
基于多目标生物地理学优化算法的模糊节能分布式流水车间调度
2024-01-03 00:00:00张振张丫丫孙美玲顾幸生
华东理工大学学报(自然科学版) 2024年6期

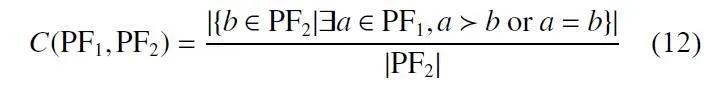








摘要: 研究了模糊节能分布式置换流水车间多目标调度问题(Fuzzy Energy EfficientDistributed Permutation Flow Shop Problem,FEEDPFSP),针对最小化模糊完工时间和模糊能耗两个优化目标, 提出了一种基于生物地理学的多目标优化算法(Multiple-ObjectiveBiogeography-Based Optimization,MOBBO)。在MOBBO 中,设计了一种有效的初始解生成规则,并根据两个优化目标之间的关系,设计了4 种速度操作方法用于迁移过程和变异过程,并且引入快速非支配排序以及拥挤距离方法,保证每次迭代的种群质量。对比两个先进算法在480 个不同规模实例下的表现,验证了所提出的MOBBO 算法在解决FEEDPFSP 问题的有效性。
关键词:分布式流水车间调度;生物地理学优化;模糊规划;节能;多目标优化
中图分类号:TB497; TP18 文献标志码:A
当今世界正面临两大严峻挑战:全球变暖和能源危机[1]。据估计,从2010 年到2040 年,全球能源消耗将以56% 的速度不断增长,其中工业制造将占据50% 的能源消耗[2]。在此背景下,节能调度逐渐成为调度领域研究的热点。
Mouzon 等[3] 试图通过生产调度降低能耗,他们采用机器的启动/关闭调度框架,成功地降低了整体能耗。在进一步的研究中,Mouzon和Yildirim[4] 提出了一种贪婪随机自适应搜索算法,以求解多目标优化调度。近年来,针对节能调度问题,采用“开-关”策略平衡最大完工时间和总能耗[5]。然而,频繁的开关机会在一定程度上减少机器的使用寿命[6],因此这种策略存在一定的局限性。针对制造过程中机器不能完全关闭的情形,一种速度缩放策略被广泛应用,该策略假定机器的能量消耗与其运行速度成正比。Wang 等[7] 提出的基于知识的协作算法通过对关键路径上的工件进行加速和非关键路径上的工件进行减速,以期实现最大完工时间和总能耗的同时优化。
置换流水车间调度问题是一个具有广泛应用背景的典型调度难题,当机器数大于3 时,已被证明是NP-hard 问题[8]。随着社会工业的发展,分布式置换流水车间调度问题(DPFSP)引起了越来越多研究者的关注。对于DPFSP 问题的研究最初由Naderi 和Ruiz[9] 展开。此后,越来越多的学者参与研究DPFSP及其变体,并提出了许多高性能算法。在单目标方面,Wang 等[10] 提出了一种有效的分布估计算法解决DPFSP,该算法建立了概率模型描述解空间的概率分布,并提供一种机制更新概率模型与上级个体。黄佳琳等[11] 提出了一种改进的生物地理学优化算法,以最小化最大完工时间为目标,求解分布式装配置换流水车间调度问题。在多目标方面,Deng 等[12]提出了一种竞争模因算法,解决具有完工时间和总拖期准则的多目标DPFSP。
上述相关文献都是在工件加工时间确定的前提下进行研究,然而在实际的制造过程中存在各种不确定因素,包括模型固有的不确定性(如动力学常数)、过程固有的不确定性(如加工时间)、外部不确定性(如产品需求)以及离散不确定性(如机器故障等)[13]。因此,研究不确定环境下的生产调度问题具有重要意义。Zheng 等[14] 将分布估计算法和迭代贪婪搜索巧妙结合,提出了一种针对具有模糊加工时间和模糊到期时间的多目标分布式混合流水车间调度问题的协同进化算法。Behnamian 等[15] 考察了具有模糊任务操作时间、到期日期和顺序相关设置时间的双目标混合流水作业调度问题,并提出了一种双层算法,旨在同时最小化完工时间和总提前/拖期。总的来说,在模糊操作时间的前提下,节能多目标调度领域的研究相对有限,寻找有效的调度方法仍然是值得深入研究的方向。
本文研究了具有模糊加工时间的多目标分布式置换流水车间调度问题,两个优化目标分别为模糊完工时间以及模糊总能耗。为了解决这一问题,首先引入了三角模糊数表征模糊加工时间;其次,为了得到Pareto 解集,提出了一种基于生物地理学的多目标优化算法(MOBBO),通过数值比较实验验证了所提出的MOBBO 算法的有效性。
1 模糊节能分布式置换流水车间调度问题
引入三角模糊数描述加工时间与能耗不确定性。对于一个三角模糊数T˜ = (t1, t2, t3),t1 lt; t2 lt; t3。
T˜的期望值分别为:(1)E1(T˜ ) = (t1 +2t2 +t3)/4;(2)E2(T˜ ) = t2;(3)E3(T˜ ) = t3 -t1。判断两个三角模糊数的大小:(1) 若E1(˜A) gt; E1(˜B),则˜Agt;˜B;(2) 若E1(˜A) = E1(˜B)、E2(˜A) gt; E2(˜B),则˜Agt;˜B;(3) 若E1(˜A) = E1(˜B)、E2(˜A) = E2(˜B)、E3(˜A) gt; E3(˜B),则˜Agt;˜B。
设有F个相同的工厂,每个工厂都拥有m台机器。共有n个工件需要进行加工,每个工件可以分配至任意工厂。工件i(i = 1,2,…,n)必须按照机器1 ~ m的顺序依次进行加工, 其工序为{Oi,1,Oi,2,…,Oi,m}。对于每台机器, 有s(v = 1,2,…, s)个不同等级的运行状态,Vv表示机器在等级v下的加工速度。机器在加工过程中速度不能发生改变。工件i在每台机器j( j = 1,2,…,m)上的标准加工时间为ti, j,其中t1 lt; t2 lt; t3。如果工序Oi, j以速度等级v进行加工,则Oi, j的实际加工时间为˜pi, j = ˜ti, j/Vv,单位运行能耗为PPj,v。如果机器 j上没有工件需要处理, 则该机器处在待机模式, 其单位能耗为SPj。πf = {πf (1),πf (2),…πf (nf )}表示工厂f 的加工序列,˜Ci, j表示工件i 在机器j 上的模糊完工时间,~PECf, j和~SECf, j分别表示工厂f 中机器j 的运行能耗与待机能耗,则最大模糊完工时间˜Cmax和总能耗~TEC计算如下:
2 MOBBO 算法
生物地理学优化算法(Biogeography-BasedOptimization, BBO)由Simon 在2008 年提出[16]。在BBO 中,每个栖息地被视为一个个体,通过栖息地适宜度指数描述该栖息地的质量。基于BBO 的优越性,越来越多的学者采用该算法解决各种优化问题,如Zhang 等[17-18] 利用BBO 算法解决大规模调度问题等。本节将详细介绍MOBBO 算法的编码和解码方法、速度调整策略、种群初始化、迁移过程以及变异过程。
2.1 编码与解码
在本算法中,一个完整的解可以分为两部分,一部分是工件编码π,另一部分是速度编码V。π采用vector数据结构表示,其包含两点信息:工件的工厂分配和工件加工顺序。V是n×m阶矩阵,表示工件在对应机器的加工速度。因此,一个完整的解可表示为П = (π,V)。
为了更好地解释本文算法采用的编码方式,以2 工厂6 工件为例,假设每个工厂有3 台机器,且机器有3 种不同的加工速度,则每个工件在每台机器上的标准时间以及每台机器在不同速度下的运行能耗以及待机能耗分别如表1、表2 所示。
步骤4:判断当前工件在当前机器的模糊完工时间是否大于前一个工件在下一台机器上的模糊完工时间,若大于则加速,直至加速到满足条件或者最大值为止;
步骤5:随机设置每个工件在最后一台机器上的加工速度,得到速度矩阵V。
2.4 迁移过程
迁移操作的目的就是在不同的解之间进行信息分享。在本算法中,对当前种群Pt中所有解进行快速非支配排序[19] 得到各个解的等级(rank),HSI 计算如下:
HSIi =1/ranki(9)
采用余弦迁移模型,迁入率( λi )和迁出率( λi )的计算公式如下:
其中,I 表示最大迁入率,E 表示最大迁出率。
在MOBBO 算法中,对于满足条件rand(0, 1) lt; λi的解作为迁入解πi,并从rank = 1的解中随机挑选一个作为迁出解πe 进行迁移操作,具体步骤如下:
步骤1:确定迁入解πi和迁出解πe,计算两者rank之差d = ranki -ranke;
步骤2:随机选择某一工厂f,并从πe的f 工厂中随机选择 个连续工件;
步骤 3:将 d 个工件迁移到 πi的相同位置。存在3 种情况,对于在索引范围内的工件进行交换操作,对于超出索引范围的工件进行插入操作;
步骤 4:迁移完成后对 πi 中所有工厂执行Accelerate2 或Decelerate2 操作,保留较优解。
对于不满足 rand(0,1) lt; λi条件的解,设计以下4 种自提升策略(self-improvement)改善解的质量:
(1) SI1:从工厂Fc中随机选择工件J*,从另一个工厂k中随机选择工件Jk,然后交换J*和Jk的位置。
(2) SI2:从工厂Fc中随机删除一个工件,并将其随机插入到另一个工厂中随机位置。
(3) SI3:从工厂 Fc中随机选择两个工件并交换它们的位置。
(4) SI4:从工厂Fc中随机选择一个作业,并将其插入到Fc中原位置外随机位置。
其中:Fc代表关键工厂,若执行加速操作,Fc为模糊完工时间最大工厂Fm·;若执行减速操作,Fc为模糊能耗最大工厂Fe。随机执行其中一种操作后,对所有工厂执行Accelerate1操作或Decelerate1操作,保留较优解。
2.5 变异过程
本算法设计了mu1、mu2 两种变异算子,介绍如下: (1) mu1:随机从关键工厂Fc中选择一个工件Jc,随机选择一个工厂k,将Jc与该工厂内所有工件依次进行交换操作,交换完成后对进行操作的工厂执行Accelerate1 操作(Fc = Fm)或者Decelerate1 操作(Fc = Fe),保留最优解。(2)mu2:随机从关键工厂Fc中选择一个工件Jc,随机选择一个工厂k,将Jc依次插入到该工厂所有位置,插入完成后对进行操作的工厂执行Accelerate1操作(Fc = Fm)或者Decelerate1操作(Fc = Fe),保留最优解。
2.6 MOBBO 总流程
首先,利用半规则半随机方法生成初始种群;其次,对当前种群进行快速非支配排序并生成非支配解集;之后,执行迁移和变异操作,速度调整策略包含在该过程当中;最后,对新种群进行快速非支配排序以及计算拥挤距离,保留前Popsize 个最优解进入下一次迭代,并更新非支配解集。具体伪代码如下:
1 Initialize the population, half using SS rule and half randomly generated;
2 Fast non-dominated sort and initialize AS;" "Nondominated solution set
3 For i = 1 ~ Popsize" "Execute twice, Accelerate1 and Decelerate1
4 If rand(0,1)lt; λi
5 Pt(i) perform migration operation;
6 Else
7 Pt(i) perform SI1~ SI4 randomly;
8 End if
9 End for
10 For i = 1 ~ 2 × Popsize
11 If i lt; Popsize
12 Qt(i) = Pt(i) ;
13 Qt(i) execute mu1 or mu2 randomly, then performing Accelerae1 operation;
14 Else
15 Qt(i) = Pt(iPopsize) ;
16 Qt(i) execute mu1 or mu2 randomly, then performing Decelerate1 operation;
17 End if
18 End for
19 Fast non-dominated sort and calculate the crowding distance;
20 Update the AS;
21 Keep the top Popsize optimal solutions and enter the next iteration
3 数值结果和比较
为了测试MOBBO 在求解FEEDPFSP 时的性能, 使用480 个算例进行实验。其中n = {20,40,60,80},m = {4,8,16},F = {2,3,4,5},对于{n,m,F}每个组合,随机生成10 个算例。每个工件的标准处理时间为ti, j = (t1, t2, t3),其中最有可能时间t2在[5,50]范围内随机生成, 最乐观值t1 = 0.85t2,最悲观值t3 = 1.3t2[20-21]。机器加工速度V为{1,1.3,1.55,1.75,2.1},v = {1,2,3,4,5}[7]。能耗与速度的关系:(1)单位运行能耗与速度的关系:PPf, j,v = 4×Vv×Vv;(2)单位待机能耗:SPf, j = 1。MOBBO 算法基于VisualStudio 2021 C++ 编码实现,所有实验实例均在PC 上进行计算,PC 配置为Microsoft Windows 11, Intel(R)Core(TM) i5-9300H CPU @ 2.40GHz /8GB RAM。
本文对比Knowledge-Based Cooperative Algorithm(KCA)[7] 和Non-dominated Sorting Genetic Algorithm-II(NSGA-II)[19] 两个算法。NSGA-II 作为求解多目标问题的经典优化算法其性能早已被相关学者证明,而KCA 算法在解决节能分布式调度问题上的优越性也在文献[7] 中得到验证。为了进行公平比较,在数值测试中,使用0.5×nCPU 时间(单位:s)作为算法的停止标准。由于FEEDPFSP 是一个模糊多目标优化问题,利用式E1(T˜ ) = (t1 +2t2 +t3)/4将实验结果由三角模糊数转化为浮点数进行对比以及绘制Pareto 前沿,并采用以下两个标准[22] 评价所获得的Pareto 解集的质量:
(1) Overall Nondominated Vector Generation(ONVG):计算所获得的Pareto 集合PF中的非支配解的数量,表示为|PF|。
(2)C-metric:测量两个Pareto 集合PF1和PF2中的解之间的支配关系。C(PF1,PF2)计算如式(12)所示,它反映了PF2中的解被PF1中的解支配或与PF1中的解相同的百分比:
当C(PF1, PF2)gt;C(PF2, PF1) 时,说明PF2 受PF1 支配的解多于PF1 受PF2 支配的解, 即Pareto 集合PF1 优于PF2。
3.1 参数设置
MOBBO 算法包含一个重要参数: 种群大小Popsize。为了研究其对MOBBO 性能的影响,将其设置为4 个不同水平{50,100,150,200}进行实验分析。同时为了防止过拟合, 随机生成校正算例:n = {20,40,60,80},m = {4,8,16},F = {2,3,4}共36种不同组合。采用贡献度CON[7] 作为衡量在不同参数水平下Pareto 解集质量的指标,CON 值越大说明解的质量越好。在测试所有实例之后,计算每个水平下的平均CON 作为响应变量值(RV) , 计算后得到4 个水平下的RV 值为{0.245 824, 0.256 858,0.251 954,0.245 364},可以看出当Popsize 为100 时效果最好,其中黑体数值表示计算结果对比最优值。
3.2 消融实验
为了验证各改进策略的有效性, 本节对比MOBBO 算法和3 种算法变体的性能指标。3 种算法变体分别为去除迁移策略(B1) 、去除变异策略(B2)和去除速度调整策略(B3)。表3~表5 分别示出了 B1、B2、B3 与 MOBBO 的 C-metric 指标对比(表中加黑数据为对比较优结果)。从表中可以看出,当分别去除迁移、变异和速度调整策略后,算法的性能普遍下降,表明3 种策略对MOBBO 算法均起到了重要作用。图2 示出了MOBBO算法与去掉迁移、变异和速度调整策略后在不同算例上的Pareto 前沿对比,其中,“I-80-8-5”中“80”代表工件数量,“8”代表机器数量,“5”代表工厂数,其他同理。
3.3 MOBBO 算法与其他算法比较
将MOBBO 与KCA、NSGA2 进行比较,所有算0:5 nC-metric法都以 CPU 时间(单位:s)作为停止准则。为了对3 种算法进行全面比较,计算各个算法在不同实例下的Pareto 集合,并根据评价指标计算得到平均ONVG(Overall Nondominated Vector Generation)以及值,实验结果分别如表6 和表7 所示。
从表6 中可以看出, MOBBO 算法的ONVG值在每个(n,m) 组合上都大于KCA 和NSGA2 的ONVG值,表明在相同时间内, MOBBO 算法能够获得比KCA 和NSGA2 更多的非支配解。这是由于Accelerate2(f) 和Decelerate2(f) 两种速度调整策略增强了算法在某一目标上的搜索能力,有效地扩大了算法的搜索范围。由表7 可知,几乎在所有的(n,m)组合上,C(MOBBO, KCA)≈1,C(KCA, MOBBO)≈0,这意味着几乎所有的KCA 算法得到的非支配解都被MOBBO得到的非支配解支配。对比MOBBO 和NSGA2,除了在工厂数F=2、(n,m) 为(20,4) 和(20,8)两种组合下,MOBBO 结果略差于NSGA2,其余规模下C(MOBBO, NSGA2)gt;C(NSGA2, MOBBO)。由于变异过程扩大算法搜索深度,并结合4 种速度调整策略,有效提高了算法搜索效率,使得算法在规定时间内表现更好。
4 结束语
为了解决以最小化最大完工时间以及最小化总能耗为优化目标的模糊节能分布式置换流水车间调度问题(FEEDPFSP) , 提出了一种有效的MOBBO算法。通过大量的数值实验,验证了所提出的MOBBO算法在解的质量和多样性方面相较于现有算法表现更为出色。这表明该算法在解决FEEDPFSP问题时具有更好的性能,并能够产生更优质和多样性的解决方案。未来的工作将聚焦更多目标下的模糊节能分布式置换流水车间调度问题,包括带有拖期约束或者机器准备时间约束等情形,致力于设计更加高效的模糊分布式流水车间调度算法。此外,将所研究的算法应用于真实的工业问题也将成为我们未来研究的重要方向。
参考文献:
[ 1 ]ZHAO F Q, HE X, WANG L. A two-stage cooperativeevolutionary algorithm with problem-specific knowledgefor energy-efficient scheduling of no-wait flow-shopproblem[J]. IEEE Transactions on Cybernetics, 2020,51(11): 5291-5303.
[ 2 ]WANG G C, LI X Y, GAO L, et al. Energy-efficientdistributed heterogeneous welding flow shop schedulingproblem using a modified MOEA/D[J]. Swarm and EvolutionaryComputation, 2021, 62: 100858.
[ 3 ]MOUZON G, YILDIRIM M B, TWOMEY J. Operationalmethods for minimization of energy consumption of manufacturingequipment[J]. International Journal of ProductionResearch, 2007, 45(18/19): 4247-4271.
[ 4 ]MOUZON G, YILDIRIM M B. A framework to minimisetotal energy consumption and total tardiness on a singlemachine[J]. International Journal of Sustainable Engineer-ing, 2008, 1(2): 105-116.
[ 5 ]DAI M, TANG D B, GIRET A, et al. Energy-efficientscheduling for a flexible flow shop using an improvedgenetic-simulated annealing algorithm[J]. Robotics andComputer-Integrated Manufacturing, 2013, 29(5): 418-429.
[ 6 ]CHE A D, WU X Q, PENG J, et al. Energy-efficientbi-objective single-machine scheduling with power-downmechanism[J]. Computers amp; Operations Research, 2017,85: 172-183.
[ 7 ]WANG J J, WANG L. A knowledge-based cooperativealgorithm for energy-efficient scheduling of distributedflow-shop[J]. IEEE Transactions on Systems, Man, andCybernetics: Systems, 2018, 50(5): 1805-1819.
[ 8 ]GAREY M R, JOHNSON D S, SETHI R. The complexityof flowshop and jobshop scheduling[J]. Mathematics ofOperations Research, 1976, 1(2): 117-129.
[ 9 ]NADERI B, RUIZ R. The distributed permutation flowshopscheduling problem[J]. Computers amp; OperationsResearch, 2010, 37(4): 754-768.
[10]WANG S Y, WANG L, LIU M, et al. An effectiveestimation of distribution algorithm for solving the distributedpermutation flow-shop scheduling problem[J]. InternationalJournal of Production Economics, 2013, 145(1): 387-396.
[11]黄佳琳, 张丫丫, 顾幸生. 基于改进生物地理学优化算法的分布式装配置换流水车间调度问题[J]. 华东理工大学学报(自然科学版), 2020, 46(6): 758-769.
[12]DENG J, WANG L. A competitive memetic algorithm formulti-objective distributed permutation flow shop schedulingproblem[J]. Swarm and Evolutionary Computation,2017, 32: 121-131.
[13]PISTIKOPOULOS E N. Uncertainty in process design andoperations[J]. Computers amp; Chemical Engineering, 1995,19: 553-563.
[14]ZHENG J, WANG L, WANG J J. A cooperativecoevolution algorithm for multi-objective fuzzy distributedhybrid flow shop[J]. Knowledge-Based Systems, 2020,194: 105536.
[15]BEHNAMIAN J, GHOMI S. Multi-objective fuzzy multiprocessorflowshop scheduling[J]. Applied Soft Computing,2014, 21: 139-148.
[16]SIMON D. Biogeography-based optimization[J]. IEEETransactions on Evolutionary Computation, 2008, 12(6):702-713.
[17]ZHANG Y Y, GU X S. Biogeography-based optimizationalgorithm for large-scale multistage batch plantscheduling[J]. Expert Systems with Applications, 2020,162: 113776.
[18]ZHANG Y Y, GU X S. A biogeography-based optimizationalgorithm with modified migration operator for large-scale distributed scheduling with transportation time[J].Expert Systems with Applications, 2023, 231: 120732.
[19]DEB K, PRATAP A, AGARWAL S, et al. A fast and elitistmultiobjective genetic algorithm: NSGA-II[J]. IEEETransactions on Evolutionary Computation, 2002, 6(2):182-197.
[20]SUN L, LIN L, GEN M, et al. A hybrid cooperative coevolutionalgorithm for fuzzy flexible job shopscheduling[J]. IEEE Transactions on Fuzzy Systems, 2019,27(5): 1008-1022.。
[21]SHAO Z S, SHAO W S, PI D C. Effective heuristics andmetaheuristics for the distributed fuzzy blocking flow-shopscheduling problem[J]. Swarm and Evolutionary Computation,2020, 59: 100747.
[22]LI B B, WANG L, LIU B. An effective PSO-based hybridalgorithm for multiobjective permutation flow shopscheduling[J]. IEEE Transactions on Systems, Man, andCybernetics-Part A: Systems and Humans, 2008, 38(4):818-831.
(责任编辑:李娟)
基金项目: 国家自然科学基金(61973120)
猜你喜欢
建筑科学与工程学报(2016年6期)2017-01-18 15:37:05
数学学习与研究(2016年17期)2017-01-17 18:31:20
软件导刊(2016年11期)2016-12-22 21:30:28
中国科技博览(2016年19期)2016-10-19 13:10:22
中国科技博览(2016年19期)2016-10-19 12:51:06
中国科技博览(2016年18期)2016-10-19 11:23:00
中国科技博览(2016年18期)2016-10-19 07:47:05
电脑知识与技术(2016年21期)2016-10-18 22:51:02
科学与财富(2016年28期)2016-10-14 20:02:56
科技视界(2016年20期)2016-09-29 11:43:16
