
基于PPO算法的机器人轴孔装配控制与仿真
2024-01-11 02:30申玉鑫刘晓明肖逸余德平
机械 2023年12期
申玉鑫,刘晓明,肖逸,余德平
基于PPO算法的机器人轴孔装配控制与仿真
申玉鑫,刘晓明,肖逸,余德平*
(四川大学 机械工程学院,四川 成都 610065)
针对在管道运输和航空航天领域常见的大口径轴孔装配任务,设计一种基于PPO算法的装配控制方法。首先,建立强化学习算法与装配环境交互训练框架,设计两个网络用于拟合装配策略和评估值函数;其次,设计机器人输出的动作空间与装配环境输出的状态空间,保证学习过程中的有效探索;然后,设计非线性奖励函数以确保训练过程的快速收敛;最后,搭建基于MuJoCo物理引擎的机器人大口径轴孔装配仿真平台,并在仿真平台上对设计算法进行训练和实验。结果表明:基于PPO算法的训练框架能保证训练过程的快速收敛,改进后的优势函数估计方法提升了训练过程的稳定性,训练模型不仅能保证轴插入孔和法兰面贴合,还能保证装配过程的安全性。
装配;PPO算法;MuJoCo仿真
在航空航天领域存在着大量轴孔部件装配任务,这类任务不仅要求将装配轴插入孔中,还要求实现装配部件上法兰面之间的完全贴合以实现机械联接[1]。然而,装配部件质量重、口径大等特点大大影响了生产效率,增加了生产安全风险。随着自动化技术的不断发展,在工业生产中的搬运、涂装、焊接等危险繁重环节机器人被大量应用[2-3]。因此,机器人可以代替人工执行这类装配任务。
机器人轴孔装配技术需要克服操作环境中不可避免的定位误差和夹持误差等,只采用位置控制无法保证装配的成功率和安全性[4]。因此,机器人必须借助外部感知手段监测装配过程[5],并设计装配控制算法以应对不同的装配任务和接触状态。视觉信息能映射环境中的位置和姿态误差,设计相应的视觉伺服算法可用于实现轴孔装配[6-7]。然而,视觉传感器的应用受到光线和视野条件的限制。力传感器可以被安装在机器人末端执行器上,在应用上不受环境条件影响。通过构建准静态轴孔装配模型来解释接触力与几何约束之间的关系,设计运动控制算法可以保证装配成功和安全[8-9]。然而,对于复杂精密的装配任务,接触模型存在精度不足、建模困难等问题,运动控制算法也难以保证任务实施。
深度强化学习是一种结合强化学习与神经网络的算法设计方式,使机器人能够在与环境的交互过程中学习运动控制技能,而不依赖于精确的接触模型[10]。它利用神经网络拟合需要学习的控制算法,并利用机器人与环境交互的训练数据更新网络参数,获得需要的装配控制算法。深度强化学习可以被用于训练基于位置的力控制器,用于保证装配过程中的柔顺性和安全性[11-12]。同时,深度强化学习也能用于弥补传统控制算法的不足,使传统控制算法得到进一步训练以加强算法鲁棒性[13]。然而,其当前应用依然需要借助传统力控算法提供先验知识,且缺乏对实际装配任务特性的深入研究。
针对上述问题,本文提出一种基于PPO(Proximal Policy Optimization,近端策略优化)算法的机器人轴孔装配控制算法。该算法不仅能够完全通过环境交互学习装配技能,还能保证装配的效率和成功率。首先,利用PPO的重要性采样方法实现对交互数据的高效利用,并对优势函数的估计方法进行改进。其次,根据大口径轴孔装配任务的插孔和法兰贴合需求设计动作与状态空间,并设计奖励函数保证训练过程的快速稳定收敛。最后,在基于MuJoCo(Multi-Joint Dynamics with Contact,接触型多关节动力学)物理引擎的轴孔装配仿真平台上进行训练和实验。实验结果表明:该算法能够在1500回合以内学习到所需要的装配技能,满足插孔和法兰面贴合的工艺需求。
1 基于PPO的装配控制算法
1.1 PPO算法
PPO算法利用Actor-Critic网络结构在连续空间中输出动作,且利用历史训练数据更新参数。该算法利用Actor网络拟合行为策略,利用Critic网络拟合值函数。装配过程被视为马尔可夫决策过程,Actor根据当前状态输出动作,环境在动作作用下转换为下一状态,并输出相关奖励。Actor和Critic拟合的行为策略和值函数分别为[11]:


为了实现两个网络的梯度更新,需要估计优势函数,为[11]:

PPO算法利用重要性采样方法来提高数据利用效率。因此,旧策略与环境交互产生的历史数据可用于更新新策略。在完成更新后,新策略的参数被复制到旧策略中。
Actor网络的更新公式为[11]:


Critic网络的更新公式为[11]:

式中:为Critic网络的损失函数;为历史交互数据集样本量。
1.2 算法改进
常规PPO算法利用蒙特卡罗法估计优势函数,该方法引入了后续时间步奖励,使得估计值方差较大。这会导致训练曲线出现较大波动,影响收敛稳定性。
为了实现参数稳定更新,使用具有泛化能力的优势函数估计方法,为:
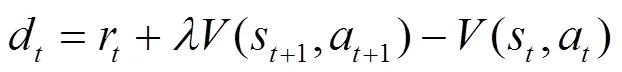

该方法的估计值虽然有一定偏差,但方差减小使得更新过程更加稳定。
Critic网络的更新公式改进为:

2 网络与参数设计
2.1 网络框架
本文设计针对大口径轴孔装配任务的PPO网络及训练框架。如图1所示,Old Actor和New Actor分别用于数据交互和参数更新,Critic网络用于估计当前策略的优异性。所有网络层使用Linear全连接层以及Tanh激活函数构建,其中Critic网络最后一层直接由Linear全连接层输出,以保证训练前期值函数的快速拟合。Actor输出的动作用于调整位姿,随后机器人沿轴位移使轴与孔主动接触。装配环境监测接触力并计算相应的奖励值,所有数据被输入到存储缓冲区中。当缓冲区数据足够时,对New Actor和Critic网络梯度更新,清空存储缓冲区,将New Actor的网络参数复制到Old Actor中。
2.2 动作空间与状态空间
机器人可在6个自由度移动或旋转轴部件以降低位姿误差。为提高装配安全性,插入动作由机器人直接执行,算法生成的装配策略只用作位姿调整。由于轴孔部件具有轴对称特性,绕轴旋转的动作不能改变轴孔接触关系。因此,动作可以表示为一个4维向量,且动作输出被限制在一定范围内以避免过度探索,为:


图1 训练网络框架
力传感器监测到的接触力由3个力和3个力矩分量组成,它们反映装配部件之间的接触关系。同样的,由于轴孔部件的轴对称特性,绕轴力矩分量不能映射轴孔位姿关系。因此,状态可以表示为一个5维向量:
式中:为力分量;为力矩分量。
2.3 奖励函数
奖励函数用于人为直观评价当前状态在装配过程中的优势。为保证训练过程的稳定性和高效性,在权衡整体进度和当前进度后设计了一种非线性奖励函数。奖励函数包括三种类型,即常规奖励、惩罚奖励和终止奖励。所有奖励都为负值,以激励策略减少装配步数。常规奖励综合考虑了装配深度和深度增量以保证训练稳定性。当接触力过大时,环境直接输出惩罚奖励。当回合完成且步数不超过允许最大值时,环境输出终止奖励。
奖励函数具体为:



其中:


3 训练与仿真实验
3.1 任务描述
本文研究对象为大口径轴孔装配任务,其中轴孔部件上都带有法兰,且孔有倒角,如图2所示。装配任务的目标是消除位姿误差以使轴插入孔中,且装配轴孔的法兰面完全贴合以
便于后续工艺实施。如表1所示,装配轴直径为206 mm,装配间隙为0.1 mm。零部件的直径大、长度短,装配过程容易受到法兰干扰。

图2 大口径轴孔零件实物图

表1 轴孔部件尺寸参数
3.2 MuJoCo仿真平台
MuJoCo物理仿真引擎可以构建高精度的接触力学模型,可直接导入需要仿真的零件模型,并根据零件相对位姿计算接触力。该仿真引擎可直接在Python环境下开发,大幅提高强化学习的训练与部署效率。
本文基于MuJoCo物理引擎构建了大口径轴孔装配仿真环境,并在仿真环境下开展了算法训练和仿真实验。如图3所示,从机器人末端执行器到轴部件之间形成一条刚性联接链,联接顺序为Mocap(末端执行器)-传感器-夹具-轴。孔被固定在平台表面。仿真平台支持直接利用欧拉角形式(如式10)控制Mocap在空间中的位姿,等价于机器人操纵装配轴运动。同时,仿真平台可以基于轴孔相对位姿计算接触力(如式11)。仿真平台中不包含任何特定的机器人,使训练的模型能够适应不同的机器人实体。所有接触都是由Mocap沿轴位移产生,这保证了接触过程的准静态特性,降低仿真与现实之间的差距。
3.3 训练结果
每回合训练开始时,轴的位姿在一定误差范围内被随机初始化,以确保算法对位姿误差具有鲁棒性。设置位置误差在1.5 mm以内、角度误差在1°以内,Actor输出的动作在0.15 mm和0.02°以内,最大允许力和力矩分别为10 N和1.5 N·m,训练回合为1500回合,每回合允许步数为800步。其他超参数设置如表2所示。

图3 基于MuJoCo的大口径轴孔装配仿真

表2 训练超参数设置
训练结果如图4所示,其中曲线steps和rewards分别代表每10回合的平均步数和平均奖励,阴影代表相应数据的标准差。可以看出,回合步数随着训练进行不断降低,在第1500回合达到90步左右。而回合奖励随着训练不断升高,在第1500回合达到-40左右。训练曲线的波动在训练过程中不断减小。

图4 训练曲线
训练过程中网络更新的损失函数变化趋势如图5所示。训练开始时,损失在16左右,这是因为具有泛化性的优势函数估计具有一定的偏差。随着训练进行,损失在300回合下降到2以下,最终下降到1以下,这说明Critic网络很快调整参数以适应优势函数估计的偏差。

图5 损失函数变化趋势
3.4 实验结果
本文针对基于PPO的装配控制算法的工作能力进行了仿真实验。装配开始时,装配轴沿轴偏移约1 mm,沿轴偏移约0.5 mm,绕轴旋转约0.5°。
如图6所示,error_和error_分别表示轴部件的横向位置误差在轴和轴上的分量,depth表示轴在孔内的深度,由于轴与实际方向相反,depth为负值时表示轴部件在孔内。可以看出,轴部件在轴和轴上的位置误差不断减小,在第16步时,横向位置误差减小到装配间隙以内,因此装配轴直接下降到孔内3 mm以下。
如图7所示,error_和error_分别表示轴部件的角度误差在轴和轴上的分量。在第16~52步,轴部件在的角度误差不断减小,这导致装配深度进一步增加,直至达到要求装配深度。
如图8所示,force_,force_,force_分别表示轴孔相对接触力在三个轴上的分量。各接触力分量始终在10 N以内。装配完成时,沿轴和轴的接触力接近0,而沿轴接触力达到-8 N,这说明轴部件已完全插入孔内,且实现了法兰面贴合。
如图9所示,torque_和torque_表示轴孔相对接触力矩在和轴上的分量。各力矩分量始终低于1.5 N·m,满足装配安全需求。

图6 横向位移误差变化趋势

图7 角度误差变化趋势

图8 接触力变化趋势

图9 接触力矩变化趋势
4 结论
本文设计了一个基于PPO的机器人轴孔装配控制算法,并在基于MuJoCo物理引擎的装配仿真平台上对大口径轴孔装配任务进行了训练与仿真实验。利用马尔可夫决策性质描述了机器人轴孔装配任务的特点;对PPO算法的优势函数估计进行了改进,使之能适用于长行程步数的装配任务;基于Actor-Critic原理搭建了算法网络结构及训练框架,设置了装配任务的动作与状态空间,并设计了非线性奖励函数。仿真实验结果表明:本文提出的基于PPO的轴孔装配控制算法可学习到机器人装配策略,训练曲线收敛快速且稳定,可快速有效地完成大口径轴孔装配任务,克服位姿误差,实现法兰面贴合。未来可增加视觉感知手段,从而克服更大程度的位姿误差并规划机器人移动路径。
[1]Xiaolin Zhang,Wang Zanqin,Yu Hang,et al. Research on Visual Inspection Technology in Automatic Assembly for Manhole Cover of Rocket Fuel Tank[C]. 2022 4th International Conference on Advances in Computer Technology, Information Science and Communications (CTISC),2022:1-5.
[2]未来10年工业机器人与协作机器人市场发展预测[J]. 机械,2017,44(10):54.
[3]计时鸣,黄希欢. 工业机器人技术的发展与应用综述[J]. 机电工程,2015,32(1):1-13.
[4]Rui Li,Qiao Hong. A Survey of Methods and Strategies for High-Precision Robotic Grasping and Assembly Tasks-Some New Trends[J]. IEEE-ASME Transactions on Mechatronics,2019,24(6):2718-2732.
[5]张松松. 多维感知融合驱动的机器人装配行为研究[D]. 贵阳:贵州大学,2023.
[6]Sainbuyan Natsagdorj,Chiang John-Y,Su Che-Han,et al. Vision-based Assembly and Inspection System for Golf Club Heads[J]. Robotics and Computer-Integrated Manufacturing,2015,32(4):83-92.
[7]R-J Chang,Lin C-Y,Lin P-S. Visual-Based Automation of Peg-in-Hole Microassembly Process[J]. Journal of Manufacturing Science and Engineering- Transactions of the Asme,2011,133(4):41015-41027.
[8]A-De-Sam Lazaro,G Rocak H. Precision assembly using force sensing[J]. International Journal of Advanced Manufacturing Technology,1996,11(2):77-82.
[9]D-E Whitney. Quasi-Static Assembly of Compliantly Supported Rigid Parts[J]. Journal of Dynamic Systems Measurement and Control-Transactions of the Asme,1982,104(1):65-77.
[10]陈佳盼,郑敏华. 基于深度强化学习的机器人操作行为研究综述[J]. 机器人,2022,44(2):236-256.
[11]Tadanobu Inoue,De Magistris Giovanni,Munawar Asim,et al. Deep reinforcement learning for high precision assembly tasks[C]. 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS),2017:819-825.
[12]Tianyu Ren,Dong Yunfei,Wu Dan,et al. Learning-Based Variable Compliance Control for Robotic Assembly[J]. Journal of Mechanisms and Robotics-Transactions of The Asme,2018,10(6):61008.
[13]Jing Xu,Hou Zhimin,Wang Wei,et al. Feedback Deep Deterministic Policy Gradient With Fuzzy Reward for Robotic Multiple Peg-in-Hole Assembly Tasks[J]. IEEE Transactions on Industrial Informatics,2019,15(3):1658-1667.
Robotic Peg-in-Hole Assembly Control and Simulation Based on PPO Algorithm
SHEN Yuxin,LIU Xiaoming,XIAO Yi,YU Deping
(School of Mechanical Engineering, Sichuan University, Chengdu 610065, China )
A PPO algorithm-based assembly control method is proposed for the large-diameter peg-in-hole assembly which is common in pipeline transportation and aerospace fields. Firstly, the interactive training framework between the reinforcement learning algorithm and assembly environment is established, and two networks are designed to fit the assembly strategy and the evaluation value function respectively. Secondly, the action space of robot output and the state space of assembly environment output are designed to ensure the effective exploration in the learning process. Then, a nonlinear reward function is designed to ensure the fast and stable convergence of the training process. Finally, a simulation platform for robot assembly of large-diameter peg-in-hole assembly based on MuJoCo physics engine is built, and the designed algorithm is trained and tested on the simulation platform. The results show that the training framework based on PPO algorithm can ensure the fast convergence of the training process, and the improved dominance function estimation method can improve the stability of the training process. The training model can not only ensure the fit of the shaft insertion hole and the flange surface, but also ensure the safety of the assembly process.
assembly;PPO algorithm;MuJoCo simulation
TP249
A
10.3969/j.issn.1006-0316.2023.12.012
1006-0316 (2023) 12-0074-07
2023-07-16
申玉鑫(1998-),男,四川遂宁人,硕士研究生,主要研究方向为机器人自动化,E-mail:shenyuxin2021@163.com。
通讯作者:余德平(1984-),男,江西抚州人,博士,教授,主要研究方向为智能与自动化装备,E-mail:williamydp@scu.edu.cn。
猜你喜欢
冶金设备(2021年2期)2021-07-21
制造技术与机床(2017年6期)2018-01-19
哈尔滨工程大学学报(2016年11期)2016-12-12
光学精密工程(2016年5期)2016-11-07
光学精密工程(2016年4期)2016-11-07
湖北工业大学学报(2016年5期)2016-02-27
锻压装备与制造技术(2015年2期)2015-06-26
电源技术(2015年9期)2015-06-05
柴油机设计与制造(2014年4期)2014-03-06
组合机床与自动化加工技术(2014年12期)2014-03-01
