
生成式人工智能机器学习中的著作权风险及其化解路径
2024-01-12 04:20:12詹爱岚田一农
电子知识产权 2023年11期
文 / 詹爱岚 田一农
近年来,人工智能,尤其是生成式人工智能(Generative Artificial Intelligence,下文简称“生成式AI”)的快速发展,给文学、绘画、音乐、计算机编程等领域带来了巨大的冲击。生成式AI 技术更是入选了世界经济论坛(World Economic Forum, WEF)“2023 十大新兴技术”,成为未来三到五年内对世界影响最大、推动第四次产业革命的新兴核心技术之一。1. World Economic Forum: Top 10 Emerging Technologies of 2023, at https://www3.weforum.org/docs/WEF_Top_10_Emerging_Technologies_of_2023.pdf, last visited on September 4,2023.与此同时,当“创作”开始变得普罗大众,这种智能型“创作”给传统著作权理论带来的挑战也日益凸显。完善生成式AI 的监管和法律规制已迫在眉睫,如何平衡好产业发展与权利保护问题,已成为当下的重点。作为一种基于机器学习的人工智能技术,生成式AI 通过大规模数据集的学习训练生成新的内容。因此,生成式AI 的“创作”,“前端”涉及机器学习所使用训练素材(即文字、音乐、绘画等作品)的著作权保护问题,“后端”则涉及“创作”成果(即人工智能生成物)的可著作权问题。随着“ChatGPT”和“文心一言”等国内外生成式AI 产品的相继面世和快速迭代,AI 大模型已然成为各国竞争的战略“高地”。然而,当产业界在为生成式AI 的“超车”发展积极添柴加火的时候,客观认识和分析机器学习所涉训练素材中面临的著作权风险,努力寻求应对和化解的路径同样具有重要的理论价值与现实意义。
一、风险源起:生成式AI 中机器学习的著作侵权风险高
生成式AI 的工作原理是通过大量数据学习总结出规律与结构,进而通过固定模型与操作者指令生成新的内容。在能够产生成果之前,从大量的数据运算中总结规律的过程便是机器学习环节。“机器学习之父”Arthur Samuel 将机器学习定义为“在不直接针对问题进行编程的情况下,赋予计算机学习能力的研究领域(Field of Study That Gives Computers the Ability to Learn Without Being Explicitly Programmed)”。2. See Samuel, Arthur L:Some Studies in Machine Learning Using the Game of Checkers, IBM Journal of Research and Development, Vol.3:210, pp.210-229(1959).因此,作为人工智能科学的一个分支,机器学习利用数据和算法,通过模型训练学习、模仿人类学习的方式来逐步提高自身决策的准确性。3. 参见汪荣贵、杨娟、薛丽霞:《机器学习及其应用》,机械工业出版社2019年版,第2 页。机器学习的过程简单分为三个阶段:(1)数据收集输入阶段,收录其他作品数据并编辑成自身的数据库;(2)机器学习阶段,选择最优算法搭建模型并进行模型质量评估,以便判断是否固定该模型;(3)输出阶段,最终模型会根据使用者输入的数据及指令产出人工智能生成物。具体过程如图1 所示。
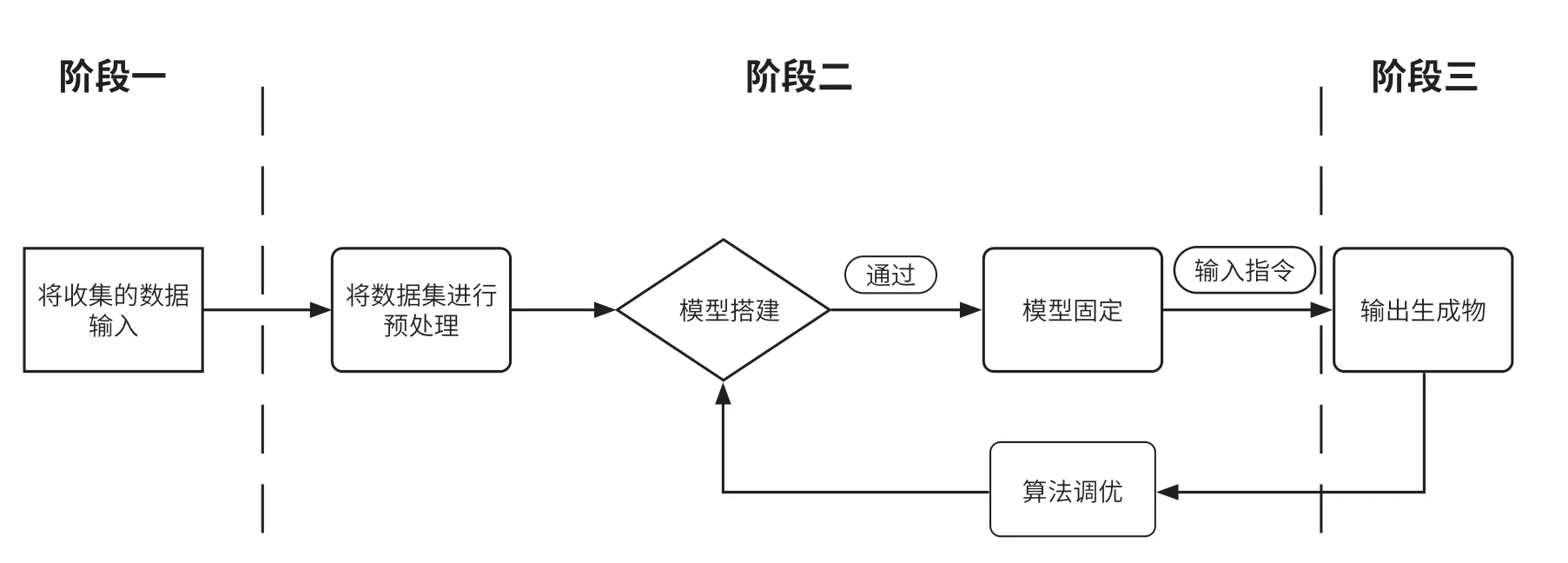
图1 机器学习流程图
数据的获取是机器学习的开端,人工智能通过大量分析获取数据的过程被称为机器阅读。4. 参见焦和平:《人工智能创作中数据获取与利用的著作权风险及化解路径》,载《当代法学》2022年第4 期,第128-140 页。此阶段人工智能开发者可以通过开源数据库、他人合法授权、使用进入公共领域的作品等方式避免著作权纠纷,本文便不再赘述。而目前以下几种能获取受著作权保护的作品方式因未经原作者许可,极易侵犯他人著作权:(1)通过网络爬虫协议爬取;(2)网络平台企业通过服务协议条款取得用户的授权许可;(3)未经授权将他人非数据作品数字化;(4)未经许可直接扒窃数据库或个人数据。
数据收集完成进入学习阶段后,人工智能会逐一分析素材的所有元素,包括类型、布局结构、内在的思想情感、作者的表达风格等。就如同在人脑中构思反馈的过程延伸到电脑之中。电脑提取这些作品中的用词、排版、结构、主题等分为不同大类小类并标注关键词,再不断完善循环这一过程,做到自我更新、迭代升级。而在这一过程中又会对他人享有著作权的作品进行无数次的拆解、排列、重新组合,这涉及了对作品的改编、翻译、汇编等行为,要视具体情况分析是否侵权。如果未经著作权人许可,则一定会对其改编权、汇编权等合法权利产生侵犯。
综上可见,没有获得著作权人授权的版权素材,无论是在数据录入阶段还是后续的机器学习阶段,都具有极高的侵权风险。实践中,美国已经发生了多起针对生成式AI 在机器学习中涉嫌侵犯训练素材著作权的纠纷,包括:2023年1—2月,针对AI 图像生成平台Stable Diffusion;Midjourney和DreamUp的著作权集体诉讼、5. Andersenv. Stability AI Ltd. et al, 3:23-CV-00201;Getty Images (US), Inc. v. Stability AI, Inc.1:23-cv-00135..2023年6月,针对AI 文本生成平台ChatGPT 的多起著作权集体诉讼。6. Tremblay, P.& Awad, Mv. OpenAI, Inc., 3:23-cv-03223.
二、侵权分析:机器学习中的具体著作权风险
人工智能的著作权风险贯穿了从机器学习阶段到作品产出阶段的始终,在这一过程中涉及了对素材作品复制、改编等权利的妨害,即便该数据是合法获取的。7. 参见刘友华、魏远山:《机器学习的著作权侵权问题及其解决》,载《华东政法大学学报》2019年第2 期,第73-75 页。
(一)机器学习在数据收集过程中对作品复制权的侵犯
机器学习对于他人作品复制权的侵犯可以分为两个阶段,首先是在数据收集阶段的侵权,也就是机器阅读环节的复制行为,这一环节往往牵涉到大量收录他人未授权的作品。根据《中华人民共和国著作权法》(以下简称《著作权法》)第十条第五款规定,8. 《中华人民共和国著作权法》第十条第五款:复制权,即以印刷、复印、拓印、录音、录像、翻录、翻拍、数字化等方式将作品制作一份或者多份的权利。已明确将数据爬取、文本作品转化等收集素材的方式都列入《著作权法》的规制。一方面,人工智能在建立自己的数据库时需要对他人作品的数据进行复制,如果这些输入的数据中涵盖了原作者未授权的作品,那么该复制行为就侵犯了受著作权法保护的原作品的复制权。另一方面,除去对原作品素材的直接复制之外,人工智能开发者还会将纸质版作品的内容扫描转化成电子介质储存到数据库当中,且未经过其作品的著作权人许可或支付报酬。以上行为都已经构成了侵犯复制权的组成要件,侵犯了原作者的复制权。
其次,对于机器学习环节的复制,即作品产出前的行为是否构成侵权。学理上主流观点认为机器学习阶段的模型建立是伴随着服务器内的数据转码产生的,是一种临时的、不具有侵害性的客观行为。并不是所有的复制行为都会侵犯复制权,必须结合复制后的行动来判断。如果在复制后产生了出售、展览等变现行为获取收益,才属于《著作权法》所明令禁止的复制行为。立法上,我国在起草《信息网络传播权保护条例》时,临时复制的法律性质也是焦点问题之一,最终对该行为的侵权定性也并未出现在正式官方文本中。9. 参见万勇:《人工智能时代著作权法合理使用制度的困境与出路》,载《社会科学辑刊》2021年第5 期,第93-102 页。其他国家,如美国的Cablevision 公司侵权案中,法院也认为被告对于原告影像数据的复制在存储器内停留的时间只有十秒,且该时间也符合当时此项技术运行的合理时间,根据合理使用四要素法判断不构成对他人著作权的非法妨害、不干涉他人著作权的行使。综上,临时复制不构成对复制权的侵害,故本文所提到的机器学习的复制权侵权行为仅仅针对生成式人工智能在数据收集及数据库建立时的复制行为。
(二)机器学习在数据处理过程中对作品改编权的侵犯
改编权即改变作品,创作出具有独创性的新作品的权利。改编权的构成要件有两个:其一,行为上利用了原作品的独创性表达;其二,结果上创作出具有独创性的新作品。就生成式AI 而言,判断机器学习是否侵犯原作者改编权的关键,是考察其对原作品表达的“利用程度”。即如果最终生成物保有原作品的独创性表达较高时,便构成对原作品的改编。
改编权的侵权分析,需从机器学习的方式入手。根据机器学习素材的录入、抓取是否具有针对性、唯一性,可将机器学习分为一般机器学习和特殊机器学习。10. 参见李安:《机器学习作品的著作权法分析——非作品性使用、合理使用与侵权使用》,载《电子知识产权》2020第6 期,第60-70 页。
一般机器学习,是指在已收集的庞杂的信息库中进行分析挑选,根据使用者的指令对照数据进行生成,不会是在某个蓝本上直接完成修改。其产出作品的风格、外观也是五花八门,并非使用者能严格控制的。这类作品往往都带有很强的创新性,即使属于改编范畴也缺乏比对目标,所以一般的机器学习对改编权几乎没有影响,除非生成物中保留了某些作品的基本独创表达。
特殊机器学习,是指使用特定素材库进行的训练,如加州大学教授戴维·柯普设计的EMI(Experiments in Musical Intelligence),专门投喂巴赫的音乐作品,模仿巴赫的风格创作。该程序创作出的作品在音乐节上使得80%以上的听众认为这就是巴赫的作品。但由于巴赫的音乐作品早已进入公共领域,不会引发著作权纠纷。不过如果巴赫还在世的话,那么根据该程序所模仿的巴赫独创性风格所占其生成物的比重以及对原有市场可能产生的替代性来判断,势必会侵犯原作者的改编权。作品的独创性表达是作者思想的延伸,特殊的机器学习本质上就是在不碰触独创性表达的同时最大程度去接近原作者的思想范畴,并用自己的方式进行表达。但原作者的思想和表达往往是紧密相连的,并且特殊机器学习由于其素材的限定也决定了必然要受到原作者表达的约束。因此此类生成物基本上都会因与原作品过度相似而产生替代性,存在侵犯原作者改编权的风险。
三、理论探源:生成式AI 中的“非表达性使用”与“转换性使用”
各国为缓和人工智能发展与著作权保护之间的矛盾,试图突破原有的著作权合理使用框架,为人工智能使用他人版权作品的免责性寻找新的法定依据。其中既有法律上的调整,如欧盟的“文本与数据挖掘例外”的明文规定,11. 欧洲议会和欧洲理事会2019年4月17日关于数字单一市场版权和相关权的指令,欧盟官方网站https://eur-lex.europa.eu/eli/dir/2019/790/oj,最后访问日期:2023年10月25日。也有理论上的突破,如美国的“转换性使用原则”的现实适用。12. 例如2010年的甲骨文公司诉谷歌公司案:Oracle America, Inc. v. Google Inc.,3:10-cv-03561、2015年的作家协会诉谷歌图书馆案:Authors Guild v. Google, Inc., No. 13-4829、2019年的新思科技公司诉英韧科技公司案:Synopsys, Inc.v.InnoGrit, Corp.,5:19-cv-02082,都是法官通过“转换性使用”及“四要素”法判断被告是否构成合理使用。考虑到目前我国司法实践中法官依靠“三步分析法”并结合实际自主裁判较多,13. 例如2014年上海美术电影制片厂诉新影公司案:(2014)普民三(知)初字第258 号、2016年向佳红诉乐视影业公司《九层妖塔》字体侵权案:(2016)京0105 民初50488 号、2021 天津字节跳动网络有限公司诉天津启阅科技有限公司等著作权侵权案:(2021)津03 民初4293 号,法官都是采用判断是否构成“合理使用”的“三步检验法”,结合是否影响到著作权人的利益判断是否构成合理使用。故若能从理论方面论证人工智能使用作品的合理性,则会比法律改制节约更多的司法成本。对此,笔者从合理使用的两个基础理论,即“非表达性使用”“转换性使用”出发,尝试能否为生成式AI 合理使用他人作品提供理论支持。
(一)“非表达性使用”对于机器学习的免责分析
根据萨格教授的观点,所谓“表达性使用”是指使用者的目的就是利用原作品独创的表达方式,既包含了原作的艺术价值也会威胁到原作品的市场价值,14. See Matthew Sag.The New Legal Landscape for Text Mining and Machine Learning, Journal of the Copyright Society of the USA,Vol.66:291,p.291-367(2019).会产生对原作者权利的侵犯。“非表达性使用”则是指人工智能并非利用原作品的独创性表达,而是为了方便检索、数据分析以及其他采取皆非传统著作权法意义上的复制、改编、传播、汇编的使用方式,15. 参见徐小奔、杨依楠:《论人工智能深度学习中著作权的合理使用》,载《交大法学》2019年第3 期,第32-42 页。不可能生成对原作具有市场替代性的新作品,也不会威胁到原著作权人的合法利益。例如人脸智能识别系统对不同摄影作品人脸特征的采集,包括五官形状、肤色等生理特征进行数据模型构建来优化人脸素材库,对于其他具有独创性的拍照角度、姿势等元素则不会触及。故人工智能对他人作品的“非表达性使用”是基于其作品的“工具性”价值而非“表达性”价值,其存在作用对于新作品整体而言也只是让他人能获得更好的实用性体验。
实践中,此理论的难点在于如何判断是否利用了原作品的独创性表达。如美国作家协会诉谷歌图书馆项目案,16. 谷歌将大量由原作者享有著作权的图书通过文字扫描录入数据库的方式建立起了一个网上的数字图书馆,并将这些已经数字化的作品的名称、关键词以及标识性的片段输入搜索系统方便游客浏览检索。美国作家协会认为谷歌未经许可为数字图书提供的扫描及检索方法构成了对著作权的侵权,此案经过十年的争议最终维持了谷歌图书不侵害著作权的判决,并经过联邦最高法院不予受理原告上诉后彻底结束。该案法官认为图书馆复制图书部分内容的目的并非产生替代原作品的市场价值而是方便群众检索图书信息,不会对原作者的利益造成“本质性的”损害(这里不能以完全不存在损害为诉的利益,因为也可能会存在通过检索部分内容就让读者失去了购买的欲望或读者已经通过阅读该部分内容得到了足够的信息)。综上,人工智能的“非表达性使用”不属于著作权法规制的侵权事项,所以目前规制的应是根据“三步检验法”可能会对原作品产生关联或替代,可能侵害原作者合法利益、产生市场替代性威胁的“表达性使用”。
(二)“转换性使用”对于机器学习的免责分析
“转换性使用”是一个衍生于美国四要素判断标准的概念,17. 美国著作权法第107 条将合理使用制度规定为:包括为了批评、评论、新闻报道、教学、研究等目的使用作品复制件、录制品或以其他任何手段使用作品。在确定在特定情况下使用某一作品是否合理时,应考虑以下因素:(1)使用的目的和性质;(2)受版权保护的作品的性质;(3)使用部分占原著作权作品的量和实质程度;(4)使用对作品潜在市场或价值的影响。于1990年由美国法官皮埃尔·勒威尔首次提出,并将其定义为“如果二次使用为原作增加了新的价值——即如果被引用的原作品被用作原材料,转换性地创作出新的信息、新的美感、新的视角和理解,那么这种行为是合理使用制度试图保护的”。“转换性使用”首次被正式采用是在1994年美国联邦法院审理的Campbell 诉 Acuff-Rose 音乐公司案中,联邦最高法院判定被告2 Live Crew 的滑稽模仿作品构成美国著作权法第107 条意义上的合理使用。这里笔者认为联邦最高法院判断的基础是新作品已经达到了让群众能够轻易感受到其区别于原作的独创内容,使得与原作品之间的联系因转换性的提高而减弱。此种减弱不仅体现在受著作权法保护的表达方面,也体现在不受保护的思想情感方面,属于“内容上的转换性使用”。因此如果具有“内容上的转换性使用”的作品,当他们的独特性表达或内容不具有足够的创新性时,即使新作品因市场流通所具有的价值远远超过了原作品本身的价值,也不能代表该作品没有侵犯原著作权人的利益。18. 参见杨书林:《作品转换性使用规则研究》,西南科技大学2022年硕士学位论文。是否具有独创性,是法官判断生成物是否属于“转换性使用”的重要标准。
“转换性使用”的本质并没有脱离四要素分析法的范围——确保在原作者市场份额不受影响的情况下尽可能保证他人通过“转换性使用”创作出更多优质产品、开发更多新客户。其中新作品所表达内容、目的、功能的“新”在哪里,“新”到什么程度难以一言以蔽之。哪怕是其发源地美国也仅仅是将该理论作为一块很好的“砖头”,哪里需要堵哪里。如果所有问题第一步都能通过“转换性使用”来判断的话,那么实则是在淡化法律的作用。所以目前笔者认为不应该将“转换性使用”视为解决一切问题的万能法宝,或许将其作为一项兜底性条款是最好的选择。研究中的优先级也应后置于“合理使用”“法定许可”的可行性分析以及我国三步检验法判断标准。
四、中国:生成式AI 的立法监管进展
(一)我国生成式AI 立法现状
鉴于人工智能产业发展的“双刃剑”属性,各国对人工智能的立法规制基本持审慎的态度。如何在促进产业发展的同时有效规制风险是立法者最为关注的问题。我国在大力推进生成式AI 产业发展的同时,对相关立法持同样态度。截至2023年,我国针对生成式AI 机器学习规则在立法上尚无明确法条。无论是《著作权法》中第二十四条的合理使用规定,还是先后颁布的《中华人民共和国网络安全法》《网络信息内容生态治理规定》《中华人民共和国个人信息保护法》等法律法规,都只是对人工智能技术和算法滥用问题规定了较为详细的法定义务和监管体系,其重心更多是放在社会利益的保护方面。而关于人工智能学习阶段内对个体作者享有的著作权的侵权保护、利益补偿等仍未涉及。2023年被称之为“生成式AI 的爆发之年”,我国立法者开始逐渐重视生成式AI 的行为规制。2023年1月10日正式实施的《互联网信息服务深度合成管理规定》标志着我国首次对生成式AI 的深度合成技术进行规制。其中第十四条第二款规定:深度合成服务提供者和技术支持者提供人脸、人声等生物识别信息编辑功能的,应当提示深度合成服务使用者依法告知被编辑的个人,并取得其单独同意。在此规定下,一方面保证了被编辑者的知情权,确保其人格权不受侵犯,为日后可能行使的权利救济夯实基础;另一方面令生成物在相关权利人许可的前提下产出,避免了“前端”权利瑕疵带来的后续侵权风险。但从生成式AI 整体发展的角度来看,仅对深度合成技术进行法律规制所产生的辐射范围远远不够,还需要更具前瞻性的立法为产业发展护航。为此,进一步制定的《生成式人工智能服务管理办法》于2023年8月15日起正式实施,作为我国甚至于全球首部针对生成式AI 的专项立法,无疑为日后的进一步立法和司法实践提供了重要的基础。
(二)最新立法:《生成式人工智能服务管理办法》仍旧存在漏洞
《生成式人工智能服务管理办法》(以下简称《管理办法》)相比于前述相关立法的成效更加显著。如第七条规定人工智能提供者应当对生成式AI 产品的预训练数据、优化训练数据来源的合法性负责。用于生成式AI 产品的预训练、优化训练数据,应满足使用具有合法来源的数据和基础模型。涉及知识产权的,不得侵害他人依法享有的知识产权。采取有效措施提高训练数据质量,增强训练数据的真实性、准确性、客观性、多样性等。此外,该《管理办法》还规定了安全等级评估、算法模型备案、数据信息来源公开等制度,明确使用者、开发者等不同主体的法律责任,确保生成式AI 在遵循创新与尊重著作权的原则下健康发展。
但是,在《管理办法》中还是能发现许多缺漏。如对第七条的解读,只要是合法作品,并获得原作者授权的,就可以纳入机器学习的数据库之中。我国也尚未明确机器学习是纳入合理使用制度、法定许可制度或以其他方式提供保护。在上位法态度尚未明确时,《管理办法》基于现行法律规定将机器学习素材的使用局限于“原作者许可”模式,未曾考虑到未来一段时间内因“原作者许可”模式运行效率较低,以及可能造成的算法偏见导致对生成式AI良好发展势头的遏制。本质上其实是淡化了知识产权制度的利益平衡原则在人工智能领域的适用。其次,第七条只针对合法作品的保护,忽视了机器学习对违禁、违法作品的使用问题。违禁、违法作品,系指“依法禁止出版、传播的作品”19. 参见金耀:《浅析违禁作品的内涵与保护》,载《中国版权》2011年第6 期,第30-32 页。,对于违禁、违法作品,我国依旧承认其享有著作权。且第二项规定“不能含有侵犯知识产权的内容”将复杂问题简单化。产业实践中机器学习无论是通过网络爬虫技术,还是对他人享有的合法数据的直接使用,都是在侵犯著作权的边缘行走。因此,迫切需要选择合适的路径来规制这些行业中盛行的行为。
(三)司法实践对立法需求依旧迫切
综上,我国对于生成式AI 机器学习的立法现状虽在进步但进展速度缓慢,仍然无法依靠成文法来缓解当下其可能侵犯著作权的燃眉之急。这导致目前我国的司法实践中针对此类问题还是多依靠法官的自由心证,甚至可能引发“同案不同判”的后果。如2018年北京菲林律师事务所诉北京百度网讯科技有限公司一案中,法院认为涉案的文章是通过人工智能软件分析获得的报告,不具有获得《著作权法》保护的属性,20. 参见北京互联网法院(2018)京0391 民初239 号民事判决书。而在2023年11月27日北京互联网法院却认可了人工智能生成图片的作品属性以及著作权归属。21. 参见北京互联网法院(2023)京0491 民初11279 号民事判决书。虽然两起案件在作品类型方面有所差异,但在说理部分北京互联网法院均是引用《著作权法》及其实施条例作为法律依据。相同的法条却引申出不同的解释,既无益于日后的司法裁判,又有损法律的准确性、权威性。虽然我国目前尚无关于生成式AI 在机器学习过程侵犯他人著作权(即“前端”)的判例,但根据司法实践中对“后端”的裁判过程也可管中窥豹。如此,在后端的裁判结果尚且有分歧的状态下,对前端的侵权行为寻求判断标准、保护措施、救济渠道等似乎是无稽之谈。故笔者认为当下我国已经严格规制了生成式AI 使用者的应尽义务,但缺少明确对原著作权人保护与补偿的条款,应尽快明确生成式AI 使用者依法使用他人作品数据的法律依据,究竟是采用美国的“转换性使用”理论,还是“合理使用”等制度模式,方可明晰接下来的立法方向。对此,下文的国外立法模式或许能给予我们一些新的启发。
五、欧盟:生成式AI 的立法监管进展
(一)《单一数字市场版权指令》:“文本数据与挖掘的例外”
欧盟一直致力于引领全球数字立法治理,早在2016年欧盟委员会就以营造服务于互联网发展的环境为目的公布了《单一数字市场版权指令》草案,并于2019年正式颁布《单一数字市场版权指令》。该指令以适应互联网时代的发展和变化为首要目的,对机器学习的前提条件“文本数据与挖掘”进行了规制。指令第2 条对适用主体进行了定义和限制:“研究机构”应当符合:以非营利为基础,或将所有利润再投资于其科学研究;或者出于为成员国所承认的公共利益而进行研究。在此基础上第3 条明确允许了科研机构和文化遗产机构为科学研究目的进行文本和数据挖掘,对其合法获取的作品或其他内容进行复制与提取的行为。可见该法主要目的是服务于科研人员,而忽视了版权人和商业主体的利益。一方面该法案对非商业主体利用他人作品的行为划定了标准,包括复制品应当妥善存储,确保研究结果准确性和完整性等;另一方面它的“狭隘性”忽视了基于商业目的而投入研究的主体的重要性。尽管指令第4条从行为方式角度进一步阐明:任何主体“以文本和数据挖掘为目的,对合法获取的作品或其他内容进行复制与提取的行为”,隐晦地表达了对以商业营利为目的的主体的许可,但仍被人诟病不能满足欧盟的科技企业在新兴的人工智能化浪潮之中取得相对于其他国家企业的优势地位。因为该条第三款规定了作品权利人可以用适当方式对作品的使用进行保留的权利,这可能会导致在实践中出现原创作者联合声明保留权利以抵制生成式AI 学习及创作的尴尬局面。综上可以看出早期欧盟对人工智能立法方向还是以促进科技发展为主,在立法态度上格外谨慎,并不认可商业性主体的使用行为,同时也禁止将通过利用他人作品产生的生成物或复印件提供给公众。最后,该指令也并未对如何使用受版权保护的文本和数据训练基础模型的行为做出明确规定,难以适应新一轮人工智能发展规制。
(二)《数据治理法》:“数据中介机构”与“数据流通共享”
2022年4月6日欧洲议会通过《数据治理法》,力求促进不同经济参与者之间的数据共享(包括商业秘密、个人数据和受知识产权保护的数据)。相比于2018年公布的《通用数据保护条例》对个人数据的严格保护,该法将数据视为一种可供流通的财产加以规制。其中企业或者个人对他人数据进行使用必须通过数据中介服务提供者加以实现。该法规定:明确数据共享服务商业务范围并实行登记制,规定从事数据持有者和潜在数据用户之间中介服务或者数据合作社服务的,为该法规定的数据共享服务商,并要求其向主管部门提交登记。同时数据服务商要确保服务的程序和价格公平透明和非歧视性,可见欧盟立法态度逐渐开始兼顾保护与流通两种属性。人工智能企业可以在数据中介机构上通过数据交易使用他人数据或是素材且不必经过他人同意,同时数据提供者又能获取合理的经济补偿,形式上符合我国法定许可制度的模式。但一方面,该法案的经济补偿机制尚未完善,数据持有人的补偿落实困难;另一方面,在缺少强制命令或激励政策的支持下,数据持有人缺少加入共享平台的意愿。本法案的目的还是在各主体“自愿”“共享”的基础上设立义务来促进数据流通,但目前看来若无额外激励,数据持有者并不具有分享的意愿。22. 《欧盟数据治理的新发展》,https://www.chinacourt.org/article/detail/2022/11/id/6994275.shtml,最后访问日期:2023年10月1日。
(三)《人工智能法案》草案:生成式AI 供应者作为义务主体下的合理使用
对此,欧盟委员会于2023年6月14日正式通过了《人工智能法案》草案,该法案立足于人工智能领域技术应用,有望成为全球首个关于人工智能的法案。该法案进一步限定了生成式AI 产物供应者的义务,其中第28 条规定:人工智能系统中使用基础模型,专门用于以不同程度的自主性生成复杂的文本、图像、音频或视频等内容(“生成式人工智能”)的供应者,以及将基础模型专门用于生成式人工智能系统的供应者还应当:(a)遵守第52 条要求的“透明度义务”23. “透明度”是指人工智能系统的开发和使用方式应允许适当的可追溯性和可解释性,同时使人类意识到他们与人工智能系统的交流或互动,以及适当告知用户该人工智能系统的能力和限制,并告知受影响的人他们的权利。。(b)训练,并在适用的情况下,设计和研发基础模型,以确保有足够的保障措施,防止产生违反欧盟法律的内容,符合普遍公认的行业先进实践,并不损害基本权利,包括言论自由。(c)在不影响国家或欧盟版权立法的情况下,记录并公开提供受版权法保护的训练数据使用情况的足够详细的摘要。可以看出该法案的态度从法定许可主义又偏向到了合理使用主义,在行为主体使用生成式AI 的过程中只要尽到了上述义务即可将该产出的基础模型向市场提供或自己使用。本次立法在一定程度上保证了原作者的著作权,通过公示其作品元素在人工智能运作中的作用,全程记录任何用于本次训练AI 系统所使用的文本、图像、视频和音乐的版权材料,并且通过技术手段保障本次训练素材的隐私性和安全性。这样可以使得原作者知晓自己的作品被哪些AI 进行模型训练,以保有自身是否决定维权且获取收益的权利。
纵观欧盟的整个人工智能立法进程可以看出立法者在“合理使用”和“法定许可”之间徘徊不定。笔者认为造成这一结果的原因是“非商业性主体”原则与人工智能发展之间的矛盾难以调和。单凭科研机构等非商业主体进行人工智能的研发困难重重,它需要大量的流通数据以及市场反馈来优化升级。商业性主体可以凭借其市场占有份额及庞大的客户量满足上述需求,若将商业主体排除在外或是对其加以繁琐的镣铐,都会限制人工智能的发展。但同时商业性主体本身的盈利性必然会损害其他著作权人的合法权益,是尽量确保二者间的利益平衡,又或者为保障我国人工智能发展而暂时降低著作权上的保护力度,这需要立足于我国人工智能产业与科技创新的现实需求,在借鉴国外立法的同时也要正视本国国情。
六、生成式AI 机器学习中著作权风险的化解路径
为了顺应国家发展战略考量,必须给予人工智能技术研发一定政策上的支持,要确保此类制度安排尽可能简洁、高效。笔者赞同目前的两种制度方案,即法定许可制度和合理使用制度,下面将逐一展开具体分析。
(一)法定许可:理想主义的选择
法定许可的赞同者认为要想确保优质作品的产出,就必须优先考虑创作者的利益。24. 参见刘友华、魏远山:《机器学习的著作权侵权问题及其解决》,载《华东政法大学学报》2019年第2 期,第68-79 页。人工智能创作本身并不具备产生“新作品”的能力,如果任凭人工智能剥夺作品权利人的应得利益,那么就会磨灭人类创作者的激情,等同“杀鸡取卵”。法定许可制度可以在保证著作权人利益的同时服务于推动人工智能发展的国家政策,较合理使用制度来说更具有合理性。支持该理论的学者对于该制度的初步构想是,25. 参见高阳、胡丹阳:《机器学习对著作权合理使用制度的挑战与应对》,载《电子知识产权》2020年第10 期,第13-25 页。建立一个类似于欧盟在《数据治理法》中设想的“个人数据共享中介机构”,要求使用主体将其欲使用的作品进行登记付费,让企业与个人在此机构的指引和帮助下合理使用他人享有著作权的作品数据。正如前文所说机器学习所需要的作品是一个庞大的数量,每一个作品都代表一位著作权人,如果单凭企业去进行协商联络,带来的时间、经济上的压力是不言而喻的。因此通过官方的平台进行作品登记,并向权利人支付报酬既可以提升交易效率、降低成本,又可以保证机器学习在获得大量素材的同时兼顾原著作权人利益。
但笔者认为虽然从模式构建上法定许可制度可以完美地解决目前人工智能机器学习和著作权人冲突的问题。但立足于实际,无论是起步阶段还是后续的维护都存在着难以克服的困难,比如:一、著作权人登记是否强制?没有著作权人的“孤儿作品”如何处理?二、目前的区块链技术不足以支撑保证数据的绝对安全,技术的桎梏暂时无法满足框架的搭建。三、法定许可的利益分配方案如何划定且由谁监督执行?如果缺少高效公平的分配体系与监督体系,著作权人应得的利益仍旧难以保障。综上,笔者认为至少根据我国现状来看,法定许可制度还只是一个理想型的方案,缺少实施的可能性。
(二)合理使用:现实主义的选择
相对于法定许可制度,合理使用最大的优势就在于其实施的现实可能性以及不必支付报酬的属性。目前除了科研院所、研发机构等国家财力支撑的主体,还需要其他商业主体承担技术开发、研究等工作。商业性质的大型科技研发企业已经成为人工智能研发主力。对此,参考欧盟许可商业性主体在不损害著作权人合法权利的情况下对数据加以利用,并不禁止以营利为目的的使用方式或许是当下最好的选择。在兼顾滋养人工智能创作产业的土壤肥沃的同时也确保以人为核心的著作权理念不被破坏。由于我国的人工智能技术尚处于起步阶段,基于合理使用制度下的免费使用无疑能为人工智能技术的研发节约更多的成本,满足人工智能开发主体的研发需求。同时若能借鉴欧盟在《人工智能法案》草案中规定的生成式AI 创作者的“素材公示义务”,则在人工智能产出时也有助于将原著作权人的作品与口碑推向其他市场,为原著作权人带来潜在的收益。此外我国的合理使用制度还有着良好的立法与实践基础,不但在新通过的《著作权法》中明确了“三步检验法”的模式,且在实践中也支持商业性主体以营利为目的的使用。如上海美术电影制片厂诉新影公司案中,新影公司以“黑猫警长”等卡通作品中的人物形象完善电影海报吸引顾客观看,从而达到获利的目的,法院也并没有因为其商业性行为而认定其侵权。故运用合理使用制度来解决机器学习的著作权问题有着良好的现实基础。最后,从著作权法追求“利益平衡”的角度来看,达成原作者“个人利益”与社会“公共利益”之间的平衡是双方矛盾和解的前提。但现有《著作权法》从文本上看对生成式AI 大规模使用他人数据的行为仍持一种抵触态度,其规定更加偏向于著作权人一方。具体表现为,生成式AI 在机器学习中稍有不慎就会触碰到“个人利益”的边界(如前文所提到的具体侵权风险),若只是机械地保护原作者的权益,显然不利于该技术在“公共利益”方面带来的效益,有悖于“利益平衡原则”。所以有必要对利益平衡的双方价值重新进行考量,避免因版权或成本问题使得生成式AI 缺少成长的养分而引发“算法歧视”“非法剽窃信息”等恶劣行径。故相比于法定许可制度的“等价交易”方式,在当下生成式AI 的“发展起步阶段”合理使用制度的免费使用属性更有利于“私人利益”与“公共利益”之间达成平衡。
当然,合理使用制度也存在着缺陷,一方面,《著作权法》第二十四条第十三项关于合理使用的兜底条款仍然存在问题。因为其规定的是“法律法规规定的其他情形”,这一前置条件使得合理使用的范围急剧缩小,只有在其他法律法规中确定了相关合理使用的条款时,才可以适用第十三项的要求并结合三步检验法进行判断。而我国目前法律法规中具有相关规范的数量较少,26. 参见高阳、胡丹阳:《机器学习对著作权合理使用制度的挑战与应对》,载《电子知识产权》2020年第10 期,第13-25 页。且都是依照《著作权法》中的合理使用内容做出的相似规定,如果没有在后续新颁布的法律法规中满足生成式AI 机器学习的这种“其他情形”,就会陷入“先有鸡还是先有蛋”的困境,故只依靠这些重复内容来进行判断无法达成目的。另一方面合理使用制度无论再怎样设定倾向于著作权人的条款在本质上都是侵害其著作权的。不但原作者的复制权、改编权、传播权等均有被侵权的风险,且依靠其作品产出的产品一定程度上还会对原有作品产生替代作用,会极大地损害著作权人的合法权益,消磨其创作的热情。不但不利于我国文化市场的长期稳定发展,还会反作用到人工智能领域,使得人工智能开发企业陷入无素材可用的尴尬境地。
七、结论
当前大模型竞争时代,在各界呼吁平衡人工智能产业发展与著作权保护之时,亟待探索化解机器学习中的著作权风险的最优路径。虽然法定许可无论从长远发展,还是合理性上均优于合理使用制度,但是现阶段尚不具备实践基础。知识产权制度的工具属性与利益平衡宗旨,使其天然具备利益衡量下的社会总体福利最优路径选择。合理使用路径便是当下人工智能发展战略下的最优解,欧盟的选择亦是如此。未来,待区块链技术发展到一定阶段,且我国人工智能产业已奠定良好的竞争基础时,机器学习训练素材的使用规则可以逐渐转向法定许可。
猜你喜欢
中国食用菌(2022年5期)2022-11-21 16:10:34
中国食用菌(2022年1期)2022-11-21 14:23:58
环球时报(2022-07-13)2022-07-13 17:18:39
环球时报(2022-03-14)2022-03-14 18:19:44
商界(2019年12期)2019-01-03 06:59:05
IT经理世界(2018年20期)2018-10-24 02:38:24
电影(2018年8期)2018-09-21 08:00:06
小康(2017年16期)2017-06-07 09:00:59
南风窗(2016年19期)2016-09-21 16:51:29
小猕猴智力画刊(2015年4期)2015-04-28 23:55:53
