
单机架可逆轧机组合负荷分配算法的应用
2024-01-07 13:44温玉莲闫洪伟齐海峰赵文姣
山西冶金 2023年11期
温玉莲,闫洪伟,齐海峰,赵文姣,温 杰
(首钢京唐钢铁联合有限责任公司冷轧部,河北 唐山 063200)
0 引言
随着汽车轻量化和安全标准要求的逐年提高[1],超高强度钢板的生产比例和强度逐渐提高,连轧机在生产高强钢过程中的难度凸显。单机架可逆轧机生产组织灵活,可多道次重复轧制,在冷轧高强钢市场中所占份额越来越重要。机组的模型设定参数既是为基础自动化(L1)提供控制目标值,也是产品生产工艺在控制系统中的体现,因此模型设定计算的精度直接影响产品质量,而厚度控制和板型控制是保证冷轧产品质量的关键[2],是评价轧机模型好坏的重要指标。
负荷分配[3]是模型计算的重要组成部分,是根据轧件特性、轧机特性和工艺要求快速计算出特定意义下最佳的生产道次和各道次压下量的一种方法。负荷分配程序根据钢卷的原始数据、轧机的设备参数、工艺要求和给定的负荷分配比例系数,对轧制工艺参数进行计算,在计算过程中对设备能力进行极限校核,如果超限则对超限的工艺参数进行修正计算[4]。本文利用三种负荷分配模式和轧制规程号相结合的方式确定了生产道次和各道次压下量[5],从而实现轧制基本设定模型的计算。
1 轧制规程计算
轧制规程[6]是带钢生产的主要工艺技术内容,是轧机生产能力发挥、产品质量及板形质量的根本保证。合理的轧制规程可以充分发挥轧机设备能力,减少能耗,保证带钢产品的精度,使轧制工艺达到最佳状态。本文所述的轧制规程表(RCM_SCHEDNUMBER)根据钢种的钢级、带钢的原料宽度、原料厚度、目标厚度确定轧制规程号。其中钢级根据屈服强度分为10 级,根据机组能力将原料宽度分为8 级、原料厚度分为7级、目标厚度分为9 级,共组合成5 040 个轧制规程号,每个轧制规程号代表了一种轧制规程,是模型计算的基础。
2 基于轧制规程的负荷分配
模型提供了三种负荷分配计算方法,供生产操作选择,通过模型控制标志位进行区分。三种计算方法各有优势,适用于不同场景。
2.1 历史规程
历史规程使用最为普遍,它以数据库表(RCM_HISTORYDRAFT)的形式存在,在原有轧制规程号基础上,将原料厚度和目标厚度都细化为30 级,另外增加了是否使用开卷机及表面类型,使分档更为细致,所以模型计算精度最高。不管以哪种方式进行模型计算,只要计算正确,模型设定值都会更新或插入历史规程表,且随着生产的不断进行,数据库表的记录由无到有、由少到多,直至覆盖所有规格。
由于采用厚度分档方式,通过历史规程表查到的记录是落在同一档的所有产品规格模型计算参考值,很可能会出现原料厚度或目标厚度与该历史规程表查到的记录不一致情况,所以不能完全按照历史规程进行轧制,需要对各道次出口厚度进行二次分配。
基本算法描述:历史表记录各道次出口厚度按比例分配,算出每道次的绝对压下率;再根据此压下率和PDI 原料厚度、目标厚度按比例重新进行二次分配。此种算法既保证了历史轧制规程的负荷分配比例得到继承,又兼顾了每卷入口厚度和目标厚度的不同。
2.2 经验规程
经验规程是一种通过积累把经验值固定下来的负荷分配算法,它以常数表的形式存在,是一种表格式轧制模型[7]。常数表可以参考其他项目积累的经验,也可以是将历史规程不断完善后,把较为满意的历史规程固化到常数表。经验规程与历史规程一样,由于采用厚度分档方式,存在原料入口厚度或目标厚度与经验规程查到的记录不一致的情况,需要重新进行负荷分配调整,使算法与历史规程二次负荷分配一致。
这种算法比较适用于新项目投产初期、新规格第一次生产、历史规程中没有记录的情况,通过借鉴其他项目的生产经验,读取常数表获取负荷分配值。
2.3 自动计算
自动计算是根据钢种牌号和总压下率来给定总道次数和各道次压下率的一种简单负荷分配算法。算法如下:在新钢种进行参数维护时,根据总压下率小于40%、50%、60%、70%、80%分别给定总道次数为3、4、5、6、7;然后在自动计算时,根据总道次数固化每道次的压下率,如表1 所示。

表1 自动计算总道次及各道次压下分配
这种算法适用于历史规程和经验规程都没有的情况,模型必须提供一种算法,且能计算成功,为操作人员提供人机界面接口进行手动修正。同时,该算法也适用于特殊钢种的批量生产及对产品规格分档要求较低的情况。
2.4 三种负荷分配算法的优缺点对比
历史规程:优点是分级最细,对每卷的规格针对性更强;能够及时修正历史记录,对操作工手动修改过的参数具有记录功能;同规格钢卷如果选择历史规程轧制,模型参数具有继承性,不需要对每卷进行修改。缺点是如果对同规格钢卷修改了轧制规程,且写入了历史数据表,一旦触发当前卷模型重计算,则计算结果会与之前轧制数据不同,容易造成同一卷轧制却使用了两种不同数据,因数据冲突造成严重错误。
经验规程:优点是经验表数值固定,不会自动更新,对同规格批次钢卷针对性强;处于同一档的所有卷使用同一规程,不受模型触发计算的时刻影响,稳定性好。缺点是需要人工手动维护,不断完善经验表,使之覆盖所有规格;规格分级较为粗略,对原料规格处于分档临界值的卷,计算出的模型数据可能差距很大,精度较历史规程稍差。
自动计算:优点是针对钢种进行最大道次分配和每道次压下率设定,对特殊钢种的针对性最强,能够弥补历史规程和经验规程由于分档导致的临界值模型差距大的缺点;能够解决历史规程和经验规程都不存在情况下的模型计算,保证模型计算的基本正确。缺点是需要人为在维护新钢种时就对模型进行负荷分配,由于没有生产经验,所以维护初期负荷分配精度可能较差。
3 组合负荷分配算法及实际应用效果分析
组合负荷分配算法为操作人员提供了模型计算的选择控制开关,可以选择历史规程、经验规程或自动计算。如果选中的是历史规程,则模型先查历史规程表RCM_HISTORYDRAFT 获取对应记录,并进行二次负荷分配;如果历史规程计算失败,则使用经验规程,并进行二次负荷分配;如果经验规程计算失败,则使用自动计算;如果自动计算也失败,则只能通过手动添加经验规程的方法,根据经验人为分配道次,直至计算成功。
通过以上三种方式的任何一种计算出模型设定值后,都可以显示在二级画面中,为操作人员提供了人机交互的界面。如果操作人员需要对某个道次压下率进行调整,那么模型将在原负荷分配基础上,对未轧制的道次进行压下分配调整策略,以达到操作人员手动修改的目标分配值。调整策略的主要方法如下:
1)计算原负荷分配各道次压下率。
2)检查操作人员输入的压下率参数是否合理,不合理直接退出。
3)如果所有道次压下率均被修改,则计算末道次的出口厚度是否与目标产品厚度一致,不一致则报错。
4)如果不是所有道次压下率都被修改,则采用新的压下分配调整策略计算出各道次最终的出口厚度。
5)如果输入的总压下量大于目标总压下量,报错退出。
6)迭代计算[8],直到收敛次数大于1 000 或新的末道次出口厚度与读表值(历史规程或经验规程计算的末道次出口厚度)之差小于0.003 mm,迭代结束。否则,收敛次数加1,针对所有道次,进行新的道次压下率计算,操作人员手动修改的道次压下率不变,其他道次新的压下率=上一次计算道次压下率+上一次计算道次压下率/(500+收敛次数)。
7)迭代计算完成后,前几道次根据最新的道次压下率计算每道次出口厚度,末道次出口厚度以目标出口厚度为准,根据末道次出口厚度和目标出口厚度计算末道次压下率。
该迭代算法具有速度快、收敛性好等特点,适于在线过程控制的编程实现[9]。本文以原料厚度为3.27 mm、原料宽度为1 407 mm、目标厚度为1.87 mm的某卷带钢为例,分别使用三种负荷分配算法,计算得到的各道次出口厚度和压下率如表2 所示。
以经验规程为例,操作工手动修改3 道次压下率为15%,4 道次压下率为10%,模型进行压下分配调整,需要进行迭代计算,收敛过程如表3 所示。

表3 收敛计算过程
使用经验规程算法,操作人员手动修改压下率后的最终计算结果如表4 所示。
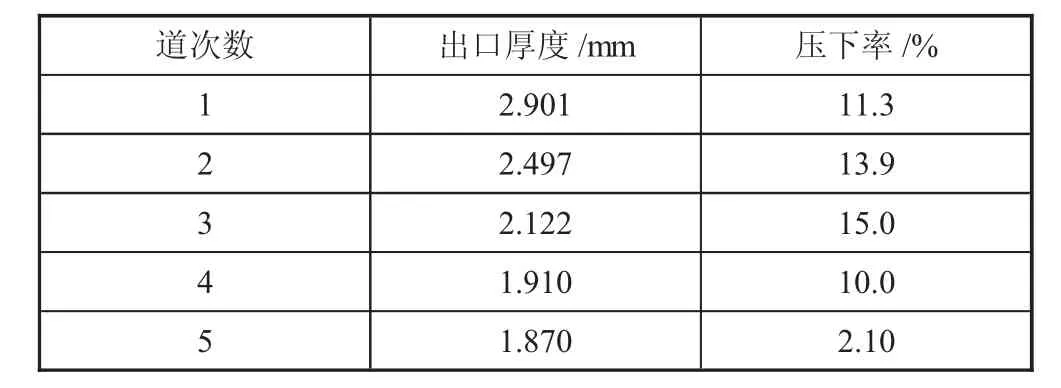
表4 收敛计算结果
4 结语
本项目开发的三种负荷分配算法,历史规程可以实现继承操作值分配,经验规程可以实现按产品规格固定分配,自动计算可以实现按钢种分配功能,系统适用性强,对其他项目具有参考意义。但是这三种负荷分配算法都是基于轧制规程的,受限于轧制规程分档的精度,因此可对单机架可逆轧机在轧制规程人工智能化的研究方面进行进一步探索。
猜你喜欢
钛工业进展(2022年4期)2022-09-15
电子乐园·下旬刊(2022年6期)2022-05-16
四川劳动保障(2021年3期)2021-01-27
世界汽车(2020年6期)2020-12-28
工程科学学报(2020年5期)2020-06-05
铁道通信信号(2020年9期)2020-02-06
数学大王·趣味逻辑(2019年5期)2019-06-13
小学科学(学生版)(2019年5期)2019-05-21
经济技术协作信息(2018年30期)2018-11-22
风能(2015年4期)2015-02-27
