
一种基于虚拟测试样本和VGG网络模型的人脸识别算法
2024-01-04 16:58:56许婷
互联网周刊 2023年23期
关键词:人脸识别
许婷
摘要:近年来,随着人工智能的快速发展,人脸识别已经成为现代生物信息识别中的一种重要技术。但是,随着人们对生物信息的隐私性越来越重视,特殊场景下样本信息数量少等问题仍然影响着人脸识别算法的精度。本文针对少样本场景,提出了一种将虚拟测试样本与原始测试样本进行结合的基于VGG卷积神经网络的人脸识别算法。经实验,该算法在少样本场景下仍能够取得较好的效果。
关键词:人脸识别;少样本;虚拟样本;VGG卷积神经网络
引言
人脸识别一直是计算机视觉领域的热门关注领域,特别是随着人工智能技术的快速发展,人脸识别技术已经被广泛应用于司法、公共交通、银行、边检安防以及日常生活等多个领域中。目前,人脸识别虽然已经得到了巨大的发展,但是由于其本身的特点及隐私性、环境复杂性等问题,仍然存在许多挑战,如人脸相似性、人脸样本量缺少、背景图案繁杂、遮挡物及面部姿态等。早期的人脸识别技术主要有基于几何特征[1]、基于隐马尔科夫模型[2]、人工神经网络[3]等。然而近几年,随着深度卷积神经网络的不断发展,通过深度卷积神经网络模型进行人脸识别几乎成为主流研究方向,但是深度卷积神经网络模型往往需要大量数据进行训练,因此,小样本下的深度卷积神经网络模型训练依然是现在重点关注的挑战。
小样本学习任务的核心问题是在训练样本不足的情况下,如何保证经验风险的可靠性。一般来说,最直观的解决方法是数据增强,也就是补充训练样本的数量,从而达到获取更多信息量的目的。例如,乔雨轩、方建安提出了一种结合图像色彩恢复、文本碎片渲染、图像前后背景融合等多种图像处理手段进行数据增强的分类识别算法[4]。张超群、易云恒、周文娟等提出通过数据增强技术扩充样本集,并将其用于神经网络模型的训练[5]。从上述文献可以看出,通过数据增强提升小样本场景下的分类识别准确率仍然具有一定成效。但是在样本量极低的情况下,仅仅增强训练数据也难以达到深度卷积神经网络模型所需的训练数量。
因此,本文提出了一种基于虚拟测试样本的方法,与传统增强训练数据集方法的不同在于,该方法在增加训练数据集样本数量的基础上,同时增强了测试数据集的样本数量,并将测试样本与其对应的虚拟样本进行加权融合后再进行分类识别。
1. 算法步骤描述
1.1 VGG16网络模型
VGGNet是2014年由Karen Simonyan和Andrew Zisserman提出的一种深度卷积神经网络模型,是牛津大学计算机视觉实验室参加2014年ILSVRC(imageNet large scale visual recognition challenge)比赛时所用的网络模型,并获得了竞赛中分类第二和定位第一的成绩。VGG的主要特点在于其通过堆叠多个小卷积核来替代大卷积核,以减少所需参数,并加深了网络层数。
Karen Simonyan等人对六个网络模型的结构进行了实验验证,其中VGG16和VGG19的实验结果效果相对较好,基于此,本文将采用VGG16和VGG19作為基础网络模型进行实验。
VGG16共包含16个子层,第1层卷积层由2个conv3-64组成,第2层卷积层由2个conv3-128组成,第3层卷积层由3个conv3-256组成,第4层卷积层由3个conv3-512组成,第5层卷积层由3个conv3-512组成,然后是2个全连接层,1个输出层。
VGG19共包含19个子层,其网络结构与VGG16一致,只是相比VGG16增加了3个卷积层,因而此处不再进行详细描述。
1.2 本文提出的算法
为了进一步提高小样本场景下的人脸识别率,本文提出了一种将虚拟测试样本与原始测试样本相结合的基于VGG卷积神经网络模型的人脸识别算法。
假设训练数据集共有L个类别,每一类共有N个样本,为了能够更好地验证小样本场景下算法的有效性,将每一类的N样本分别选取T个样本作为训练样本,剩余N-T个样本作为测试样本,此时可知训练样本的个数为L×T,测试样本的个数则为L×(N-T)。
原始训练样本X和原始测试样本Y分别生成对应的虚拟样本X'和Y',本文采用的生成方式来源于张洋铭、吴凯、王艺凡等提出的利用人脸对称性生成虚拟样本,从而实现人脸识别[6]。该方法主要利用了人脸具有对称性这一主要生物特征生成虚拟训练样本,以达到扩充样本数量的目的,能够在一定程度上保留原样本的特征,并且弥补样本不足的问题。
通过生成虚拟样本后的训练样本集Xtotal和Ytotal分别如下:
(1)
(2)
其中 ,Yk表示原始测试样本,Ykι表示将的左脸进行对称转换后的虚拟测试样本,Ykr表示将Yk的右脸进行对称转换后的虚拟测试样本。
将Yk输入到由Ytotal进行训练的VGG卷积神经网络模型中后,在输出层可以得到一个输出向量,同理,将Ykι和Ykr输入到由Xtotal进行训练的VGG卷积神经网络模型中后可以得到向量。
为了能够更好地对测试样本进行描述,可以将原始测试样本与虚拟测试样本的输出向量进行加权融合,从而得到加权后的输出向量Wkall。
(3)
该算法的具体步骤描述如下:
(1)将样本分为测试样本和训练样本,利用人脸“对称性”生成虚拟人脸样本。
(2)将训练样本及其生成的虚拟训练样本一起输入VGG卷积神经网络中进行模型训练,增强训练样本数量。
(3)将测试样本和其对应生成的虚拟测试样本分别输入模型并对其生成结果进行加权融合。
(4)将样本分类到最终加权融合后贡献度最大的类别中。
2. 实验
2.1 实验数据集
本实验主要在ORL人脸数据库中进行,将改进后的算法与VGG卷积神经网络进行对比。ORL人脸数据库共包括40人,每人10幅正面人脸图像。为了验证少样本场景下的精确性,本实验中将对每人分别随机选取1、3、5幅人脸作为训练集,其余作为测试集,并针对训练集和测试集分别生成对应的虚拟样本数据,并将原始数据样本与虚拟数据样本结合,用于模型训练及测试过程中。
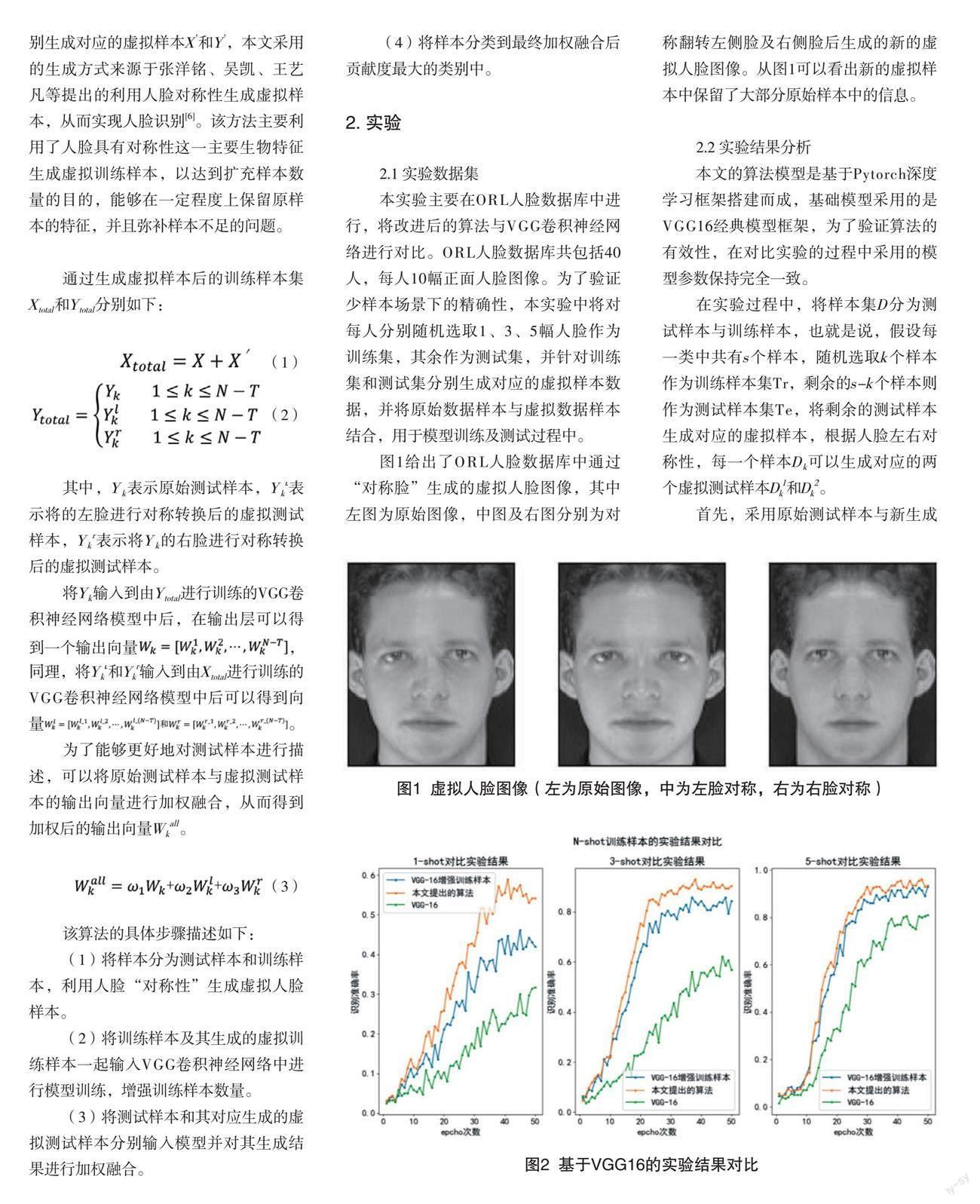
图1给出了ORL人脸数据库中通过“对称脸”生成的虚拟人脸图像,其中左图为原始图像,中图及右图分别为对称翻转左侧脸及右侧脸后生成的新的虚拟人脸图像。从图1可以看出新的虚拟样本中保留了大部分原始样本中的信息。
2.2 实验结果分析
本文的算法模型是基于Pytorch深度学习框架搭建而成,基础模型采用的是VGG16经典模型框架,为了验证算法的有效性,在对比实验的过程中采用的模型参数保持完全一致。
在实验过程中,将样本集D分为测试样本与训练样本,也就是说,假设每一类中共有s个样本,随机选取k个样本作为训练样本集Tr,剩余的s-k个样本则作为测试样本集Te,将剩余的测试样本生成对应的虚拟样本,根据人脸左右对称性,每一个样本Dk可以生成对应的两个虚拟测试样本Dk1和Dk2。
首先,采用原始测试样本与新生成的虚拟测试样本共同构成的新训练样本集Tr'对VGG网络模型进行训练;然后,分别将每一个测试样本及其对应的虚拟测试样本输入训练后的VGG网络模型中,可以得到其对应的输出结果,将其输出结果进行加权融合后得到最终结果,并将测试样本分到最终结果中贡献度更大的类别中。通过大量实验过程,同时结合前人的分析,为了得到更好的识别效果,可将权值分别设置为0.6、0.2、0.2。
图2对比了在N-shot下,本文提出的算法与原始VGG16以及增强训练样本后的VGG16的识别率。从图2可以看出,在样本量不足的情况下,本文所提出的基于虚拟测试样本加权融合算法的准确率高于增强训练样本和原始网络模型的准确率,并且在样本量极低的情况下,效果更好。
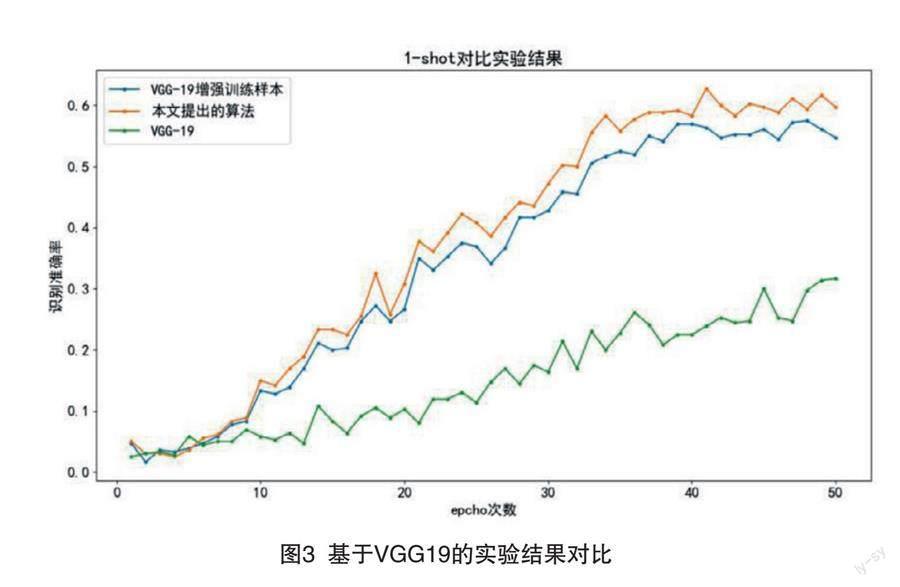
基于VGG19的网络模型,我们也对1-shot进行了对比实验,实验结果如图3所示。从实验结果可以看出,VGG19的模型结果比VGG16的结果更好,增加训练样本后也有一定提升,但是经过虚拟测试样本融合后,能够得到更进一步提升。
结语
本文提出了一种加权融合虚拟测试样本和虚拟训练样本的人脸识别算法,该算法能够在样本量明显不足的场景下取得较好的效果。增强数据能够很好地改善样本量不足引起的特征量不足问题。本文主要是通过同时增强训练样本集和测试样本集,然后将训练样本输入VGG模型中进行训练,但是其从有限的虚拟样本中获取的特征仍然是有限的。因此,在此基础之上,本文引入了虚拟测试样本数据,由于人脸对称性,新的虚拟测试样本与原测试样本具有一定相同特征,故在输入模型后可以提取到相似特征,基于此,将虚拟测试样本与原始测试样本进行加权融合后能够得到更有效的特征量,也在一定程度上提升了样本量不足情况下人脸识别的精度。
参考文献:
[1]王寻,赵怀勋.基于改进的肤色空间和几何特征的快速人脸检测研究[J].计算机应用与软件,2015,32(2):151-154.
[2]孟辉,高德施,李颖,等.基于隐马尔科夫模型的人脸识别[J].中国刑警学院学报,2019(4):124-128.
[3]冯巧娟.人工神经网络在人脸识别中的应用[J].平顶山工学院学报,2008, 17(2):19-20,26.
[4]乔雨轩,方建安.基于數据增强的小样本字符识别模型[J].计算机科学与应用,2022,12(5):1280-1291.
[5]张超群,易云恒,周文娟,等.基于深度学习与数据增强技术的小样本岩石分类[J].科学技术与工程,2022,22(33):14786-14794.
[6]张洋铭,吴凯,王艺凡,等.基于随机权重分配策略的面目表情识别[J].重庆大学学报,2022,45(9):135-140.
作者简介:许婷,硕士研究生,助教,研究方向:模式识别。
猜你喜欢
作文中学版(2022年1期)2022-04-14 08:00:34
学生天地(2020年31期)2020-06-01 02:32:06
电子制作(2019年14期)2019-08-20 05:43:34
中国交通信息化(2018年1期)2018-06-06 07:29:55
电子制作(2017年17期)2017-12-18 06:40:55
中国公共安全(2017年7期)2017-10-13 08:18:26
电子制作(2017年1期)2017-05-17 03:54:46
中国公共安全(2017年9期)2017-02-06 03:05:32
现代工业经济和信息化(2016年6期)2016-05-17 05:36:23
华东理工大学学报(自然科学版)(2015年2期)2015-11-07 09:16:51
