
一种基于YOLOv4的隧道吊柱位姿检测方法
2024-01-11 02:24吴越舟邓斌李荣铎许冠麟
机械 2023年12期
吴越舟,邓斌,李荣铎,许冠麟
一种基于YOLOv4的隧道吊柱位姿检测方法
吴越舟,邓斌,李荣铎,许冠麟
(西南交通大学 机械工程学院,四川 成都 610031)
针对隧道内吊柱实现自动抓取安装需要获取吊柱位姿信息的问题,提出一种将YOLOv4目标检测算法与多特征点提取算法融合的吊柱位姿检测算法。通过YOLOv4算法在双目视觉的左右图像上标出吊柱法兰的识别框,在扩大后的识别框范围内将图像从三原色(RGB)空间转换到HSV空间,利用检测目标的特有HSV信息分离出其区域,对该区域进行直线检测,通过canny和霍夫变换筛选出吊柱法兰的特征点。利用视差原理与面面交会原理还原出吊柱相对于相机的位姿信息。在不同距离进行了多组位姿检测实验,结果显示,检测速度为26 f/s,在1000~1500 mm内平均误差均在20 mm以内,具有较高的精确性和实时性。
隧道吊柱;YOLOv4;位姿检测;双目视觉
当前国内外隧道内的吊柱安装大多采用人工完成,如图1所示,即搭设脚手架,由人力将吊柱吊至隧道顶部,并在脚手架上对位安装。该方法存在劳动强度大、安装效率低等问题。因此,杨三龙[1]设计了接触网吊柱安装机器人构型布局,开发了一套接触网上部机构智能化安装设备。但目前对吊柱自动化安装的研究较少,且诸如杨三龙设计的吊柱安装机器在对吊柱进行抓取时,普遍是人工将吊柱的三维位姿信息输入计算机再下达指令进行抓取,自动化程度与精度均略显不足,且不能满足不同位姿吊柱的抓取。要实现吊柱的自动抓取及安装,关键是在特定环境中对吊柱进行准确且快速的定位识别。目前,机器视觉技术在视觉导航、工业自动化和智能机器人等领域应用非常广泛,因此,研究基于机器视觉技术的隧道吊柱识别与定位技术具有重大意义[2],可为后续的吊柱安装及吊柱日常维护等研究奠定基础。

图1 吊柱人工作业图
目前国内外针对隧道吊柱的识别定位研究较少,大多是对接触网的其他部分,如绝缘子、支柱等的识别定位研究。展明星[3]提出一种双目视觉结合SURF(Speed Up Robust Features,加速稳健特征)的目标识别定位方法,张珹[4]提出一种改进的FasterR-CNN(Convolutional Neural Networks,卷积神经网络)算法。以上研究均是先通过各自算法识别整个物件,通过识别出的轮廓质心或识别框中心的位置来代表识别物件的位置。对于需要准确识别物件某个空间特征点的情况,容易出现识别精度不足的问题。
在位姿估计方面,空间目标三维姿态估计方法大致可分为三种[5]:
(1)基于三维模型检索的方法。需要掌握较多的目标先验信息,从而建立足够丰富的目标二维姿态模型数据库,因此实际使用率较低。
(2)基于特征点对应的方法。在表面纹理不明显时得到的结果可能不准确,需要找到合适的特征提取方式。
(3)基于三维特征描述符的方法。通常通过三维扫描仪或者RGB-D相机获取目标点云信息,利用3D-3D点对求解目标位姿。需要用到深度相机,对设备功能有要求。
针对以上问题,本文研究了一种基于YOLOv4的隧道吊柱位姿检测算法,其将YOLOv4识别算法、特征融合检测算法融合,可以实时得到吊柱法兰的特征点位置,再通过三维重建算法还原吊柱的位姿信息。在Python环境中对该算法进行实例测试,验证了该算法的实时性和精确性。
1 吊柱位姿检测算法原理
针对隧道施工中对吊柱自动识别抓取的要求,本算法主要包含两个部分:
(1)位置检测。通过YOLOv4算法、特征融合检测算法结合视差原理共同实现。通过YOLOv4算法得到吊柱法兰的定位框,然后在定位框的一定范围内通过吊柱多特征共同提取出所需位置特征点,将位置特征点匹配并由三角形算法还原出位置信息。
(2)姿态检测。同样在基于YOLOv4算法得到的识别框的一定范围内,通过吊柱多特征共同提取出所需姿态特征点,再将姿态特征点利用面面交会原理算法进行姿态的还原。
吊柱位姿检测算法框架如图2所示。

ROI(Region of Interest):感兴趣区域;HSV(Hue,Saturation,Value;色调,饱和度,亮度):一种颜色模型。
图2 吊柱检测算法流程
2 位姿计算原理
2.1 视差原理位置计算
视差测距法又称三维重建。视差是指左右观测点在观察物体时的偏差,其与观测点及目标物体的位姿有关。三维重建是模拟人双眼观察物体的原理,是物体成像的逆过程[6]。
平行双目立体视觉模型原理如图3所示。

O1-X1Y1Z1、O2-X2Y2Z2为左右相机的坐标系;1-11、2-22为左右图像坐标系;(,,)为所求目标;1(1,1)、2(2,2)为在左右图像坐标系的投影;为双目相机基线,即两个相机之间的距离;为相机焦距。
图3 平行双目立体视觉模型
在平行双目立体视觉中,左右相机的内外参数可以通过张正友相机平面标定法[7]得到。再结合相机标定参数,通过空间三角形相似的性质可以得到点的三维坐标:
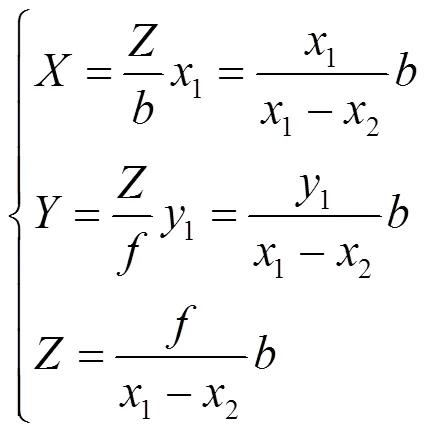
因此,通过左右图像匹配的位置特征点即可实现吊柱的定位。
2.2 面面交会估计姿态指向
吊柱法兰形状为正方形,其有两组相互正交的平行线,利用单幅图像中的两组平行线,通过面面交会,可以计算出吊柱的姿态指向,如图4所示,其中1平行于2,3平行于4。通过1、2两个空间平面方程联立描述空间直线,即面面交会确定空间直线[8]。由空间几何知识可知,与L平行,即可通过求的姿态角求得L的姿态角,同理L也可以通过3、4转换得到。得到L、L的方向向量后可通过右手定理得到L,即最终需要的吊柱姿态指向。
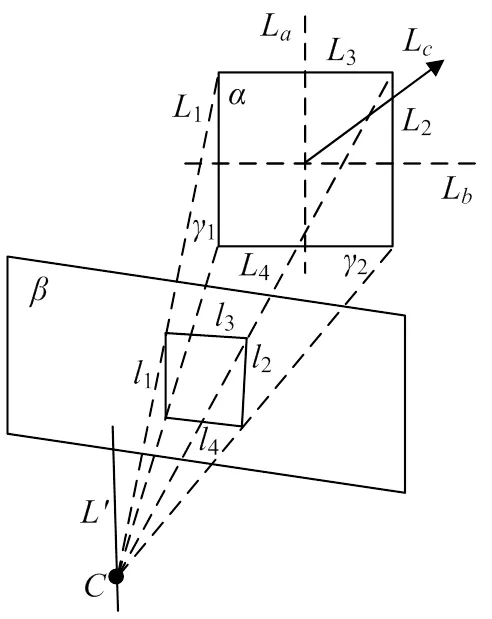
平面为吊柱法兰;平面为相机成像面;1、2、3、4为吊柱法兰的四条边;1、2、3、4为1、2、3、4在相机成像面对应的投影;为光心;1和2为1和2分别与所确定的平面;为1和2交会所得直线;L为与1、2平行的直线;L为与3、4平行的直线;L为吊柱姿态指向。
图4 面面交会模型
由于空间直线与空间平面难以表示且计算复杂,将求面面交线的问题转换成求两个面的法向量,再通过右手定理求两个法向量的外积的问题。
如图5所示,1~4的直线方程式为:
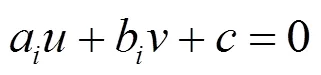
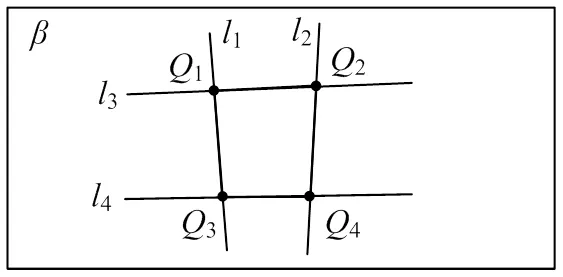
1、2、3、4为1、2、3、4的交点,即成像面四边形的四个角点。
图5 成像面特征直线与特征点
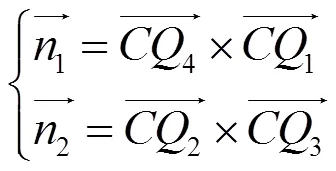
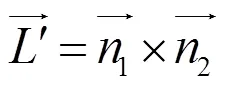

RPY(Roll,Pitch,Yaw;横滚,俯仰,偏航)角用于目标坐标系相对于参考坐标系的姿态描述,是一种基于绕固定坐标轴旋转得到的角。RPY角转换式为:

3 目标检测与特征点定位
3.1 特征点选取
隧道吊柱法兰是一个厚度为20 mm的正方形板状结构,需要特征识别并进行匹配的即为此正方形,包括正方形的中心点以及四个角点,如图6所示。在实际拍摄中,由于拍摄角度的倾斜,正方形会变形为一个普通的四边形,因此不能用正方形或矩形拟合,需要使用更为普遍的四边形拟合。所识别的隧道吊柱法兰颜色与直线特征明显,基于这两类特征,对吊柱法兰进行特征提取。
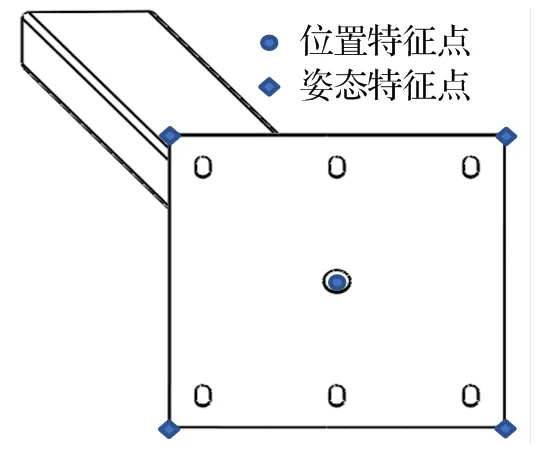
图6 吊柱法兰特征点示意图
3.2 目标检测
目标检测可定位检测目标,从而过滤掉目标区域以外的背景干扰,减小后续图像处理的难度。本文的目标检测主要使用YOLOv4算法。
YOLOv4算法是在YOLOv3算法的基础上进行改进,得出的一种能够同时得到目标种类与位置信息的算法,是一种高实时性、高精度的目标检测模型。YOLOv4算法的实现主要分为数据集标定、模型训练与目标物检测。数据集标定主要是将数据集内图片上的目标物进行标注,作为先验信息输入到YOLOv4网络中进行训练得到权重,最终可以通过该算法对吊柱法兰进行识别定位。
3.3 特征点提取
在三维重建的整个过程中,特征点的检测与匹配是最为基础的部分[9]。确定了目标区域之后,可以对区域内的图像进行相关处理,以获取所需特征点像素坐标。处理步骤主要包括HSV图像分割、直线提取与聚类及特征点匹配。
HSV由表示占主导频谱颜色的色调、表示颜色丰富程度的饱和度和表示颜色亮度的所组成。采用HSV模型时从色彩本质特性出发,使用色度分量来聚类分析,可以有效克服光照变化带来的影响[10]。从RGB空间到HSV色彩空间的变换表达式为:
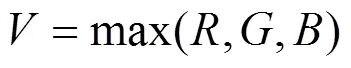


阈值处理主要是根据颜色特征对图片中的目标物进行标记。这里选择HSV颜色模型来表征颜色特征。阈值处理的步骤为:
(2)将原RGB图像通过式(7)~(9)转化成HSV图像;
(3)新建一个与原始图像等大的二维数组,其每个点通过式(10)进行赋值。
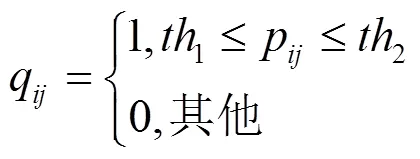
相比于原图像直接通过canny边缘检测算法识别轮廓,在上一步通过HSV分割得到的吊柱二值图会大大减少背景杂线,只保留吊柱的轮廓线,为后续的霍夫变换(Houghlines)优化了输入环境。再通过设定合适的Houghlines函数的阈值,提取到满足要求的直线,即与空间变形后的吊柱法兰四边重合的直线。但此时提取的每条边的重合直线往往有多条,因此需要对这些直线进行聚类与合并。
采用k-means++均值聚类算法对识别出的直线进行聚类,k-means++在选择初始类别中心时进行了优化。初始类别中心的选择步骤为:
(1)在数据点之间随机选择一个中心1;
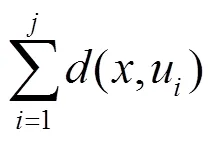
(4)重复步骤(2)和(3),直到选择了个中心(即=);
(5)选择初始中心后使用标准均值聚类。
使用k-means++均值聚类算法可以减少计算时间,且具有聚类的唯一性。通过k-means++均值聚类算法对所得直线聚类求均值,最终可以得到四条结果直线,从而得到五个特征点。
立体匹配原理是得到所测物在不同成像平面上的特征匹配过程,而图像的立体匹配就是通过算法实现这一过程[11]。本文得到的特征点只有五个,因此按照以下步骤进行特征点匹配。
对通过k-means++算法得到的四条直线求交点即可得到四个顶点。四个顶点按照以下规则进行排序:
(1)计算出四个顶点在图像坐标系的横纵坐标之和M=Q+Q(=1~4),将M按照大小进行排序,M取最小时对应的点定义为1,M取最大时对应的点定义为3。
(2)通过点1、3得到经过此两点的直线13,判断剩余两顶点是位于13的上方还是下方,位于上方的点定义为2,位于下方的点定义为4。
(3)通过点2、4得到经过此两点的直线24,再对1324进行求交点,最终得到5。
双目相机的左右图像经过以上规则求得Q(=1~5)后,即可将左图像的Q与右图像的Q进行匹配,即完成5个特征点的匹配。
4 吊柱位姿检测实验及结果
4.1 目标检测与特征点提取
目标检测方面,对所识别的吊柱采集了240张图像,经过顺时针旋转90°、水平镜像、颠倒等一系列数据增强操作,最终得到960张训练样本。通过LabelImg将这些训练样本进行目标物种类位置的标注,生成xml文件,再输入YOLOv4网络进行训练,得到模型的权重。使用训练出的网络对立体校正后的左右相机的图像进行识别检测。
如图7(a)所示,YOLOv4识别网络能准确识别吊柱法兰的位置,检测速度可达26 f/s,平均精确率(mAP)可达94.6%。得到识别框后将识别框的四边均双向扩大20个像素得到图7(b)。再在扩大后的识别框里进行霍夫变换直线提取,并最终得到所需特征点,如图7(c)~(f)所示。
相比于对原始图片直接进行特征识别,本实验提出的基于YOLOv4的特征融合识别算法具有识别范围小、受背景干扰影响小、精度高的特点。本文算法与直接对原始图片特征提取的算法的效果对比如图8、图9所示,可见通过YOLOv4算法大大减少了背景的杂线影响,大幅度提升了直线检测精度。

图7 特征点提取过程图

图8 HSV效果对比图

图9 直线提取对比图
4.2 吊柱位姿估计
在相机与吊柱法兰中心分别距离1000 mm、1250 mm、1500 mm、1750 mm、2000 mm的情况下进行了五组实验。每个距离在不同的角度拍摄了三组照片。位姿验证点如图9所示,此点也为机械臂后续的抓取点。
通过吊柱法兰中心的位置还原与吊柱的姿态计算,可综合得到抓取点的位置及距离,实验结果如表1所示。

图10 吊柱位姿验证点
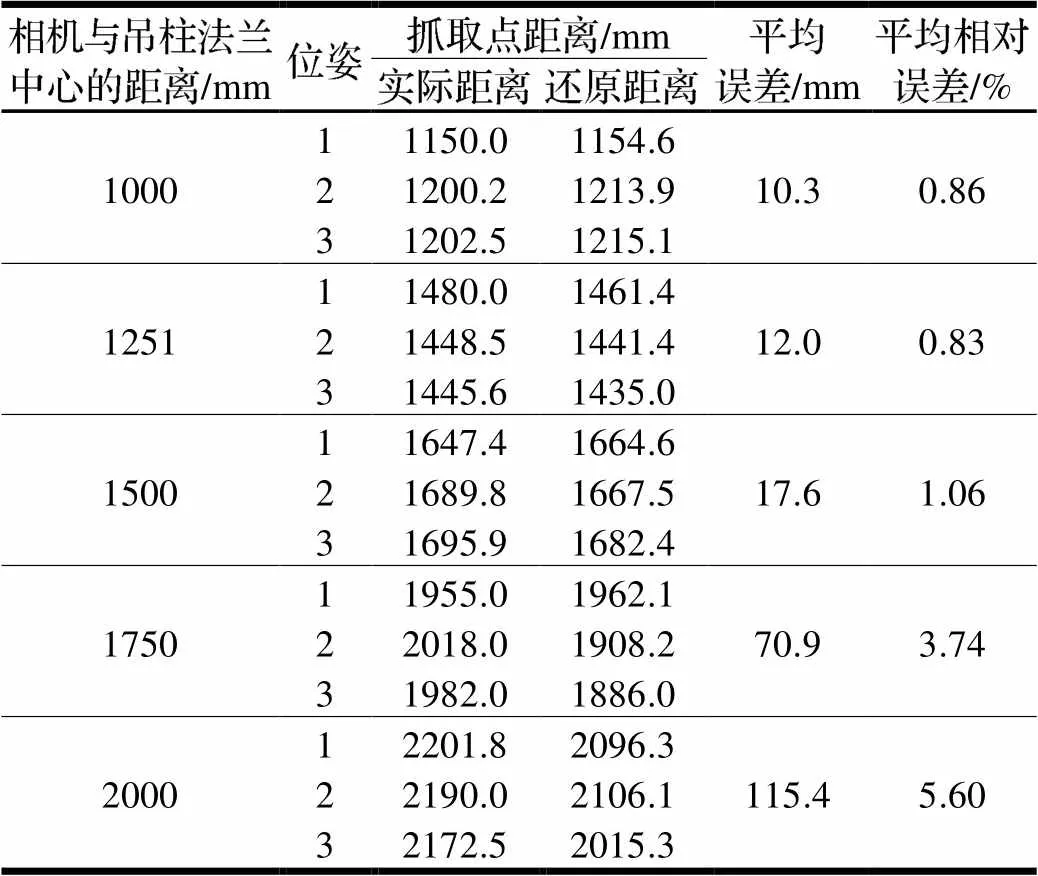
表1 吊柱抓取点距离信息还原结果
实验表明,还原的吊柱抓取点距离的平均误差随着吊柱中心点距离的增大而增大,在1000~1500 mm内,误差在20 mm范围内缓慢增长,1750 mm与2000 mm误差有较大增长。因此,在1000~1500 mm内,对吊柱的位姿估计误差较小,吊柱抓取点距离误差较小,符合任务要求。
5 结论
为了实现隧道施工自动化,本文提出一种基于YOLOv4的吊柱识别及位姿检测算法。通过YOLOv4算法实现吊柱法兰的定位,再通过色彩以及轮廓的特征提取算法提取出特征点。提取出的特征点通过视差原理与面面交会原理综合得出吊柱的位姿信息,最终确定吊柱抓取点的信息。通过实验确定了此方法的最佳使用距离范围为1000~1500 mm,在此范围内具有较好的实时性和准确性。为后续隧道施工自动化以及吊柱自动抓取提供了理论支持。
[1]杨三龙,饶道龚,李广平,等. 接触网吊柱安装机器人静力学分析及结构优化[J]. 筑路机械与施工机械化,2020,37(12):74-77,91.
[2]HAN Y,LIU Z G,LEE D J,et al. Computer vision-based automatic rod-insulator defect detection in high-speed railway catenary system[J]. International Journal of Advanced Robotic Systems,2018,15(3):1729881418773943.
[3]展明星,王致诚,李致远. 基于视觉的接触网绝缘子识别定位研究[J]. 西部交通科技,2022(4):184-187.
[4]张珹. 高铁接触网支持装置紧固件识别与定位的深度学习方法[J]. 工程数学学报,2020,37(3):261-268.
[5]王一,谢杰,程佳,等. 基于深度学习的RGB图像目标位姿估计综述[J]. 计算机应用,2023,43(8):2546-2555.
[6]郭星源. 基于双目视觉的移动目标测距方法研究与实现[D]. 成都:电子科技大学,2021.
[7] Zhang Z. A Flexible New Technique for Camera Calibration[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2000,22(11):1330-1334.
[8]宋平,杨小冈,蔡光斌,等. 单站光测图像中空间目标姿态估计[J]. 兵器装备工程学报,2020,41(9):165-170.
[9]徐建鹏,卜凡亮. 三维重建系统下的特征点处理与位姿恢复优化算法[J]. 计算机应用研究,2019,36(10):3196-3200.
[10]陈梅香,郭继英,许建平,等. 梨小食心虫自动检测识别计数系统研制[J]. 环境昆虫学报,2018,40(5):1164-1174.
[11]胡高芮,何毅斌,陈宇晨,等. 基于二维图像的三维重建技术研究[J]. 机械,2019,46(8):27-31.
Pose Detection Methodof Tunnel Davit Based on YOLOv4
WU Yuezhou,DENG Bin,LI Rongduo,XU Guanlin
(School of Mechanical Engineering, Southwest Jiaotong University, Chengdu 610031,China)
In order to obtain the pose information of the davit to realize the automatic grasping and installation of the davit in the tunnel, this paper proposes a davit pose detection algorithm that combines YOLOv4 target detection algorithm and multi-feature extraction algorithm. The identification frame of the flange of the davit on the left and right images of binocular vision is marked through the YOLOv4 algorithm, and the image is converted from the three primary colors (RGB) space to the HSV space within the expanded identification frame range, and the specific HSV information of the detected object is used to separate its area and conduct the line detection on the area. And the features of the flange of the davit are selected through Canny and Hough Transform. Finally, the pose information of the davit relative to the camera is restored by using the parallax principle and the surface to surface intersection principle. Several groups of pose detection experiments are carried out at different distances. The results show that the detection speed is 26 f/s, and the average error within 1000~1500 mm is within 20 mm, which has high accuracy and real-time performance.
tunnel davit;YOLOv4;pose detection;binocular vision
TP391.41
A
10.3969/j.issn.1006-0316.2023.12.002
1006-0316 (2023) 12-0008-07
2023-03-02
吴越舟(1998-),男,四川南充人,硕士研究生,主要研究方向为机器视觉,E-mail:934712683@qq.com;邓斌(1964-),男,湖北荆门人,博士研究生,教授,主要研究方向机电液一体化。
猜你喜欢
汽车维修与保养(2021年12期)2021-03-08
汽车维修与保养(2020年10期)2021-01-22
小学生导刊(2018年13期)2018-11-30
数学小灵通·3-4年级(2017年10期)2017-11-08
小学生导刊(低年级)(2017年2期)2017-06-10
光学精密工程(2016年5期)2016-11-07
光学精密工程(2016年4期)2016-11-07
湖北工业大学学报(2016年5期)2016-02-27
现代制造技术与装备(2015年4期)2015-12-23
石油工程建设(2014年5期)2014-03-20
