
自监督学习HOG预测辅助任务下的车位检测方法
2024-01-09 02:47:32刘磊伍鹏谢凯程贝芝盛冠群
计算机应用 2023年12期
刘磊,伍鹏*,谢凯,程贝芝,盛冠群
自监督学习HOG预测辅助任务下的车位检测方法
刘磊1,伍鹏1*,谢凯1,2,程贝芝1,盛冠群3
(1.长江大学 电子信息学院,湖北 荆州 434023; 2.长江大学 西部研究院,新疆 克拉玛依 834000; 3.三峡大学 计算机与信息学院,湖北 宜昌 443002)(∗通信作者电子邮箱wupeng78@126.com)
针对智能车位管理系统中,光照变化、车位遮挡等因素导致车位预测的精度下降、有效性变差的问题,提出一种自监督学习方向梯度直方图(HOG)预测辅助任务下的车位检测方法。首先,设计预测图像遮挡部分HOG特征的自监督学习辅助任务,利用MobileViTBlock(light-weight, general-purpose, and Mobile-friendly Vision Transformer Block)综合图像全局信息,使模型更充分地学习图像的视觉表征,并提高模型的特征提取能力;其次,改进SE(Squeeze-and-Excitation)注意力机制,使模型在更低的计算开销上达到甚至高于原始SE注意力机制的效果;最后,将辅助任务训练的特征提取部分应用于下游的分类任务进行车位状态预测,在PKLot和CNRPark的混合数据集上进行实验。实验结果表明,所提模型在测试集上的准确率达到了97.49%,相较于RepVGG,遮挡预测准确率提高了5.46个百分点,与其他的车位检测算法相比进步较大。
智能停车系统;自监督学习;方向梯度直方图;辅助任务;车位状态预测
0 引言
现有停车场管理方法相对落后,且对车位资源的实时监控能力不足,迫切需要构建智能化的停车管理系统,实现停车快速有序,缓解交通拥堵。系统构建的关键是准确实时的车位检测,不仅能提高停车场资源的利用率,还能舒缓交通压力,解决停车难等问题,具有重要的现实意义。
现有的智能化停车场多数采用外部传感器检测停车位状态。外部传感器虽然可以高效、准确地获取停车位状态,但是一个地磁传感器只能检测一个车位,且设备安装维护难,成本高;基于计算机视觉的停车位状态检测方法较好地克服了以上缺点,该方法主要检测停车位中有无车辆,检测精度高且成本较低,更重要地,仅需较少的摄像头就可以覆盖整个停车场。De Almeida等[1]提出使用多个车位的纹理特征训练支持向量机(Support Vector Machine, SVM)分类器,使用SVM分类器检测车位的状态,但异常天气情况通常对检测结果影响较大;黄伟杰等[2]通过图像处理的手段自动划分车位,并用SVM分类,但对较低空或遮挡车位的检测存在较大困难;Jermsurawong等[3]提出从车位提取视觉信息后,经过特定的神经网络检测车位状态。以上这些方法都只针对特定场景或加入人工设计特征的情况。安旭骁等[4]设计了一个仅有5层的迷你卷积神经网络(Mini Convolutional Neural Network, MCNN),极大减少了参数量和计算量,但由于网络层数过少,对车位特征提取不够充分,无法应对更多的极端情况;Amato等[5]基于AlexNet[6]设计mAlexNet(mini Alex Network)并提出了新的车位检测的数据集CNRPark,mAlexNet虽然基本实现了实时高精度的检测,但对弱光照、遮挡等情况(如图1)存在检测精度低、鲁棒性弱的问题。申铉京等[7]利用Ding等[8]提出的结构重参数化方法解耦了车位检测模型训练和推理的过程,设计了相较于mAlexNet更优良的车位检测模型,但它对遮挡等复杂情况下车位的检测仍不足。结构重参数化方法对于类似VGG(Visual Geometry Group)[9]的平铺式网络模型的精度有较大提升,它的代表网络为RepVGG。

图1 两种条件下的车位示意图
虽然现有的基于视觉的车位检测方法基本可以实现较高精度的检测,但是在弱光照、遮挡等条件下的检测依旧存在困难。针对此问题,本文模型通过使用Transformer[10]对特征图重新进行线性组合综合全局信息,使用改进的注意力机制过滤无关或者干扰信息,并设计自监督学习的辅助任务增强模型在遮挡、弱光等情况下的鲁棒性,通过轻量化的设计使模型更好地平衡速度和精度。
将本文模型与MCNN、RepVGG、mAlexNet和其他传统网络模型在车位检测性能方面进行了详细对比。实验结果表明:本文模型在PKLot和CNRPark的1∶1混合测试集上的检测精度达到了97.49%,较现有的车位检测模型有较大提升;且在真实场景下的测试结果表明,本文模型仍具有较高的精度和泛化性能。本文模型在精度、泛化性能和鲁棒性等方面均取得了进步。
本文的主要工作为:
1)提出一个自监督学习方向梯度直方图(Histogram of Oriented Gradient, HOG)[11]预测辅助任务下的车位检测方法。使用自监督学习的方法设计辅助任务使网络充分地学习车位的视觉信息,提升模型的泛化性能。
2)设计了CSE(Convolutional Squeeze-and-Excitation)注意力机制模块。使用多次的一维卷积代替SE(Squeeze-and-Excitation)注意力机制[12]中的全连接层,并采用了计算量更少的激活函数,在保证原有性能的情况下极大地减少了计算量,使模型更轻、更快。
3)自制用于检验模型光照鲁棒性的Light-Change数据集,为进行不同光照强度以及阴影干扰等复杂情况下的车位检测模型鲁棒性测试提供了测试基础。
1 相关工作
1.1 HOG特征
HOG特征是一种常用的图像特征描述方法,由Dalal等[11]提出,并广泛应用于目标检测、行人识别和车辆检测等领域。HOG特征通过计算图像中不同方向梯度的直方图描述图像的局部纹理特征。具体地,HOG特征首先将图像划分为多个小单元;其次在每个单元内计算梯度的幅值和方向,并将这些信息组成一个方向直方图;最后通过对相邻单元的直方图进行归一化和连接,得到整个图像的HOG特征描述。HOG特征善于捕捉图像局部的形状和外观,同时它不仅对几何变化不敏感,还对光照的变化具有不变性,计算引入的开销也可以忽略不计。针对车位检测精度受光照变化影响较大的问题,本文使用HOG特征设计辅助任务,降低光照变化对车位检测效果的负面影响,增强模型对光照变化的鲁棒性。
1.2 注意力机制
注意力机制类比了人类对于外界事物的观察和感知。人类在感知外界事物时,通常更关注被观察事物的重要的局部特征信息,再结合事物不同部分的特征信息,实现对事物整体的认知。注意力机制是提升模型性能的重要手段之一。通过引入注意力机制,模型能够在大量的特征信息中更关注对当前任务更重要的信息,并降低对次要信息的关注度,过滤无关信息,以提高模型效率和精度。目前,注意力机制已经广泛应用于深度学习的各个领域,如自然语言处理、图像处理和语音识别等任务。它可以帮助模型更好地处理复杂的输入数据,提高模型的性能,增强模型的鲁棒性。Hu等[12]提出了用于增强神经网络对输入数据中重要特征通道关注度的SE注意力机制。SE注意力机制分为Squeeze和Excitation两个阶段:在Squeeze阶段,SE注意力机制通过全局平均池化操作压缩每个特征图的通道维度,得到一个全局描述符;在Excitation阶段,SE注意力机制利用一个多层感知机(Multi-Layer Perceptron, MLP)学习每个通道的权重,生成一个通道注意力向量。将通道注意力向量与原始特征图相乘得到加权后的特征图,以增强模型对重要特征通道的关注度。SE注意力机制可被用于各种深度神经网络结构(如VGG、ResNet[13]等),以提高模型的性能。本文改进了SE注意力机制并将改进后的SE注意力机制应用于车位检测模型,以提升本文模型的车位检测效果。
1.3 自监督学习
大多数深度学习任务通常需要首先使用主干网络(如VGG、ResNet、MobileNet[14-16]和InceptionNet[17]等)提取输入图像特征,其次将提取的特征信息用于下游的分类、检测或者分割等任务。带标签的大数据集(如ImageNet(https://image-net.org))对主干网络的特征提取能力至关重要,但这在很多领域较难实现:一方面,标签难获取;另一方面,提取的特征依赖于标签(即特定任务),而不是数据本身的特征。因此,通过监督学习训练的模型通常泛化能力较弱。
自监督学习是一种无需人工标注数据就能够自我学习的机器学习方法。自监督学习方法避免了有监督学习中对数据标注和数据量需求大的问题。相较于有监督学习,自监督学习可以利用原始数据进行训练,无需手动标注每个样本,降低了人工成本,扩展了数据集规模,提高了模型泛化能力;因此,自监督学习在深度学习领域备受关注。在相关领域的研究中,已经提出了各种各样的自监督学习方法,并取得了不错的效果。例如:基于图像的自监督学习方法可以通过旋转、裁剪和颜色变换等方式生成大量的训练数据,提高模型的泛化能力;基于对比损失的自监督学习方法,如MoCo(Momentum Contrast for unsupervised visual representation learning)算法[18]和SimCLR(Simple framework for Contrastive Learning of visual Representations)算法[19],通过最大化同一个样本的不同视角之间的相似性训练模型;BERT(Bidirectional Encoder Representations from Transformers)模型[20]是一种基于文本的自监督学习方法,通过遮挡部分文本并让模型预测被遮挡的内容训练模型。
MAE(Masked AutoEncoders)算法[21]随机遮挡图片中的部分图像块,让模型重建这些丢失的区域,以此提升模型对图像视觉特征的理解能力。Wei等[22]提出了MaskFeat(Masked Feature prediction)算法,通过设计预测图像遮挡部分HOG特征的自监督学习辅助任务,极大地缓解了MAE算法在高频部分特征丢失的问题,同时减少了运算开销。针对监督学习的缺陷,受MAE算法和MaskFeat算法的启发,本文通过设计图像遮挡部分HOG特征预测的自监督学习方法提升模型的泛化性能。
2 本文模型
为了提高对不同环境下停车场车位检测的精度和算法的泛化性能,本章设计一种自监督学习HOG特征预测辅助任务下的车位检测方法。
2.1 辅助任务设计
本节设计预测图像遮挡部分HOG特征的辅助任务。首先将图像划分成一系列不重合的图像块;其次随机地遮挡图片中若干个相邻的图像块(如图2所示);再次在给定剩余图像块的情况下预测被遮挡部分的HOG特征,以帮助模型更好地理解图像中的物体和空间纹理信息,从而提升模型的车位检测效果。例如,为了正确预测图2中被遮挡部分的车位的HOG特征,必须首先根据未遮挡的部分识别对象,并知道该类对象通常的出现形式,以修复被遮挡部分。

图2 车位样本示意图
在对图像可见部分进行特征提取时,本文考虑两个问题:1)虽然卷积神经网络(Convolutional Neural Network, CNN)已有的轻量化模型计算成本低且易于训练,但卷积操作在空间上只能提取局部特征;2)ViT(Vision Transformer)系列模型[23]通过学习像素的线性组合将空间信息转化为潜在信息后,使用Transformer对全局信息进行编码学习,从而学习图像的全局信息,但是它忽略了CNN模型的空间归纳偏置,导致需要更多的参数学习视觉表征,且这类模型的可优化性较差。基于上述两个问题,本文采用MobileViTBlock(light-weight, general-purpose, and Mobile-friendly Vision Transformer Block)结构[24]将卷积学习局部特征的方法用Transformer的全局特征表示方法代替,使模型学习的信息既包括局部信息又包括全局信息。本文网络的特征提取部分主要由如图3所示的3个Block组成。
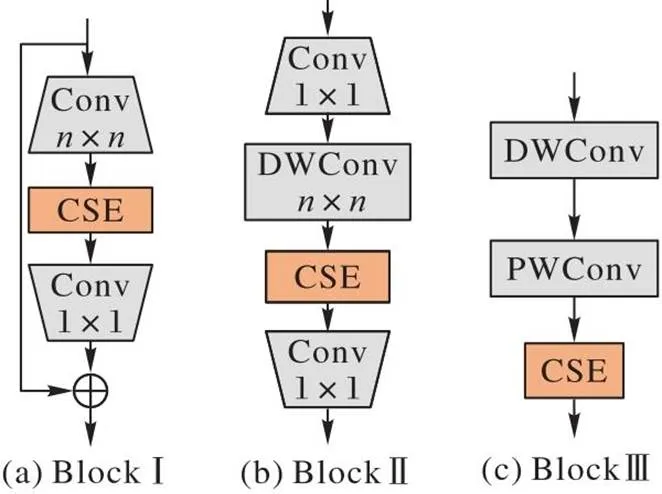
图3 特征提取部分的Block结构示意图
为使模型更关注图像的可见部分,本文在特征提取的过程中加入CSE注意力机制(如图4所示),将SE的Sequeeze阶段的全连接层使用次一维卷积代替;Excitation阶段的全连接层使用上采样(Upsampling)代替。同时,对于ReLU(Rectified Linear Unit)和Sigmoid激活函数,本文使用文献[16]中改进的hard-swish和hard-Sigmoid激活函数代替。这不仅能减少注意力层所需的参数量,降低过拟合的风险,还能在减少运算开销的情况下提升模型的性能。
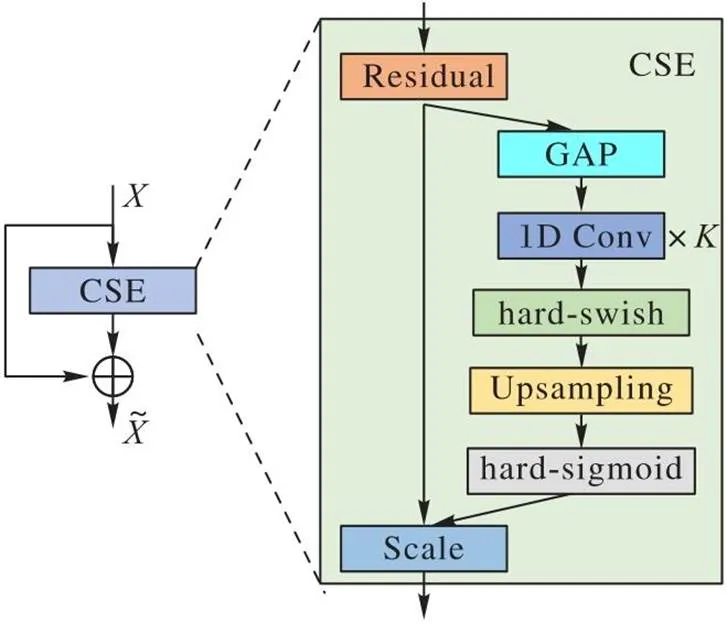
图4 CSE注意力机制的结构
注意力机制热图是在应用注意力机制时生成的一种可视化热图,用于展示模型在输入图像上的注意力分布情况。利用注意力热图可以直观地呈现模型对输入的关注程度,从而更好地对比CSE与SE的效果。图5为CSE与SE的效果对比,可见,CSE与SE的整体效果差距不大,甚至略胜于SE,且在参数量上远小于SE。因此,在图3的3种不同的Block中,本文都加入了CSE注意力机制。

图5 CSE与SE的效果对比
首先,使用了一个3×3的普通卷积对整个输入图像进行通道扩张和下采样(Downsampling)。其次,通过连续的4个卷积块进行特征提取。由于在浅层网络中使用深度卷积会降低速度[25],因此本文前3个卷积块使用了以标准卷积为基础带有残差连接的Block Ⅰ。在深层网络中,通道间的特征通常更重要,深度可分离卷积通过分步的卷积操作能够更好地提取通道之间的关系从而提高模型的表现能力,同时也可以减少参数量、降低计算复杂度,并有效地避免了过拟合问题[14]。因此,本文第4个卷积块使用以深度可分离卷积为基础的Block Ⅱ,以更好地搭配CSE通道注意力机制。再次,本文引入了MobileViTBlock结构[24]综合图像的局部信息和全局信息,使模型能够更好地预测图像遮挡部分的HOG特征。继次,使用3×3的普通卷积将MobileViTBlock输出的特征图下采样为与原图像提取的HOG特征图同尺寸的特征图。最后,通过Linear层映射得到预测的HOG特征图。
辅助任务训练过程中的损失仅对被遮挡的图像块进行计算。本文采用图像遮挡部分的余弦相似度作为评判辅助任务的HOG特征预测效果的指标:
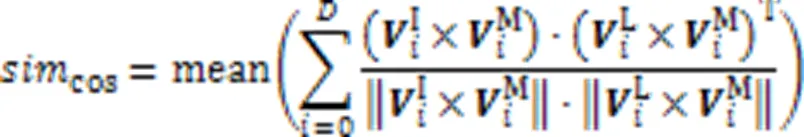
辅助任务的整体流程如图6所示,其中MVIT Block为MobileViTBlock的缩写。
2.2 车位状态分类
经过辅助任务训练的模型可以充分学习图像的视觉信息,在完成图像分类任务时,通常比传统的CNN具有更强的泛化性能。停车位的状态通常分为空闲和占用两种,因此可以将1.2节的车位状态分类看作一个简单的二分类问题。
推理过程的网络结构如图7所示,本文在自监督学习的下游任务时,首先舍弃了辅助任务中最后用于通道调整的1×1卷积;其次对MobileViTBlock的输出特征继续使用2个BlockⅢ归纳提取特征并将特征图下采样为原来的1/4,得到7×7的特征图。其中,第2个BlockⅢ使用5×5的卷积核,这是因为大卷积核对全局信息的提取能力通常优于堆叠小卷积核达到相同感受野的组合块,且仅在网络尾部使用5×5的卷积核替换3×3的卷积核就可以达到替换网络所有层的效果[26],所以本文仅在网络的尾部做了这一替换操作。再次,使用1×1卷积、GAP(Global Average Pooling)和1×1卷积进行通道压缩、全局平均池化和通道再压缩。最后,通过Linear层输出分类结果,实现对车位状态的分类。
在实验过程中,本文使用了ImageNet100数据集(https://www.kaggle.com/datasets/ambityga/imagenet100)预训练辅助任务,并将预训练得到的参数应用于新的分类网络。随后,在现有的车位检测数据集上进行了微调。

图6 辅助任务的整体流程
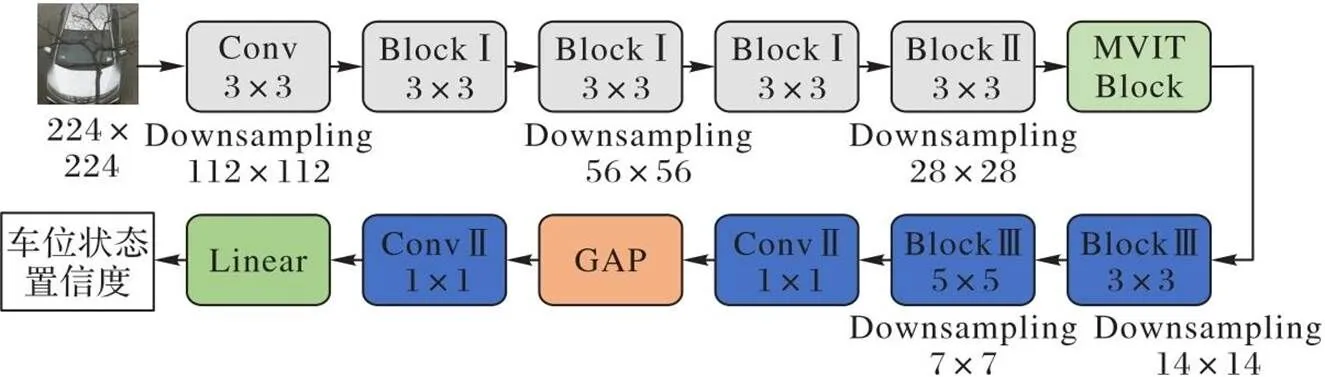
图7 推理过程的网络结构
使用本文网络的最后的输出特征图(即BlockⅢ的输出特征图)对遮挡车位进行注意力可视化(如图8)。可见,本文模型在处理遮挡问题时,能够更准确地关注和提取关键特征。未被遮挡的部分在注意力热图中明显被高亮,这证明了模型在处理遮挡车位时,不会被遮挡物所干扰,而是能够聚焦于有效的信息区域,这进一步证明了本文模型对于遮挡情况具有极强的鲁棒性。

图8 注意力可视化结果
3 实验与结果分析
为验证本文方法的有效性,本章将从数据集使用和对比分析两个方面对实验结果进行分析验证。本文实验所使用的计算机软硬件配置如表1所示。

表1 计算机软硬件配置
实验中,将所有车位图像的大小统一转化为224×224。训练时,BatchSize设置为16,迭代10轮,使用随机梯度下降算法,初始学习率设置为0.01,学习率衰减采用余弦退火策略,权重衰减设置为5×10-5,动量设置为0.9。通过随机水平翻转、随机改变图像的亮度、对比度、饱和度和色调等手段进行图像增强。
3.1 数据集扩充
现有的车位检测数据集PKLot[1]和CNRPark[5]将不同天气场景主要分为SUNNY、RAINY和CLOUDY(OVERCAST)这3种情况。其中:PKLot是主要针对无遮挡条件下的停车场的车位检测数据集;CNRPark是针对遮挡条件下的车位检测数据集。针对目前已有的车位检测数据集中复杂光照情况的数据样本较少、现有模型在复杂光照条件下的车位检测精度较低的问题,本文以复杂光照条件为原则,自制了一个用于本文实验的包含复杂光照情况的车位检测数据集——Light-Change数据集(以下简称为LC数据集)。该数据集综合了不同时间段中的各种光照强度的车位样本,用于检验模型在光照影响剧烈的情况下的鲁棒性。图9为LC数据集中的部分样图。

图9 Light-Change数据集示例
3.2 消融实验
针对本文设计的自监督学习的辅助任务的有效性进行了消融实验。
在进行消融实验时,本文选取的模型性能参数包括准确率、精确度、召回率、F1分数、浮点计算量、推理时间和参数量。F1分数能够找到精确度和召回率之间的平衡,是一个用于分析模型性能的综合的评价指标,可以更充分地检验模型的优劣性。
由于PKLot数据集中存在两个不同停车场的车位信息,本文采用交叉验证的方法检验模型的泛化性能。在PUCPR和UFPR两个停车场中各自随机选取了50 000张车位图片,并分别按照8∶2划分训练集和验证集进行训练。测试时,本文使用了两种测试方法(C1和C2):C1使用PUCPR停车场的数据进行训练,UFPR停车场的数据进行测试;C2使用UFPR停车场的数据进行训练,PUCPR停车场的数据进行测试。
本文对比了模型1(未使用自监督学习辅助任务的预训练权重)和模型2(使用自监督学习辅助任务的预训练权重)在C1和C2两种条件下的准确率和F1分数,以验证本文设计的自监督学习辅助任务的有效性。实验结果如表2所示。
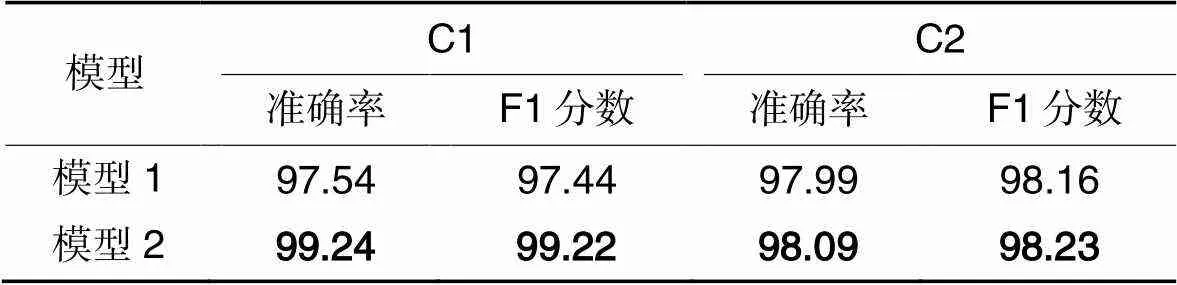
表2 两种模型在C1和C2条件下的检测性能对比 单位:%
由表2的实验数据可知,模型2在C1和C2两种条件下的性能都优于模型1,由此可以验证本文设计的自监督学习辅助任务的有效性。
此外,本文还对比了原始SE注意力机制与CSE注意力机制在本文模型上的应用效果,主要体现在准确率、F1分数、参数量以及浮点计算量这4个方面。具体实验结果如表3所示。
表3C1和C2条件下两种注意力机制应用在本文模型上的效果对比
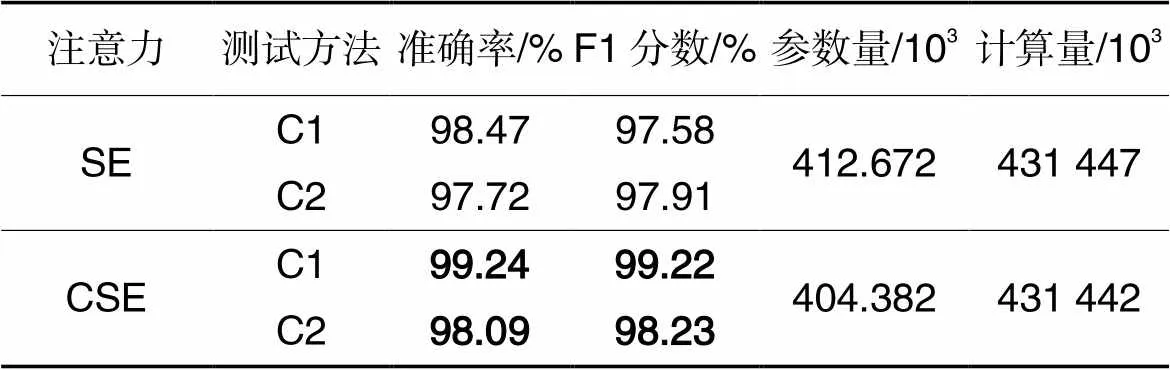
Tab.3 Comparison of effects of two attention mechanisms applying on proposed model under C1 and C2 conditions
从表3可知,CSE注意力机制在C1和C2两种条件下应用于本文模型相较于原始的SE注意力机制,在准确率上分别提高了0.77和0.37个百分点,在F1分数上分别提高了1.64和0.32个百分点;同时在参数量和计算量上也均减少,可以看出本文对SE注意力机制改进的有效性。
3.3 对比分析
将本文模型与传统的CNN(如AlexNet、VGG和ResNet等)以及mAlexNet、MCNN、RepVGG进行对比。为充分检验模型的性能,本文设计了3个实验分别检验模型的泛化性能、对遮挡的鲁棒性和光照的鲁棒性。为保证实验的严谨性,本文实验数据采用了3次实验取平均值的方法进行处理。
表4中为本文模型与其他网络模型在C1和C2条件下的性能对比。从表4的对比结果可知,本文模型在C1条件下各项指标均最优。在C2条件下,本文模型的准确率和F1分数表现最优;然而,精确度和召回率未达到最优状态,这是因为PUCPR停车场的车位图像的原始尺寸相对UFPR停车场的图像较小。在将这些图像调整为网络输入大小时,图像的梯度特征受到了更大程度的削弱,从而影响了精确度和召回率的表现。
表4不同模型在C1和C2条件下的检测性能对比 单位:%
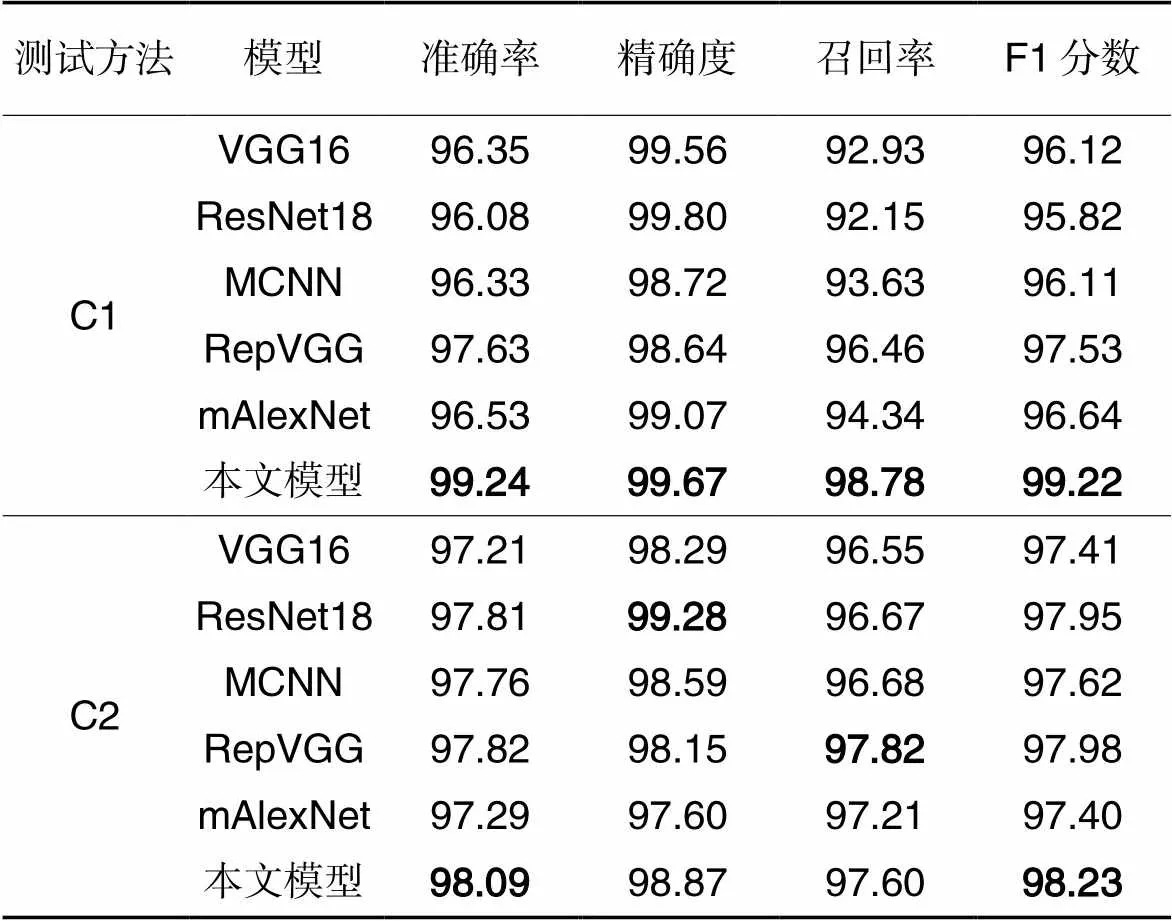
Tab.4 Comparison of detection performance of different models under C1 and C2 conditions unit:%
为检验模型对遮挡车位的鲁棒性,本文将PKLot数据集与CNRPark数据集的部分数据按照1∶1混合训练,将训练得到的权重用于模型的鲁棒性检测。为保证训练集、验证集和测试集这三者之间的数据没有交叉,在划分训练集、验证集和测试集时,对于PKLot,本文按照PUCPR、UFPR04和UFPR05分别对应随机选取部分数据;对于CNRPark,本文按照它的摄像机标号划分数据集,在1、4、5、6和8号相机拍摄的数据中随机选取部分数据放入训练集,在3、7号相机拍摄的数据中随机选取部分数据放入验证集,在2、9号相机拍摄的数据中随机选取部分数据放入测试集。表5中的3种遮挡情况的车位数据均来自上述划分好的测试集。
将2、9号相机拍摄的数据中有遮挡的车位的图像按照遮挡程度的不同划分为轻度遮挡(遮挡1/3以下)、中度遮挡(遮挡1/3到2/3)、重度遮挡(遮挡2/3以上)这3种车位样本。
从表5中可以看出,本文模型对不同遮挡情况下的准确率相较于mAlexNet、MCNN和RepVGG都有明显优势,相较于RepVGG提高了5.46个百分点,说明了本文模型对遮挡有着更强的鲁棒性。
为检验模型对光照变化的鲁棒性,本文使用了LC数据集,并对本文模型、mAlexNet、MCNN和RepVGG进行比较,结果如表6所示。
从表6可以看出,以上4种模型对于强光、阴影、幽暗等条件下的检测准确率都有所降低,但本文模型使用了辅助任务预训练权重,相较于其他3种模型都有所提升。
最后,对比本文模型与其他对比模型在浮点计算量、参数量和单个车位的推理时间,对比结果如表7所示。
从以上实验结果可以看出,本文模型对于车位状态的检测相较于其他对比模型在精度和速度上有着更好的平衡。
表5测试集上不同模型在不同遮挡条件下的准确率对比 单位:%
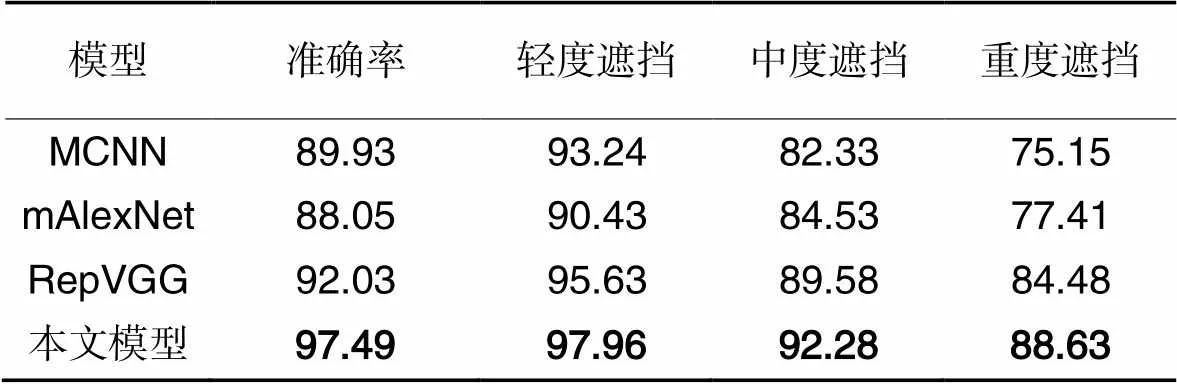
Tab.5 Accuracy comparison of different models under different occlusion conditions on test set unit:%
表6不同模型在LC数据集上的检测性能对比 单位:%
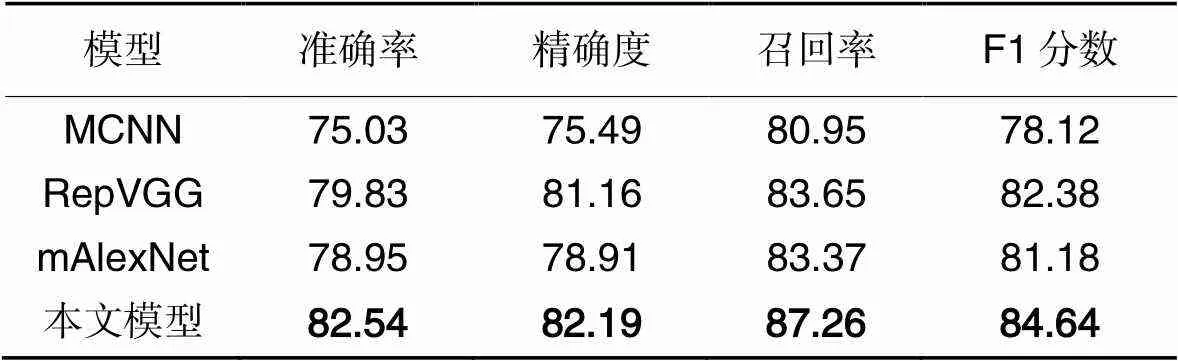
Tab.6 Comparison of detection performance of different models on LC dataset unit:%
表7不同模型的计算量、参数量和推理时间对比
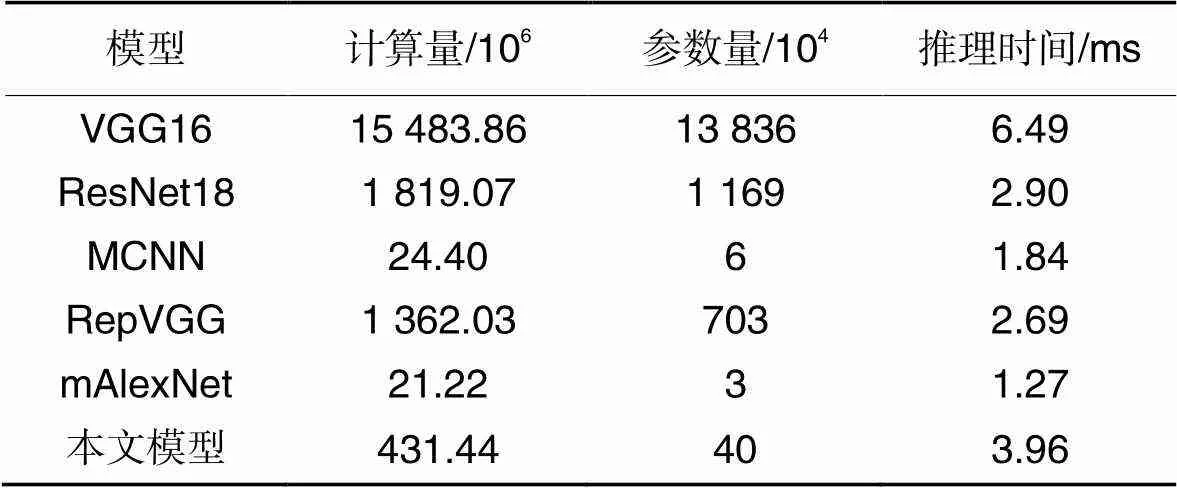
Tab.7 Comparisons of computational cost, parameter number and reasoning time of different models
4 停车场实地效果
为了验证模型在真实停车场环境下的性能,实现真正落地,对比本文模型与现有模型在真实停车场环境下的检测效果,对一处户外停车场的车位状态进行了检测。首先,通过labelimg应用程序对停车场的监控视频中的车位进行了人工标注,并将它们存入.xml文件。其次,在车位状态检测过程中,使用提前标注好的车位信息,切分该摄像头有效覆盖的停车位的图片,并将分割的停车位图片通过插值的方式放大,并以图像中心为标准点裁剪成相同大小的图像。最后,将它们输入测试模型进行车位状态检测。图10为停车场中某一监控摄像头的检测结果,其中实线框为占用,虚线框为空闲。
从图10中两幅真实停车场环境下的预测结果可以看出,虽然本文模型与其他对比模型在面对复杂的地面纹理时均出现了错误,但是在面对遮挡状况时,本文模型相较于其他模型表现了更好的预测效果。可见,在真实的停车场环境下本文模型相较于其他模型依然有着较高的准确率和鲁棒性。

图10 不同模型对停车场中某一监控摄像头的检测结果
5 结语
针对现有的智能停车场车位检测在受到外界环境变化影响时适应能力变差、模型推理速度低等问题,本文提出了一个自监督学习HOG预测辅助任务下的车位检测方法,以求模型在弱光、遮挡等环境下寻找到速度和精度之间的良好平衡。通过设计辅助任务使模型能够更充分地学习图像的视觉信息以提升模型特征提取能力,提高了模型的泛化性能,使模型更能适应不同的外界环境。同时,提出分类网络和CSE注意力机制,使模型能够更好地利用所学的视觉信息进行精准分类。实验结果表明,本文模型具有较高的分类准确性和很强的泛化性能,能够显著提高停车场车位的使用效率,缓解停车场停车难、交通拥堵等问题。但目前本文模型还不能完全解决所有的问题,例如在极昏暗或冬季雪天积雪覆盖停车位等情况下的车位状态预测精度难以保证。
为了进一步提高模型在极端环境下的车位状态预测精度,未来的工作包括两个方向:1)改进模型。通过引入更强大的特征提取技术,优化模型的训练策略,以提高模型对复杂环境的适应能力;2)改善数据集中的样本不均匀问题。通过增加在极端环境下的样本数量,提高模型对这些环境的理解和预测能力。
[1] DE ALMEIDA P R L, OLIVEIRA L S, BRITTO A C, Jr, et al. PKLot — a robust dataset for parking lot classification[J]. Expert Systems with Applications, 2015, 42(11):4937-4949.
[2] 黄伟杰,张希,赵柏暄,等. 基于视觉的停车场车位检测与分类算法[J]. 计算机系统应用, 2022, 31(3):234-240.(HUANG W J, ZHANG X, ZHAO B X, et al. Vision-based parking space detection and classification algorithm[J]. Computer Systems and Applications, 2022, 31(3):234-240.)
[3] JERMSURAWONG J, AHSAN U, HAIDAR A, et al. One-day long statistical analysis of parking demand by using single-camera vacancy detection[J]. Journal of Transportation Systems Engineering and Information Technology, 2013, 14(2): 33-44.
[4] 安旭骁,邓洪敏,史兴宇. 基于迷你卷积神经网络的停车场空车位检测方法[J]. 计算机应用, 2018, 38(4): 935-938.(AN X X, DENG H M, SHI X Y. Parking lot space detection method based on mini convolutional neural network[J]. Journal of Computer Applications, 2018, 38(4): 935-938.)
[5] AMATO G, CARRARA F, FALCHI F, et al. Deep learning for decentralized parking lot occupancy detection [J]. Expert Systems with Applications, 2017, 72: 327-334.
[6] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks[C]// Proceedings of the 25th International Conference on Neural Information Processing Systems — Volume 1. Red Hook, NY: Curran Associates Inc., 2012: 1097-1105.
[7] 申铉京,刘同壮,王玉,等. 基于卷积网络结构重参数化的车位状态检测算法[J]. 吉林大学学报(工学版), 2022, 52(12): 2898-2905.(SHEN X J, LIU T Z, WANG Y, et al. Detection algorithm for parking space status based on of convolution network structural re-parameterization[J]. Journal of Jilin University (Engineering and Technology Edition), 2022, 52(12): 2898-2905.)
[8] DING X, ZHANG X, MA N, et al. RepVGG: making VGG-style ConvNets great again[C]// Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2021: 13728-13737.
[9] SIMONYAN K, ZISSERMAN A. Very deep convolutional networks for large-scale image recognition [EB/OL]. (2015-04-10)[2021-04-20].https://arxiv.org/pdf/1409.1556.pdf.
[10] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017: 6000-6010.
[11] DALAL N, TRIGGS B. Histograms of oriented gradients for human detection[C]// Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition — Volume 1. Piscataway: IEEE, 2005: 886-893.
[12] HU J, SHEN L, SUN G. Squeeze-and-excitation networks[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 7132-7141.
[13] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778.
[14] HOWARD A G, ZHU M, CHEN B, et al. MobileNets: efficient convolutional neural networks for mobile vision applications [EB/OL]. (2017-04-17)[2021-06-05].https://arxiv.org/pdf/1704.04861.pdf.
[15] SANDLER M, HOEARD A, ZHU M, et al. Inverted residuals and linear bottlenecks: mobile networks for classification, detection and segmentation[EB/OL]. (2018-01-13)[2021-06-20]. https://arxiv.org/pdf/1801.04381v1.pdf.
[16] HOWARD A, SANDLER M, CHEN B, et al. Searching for MobileNetV3[C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 1314-1324.
[17] SZEGEDY C, VANHOUCKE V, IOFFE S, et al. Rethinking the inception architecture for computer vision [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016:2818-2826.
[18] HE K, FAN H, WU Y, et al. Momentum contrast for unsupervised visual representation learning [C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2020: 9726-9735.
[19] CHEN T, KORNBLITH S, NOROUZI M, et al. A simple framework for contrastive learning of visual representations [C]// Proceedings of the 37th International Conference on Machine Learning. New York: JMLR.org, 2020: 1597-1607.
[20] DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding [C]// Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long and Short Papers). Stroudsburg, PA, ACL, 2019: 4171-4186.
[21] HE K, CHEN X, XIE S, et al. Masked autoencoders are scalable vision learners[C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 15979-15988.
[22] WEI C, FAN H, XIE S, et al. Masked feature prediction for self-supervised visual pre-training [C]// Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2022: 14648-14658.
[23] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[EB/OL]. (2021-06-03)[2022-03-21].https://arxiv.org/pdf/2010.11929.pdf.
[24] MEHTA S, RASTEGARI M. MobileViT: light-weight, general-purpose, and mobile-friendly vision transformer [EB/OL]. (2022-03-04)[2022-05-16].https://arxiv.org/pdf/2110.02178.pdf.
[25] TAN M, LE Q. EfficientNetV2: smaller models and faster training[C]// Proceedings of the 38th International Conference on Machine Learning. New York: JMLR.org, 2021: 10096-10106.
[26] CUI C, GAO T, WEI S, et al. PP-LCNet: a lightweight CPU convolutional neural network[EB/OL]. (2021-09-17)[2022-05-12].https://arxiv.org/pdf/2109.15099.pdf.
Parking space detection method based on self-supervised learning HOG prediction auxiliary task
LIU Lei1, WU Peng1*, XIE Kai1,2, CHENG Beizhi1, SHENG Guanqun3
(1,,434023,;2,,834000,;3,,443002,)
In the intelligent parking space management system, a decrease in accuracy and effectiveness of parking space prediction can be caused by factors such as illumination changes and parking space occlusion. To overcome this problem, a parking space detection method based on self-supervised learning HOG (Histogram of Oriented Gradient) prediction auxiliary task was proposed. Firstly, a self-supervised learning auxiliary task to predict the HOG feature in occluded part of image was designed, the visual representation of the image was learned more fully and the feature extraction ability of the model was improved by using the MobileViTBlock (light-weight, general-purpose, and Mobile-friendly Vision Transformer Block) to synthesize the global information of the image. Then, an improvement was made to the SE (Squeeze-and-Excitation) attention mechanism, thereby enabling the model to achieve or even exceed the effect of the original SE attention mechanism at a lower computational cost. Finally, the feature extraction part trained by the auxiliary task was applied to the downstream classification task for parking space status prediction. Experiments were carried out on the mixed dataset of PKLot and CNRPark. The experimental results show that the proposed model has the accuracy reached 97.49% on the test set; compared to RepVGG, the accuracy of occlusion prediction improves by 5.46 percentage points, which represents a great improvement compared with other parking space detection algorithms.
intelligent parking system; self-supervised learning; Histogram of Oriented Gradient (HOG); auxiliary task; parking space status prediction
This work is partially supported by National Natural Science Foundation of China (42204111).
LIU Lei, born in 2002. His research interests include image processing,artificial intelligence.
WU Peng, born in 1978, M. S., associate professor. His research interests include image processing, artificial intelligence.
XIE Kai, born in 1974, Ph. D., professor. His research interests include signal and information processing, image processing, artificial intelligence.
CHENG Beizhi, born in 2002. Her research interests include image processing, artificial intelligence.
SHENG Guanqun, born in 1987, Ph. D., associate professor. His research interests include artificial intelligence, signal and information processing.
TP389.1
A
1001-9081(2023)12-3933-08
10.11772/j.issn.1001-9081.2022111687
2022⁃11⁃10;
2023⁃05⁃23;
2023⁃05⁃29。
国家自然科学基金资助项目(42204111)。
刘磊(2002—),男,山东青岛人,主要研究方向:图像处理、人工智能;伍鹏(1978—),男,湖北黄冈人,副教授,硕士,主要研究方向:图像处理、人工智能;谢凯(1974—),男,湖北荆州人,教授,博士,主要研究方向:信号与信息处理、图像处理、人工智能;程贝芝(2002—),女,湖北黄冈人,主要研究方向:图像处理、人工智能;盛冠群(1987—),男,山东东营人,副教授,博士,主要研究方向:人工智能、信号与信息处理。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
汽车画刊(2020年5期)2020-10-20 05:37:35
祝您健康·文摘版(2020年3期)2020-04-09 04:47:27
电子制作(2018年9期)2018-08-04 03:31:18
现代家长(2018年11期)2018-01-05 11:22:22
传媒评论(2017年3期)2017-06-13 09:18:10
电子制作(2016年15期)2017-01-15 13:39:21
少年博览·初中版(2016年11期)2016-11-30 05:02:05
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
中国石油石化(2015年17期)2015-06-01 12:21:42
