个并行卷积核获取的信息集中到方核卷积,在不增加额外计算量的基础上,提取到丰富的空间细节信息,保证网络对各切分区域内目标具有良好地辨识能力,利用式(1)、式(2)描述非对称卷积块:
CXI=Lconv3×3(XI)+Lconv1×3(XI)+Lconv3×1(XIi),
(1)
(2)
式中,XI和XI1分别表示输入特征和输出特征,Var(·)和E(·)表示输入的方差函数和期望值,ε是保持数值稳定性的常数,γ和β是BN层的两个可训练参数,σ(·)表示ReLU激活函数。
2 多层级特征增强聚合的遥感图像细小水体语义分割模型
2.1 网络结构
本文方法的网络基本结构如图3所示,采用U型网络框架,具体包括4个部分:特征提取网络、细节特征增强模块(detail feature enhancement module,DFEM)、全局局部空间金字塔池化模块(global local-spatial pyramid pooling,GL-SPP)、双分支聚合模块(two-branch fusion module,TBFM)。特征提取网络以CSPDarknet53为主干网络采用stem,stage0-stage4卷积块连续下采样,得到多分辨率特征信息{E0,E1,E2,E3,E4}。将含丰富空间信息的浅中层特征{E1,E1}输入至DFEM模块,扩大不同尺度下局部区域的细小目标并捕获更加有效的上下文信息和全局信息,得到描述不同语义信息的特征{PE1,PE2},采用逐像素相加的方式将其与上一阶段的特征合并得到特征{DE1,DE2},以便后期编码阶段融合。编码末端特征E4通过GL-SPP模块生成优化特征EP4,实现深层次语义信息的充分提取和有效编码。在解码端4个A-TBFM模块用于逐步完成上采样特征聚合和恢复,通过相互融合和引导生成丰富特征{D1,D2,D3,D4},低层特征提供更精确的空间定位,高级特征增强信息的长期依赖性,提供更准确的类别一致性判断。通过4×4转置卷积将D1还原到原图像大小,使用3×3卷积将D0进行通道压缩,经由SigMoid函数映射完成输出。
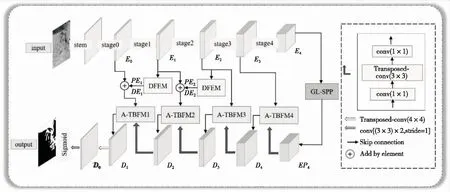
图3 网络基本结构Fig.3 Network basic structure
2.2 细节特征增强模块
中间层特征复用有助于网络对编码特征的增强和利用,是解决遥感图像细小水体提取目标有效信息量少的有效途径,其处理方式通常直接对整张特征图进行卷积操作。但对细小水体而言,其往往分布于图像的某一小块区域内,这种特征提取过程未考虑细小水体的空间位置信息,对处于图像某局部区域细小目标缺乏很好的关注,且随着特征提取层数的变多无法避免地增加了模型参数量。此外,根据可视化深度卷积神经网络,浅中层特征携带大量的空间细节信息,而高层特征基本不包含[18]。因此,如何以浅中层特征为主高效地捕获丰富信息是实现遥感图像细小水体提取的关键。
本文设计的DFEM模块从空间维度上划分浅中层特征,生成局部扩大区域以充分利用所携带的空间细节信息,然后将其输送到混合分层非对称卷积特征提取块(mixed layered asymmetric convolution feature extraction block,AFEB)获取对应区域下的语义类别信息,得到更具空间区域性质的上下文信息和全局信息,利用参数共享机制加强各局部扩大特征之间的联系,最后将获取的特征与解码阶段对应输出特征融合生成更全面的特征表达,达到增强细小目标特征辨识能力的目的。DFEM模块具体如图4所示,将DFEM模块附着在主干网络编码阶段{E1,E2}处,获取更加有效的浅中层特征。
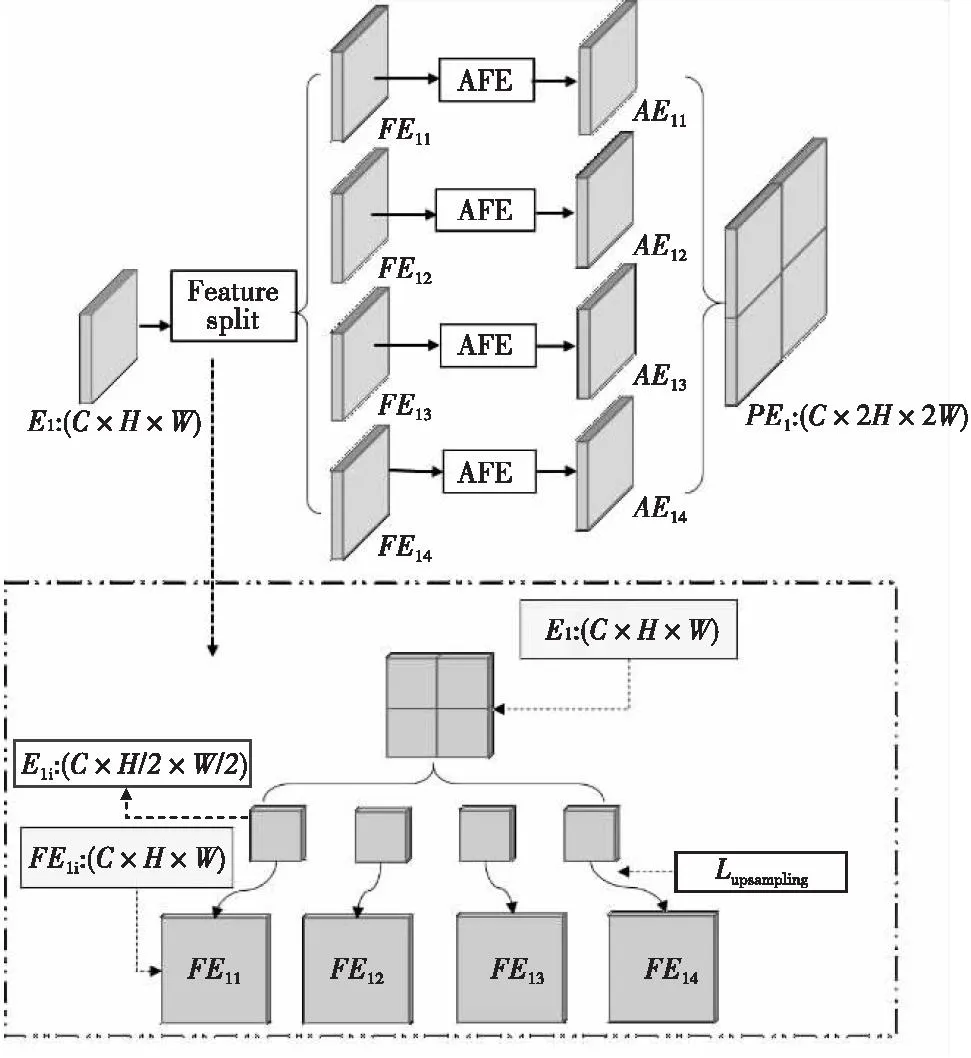
图4 DFEM模块Fig.4 DFEM module
以E1为例分析说明DFEM模块,当高度为H,宽度为W,通道数为C的输入特征经切分操作之后,得到2×2个张量大小为H/2×W/2×C的局部区域切分块E1i,利用式(3)将其还原至原特征大小,生成局部扩大区域特征FE1i:
FE1i=Lupsampling(E1i) (FE1i=1,2,3,4),
(3)
式(3)中,Lupsampling(·)表示双线性插值上采样。
AFEB具体结构如图5所示,以通道数为C的FE11为例,经方形卷积和带有扩张率的非对称卷积构成两条分支进行特征提取,提升卷积层的实际感受野,各分支分别对特征图维度进行压缩,之后将不同尺寸卷积核提取的特征在通道维度上进行拼接。利用扩张卷积的分层加法,在多尺度上下文中保留层次相关性,在特征图的计算中涉及更多像素。因此,叠加扩张非对称卷积特征提取层,获得不同尺度增强特征P,V,获取过程如式(4)、式(5)所示;结合两层生成的特征图得到深层次融合特征K,获取过程如式(6)所示。
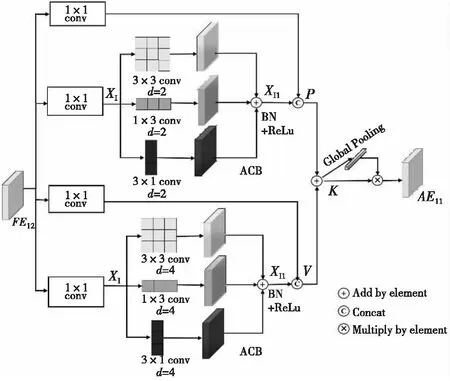
图5 AFEB具体结构Fig.5 AFEB specific structure
P=Lconv1×1×C′(FE11)·
‖LACB3×3×C′,rate=2(Lconv1×1×C′(FE11)),
(4)
V=Lconv1×1×C′(FE11)·
‖LACB3×3×C′,rate=4(Lconv1×1×C′(FE11)),
(5)
K=P⊕V,
(6)
式中,‖表示特征拼接,⊕表示按元素相加,LACB3×3×C′,rate=i(·)表示扩张率为i的非对称卷积块。
将全局平均池化操作扩展到特征提取中得全局特征信息,将该特征结合式(5)生成深层次融合特征K,通过式(7)获取更具空间区域性质的上下文信息表征AE11,其大小与初始特征E11保持一致。最后,将{AE11,AE12,AE13,AE14}在空间维度上重新拼接,生成通道数为C,高度为2H,宽度为2W的浅层优化特征PE1。该操作在不同的切分区域提取对应区域下的语义类别信息,从而能够关注区域内的细小目标,提供更加有效的浅中层特征信息。
AE11=GP(K)⊙K,
(7)
式(7)中,⊙表示按元素相乘,GP表示全局池化操作。
2.3 全局局部空间金字塔池化模块
高层次上下文语义信息的充分提取和有效编码是缓解浅层特征无法满足具有特征多样性的细小水体精确提取的常用手段,而扩张卷积和空间金字塔池化是捕获高质量语义上下文信息的有效模块。通常,以级联或并联的方式堆叠不同扩展率的扩张卷积增大感受野,但文献[19]表明积极增加的扩展因子会导致相邻单元之间的空间不一致,以及无法聚合小对象的局部特征。此外,扩张卷积可能会因为感受野过大造成从特征图中提取到的有用信息量较少,使其失去建模能力。基于此,本文提出一个GL-SPP模块(见图6),用于提升网络感受野的同时减少特征信息的丢失,整合水体更多尺度的语义信息。
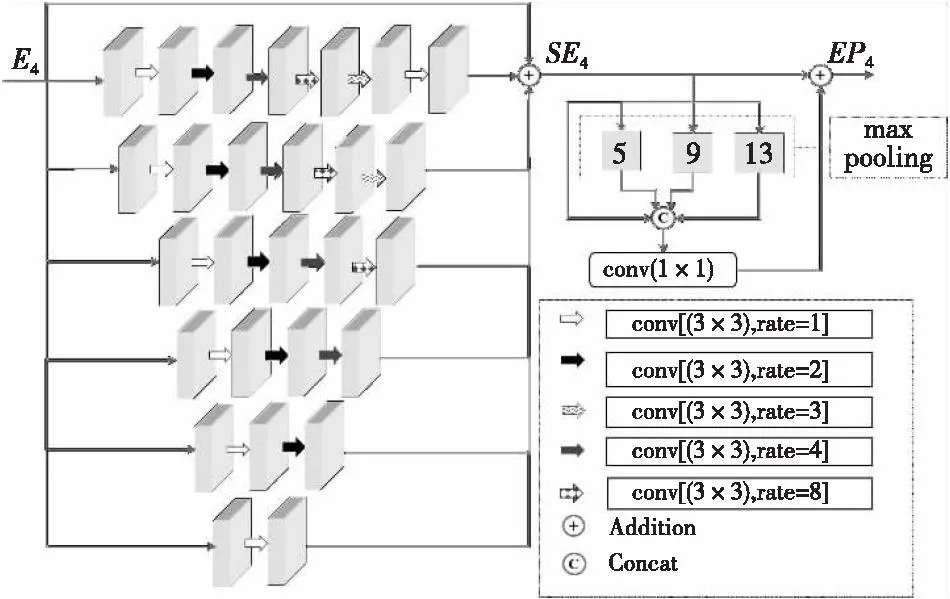
图6 GL-SPP模块Fig.6 GL-SPP module
GL-SPP模块通过堆叠递增递减不同扩张率的3×3卷积核提取E4特征,获取像素点周围的特征信息;递增的扩张因子提取覆盖上下文的特征,保证其最大感受野可以获取全局语义信息;递减的扩张因子逐渐恢复相邻单元之间的一致性,聚合前端分散的局部特征;同时,多条并行支路与初始特征E4利用相加操作将具有不同感受野的扩张卷积融合,利用式(8)进行计算,得到输出特征SE4,获得周围特征信息和大感受野的同时减少信息丢失。其次,利用池化核大小分别为13×13,9×9,5×5,1×1的空间金字塔池化进一步分离出最显著的上下文特征,获取特征图不同局部感受野及全局感受野的特征信息,对它们进行拼接操作及1×1卷积将其通道数调整为与E4相同。最后,与残差进行融合获得多尺度特征EP4,增强高阶水体语义表达能力的同时加速梯度反向传播。
(8)
式(8)中,conv1-conv4表示依次叠加扩张率为1,2,4,8的3×3卷积,conv5包含扩张率为1,2,4,8,3的3×3卷积,conv6包含扩张率为1,2,4,8,3,1的3×3卷积。
2.4 注意力引导的双分支聚合模块
融合更多特征信息对于细小水体识别取得优秀的分割效果至关重要,但跨越不同层级特征间的语义差距也是细小水体分割面临的一个挑战。语义差距通常是指低层和高层语义特征之间的差异。一般而言,低层特征包含边缘、颜色和纹理等空间细节,但缺乏高级语义信息;而高层特征包含更多的判别性信息,如语义信息,却缺乏空间细节信息。为了使这些信息相互补充以获得更具有判别力的特征表示,进行多层次的特征融合是必要的。待融合的低分辨率高层特征通过转置卷积或者双线性插值的上采样操作恢复到与低层特征相同的分辨率,使得两层特征图在空间尺寸上保持一致,然后经沿通道拼接或逐像素相加的方式进行融合。然而,由于特征结构以及特征内容本身的限制,不同层级之间的特征简单融合势必会存在语义差距[20]。例如高低层特征的每个位置并不都是同等有效的,直接利用相同的权重来融合,忽略了多层级特征的不同重要性。并且,直接融合势必会引入低层特征的背景噪声。
因此,针对细小水体特征响应弱,易与地面其他相似目标混淆的问题,本文提出A-TBFM模块将通道注意力和空间注意力结合,用于特征聚合强化关键特征信息,缓解不同层级特征之间语义不一致的问题,减少背景噪声对识别任务的干扰,生成表征信息更加丰富的语义特征图,实现不同尺度特征有效融合。即深入挖掘和使用不同尺度的图像信息,并将输出具有较强语义信息的高层特征反馈至低层,在补充低层特征信息的同时引导其进行学习,使得最终低高层特征分别提供更精确的空间定位和类别一致性判断。
本文使用4个双分支聚合模块逐步完成特征聚合和恢复,高层特征分支采用经转置卷积上采样获取的语义信息,低层特征分支中包含下采样的语义信息和DFEM模块优化的语义信息,为实现小水体分割提供更详细的特征信息,A-TBFM模块具体结构如图7所示。为了充分利用低层特征信息,A-TBFM模块首先利用3×3深度可分离卷积层对其进行建模,并在卷积操作后附加归一化BN层,对数据进行标准化处理,以提高训练效率,强化网络泛化能力;再经过激活函数ReLu层,增加网络的非线性表达能力,缓解梯度消失的问题,之后生成低级优化特征L。同时,通道数为C、高度为H、宽度为W的高级语义特征经式(9)-式(11),获得通道数为C的区域重塑特征B,A,D。B∈RN×C,{A,D}∈RC×N,其中N=H×W:
B=Lreshape(H)T,
(9)
A=Lreshape(H),
(10)
D=Lreshape(H)。
(11)
采用式(12)计算A和B的通道注意力图S∈RC×C。具体来说,在A与B之间进行矩阵相乘,计算相似度,在最后一个维度上执行softmax操作。这个过程相当于通道注意,即利用所有对应位置的空间信息来建模通道相关性,softmax激活函数主要是求特征图中每个像素与图片中的其他图像的归一化相关系数。最后,(C,C)通道注意力矩阵中第i行第j列元素的值为图中第i通道像素点与第j通道像素点之间的相关性。接着,通过式(13)生成具有全局上下文信息的高层通道增强特征Z。对通道注意力矩阵ST和D之间执行矩阵乘法,并将结果再次重塑为RC×H×W。这样得到的输出是考虑全局信息的特征图,每个位置的输出值为所有其他通道的加权和,用于建模特征映射之间的长期语义依赖关系。最后,高层通道增强特征Z与低级优化特征L相乘为其提供加权参数,获取图像的通道语义关系y。
S=Lsoftmax(A×B),
(12)
Z=(Lreshape(ST×D)),
(13)
式中,×表示矩阵相乘,即对于矩阵运算ST×D,ST∈RC×C,D∈RC×N,则结果为RC×N。
为获得特征图的空间注意力信息,对加权低级优化特征y通过平均池化操作压缩通道特征信息,采用SigMoid激活函数获取特征图在宽度和高度维度的空间权重,生成子区域特征相关性注意力矩阵y′,y′∈R1×H×W,将y′结合高层通道增强特征Z得到区域间特征空间位置信息的注意力表征。最后将其与高层特征和带有全局上下文信息的通道特征融合,通过式(14)获取兼具空间定位信息和上下文信息的高级语义特征F,F∈RC×H×W:
F=H+y+y′⊙Z,
(14)
式中,⊙表示按元素相乘,+表示像素级相加。
2.5 损失函数
本文采用如式(15)所示损失函数,采用逐像素二元交叉熵损失(binary cross entropy,BCE)和Dice损失函数的混合损失函数进行计算:
L=Lbce+LDice。
(15)
Lbce和LDice计算公式为
(16)
(17)
式中,tij为某像素真实类别标签,pij为某像素预测类别标签,W和H分别为图像的宽度和高度。
3 实验及结果分析
3.1 数据集与评价指标
3.1.1数据集
1) GOQQ数据集
GOQQ数据集以青藏高原湖泊水体数据集[8]为基础进行扩充丰富水体多样性,补充研究区域为青海省,水体类型包括湖泊、河流、水库等。青海和青藏高原属于典型寒旱区域,不同于一般区域,寒旱区地形复杂,山脉河谷较多,其遥感图像易受到山体阴影、干涸河床、植被等影响;且因天气因素影响,寒旱区降水量少且分布不均,使水体具有小尺度目标以及细长狭窄目标多,排布较为分散等特点,适合细小水体遥感信息提取。目前对于细小水体的定义尚未形成严格的标准,本文参考多种研究将占据5~30个像素的水体定义为细小水体。选取第14级谷歌遥感图像作为研究数据,共截取50张大小为256×256的包含细小水体的图像构成补充数据集,最终GOQQ数据集按照训练集(5 460张),验证集(688张)和测试集(674张)进行划分。
2) LoveDA数据集
为进一步检验网络模型的稳定性,本文选择在LoveDA[21]数据集上进行模型应用验证。该数据集共5 987幅高空间分辨率遥感影像,包含城市和农村两个区域,地理环境风格差异大且水生环境复杂,包含众多类型细小水体,适合作为验证细小水体提取模型稳定性的研究区域。由于测试集标签未开源,则将训练集和验证集合并,重新划分训练集、验证集和测试集。图像尺寸裁剪为512×512,去除标注错误、存在黑边区域和纯背景标签的图像,减小数据误差及样本不平衡对实验的影响,最终选用训练集5 313幅,验证集1 518幅,测试集759幅。
3.1.2评价指标
准确率、召回率、精确率、F1以及平均交并比是遥感图像语义分割任务常采用的评价指标,具体计算公式为
(18)
(19)
(20)
(21)
(22)
式中,VTP为真正例,表示正样本被判断为正确样本的数目;VFN为假反例,表示正样本被判断为错误样本的数目;VFP为假正例,表示负样本被判断为正确样本的数目;VTN为真反例,表示负样本被判断为错误样本的数目。
3.2 实验环境及训练策略
本文及所对比算法均在Ubuntu系统下进行,GPU型号为RTX2080Ti,环境配置为CUDA11.2+python3+pytorch1.7.0。主干网络CSPDarkNet53选择ImageNet[22]预训练结果作为初始化参数,采用Adam算法对网络进行优化,GOQQ数据集Batch Size设置为8,LoveDA数据集Batch Size设置为4,动态改变网络学习率大小。在训练网络过程中,采用数据增强策略,包括对比度变换、随机水平垂直翻转以及图像随机旋转90°。此外,训练的总迭代次数设置为120,以保证各模型在训练过程中均可达到收敛。使用早停策略,避免过拟合。
3.3 GOQQ数据集实验结果分析
为了验证本文方法的有效性,与SegNet,U-Net,DeeplabV3+,DANet,Linknet等模型进行对比实验,从定量与定性两个方面综合评价本文方法的性能。对比实验的定量性能指标如表 1所示,所提模型MLEA-Net在准确率、召回率、精确率、F1和平均交并比等精度指标上分别达到了96.91%,96.90%,95.61%,96.23%和93.82%,与各网络模型相比都有显著的提升。因此,表1的对比结果证明了所提模型在细小水体分割任务中的有效性。
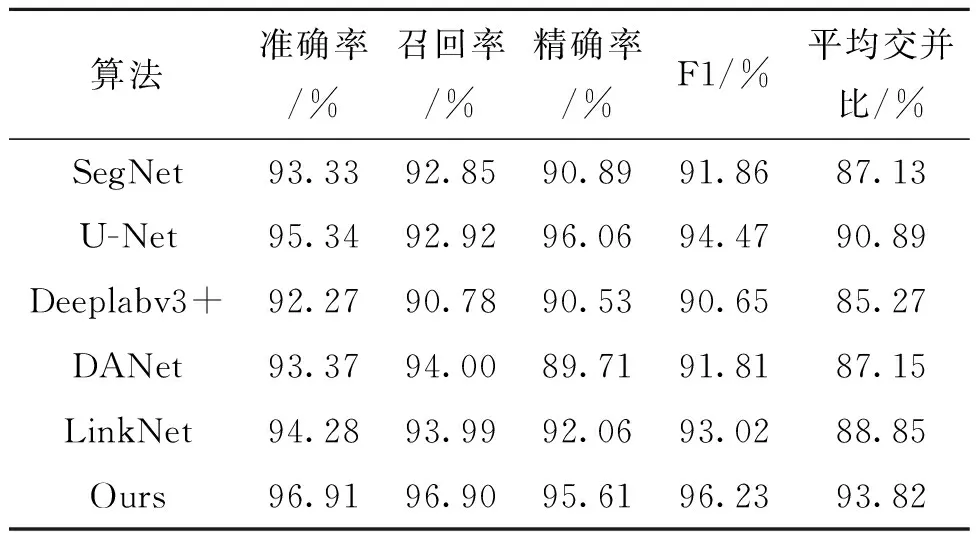
表1 GOQQ数据集不同算法结果对比Tab.1 Comparison of results of different algorithms in GOQQ dataset
如图8所示,选择5张典型影像进行分析,进一步突出本文方法的可行性。其中影像1有大面积和分散的不规则小目标水体,可将其用来验证模型对于小目标水体的识别效果;影像2包含大量彼此非常接近并且具有微小轮廓的小目标水体;影像3,4用来分析细长目标的分割性能;影像5有较明显的山脉阴影干扰区域,用于探究模型受阴影干扰时的分割性能。为了更清晰地对比各模型的提取结果,在图中用虚线框围出区域为分割细节对比和漏分及误分情况。

图8 不同网络模型在GOQQ数据集上的预测结果对比Fig.8 Comparison of prediction results of different network models of GOQQ dataset
分析图8的分割结果图细节,在图8(c)中,无论是排列分散或密集的小目标水体都存在被漏分割的现象,细长水体的连接处也被误分为背景,受高山阴影干扰的区域水体将背景误分为水体,这种误分割主要是因为SegNet的编码器深度不够导致特征提取不够充分,无法很好地处理区域内的阴影干扰,且网络中的最大池化索引无法使编解码特征有效聚合,达不到增强目标语义的作用。图8(d)中,U-Net网络对水体分割效果较好,其通过在上采样过程中,跳跃连接相同尺寸的特征图并采用拼接操作进行特征融合,在受高山阴影干扰的水体区域中,水体的轮廓可以大概被分割出来,但仍会将小部分阴影错误识别为水体。由于其利用的2倍上采样倍数小,特征保留相对比较丰富,除极小水体外大多数小目标水体能够被识别出,但在细长水体的较细处出现了中断,细节识别效果不理想。图8(e)中,DeepLabV3+模型中使用扩张卷积可以缓解由于下采样过多使得水体信息丢失的问题,但其会造成局部信息丢失以及长距离获取的信息关联减弱,无法完全正确提取出水体的精细边界,如第二列图中小目标水体轮廓分割过多,第四列图中细长水体的较细处将背景误分为水体。图8(f)中,DANet网络不同于ASPP等结构特征聚合获取上下文,其利用并行注意力机制分别模拟空间和通道维度中的语义相互依赖性,有效地集成局部特征与全局特征,对大尺寸水体整体分割表现较好,但缺乏包含丰富空间信息的浅层特征造成小目标水体识别效果较差。图8(g)中,LinkNet模型编码部分采用ResNet捕获丰富特征,且编解码层采用相加的操作有效增强了语义信息,对细长水体的分割效果较好,如第4列图中细长水体的轮廓连续完整,但简单的逐像素相加的方式,使得背景噪声影响高阶水体语义特征的表达,同时结构中无优化模块,缺乏抑制背景噪声的能力,使得极小目标漏分割,山脉阴影与水体难以区分。图8(h)是本文方法的分割结果,从影像一和影像二的分割结果可以看出,所提模型将分散和密集排布的小目标都能够完整地识别,且影像一右上方受干扰区域也未出现误分割的现象,具有较强的小目标分割能力。影像三和影像四中的细长水体识别较为完整连贯,清晰地反映出水体的细节部分。由于影像五中山脉阴影与水体具有相似的特征,分割结果很大程度上受其干扰,对高山阴影遮挡等干扰因素有较强的区分性。对比实验结果表明,本文所提模型具有提取细小水体的能力,提取细小水体区域面积准确且轮廓边缘信息清晰完整,总体精度较高,优于其他水体提取算法。
3.4 LoveDA数据集实验结果分析
为验证模型稳定性,在LoveDA数据集上也评测了本文方法,将所提模型与其他5种语义分割网络进行对比,定量精度如表2所示。
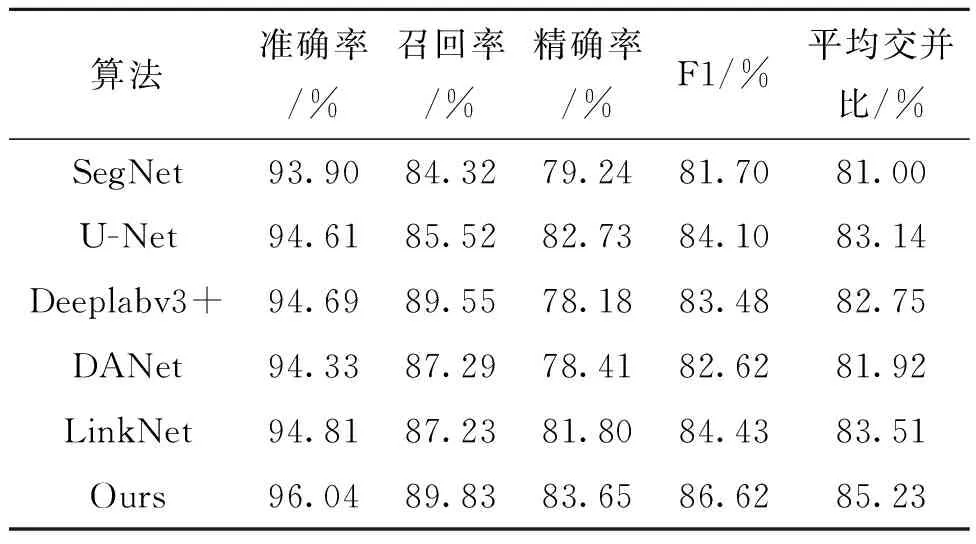
表2 LoveDA数据集不同算法结果对比Tab.2 Comparison of results of different algorithms in LoveDA dataset
从表2可以看出,本文提出的MLEA-Net模型在准确率、召回率、精确率、F1和平均交并比5个精度指标上分别达到96.04%,89.83%,85.65%,86.27%和85.65%,各项指标均高于其他网络,具有一定的性能优势。
为比较不同方法的水体提取结果,从测试集中选取5幅典型影像进行分析,如图9第1行所示,其中包含植被与人工建筑交错的水体、细长和微小水体、不同面积规则和颜色的水体分布紧凑以及具有阴影和其他地物干扰的水体。

图9 不同网络模型在LoveDA数据集上的预测结果对比Fig.9 Comparison of prediction results of different network models of LoveDA dataset
从图9可以看出,与其他方法相比,本文方法的水体提取结果与真值图最匹配,漏分和错分现象也比较少且轮廓更为准确清晰。影像一中,小块水体之间夹杂较细的中间边界且右下方水体被植被阴影遮挡着一小部分,对比方法中间距微小的水体几乎都被粘连,而本文方法则提取了较为精细的边界;影像二微小水体和窄长的沟渠识别结果更连续和完整,水体的完整性不受河岸周围植被的影响,且准确区分出水体和相邻的建筑物阴影;影像三中不同面积规则的坑塘水体分布紧凑,同物异谱现象显著,本文方法将绝大多数坑塘都提取出来,与水体特征相似的干涸河床也没有被错误分类为水体;影像四中除本文方法外,与小面积水体特征相似的操场、植被和深色顶棚的建筑物几乎都存在误分;影像五中港口处的码头和停靠的船只将水体分割成边界崎岖的几部分,使得在对水体轮廓的提取过程中难以保证其完整性,本文方法可以对大面积水体和微小水体都实现较为准确的识别,然而过于凹凸的细节处没有被完全提取出来。基于以上分析,表明本文方法MLEANet具有较高的稳定性,在应用于地理环境风格差异大的数据集时也可以表现出较为优越的性能。
3.5 消融实验
为验证MLEA-Net模型各模块的有效性,在GOQQ遥感数据集上开展消融实验。表3给出了各网络的详细结构,所提模型以CSPDarknet53为特征提取网络,利用转置卷积进行特征恢复,辅以跳跃连接减轻信息损失,故将该U型结构作为baseline网络,DFEM表示细节特征增强模块,GL-SPP表示全局局部空间金字塔池化模块,A-TBFM表示注意力引导的双分支聚合模块。对比结果如表4所示。
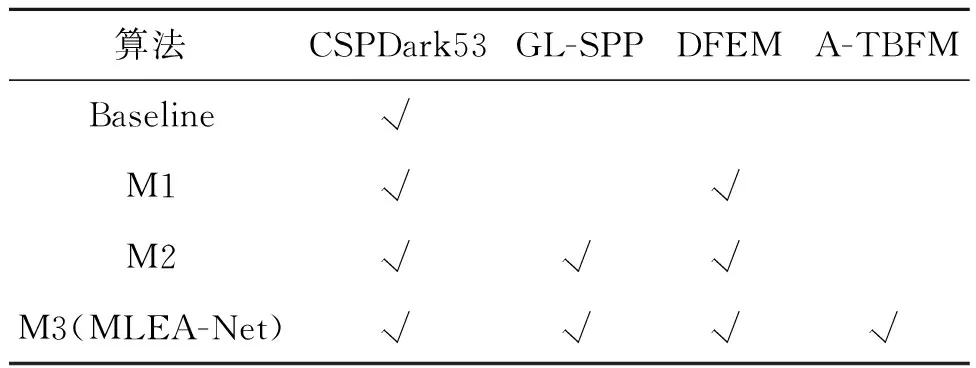
表3 各模块组成的方法Tab.3 Method of composition of each module
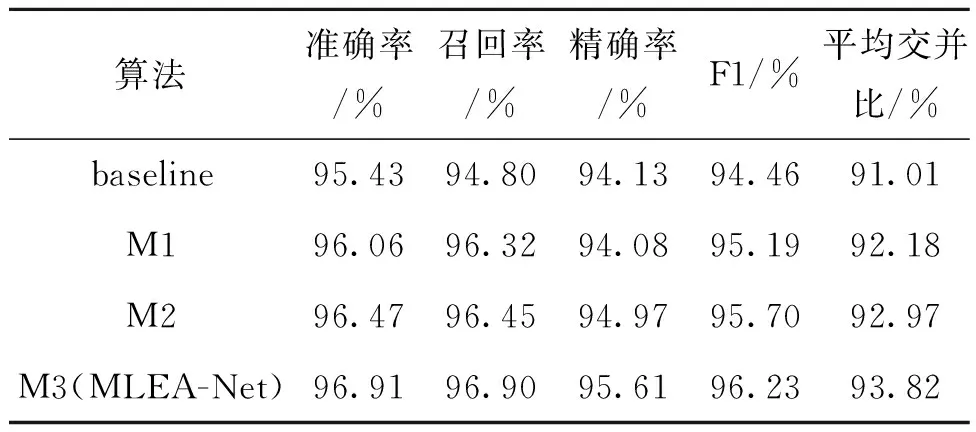
表4 消融实验结果Tab.4 Ablation experiment results
分析表4可得:
1) 以CSPDarknet53为特征提取网络,5个指标分别为95.43%,94.80%,94.13%,94.46%,91.01%,表明CSPDarknet53能有效增强网络特征提取能力,可学习到更利于辨别水体的判别信息。
2) 对比baseline和M1结构,通过在跳跃连接处添加DFEM模块,准确率、召回率、F1和平均交并比指标分别提高了0.63%,1.52%,0.73%和1.17%,表明DFEM模块高效利用了编码端浅中层特征,在保留空间细节信息的同时提升语义表达能力;对比M1和M2结构,加入GL-SPP模块后各性能指标均有小幅度提升,其中平均交并比提高了0.79%,说明GL-SPP模块能获取有效的周围特征以及不同尺度特征,从而提高分割性能;对比M2和M3(MLEA-Net)结构,精度指标准确率、F1和平均交并比分别提升了0.44%,0.53%和0.85%,表明添加A-TBFM模块后能够集中注意力关注输入特征的重要语义信息,可以融合更多跨层特征信息,对于提升网络的分割性能十分有益。
3) 随着本文提出的关键模块逐步添加在baseline网络上,分割的准确性逐渐提升,对比baseline和D(MLEA-Net)结构,5个指标分别提高了1.48%,2.10%,1.48%,1.77% 和2.79%。实验结果表明本文提出的每个关键模块对于获得最佳遥感图像水体语义分割结果都是必要的。
4 结论
针对遥感图像细小水体多样、有效特征信息难获取及易受背景噪声干扰的问题,设计多层级特征增强聚合的遥感图像细小水体提取方法(MLEA-Net),以CSPDarknet53作为骨干网络挖掘深层次特征,保证网络特征提取能力的同时降低模型复杂度,利用细节特征增强模块(DFEM)提高浅中层特征质量;而后,设计全局局部空间金字塔池化结构(GL-SPP)在编解末端捕获全局局部多尺度上下文信息;最终,在解码端提出通道注意力和空间注意力引导的双分支聚合模块(A-TBFM)进行不同尺度特征图有效聚合,增强目标边缘的像素信息和空间信息,进而提升细小水体的分割性能。
实验结果证明:GOQQ数据集的精确率、召回率和平均交并比分别为96.91%,95.61%,96.90%和93.82%,LoveDA数据集的精确率、召回率和平均交并比分别为83.65%,89.83%和85.23%,提升效果显著。但本文方法仍有需要改进的地方,MLEA-Net对与山脉阴影紧密相连的细长水体分割效果仍有提升的空间,后期研究将进一步优化注意力模块或尝试将其与网络其他位置结合,抑制噪声信息。
猜你喜欢
开放教育研究(2020年2期)2020-03-31
兽医导刊(2019年1期)2019-02-21
电子制作(2018年19期)2018-11-14
自动化学报(2017年11期)2017-04-04
现代语文(2016年21期)2016-05-25
中国畜牧兽医文摘(2015年9期)2015-12-29
海峡姐妹(2015年5期)2015-02-27
大连民族大学学报(2015年2期)2015-02-27
噪声与振动控制(2015年4期)2015-01-01
草食家畜(2012年2期)2012-03-20
