
基于时延估计改进的主动隔声耳罩语音增强算法
2024-01-17 07:16王宁刘剑刘苏洋
声学技术 2023年6期
王宁,刘剑,刘苏洋
(南京航空航天大学自动化学院,江苏南京 211106)
0 引言
随着物质生活水平的提高,人们对工作、生活环境的改善也日益重视。在强噪声环境下,为实现有效的听力保护,工作人员可通过佩戴主动降噪耳罩实现噪声隔离,其中,耳罩本身的物理材料能够有效地隔绝高频噪声,低频噪声则通过有源噪声控制(Active Noise Control,ANC)技术抵消[1-3]。在此基础上,采用基于广义旁瓣抵消器(Generalized Sid‐elobe Canceller,GSC)的主动隔声耳罩语音增强算法[4],能够使得主动降噪耳罩在抑制环境噪声的同时,实现垂直角度入射声源的语音增强,但对于声源从其他角度入射的情况,文献[4]并没有提及。不同角度入射声源的语音增强是佩戴者之间能够正常交流的关键。麦克风阵列间准确的时延估计(Time Delay Estimation,TDE)是GSC 算法实现不同角度入射声源语音增强的前提,同时也是基于到达时间差(Time Difference of Arrival,TDOA)声源定位技术的前提[5]。
目前时延估计算法主要包括广义互相关(Gener‐alized Cross Correlation,GCC)[6]方法、自适应最小均方(Least Mean Square,LMS)[7]方法、基于子空间的特征值分解(Eigen Value Decomposition,EVD)[8]方法和基于传递函数比(Acoustical Transfer Functions ratio,ATF-s ratio)[9]的方法等。GCC方法运用最为广泛,在实际应用中为了抑制噪声对GCC 算法结果准确性的影响,常采用不同的加权函数进行时延估计[10-11]。
本文设定的环境噪声是生活、工作等场景下的常见噪声,在传统的GCC 时延估计算法基础上,将多窗谱估计的谱减法与GCC 法结合,进一步提高了算法的抗噪能力和时延估计的准确性,通过仿真验证了该方法的有效性。将时延估计算法加入到GSC主动隔声耳罩语音增强算法中以实现不同角度入射声源的语音增强,对整体算法的噪声抑制和语音增强效果进行了仿真实验,验证了本文所提算法的有效性。
1 麦克风阵列时延估计
1.1 麦克风阵列时延模型
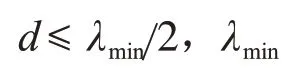
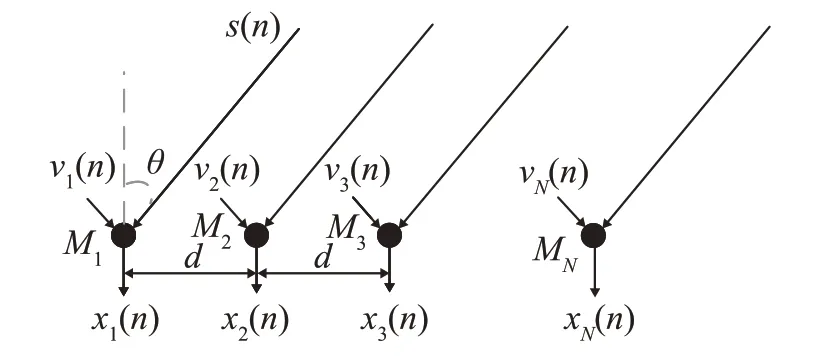
图1 麦克风阵列信号模型Fig.1 Signal model of a microphone array
以传声器M1和M2为例,接收到的语音信号模型为
其中:v1(n)和v2(n)为相互独立的加性噪声信号,声源信号s(t)与vi(n)也相互独立,τ1和τ2表示声波到达传声器M1和M2的时间,α1和α2为声波的衰减系数。τ12=τ1-τ2表示声源信号到达传声器M1和M2间的时间延迟。
1.2 GCC算法
传声器接收到的语音信号x1(n)、x2(n)的互相关函数R12(τ)可以表示为
将式(1)中的信号模型代入式(2),可得:
当s(n)、v1(n)和v2(n)之间相互独立时,式(3)可化简为
Rss(τ-τ12)表示声源信号s(t)的自相关函数。根据互相关函数的性质,当τ=τ12时,R12(τ)取得最大值。两传声器之间接收信号的到达时间差估计可以表示为
在实际应用中噪声的干扰会影响互相关函数峰值的准确性,对此可先对观测信号的频谱进行加权处理,在频域中抑制噪声的干扰,锐化声源信号。
利用GCC法进行时延估计的原理如图2所示。
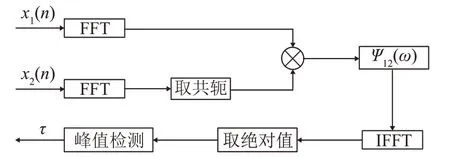
图2 基于GCC法的时延估计原理示意图Fig.2 Principle diagram of the time delay estimation based on GCC method
由互相关函数与互功率谱密度的关系,可得:
式中:G12(w)为传声器接收信号x1(n)和x2(n)的互功率谱。
对式(6)进行频域加权并反变换到时域,可得:
式中:ψ12(ω)为GCC 加权函数。在实际中,为使互相关函数R12(τ)有一个相对尖锐的峰值,需选择合适的GCC 加权函数,常用的GCC 加权函数[14-16]如表1所示。
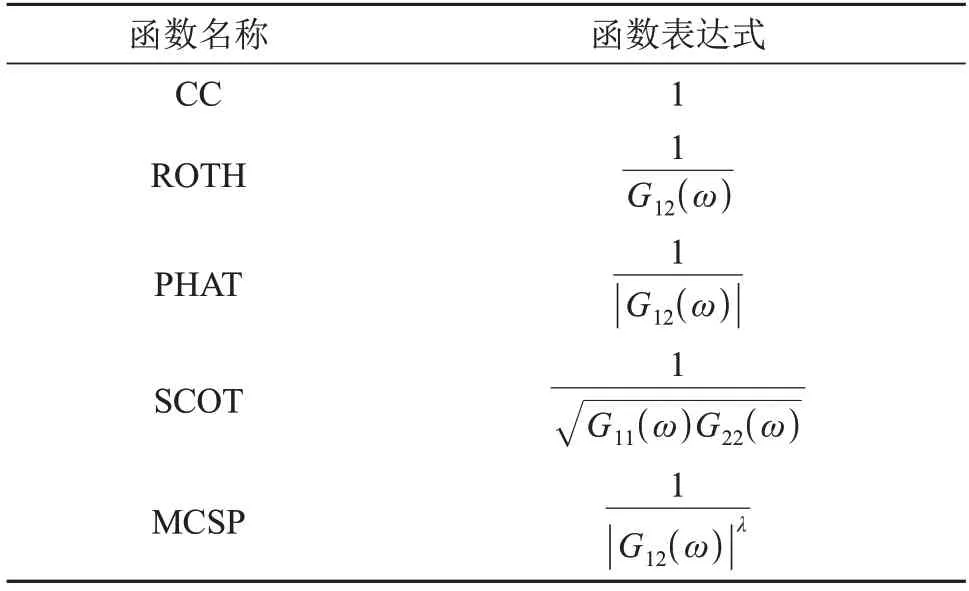
表1 常用的GCC加权函数Table 1 Commonly used GCC weighting functions
1.3 基于谱减法改进的GCC算法
虽然通过GCC 法可以抑制噪声对时延估计的影响,但通过仿真发现在信噪比低于0 dB 时到达时间差(Time Difference of Arrival,TDOA)估计的准确率并不高。考虑到本文算法针对的是正常生活、工作中的高噪声场所,环境噪声可以看成是变化缓慢的加性噪声且与语音信号的相关性较弱。因此,可以利用无话段时的纯噪声,以GCC法作为基础,引入谱减法[17-19]进行信号预处理,提高传声器接收信号的信噪比,从而实现算法改进。
谱减法是利用语音信号的短时平稳性,从带噪语音的前导无话段估算出噪声频谱,然后用带噪语音的频谱减去噪声频谱,从而提高语音信号的信噪比。但是在传统的谱减法中得到的噪声功率谱与信号的真实功率谱之间存在着较大的方差,进行谱减后会在信号的频谱上出现随机的尖峰,即“音乐噪声”,文献[20]的研究结果表明先验信噪比估计的较大方差是产生音乐噪声的根本原因。因此功率谱估计的准确性直接关系到谱减法降噪的效果,为降低“音乐噪声”对音频信号的影响,需要选择一种估计更加准确、方差较小的功率谱估计方法。文献[21-22]中提出的多窗谱估计方法就具备以上的特点[21-22]。
多窗谱估计谱减法是一种改进的谱减法,其用多个相互正交的数据窗分别对同一输入信号求功率谱,然后取平均得到功率谱估计。多窗谱估计使用的数据窗是一组相互正交的离散椭球序列,相较于只使用一个数据窗的传统功率谱估计其估计方差更低。由于多窗谱估计是一种更加准确的谱估计方法,应用于谱减法时降噪效果更好,而谱减法运算简单、实时性好,并且本文算法针对的噪声环境适合引入谱减法作为信号的预处理方法,因此选用多窗谱估计的谱减法对GCC算法进行改进。
多窗谱定义为
其中:
式中:x(n)为数据序列,n为序列长度,L为数据窗个数,ak(n)为第k个数据窗,ak(n)满足:
基于谱减法改进的GCC时延估计原理图如图3所示。算法具体步骤如下:
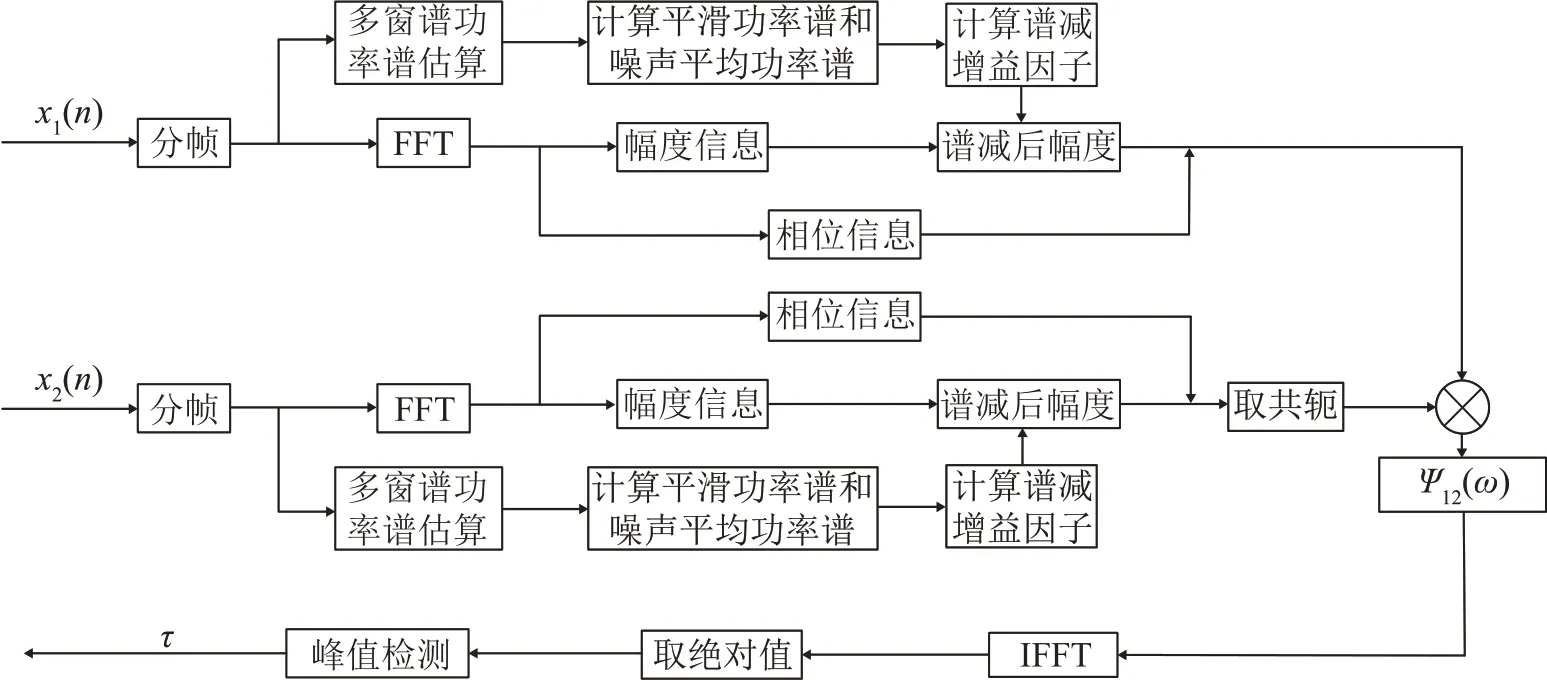
图3 基于谱减法改进的GCC时延估计原理框图Fig.3 Functional block diagram of the improved GCC delay estimation based on spectral subtraction
(1)对带噪语音进行分帧,帧间重叠率50%。对分帧后的信号进行FFT 变换,分别求得幅度谱|y(ω)|和相位谱|θ(ω)|;
(2)对分帧后的信号进行多窗谱估计,计算带噪语音的平滑功率谱P(ω)。利用语音信息的前导无话段计算噪声平均功率谱Pn(ω);
(3)计算谱减增益因子g(ω)
式中:α为过减因子,β为增益补偿因子。选择合适的α可以有效去除由于估计方差产生的尖峰;
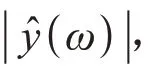
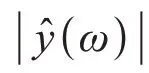
(5)进行GCC处理,得到时延估计值。
2 基于GSC 的主动隔声耳罩语音增强算法
基于GSC 的主动隔声耳罩语音增强算法主要由ANC算法[23-24]和GSC语音增强算法[25-26]构成。两者通过ANC 算法中的次级通道在线辨识模块耦合在一起,算法框图如图4所示。

图4 基于GSC的主动隔声耳罩语音增强算法框图Fig.4 Block diagram of GSC based speech enhancement algorithm for active noise insulation earmuff
经过时延补偿处理的麦克风阵列信号输入GSC语音增强算法中,得到增强后的语音信号。将信号v(n)与ANC 算法中的次级通道在线辨识模块耦合在一起,最终通过ANC 算法输出抑制耳罩内低频噪声p(n)后的语音增强信号e(n)。
3 算法计算复杂度
在已证明算法正确性的前提下,算法的时间复杂度和空间复杂度是评价算法优劣的关键指标。由于半导体行业的飞速发展,算法的时间复杂度相对于空间复杂度在实际应用中显得更为重要。算法时间复杂度的本质是算法的执行时间,即算法中所有语句的频度之和[27]。
本文的算法主要由基于谱减法改进的GCC 算法、GSC 语音增强算法和ANC 算法构成。其中GSC 算法和ANC 算法的执行时间主要集中于自适应滤波器系数的更新。自适应滤波器的阶数并不随算法输入的增加而增加,因此ANC算法和GSC算法的时间复杂度都为O(n)。在基于谱减法改进的GCC 时延估计算法中多窗谱估计和求序列的最大值的算法运行时间最长。但在实际应用中FFT的点数是一定的,因此算法的时间复杂度仍为O(n)。
此外,当本文的算法应用于实时系统时,可以在一个大循环中随采样时刻按顺序对以上三种算法进行调用。因此整体算法的时间复杂度为各算法时间复杂度的线性叠加,即时间复杂度为O(n)。
4 仿真结果与分析
为了验证本文算法在不同噪声环境下的时延估计性能和入射声源的语音增强效果,分别对时延估计算法和改进的GSC 主动隔音耳罩语音增强算法进行了仿真实验。算法中由4个模拟传声器组成均匀线性阵列,阵元间距为0.05 m。目标语音信号来自MUSAN语音库。MUSAN数据库是得到美国国家科学基金会研究生研究奖学金支持的包含音乐、语音和噪声记录的语料库,采样频率为16 kHz。设定声速为340 m·s-1,声源处于远场中,环境噪声选用Noise-92 库中的粉色噪声(pink)、工厂车间噪声(factory1、factory2)、汽车车内噪声(car volvo)。Noise-92 噪声数据库是由英国荷兰Perception-TNO研究所的语音研究单位在现场测量的不同噪声数据。
4.1 时延估计算法的仿真与分析
对基于谱减法改进的GCC 算法进行Matlab 仿真,从MUSAN 语音库中选取10组时长为3 s的目标语音信号,信噪比分别设置为10、5、0、-5、-10 dB。每次仿真选取有话段的3帧数据用于时延估计,帧长N=1 024个采样点,帧移为50%,计算谱减增益时α=3.8,β=0.001。麦克风阵列模型如图1所示,进行时延估计时分别设置声源入射角θ为0°、64.85°、-64.85°。在三种声源入射角度下,如果算法估计的传声器M1和传声器M2、M3、M4之间的延迟采样点与实际延迟采样点有一个不符合时,则此次时延估计是异常的。图5 为factory2 噪声环境下不同GCC加权函数的时延估计异常率。

图5 在factory2 噪声环境中不同GCC 加权函数的时延估计异常率Fig.5 Abnormal rates of time delay estimation of different GCC weight functions in the factory2 noise environment
通过仿真结果可以看出,在factory2噪声环境下时延估计的准确率随信噪比的下降而下降。其中,λ=0.1的MCSP加权函数的算法性能要优于其余4 种加权函数。并且factory1、car volvo 和pink噪声环境下MCSP加权算法的性能也是最优的。
此外,当用于时延估计的2 048个采样点信噪比大于-4 dB时,factory1与pink噪声环境下时延估计的准确率达到80%以上,当信噪比低于-4 dB时,其时延估计准确率急剧下降。类似地,用于时延估计采样点的信噪比分别高于-8 dB 和-15 dB时,factory2 和car volvo 噪声环境下的时延估计的准确率达到80%以上。
4.2 入射声源的语音增强仿真与分析
为了验证加入时延补偿后整体算法的噪声抑制和语音增强效果,对改进的GSC 主动隔声耳罩语音增强算法进行了仿真实验,仿真中预置参数设置如表2所示。

表2 仿真预置参数Table 2 Preset parameters of the simulation
从MUSAN语音库中选取一段长为4.5 s的语音作为目标声源信号,内容为:“手表等穿戴设备也具备支付指纹识别的功能”。选用相同的噪声环境,声源入射角θ为64.85°,信噪比为-10 dB。根据时延估计算法的性能,在仿真中选取语音信号能量较高的语音段用于时延估计,以确保时延估计准确。带噪语音信号经算法处理后信噪比变化如表3所示。从表3中可以看出,加入时延补偿算法后,带噪语音信号经过GSC 算法能够在不同噪声环境下提高信噪比10 dB左右。
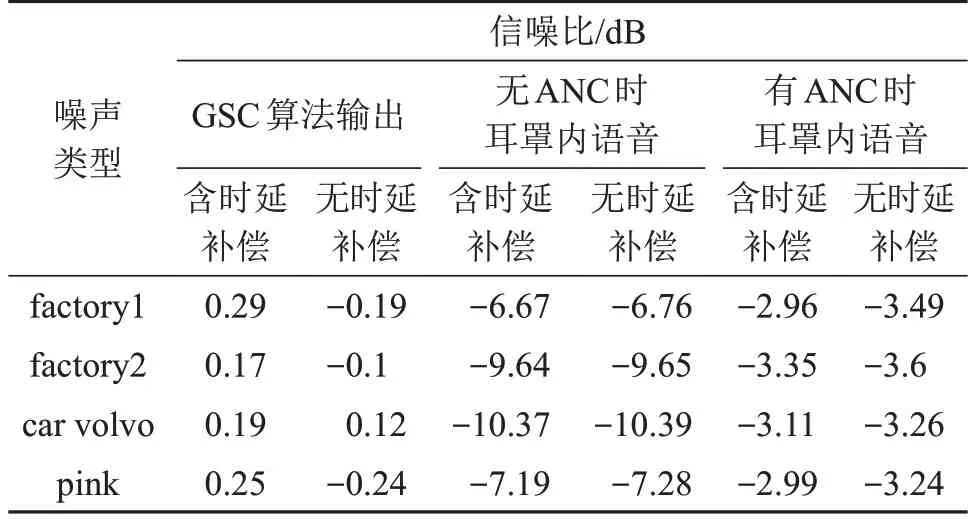
表3 含噪语音处理后信噪比Table 3 Signal to noise ratio after noisy speech processing
图6是不同环境噪声下加入时延补偿算法和未加时延补偿算法的输出信号波形图。如果仅使用耳罩的被动降噪抑制环境噪声,将GSC 算法输出的语音信号经过次级通道直接输入耳罩内,由于外界低频噪声的引入使得耳罩内信号的信噪比相较于GSC输出信号下降6~10 dB左右,此时耳罩内信号的波形图对应于图中加入时延补偿无ANC 时算法输出信号。根据表3和加入时延补偿后算法最终输出信号的波形图可以看出,将GSC和ANC算法结合可以在增强语音的同时有效抑制外界环境传入耳罩内的低频噪声,与仅使用耳罩被动降噪的输出信号相比,信噪比提高了3~7 dB。
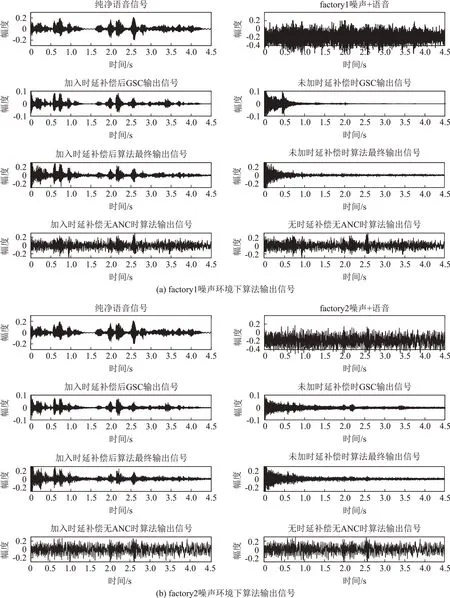
图6 不同噪声环境下算法输出信号Fig.6 Algorithm output signals under different noise environments
此外,由未加时延补偿的算法输出波形可知,在车内噪声环境下,有无时延补偿算法对输出的语音信号质量影响不大。但是,在工厂噪声和粉红噪声环境下,如果没有相应的时延补偿,GSC算法和ANC算法的输出会同时抑制语音信息与噪声信息,虽然输出信号的信噪比是提高的,但其携带的语音信息非常少。
为了对算法最终输出的语音质量进行评价,将相应的输出信号转换为音频信息,采用可懂度[29]及语音质量感知评估(Perceptual Evaluation of Speech Quality,PESQ)[30]得分分别对其进行主观和客观评价。
可懂度评测中由20 位未听过原始语音的测试人员分别用人耳收听播放的音频信息,音频信息分别是耳罩外信号、外界声音经过耳罩被动降噪传入耳罩内的信号和耳罩内分别经过改进的和未改进的语音增强算法处理后的信号。将测试人员复述内容的正确字数与实际字数的百分比作为可懂度数值。不同噪声环境下测试人员的平均可懂度数据结果如表4所示。
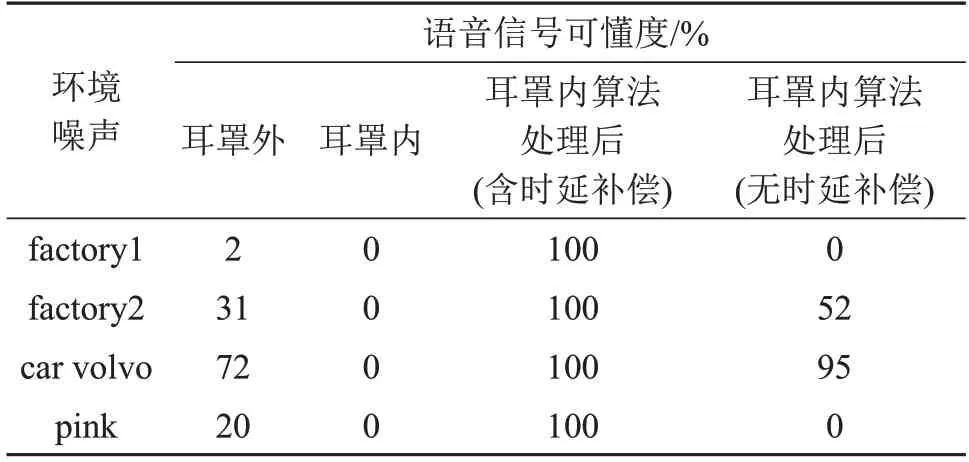
表4 不同噪声环境下可懂度主观测试结果Table 4 Intelligibility subjective test results under different noise environments
从表4中可以看出,由于耳罩的被动降噪特性相当于一个低通滤波器,抑制了声音信号的高频分量,使得传入耳罩内的信号听不到有效信息。加入时延补偿后外界信号经过算法处理最终得到的语音输出能够保留所有的有效信息,时延补偿对car volvo 噪声环境下输出的信号可懂度影响较小,而对其余三种噪声环境下输出信号的可懂度影响较大,尤其是在factory1和pink噪声环境下,如果没有时延补偿,耳罩内算法输出的信号听不到任何有效信息。
在客观评价中,PESQ的感知模型用于计算经过系统处理后的信号与期望信号的距离,其输出是对受试者在主观听力测评中给予的感知质量的预测。模型得到的PESQ 取值在-0.5~4.5 之间,得分越高表示语音质量越好。在不同的噪声环境下,用于可懂度评价中的不同音频信号的PESQ得分如图7所示。由图7 可知,带噪语音信号经过改进的算法处理后具有最高的PESQ得分,与耳罩内的信号质量相比有2~3分的提高,与改进前算法输出信号的质量相比有0.2~2.5 分的提高。其中factory1 和pink噪声环境下的语音质量提升达2分以上。
5 结论
本文通过仿真分析了基于谱减法改进的GCC时延估计算法的性能以及加入时延补偿后的GSC主动隔声耳罩语音增强算法的噪声抑制和语音增强效果。文中通过比较不同加权函数在不同噪声环境下的时延估计异常率,确定了λ=0.1的MCSP加权函数在本文的时延估计算法中具有更好地抗噪性和普适性。此外,仿真结果表明,将ANC 算法与GSC语音增强算法结合,可以在有效增强语音的同时抑制外界传入耳罩内的低频噪声,并且加入时延补偿算法后,经过改进的算法在factor 噪声和pink噪声环境下输出的语音信号质量相比于改进前的算法有明显提升。本文中的方法对高噪声场所中实现听力保护和不同角度入射声源的语音增强具有指导意义。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
智慧少年·故事叮当(2021年12期)2021-01-17
动漫星空(兴趣百科)(2019年12期)2019-12-05
电子制作(2019年23期)2019-02-23
电子设计工程(2017年17期)2017-09-07
噪声与振动控制(2016年5期)2016-11-09
数字通信世界(2015年4期)2015-09-23
噪声与振动控制(2015年5期)2015-08-19
舰船科学技术(2015年8期)2015-02-27
装备环境工程(2015年1期)2015-02-06
