
分析性临床医学研究:队列研究的设计要点
2024-01-09 00:47王瑞平肇晖吴颖李斌
上海医药 2023年23期
王瑞平 肇晖 吴颖 李斌
(1.上海市皮肤病医院临床研究与创新转化中心 上海 200443;2.上海医药行业协会 上海 200003)
流行病学(epidemiology)作为一门基础学科,是研究人群中疾病与健康状况分布及其影响因素,并研究防治疾病及促进健康的策略和措施的科学[1]。近年来,流行病学在疾病预防和健康促进、疾病监测、疾病病因和危险因素研究、疾病自然史、疾病防治效果评价等方面发挥了重要作用。同时,流行病学也是一门逻辑性很强的应用学科,流行病学以医学为主的多学科知识为依据,利用观察和询问的方式调查社会人群的疾病和健康状况,描述疾病频率和分布,通过归纳、综合和分析提出病因假说,进而应用分析性研究对建立的病因假说进行验证,最后再通过试验研究来进一步证实。对疾病的发病规律了解清楚后,可以上升到理论高度,用数学模型预测疾病。
流行病学研究方法可以分为“观察法”“实验法”和“数理法”三大类。队列研究(cohort study)是分析流行病学一种重要研究类型。如图1所示,队列研究是在一个特定人群中选择所需的研究对象,根据研究对象目前或过去某个时期是否暴露于研究的因素或不同的暴露水平将研究对象分为不同组别,如暴露组和非暴露组,高剂量暴露组和低剂量组,通过询问、实验室检测和问卷调查等方法采集相关信息;并随访观察一段时间后,观察登记不同暴露人群的结局事件发生情况,比较各组结局的发生率,从而评估和检验危险因素与结局的关系[2]。
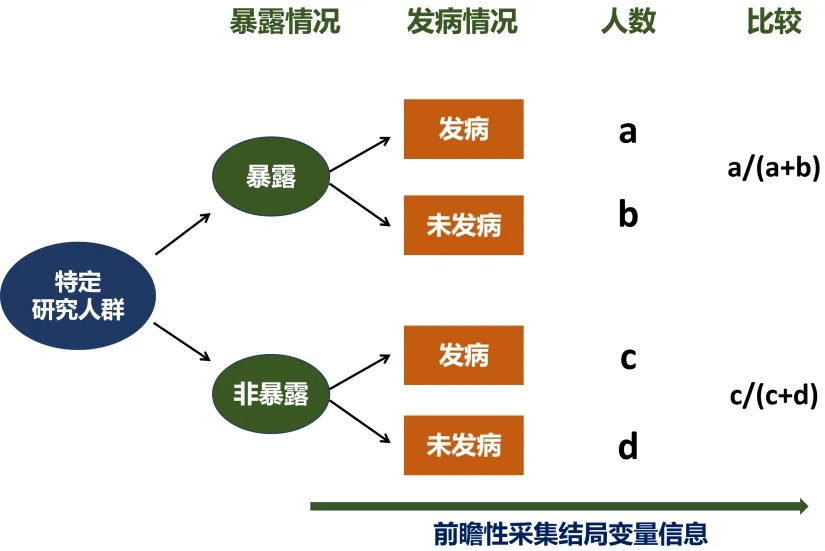
图1 队列研究的设计原理示意图
1 队列研究的分类
前瞻性队列研究(prospective cohort study):是队列研究最常用的一种类型,研究对象的分组是根据研究开始时研究对象的暴露情况而定,此时研究对象的结局还没有出现,须前瞻性观察一段时间才能得到。因此,前瞻性队列研究所需的观察时间一般比较长。在前瞻性队列研究中,由于研究者可以直接获取关于暴露与结局的一手资料,所以获得数据的偏倚较小。
回顾性队列研究(retrospective cohort study):是指研究对象的分组根据研究开始时研究者已掌握的有关研究对象的暴露情况而定,同时在研究开始时,其研究结局已出现,其资料可以从历史资料中获取,不需要再开展前瞻性观察来采集的一种队列研究类型。相比于前瞻性队列研究,回顾性队列研究可以通过回顾历史资料信息同时获取研究对象暴露和结局,研究可以在相对较短的时间内完成,具有省时、省力、研究周期短等优势,近年来受到研究者们的欢迎。
双向性队列研究(ambispective cohort study):是在历史性队列研究后,继续前瞻性观察一段时间,是将回顾性队列研究和前瞻性队列研究相结合的一种研究方法。在开展回顾性队列研究时,如果从暴露到现在的观察时间还不能满足研究的要求,可以采用双向性队列研究。
2 队列研究样本量估算
队列研究一般很难将全部暴露人群纳入研究,因此需要从目标总体中选择一部分人群组成样本开展队列研究。在队列研究样本量估算时,应考虑一般人群中所研究疾病的发病率、暴露组与对照组人群发表率的差异、I类错误和Ⅱ类错误、失访率等因素。无论是前瞻性队列研究、回顾性队列研究还是双向性队列研究,其样本量计算公式均相同,具体如下:
上述计算公式中,α为I类误差,β为Ⅱ类误差,p0和p1分别代表非暴露组和暴露组人群研究疾病的发病率,p1=p0RR,RR为相对危险度(relative risk, RR)。
例如:拟开展一项前瞻性队列研究,探讨吸烟与肺癌的关系。既往研究显示,非吸烟人群肺癌发病率为0.5‰,估计吸烟与肺癌关联的RR值为4.0,设α=0.05,β=0.10,根据p1=p0RR,计算p1=2‰,代入上述样本量计算公式计算后得n=11 648,考虑10%失访率,即分别需要纳入12 812名非吸烟者和12 812名吸烟者。由此可见,对于发病率低的疾病,采用队列研究需要的样本量很大,实施难度高,因此采用病例对照研究更合适。
3 队列研究设计和实施要点
1)遵循队列研究设计原则 与病例对照研究及其他类型的临床研究一样,队列研究设计也需遵从PICO原则,即明确研究人群(population, P)、确定暴露因素(intervention, I)、设置对照组(control, or comparison, C)和确定结局变量(outcome, O)。
2)明确研究目的 队列研究是一项费时、费力和费钱的研究类型,且一次只能研究一个暴露因素,因此正式开始前要把握好研究动态,明确研究目的。在队列研究设计时,一定要明确研究的暴露因素和测量方式,包括暴露时间、暴露频次,累计暴露剂量等。此外,对于研究的结局变量,要给出全面、具体和客观的定义。结局变量不仅限于发病、死亡,也可以是健康状况和生命质量的变化,如分子或血清学变化等。在研究实施过程中,对于潜在的混杂因素,也应该进行合理的测量和记录,便于后面研究结果的综合评估。
3)确定研究现场和研究对象 队列研究的随访周期一般较长,在研究现场选择时应注意目标人群的稳定性,最好能够获得当地管理部门的重视,群众的理解和配合,便于后续研究工作的顺利开展。对于研究对象的选择,根据确定的研究现场和样本量估算结果,在目标人群中根据研究对象就某一个风险因素的暴露情况,分为暴露组和非暴露组。暴露人群包括职业人群、特殊暴露人群、一般人群和有组织的人群;非暴露人群包括内对照、特设对照和总人群对照,研究者根据实际情况选择暴露组和非暴露组人群,开展研究即可。
4)资料采集和随访 在队列研究开始之前,项目组应根据研究目的制定研究方案,明确资料采集的方法。队列研究资料采集主要通过问卷调查方法开展,近年来电子数据库信息平台在队列研究中得到了推广和应用。在研究数据采集时,须详细收集每一个对象的基础信息,包括暴露资料、可能的混杂因素信息和个人资料信息等。在基线信息采集完毕后,则须对研究对象进行长期随访,根据实现制定的计划严格落实。在随访计划中,应明确随访的对象、内容、方式(如面谈、电话、复诊检查等)、频次(如每年1次、每3年1次等)和结局等内容,然后对暴露对象和非暴露对象开展同质化随访工作。
5)研究过程质量控制 队列研究费时、费力、消耗大,应加强研究实施的过程管理,特别是随访过程中的资料采集过程应做好质量控制。①严格挑选调查员,强调调查员的科学态度和责任心;②对调查员进行统一培训,掌握调查方法和技巧,同时考核合格后上岗,并在研究过程中实施定期培训和考核管理;③加强项目实施过程的监督,做好项目的质量控制,定期组织项目组会议,开展数据核查和质量控制工作,必要时可邀请第三方专业质量控制团队开展。对完成的调查问卷进行抽样重复调查,并做好问题及时反馈工作。
6)数据统计分析要点 队列研究数据统计分析同样包括统计描述和统计推断。统计学描述主要是对暴露组和非暴露组研究对象的一般人口学特征、主要暴露信息和协变量信息进行描述分析,计算暴露组和非暴露组人群的观察人时数(人年数),计算累计发病率、发病密度、RR、归因危险度(attributable risk, AR)等;统计学推断主要采用卡方检验(计算RR值和95%置信区间等)、二项分布检验或泊松分布检验;趋势卡方检验、泊松回归分析等分析暴露因素的效应估计与因果关联分析。
7)常见的偏倚类别和控制 队列研究在设计、实施和资料整理分析等环节都可能导致偏倚的产生,包括选择性偏倚、失访偏倚、信息偏倚和混杂偏倚。上述偏倚产生的原因与病例对照研究类似。因此,研究人员须注意,在队列研究实施的全过程都应该采取措施,预防和控制偏倚的产生。
4 队列研究的应用
队列研究属于观察法、分析流行病学范畴,相比于现况研究和病例对照,队列研究可以计算发病率,暴露和结局的时间先后顺序更为明确,因此对暴露和疾病因果关系可以进行更深入验证。队列研究的主要用途包括:①检验病因假设,可以检验同一暴露与多种结局之间的关联;②评估预防和治疗措施效果;③用于研究疾病发生和发展的自然史。
猜你喜欢
内蒙古统计(2021年4期)2021-12-06
法律方法(2021年3期)2021-03-16
中华养生保健(2020年8期)2021-01-14
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
军营文化天地(2018年2期)2018-12-15
测控技术(2018年4期)2018-11-25
上海精神医学(2017年5期)2017-11-29
产品可靠性报告(2017年7期)2017-09-05
中华胃食管反流病电子杂志(2016年2期)2016-10-10
