
算法透明的法律实现与限定
——基于商业秘密保护的视角
2024-01-12 04:20:14杨莹莹
电子知识产权 2023年11期
文 / 杨莹莹
一、问题的提出
伴随大数据和人工智能技术的发展,以大数据为基础的算法跨越网络和物理空间、跨越公共和私人领域,给社会治理和个人生活带来深刻而复杂的影响。算法在广泛运用于诸多场景的同时,其两面性也逐渐凸显:在积极层面,算法因其理性、客观性、精准性优势为商业领域和公共领域带来了效率。在消极层面,算法因其不透明性、价值非中立性特征使得个人自治价值不断被消解、社会原有秩序价值逐渐偏移和异化。在算法自动化决策背景下,普通个人处于无从知晓、无力掌握的失控局面,自由和尊严无法得到保障。如基于个体偏好预测并迎合的个性化推送使得个体不知不觉中被困于“信息茧房”,单一偏狭的信息摄入阻碍了个体自由的实现;基于效益最大化导向的算法目标设定与康德所言的“人是目的,不是手段”相背离,使得人性尊严的价值内核也逐渐偏离。此外,算法决策以更为隐蔽的方式给社会秩序价值带来了负面效应。其中,以“算法歧视”问题尤为突出。反垄断语境下,算法歧视(如价格歧视)可能造成排除、限制竞争的损害后果,扰乱市场竞争秩序,攫取更多的消费者剩余;平等权语境下,算法歧视屡屡在就业1. See Allan G.King&Marko J.Mrkonich, Big Data and the Risk of Employment Discrimination, Oklahoma Law Review,Vol.68:555, pp.555-584(2016).、金融信贷2. See Danielle Keats Citron&Frank Pasquale, The Scored Society:Due Process for Automated Predictions, Washington Law Review, Vol.89:1, pp.1-33 (2014).等领域中恣意表达性别、身份偏好,在ChatGPT 等生成式人工智能领域中甚至可能会被进一步延续或放大3. David Mhlanga, Open AI in Education, the Responsible and Ethical Use of ChatGPT Towards Lifelong Learning,at https://ssrn.com/abstract=4354422(Last visited on May 21, 2023).。面对深深嵌入生活各个方面的算法自动化决策,社会公众在失去控制权、选择权的状态下,对于技术失范威胁社会公平正义的忧虑也集中指向了算法自动化决策的“不透明”和“缺乏监督”。
既有的算法规制理论体系包含了算法的风险、工具和目标三大部分。4. 周翔:《算法可解释性:一个技术概念的规范研究价值》,载《比较法研究》2023年第3 期,第188 页。如前所述,算法自动化决策可能带来的一系列风险备受关注,对风险进行防范成为算法规制理论建构的共识。对此,不少国家和地区从算法规制目标层面提出了算法透明的要求。在国际层面,以美国和欧盟为代表的国家和地区纷纷探寻算法治理之道,并作出了有益尝试。5. 例如,2018年5月,欧盟《通用数据保护条例》正式生效,第5 条引入了关于个人数据处理应遵循合法、公正和透明性等一般原则,第12 条至第22 条赋予了数据主体新型权利、更为严格地规定了数据控制者和处理者的责任,并针对算法自动决策设置了相关条款。又如,2021年5月,美国《算法公正与在线平台透明度法案》从用户、监管部门和公众三个维度提出算法透明的要求;2022年2月,美国民主党参议员提出《2022年算法责任法案》,该法案提出了酌情报告或披露算法等信息的一系列要求,是美国关于算法治理专门立法的一次重要探索。在国内层面,我国2021年11月施行的《中华人民共和国个人信息保护法》(以下简称《个人信息保护法》)回应社会关切,就个人信息处理公开、透明作出了原则性规定。2022年3月施行的《互联网信息服务算法推荐管理规定》(以下简称《算法推荐管理规定》)鼓励优化算法规则的透明度和可解释性。上述法律法规的出台表明了我国规制算法、坚持算法透明的立法态度。尽管算法“应当透明”的问题已在立法中得到体现,但连接“风险”和“目标”的算法透明“工具”,如算法披露和公开、个体赋权等,与商业秘密保护之间的冲突十分引人注目。倘若算法或其部分信息受到商业秘密的保护,这将使得实现算法透明与保护商业秘密二者之间的取舍成为难题。我国现有关于算法透明的规范缺乏系统性构造,与商业秘密保护制度的衔接缺乏协调性,这在一定程度上阻碍了算法透明目标的有效实现。算法透明与商业秘密保护之间的协调,实质上是考量如何在鼓励投资、鼓励创新的背景下,以尊重知识产权、保护私权为前提,引导算法自动化决策透明,同时对行权进行一定限制的利益平衡问题。为了适应对数字经济常态化监管的要求,需要对算法透明工具的整体框架及其限度作出正面回应,就商业秘密保护限制制度进行完善,在现行法基础之上助力算法透明的实现与商业秘密的保护,促进算法生态规范发展。
二、现行法视野下算法透明的展开
算法时代,社会逐渐形成了“资源由算法支配,而算法技术的运用实际上赋予了算法主体权力属性”的结构形态,导致普通个人在算法社会中处于最弱的一角,6. 参见张爱军:《算法政治“三角”关系的构建:稳定性逻辑与可能性建构——以抖音算法为例》,载《天津行政学院学报》2023年第2 期,第45-46 页。在传统治理框架下难以寻求救济。而算法透明是法律回应算法妨害的各种路径中最直接、有效和恰当的方式。7. 汪庆华:《算法透明的多重维度和算法问责》,载《比较法研究》2020年第6 期,第165 页。算法透明不仅具有辅助算法问责和改进算法设计的工具价值,更具有增进算法社会交往、理性与信任,监督算法权力的内生价值,8. 参见安晋城:《算法透明层次论》,载《法学研究》2023年第2 期,第53-57 页。逐渐成为各国和地区算法规制的重要目标。为达至算法透明这一目标,需要一个能使受算法决策影响的个人和社会公众充分了解、理解算法信息的途径,即应披露算法信息。然而,在实务中算法往往被当作商业秘密进行保护,这也致使涉及代码、公式、参数权重层面的算法披露均难以绕开商业秘密的保护区。9. 参见林洹民:《个人对抗商业自动决策算法的私权设计》,《清华法学》2020年第4 期,第130-132 页。如何妥善处理算法透明与商业秘密保护之间的紧张关系成为当下不容忽视的问题。
(一)算法透明目标的现实需求
近年来,从欧盟《通用数据保护条例》《算法问责及透明度监管框架》、美国联邦政府层面的《过滤泡沫透明度法案》《算法公正与在线平台透明度法案》《2022年算法责任法案》、英国《算法透明度标准》等,到我国《个人信息保护法》《关于加强互联网信息服务算法综合治理的指导意见》《算法推荐管理规定》等法律文件中,“算法透明”成为了各国和地区规制算法的重要目标,这既反映了国际算法治理立法趋势,也体现了算法透明化的现实需求。
1.算法透明是“算法生态”规范发展的重要前提
将算法透明作为算法治理的目标,其直接原因是算法的复杂性和不可知性为掩盖算法妨害提供了天然保护屏障,而算法透明旨在为审查或检验是否存在算法妨害提供助力。当算法设计者或使用者刻意为算法披上“不可知”的外衣,因果关系的隐藏或复杂化隔绝了社会公众的感知,极易导致算法相对人合法权益受损以及作为法治基石的问责机制失灵。10. 参见衣俊霖:《数字孪生时代的法律与问责——通过技术标准透视算法黑箱》,载《东方法学》2021年第4 期,第82 页。正如阿里尔·扎拉奇和莫里斯·斯图克所言,普通个人在面临算法自动化决策时就好比“楚门的世界”中一样,处于被人为操控并精心设计好的舞台中却不自知,而最大的受益者是亲手打造并编制这个虚拟世界的制作人。11. 参见【英】阿里尔·扎拉奇、【美】莫里斯·E·斯图克:《算法的陷阱:超级平台、算法垄断与场景欺骗》,余潇译,中信出版集团 2018年版,第40 页。提高算法透明度能够让社会公众或算法监管机构了解算法是如何工作的,是否存在算法妨害风险,进而保护算法相对人的合法权益和社会公共利益。例如,当算法的不当利用带来了对消费者、市场竞争秩序的潜在损害,算法透明有助于识别算法歧视、算法共谋,为执法机关在反垄断案件中获得证据。因此,为规范算法权力的正当行使,算法透明成为重要前提。
2.算法透明是“信任生态”系统构筑的核心枢纽
信任是社会交往和理性发展中不可或缺的基石,算法透明度的缺乏会削弱个体对算法技术、数字市场的信任。算法透明与算法信任是正向关系,尤其对于社会个体而言,实现算法透明是维系算法信任的核心枢纽。以大数据为基础的算法自动化决策并非一个全然与价值无涉的中立过程,而是蕴含着特定的价值判断。数据、算法设计和结果均有可能对算法自动决策结果产生错误或歪曲的影响。12. SeeSolon Barocas & Andrew D Selbst, 'Big Data's Disparate Impact, California Law Review, Vol.104:671, p.680(2016);James Grimmelmann & Daniel Westreich, Incomprehensible Discrimination, California Law Review Online, Vol.7:164, pp.164-177(2017).“算法歧视”“算法合谋”“信息茧房”等问题层出不穷,在引发人们对算法黑箱问题担忧的同时,也逐渐使人们产生了“算法厌恶”(algorithm aversion),这会导致人们在信任受损后主观上更加抗拒算法自动化决策,最终不利于算法经济的长期发展。因此,提升算法透明度使受算法影响的个人有机会知晓个人数据自动处理的逻辑,有助于提升其对算法自动决策的掌控感,弥合算法主体与普通个体之间的“数字鸿沟”,进而维系算法信任、间接预防算法设计目标偏离。
3.算法透明是既有路径的有益补充
面对算法妨害,不论是个人还是社会整体,在现有法律框架下均难以寻求救济。
从受算法影响的个体来看,既有民商法制度框架下的合同效力制度不能对实体不公平本身提供救济;违约请求权无力回应自动化决策相对人知晓具体算法决策理由的诉求,即便是不利的自动化决策,在受到侵权责任的过错、因果关系等构成要件的多重限制的情况下,也难以满足侵权责任之构成要件;13. 张凌寒:《商业自动化决策的算法解释权研究》,载《法律科学(西北政法大学学报)》2018年第3 期,第 66-68 页。在消费者权益保护制度下,我国《消费者权益保护法》并未明确将“算法歧视”纳入规制范围,消费者可依据的仅有该法第8 条“知情权”、第9 条“自由选择权”以及第10 条“公平交易权”。然而,基于算法的法律定位仍为企业的工具而非商品,消费者知情权无法提供真正的算法解释。14. 张凌寒:《商业自动化决策的算法解释权研究》,载《法律科学(西北政法大学学报)》2018年第3 期,第 66-68 页。此外,由于算法社会算法主体与消费者信息占有不对称,加之头部互联网企业对消费者的锁定效应,消费者的自由选择权在客观上表现为一种转向困难下的主观不能。
从受算法影响的社会整体来看,尽管我国《反垄断法》第9 条明确规定经营者不得利用数据和算法、技术、资本优势以及平台规则等从事本法禁止的垄断行为,但适用反垄断法规制个性化定价算法的滥用需要证明具有市场支配地位的经营者利用数据和算法向不同消费者收取了歧视性的价格,同时该行为对于市场还存在反竞争的损害效果。15. 参见周围:《人工智能时代个性化定价算法的反垄断法规制》,载《武汉大学学报(哲学社会科学版)》2021年第1期,第118 页。而个性化定价在竞争损害上又具有复杂性和模糊性,无论是执法部门,抑或是受到歧视性对待的最终消费者,在实际案件中都将承担较高的举证难度。
简言之,由于算法决策负面效应的核心根源离不开“算法黑箱”问题,而现有法律框架在应对算法妨害时具有局限性。因此,面对算法黑箱滋生出的算法权力,亟需算法透明缓解信息不对称、规范算法应用实施,促进个人自治、社会公平正义价值的实现。
(二)算法透明工具的核心构造
如何设计算法透明工具以化解算法自动化决策风险、实现算法透明的目标,是既有算法规制理论中争议最大也是最困难的部分。对此,学界已有部分研究成果,并就算法透明工具作了初步梳理。16. 如有学者提出算法透明是算法事前规制的代表,指的是“要求算法主体(设计者或使用者)打开算法黑箱,将与算法运作原理、算法决策过程有关的信息或公之于众,或报送主管部门。”参见李安:《算法透明与商业秘密的冲突及协调》,载《电子知识产权》2021年第4 期,第26 页;有学者进一步概括了算法透明包含的内容,“算法透明具体包含着从告知义务、向主管部门报备参数、向社会公开参数、存档数据和公开源代码等不同形式,算法解释权也可以看成是算法透明原则的具体化体现。”参见汪庆华:《算法透明的多重维度和算法问责》,载《比较法研究》2020年第6 期,第166 页。既有关于算法透明工具的研究虽各有侧重,但总体而言可以归纳为以下两类:一是限权型工具,主要从算法权力范围、正当程序、问责机制等方面进行制度设计,以制约算法权力、防止算法权力异化。例如,限制算法的应用条件与范围、建立算法标准化、实行算法参数备案、进行算法影响评估、开展算法合规审计等。二是赋权型工具,即从私法的角度赋予用户一定的民事权利以实现与算法主体之间的平衡,主要包括赋予数据主体算法解释权(也有学者从义务角度出发,指出我国现行法实际规定了相关主体的算法解释义务17. 参见吕炳斌:《论个人信息处理者的算法说明义务》,载《现代法学》2021年第4 期,第90-92 页。)、知情权以及理解权等。在实现算法透明的工具设计中,不论是限权型工具还是赋权型工具,都将可能涉及一定算法信息的公开披露。尤其是其中被视为算法治理制度核心的“算法解释权”,18. 参见张欣:《算法解释权与算法治理路径研究》,载《中外法学》2019年第6 期,第1426 页。与商业秘密之间的矛盾最为尖锐。以下将主要围绕算法解释权的基本构造展开。
学界有关算法解释权的研究几乎都以欧盟《通用数据保护条例》(GDPR)为基础样本,其中第22 条以及背景序言第71 条更是被多数学者视为“算法解释权”的经典条款。在某种程度上,GDPR 首次为个人引入了解释权,以便在面对算法自动化决策时获得“对相关逻辑的有意义的解释”。19. See Riccardo Guidotti, et al., A Survey of Methods for Explaining Black Box Models, ACM Computing Surveys (CSUR),Vol. 51:1, p.2(2018).虽然GDPR 并未明确提出“算法解释权”概念,但有学者结合第22 条和序言第71 条,将算法解释权总结为“当自动化决策的具体决定对相对人有法律上或者经济上的显著影响时,相对人向算法使用人提出异议,要求提供具体决策解释,并要求更新数据或更正错误的权利。”20. 张凌寒:《商业自动化决策的算法解释权研究》,载《法律科学(西北政法大学学报)》2018年第3 期,第68 页。与之相似的是,我国《个人信息保护法》第24 条同样采用了赋予数据主体权利对抗算法自动化决策的立法范式。针对个人信息处理者利用个人信息进行自动化决策的情形,《个人信息保护法》第24 条强调决策的透明度和结果公平、公正,并且规定了“对个人权益有重大影响”下的解释说明义务。实际上,这也是对《民法典》第1035 条要求个人信息处理者必须满足“公开处理信息的规则”和“明示处理信息的目的、方式和范围”这两项前提条件的重申。此外,《算法推荐管理规定》针对信息服务提供者推荐算法的使用场景,为算法推荐服务提供者设置了算法解释义务,该规定第15 条第3 款设置了用户的算法解释请求权及其他相关请求权,其中的“说明”可以被理解为算法解释。21. 苏宇:《优化算法可解释性及透明度义务之诠释与展开》,载《法律科学(西北政法大学学报)》2022年第1 期,第140 页。在算法推荐场景下,此处为算法推荐服务提供者设置解释义务还包含了对“运行机制”的解释,已然超越了一般告知义务,即仅就“处理目的、方式和范围”进行告知的要求,体现了在算法应用场景下更高的解释义务要求。总体而言,鉴于我国个人信息处理者和算法使用者往往与平台企业高度重合的实际情形,我国将算法透明目标内嵌于平台治理框架之中,通过在平台应用场景中为个人信息处理者、算法使用者设置解释说明的义务以保护用户知情权、实现算法自动化决策的透明化,形成了围绕个人信息保护对算法自动化决策进行规制的法律框架。
结合现行法和既有研究,算法解释权主要有以下几方面特征:其一,就算法解释权的性质来看,应当属于请求权的范畴。22. 解正山:《算法决策规制——以“算法解释权”为中心》,载《现代法学》2020年第1 期,第180-181 页。实质上,算法解释权可以理解为一种工具性权利,同时也具有目的性权利的特征。前者是指该权利更多情况下是算法相对人保障自身权益的一种手段,算法相对人通过算法解释权获取信息是为了采取进一步的法律行动,如当人格尊严、人身财产安全等利益受到侵害时,以及时对算法主体提起诉讼等;后者是指算法相对人知情权的行使仅仅是为了可主动明晰个人信息如何被处理、使用,是个人隐私权的自然延伸,即数据主体对数据处分、控制的权利。23. 参见王聪:《“共同善”维度下的算法规制》,载《法学》2019年第12 期,第76 页。其二,就算法解释的具体内容来看,学界探讨的算法解释内容包括决策系统的逻辑、意义、设想后果和一般功能以及具体决策的基本原理、理由和个体情况;或者包括决策过程中所使用的数据、代码、决策目标、结果、合规情况、利益冲突情况、数据使用方法等信息。24. 胡小伟:《人工智能时代算法风险的法律规制论纲》,载《湖北大学学报(哲学社会科学版)》2021年第2 期,第124 页。其三,就算法解释的标准来看,大体分为形式性标准和实质性标准。对于形式性标准,学界大体无争议,即应当以“易见、易懂、易读”的方式提供;对于实质性标准,学界尚未达成共识。有观点认为,应以相关性和相对人的可理解性作为算法解释的标准。25. 张凌寒:《商业自动化决策的算法解释权研究》,载《法律科学(西北政法大学学报)》2018年第3 期,第72 页。其四,从算法解释的启动时机和前提来看,多数观点认为算法解释权应在事后启动,前提应当限定在对用户个人有重大影响的情况。
算法解释权是个人数据保护理论下的自然延伸,是算法经济下信息不对称的典型“纠正”手段,为个人防御算法侵害提供了权利武器,对于从源头端防治算法错误、算法歧视、算法标签等算法侵害无疑具有重要意义。
(三)算法透明实现的法律阻碍
为达至算法透明这一目的,需要一个能让受算法决策影响者和社会公众充分了解、理解算法信息的途径,即披露算法信息。然而,由于涉及代码、公式、参数权重层面的算法披露均难以绕开商业秘密的保护区,26. 参见林洹民:《个人对抗商业自动决策算法的私权设计》,载《清华法学》2020年第4 期,第130-132 页。故而,商业秘密保护制度也成为了具体场景下阻断算法透明化的法律障碍。
在实践层面,算法主体往往选择将算法及其源代码等作为商业秘密进行保护,27. See Sonia K. Katyal, Private Accountability in the Age of Artificial Intelligence, UCLA Law Review, Vol.66:54, p.125 (2019).以维系其在市场中的竞争优势。从对算法保护的现实需求来看,由于专利须以公开技术方案换取保护,故而“商业秘密是专利权常用的替代制度”。28. 参见【美】理查德·A·波斯纳:《法律的经济分析》,蒋兆康译,法律出版社2012年版,第54 页。从市场竞争的角度来看,算法的经济价值取决于其保密性,算法开发者也具有内在动力去保持算法的复杂性和晦涩性,从而避免公开带来利益受损的风险。商业秘密制度作为技术保护的重要私法制度,将算法作为商业秘密进行保护有利于防止其他竞争者的搭便车行为。29. 参见孙建丽:《试论算法的法律保护模式》,载《电子知识产权》2019年第6 期,第43 页。
在法理层面,从劳动价值理论来看,算法是算法主体的私有财产,算法研发、运用过程所汇聚的大量人财物力投入需要相应的权利(益)保护。提升算法透明度的同时需要对合法的私有财产予以充分尊重。若法律强制对算法开发者或使用者施加充分公开和完全透明的解释义务,这不仅与劳动价值理论相悖,也可能会阻碍算法技术的研发,抑制算法应用的创新和发展。从商业秘密的构成要件来看,商业秘密是一种无形的信息财产,具有秘密性、价值性和保密性三个要素。而商业秘密的“秘密性”在权利存续期间应当是一种持续状态,并由权利人的“保密性”措施来维系,30. 参见吴汉东:《试论“实质性相似+接触”的侵权认定规则》,载《法学》2015年第8 期,第69 页。若完全的算法透明必然会破坏商业秘密的“秘密性”从而损害权利人的合法利益。因此,基于商业秘密的特性,算法及其所涉数据等信息的商业秘密保护将对算法披露和说明构成实质性的限制。
在立法层面,我国也已明确将算法作为信息技术纳入商业秘密保护的范畴,31. 参见《最高人民法院关于审理侵犯商业秘密民事案件适用法律若干问题的规定》第一条。并强调保护算法知识产权的重要性。2021年,国家互联网信息办公室、中央宣传部等机关联合发布的《关于加强互联网信息服务算法综合治理的指导意见》中也明确指出,“引导算法应用公平公正、透明可释”同时“保护算法知识产权”,反映了算法透明与知识产权保护的重要地位,即算法透明应以尊重算法知识产权保护为前提。
在司法层面,法院在案件审判过程中也倾向于因商业秘密保护而拒绝公开算法的请求。例如,在日本“Tabelog 算法滥用案”32. 《日本大众点评败诉!因点评系统算法不公平》,https://jp.hjenglish.com/new/p1377640/,最后访问日期:2023年6月23日。中,餐饮店“韩流村”认为Tabelog 平台(与我国的“大众点评网”平台功能类似)下调连锁店评分的算法机制变更属于优势地位的滥用,要求Tabelog平台公开点数计算的算法,但法院以算法为商业秘密为由驳回了公开算法的请求。在“Viacom 诉YouTube 案”33. Mark MacCarthy,Standards of fairness for disparate impact assessment of big data algorithms, Cumb. L. Rev, Vol.48:67(2017).中,尽管审查计算机源代码是判断YouTube 搜索功能算法是否存在提升排名等不正当行为的唯一解决方案,但是法院仍以保护商业秘密为由拒绝了原告强制披露被告计算机源代码的请求。在事关个人自由的刑事司法背景下,算法的商业秘密保护障碍尤为显著。在“美国威斯康星州诉Loomis 案”34. See State of Wisconsinv. Eric L.Loomis, 881 N.W.2d749 (2016).中,Loomis 质疑由COMPAS(犯罪累犯风险预测模型)所计算刑期的合法合理性,认为该模型含有强烈的种族偏见,并请求公开解释算法,但法官将COMPAS 算法视为商业秘密,驳回了对算法进行解释的请求。纵观我国现阶段涉及算法披露诉求的案例,我国法院也将算法认定为商业秘密进行保护。例如,在“亿桐公司与百度公司服务合同纠纷案”35. 参见北京市第一中级人民法院(2023)京01 民终2697 号民事判决书。与“陈鱼与阿里妈妈公司服务合同纠纷案”36. 参见杭州铁路运输法院(2017) 浙 8601 民初 3306 号民事判决书。中,法院均以保护算法商业秘密为由拒绝披露具体算法的请求。以上类似情形,不胜枚举。
综上所言,算法透明成为规制算法的重要目标具有其客观现实需求,但算法透明,特别是其核心工具——算法解释权,与商业秘密保护形成强烈对抗。如何解决冲突双方均主张各自权利的对峙局面成为当下不容忽视的重要命题。
三、“调和论”视角下算法透明与商业秘密的利益平衡
西方传统思想认为,所有善可以相互包容并且共存,但英国哲学家以赛亚·柏林提出,“善”与“善”之间不可相容、不可公度。37. 参见梁上上:《异质利益衡量的公度性难题及其求解——以法律适用为场域展开》,载《政法论坛》2014年第4 期,第3 页。算法透明与商业秘密保护之间即存在难以避免的冲突,具体体现为法律利益之间的冲突,其解决之道在于衡量二者之间的冲突利益并寻求利益的平衡。依照传统思路,充分的利益解构是利益衡量的必要前提,而利益衡量则是利益解构后的必然延续。利益位阶法下,衡量是否能够阻却商业秘密保护实现算法透明化,实际上就是寻找算法透明背后是否具有更高位阶的利益予以优先保护。本文基于横向解构与纵向衡量后认为,算法透明与算法商业秘密保护之间并不存在普适性的理由使前者凌驾于后者之上。因此,算法透明的实现需要转向“调和”视角,即彼此让渡一定非核心利益以达至整体利益最大化。
(一)利益的横向解构与纵向衡量
按照不同的分类标准,利益可以呈现为多元多层次的样态,既存在同质利益之间的衡量,也存在异质利益之间的衡量。大体而言,可以将利益衡量分为横向和纵向两个维度。横向维度基于事实进路展开,需要对所涉利益结构进行充分的解构分析;纵向维度基于规范进路展开,需要对所涉利益进行价值判断、衡量利益重要性差异。
1.冲突利益的横向解构
从横向衡量的维度来看,将算法透明与算法商业秘密所涉利益按照主体进行横向划分,可以分为个人利益以及公共利益。其中,个人利益又分为算法主体个人利益和算法相对人个人利益。
算法主体个人利益与算法相对人个人利益之间的冲突,集中表现为商业秘密保护与算法解释权的冲突。图1 所示为算法主体个人利益与算法相对人个人利益的冲突关系,总体呈现为一个平面的利益结构图。在这个基础的利益格局中,二者之间的利益冲突落在了以算法的完全公开以及算法的完全保密为两端极点的横轴之间,体现了不同个体之间在利益上此增彼减的关系。算法相对人主张算法透明,即通过算法解释权获得算法相关信息以维护自身合法权益;而反对披露算法相关信息的算法主体则基于商业秘密保护的目的希望算法“不透明”。商业秘密在这层冲突关系中成为了算法主体的“利益放大器”,而利益“放大”导致的冲突后果极易导致算法相对人个人利益的“缩水”。

图1 算法主体个人利益与算法相对人个人利益的冲突关系
算法主体个人利益与公共利益之间同样会发生利益冲突。迈入数字时代,算法已然成为对社会生活产生整体性影响的关键资源。过度的商业秘密法律保护将间接对社会公众获取重要信息造成一定阻碍,影响社会监督算法决策的合法性,难免招致公共安全风险,损害公共利益。图2 所示为算法主体个人利益与算法相对人个人、社会公共利益的冲突关系。在图1的基础上加上了公共利益之后,可以看到,算法透明背后蕴含着民主、自由等深层价值,从总体上看,这与算法主体利益——保护商业秘密以维持竞争优势,构成一个二维平面的利益结构图。而在算法公开还是不公开的博弈中,公共利益衡量成为了改变基础利益关系的重要砝码,当公共利益向公开的方向倾斜时,成为影响算法公开的最主要的因素。
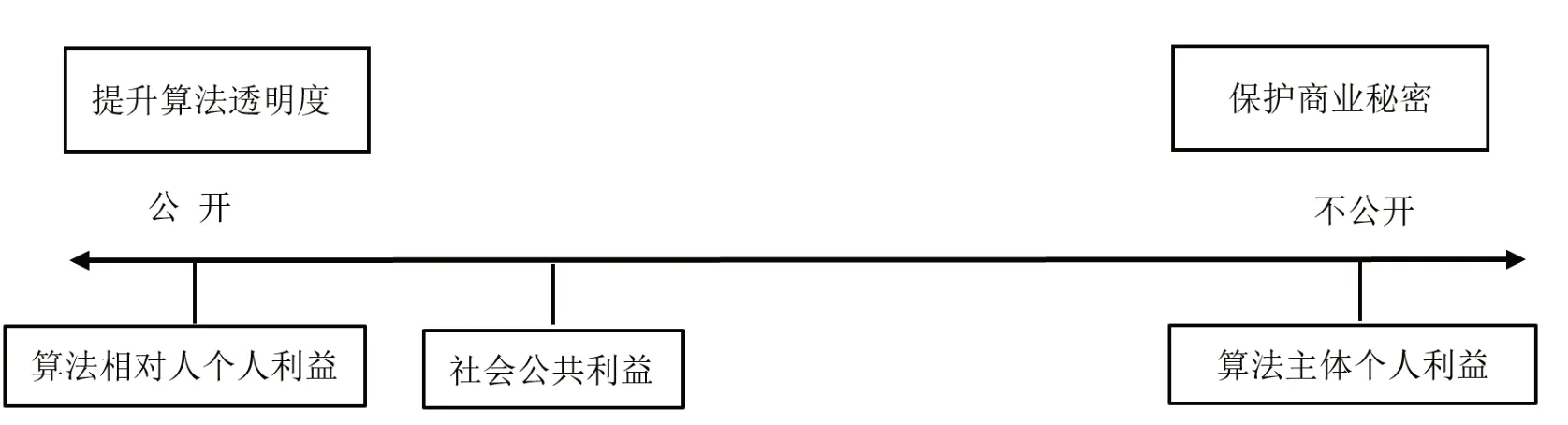
图2 算法主体个人利益与算法相对人个人、社会公共利益的冲突关系
2.冲突利益的纵向衡量
根据通常的思维惯性,当利益之间发生冲突时会将所涉利益性质进行对比,分析是否存在某种利益应当被优先考虑,即确定利益位阶。在权利的体系中,权利位阶的存在基本上是一个不争的事实。但是,从权利位阶视角出发,在此区域内算法主体与算法相对人、社会公众之间冲突关系的衡量难以直接得出普适性结论。
从表面上看,较之于知识产权保护,保护个人的隐私与数据权益似乎更为重要,因为它们关乎个人的自主及尊严。38. 解正山:《算法决策规制——以“算法解释权”为中心》,载《现代法学》2020年第1 期,第191 页。但更进一步来看,当算法上存在商业秘密时,基于一般道德理由或法律理由的算法解释权能否构成对商业秘密的一种强制衡,还有赖于在具体场景中的论证。受算法所影响的法益可能包括关乎人的尊严和自由等较高位阶的人格利益,但这并不意味着在所有具体场景下可以在商业秘密这一财产利益面前占据绝对优势,因为对算法的保护和自由利用也可以促进这些利益的保护。因此,当两种权利(益)形成实质对峙时,算法解释权并非当然能够形成制约商业秘密的优势理由。
公共利益也同样难以成为公开算法商业秘密的绝对理由。有学者认为,在特定情形下公共利益的分量可以否定算法的商业秘密保护,39. 陈景辉:《算法的法律性质: 言论、商业秘密还是正当程序?》,载《比较法研究》2020年第2 期,第127 页。商业秘密应让位于代表公共利益的算法解释规则。40. See David S. Levine, Secrecy and Unaccountability: Trade Secrets in Our Public Infrastructure, Florida Law Review,Vol.59:135, pp.135-163(2022).诚然,公共利益作为法治社会的基本理念,是整个社会和谐发展的根本价值,可以构成对民事权益的限制。但是,缘于公共利益本身的复杂性和高度抽象性,在对民事权益进行限制的时候应当谨慎适用。另外,公共利益具有普遍性和形式多样性,算法商业秘密可能出现公开还是不公开其背后都涉及公共利益的情形。可以发现,虽然算法所涉及的利益主体既包括个人也包括社会公众,但同时,算法主体的个人利益同样也会与公共利益之间形成紧密关联。由于算法广泛内嵌到社会的各个领域,算法商业秘密保护背后也蕴含着相应的深层制度价值——鼓励企业技术研发和创新、提升社会整体创新能力、维护公平竞争的商业秩序、促进数字市场经济的健康发展、构建更高水平的对外开放格局等。如果算法规制负担过重,将可能导致商业秘密权利人创新热情的积极性严重减退,同时造成数字产业发展上的不利局面。因此,算法透明与算法商业秘密保护的对局转化为了不同公共利益之间的衡量。在这种情况下,仅仅依靠公共利益优先原则显然无法解决问题。
(二)“调和论”的引入与展开
利益之所以“衡量”,并非因不同利益之间存在位阶权重差异而需要对其“排序”,这种“排序”不是“衡量”,是确定利益的优先性,属于“冲突论”的解决思路。“衡量”之原因在于需要在无法比较权重位阶的情形下,考虑如何采取“衡平”的方式使利益得到恰当保障。41. 蔡琳:《论“利益”的解析与“衡量”的展开》,载《法制与社会发展》2015 第1 期,第146 页。这种衡平观就是“调和论”的体现。换言之,作为调和论解决方案的“衡量”,并非是权衡利益的相互排除,而是以“利益保障的最大化”为目标。42. 蔡琳:《论“利益”的解析与“衡量”的展开》,载《法制与社会发展》2015 第1 期,第147 页。“调和”有利于将价值冲突引向一种相互协作、助益下达成的实质正义。
以“调和”方式平衡算法透明与算法商业秘密之间的利益具有必要性。若仅通过利益位阶的纵向衡量去解决利益冲突,其效用是有限的。因为利益位阶的判断本质上是价值判断,往往难以具备完整的客观可能性。如上所述,算法透明与算法商业秘密保护之间的利益结构实际上并不是单纯的平面利益格局,而是存在多重对立关系的复合式立体格局。从这一立体结构关系来看(如图3 所示),算法透明与商业秘密保护均承载着社会公共利益。因此,二者之间的利益“衡量”并不再是可见的物质利益之间的比较,而是原则、价值、或是“理想利益”之间的“衡量”,43. 蔡琳:《论“利益”的解析与“衡量”的展开》,载《法制与社会发展》2015 第1 期,第148 页。即实质上是两种不同制度内生性利益之间的衡量,并外化为具有冲突关系的两个层级的对立利益:第一个层次,算法决策正义和法的安定性。公开算法,有利于提高对算法的监督,有益于保障算法决策正义。但是算法公开必然涉及法的安定性利益,如果过度公开,就会挫伤算法主体的创新积极性、损害公平竞争的市场经济秩序。第二个层次,在促进算法决策正义这一根本目标下,“公开”和“不公开”之间仍然需要进行考量。公开算法是为了个人能够维护个人权益、避免遭受算法歧视;不公开算法则是为了避免公开而引起个人隐私泄露、算法算计。故而,需要分别在两个双层对立关系中找到有利于实现算法透明与算法商业秘密保护利益平衡与总体最大化的“中间值”,将利益衡量视为指引性的价值原则,转向更加合理的“调和”思路。
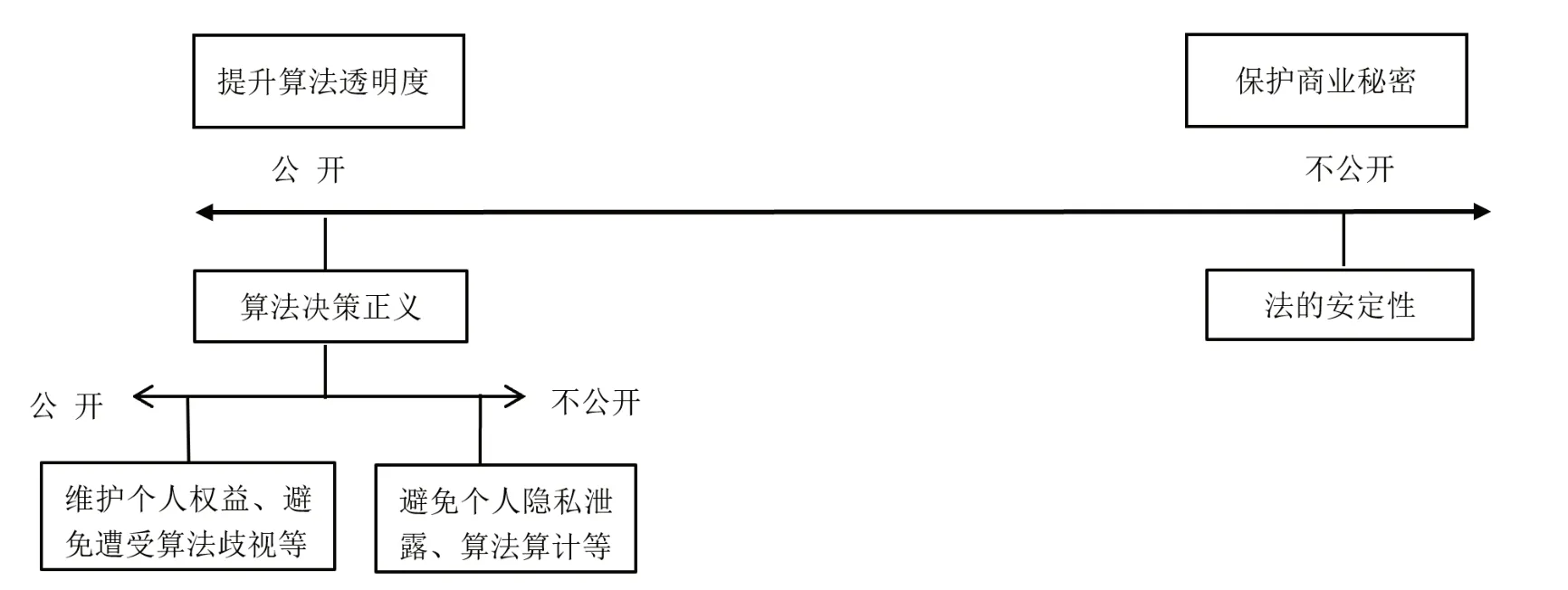
图3 算法透明涉及的利益关系
以“调和”方式平衡算法透明与算法商业秘密之间的利益具有合理性。算法系统运作具有技术封闭性,其技术细节封装于黑箱之中又具有天然的秘密性。算法透明固然要以保护商业秘密这一私权为前提,但若是以商业秘密保护之由全然拒绝算法解释,无疑会造成规则隔音进而产生一定的负面效应,导致事后问责无从谈起。首先,商业秘密保护缺乏明确的边界,也不像权利化的著作权、专利权那样存在法定的限制和例外,从而缺乏明确的权利保护的平衡机制,需要在个案中进行利益衡量。其次,商业秘密缺乏也不可能具有公示制度,故而号称受到商业秘密保护的算法到底能否构成商业秘密,旁人无从得知。再次,算法的商业秘密保护实际上为算法主体提供了强力抗辩理由,可能会对企业形成过度保护,以致纵容怀有不良动机的使用者利用算法侵害社会公众和其他竞争者的合法权益。44. 参见孙建丽:《试论算法的法律保护模式》,载《电子知识产权》2019年第6 期,第39-47 页。因此,需要在“调和论”的指导下,使“二者在某一程度上必须各自让步”。45. 【德】卡尔·拉伦茨:《法学方法论》,陈爱娥译,商务印书馆2003年版,第279 页。
以“调和”的方式平衡算法透明与算法商业秘密之间的利益具有可行性。虽然算法主体与算法相对人、社会公众实现利益的方式存在矛盾甚至对立,但这种“对立”也并非绝对的不可调和。算法透明与商业秘密保护在数字经济背景下具有共同的根本目标,即二者的内核均在于促进算法经济的高质量发展,这为达成利益的衡平具有相当的可行性,是达至平衡状态的内在根基。市场经济的繁荣离不开经营者的创新和发展;反之,经营者利益的保障也离不开透明、公平、公正的市场经济环境。因此,在“调和论”视角下,算法透明与算法商业秘密之间的利益协调应以实现算法透明与算法经济高质量发展为根本目标,让渡非核心利益作为他方实现其核心利益的条件和基础。一方面,为保障有效的算法监管和问责,应在尽可能减少对算法主体商业秘密利益损害的基础上实现算法透明;另一方面,为维护市场竞争秩序以及提供创新激励,应在尽可能减少对算法相对人和社会公共利益负面影响的基础上保护算法商业秘密。
四、迈向利益平衡的算法透明化路径构思:适当的透明
算法透明最终能否合理落地,能否与商业秘密保护之间保持动态平衡,与算法解释的范围和程度具有直接关联。算法解释所涉算法技术内容各异,“一刀切”式过度“透明”或“保密”极易导致算法透明与商业秘密保护之间动态博弈的结果失衡,难以实现算法正义。为平衡算法透明与商业秘密保护,需要从方法论角度对算法解释框架进行重构。算法解释可以遵循分类分级的整体布局以及比例原则下的个案认定,构筑算法解释的差序规制格局,进而实现总体的解释效率和个案的解释正义。与此同时,进一步建立健全多元算法监督机制,实现适当的透明。
(一)算法解释的体系化构建
算法分类分级旨在对不同性质的算法决策可能引发的风险进行程度区分,并设置与之相适应的算法解释义务。分类分级所具有的多层次结构区隔了不同性质和不同风险程度的算法决策,有利于合理划分解释范围和精准匹配监管资源,是平衡“透明”与“保密”的有力工具。然而,分类分级仅能就算法决策的共性作出初步指引,具有一定的静态性和模糊性。算法正义最终需要在个案中实现,在个案认定中遵循比例原则具有动态性和灵活性,从而可以避免算法主体的解释义务超出合理范围,保障算法解释权有效实现的同时防止对商业秘密造成侵害。
1.整体解释框架:算法解释分类分级
分级分类监管、精准精细施策的立法思路已经在国内外立法中广泛呈现。例如,欧盟GDPR 较早提出基于算法应用风险的治理路径,同时还对算法决策类型进行了划分,即分为完全基于自动化和非完全自动化类型。随后,欧盟在《人工智能法案》中基于不同等级的风险提出了分级分类治理框架。46. 《人工智能法案》以对健康、安全和权益的影响程度为划分标准,将人工智能系统评估后划分为最小风险、有限风险、高风险和不可接受风险四个等级,并对各等级施以差异化监管。就我国立法而言,2021年9月发布的《关于加强互联网信息服务算法综合治理的指导意见》首次提出了“算法分级分类安全管理”的概念。随后,我国《算法推荐管理规定》也明确指出建立算法分级分类安全管理制度,第2 条第2 款将算法推荐技术从横向分为五大类,47. 《互联网信息服务算法推荐管理规定》第2 条第2 款规定,“前款所称应用算法推荐技术,是指利用生成合成类、个性化推送类、排序精选类、检索过滤类、调度决策类等算法技术向用户提供信息。”第24条、27条区分出了“具有舆论属性或者社会动员能力”的算法推荐服务提供者。此外,该规定还结合算法推荐技术处理的数据重要程度、用户规模和对用户行为的干预程度等进行了制度设计。综观上述规范,算法分类分级监管思路在确保算法经济效率、精准匹配监管资源以及引导算法透明上具有重要意义。但在强化算法透明背景下存在以下不足:一是分类分级标准过于单一、范围过窄,如《算法推荐管理规定》仅在“算法推荐”的应用场景之下对算法推荐服务提供者加以分类分级,而非针对具体的算法应用,由此可能导致难以实现算法监管的根本目标。二是缺乏制度衔接,该规定所列举的“具有舆论属性或者社会动员能力”的算法推荐服务提供者,仅就事前安全评估、备案等程序上与其他算法推荐服务提供者的义务有所区分。换言之,在事后的算法解释义务上,所有的算法推荐服务提供者并实质无差别。不加区分的规范设计将不利于与商业秘密保护制度相衔接。
本文认为算法解释框架的构筑可以延续算法分类分级的规制思路,并在此基础上进行细化设计。一方面,可依据算法的性质进行横向分类,如图4“横轴”所示,算法由最左端的辅助性工具逐渐发展为完全独立的决策者。另一方面,可以风险层级为基准进行纵向分级。如图4“纵轴”所示,算法决策的风险层级由最下端的“极低风险”不断往最上端的“极高风险”升高。在判断某一特定场景下的算法应用是否可能带来高外部风险时,可结合算法应用的行业、预期风险系数及其对公共安全、公民基本权利和消费者利益的影响程度进行考量。48. 林洹民:《自动决策算法的风险识别与区分规制》,载《比较法研究》2022年第2 期,第199 页。例如,超级平台较之中小平台具有更大的用户规模、经济体量、业务种类,更强的限制能力,算法决策的不当利用更容易对公民基本权利和消费者权益造成更大规模侵害,因而应视为算法应用存在高风险。质言之,横轴代表“分类”,纵轴代表“分级”,横纵交错的两个维度共同将算法解释框架划分为四个象限。

图4 算法解释框架
算法解释背后实质上是不同场景下的价值衡量。是故,需要在“调和论”视角下处理透明价值与商业秘密之间的冲突。在算法决策的潜在外部风险远小于其带来的收益时(象限Ⅲ和象限IV),算法解释权需要作出更多让步,选择替代性方案;而当处于个人权益受到重大影响和社会公共利益受到威胁的高风险领域(象限Ⅰ和象限II)时,算法解释权则不应过多让步。
象限Ⅲ中,算法可能引致的外部风险层级低且在决策中具有较强的辅助性工具价值。在这一区域中算法决策并不直接涉及个人权益,或可能仅在一定程度上影响算法相对人的个人选择。在此情形下,若强制要求对算法进行解释反而会导致算法主体承担过重义务,甚至侵害商业秘密。因此,算法透明的实现可在既有法律体系内进行,无须法律或规范针对算法解释作出专门规定。
象限IV 中,算法可能引致的外部风险层级低但在决策中独立性强。在这一区域中,具有高自主性的算法决策蕴含着复杂的社会互动,“硬法”的局限性和政府监督的有限性无法快速根本预防并解决现有及未来算法黑箱带来的科技伦理问题。因而这一区域的算法透明,一方面,应主要依托“软法”约束,辅以“硬法”加以强化。通过公开披露技术标准这一“软法”透视算法黑箱,提升算法透明度,以缓解用户与算法生产者、使用者之间的信息不对称。另一方面,应充分利用社会监督,使之与监管部门形成合力,提高执法效率。例如鼓励用户社群参与算法治理,通过技术社群的力量识别算法的潜在危害和伦理等问题。
象限II 中,算法可能引致的外部风险层级高但在决策中具有较强的辅助性工具价值。在这一层级中算法自动化决策独立性较弱,外部风险的成因既可能因算法作为侵权工具,也可能基于算法自身。对于前者而言,算法多数情形下是作为平台的工具,平台对算法的运行具有充分的控制能力,对算法自动化决策的结果也有充分的预测能力,因而宜采取“结果导向”“事后追责”的传统监管思路,以避免立法者和司法者过多介入算法运行的内部结构,对商业秘密造成侵害。49. 张凌寒:《风险防范下算法的监管路径研究》,载《交大法学》2018年第5 期,第53 页。对于后者而言,因算法自身导致“对个人权益有重大影响”的算法自动化决策需以“算法解释权”为主要抓手。在该区域内,算法解释权的基本设置以我国现行法的规定配置足矣,即当个人权益受到重大影响时,仅由个人在事后提起解释。但以《个人信息保护法》为法律基础的算法解释权设置过于笼统,尚需出台相关规范予以细化。算法解释权的细化应当以算法解释权的核心目标为起点,以利益平衡理论为导向,明晰算法解释权的权利半径。就此而言,有以下关键问题尚待明晰,一是“对个人权益有重大影响”这一要件的标准为何?首先,需要明确的是,对个人权益是否有重大影响的判断标准应该从严。若行权门槛过低,必然会造成资源的大量浪费、降低经济效率。其次,解释的效用必须与产生解释的成本相平衡,在衡量解释价值时,应当围绕算法解释权的核心指向,不宜过于宽泛。二是算法解释的方式、内容为何?按照学界主流观点以及GDPR 第12 条第1 款要求,算法主体应以“简洁、透明、易懂和易获取的形式”向数据主体提供必要解释。就解释内容而言,尽管对技术的解释是十分重要的,但这不足以实现法律规制的目标,因为实践中多数情况下的解释目的不是为了解释技术本身,而是为了确保有一种途径可以评估算法决策的基础是根据反歧视或正当程序等规范进行的。50. See Andrew Selbst & Solon Barocas,The Intuitive Appeal of Explainable Machines, Fordham Law Review ,Vol.87:1085,p.1105(2018).因此,总体而言,算法主体可以通过反事实解释的方法予以答复,51. See Sandra Wachter,Brent Mittelstadt & Chris Russell,Counterfactual Explanations without Opening the Black Box:Automated Decisions and the GDPR, Harvard Journal of Law&Technology, Vol. 31:841, pp.841-861 (2018).内容原则上应限定为与个人权益紧密相关的算法主体信息和算法的影响等外部信息而不侧重于向用户详细讲解系统的运作细节或整体逻辑。主要包括算法决策所需数据及其类别、权重、相关性解释,以及个人“画像”如何建立、它与决策过程相关性的说明以及是如何被用于涉及个人的算法决策等能够使算法相对人充分理解的信息。52. 解正山:《算法决策规制——以“算法解释权”为中心》,载《现代法学》2020年第1 期,第187-188 页。
象限Ⅰ中,算法风险高且独立性强,旨在实现算法透明内生价值的制度设计更应坚持人的主体性,同时赋予更强的约束力。仅凭借现行单一的算法解释权或政府监管均难以应对。尤其是当市场上的算法与竞争相结合,以及实施默示算法共谋等新型垄断行为时,着眼于自动化决策相对方事后救济的算法解释权构造几乎难以发挥效用,53. 参见刘辉:《双向驱动型算法解释工具:以默示算法共谋为场景的探索》,载《现代法学》2022年第6 期,第59 页。传统反垄断监管对此也显得力有所不逮。因此,需要就现行法下的算法解释权进行扩充改造,但并非仅就算法解释范围的简单扩充,因为这种盲目扩大解释权边界的方式只会使算法透明与商业秘密保护之间的矛盾更加尖锐,却依旧无法得到有效的算法解释。对算法解释权的重构应以多元主体为主导,将解释与审查相结合。具言之,一是,仍然与现行算法解释权相同,当算法决策相对人认为个人权益受到重大不利影响之时,可依法启动算法解释工具。此外,当受算法决策侵害的是大规模群体时,也可考虑参考欧盟GDPR 第80 条第1 款、第2 款规定,由第三方机构代替个人行使救济权利。二是,将启动主体由单一主体扩充为多元主体,即除了算法决策相对人之外,还包含公权力机关。作为算法规制主体的算法监管部门以及司法机关,在日常算法监管执法或者算法司法活动中发现不利的算法决策,可主动启动算法解释工具。三是,根据不同主体调整算法解释要求。面向算法决策相对人,算法解释与象限II 中要求基本一致,即解释的侧重点在于算法决策形成的逻辑以及对算法相对人可能产生的不利影响等局部信息;面向专业人员,解释算法的内容需要深入到模型设计、训练方式以及运行逻辑的具体细节,以便其对算法决策可能带来的风险有更科学的预期和判断。面向政策制定者,解释的侧重点应当更加全面,使其能够从全局进行把握,充分了解数据选取、算法设计运行的逻辑和影响。
总体而言,算法解释的内容应当随着算法决策风险的加强而不断趋于严格。随着算法在决策过程中的主导性不断加强,算法主体的解释义务应当逐步加强,与之相应的算法解释目标不断趋严,算法透明度也应逐步提升。
2.个案认定原则:坚持比例原则
确定在何种程度上针对算法所作出的解释具有法律意义,是关系算法透明与商业秘密保护之间利益平衡的重要砝码。算法透明的程度需在个案中根据比例原则进行判断。可以说,比例原则是“调和论”下的具体体现,其要义在于所采取之手段与所欲达成之目的之间应有适切的关系,54. 【德】卡尔·拉伦茨:《法学方法论》,陈爱娥译,商务印书馆 2003年版,第282 页。即禁止过度的透明或过度的保密。立足比例原则,狭义比例原则要求算法解释权以最缓和的手段来实现算法解释的目的,以减少和避免对商业秘密的侵害。55. 吕炳斌:《论个人信息处理者的算法说明义务》,载《现代法学》2021年第 4 期,第97 页。通过算法解释权提高算法透明度以保护个人权益和社会公共利益,应当符合适当性的要求,即算法解释的程度应当与算法所可能产生的外部风险正相关。同时,还需要将算法解释对算法商业秘密保护造成的负面影响范围控制在最小,应当符合必要性的要求,即算法解释的方式方法应当尽可能保护算法商业秘密。
(二)建立健全多元算法监督机制
鉴于算法应用广泛、形态多样,单一算法解释难以实现算法透明。因此,在对算法解释进行体系化构建的同时,还需要辅以更多元的算法自动化决策规制手段实现算法透明化,将算法解释和算法监管相结合,在不同利益主体、不同制度价值之间寻求平衡。
一是优化经由设计的透明柔性规范。我国《算法推荐管理规定》第12 条提出要求优化可解释性,并列举了优化的对象。但该规定过于笼统,导致对“可解释性”的重视不足。从概念上来看,“解释”在词典中的含义为,赋予概念或者以可理解的术语解释和呈现某些概念。在数据挖掘和机器学习中,可解释性则可被定义为以可理解的术语向人类解释或提供说明的能力。56. Finale Doshi-Velez & Been Kim, Towards a Rigorous Science of Interpretable Machine Learning, at https://doi.org/10.48550/arXiv.1702.08608, last visited on June 24, 2023.故本质上而言,“可解释性”是连接人类和(机器)决策者之间的“接口”(interface)。57. Riccardo Guidotti, et al., A Survey of Methods for Explaining Black Box Models, ACM Computer Surveys, Vol.51:5, p5(2018).算法可解释性攸关模型透明度,对于评估模型决策行为、验证决策结果可靠性和安全性具有重要意义。58. 纪守领、李进峰等:《机器学习模型可解释性方法、应用与安全研究综述》,载《计算机研究与发展》2019年第10期,第 2088 页。就目前的算法解释技术来看,模型预测的可靠性与自动化决策过程、结果的全面留痕之间存在反向关系,即越是具有可解释性的算法模型,则该算法模型的性能则越差。因此,优化算法可解释性的柔性规范应当区分不同场景、不同功能,对于具有高风险、需要重点监管的场景(如司法、医疗、金融等领域),即使牺牲部分模型性能也需要配置更高算法可解释性的规范义务。
二是配置协同治理的中性规范。实践中,尽管在算法设计阶段可以预先优化算法可解释性,例如采用决策树等自解释模型,达成技术上的“可解释性”,或者鼓励企业采用可解释性较强的深度学习算法模型以提升算法透明度。但是,在巨大规模参数和大型多模态模型面前,算法可解释性几乎难以实现。例如,OpenAI 推出的预训练模型(Generative Pretrained Transformer,GPT)在经历技术的飞速迭代后,GPT-4 的参数量预测将达100 万亿。59. ICO, Explaining Decisions Made with AI, at https://ico.org.uk/media/for-organisations/guide-to-data-protection/key-dpthemes/guidance-on-ai-and-data-protection-2-0.pdf, last visited on June 13, 2023.因此,对于此类具有超大规模的深度学习模型,不宜设置算法解释工具,而应转向多元主体协同治理、多元方式并进监管的模式。例如,“为专业性非营利组织和用户社群参与治理创造制度环境,探索符合我国发展特点的协同治理范式,促进社会监督与政府监管的协同联动。”60. 张欣:《生成式人工智能的算法治理挑战与治理型监管》,载《现代法学》2023年第3 期,第118 页。如此一来,可以在一定程度上避免陷入“解释不足”和“解释过度”的两难困境,促使算法受到专业人士和社会公众的监督和控制。
三是强化算法登记备案与定期审核的刚性规范。首先,需要在高风险领域进行严格的市场准入监管,要求就算法模型、算法训练数据集等算法详细属性信息进行备案说明。其次,监管部门应定期和不定期对算法自动化决策的应用情况进行审核,重点关注是否具有利用算法进行排除、限制市场竞争的行为。通过公权介入的形式强化对私权的保护,维护市场竞争秩序,以弥补算法解释这一私权救济机制的不足。最后,还需要求算法主体就算法进行自我检查,并就实施情况的检查的报告进行公开声明,进而在法律范围内受到监督。算法主体在服务过程中所使用的算法应当符合其声明公开的标准的技术要求,如果违反其公开声明的标准就要承担相应的法律责任。
五、迈向利益平衡的算法透明化路径构思:合理的保密
从商业秘密保护制度的本质来看,其“以保密守权益”的特征必然与算法透明之间产生价值冲突。“保密性”并不是商业秘密权利人的避风港,过度的商业秘密保护将会对他人权利和社会公共利益产生不利影响。因此,需要对商业秘密保护的限制制度进行完善。
(一)明确商业秘密内容的“合法性”
作为商业秘密进行保护的算法内容应当具有合法性。我国对商业秘密保护的规定集中体现在《反不正当竞争法》之中,其中关于商业秘密的三大构成要件“秘密性、保密性和价值性”中并未包括“合法性”。从广义范围来看,算法既有可能包括“合法”的算法信息,也有可能包括“非法”的算法信息(例如侵害基本权利、违反反垄断法等信息),而能够受到法律保护的显然只有前者。因为,从法理角度而言,若利用商业秘密的非公开性和保密性的特点将违法、违规、违反公序良俗的信息混同为商业秘密加以保护,以阻碍消费者、公共监督群体监督,这显然违背了立法目的。因此,“合法性”要件对于商业秘密的认定与依法保护不可或缺。从国际性立法文件TRIPs 协议来看,其明确指出受保护的秘密信息应为“合法控制的信息”。这里“合法控制”应当作广义理解,即不仅指的是对秘密信息“控制行为”合法性的要求,而且也强调“秘密信息”本身的合法性。德国的《商业秘密保护法》更是明确要求秘密信息所有人应当对该信息具有“合法的保密利益”。另外,我国《反不正当竞争法》第2 条第1 款有关“遵守自愿、平等、公平、诚信的原则,遵守法律和商业道德”的原则性条款,实质上也是对商业秘密所保护的内容提出了合法、合乎商业道德的要求,可以由此推导出“合法性”是商业秘密的当然构成要件。
相较于专利的审查和对外公开要求而言,商业秘密的“秘密性”和“保密性”决定了其权属状态具有不确定性的特征。对于商业秘密信息本身是否合法、是否真实存在,外界无从得知。为避免司法实践中出现因合法性审查程序不统一而导致审判结果迥异的情形,应当明确将“合法性”作为获得商业秘密保护的构成要件。对于来源不合法以及内容不合法的算法信息,如被用来窃取用户数据、进行纵向和横向垄断、损害他人合法利益等,不应也不能作为商业秘密受到法律保护。
(二)完善公共利益抗辩制度
在商业秘密保护的法律规范中应当明确规定公共利益抗辩规则。为公共利益需要对算法进行一定程度和范围的披露,是平衡社会公共利益与算法商业秘密权利人私益的有效措施。
在比较法上,一些国家在相关制度的构建中也囊括了公共利益抗辩制度的规定。如日本《不正当竞争防止法》中规定“违反公序良俗的信息不予保护”,美国2016年《保护商业秘密法案》第7 条和欧盟2016年《商业秘密保护指令》第5 条都有商业秘密披露的公共利益(揭发违法行为)例外。在国内法上,尽管我国的商业秘密保护制度设计了诸多平衡规则,如独立研发抗辩、反向工程抗辩等等,但我国法律规定中尚未建立商业秘密领域的公共利益抗辩制度。虽然公共利益对商业秘密的限制条款在《环境保护法》第24条61. 《环境保护法》第24 条规定,县级以上人民政府环保部门,有权现场检查排放污染物的企事业单位,要求被检查的对象提供有关排放污染物的数量、成分、浓度等必要的技术资料,相关单位不得以商业秘密保护为由拒绝披露。、《政府信息公开条例》第15条62. 《政府信息公开条例》第15 条规定,对于涉及商业秘密、个人隐私的政府信息,有关政府部门不得公开。但若不公开会造成社会公共利益重大损害或第三人同意公开的,应当予以公开。中有据可循,但由于适用的范围仅限于环境保护和政府信息公开领域,对商业秘密的披露范围有限。在此情形下,实践中法院常引用的仍是《民法典》中的诚信原则等条款。而这种向一般条款逃逸的方式缺乏明确的制度界限,也极易导致法官自由裁判权过大,不利于制度之间的衔接。
近年来,我国已经注意到并考虑将公共利益作为商业秘密保护限制的事由。2020年最高院颁布的《最高人民法院关于审理侵犯商业秘密纠纷民事案件应用法律若干问题的解释(征求意见稿)》第19 条提出了建立商业秘密领域的“公共利益抗辩”制度:“被诉侵权人为维护公共利益、制止犯罪行为,向行政主管部门、司法机关等披露相关商业秘密,权利人主张其承担侵权责任的,人民法院一般不予支持。”但是,在正式通过的《商业秘密司法解释》中将其删除。2020年国家市场监督管理总局《商业秘密保护规定(征求意见稿)》第19 条列入了侵犯商业秘密行为的例外,其中第四款规定“商业秘密权利人或持有人的员工、前员工或合作方基于环境保护、公共卫生、公共安全、揭露违法犯罪行为等公共利益或国家利益需要,而必须披露商业秘密的。”可以作为商业秘密保护的例外。此外,我国也在地方性法规和规范性法律文件中,就公共利益对商业秘密的限制进行了原则性的规定。如《广东省技术秘密保护条例》《浙江省技术秘密保护办法》《深圳经济特区企业技术秘密保护条例》等。63. 《广东省技术秘密保护条例》第3 条第三款规定:“有损社会公共利益、违背社会道德的技术秘密,不受本条例保护。”《浙江省技术秘密保护办法》第4 条规定:“违反法律、法规,损害国家利益、社会公共利益,违背公共道德的技术秘密,不受本办法保护。”《深圳经济特区企业技术秘密保护条例》第9 条规定:“违反法律、法规,损害国家利益、社会公共利益,违背公共道德的技术秘密,不在本条例的保护范围。”这也意味着算法商业秘密持有者并不能利用法律对商业秘密的保护,拒绝所有情形下的算法透明。
从以上我国现有立法来看,各规定过于分散,在各自立法目的指导下,对商业秘密保护限制的具体规范与标准不一,限制的范围缺乏系统性考量,没有形成体系化的指引。这也导致现有规则在司法实践中适用难度较大,难以发挥其应有效用。为此,应当从立法层面完善我国商业秘密保护规范构造中的公共利益抗辩规则,以实现算法透明与商业秘密保护之间的利益平衡。
第一,在立法模式上,采用列举概括并用模式。商业秘密保护的范围随着社会经济的发展呈不断动态扩张的趋势,单纯列举式的方法必将难以适应新业态的发展。此外,公共利益是一个具有高度抽象性的概念,无法完全列举。同时,又需要详尽列举降低公共利益的抽象性,增强法律规定的明确性和可操作性。
第二,在公共利益的核心指向上,应确定适用的具体范围。尽管“公共利益”作为“以价值判断为核心的不确定的法律概念”64. 余军: 《“公共利益”的论证方法探析》,载《当代法学》2012年第 4 期,第 19 页。,其内涵的界定一直存在诸多争议,但从域外相关立法和司法实践的经验中依然可以找到值得借鉴的方向。在美国,根据《保护商业秘密法》《统一商业秘密法》以及相关联邦立法规定,公共利益抗辩事由主要涉及公共健康、公共安全、披露犯罪或侵权行为、言论和出版自由,与此同时,美国法院通过判例还确定了涉及国家安全、公共设施、维护商业道德和自由竞争秩序以及基本权利的公共利益抗辩情形。65. 参见黄武双:《英美商业秘密保护中的公共利益抗辩规则及对我国的启示》,载《知识产权》2009年第3 期,第85-88 页。在欧盟,《商业秘密保护指令》中所及为保护公共利益而进行披露的,主要涉及不当行为、不道德行为或者非法行为。相较之下,欧盟所设立的公共利益抗辩规则适用范围比美国更广。之所以有此差别,主要还是因为各国和地区的国情、政策不同,对商业秘密保护的力度不同。鉴于我国目前处于强化商业秘密保护的政策立场,我国现阶段的公共利益抗辩规则设计应将适用范围限缩在核心性公共利益上,并且实践中对公共利益内涵与外延的解释也应当非常谨慎。具言之,相关人可基于以下情形提起公共利益抗辩:国家安全;公众健康与安全;环境保护;揭露、制止已经发生、正在发生或即将发生的犯罪行为;基于保护其他公共利益的需要。
第三,在商业秘密披露的方式和对象上,应当做出更偏向于商业秘密权利人的倾斜式设计,选择最低限度干预商业秘密保护的披露手段,以免贸然公开秘密信息对权利人造成无法挽回的损失。当算法商业秘密保护需要对公共利益作出让步时,只是算法持有者的经营自主权在行使时受到一定克减,而非意味着对商业秘密这一私权利价值的全然否定。因此,立法上需要选择一种对商业秘密权利人私权利损害最小的披露方式。对比来看,《商业秘密保护规定(征求意见稿)》在有关商业秘密披露方式和对象的限制上总体与《美国保护商业秘密法》相似,其中“须以保密方式提交包含商业秘密的文件或法律文书”“向有关国家行政机关、司法机关及其工作人员”等程序性条款内容,为公共利益抗辩规则提供了具体化操作流程的补充,能够避免条款在适用过程中流于形式。在此意义上,即使是出于保护公共利益的需要,算法持有者的员工或合作方等对算法更为了解的相关人对算法的披露方式也需要以秘密的形式,向国家机关披露。
六、结语
数字经济是当今世界经济发展的重要引擎,而数字经济发展的核心离不开数字技术的发展,作为数字技术三要素(数据、算力和算法)之一的算法在助力数字产业发展的同时,算法黑箱化也带来了法律问责难题。算法透明作为化解算法风险的重要一环,有助于规训算法权力,维护个人利益和社会公共利益。但实践中,算法透明与商业秘密保护之间存在着紧张关系。解决之道在于取得算法透明与商业秘密保护之间的微妙平衡,即在“调和论”下寻求适当的算法透明和合理的商业秘密保护。对算法解释框架进行系统性重构,可以遵循分类分级的整体布局以及比例原则下的个案认定,构筑算法解释的差序规制格局,进而实现总体的解释效率和个案的解释正义。此外,进一步建立健全算法监督机制,实现适当的透明。与此同时,对商业秘密保护的限制制度进行完善,明确商业秘密内容的“合法性”要件,完善公共利益抗辩制度。
猜你喜欢
公民与法治(2023年12期)2023-12-11 04:01:48
公民与法治(2022年10期)2022-10-12 07:46:34
研究生法学(2020年6期)2020-04-13 07:59:46
知识产权(2016年7期)2016-12-01 07:01:08
知识产权(2016年6期)2016-12-01 07:00:11
能源(2016年3期)2016-12-01 05:11:17
中国卫生(2015年1期)2015-11-16 01:05:36
中国检察官(2015年14期)2015-02-27 15:39:42
对外经贸实务(2015年2期)2015-02-27 09:01:59
中国卫生(2014年10期)2014-11-12 13:10:22
