
平衡信息与动态更新的原型表示联邦学习
2024-01-03 00:00:00徐炜钦肖婷王喆
华东理工大学学报(自然科学版) 2024年6期
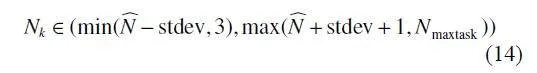
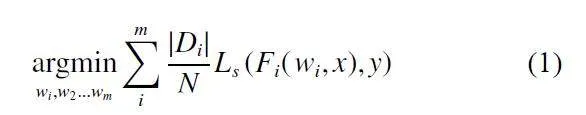






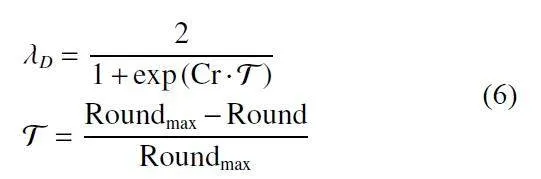
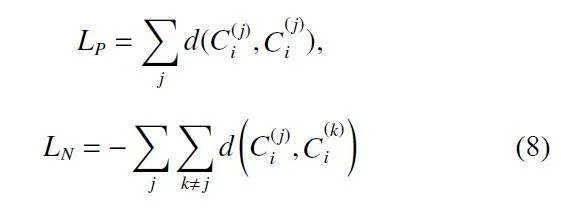
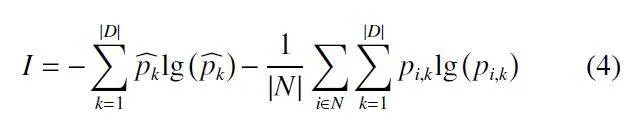
摘要:联邦学习(FL)是一种分布式机器学习方法,旨在通过训练模型而不共享客户之间的原始数据来解决隐私问题。然而,跨客户端数据的异构性会阻碍FL 中的优化收敛性和泛化性能。为了解决这个问题,本文提出了平衡信息与动态更新的联邦原型学习(BD-FedProto)框架,它由两个组件组成:原型调度的动态聚合(DA)和对比原型聚合(CPA)。前者动态地调整局部学习和全局学习之间的比例,以平衡局部知识和全局知识的有效性;后者利用缺失的类作为负样本,通过统一的原型集群来学习未知的分布。在CIFAR-10 和MNIST 数据集上的实验结果表明,BD-FedProto 能有效提高FL 的分类性能和稳定性。
关键词:联邦学习;特征空间聚合;原型表示;对比学习;数据异构
中图分类号:TP391 文献标志码:A
联邦学习(FL)框架[1] 是一个分布式深度学习框架,它处理图像、文本和语音领域的问题,应用于遵守某些约束的同时实现数据交互。数据在医学和军事等领域受到严格控制, 而情报依赖于生产力[2],FL 是解决这种冲突的合适方法。然而,提供数据的客户端通常不能在数据收集阶段评估他人分享的数据,从而导致跨客户端的异构数据[3]。
知识蒸馏(KD)的FL 框架,作为解决数据异构性挑战的替代方案,可以解决通信成本高和不灵活的结构问题,如文献[4] 提出了一种考虑模型可信度的方法,以减轻噪声和提取知识的影响。然而基于KD 的方法,会受到公共数据集之间的偏差和客户端本地数据分布的影响[5],造成这些问题的根本原因是异构联邦学习的泛化性能要求:首先,是全局模型的泛化能力,在知识迁移的过程中,能否得到一个泛化的全局模型是至关重要的;其次,局部模型是否能够识别偏差,并在学习过程中采用定制的调整策略,决定了其适应新场景的能力。
本文提出了一种对比原型聚合(CPA)方法,该方法对正样本和负样本进行比较,以减轻不相关样本对全局学习过程的影响。它将目标类别的全局原型标签作为负样本,并应用于全局学习阶段的对比损失,使局部原型更接近正样本类,而远离负样本类。同时,提出了一种动态调整(DA)策略来平衡全局一致性学习和局部监督学习之间的关系。在一个完整的轮次中,DA 策略分别记录总损失各部分,计算各部分减少率,最后通过比较损失函数方法来拟合全局原型的置信度。
本文将CPA 和DA 统一到同一个框架设计了平衡信息与动态更新的联邦原型学习(BD-FedProto),解决了全局模型和局部模型之间信息不平衡问题,以及由于收敛效率的差异而导致的局部模型的漂移问题。通过计算全局聚合阶段的损失与局部监督学习阶段的损失,将二者进行比较,使全局学习与局部学习的权重动态调整,令平衡全局信息与局部信息的速率达到相对平衡。
1 相关工作
由FedAvg[1] 表示的集中式FL 框架主要分为两个步骤: (1) 每个客户端获取模型的全局知识,并使用本地数据进行训练;(2) 服务器使用本地模型更新全局知识。由于数据分布在本地模型中的偏差,数据的异构性往往会严重影响服务器的聚合效应。具有聚合参数的FL 框架在克服异构模型的挑战方面取得了许多突破。文献[6] 提出添加正则化项来优化模型,而文献[7] 提出添加一个全局模型,并比较前一个模型的逻辑输出来更新局部模型。文献[8] 提出,服务器对不同客户端的不同网络层使用不同的权值来计算权值矩阵,并利用权值矩阵对权值进行聚合和更新,以实现个性化处理。这些方法虽然在一定程度上缓解了数据异构性引起的模型聚合偏差,但也增加了参数聚合的通信负载,降低了框架的效率。
解决异质性挑战的一种新颖的方法是通过KD 的FL 框架。文献[9] 提出使用初始模型和以前的模型进行连续学习,以最小化针对不同客户的公共数据集的大型网络相关性矩阵。而文献[4] 提出了基于反交叉熵来判断客户的噪声比,并定义客户的可信度,以更好地利用客户的数据。在联邦学习中,KD 的优势在于它能够控制逻辑输出、传输全局知识, 以及它对模型变化的更高容忍度。然而,KD 需要额外的公共数据集,并且为传输教师模型产生了很高的通信成本。同时,文献[9] 提出了一种聚合任务原型的方法,该方法具有对模型异构性的容忍度高、通信成本低的优点。
缓解FL 全局模型缺乏的关键是改进全局模型的泛化和个性化局部模型的学习过程。一方面,由于模型和数据的异质性,异质性FL 需要增加对全局模型的泛化。为了解决这一挑战,域泛化(DG)[10-13]被开发为域适应[14-17] 的扩展。文献[18] 提出,分类器倾向于记忆训练域,而忽略来自其他域的信息,而DANN[19] 则使用对抗性学习来使模型域不变。这些方法已被扩展到联邦学习域泛化(FedDG)[20-22]中,通过校正非IID(Independent Identically Distribution) 数据[23] 引起的漂移来提高全局模型的泛化。文献[24] 使用一个生成器从输入空间中提取知识并将其转移到全局模型中,而文献[25] 通过连续谱空间进行插值来补充域,得到一个更广义的域。在更新中添加正则化约束来纠正漂移。文献[26] 通过对连续的频谱空间进行插值来补充该域,从而得到一个更广义的域。
相反地,当全局模型的泛化能力不足时,解决问题的方法就会转向解决局部模型和全局模型的差异。提高FL 能力的一种方法是通过个性化的本地学习过程[27-28],如Per-FedAVG[29] 通过改进FL 框架来增强个性化。
2 基于原型表示的FL
2.1 FL 问题设置
在真实的FL 环境中,每个客户端都拥有自己的本地隐私数据集,并且每个客户端的数据分布可能是不同、重叠或不相关,这种现象被称为统计异质性。在统计异质性设置中,第i个客户端分布记为Fi (wi),其中w为局部模型的权重,每个客户端的w是不同的。训练阶段的优化目标定义为:
其中,Di和N分别为客户端的本地数据集和所有数据的数量。m是FL 组中的客户数量。在异质性的情况下,权重wi不同,因此通信和聚合原型比参数聚合的FL 更有效。
2.2 整体框架
本文整体框架由服务器和若干本地模型组成。组成本地模型是标准的深度神经网络,包含两个组成部分:(1) 编码器:第i个客户端的编码器fi (φi)由φi参数化,x的编码嵌入被表示为f (φ, x)。(2) 分类器:通常分类器是一个标记为g(v)的线性层,它生成一个预测的逻辑输出, 其分类器权重为v, 模型Fi (φi) · g(v) = Fi (wi)。原型Cj是第j类嵌入f (φ, x)的平均值,φ为特征提取器权重,F代表全局模型,f 为该模型提取的特征嵌入输出。
本文算法如图1 所示,它包括两个阶段:第1 阶段在服务器上执行,将上传的本地原型进行集成,得到全局原型。同时服务器负责向本地模型传输全局信息。第2 个阶段是本地训练阶段,先由本地数据生成编码嵌入,分别用于计算本地原型与生成预测结果。由预测结果与真实标签计算监督损失,本地原型则与全局原型计算对比损失。
训练步骤中的总体损失函数如式(2) 所示:
总体损失包括监督损失 LS 和正则化项损失 LR 。监督损失LS负责指导本地模型学习客户端的数据即,而正则化项损失LR负责指导局部模型学习全局模型的信息。
为了在客户端之间实现一致的原型分布,本文方法的正则化项损失为对比损失(LC),其目的是使局部原型分布更接近全局分布,同时最小化分类误差。总体损失函数定义为
L(Di,ωi) = LS (Fi(ωi,"x),"y)+α·λD·LC(Ci,C) (3)
监督损失LS采用经典的交叉熵损失,此处的超参数α固定为1,对比损失LC是全局原型C和本地原型Ci之间的均方损失函数,是正则化项损失LR的具体形式,负责维护全局分布的一致性。λD是一个控制全局学习效率的动态参数。
2.3 动态调整的全局表征学习
虽然基于KD 的FL 对数据异质性表现出了很高的容忍度,但它假设所有客户端都包含相同数量的有效信息,并在全局和局部学习中使用固定比例的参数,但当局部数据集发生变化时,这可能会导致学习效率的偏差。为了解决这个问题,本文通过信息熵进行了不同阶段的信息量评估。
为了评估全局分布与本地分布的信息熵,互信息(MI)可通过式(4) 进行计算:
其中,︿pk是本地数据集中类k的平均概率,|N|为任务数量,|D|为数据集规模。pi,k是一个样本xi的类k的概率。
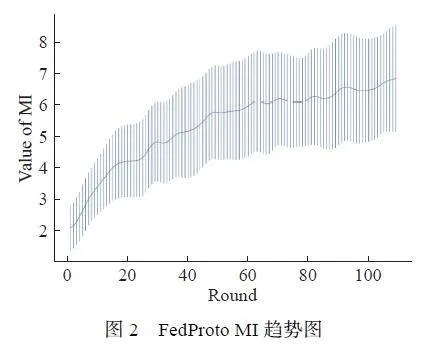
如图2 所示,随着训练进行,原始FedProto 中的互信息(MI)逐渐增加,全局模型捕获更有效信息,更好地适合真实数据。然而,随着学习过程的进行,MI 的值也会增加,说明所有客户的全局学习效率都有很大方差。
从交叉熵与原型距离的定义可以发现,交叉熵越低表示局部模型与局部数据的拟合较好,而原型距离损失越低表示局部模型与全局模型的拟合较好。
因此,通过对交叉熵与原型距离进行对比,可以推导得出全局模型相对与局部模型的置信度。监督损失LS表示局部数据的学习程度,而正样本LP的距离表示全局数据的学习程度。置信度计算方法如公式(5) 所示:
其中, 上标prev 代表上一轮的输出。在上述假设的基础上,本文提出了一个基于模拟退火方法的动态参数λD,如公式(6) 所示:
其中,Т为温度参数,Round 为训练轮次。为了保证最终整体模型的稳定性,本文采用模拟退火方法来调整损失模块的可接受程度,并动态调整损失模块全局部分的学习率。
2.4 三元对比学习
在全局学习过程中,客户端中不存在的类别仍然会影响中心服务器中的聚合,进而影响本地模型。为了减少无关类别的影响,本文提出正、负样本聚合的方法,将标签不同的所有原型去掉具体标签后作为正样本,虽然引入了缺失类,但由于负样本抹除了标签,因此对于客户端是透明的,不存在数据安全风险。这种方法补充了嵌入空间中的信息。总体对比损失表示为公式(7):
LC = LP +β·LN (7)
其中, LP 和 LN 分别是正样本和负样本的对比损失。可定义为公式(8):
其中, d(·) 为度量函数,C 为该类别样本的原型表示,上标表示类别。
2.5 收敛分析
为了验证模型的收敛性,本文引用了以下几个假设来证明推导过程。
定义1: 第i个客户端的分布可以用子分布j( j ∈ |Di|)表示,如:
φi = φi,1∩…φi,"j,∀"j ∈ |Di| (9)
定义 2:全局分布由k(k∈"|Di|)个子分布构成,如公式(10):
φi,1 ∩…φi,k,∀k ∈"|Di|
φi,1∩φNi,"j = 1 (10)
根据定义1 和定义2,负样本分布定义为公式(11):
φi,1 ∩…φi,k = φNi,"j,
∀k∈"|Di|",∀ j ∈"|Di|,"k≠"j (11)
其中,E(·) 为期望值函数,E 为局部学习的周期,e 为E 的最小单位,G 为梯度。
当一个新的客户端加入FL 组时,只需要客户端在中心服务器中下载原型,并初始化其模型,然后调整其本地模型。与FedProto 相比,本文方法更平衡、偏差较小,并产生了一个更通用的全局模型。当覆盖一定数量的全局类时,下载的数据量从本地数据集中覆盖的类的数量增加到所有类的数量,在绝大多数情况下,这是可以接受的。与其他FL 方法相比,本文方法不需要权重交换,且具有较高的通信效率,同时在域内没有样本的情况下,具有忽略信息的好处。此外,本文方法聚合了与现有样本相似的未知样本的偏差。由于原型计算采用平均的方式,当客户的样本分布不平衡时,本文方法可能会比聚合参数的FL 方法具有更大的偏差。此外,当每个客户端的任务没有重叠时,基于原型的方法会陷入独自训练的情况。
3 实验部分
3.1 实验设置
本实验采用了典型的训练设置,即中央服务器传输信息,每个客户端都拥有自己的私有数据,并使用 MNIST[30] 和CIFAR-10[31] 两个流行的数据集进行评估。实验在非IID 局部任务分布中应用了FedProto的异构设置。为了模拟在现实中常见的异构性,实验中采取了随机采样的方式,对标准差与平均任务数量进行固定的设置。实验中,每个客户端监督学习的任务分布采用了小样本学习中的N-way Kshot的概念来定义采样计划,其中N 和K 分别为训练阶段的平均任务数和每个任务的平均样本数。为了模拟异质性,实验随机调整了N 和K 的值。具体来说,每个客户端利用式(14) 得到N 和K:
其中,Nk 为每个客户端具体的任务数量, N︿ 为预设的平均任务数量,Nmaxtask 为最大任务数量。
基准测试是FedProto[9]、FedAvg[1]、FedProx[6] 以及不进行通讯的局部训练。
MNIST 的局部模型是一个2 层的CNN 网络,CIFAR-10 中的骨干网络是ResNet-18[32],在PyTorch提供的整个CIFAR-10 测试数据集上,该预训练模型的初始测试精度为27.55%。在实验过程中,学习率设置为0.01,客户端数量为20 个。α和β的值都被设置为0.5。
3.2 实验结果
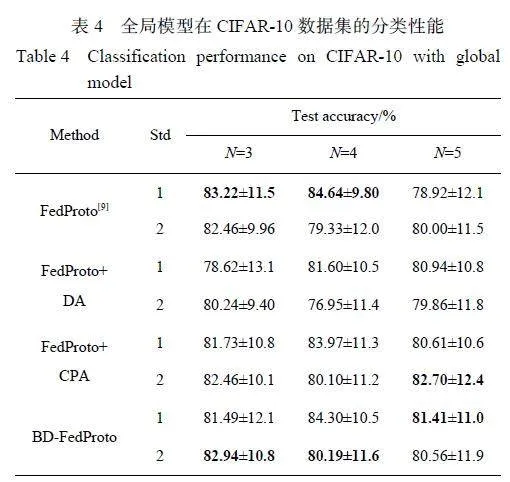
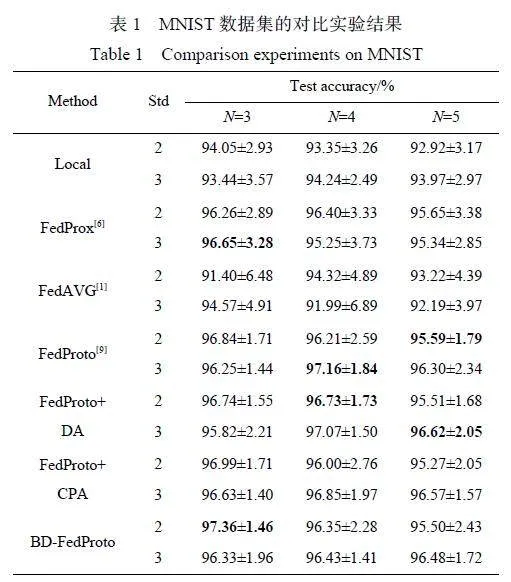
表1 与表2 所示分别为数据集MNIST 和CIFAR-10 的对比实验结果。结果表明,BD-FedProto比其他方法具有更高的测试精度,且在大多数情况下表现最为稳定。对于4-way 和5-way 的情况,带有CPA 模块的框架通常可以获得更好的性能。
在3 种情况下,带有CPA 模块的框架不能在保持良好稳定性的同时保持更高的分类性能。这是因为在CIFAR-10 数据集上随机采样N 类,因此异质性随着类别数量的增加而减小。因此,当异质性较高时,信息越平衡,框架的整体稳定性就越高,但整体分类性能越低。随着异构性的减少和信息的补充,框架的整体性能也有所提高,这可能是当补充信息空间时,分类更倾向于更关注重叠率较高的类别,而忽略了一些孤立的类别。
然而,在异质性较高的情况下,大部分分类任务属于低重叠率类别,导致整体性能下降。相比之下,在异质性较低的情况下,主要分类任务转变为具有较高重叠率的任务,其性能改进是决定模型整体性能的主要因素。在MNIST 数据集的实验中,任务难度相对较低,模型深度不高,优化难度较低。因此,参数聚合方法大大缓解收敛缓慢的缺点,针对异构场景的FedProx 在某些场景中取得了优异的性能,与其他框架相比,BD-FedProto 仍然具有一定的优势。
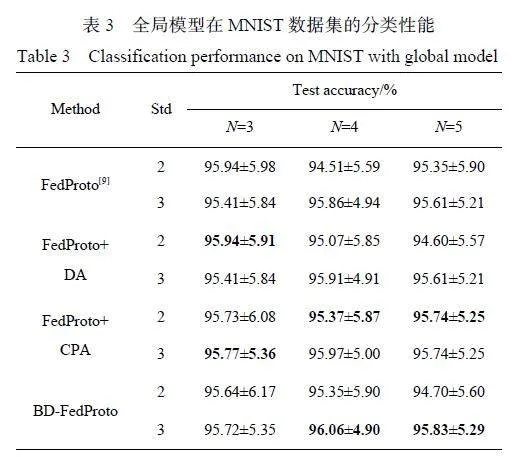
表3 和表4 分别示出了使用全局原型在MNIST 数据集和CIFAR-10 数据集上进行分类性能的实验结果。结果表明,该方法在大多数情况下都优于基线模型,证明了该方法在提高原型聚合的泛化性能方面的有效性。在使用全局模型进行分类的实验中,本文的全局模型在合并CPA 模块时表现良好,通过CPA 模块来增强负样本,导致了局部模型可访问的信息池的显著放大。因此,局部模型的特征提取器倾向于收敛统一的原型进行分类。
同样,在全局模型分类任务中,当场景中的异质性降低时, CPA 模块分类性能优异。相比之下,DA 模块在不与CPA 模块配对时,会动态调整其速率,增加局部模型的个性化,导致全局模型和局部模型之间的差异更大,最终降低分类性能。
3.3 消融实验
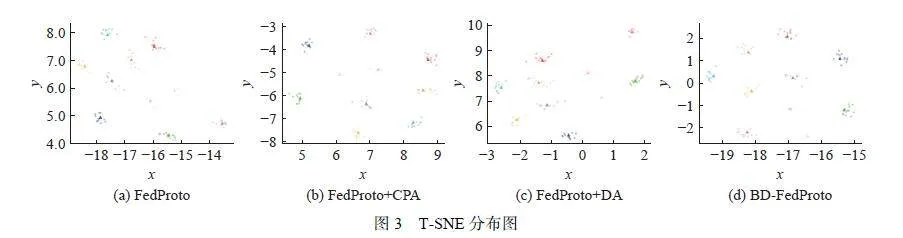
本文对不同模块进行了消融实验,并使用TSNE[33] 给出了结果,图3 显示了不同模块影响下的T-SNE 分布,不同的类别用不同的颜色标记,全局原型用方块标记。从图中来看,CPA 的加入令FedProto中的原型分布更加均匀。
本文对DA 模块的动态参数λD进行了实验,结果如图4 所示。由图可得,在收敛阶段,λD有显著的波动,这表明有必要加入一个温度参数Τ 。
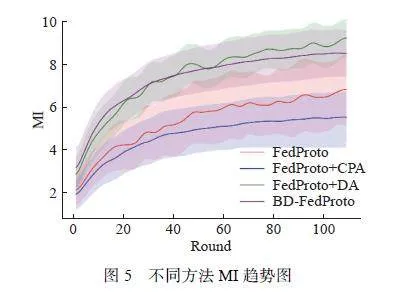
图5 示出了不同方法对MI 的影响,CPA 方法提高了全局模型的稳定性和平衡客户,而DA 方法显著提高了全局模型的收敛效率。
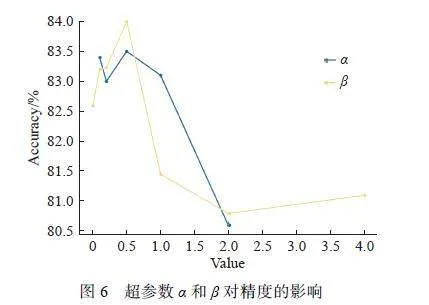
3.4 超参数
本文在CIFAR-10 中设置N=5 和K=100, 测试α和β对精度的影响,结果如图6 所示。可以看出,当α和β超过0.5 时,总体精度显著下降,这有可能是在全局原型的学习率过大,从而导致学习效率较低。因此本文最优取值为0.5。
4 结束语
BD-FedProto 同时包含了CPA 和DA,是专门为解决FL 中的异质性和不平衡信息问题而设计的。在BDFedProto 中,CPA 解决了由信息不平衡引起的局部模型中的漂移问题,它引入了缺失的类作为负样本来弥补样本空间信息缺失的问题;同时,DA 采用了一种新的调度器来动态调整局部学习和全局学习的比例。这种方法解决了在不同的局部模型中学习率不平衡的问题,本文可以调整簇在样本空间中的分布,使其更加均匀。实验结果表明,与最近的方法相比,本文方法在异质性场景方面取得了更好的准确性和稳定性。
虽然BD-FedProto 在分类性能和稳定性方面取得了改进,但本文存在一定的局限性和假设。首先,全局模型假设了一个广义和统一的原型,而局部模型可能有不同的应用场景和焦点区域,并且在局部模型中嵌入全局原型的网络是否能提高性能尚不清楚。此外,原型网络本身是一种聚类模型,使用线性分类器可能会降低其性能。这些限制和假设需要在未来的研究中得到进一步的探索和解决。
参考文献:
[ 1 ]MCMAHAN B, MOORE E, RAMAGE D, et al.Communication-efficient learning of deep networks fromdecentralized data[C]// In Artificial Intelligence and Statistics.New York: PMLR, 2017, 50: 1273-1282.
[ 2 ]LONG G, TAN Y, JIANG J, et al. Federated learning foropen banking[M]//Federated Learning. [s.l.]: Springer,2020: 240-254.
[ 3 ]MENDIETA M, YANG T, WANG P, et al. Local learningmatters: Rethinking data heterogeneity in federated learning[C]// In Proceedings of the IEEE/CVF Conference onComputer Vision and Pattern Recognition. New York:IEEE, 2022: 8397-8406.
[ 4 ]FANG X, YE M. Robust federated learning with noisy andheterogeneous clients[C]// In Proceedings of the IEEE/CVFConference on Computer Vision and Pattern Recognition.New York: IEEE, 2022: 10072-10081.
[ 5 ]LIN T, KONG L, STICH S U, et al. Ensemble distillationfor robust model fusion in federated learning[C]//NIP'20:Proceedings of the 34th International Conference on NeuralInformation Processing Systems. Vancouver: Neural InformationProcessing Systems Foundation, 2020: 2351-2363.
[ 6 ]LI T, SAHU A K, ZAHEER M, et al. Federated optimizationin heterogeneous networks[EB/OL]. (2020-07-16)[2021-08-09]. https://proceedings.mlsys.org/paper_files//paper2020/file/1f5fe83998a09396ebe6477d9475ba0c-Paper.pdf.
[ 7 ]LI Q, HE B, SONG D. Model-contrastive federated learning[C]//IEEE/CVF Conference on Computer Vision andPattern Recognition. New York: IEEE, 2021: 10713-10722.
[ 8 ]MA X, ZHANG J, GUO S, et al. Layer-wised modelaggregation for personalized federated learning[C]//IEEE/CVF Conference on Computer Vision and Pattern Recognition.New York: IEEE, 2022: 10092-10101.
[ 9 ]TAN Y, LONG G, LIU L, et al. Fedproto: Federated prototypelearning across heterogeneous clients[C]//AAAI Conferenceon Artificial Intelligence. Menlo Park: AAAI Press,2022, 1: 3.
[10]ZHOU K, LIU Z, QIAO Y, et al. Domain generalization: Asurvey[J]. IEEE Transactions on Pattern Analysis andMachine Intelligence, 2022, 45: 4396-4415.
[11]LI D, YANG Y, SONG Y Z, et al. Deeper, broader and artierdomain generalization[C]//IEEE International Conferenceon Computer Vision. New York: IEEE, 2017: 5542-5550.
[12]MUANDET K, BALDUZZI D, SCHÖLKOPF B.Domain generalization via invariant feature representation[C]//International Conference on Machine Learning. NewYork: PMLR, 2013: 10-18.
[13]LI H, PAN S J, WANG S, et al. Domain generalizationwith adversarial feature learning[C]//IEEE/CVF Conferenceon Computer Vision and Pattern Recognition. NewYork: IEEE, 2018, 5400-5409.
[14]YOU K, LONG M, CAO Z, et al. Universal domain adaptation[C]//IEEE/CVF Conference on Computer Vision andPattern Recognition. New York: IEEE, 2019: 2720-2729.
[15]GANIN Y, LEMPITSKY V. Unsupervised domain adaptationby backpropagation[C]//International Conference onMachine Learning. New York: PMLR, 2015, 37: 1180-1189.
[16]BEN-DAVID S, BLITZER J, CRAMMER K, et al. Analysisof representations for domain adaptation[C]// Advancesin Neural Information Processing Systems. Vancouver,Canada: Neural Information Processing Systems Foundation,2006: 137-144.
[17]TZENG E, HOFFMAN J, SAENKO K, et al. Adversarialdiscriminative domain adaptation[C]//IEEE Conference onComputer Vision and Pattern Recognition. New York:IEEE, 2017: 7167-7176.
[18]CHU X, JIN Y, ZHU W, et al. Dna: Domain generalizationwith diversified neural averaging[C]//International Conferenceon Machine Learning. New York: PMLR, 2022: 4010-4034.
[19]RANGWANI H, AITHAL S K, MISHRA M, et al. Acloser look at smoothness in domain adversarialtraining[C]//International Conference on Machine Learning.New York: PMLR, 2022: 18378-18399.
[20]WANG R, HUANG W, SHI M, et al. Federated adversarialdomain generalization network: A novel machinery faultdiagnosis method with data privacy[J]. Knowledge BasedSystems, 2022, 256: 109880.
[21]NGUYEN A T, TORR P, LIM S N. Fedsr: A simple andeffective domain generalization method for federatedlearning[C]//Advances in Neural Information ProcessingSystems. New Orleans: Neural Information ProcessingSystems Foundation, 2022: 38831-38843.
[22]QU L, ZHOU Y, LIANG P P, et al. Rethinking architecturedesign for tackling data heterogeneity in federatedlearning[C]// In Proceedings of the IEEE/CVF Conferenceon Computer Vision and Pattern Recognition. New York:IEEE, 2022: 10061-10071.
[23]KARIMIREDDY S P, KALE S, MOHRI M, et al. Scaffold:Stochastic controlled averaging for federated learning[C]//International Conference on Machine Learning. New York:PMLR, 2020: 5132-5143.
[24]ZHANG L, SHEN L, DING L, et al. Finetuning globalmodel via data-free knowledge distillation for non-iid federatedlearning[C]//Proceedings of the IEEE/CVF Conferenceon Computer Vision and Pattern Recognition. NewYork: IEEE, 2022: 10174-10183.
[25]CHENG A, WANG P, ZHANG X S, et al. Differentiallyprivate federated learning with local regularization andsparsification[C]//Proceedings of the IEEE/CVF Conferenceon Computer Vision and Pattern Recognition. NewYork: IEEE, 2022: 10122-10131.
[26]LIU Q, CHEN C, QIN J, et al. Feddg: Federated domaingeneralization on medical image segmentation via episodiclearning in continuous frequency space[C]//IEEE/CVFConference on Computer Vision and Pattern Recognition.New York: IEEE, 2021: 1013-1023.
[27]TAN A Z, YU H, CUI L, et al. Towards personalized federatedlearning[J]. IEEE Transactions on Neural Networksand Learning Systems, 2022, 34: 9587-9603.
[28]T DINH C, TRAN N, NGUYEN J. Personalized federatedlearning with moreau envelopes[C]// Advances in NeuralInformation Processing Systems. Vancouver, Canada:Neural Information Processing Systems Foundation, 2020:21394-21405.
[29]FALLAH A, MOKHTARI A, OZDAGLAR A.Personalized federated learning with theoretical guarantees:A model-agnostic meta-learning approach[C]// Advances inNeural Information Processing Systems. Vancouver,Canada: Neural Information Processing Systems Foundation,2020: 3557-3568.
[30]YANN L. The mnist database of handwrittendigits[EB/OL]. (1998-06-18) [1998-09-26]. http://yann.lecun.com/exdb/mnist/.
[31]KRIZHEVSKY A, HINTON G. Learning multiple layers offeatures from tiny images [EB/OL]. (2009-01-28) [2009-07-19]. http://www.cs.toronto.edu/~kriz/learning-features-2009-TR.pdf.
[32]HE K, ZHANG X, REN S, et al. Deep residual learning forimage recognition[C]//IEEE Conference on Computer Visionand Pattern Recognition. New York: IEEE, 2016: 770-778.
[33]VAN DER MAATEN L, HINTON G. Visualizing datausing t-SNE[J]. Journal of Machine Learning Research,2008, 9: 2579-2605.
(责任编辑:王晓丽)
基金项目: 国家自然科学基金(62076094);上海市科技计划项目‘联邦框架下跨域/跨任务增量学习方法研究’(21511100800)
