
基于协同融合网络的代码搜索模型
2024-01-09 03:59:32宋其洪刘建勋扈海泽张祥平
计算机应用 2023年12期
宋其洪,刘建勋*,扈海泽,张祥平
基于协同融合网络的代码搜索模型
宋其洪1,2,刘建勋1,2*,扈海泽1,2,张祥平1,2
(1.服务计算与软件服务新技术湖南省重点实验室(湖南科技大学),湖南 湘潭 411201; 2.湖南科技大学 计算机科学与工程学院,湖南 湘潭 411201)(∗通信作者电子邮箱904500672@qq.com)
搜索并重用相关代码可以有效提高软件开发效率。基于深度学习的代码搜索模型通常将代码片段和查询语句嵌入同一向量空间,通过计算余弦相似度匹配并输出相应代码片段;然而大多数模型忽略了代码片段与查询语句间的协同信息。为了更全面地表征语义信息,提出一种基于协同融合的代码搜索模型BofeCS。首先,采用BERT(Bidirectional Encoder Representations from Transformers)模型提取输入序列的语义信息并将它表征为向量;其次,构建协同融合网络提取代码片段和查询语句间分词级的协同信息;最后,构建残差网络缓解表征过程中的语义信息丢失。为验证BofeCS的有效性,在多语言数据集CodeSearchNet上进行实验。实验结果表明,相较于基线模型UNIF(embedding UNIFication)、TabCS(Two-stage attention-based model for Code Search)和MRCS(Multimodal Representation for neural Code Search),BofeCS的平均倒数排名(MRR)、归一化折损累计增益(NDCG)和前位成功命中率(SR@)均有显著提高,其中MRR值分别提升了95.94%、52.32%和16.95%。
软件开发;代码搜索;协同融合;BERT;残差网络
0 引言
随着开源代码数量不断增长,从大型代码库中搜索和重用代码已经成为提高软件开发效率的主要方法之一。开发人员在搜索工具中输入查询语句,搜索工具在开源代码库(如Github)中进行搜索匹配,进而推荐最相似的代码片段供开发人员选择和重用。因此,准确地为开发人员推荐符合需求的代码片段对软件工程的发展具有十分重要的意义。
然而,当前基于深度学习的代码搜索模型并没有完全捕获代码片段和查询语句之间的关系[1-3]。图1是一个代码-查询对示例,大多数模型只能将查询语句中的分词“file”同代码片段中的分词“filewriter”和“File”等分词联系起来,因为其中都含有关键词“file”;然而,从深层语义联系层面,分词“file”与代码片段中的分词“content”和“write”也有强联系。在真实的代码搜索任务中,查询语句和代码库中的候选代码同样存在这种深层语义联系,即协同信息。若模型无法完全感知代码片段和查询语句间的关系,势必影响表征向量的完整性,进一步影响代码搜索的准确性。

图1 代码-查询对示例
针对当前代码搜索模型对协同信息考虑不足的问题,本文提出一种代码搜索模型BofeCS。首先采用BERT (Bidirectional Encoder Representations from Transformers)模型提取语义信息并表征为向量。其次,在计算机视觉(Computer Vison, CV)和自然语言处理(Natural Language Processing, NLP)领域,一些研究者应用协同注意力机制捕获多输入信息间的相关性[4-6]。受此启发,构建协同融合网络提取代码片段和查询语句间分词级协同信息。最后,受CV领域的残差机制[7]启发,构建残差网络弥补表征过程中语义信息丢失。最终融合协同信息生成语义信息相对完整的表征向量,通过计算代码片段和查询语句间向量距离,实现最优代码匹配。
为验证BofeCS的有效性,在CodeSearchNet数据集[8]上进行对比分析,并选择UNIF(embedding UNIFication)[9]、TabCS(Two-stage attention-based model for Code Search)[10]和MRCS(Multimodal Representation for neural Code Search)[11]这3种先进方法作为基线模型;同时构建了一系列实验,验证BofeCS的结构合理性,并探索具体细节以优化模型性能。
本文的主要工作如下:1)提出一种高效的代码搜索模型BofeCS,它可以捕获代码片段和查询语句间的深层联系,帮助开发人员快速准确地搜索相关代码。2)通过构建协同融合网络充分感知语义关联,捕获代码片段和查询语句间的协同信息。3)通过构建残差结构,有效缓解语义特征表征过程中的信息丢失。
1 相关工作
代码搜索是采用查询语句描述需求以搜索相应功能的代码片段,供开发人员重用以高效编码。目前,代码搜索的研究主要包含查询扩展(Query Expansion,QE)和代码表征模型两方面。
1.1 查询扩展
相较于代码注释,查询语句较短,它所包含的语义信息通常无法全面表达开发人员的查询意图。因此,基于QE的研究提高了需求描述的完整性,进而提高了代码搜索的准确性。该流程如式(1)所示:
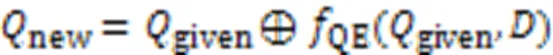
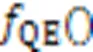
目前,QE研究主要集中于扩展同义词的方法[12-14]。例如:Liu等[15]提出神经查询扩展(Neural QE, NQE)方法,使模型接受一组关键字并预测一组与基础语料库中查询关键字共同出现的关键字,实现QE;Wang等[16]结合强化学习与QE以提升QE的能力;基于变化序列的语义信息,Zou等[17]提出了一种新型查询方法QESC(QE method based on Semantics of Change sequences),可以从与查询语义相似的变化中提取相关的术语以扩展查询;Hu等[18]提出代码描述挖掘框架CodeMF(Code-description Mining Framework),以消除噪声帖子并从编程论坛中提取高质量的软件库,应用于QE以提高代码搜索的性能;由于检索到的方法大多不能直接满足用户需求,Wu等[19]基于检索到方法后可能发生的改变这一观察,提出预测改变意图的QE方法。
1.2 代码表征模型
由于自然语言和编程语言存在较大的语义鸿沟,所以通过构建表征模型将代码片段和查询语句嵌入同一向量空间,以缩小两者之间的语义鸿沟,探索两者间的联系。具体流程如图2所示,代码片段和查询语句作为模型输入,分别经过代码片段和自然语言编码器编码,嵌入为代码片段和查询语句向量,通过计算向量相似度以推荐相关代码片段。
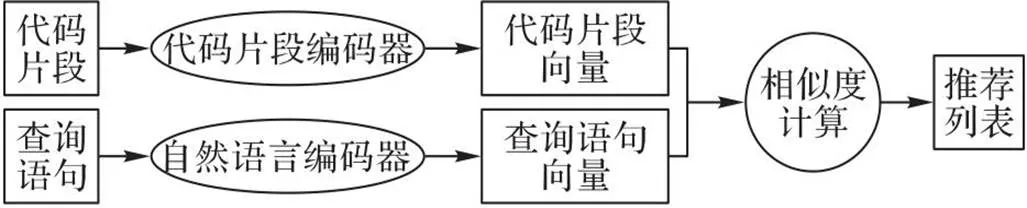
图2 基于深度学习的代码搜索流程
近几年,基于深度学习的代码表征模型成为研究的热点,例如:Gu等[3]首次将深度学习与代码搜索结合提出DeepCS(Deep Code Search)模型,使用两个长短期记忆人工神经网络分别嵌入代码片段和查询语句的语义信息,学习其中的语义关联以实现代码匹配;基于DeepCS,COSEA(Convolutional cOde SEarch with layer-wise Attention)模型[20]使用卷积神经网络捕捉代码结构信息以丰富表征向量的语义信息;Cambronero等[9]提出有监督的代码搜索模型UNIF,使用基于注意力的权重机制结合每个分词向量生成代码表征,通过求查询语句分词向量均值生成查询语句表征;Xu等[10]提出TabCS,通过双阶段注意力机制考虑模型输入特征间的关系表征代码和查询语句;基于图嵌入技术,Ling等[21]提出的DGMS(Deep Graph Matching and Searching for semantic code retrieval)模型将代码片段和查询语句用图结构表示,并构建基于图的匹配和搜索模型检索最佳匹配代码;Wang等[22]尝试构建图神经网络以增强对代码的表征能力。一些研究针对二进制代码的相似性优化代码搜索[23]。在模型输入的预处理方面,ASTNN(AST-based Neural Network)方法[24]切分表示代码结构的抽象语法树(Abstract Syntax Tree, AST),生成语句级的表征向量,增强了代码表征的完整性。Gu等[11]提出新型多模态表征模型MRCS(Multimodal Representation for neural Code Search)。针对代码提出基于AST遍历和采样的4种树序列,分别与代码分词结合作为多模态代码表征;针对查询语句,使用它的分词作为单模态表征。为了探索模型的普适性,AdaCS(Adaptive deep Code Search)方法[25]嵌入特定领域的词汇并匹配句法模式,将匹配特征转移到新的代码库中以降低训练成本。
1.3 协同注意力机制
注意力机制使深度学习模型可以专注于数据的重要部分。由于多数模型的输入包含多种模态信息,为了捕获输入信息间的映射语义关系,研究者们提出了协同注意力机制[4-6]。该机制主要采用注意力机制探寻多个输入间交互关系中的重要部分,捕获多输入间的映射语义信息。例如:Ma等[26]基于协同注意力机制针对多标签文本分类任务提出一种改进的多步多分类模型,具体使用协同注意力机制分析原文和引导标签之间的联系,有助于过滤错误预测引起的错误累积问题;Zhang等[27]提出基于协同注意力机制的网络捕获情感分析中方面(Aspect)和上下文之间的关系,为给定句段分配正确的极性;Shuai等[28]将协同注意力机制应用于基于卷积神经网络的模型,捕获输入数据的联系,提高代码表征的能力。
2 BofeCS
2.1 整体架构
BofeCS的架构如图3所示,包括三个模块:第一模块将预处理得到的代码片段和查询语句向量分别送入BERT完成语义嵌入;第二模块构建协同融合网络生成协同矩阵以捕获代码片段和查询语句之间分词级的协同信息,突出关键语义特征,降低噪声;第三模块构建残差网络,将协同信息作为语义残差,弥补模型训练过程中丢失的语义信息,得到代表代码片段和查询语句语义特征的完整表征向量。最后,通过计算余弦相似度匹配代码片段向量与查询语句向量,推荐最优的代码片段。
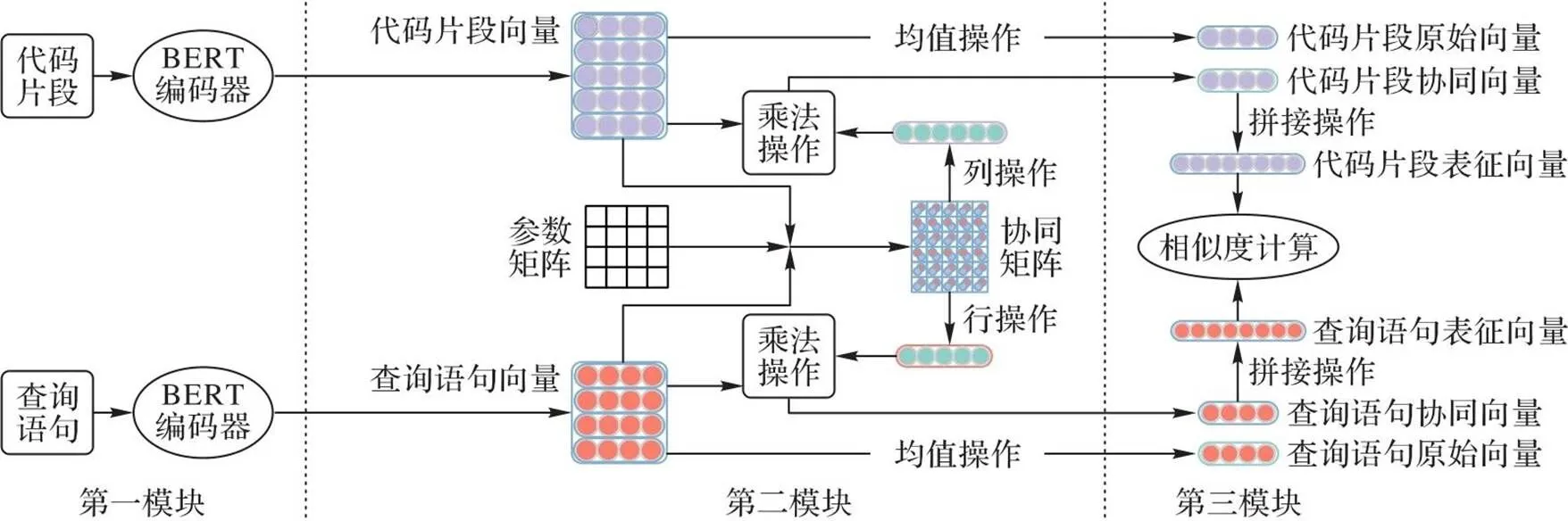
图3 BofeCS的整体架构
2.2 语义嵌入
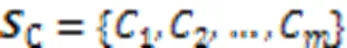
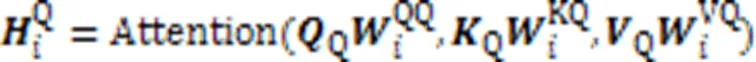
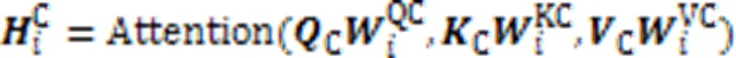
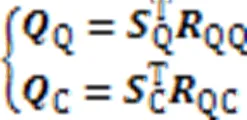
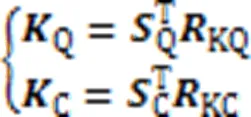
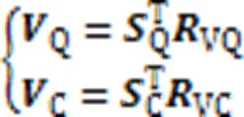
结合个注意力头,得到查询语句和代码片段的多头自注意力层输出,计算过程如式(7)(8)所示:
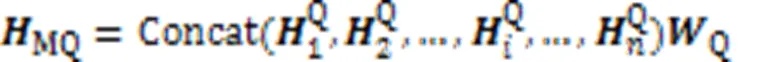
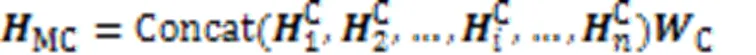
其中:Q和C分别是查询语句和代码片段多头自注意力层的融合矩阵;Concat代表连接操作。
为了防止模型训练过程中出现过拟合,在BERT层后连接Dropout层,以增强模型的泛化能力。由于BERT内部结构较复杂,整个BERT编码运算由BERT操作表示。代表代码片段的序列向量C和代表查询语句的序列向量Q经过式(9)(10)的BERT计算,分别得到模型第一模块中代码片段与查询语句的向量C和Q。
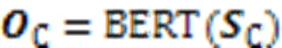
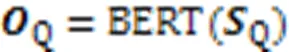
2.3 协同融合网络
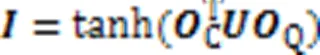
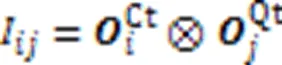
其中⊗代表两矩阵点乘过程中对应分词间协同信息的计算。
对于图1所示的代码-查询对,经过上述计算生成如图4所示的协同矩阵。其中:每一行代表代码片段中相应的某一个分词与查询语句中每一个分词的关联程度;每一列代表查询语句中相应的某一个分词与代码片段中每一个分词的关联程度;矩阵中每个方格的不同颜色和数值代表相应分词间的协同信息。分词间关联越密切,相应方格的颜色就越深,数值就越高;关联越强意味着语义信息越相近,则相应分词对此代码片段和查询语句的匹配贡献度就越高。因此,各分词间的协同信息是衡量相应代码片段和查询语句的语义信息是否匹配的重要因素。例如,查询语句中的分词“file”与代码片段中的分词“content”和“txt”的语义相似,有着密切的联系,故图4中相应方格的颜色就较深;而查询语句中的分词“file”与代码片段中的“public”分词的语义联系较弱,相应方格的颜色就较浅。在计算相似度时,更应关注联系密切的分词语义,降低无关分词对代码匹配的影响。通过有侧重地表征对匹配具有不同贡献程度的分词,提高特征信息表征准确度,进而提高代码推荐的准确性。

图4 协同矩阵中的协同信息
由于协同矩阵第行中的每个元素代表代码片段中第个分词与查询语句中每个分词的关联程度,则第行元素组成的协同信息代表代码片段中第个分词对该代码-查询对匹配的贡献程度。因此,对协同矩阵的所有行向量进行如式(13)的最大池化操作,得到该代码片段中的各分词与当前查询语句段匹配的贡献权重。同理,对于协同矩阵的列向量,同样如式(14)对它们进行最大池化操作,得到查询语句中所有分词对于整个匹配的贡献权重。
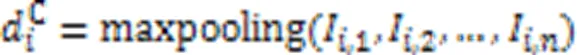
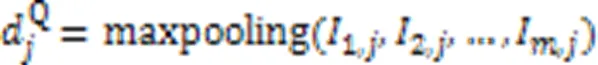
故代码片段和查询语句各分词的权重分数计算如下:
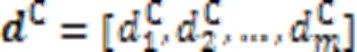
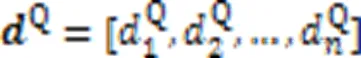
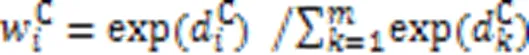
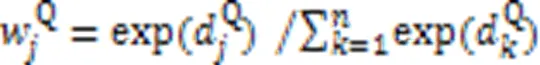
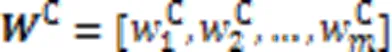
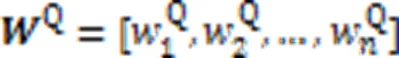
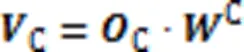
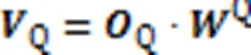
2.4 残差网络及相似性度量
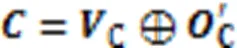
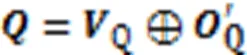
最终,代码片段和查询语句的匹配程度由余弦函数计算的相似分数决定。如式(25)所示:
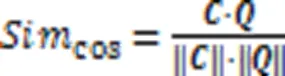
2.5 模型训练
代码搜索任务实际上可以看成一个分类任务。每个查询语句可能对应着多个满足功能需求的代码片段,而它们之间存在着语义相似度,相似度分数越高的代码片段将被视为最佳匹配结果。因此,将代码搜索任务转化为将某一查询语句归类为代码库中某一代码片段的分类任务,故采用多分类协同熵函数作为模型训练的损失函数,如式(26)所示:
其中:L表示第个batch的损失值;是模型参数;Avg表示值函数;是整个数据集划分的batch数。
损失函数的计算过程分为softmax计算和协同熵计算两个阶段:
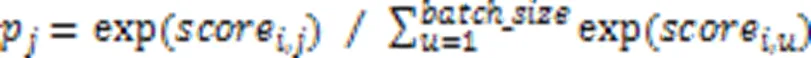
2)对于此batch中的协同损失,个代码片段可以作为个标签,计算将查询语句分类为个代码片段标签情况的损失,如式(28)所示:
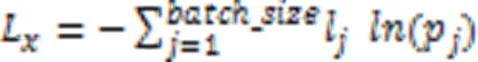
其中:l为此batch中第个查询语句正确分类的情况;p为经softmax归一化输出第个类别的概率。当分类越准确时,p对应的分量越接近1,L也越小。
此外,模型使用Adam优化器,将学习率设为0.000 4,学习率衰减值设为0.001进行训练。
3 实验与结果分析
为了验证所提模型在代码搜索任务上的效果以及结构的合理性,构建了以下实验:
1)RQ1。将BofeCS与当今先进模型对比,验证BofeCS在代码搜索任务上的效果。
2)RQ2。探索如何构建输入信息并选择具体方法,最大限度地提升BofeCS的性能。
3)RQ3。验证BofeCS中的不同部分对代码搜索性能的影响。
4)RQ4。验证BofeCS在其他编程语言上的表现。
3.1 实验配置
3.1.1环境配置
所有实验均在linux环境下,使用两块内存为11 GB的Nvidia GTX 2080Ti GPU,基于Tensorflow学习框架,使用Python语言进行编码、测试及运行。
3.1.2数据集
采用CodeSearchNet数据集[8]进行训练、验证和测试,该语料库涵盖超过两百万条从开源库收集的代码-查询对,其中查询语句使用相应代码注释表示,包含6种常用编程语言:Python、Javascript、Ruby、Go、Java和PHP。RQ1~RQ3均采用其中的Java数据集,RQ4采用全部6种数据集。该语料库的具体细节如表1所示,预先按编程语言种类分为6类,并分别划分为训练集、验证集(Valid)和测试集这3部分。
表1CodeSearchNet语料库的具体情况
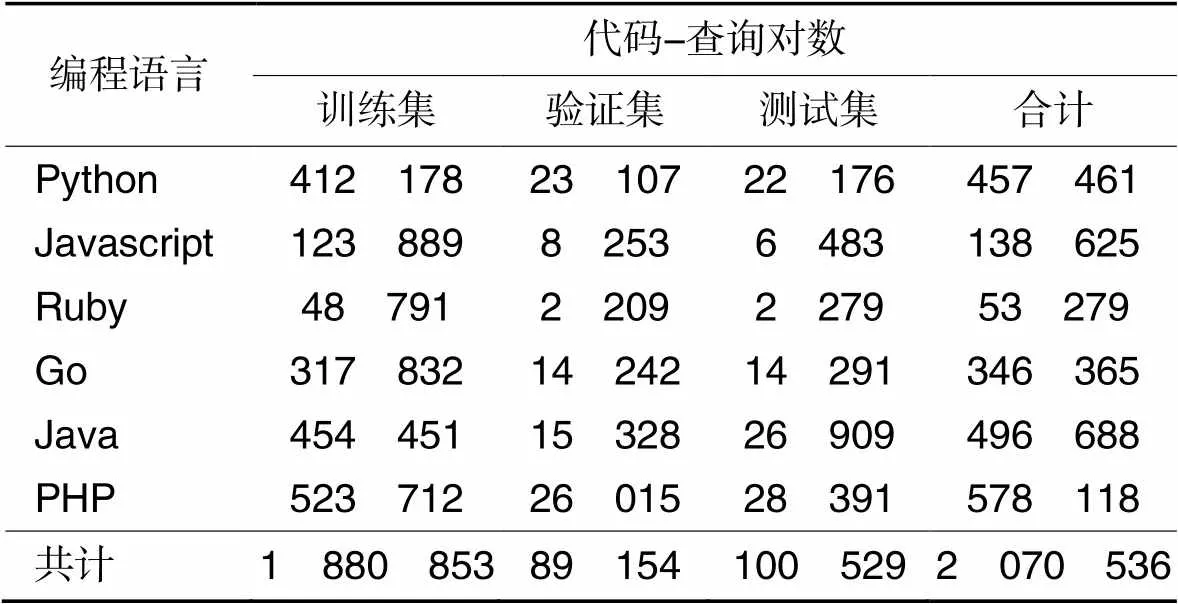
Tab.1 Details about CodeSearchNet corpus
3.1.3评价指标
为了有效评估BofeCS的效果,本文采用代码搜索领域使用最广泛的3个指标进行评价,分别是:
1)归一化折损累计增益(Normalized Discounted Cumulative Gain, NDCG)。它衡量实际返回的代码片段排序列表与最理想的代码片段排序列表之间的相似性,注重最终推荐的代码列表中代码片段的整体排序情况,如式(29)所示:
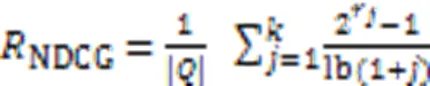
其中:是验证/测试集中查询语句数,r是返回的top-搜索结果中位置的代码片段与查询语句的相关性。代码搜索模型的NDCG分数越高,代表返回推荐代码列表的整体质量越高,且将更相关的代码排序到列表越靠前的位置。
2)平均倒数排名(Mean Reciprocal Rank, MRR)。它衡量与查询语句匹配的目标代码片段在返回的代码列表中的排名情况,且只关心最相关代码片段的排名情况,排名越靠前,MRR值越高,反之越低,如式(30)所示:
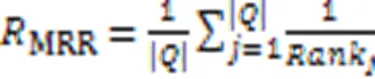
其中:Rank是对于第个查询语句返回的代码片段推荐列表,最相关的代码片段的排序位置。MRR值越高,代表代码搜索的性能越好。
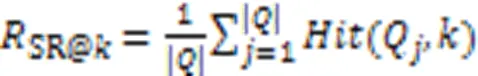
3.1.4基线模型
将BofeCS与当前先进的方法进行对比分析,包括:
1)UNIF[9]。它是有监督代码搜索模型,引入注意力机制,并结合每个分词的嵌入信息,分别生成代码片段与查询语句的表征向量。
2)TabCS[10]。它是双层注意力代码搜索模型,通过两层注意力机制,根据输入信息之间的关系分别生成代码片段与查询语句的表征向量。
3)MRCS[11]。它是多模态代码表征模型,基于遍历和采样的4种树序列作为代码的语法信息,结合源代码的分词序列进行特征信息表征。
3.2 RQ1:BofeCS在代码搜索任务上的表现
RQ1将各模型在代码搜索任务上进行对比分析。其中,MRCS模型将代表代码语义信息的Tokens序列与代表代码语法信息的树序列作为代码片段部分的输入。Gu等[11]提出了基于遍历和采样的4种树序列:SBT(Structure-Based Traversal)、LCRS(Left-Child Right-Sibling)、RootPath和Leafpath,RQ1使用效果最好的Tokens+SBT作为MRCS的输入结构。4个模型均在CodeSearchNet语料库的Java数据集进行模型的训练和测试,实验结果如表2所示。由表2可知,相较于基线方法UNIF、TabCS和MRCS,BofeCS的评价指标值均有显著提升,其中MRR值分别提升了95.94%、52.32%和16.95%。
相较于其他3种方法,BofeCS不仅使用表征能力更强的BERT进行语义嵌入,还在分词粒度上捕获查询语句与源代码之间的协同信息;同时考虑语义表征过程中丢失的语义信息,保证语义信息的完整性。这些都使BofeCS大幅提高了对语义信息表征的准确性,具有较好的代码搜索效果。
表24个模型在代码搜索任务上的对比实验结果
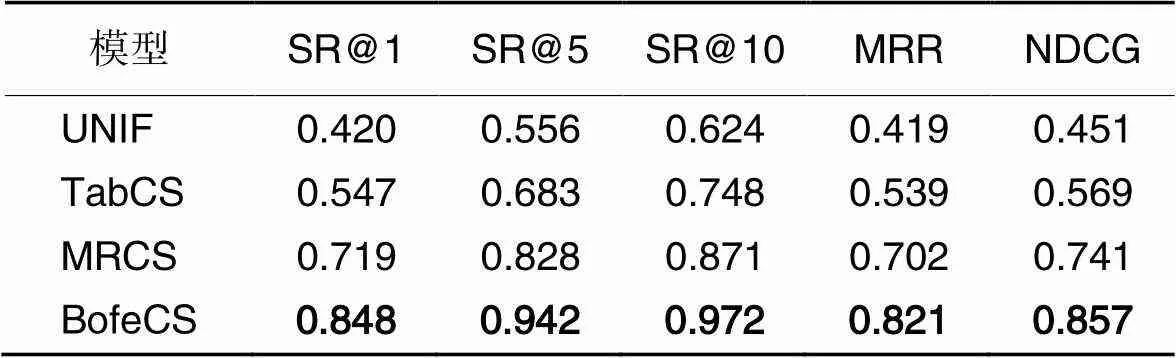
Tab.2 Results of comparison experiment of four models on code search task
3.3 RQ2:输入信息的构建和具体方法的选择
3.3.1探索BofeCS输入信息的构成
BofeCS使用代码片段和查询语句的分词序列(T)作为语义信息作为输入,而MRCS采用基于遍历和采样的4种树序列SBT、LCRS、RootPath和Leafpath代表代码的语法特征信息。本节将代表代码语法特征的4种树序列分别与代表代码语义特征的分词序列一同作为BofeCS的输入,讨论树序列是否能增强BofeCS的表征能力,提升代码搜索准确性。实验结果如表3所示,可以看出,使用任一种树序列作为额外输入,对BofeCS的代码搜索效果均没有积极作用。这可能是由于过多的信息作为输入,导致BofeCS无法捕获关键语义信息,表征向量中充斥过多噪声导致搜索性能下降。因此,以分词序列(T)作为BofeCS的输入,既能保证表征信息的完整性,又能避免信息冗余而产生的噪声,进而提高模型的准确性。
表3树序列对BofeCS性能的影响
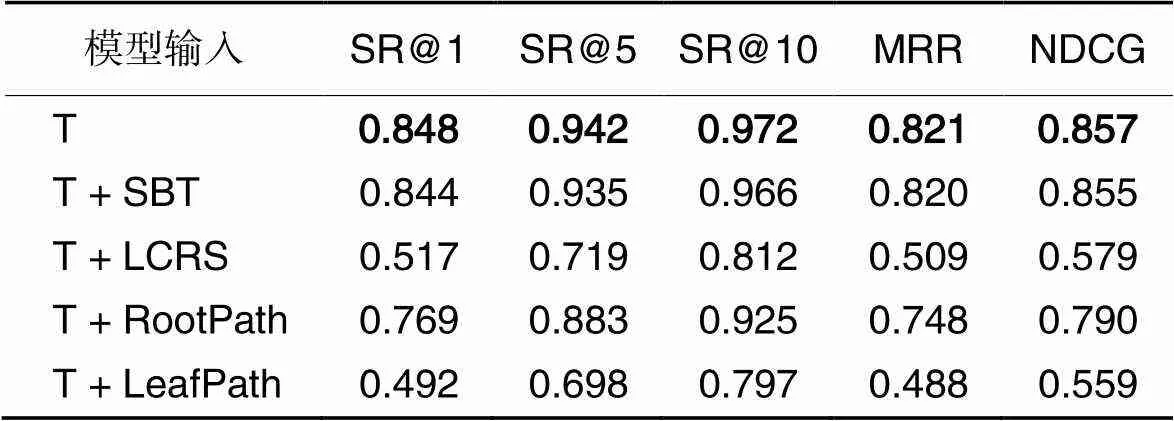
Tab.3 Influence of tree sequence on BofeCS performance
3.3.2损失函数的选择
本文选择如式(26)所示的多分类协同熵(S)作为损失函数,式(32)所示的损失函数(M)也常用于代码搜索模型的训练。
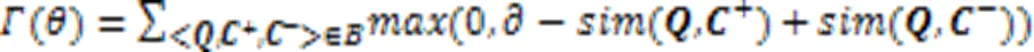
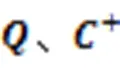
表4两种损失函数的表现

Tab.4 Performance of two loss functions
3.3.3池化操作的选择
由上文可知,BofeCS在协同融合模块通过对协同矩阵展开行/列操作,池化操作生成各分词对于对应查询-代码对的匹配权重值。最大池化和平均池化的区别是选择分词与对应代码片段或查询语句的各分词匹配的权重最大值或平均值作为该分词的权重值。对比最大池化操作和平均池化两种方法对BofeCS性能的影响,结果如表5所示,可以看出,最大池化操作的效果优于平均池化操作。
表5两种池化操作的表现

Tab.5 Performance of two pooling operations
综合以上实验结果,本文选择多分类协同熵损失函数作为损失函数,并选择最大池化作为池化操作以最大限度提升BofeCS性能。
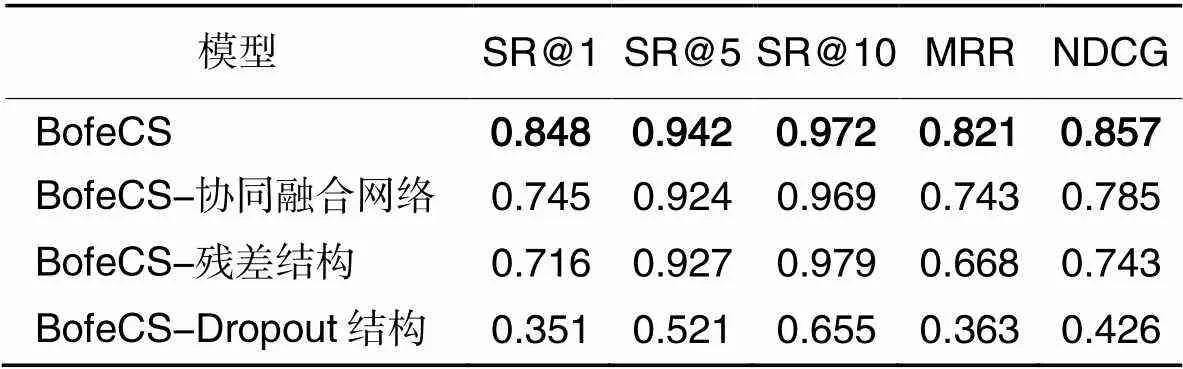
3.4 RQ3:消融实验
为验证BofeCS中各模块的有效性,分别去除BofeCS中的协同融合网络、残差结构和Dropout结构,结果如表6所示。由表6可知,这3个部分均对BofeCS的性能起着关键的作用:协同融合网络用于捕获代码片段与查询语句间映射关系中所蕴含的语义信息,突出匹配的关键语义信息并指导表征过程;残差结构将第一模块嵌入的原始语义向量与协同融合网络生成的协同向量进行融合,保证了表征语义信息的完整性;Dropout结构丢弃部分隐藏层节点,使BofeCS不会过度依赖训练数据集的局部特征,增强模型的泛化能力。
表6消融实验结果
Tab.6 Results of ablation experiments
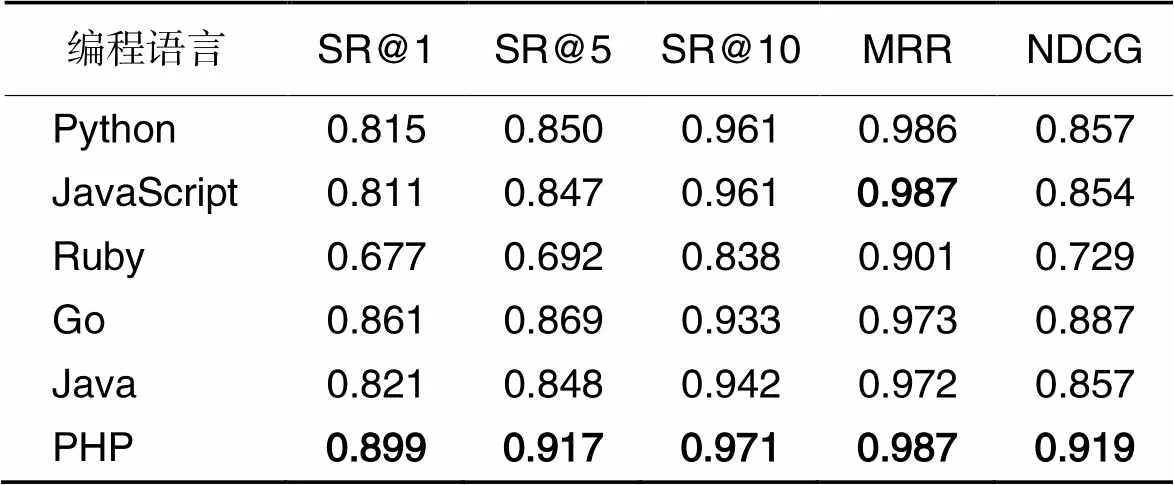
3.5 RQ4:BofeCS在多语言上的表现
CodeSearchNet是目前代码搜索研究最为广泛的数据集,共包含6种常用编程语言,超过200万条数据。因此在CodeSearchNet数据集上对BofeCS的多语言代码搜索任务进行实验并分析。实验结果如表7所示,可以看出,BofeCS在6种语言上都具有较高的准确度,且在PHP语言上表现最优,在Ruby语言上的代码搜索性能较弱。这可能由于Ruby数据集的数据量仅为Java数据集的11%,模型无法充分地学习深层语义联系,但良好的结果依然说明BofeCS在较小的数据集上仍能展现较优的代码搜索效果。因此,BofeCS在代码搜索任务中具有较强的泛化能力。
表7BofeCS在6种语言上的表现
Tab.7 Performance of BofeCS in six languages
4 结语
针对代码搜索中存在的协同信息缺失问题,本文提出了一个代码搜索模型BofeCS。实验与结果分析表明,BofeCS能有效提高代码搜索的准确性,同时具有较高的多语言搜索的泛化能力。本文的研究结论如下:1)源代码与查询语言之间存在较强的协同信息,并影响模型表征的准确度;2)协同融合网络能有效地提取源代码与查询语言之间的协同信息,提高表征的准确性;3)BofeCS包含的3个模块具有充分的结构合理性,同时具有多语言搜索的泛化能力。
未来工作将探索更有效的代码结构信息表示方法以提高对于代码的表征能力,还将尝试使用迁移学习、元学习等技术来提高模型对不同数据集的适应能力。
[1] YAO Z, PEDDAMAIL J R, SUN H. CoaCor: code annotation for code retrieval with reinforcement learning [C]// Proceedings of the 2019 World Wide Web Conference. Republic and Canton of Geneva: International World Wide Web Conferences Steering Committee, 2019: 2203-2214.
[2] WAN Y, SHU J, SUI Y, et al. Multi-modal attention network learning for semantic source code retrieval [C]// Proceedings of the 34th IEEE/ACM International Conference on Automated Software Engineering. Piscataway: IEEE, 2019: 13-25.
[3] GU X, ZHANG H, KIM S. Deep code search [C]// Proceedings of the ACM/IEEE 40th International Conference on Software Engineering. New York: ACM, 2018: 933-944.
[4] YU Z, YU J, XIANG C, et al. Beyond bilinear: generalized multimodal factorized high-order pooling for visual question answering [J]. IEEE Transactions on Neural Networks and Learning Systems, 2018, 29(12): 5947-5959.
[5] LI L, DONG R, CHEN L. Context-aware co-attention neural network for service recommendations [C]// Proceedings of the IEEE 35th International Conference on Data Engineering Workshops. Piscataway: IEEE, 2019: 201-208.
[6] LI B, SUN Z, LI Q, et al. Group-wise deep object co-segmentation with co-attention recurrent neural network [C]// Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision. Piscataway: IEEE, 2019: 8518-8527.
[7] HE K, ZHANG X, REN S, et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2016: 770-778.
[8] HUSAIN H, WU HH, GAZIT T, et al. CodeSearchNet challenge: evaluating the state of semantic code search [EB/OL]. [2022-09-12].https://arxiv.org/pdf/1909.09436.pdf.
[9] CAMBRONERO J, LI H, KIM S, et al. When deep learning met code search[C]// Proceedings of the 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering. New York: ACM, 2019: 964-974.
[10] XU L, YANG H, LIU C, et al. Two-stage attention-based model for code search with textual and structural features[C]// Proceedings of the 2021 IEEE International Conference on Software Analysis, Evolution and Reengineering. Piscataway: IEEE, 2021: 342-353.
[11] GU J, CHEN Z, MONPERRUS M. Multimodal representation for neural code search[C]// Proceedings of the 2021 IEEE International Conference on Software Maintenance and Evolution. Piscataway: IEEE, 2021: 483-494.
[12] LV F, ZHANG H, LOU J G, et al. CodeHow: effective code search based on API understanding and extended Boolean model (E)[C]// Proceedings of the 30th IEEE/ACM International Conference on Automated Software Engineering. Piscataway: IEEE, 2015: 260-270.
[13] LU M, SUN X, WANG S, et al. Query expansion via WordNet for effective code search[C]// Proceedings of the IEEE 22nd International Conference on Software Analysis, Evolution, and Reengineering. Piscataway: IEEE, 2015: 545-549.
[14] LEMOS O A L, DE PAULA A C, ZANICHELLI F C, et al. Thesaurus-based automatic query expansion for interface-driven code search [C]// Proceedings of the 11th Working Conference on Mining Software Repositories. New York: ACM, 2014: 212-221.
[15] LIU J, KIM S, MURALI V, et al. Neural query expansion for code search[C]// Proceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages. New York: ACM, 2019: 29-37.
[16] WANG C, NONG Z, GAO C, et al. Enriching query semantics for code search with reinforcement learning[J]. Neural Networks, 2022, 145: 22-32.
[17] ZOU Q, ZHANG C. Query expansion via learning change sequences[J]. International Journal of Knowledge-based and Intelligent Engineering Systems, 2020, 24(2): 95-105.
[18] HU G, PENG M, ZHANG Y, et al. Unsupervised software repositories mining and its application to code search[J]. Software: Practice and Experience, 2020, 50(3): 299-322.
[19] WU H, YANG Y. Code search based on alteration intent[J]. IEEE Access, 2019, 7: 56796-56802.
[20] WANG H, ZHANG J, XIA Y, et al. COSEA: convolutional code search with layer-wise attention [EB/OL]. [2022-09-12].https://arxiv.org/pdf/2010.09520.pdf.
[21] LING X, WU L, WANG S, et al. Deep graph matching and searching for semantic code retrieval[J]. ACM Transactions on Knowledge Discovery from Data, 2021, 15(5): No.88.
[22] WANG W, LI G, MA B, et al. Detecting code clones with graph neural network and flow-augmented abstract syntax tree[C]// Proceedings of the IEEE 27th International Conference on Software Analysis, Evolution and Reengineering. Piscataway: IEEE, 2020: 261-271.
[23] 夏冰,庞建民,周鑫,等.二进制代码相似性搜索研究进展[J]. 计算机应用, 2022, 42(4):985-998.(XIA B, PANG J M, ZHOU X, et al. Research progress on binary code similarity search[J]. Journal of Computer Applications, 2022, 42(4):985-998.)
[24] ZHANG J, WANG X, ZHANG H, et al. A novel neural source code representation based on abstract syntax tree [C]// Proceedings of the IEEE/ACM 41st International Conference on Software Engineering. Piscataway: IEEE, 2019: 783-794.
[25] LING C, LIN Z, ZOU Y, et al. Adaptive deep code search [C]// Proceedings of the 28th International Conference on Program Comprehension. New York: ACM, 2020: 48-59.
[26] MA H, LI Y, JI X, et al. MsCoa: multi-step co-attention model for multi-label classification [J]. IEEE Access, 2019, 7: 109635-109645.
[27] ZHANG P, ZHU H, XIONG T, et al. Co-attention network and low-rank bilinear pooling for aspect based sentiment analysis [C]// Proceedings of the 2019 IEEE International Conference on Acoustics, Speech and Signal Processing. Piscataway: IEEE, 2019: 6725-6729.
[28] SHUAI J, XU L, LIU C, et al. Improving code search with co-attentive representation learning[C]// Proceedings of the 28th International Conference on Program Comprehension. New York: ACM, 2020: 196-207.
[29] SHWARTZ-ZIV R, TISHBY N. Opening the black box of deep neural networks via information [EB/OL]. [2022-09-12].https://arxiv.org/pdf/1703.00810.pdf.
[30] BELGHAZI M I, BARATIN A, RAJESWAR S, et al. Mutual information neural estimation[C]// Proceedings of the 35th International Conference on Machine Learning. New York: JMLR.org, 2018: 531-540.
Code search model based on collaborative fusion network
SONG Qihong1,2, LIU Jianxun1,2*, HU Haize1,2, ZHANG Xiangping1,2
(1(),411201,;2,,411201,)
Searching and reusing relevant code can significantly improve software development efficiency. The deep learning-based code search models usually embed code pieces and query statements into the same vector space and then match and output the relevant code by computing cosine similarity; however, most of these models ignore the collaborative information between code pieces and query statements. To fully represent semantic information, a collaborative fusion-based code search model named BofeCS was proposed. Firstly, BERT (Bidirectional Encoder Representations from Transformers) model was utilized to extract the semantic information of the input sequences and then represent it as vectors. Secondly, a collaborative fusion network was constructed to extract the token-level collaborative information between code pieces and query statements. Finally, a residual network was built to alleviate the semantic information loss during the representation process. The multi-lingual dataset CodeSearchNet was used to carry out experiments to evaluate the effectiveness of BofeCS. Experimental results show that BofeCS can significantly improve the accuracy of code search and outperform the baseline models, UNIF (embedding UNIFication), TabCS (Two-stage Attention-Based model for Code Search), and MRCS (Multimodal Representation for neural Code Search), in Mean Reciprocal Rank (MRR), Normalized Discounted Cumulative Gain (NDCG), and TopSuccess hit Rate (SR@), where the MRR values are improved by 95.94%, 52.32%, and 16.95%, respectively.
software development; code search; collaborative fusion; BERT (Bidirectional Encoder Representations from Transformers); residual network
This work is partially supported by National Natural Science Foundation of China (61872139).
SONG Qihong, born in 1998, M. S. candidate. His research interests include code search, code completion.
LIU Jianxun, born in 1970, Ph. D., professor. Her research interests include big data, service computing, cloud computing.
HU Haize, born in 1989, Ph. D. candidate, lecturer. His research interests include data mining, code search.
ZHANG Xiangping, born in 1993, Ph. D. candidate. His research interests include code representation, code clone detection.
TP311.5
A
1001-9081(2023)12-3896-07
10.11772/j.issn.1001-9081.2022111783
2022⁃11⁃29;
2023⁃03⁃25;
2023⁃03⁃28。
国家自然科学基金资助项目(61872139)。
宋其洪(1998—),男,陕西宝鸡人,硕士研究生,CCF会员,主要研究方向:代码搜索、代码补全;刘建勋(1970—),男,湖南衡阳人,教授,博士,CCF杰出会员,主要研究方向:大数据、服务计算、云计算;扈海泽(1989—),男,湖南邵阳人,讲师,博士研究生,主要研究方向:数据挖掘、代码搜索;张祥平(1993—),男,福建三明人,博士研究生,主要研究方向:代码表征、代码克隆检测。
猜你喜欢
无线电工程(2024年8期)2024-09-16 00:00:00
科学技术与工程(2023年3期)2023-03-15 10:34:12
软件导刊(2022年3期)2022-03-25 04:45:04
新世纪智能(语文备考)(2020年4期)2020-07-25 02:28:50
智富时代(2019年6期)2019-07-24 10:33:16
计算机技术与发展(2019年1期)2019-01-21 00:56:38
作文评点报·低幼版(2017年44期)2017-11-16 08:24:58
高中生·天天向上(2016年9期)2016-11-22 09:10:34
语文知识(2014年4期)2014-02-28 21:59:52
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
