
基于深度学习的目标检测算法综述
2024-01-17 08:57:10郭庆梅刘宁波王中训孙艳丽
探测与控制学报 2023年6期
郭庆梅,刘宁波,王中训,孙艳丽
(1. 烟台大学物理与电子信息学院,山东 烟台 264005;2. 海军航空大学信息融合研究所,山东 烟台 264001)
0 引言
目标检测是计算机视觉[1]领域中的一个重要方向,其目的是对目标进行定位和分类,即在所给的图像或视频中找到所需的目标物体,并用边界框标出其位置,判断出其所属类别。由于目标物体存在差异性与不确定性,使得目标检测一直以来都是该领域的核心问题之一。早期的目标检测采用手工设计的特征提取方法,检测精度并不高,文献[2]提出的AlexNet成功推动了卷积神经网络(convolutional neural network,CNN)[3]的发展,文献[4]提出了基于CNN的目标检测算法R-CNN,使得检测精度有了很大的提升。至此,目标检测算法主要分为传统目标检测算法和基于深度学习的目标检测算法两类[5]。
1 传统目标检测算法
传统目标检测算法是将人为设计的目标特征和机器学习的分类器进行综合,文献[6]提出可用于杂乱场景的静态图像目标检测,直接从图像中学习Haar特征,利用支持向量机(support vector machine,SVM)[7]对目标进行分类,从而实现目标检测。文献[8]提出主要用于人脸检测的VJ检测器,利用积分图来计算任何尺度或位置的Haar特征,通过AdaBoost[9]方法学习分类器,以级联的方式进行训练,实现实时人脸检测,在相同的分类准确度下,速度提升了几十倍甚至上百倍。文献[10]将1999年提出的尺度不变特征变换(scale invariant feature transform,SIFT)进一步整理和优化,结合位置、所处尺度以及方向确定特征区域,提取的特征能够在光线和噪声等因素下有很好的鲁棒性。文献[11]设计了方向梯度直方图(histogram of oriented gradient,HOG),通过图像部分区域的HOG获得特征,结合SVM实现检测[12]。文献[13]设计了可变形的组件模型(deformable parts model,DPM),采用滑动窗口进行目标定位、HOG组件进行特征提取、SVM进行分类,具有良好的检测效果。
传统目标检测算法存在的缺点有计算量大、效率低、鲁棒性不好、针对性强、局限性大、泛化性差以及检测效果较差等。随着人工智能的发展,传统目标检测逐渐成为过去式,深度神经网络迅速发展,在提高准确度、降低计算量等方面都有了很大进步[14]。
2 基于深度学习的目标检测算法
随着CNN的改进,基于深度学习的目标检测算法也有了很大的提升,在目标识别、智慧交通等方面有着重要作用。目前出现的算法大致分为两类:一类是基于候选区域的双阶段(two-stage)目标检测算法;另一类是基于回归的单阶段(one-stage)目标检测算法[15]。这两类算法主要的区别为是否有候选区域目标推荐的步骤[16]。目标检测算法发展时间轴如图1所示。
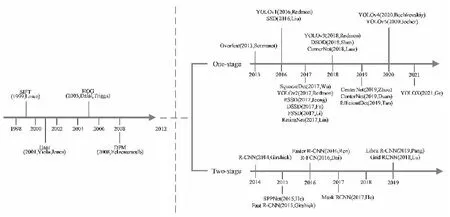
图1 目标检测算法发展时间轴Fig.1 Timeline of object detection algorithm development
2.1 Two-stage目标检测算法
2.1.1R-CNN算法
文献[4]在2014年提出了R-CNN,该算法的创新点:1) 在候选区域使用CNN进行自下而上的特征提取;2) 对于数据集不足的情况,使用迁移学习,提高了检测准确率和模型性能,解决了对小样本难训练和过拟合的问题,证明了CNN具有可迁移性。如图2所示,该算法的主要流程:1) 输入已标注的图像;2) 使用选择性搜索算法生成候选区域;3) 将得到的候选区域进行裁剪和缩放到规定尺寸,输入到CNN中进行特征提取;4) 将提取到的特征输入SVM分类器进行分类,使用非极大值抑制(non-maximum suppression,NMS)得到候选框,使用边界框回归对NMS处理后的候选框进行位置回归操作,得到准确率最高最合适的候选框。

图2 R-CNN算法流程Fig.2 R-CNN algorithm flow
2.1.2SPPNet算法
为了解决R-CNN在提取特征时需要对所有的候选区域进行提取等问题,文献[17]在2015年提出了可以适应不同尺寸图像输入的空间金字塔网络(spatial pyramid pooling network,SPPNet)。该算法在网络中的最后一个卷积层和全连接层之间接入空间金字塔池化层(spatial pyramid pooling,SPP)[18],结构如图3所示,目的是为了输送给全连接层固定大小的特征图。
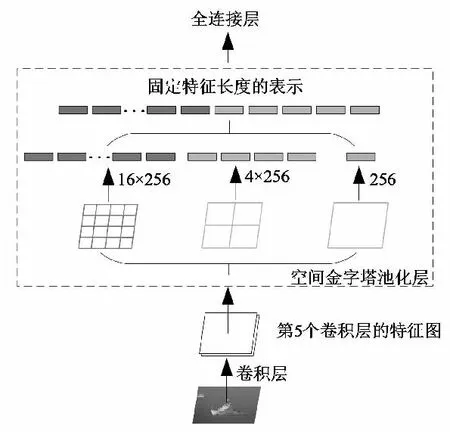
图3 SPP结构Fig.3 SPP architecture
2.1.3Fast R-CNN算法
为了解决R-CNN算法重复提取特征以及多级管道训练等问题,文献[19]在2015年提出了Fast R-CNN算法,该算法有四个创新点:1) 不再是多级管道训练,将SVM分类和BBox回归两个部分都放到了CNN中进行训练;2) 改进SPP提出更简洁的感兴趣区域(region of interest,RoI)池化层,添加了候选框映射功能;3) 使用了多任务损失,用其来更新参数,降低了计算的复杂度,提高了检测速度和精度;4) 在全连接层中使用了截断奇异值分解进行加速,降低前向传播的时间,加速了全连接层网络的运算。Fast R-CNN算法主要流程如图4所示。
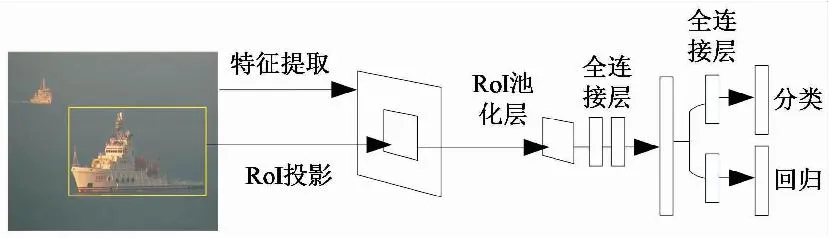
图4 Fast R-CNN算法流程Fig.4 Fast R-CNN algorithm flow
2.1.4Faster R-CNN算法
为了解决Fast R-CNN获得候选区域时间复杂度高等问题,文献[20]提出了Faster R-CNN算法,该算法的创新点:1) 使用了区域建议网络(region proposal network,RPN),加入Anchor机制,将候选区域、特征提取、分类和回归融合在一起,实现了真正的端到端的训练,保证了实时性,实现了训练时RPN与检测网络Fast R-CNN共享卷积层,提高了模型的检测速度和更高的检测精度;2) 使用GPU,提高了运行速度。Faster R-CNN主要流程如图5所示。
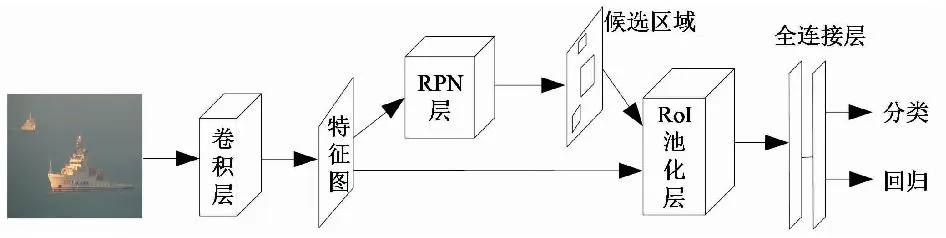
图5 Faster R-CNN算法流程Fig.5 Faster R-CNN algorithm flow
2.1.5R-FCN算法
为了解决Faster R-CNN算法提取特征的Header部分比较重等问题,文献[21]在2016年提出了基于区域的全卷积网络(region based fully convolutional networks,R-FCN)算法。该算法的创新点:1) 提出了位置敏感得分图,解决了分类的平移不变性和回归的平移可变性之间的矛盾;2) RoI池化层后面的全连接层改用卷积层,提高了检测速度;3) 对RoI加入了空间位置编码信息,提高了检测框的位置精度。R-FCN算法主要流程如图6所示。
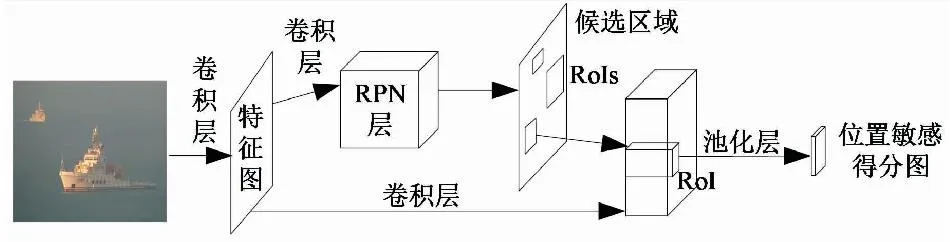
图6 R-FCN算法流程Fig.6 R-FCN algorithm flow
2.1.6Mask R-CNN算法
文献[22]在2017年对Faster R-CNN进行优化提出了Mask R-CNN算法,主干网络在ResNet的基础上添加了特征图金字塔网络(feature pyramid networks,FPN),即该算法由负责目标检测的Faster R-CNN和负责语义分割的FPN组成。该算法的创新点:1) RoI池化部分替换为RoI Align,解决了区域不匹配问题;2) 增加Mask网络。Mask R-CNN算法主要流程如图7所示。
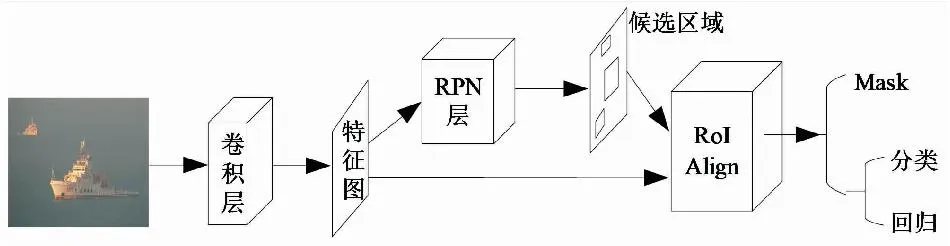
图7 Mask R-CNN算法流程Fig.7 Mask R-CNN algorithm flow
2.1.7Libra R-CNN算法
在目标检测过程中,存在一些问题:1) 随机采样会选取大量的简单样本,使得正负样本数量差距大,造成样本层面不平衡,常使用OHEM方法增加对复杂样本的选取来解决正负样本不平衡的问题,使用Focal loss方法可以降低噪声的影响,对One-stage目标检测有效,对Two-stage目标检测效果不好;2) 使用FPN和PAN将高层的语义信息和低层的细节定位信息进行特征融合时,融合后的相邻分辨率的特征效果很好,但忽略了非相邻层的特征,并且其语义信息会在每次融合时都会被稀释一次,造成特征层面不平衡;3) 在训练过程中需要平衡分类和定位任务,否则会造成目标层面不平衡。
针对上述因素导致检测性能差的问题,文献[23]在2019年提出了Libra R-CNN算法,该算法的创新点:1) 使用交并比(intersection over union,IoU)平衡采样来解决样本层面不平衡问题,即采用分箱操作,利用IoU将正负样本均衡分配。2) 使用平衡特征金字塔,结构如图8所示,解决了特征层面不平衡问题,首先将FPN结构输出的C2和C3层的特征图进行最大池化操作,将C5层的特征图进行双线性插值操作,统一得到和C4层特征图大小相等的特征图;其次将得到的特征求平均值,融合得到一张特征图,使用嵌入的高斯非局部注意结构对特征进一步提炼加强,提高非相邻分辨率的特征;最后将特征图还原到原来尺寸,分别进行add操作得到强化后的特征图。3) 使用平衡L1损失解决了目标层面不平衡,即平衡大样本和小样本的梯度。
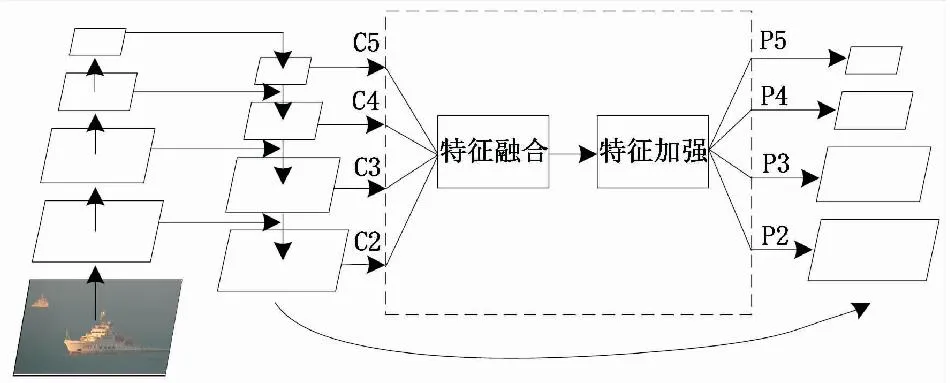
图8 平衡特征金字塔Fig.8 Balanced semantic pyramid
2.1.8Grid R-CNN算法
为了能够进行精确的目标检测,文献[24]在2018年提出了自顶向下的Grid R-CNN算法,该算法的创新点:1) 利用网格定位实现目标检测;2) 提出了一个多点监督机制,进行更准确的定位;3) 提出了空间信息融合模块,利用网格点的空间相关性,相互校准位置信息;4) 采用扩展区域映射修正输出热图和原始图片区域的关系;5) 可以灵活运用到不同的目标检测框架内。Grid R-CNN算法主要流程如图9所示。
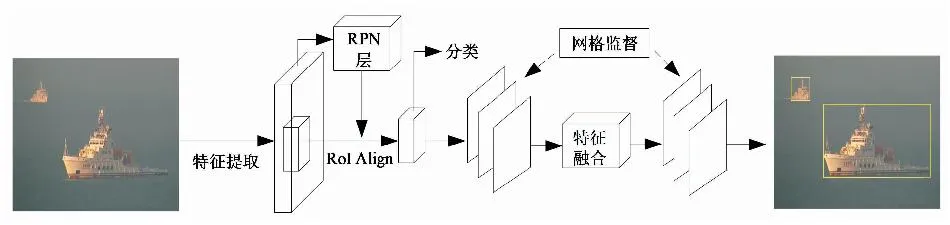
图9 Grid R-CNN算法流程Fig.9 Grid R-CNN algorithm flow
2.1.9小结
Two-stage目标检测将检测过程主要分为两步:1) 在给出的图像上找到有目标物体的候选区域;2) 对候选区域进行分类与回归操作,得到目标检测结果[25]。在区域提取方面,早期的Two-stage目标检测算法主要使用选择性搜索算法,如R-CNN,SPPNet和Fast R-CNN等算法,但速度较慢,实用性差;Faster R-CNN提出了基于RPN的方法,极大地提高了区域提取的速度和准确率。在特征利用方面,提出使用FPN结构,将高层的语义信息和低层的空间信息进行融合,提高对小目标的检测效果,如Mask R-CNN和Libra R-CNN等算法。随着网络的改进,检测精度得到了大幅提升,由于网络模型复杂度提高,导致训练和检测速度有所下降,实时性差。Two-stage目标检测算法的性能对比如表1所示,其中“-”表示原文献中无相关数据信息,优缺点如表2所示。
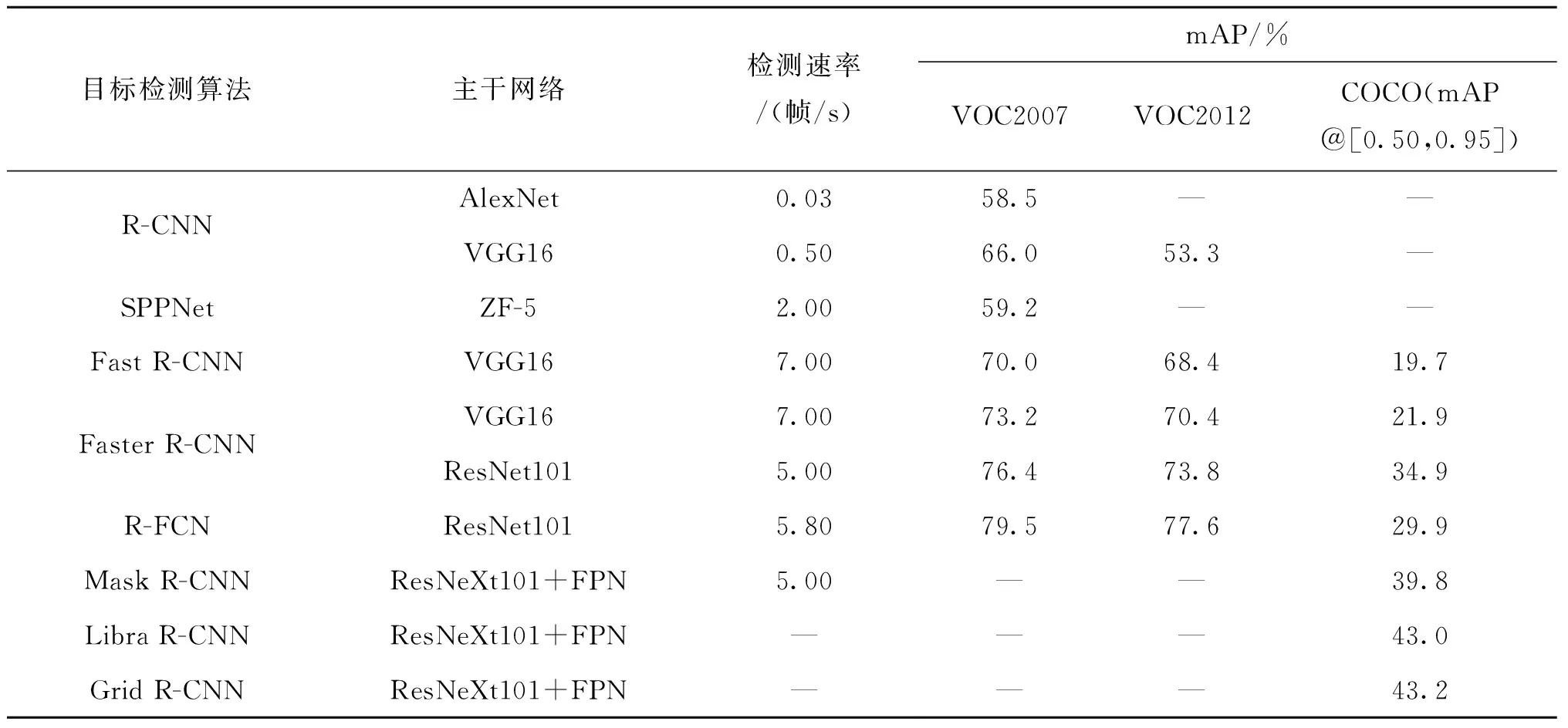
表1 Two-stage目标检测算法性能对比Tab.1 Performance comparison of Two-stage target detection algorithms

表2 Two-stage目标检测算法优缺点Tab.2 Advantages and disadvantages of Two-stage object detection algorithm
2.2 One-stage目标检测算法
2.2.1OverFeat算法
文献[26]在2013年提出了OverFeat算法,是One-stage目标检测的先驱,主要原理是以滑动窗口的方式在图像多尺度区域的不同位置进行图像分类,以及在相同的卷积层上训练一个回归器来预测边界框的位置。该算法的创新点:1) 改进AlexNet实现分类、定位和检测的融合;2) 提出offset max-pooling;3) 多尺度预测;4) 通过累积预测得到边界框。
该算法给出了准确模型和快速模型,在准确模型中,分类错误率为14.18%;在快速模型中,分类错误率为16.39%;使用7种准确率模型组合时,分类错误率为13.6%。
2.2.2YOLO系列算法
文献[27]在2016年提出了YOLO (you only look once)算法,该算法的创新点:1) 将分类、定位和检测融合在一个网络里,速度快;2) 避免将背景判断为目标,降低了检测错误率;3) 泛化能力强,适应性强。
为了解决YOLO检测精度低等问题,文献[28]在2017年对YOLO进行了更准确、更快和更强的改进,提出了YOLOv2算法。改进点:1) 在更好方面:去掉随机失活,引入批归一化(batch normalization,BN)来提高收敛性,mAP提升了2.4%;使用高分辨率图像微调分类模型,mAP提升了3.7%;去掉全连接层,使用锚框卷积预测边界框,可以预测1 000左右个边界框,mAP降低了0.3%,召回率提高了7%;聚类提取先验框尺度,采用K-means聚类方法进行聚类分析,提高了泛化能力,mAP提升了4.8%;通过单元格左上角格点的坐标来预测偏移量,达到对预测边框的位置的约束,mAP提高了约5%;进行多尺度图像训练;进行高分辨率图像的对象检测,mAP提升了1.8%。2) 在更快方面:图像尺寸为448×448时,训练分类网络,top-1和top-5准确率分别为76.5%和93.3%;对中间层不同尺度的特征进行拼接,拥有了细粒度特征,便于检测小目标。3) 在更强方面:将ImageNet和COCO联合构建WordTree进行分类数据和检测数据联合训练。在数据集方面进行融合,提出可以实时预测9 000个种类的YOLO9000。后续对YOLOv2改进,文献[29]提出了Fast YOLO,此算法主要是应用在嵌入式设备上的,实时性强,处理图像的速度达到了155 帧/s。
为了提高小目标检测能力,文献[30]在2018年对YOLOv2进行改进,提出了YOLOv3。此算法的创新点:1) 主干网络是Darknet53,以便能够获得更深层次的图像特征;2) 利用残差网络特征融合,达到多尺度预测,在小目标检测方面有了进一步的提升;3) 分类使用logistic算法的二元交叉熵损失函数,实现了多目标分类;4) 在物体分数和类置信度方面,使用Sigmoid函数,可以将目标进行类别细分。后续有YOLOv3-SPP对YOLOv3进行改进,加入了SPP模块实现了不同尺度的特征融合,在数据集COCO上mAP达到了59.5%,YOLOv3-SPP-ultralytics版本在MS COCO数据集上mAP达到了62.4%。
文献[31]在2020年对YOLOv3进行改进,提出了YOLOv4。该算法将框架分为输入端、Backbone,Neck和Head四部分,该算法创新点:1) Neck部分采用SPP和PAN模块进行特征融合;2) 使用CutMix和Mosaic数据增强以及DropBlock正则化,减少过拟合问题,提高泛化能力;3) 引入缩放系数,提高了准确率;4) 优化不同目标尺度的Anchor;5) 采用CIoU定位损失。
文献[32]提出了YOLOv5,该系列包含S,M,L,X四个版本,如图10所示是YOLOv5S的网络结构,主要流程:1) 输入端使用Mosaic数据增强,同时减少GPU的使用个数,使用自适应锚框计算来得到得分高的Anchor,采用自适应缩放将图片的大小统一固定为一个合适的尺寸;2) Backbone部分采用New CSP-Darknet53模型,使用Focus模块完成切片操作,利用CSP1_X进行特征融合,利用SPP模块得到固定长度输出;3) Neck部分采用了FPN和PAN模块,两者结合增强了多尺度的语言表达和强定位信息,CSP2_X对上一步的特征融合进一步加强;4) Prediction部分定位损失采用了GIoU_Loss损失函数。该算法在检测速度方面有了很大的提升,是YOLOv4的2倍多,体积也小,比YOLOv4小了90%左右。

图10 YOLOv5S算法流程Fig.10 YOLOv5S algorithm flow
文献[33]在2021年提出了YOLOX,该系列有7个版本,这里主要介绍YOLOX-Darknet53的改进之处,其输入部分是采用Mosaic和Mixup进行数据增强;Neck部分采用FPN进行特征融合;Prediction部分采用3个Decoupled Head提高精度和加快收敛速度,采用Anchor-free减少参数量,进行标签分配时,首先根据中心点和目标框进行初步筛选正样本操作,再用SimOTA进行精细化筛选,使用损失函数计算目标框和正样本预测框之间的误差。
2.2.3SqueezeDet算法
文献[34]在2017年针对自动驾驶需要高精度、实时性、小模型和低能耗的任务,提出了SqueezeDet算法,该算法的流程:1) 改进YOLO模型,使用层叠卷积滤波器得到高维度低分辨的特征图,提高了精度,降低了参数量;2) 提出了ConvDet,得到边界框和类别;3) 通过边界框回归得到最终的检测结果。优点是模型小,并且推理速度更快。
2.2.4SSD系列算法
结合Faster RCNN高检测精度和YOLO高检测速度的特点,文献[35]在2016年提出可以保证精度、速度和实时性的SSD算法,主干网络是修改后的VGG16模型。该算法的创新点:1) 采用了多尺度特征图,提高对小目标检测的检测能力;2) 在特征图上设置多个不同尺寸和宽高比的先验框,用IoU来决定哪个Anchor负责哪个目标物体,提高了准确率;3) 在卷积层中进行分类和定位的预测,降低计算量。该算法在检测速度方面超过了之前最优的YOLO,在检测精度方面超过了之前最优的Faster RCNN。SSD算法主要流程如图11所示。
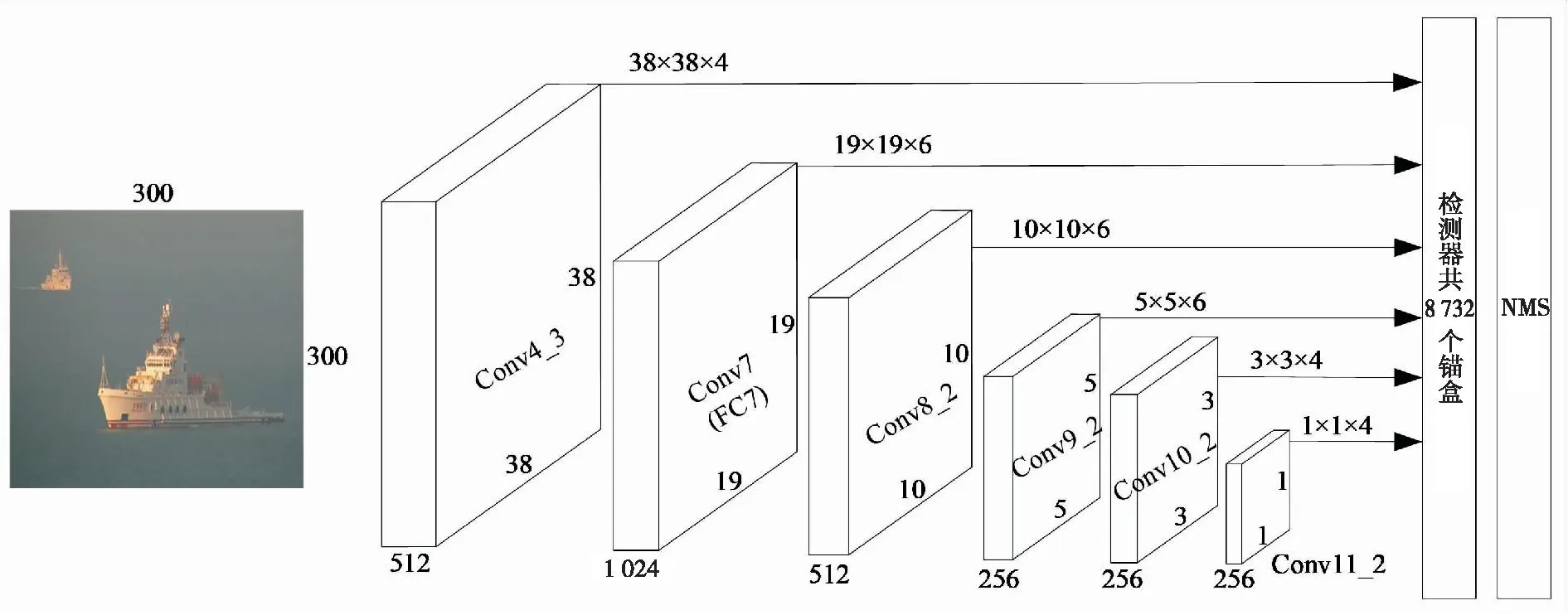
图11 SSD算法流程Fig.11 SSD algorithm flow
针对SSD算法重复检测等问题,文献[36]在SSD基础上进行改进并在2017年提出了R-SSD算法,该算法的创新点:1) 使用分类网络增加不同特征图层之间的联系,降低计算量;2) 增加特征金字塔中特征图的个数,提高对小目标检测的能力。
针对SSD算法获取较深层语义信息能力差的问题,文献[37]在2017年提出了DSSD算法,该算法的创新点:1) 主干网络采用ResNet101,以便获得深层的语义信息;2) 上采样采用反卷积结构,将深层和浅层的特征图进行融合,获得语义和位置信息;3) 在预测模块部分加入残差结构,提取更深维度的特征,提升对小目标的检测能力。
针对SSD算法难以进行特征融合的问题,文献[38]在2017年将SSD和FPN进行改进提出了将定位和识别进行结合的F-SSD算法,在SSD上结合了轻量级的特征融合模块,该算法的流程:1) 将SSD分支上不同尺度的特征图通过双线性插值操作调整到同尺度的特征图;2) 通过concat进行特征融合,通过BN进行正则化;3) 通过下采样模块生成新的特征金字塔,使用多盒探测器预测目标。该算法在精度方面有了显著的提升。
针对常见的目标检测算法先预训练再微调的问题,文献[39]在2019年融合SSD和DenseNet的思想提出了可以从头开始训练的DSOD算法,经过大量的实验得出:1) 使用无候选目标框方法可以从零训练并收敛;2) 借鉴DenseNet的思想,其致密块与所有块有连接,可以跳过连接实现监督信号的传递,浅层也可以受目标函数的监督,同时增加致密块的数量;3) 使用stem模块减少信息损失,提升检测效果;4) 融合多个阶段网络的输出,采用顺序连接,每一阶段都包含前面所有阶段的输出。
2.2.5RetinaNet算法
针对常见的One-stage目标检测算法正负样本不平衡的问题,文献[40]在2017年提出了Focal Loss损失函数来提高复杂样本在标准交叉熵中所占的权重,同时提出了RetinaNet算法来验证此损失函数的有效性。此算法的流程:1) 利用ResNet提取特征,防止梯度爆炸或消失;2) 利用FPN进行多尺度特征融合;3) 利用分类回归网络得到类别和定位信息。Retina Net算法主要流程如图12所示,其中K表示类别个数,A表示anchor个数。
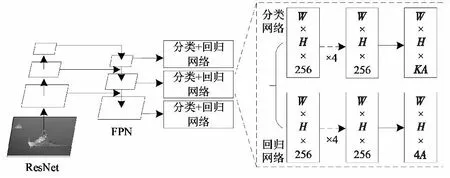
图12 RetinaNet算法流程Fig.12 RetinaNet algorithm flow
2.2.6CornerNet算法
针对常见的目标检测算法使用Anchor引起的正负样本不平衡,导致训练效率降低,以及引入大量超参数增加设计难度等问题,文献[41]在2018年提出了自底向上的CornerNet算法。该算法的创新点:1) 预测方法抛弃了原先的Anchor和RPN思想,采用确定左上角和右下角两个关键点的方法对边界框进行定位;2) 识别组合属于相同实例的关键点;3) 提出了使用角点池化的方法,进行两角点的定位。CornerNet算法主要流程如图13所示。
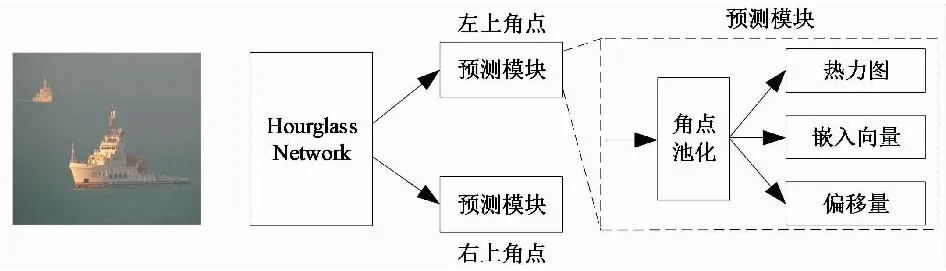
图13 CornerNet算法流程Fig.13 CornerNet algorithm flow
2.2.7CenterNet算法
针对CornerNet采用双角点确定边界框出现准确率不高和检测速度降低等问题,文献[42]在2019年提出了CenterNet算法,该算法的创新点:1) 丢弃了双角点确定边界框的思想,借鉴关键点估计思想,用点代表目标,该点也是边界框的中心点,同时去除了NMS后处理操作,降低了复杂度,提高了检测速度;2) 可以灵活运用到2D和3D等目标检测的任务中。该算法的流程是通过全卷积网络生成热力图,热力图峰值点作为目标中心点,用峰值位置的图像特征预测回归边界框的宽高和维度等信息。
文献[43]在2019年提出了使用左上角点、右下角点和中心点形成三元组来判断边界框的方法,也被称为CenterNet算法,利用级联角点池化和中心池化优化关键点的生成,提高了精确度和召回率,但当目标物体的中心在同一个位置时,只能检测出该位置的一个目标物体。
2.2.8EfficientDet算法
针对提高精度和检测速度的问题,文献[44]在2019年提出了EfficientDet算法,该系列算法的创新点:1) 提出能快速进行多尺度特征融合的加权双向特征金字塔网络(BiFPN);2) 提出可以对主干网络、特征网络和预测网络的分辨率、深度和宽度三要素进行均匀缩放的混合缩放方法[45]。有D0到D7共8种版本,按序号模型体积越来越大,速度越来越慢,精度越来越高。EfficientDet算法主要流程如图14所示。
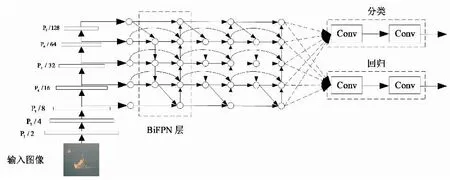
图14 EfficientDet算法流程Fig.14 EfficientDet algorithm flow
2.2.9小结
One stage目标检测直接通过CNN提取特征,同时预测目标物体的分类与定位。在锚框设计优化方面,YOLOv2使用基于K-means聚类的方式来自适应地生成锚框,SSD系列使用多尺度的锚框生成策略,EfficientDet使用可变形锚框等,此外,还有一些算法去掉了锚框设计,如YOLOX通过预测分支解耦的方式确定边界框;CornerNet通过双角点确定边界框;CenterNet通过中心点确定边界框[15]。在特征利用方面,SSD系列使用多层特征融合的方式,EfficientDet使用BiFPN来进行特征的高效传递和融合。One-stage目标检测算法的性能对比如表3所示,其中“-”表示原文献中无相关数据信息,优缺点如表4所示。

表3 One-stage目标检测算法的性能对比Tab.3 Performance comparison of One-stage target detection algorithms

表4 One-stage目标检测算法优缺点Tab.4 Advantages and disadvantages of One-stage object detection algorithm
3 总结
由于传统目标检测算法的过程过于繁琐,且在处理复杂场景时效果差,与深度学习相结合的目标检测逐渐成为研究热点,其在精度和速度方面有了很大的提升。本文分析了目标检测的发展历程,尤其对基于深度学习的目标检测算法进行了深度剖析。虽然此领域发展迅速,但是仍有很多方向值得探讨和研究。
1) 多领域数据集:现有数据集在单一领域完善性比较好,但是相对来说,目标类别数少,对于新场景出现的目标只能检测出少类目标,或出现错检、漏检等问题,对于建立一个多领域多场景多元化目标数据集是一个迫切需要解决的问题,同时也是一个重要的研究方向。
2) 自动标注数据集技术:当前的目标检测数据集是人工进行标注,这一过程需要大量的时间和精力,成本高,容易出现错标、漏标等问题,可以考虑使用迁移学习技术,将其他已标注数据集迁移使用,再训练少量项目所需数据集,或者研究一种自动标注技术,使用网络直接实现目标标注。
3) 小目标检测:随着卷积神经网络的进一步完善,基于深度学习的目标检测方法成为主流,但是小目标的特征存在于浅层语义中,深度学习模型往往更擅长提取深层次的语义特征,因此,对于小目标检测效果较差,可以尝试改进网络结构使其更好地利用浅层语义特征。
4) 基于GAN的目标检测:对于目标检测需要大量数据集进行训练,由于数据采集成本、时间限制及特殊场景等因素,会出现数据不足的问题,可以考虑使用GAN系列网络,使用一部分真实场景数据生成部分虚拟数据,扩大数据集,使其覆盖更多不同的场景,可以提高检测效果。
5) 多任务学习:在传统的单任务学习中,需要为每个任务训练一个独立的模型,为降低时间复杂度,可以考虑将目标检测、语义分割以及实例分割等任务融合到一个网络,实现同时兼顾速度与精度的目的。
猜你喜欢
速读·下旬(2021年11期)2021-10-12 01:10:43
今日农业(2021年10期)2021-07-28 06:28:12
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:25:56
大东方(2019年12期)2019-10-20 13:12:49
中学生数理化·七年级数学人教版(2019年4期)2019-05-20 10:06:32
中学生数理化·七年级数学人教版(2018年6期)2018-06-26 08:36:06
劳动保护(2018年5期)2018-06-05 02:12:10
初中生世界·七年级(2017年9期)2017-10-13 22:27:46
科学与财富(2017年22期)2017-09-10 13:20:02
商情(2017年1期)2017-03-22 16:56:36
