
一种基于StyleGAN 生成器的自监督人脸正面化模型
2024-01-03 00:00:00谢立志刘漫丹朱宝旭张雯婷
华东理工大学学报(自然科学版) 2024年6期
关键词:生成对抗网络










摘要: 提出了一种基于StyleGAN 生成器的新型自监督人脸正面化模型( Self-SupervisedFace Frontalization Model,SFM),通过改变潜空间编码实现人脸正面化。为了合成质量优异的正面人脸图像,使用对比语言图像预训练( Contrastive Language Image Pretraining,CLIP)模块和自适应增强模块(Adaptive Enhancement Module,AEM)来编辑潜空间,在最大程度上只修改面部姿态而不修改面部的其他特征。研究结果表明,本文方法无需配对人脸数据集训练就能生成质量优且完整的正面人脸图像。在定性和定量实验数据的比较中,本文方法最优。
关键词:人脸正面化;潜空间编辑;生成对抗网络;StyleGAN;预训练
中图分类号:TP391 文献标志码:A
人脸正面化是一种图像处理技术,其目的是将人脸图像从侧面不同的角度转换为正面角度,是计算机视觉领域的一项重要研究课题。随着深度学习的不断发展,许多学者提出了解决人脸正面化的方法,应用于多个领域。首先,人脸在人脸识别[1-2]、面部编辑[3] 和虚拟现实[4-5] 等许多应用中发挥着重要作用,然而,由于人脸图像的多样性和复杂性,人脸识别等任务在非正面视图中往往表现不佳。因此,正面化技术可以提高这些任务的准确性和可靠性。此外,人脸正面化还可用于数字艺术、娱乐和游戏等应用领域。通过改变人脸图像的角度和姿态,可以为用户提供更加个性化的选择和娱乐体验。根据目前大多数学者的研究,可以将人脸正面化方法大致分为两类:基于三维模型的方法和基于深度学习的方法。
基于三维模型的人脸正面化通常是利用二维人脸图像和三维人脸模型之间的对应关系来实现旋转、变形和渲染等操作的。Asthana 等[6] 提出了一种三维姿态归一化方法,将非正面人脸图像映射到对齐的三维人脸模型上,并通过调整该三维模型的姿态获得正面人脸图像。随后,Hassner 等[7] 提出了一种简单有效的生成正面人脸的方法,即使用单一不变的三维形状生成正面人脸。Zhu 等[8] 考虑到传统3DMM 计算速度慢等问题,提出了一种基于3DMM的高保真姿态和表情归一化(High-Fidelity Pose andExpression Normalization ,HPEN)方法[9]。然而,这种方法在处理大姿态人脸时效果较差,而且存在模型结构复杂、运行速度慢等问题。
随着深度学习的不断发展,人脸正面化的研究也得到了很大的进步。起初,它们大多基于自编码器[10-11] 和卷积神经网络[12-13] 等网络结构,近年来越来越多的相关研究开始使用生成对抗网络( Generative Adversarial Network, GAN) 。GAN[14] 是近年来流行的模型,被广泛应用于计算机视觉和图像处理领域。Huang 等[15] 提出了一种双路径生成对抗网络(Two-Pathway Generative Adversarial Network,TP-GAN),它包含4 个有边界位置的跳转网络和一个全局编码器-解码器网络。通过将对抗性损失、对称性损失和特性保持损失相结合,TP-GAN 在生成正面视图的同时保留了全局结构和局部细节。Tran 等[16] 认为,最好能联合执行人脸识别和人脸正面化这两项任务,以便它们能相互结合使用。在此基础上,他们提出了3 种不同的新型分离表征学习-生成对抗网络( Disentangled Representation Learning-Generative Adversarial Networks ,DR-GAN)。DR-GAN以 CGAN( Cycle GAN) [17] 为基础,增加了一些新功能,包括编码器-解码器结构生成器、位姿编码、鉴别器中的位姿分类以及集成的多图像融合方案。Tu等[18]提出了一种名为 \"多生成人脸恢复( Multi-Degenerate Face Recovery, MDFR) \"的模型。该模型能够从给定的低质量图像中恢复出任何面部姿势的高质量正面人脸图像。Duan 等[19] 还提出了一种新颖的掩码引导的两阶段生成对抗网络,它是一种基于掩码的注意力模型以利用噪声的先验信息,并通过U 型连接将其集成到两阶段中。
虽然许多基于深度学习的方法都能实现人脸正面化,但这些方法大多是基于成对人脸数据集进行训练的。Richardson 等[20] 提出了一种基于StyleGAN[21]的图像翻译网络,该网络可实现端到端的人脸正面化,且无需使用配对人脸数据集进行训练。然而,它无法控制人脸正面化过程中的潜空间编辑,这导致除了人脸姿态变化外,人脸的其他特征也会发生相应的变化。本文提出了一种基于StyleGAN 生成器的新型自监督人脸正面化模型(SFM),通过编辑潜空间编码解决了这一问题。这样,无需使用配对数据集进行训练,就能生成高质量的正面人脸图像。
1 自监督人脸正面化模型框架及其实现
本文提出的框架建立在具有W+潜空间的预训练StyleGAN 生成器之上。首先通过编码器对图像进行反演,将其映射到潜空间W+,然后编辑潜空间中的潜编码,并将其送入预训练的StyleGAN 生成器,从而得到最终合成的正面人脸图像。
1.1 SFM 整体网络结构
本文的整体网络框架如图1 所示,主要由4 个模块组成: GAN 反演模块( GAN inversion module) 、正面化反演模块(Frontalization inversion module)、潜空间编辑模块( Latent space manipulation module)和StyleGAN生成器模块( StyleGAN generator module)。本文的大致思路是将输入人脸图像通过GAN 反演模块映射到潜空间,得到对应的潜编码,然后根据正面化反演模块和潜空间编辑模块改变潜编码中的人脸姿态相关信息,得到转正后的潜编码,最后将转正后的潜编码送入StyleGAN 生成器合成正面人脸图像。其中GAN反演模块的目的是将输入人脸图像x映射到潜空间W+,本文采用预先训练好的e4e 编码器[22] 作为GAN 反演模块,得到输入人脸图像 的潜编码w,以备后续潜空间编辑。通过编码器得到的人脸图像潜编码w是一个18×512 维的向量,也就是18 个不同的风格编码,每个风格编码控制着人脸的相应特征,通过改变这些参数可以改变人脸的相应特征。将人脸图像x和文字输入正面化反演模块得到所需的正面化潜编码wfron,是后面潜空间编辑的主要依据。为了能通过编辑潜编码来实现人脸正面化,本文将w和wfron一起输入潜空间编辑模块,得到编辑后的潜编码w′。为了获得更好的编辑效果,潜编码w被分为可编辑部分wedit和固定部分wfix。在编辑过程中,只对可编辑部分wedit进行编辑,得到编辑后的w′edit,而固定部分wfix则保持不变,以尽可能确保除脸部姿态外的其他特征不被改变,获得更好的正面化效果。将wedit替换为w′edit,就得到了编辑后的潜编码w′。最后,将编辑后的潜编码w′输入预训练的StyleGAN 生成器,得到合成的正面人脸图像x^ 。
1.2 正面化反演模块
正面化反演模块是在网络中实现潜编码编辑的关键模块,通过它可以得到正面化编码wfron。正面化反演模块的结构如图2 所示。
在获得输入图像潜编码w之后,需要对人脸图像潜编码w进行编辑,尽量只改变面部姿态特征,而不改变其他特征。要完成潜编码的编辑操作,需要利用相应的模块来获取相应的改变编码。首先,为确保面部身份特征尽可能保持不变,将输入的人脸图像送入身份特征编码器(ID Encoder),以获得面部特征fid。然后,通过全连接层(MLPs)将面部特征fid映射到潜空间,得到对应的潜编码wid。获取wid的主要目的是确保将人脸图像输入到正面化反演模块后,面部身份特征信息保持不变。面部特征提取模块使用Arcface 模块[23],该模块在应用于面部识别等任务时表现出良好的性能。
然后,需要获取相应的潜编码来改变面部姿态,使面部正面化。这部分主要利用CLIP 模型强大的文本图像对应能力,监督相应潜编码变化的形成。将输入人脸图像 x送入到CLIP 图像编码器( CLIPimage encoder)后,得到输入人脸图像的图像编码ei。将文本输入CLIP 文本编码器(CLIP text encoder),得到文本编码et。由于本文的目标是将输入的人脸图像正面化, 因此输入文本是 \"人脸正面化( Facefrontalization)\"。
通过CLIP 图像编码器得到的输入人脸图像的图像编码ei并不是正面人脸的图像编码,因此还设计了AEM (Adaptive enhancement module) 模块来提取输入人脸图像编码ei中与文字编码et相近的部分。因为编码et对应的是正面人脸图像,这样可以使人脸图像编码更接近正面人脸。AEM 模块的结构如图3 所示。将ei输入AEM模块后,该编码经过全连接层MLPs 后将被分解为e+i、e-i、e+i与所需的文字编码et尽可能接近,然后对e+i部分进行一定程度的强化,再与e-i相加并组合,得到最终的输入人脸图像编码e'i,该编码与文字编码et更加接近,以便后续对潜编码进行编辑。这里采用对e+i进行γ倍放大的方法来实现对e+i部分的增强,经过多次实验比较,选择γ=2作为放大倍数,以达到最佳实验效果。具体计算式如下:
ei = Ci (x) = e+i+e-i (1)
et = Ct (text) (2)
e′i = AEM(ei, et) ="γe+i+e-i (3)
其中,text代表输入的文本,Ci、Ct和AEM 分别代表CLIP 图像编码模块、CLIP 文本编码模块和AEM模块,公式(3) 对应的是AEM 模块的计算公式。在实验过程中,主要是通过对MLPs 网络的不断训练,让不同的输入人脸图像的图像编码ei都可以分解出靠近文字编码et的那一部分e+i,然后再对e+i这一部分进行相应的加强,实现对图像编码转正的自适应加强。
通过正面化反演模块可以得到3 个潜空间编码wid、et和e′i。获得的这3 个潜编码具有相同的维度,我们将它们拼接在一起,以方便后续的潜空间操作。本文将这3 个潜编码用图中的正面化编码wfron表示,以便后续编辑潜编码w实现人脸正面化。
1.3 潜空间编辑模块
通过正面化反演模块得到用于人脸正面化的正面化编码wfron后,还需要据此对w进行相应的编辑,因此还设计了潜空间编辑模块来实现这一操作,具体结构如图4 所示。
将输入人脸图像送入GAN 反演模块和正面化反演模块后,得到了人脸图像潜编码w和正面化编码wfron。本文的目标是利用这些潜编码编辑输入人脸图像潜空间编码w来改变面部姿态。因此,将这些编码输入变换器层(Transformer layers)进行融合,得到必要的调整编码ealign,以编辑潜编码w。
在编辑人脸图像潜编码时,并非所有人脸图像潜编码都需要编辑。人脸图像潜编码中共有18 种不同的风格编码,它们控制着面部的不同特征。如果对所有18 个风格编码进行编辑和更改,除了姿势之外,头发等面部特征也会发生重大变化。然而,由于每个风格编码控制的并不是单一的面部特征,也不能完全解耦出单一的面部特征,因此不可能在改变一个特征的同时保持其他特征完全不变。因此,本文要做的就是尽可能减少其他面部特征的变化,为此参考了Lou 等[24] 的研究结果,如表1 所示。在这18 层中,每一层都控制了一个以上的面部特征。本文将这18 个风格编码分为两部分:编辑层wedit和固定层wfix。由于前4 层风格编码主要控制面部姿态和其他特征,因此这4 个层被用作编辑层。其余的固定层不进行任何改变,以尽可能保证除面部姿态外的其他特征的变化。因此,如图4 所示,将编辑层的wedit和调整编码ealign一起送入文本注入模块( Textinjection),实现编辑层的变化。本文提出的结构是对Wei 等[25] 提出的调制模块结构的简化,简化公式如下:
w′edit = k(αwedit +β) (4)
其中,超参数α、β、k通过网络训练得到。通过向两个不同的全连接层网络输入ealign得到相应的参数α和β。文本注入模块主要是通过全连接层实现ealign对wedit的线性变化,从而实现对编辑层的变化,得到编辑后的w′edit。最后,编辑后的编辑层w′edit与固定层wfix结合,得到编辑后的图像编码w′,将其输入预训练的StyleGAN 生成器模型,得到合成的正面图像。
w = w′edit +wfix (5)
1.4 损失函数
在确定网络结构后,还需要确定合适的损失函数来训练网络模型,本文选择多个损失函数的加权组合来监督网络的训练。
(1)身份损失:对于人脸正面化来说,更重要的是保持人脸被翻转前后的身份信息一致。为此,使用Arcface 计算输入人脸图像x与合成的正面人脸图像^x的余弦相似度。
Lid = 1-⟨R(x) ,R( ˆx⟩ (6)
式中, R 是预训练 Arcface 网络, ⟨·,·⟩ 代表计算余弦相似度的算子。
(2)CLIP 损失:为确保最终获得正面人脸,利用CLIP 强大的文本与图像对应功能来监督最终合成的正面人脸图像。
Lclip = 1-⟨ ˆx,Ct (text)⟩ (7)
(3)余弦损失:为了编辑潜编码,使用CLIP 模块结合AEM 来获取与人脸正面化文本编码et相似的图像编码e+i。为了确保在训练过程中获得的e+i与et尽可能相似,还计算了e+i与et之间的余弦相似度。
Lcosin = 1-⟨e+i, et⟩(8)
(4)潜空间损失:在编辑潜空间编码时,为了尽量减少人脸图像细节的变化,还必须控制编辑前后潜空间编码的变化不能太大。因此,潜空间损失的计算方法是输入图像的潜空间编码w与编辑后的潜空间编码w′之间的均方误差。
Llatent = MSE(w,w′) (9)
式中, MSE 代表均方误差。
最后,对4 个损失函数进行加权求和,得出总损失函数。如式(10) 所示,其中λi表示着每项损失的权重参数。
L = λ1Lid +λ2Lclip +λ3Lcosin +λ4Llatent (10)
2 实验结果及分析
为了验证提出方法的有效性和可靠性,本文在不同的数据集上进行了定量和定性实验。
2.1 实验设置
2.1.1 人脸数据集
在训练数据集方面,本文使用了Celeba-HQ 数据集[26]。Celeba-HQ 数据集是一个人脸数据集,是Celeba 数据集的高质量版本。它包含30 000 张分辨率为1 024×1 024 的人脸图像。这些图像涵盖了不同性别、年龄和种族的名人和非名人。每张图像都有40 个属性标签,用于表示脸部的不同特征,如性别、面部表情等。
除此之外, 本文还测试了FFHQ 数据集[21]、Multi-PIE 数据集[27] 和FEI 数据集[28]。FFHQ 数据集是一个高质量的人脸图像数据集,包含70 000 张人脸照片,分辨率尺寸为1 024×1 024。FFHQ 数据集是通过从Flickr 网站搜索包含人脸的图像,并使用自动化流程过滤和处理这些图像,然后使用面部关键点检测技术进行对齐和裁剪,以确保面部位置和姿势的一致性。最终数据集经过人工筛选和质量控制,以确保数据集中包含高质量的人脸图像。
FEI 数据集包含来自不同性别、年龄和种族的200 名受试者的面部图像,每个受试者包含7 种不同的面部表情,即中性、快乐、害怕、愤怒、厌恶、悲伤和惊讶。在相同的照明条件和背景下拍摄,以减少环境变化造成的不一致性。
Multi-PIE 数据集是人脸识别和人脸分析研究领域广泛使用的高质量数据集。它由卡内基梅隆大学的多个研究团队联合创建。Multi-PIE 数据集具有多视角、多光照和多表情的特点,提供了丰富的应用场景。该数据集包含750 000 多张图片,涉及750 多人,每张图片都有15 种不同的照明条件、9 种不同的相机视角和6 种不同的表情状态。这些图像涵盖了现实世界中各种复杂的情况,如不同的光照强度、方向、颜色变化和姿势变化。
2.1.2 实验细节
在实验中使用Adam 优化器训练网络,初始学习率为 0.000 1。此外,通过多次实验对比,将每个损失函数的权重分别设置为λ1=0.2、λ2=0.8、λ3=0.2 和λ4=2.0。所有实验均使用 Pytorch 框架在单个英伟达RTX 2080Ti GPU 上进行训练。
2.2 结果及分析
2.2.1 定性比较
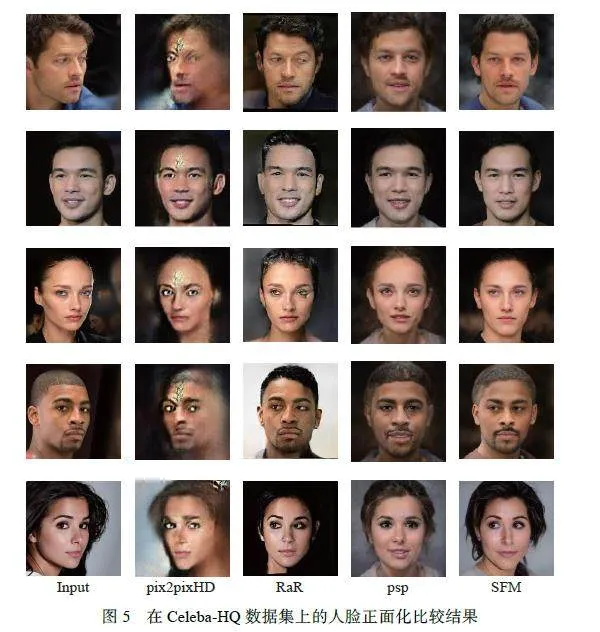
图5 示出了在Celeba-HQ 数据集上测试的正面人脸可视化效果,并与其他不需要成对人脸数据集训练的自监督方法进行了比较。其中,由于pix2pixHD[29] 在没有配对人脸数据集训练的情况下,并不能实现人脸正面化功能,生成的人脸图像不是正面的。pixel2style2pixel(psp)[20] 的方法完成了人脸正面化,但合成的正面人脸图像与真实效果不太接近,图像的风格也发生了变化。Roate-and-Render(RaR)[30] 合成的正面人脸图像效果较好,但由于RaR 是通过三维模型实现的,整体模型较为复杂。此外,图像的背景也发生了很大变化。相比之下,本文方法合成的结果保持了较高的质量和保真度,图像背景变化不大,人脸正面化效果较好。
为了验证本文提出的方法的泛化能力, 还在FFHQ 数据集上进行了测试。除了与已有的自监督方法(psp)进行比较外,还与使用配对人脸数据集训练的其他方法进行了比较。如图6 所示,在训练次数相同的情况下, psp 的效果明显不如本文的方法。psp 得到的人脸并不是很相似,并且图像背景也发生了变化。人脸归一化模型( Face Normalization Model,FNM)[31] 的人脸正面化效果不错,得到正面人脸与源人脸比较相似。但受到训练的成对人脸数据集的限制,FNM 合成的正面人脸图像的背景都大致相似,与相应测试图像的背景变化很大。而完整人脸恢复GAN(Complete Face Recovery GAN,CFR-GAN)[32] 的合成效果也很差,合成的正面人脸图像质量不高,并且与源人脸不太相似。相比之下,本文提出的方法在FFHQ 数据集上也取得了很好的结果,具有良好的泛化能力。
2.2.2 消融实验
本文提出的SFM 中,人脸正面化主要由正面化反演模块完成,因此对其不同的模块组合进行了比较,以验证该方法的有效性。实验过程中设置了4 种不同的实验进行比较:(1)不含身份特征编码器模块和AEM 模块的SFM; ( 2) 不含AEM 模块的SFM;(3)不含身份特征编码器模块的SFM;(4)完整的SFM。本文在Multi-PIE Setting 2 数据集上测试了 30° 、 45° 、 60° 脸部图像。通过测试不同实验设置下的结构相似性指数( StructuralSimilarity Index Metrics,SSIM)指标来评估图像生成的质量,以验证添加不同模块的效果。SSIM 的数值越大, 结构相似度越高。表2 示出了在Multi-PIESetting 2 数据集上对不同实验设置的比较。如表2所示,当使用完整SFM 时,获得的SSIM值最高,生成的图像效果最好。两个模块都未使用时,结果最差。添加两个模块中的一个模块后,SSIM 值都有不同程度的增加。这表明身份特征编码器和AEM 在提升合成正面人脸图像的相似度上都有贡献。这是因为在获取人脸正面化编码的时候,添加了身份特征编码模块来对人脸特征信息进行加强,这样在根据人脸正面化编码对输入人脸图像潜编码进行编辑时就会减少对人脸身份特征信息的影响。同时,通过AEM 模块对人脸正面化进行自适应增强,保证得到的人脸都是正面人脸。因为正面人脸的身份特征信息要多于侧面人脸的身份特征信息,所以添加该模块也会提高相应的人脸相似性。由于本身对于倾斜角度不大的侧面人脸来说,减少的身份特征信息也比较少,所以相应的AEM 模块的增益在SSIM 指标的体现上就会小于身份特征编码器带来的增益。但也可以看到,只有在两个模块都添加的情况下才能取得最高的SSIM 指标,证明了添加这两个模块的必要性。
2.2.3 定量比较
为了将本文的方法与现有方法进行比较,在FFHQ 数据集和FEI 数据集上进行了测试,并计算了相应的指标进行比较。
首先在FFHQ 数据集进行了测试,并将其与模型FNM、psp 和CFR-GAN 进行了比较,结果如表3所示。本文计算了峰值信噪比(Peak Signal-to-NoiseRatio,PSNR)、SSIM 和学习感知图像相似性(LearnedPerceptual Image Patch Similarity, LPIPS) [33] 指标, 其中PSNR 指峰值信噪比,其值越大,合成图像的效果越好;LPIPS 指感知损失,其值越小,两幅图像的感知相似性越高。从表3 可以看出,本文SFM 方法的PSNR 指数最高,而PSNR 主要体现了生成图像的质量,这一部分的优异表现主要取决于StyleGAN 生成器的高质量图像生成能力。除此之外, SSIM 和LPIPS 的指标也是SFM 最优,这两个指标分别从图像方面和人类感知方面计算图像相似度,而SFM 在这两方面的效果都最佳,可见本文的方法得到的正面人脸图像要更接近于真实的正面人脸图像。据此可以看出,本文提出的SFM 要优于其他方法。
此外,为了验证在不同旋转角度下输入人脸后是否具有良好的人脸正面化效果,本文在FEI 数据集的 30° 、 45° 、 75° 和 90° 这 4 个旋转角度下测试了不同的方法,测试结果如表4 所示。可以看出,在不同旋转角度下,SFM 的指标均优于其他方法。随着旋转角度的增大,SFM 的指标变化不大,这表明在姿态旋转角度较大的情况下性能不会下降太多。最后通过计算自由切入距离( Frechet Inception Distance,FID)[34] 来计算人脸的真实度。FID 用于评估生成对抗网络生成图像的质量,分数越低代表着两组图像越相似。在FEI 数据集上测试的结果如表5 所示,SFM 的FID 值在人脸姿态的所有角度都最小,这证明了本文提出方法的优越性。通过定量比较,本文提出的方法优于psp、FNM 和CFR-GAN 方法,表现出良好的性能。
3 总结
本文介绍了一种通过文本编辑实现的自监督人脸正面化网络。整体网络架构基于预训练的StyleGAN 生成器,通过编辑潜空间实现人脸正面化,其中使用e4e 编码器将输入的人脸图像映射到潜空间,从而获得相应的潜编码。为了通过编辑潜编码实现人脸正面化,采用CLIP 模块强大的文本图像转换能力获取潜编码来改变人脸姿态,并增加了人脸特征提取模块和AEM 模块,以保证正面化前后人脸的身份信息保持不变。定性和定量实验表明,本文的方法可以合成高质量、高保真的正面化人脸图像,效果优于其他方法。
参考文献:
[ 1 ]DORDINEJAD G G, ÇEVIKALP H. Face frontalization forimage set based face recognition[C]//2022 30th Signal Processingand Communications Applications Conference(SIU). Safranbolu, Turkey: IEEE, 2022: 1-4.
[ 2 ]LIU Y, CHEN J. Unsupervised face frontalization for poseinvariantface recognition[J]. Image and Vision Computing,2021, 106(12): 104093.
[ 3 ]SHEN Y, GU J, TANG X, et al. Interpreting the latentspace of GANs for semantic face editing[C]//2020IEEE/CVF Conference on Computer Vision and PatternRecognition (CVPR). Seattle, WA, USA: IEEE, 2020:9240-9249.
[ 4 ] YU L, YU J, LI M, et al. Multimodal inputs driven talkingface generation with spatial-temporal dependency[J]. IEEETransactions on Circuits and Systems for Video Technology,2020, 31(1): 203-216.
[ 5 ]PENG C, WANG N, LI J, et al. Face sketch synthesis in thewild via deep patch representation-base"probabilisticgraphical model[J]. IEEE Transactions on InformationForensics and Security, 2019, 15: 172-183.
[ 6 ]ASTHANA A, MARKS T K, JONES M J, et al. Fully automaticpose-invariant face recognition via 3D pose normalization[C]//International Conference on Computer Vision.Barcelona, Spain: IEEE, 2011: 937-944.
[ 7 ]HASSNER T, HAREL S, PAZ E, et al. Effective facefrontalization in unconstrained images[C]//Proceedings ofthe IEEE Conference on Computer Vision and PatternRecognition. Boston, MA, USA: IEEE, 2015: 4295-4304.
[ 8 ]ZHU X, LEI Z, YAN J, et al. High-fidelity pose andexpression normalization for face recognition in thewild[C]//Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition. Boston, MA, USA: IEEE,2015: 787-796.
[ 9 ]BLANZ V, VETTER T. A Morphable Model for the Synthesisof 3D Faces[M]. Seminal Graphics Papers: Pushingthe Boundaries, 2023.
[10]XU Q, WU Z, YANG Y, et al. The difference learning ofhidden layer between autoencoder and variational autoencoder[C]//2017 29th Chinese Control and Decision Conference(CCDC). Chongqing, China: IEEE, 2017: 4801-4804.
[11]KAN M, SHAN S, CHANG H, et al. Stacked ProgressiveAuto-Encoders (SPAE) for face recognition acrossposes[C]//2014 IEEE Conference on Computer Vision andPattern Recognition. Columbus, OH, USA: IEEE, 2014:1883-1890.
[12]NOURABADI N S, DIZAJI K G, SEYYEDSALEHI S A.Face pose normalization for identity recognition using 3Dinformation by means of neural networks[C]//The 5th Conferenceon Information and Knowledge Technology. Shiraz,Iran: IEEE, 2013: 432-437.
[13]JACKSON A S, BULAT A, ARGGYRIOU V, et al. Largepose 3D face reconstruction from a single image via directvolumetric CNN regression[C]//2017 IEEE InternationalConference on Computer Vision (ICCV). Venice, Italy:IEEE, 2017: 1031-1039.
[14]GOODFELLOW I, POUGET-ABADIE J, MIRZA M, et al.Generative adversarial nets[J]. Advances in Neural InformationProcessing Systems, 2014, 27: 2672-2680.
[15]HUANG R, ZHANG S, LI T, et al. Beyond face rotation:Global and local perception GAN for photorealistic andidentity preserving frontal view synthesis[C]//Proceedingsof the IEEE International Conference on Computer Vision.Venice, Italy: IEEE, 2017: 2439-2448.
[16]TRAN L, YIN X, LIU X. Disentangled representationlearning GAN for pose-invariant face recognition[C]//Proceedingsof the IEEE Conference on Computer Vision andPattern Recognition. Hondulu, HI, USA: IEEE, 2017: 1415-1424.
[17]MIRZA M, OSINDERO S. Conditional generative adversarialnets[EB/OL]. (2014-11-6) [2014-12-8]. https://doi.org/10.48550/arXiv.1411.1784.
[18]TU X, ZHAO J, LIU Q, et al. Joint face image restorationand frontalization for recognition[J]. IEEE Transactions onCircuits and Systems for Video Technology, 2021, 32(3):1285-1298.
[19]DUAN Q, ZHANG L, GAO X. Simultaneous face completionand frontalization via mask guided two-stage GAN[J].IEEE Transactions on Circuits and Systems for VideoTechnology, 2022, 32(6): 3761-3773.
[20]RICHARDSON E, ALALUF Y, PATASHNIK O, et al.Encoding in style: A stylegan encoder for image-to-imagetranslation[C]//Proceedings of the IEEE/CVF Conferenceon Computer Vision and Pattern Recognition. Nashville,TN, USA: IEEE, 2021: 2287-2296.
[21]KARRAS T, LAINE S, AILA T. A style-based generatorarchitecture for generative adversarial networks[C]//Proceedings of the IEEE/CVF Conference on ComputerVision and Pattern Recognition. Long Beach, CA, USA:IEEE, 2019: 4401-4410.
[22]TOV O, ALALUF Y, NITZAN Y, et al. Designing anencoder for stylegan image manipulation[J]. ACM Transactionson Graphics (TOG), 2021, 40(4): 1-14.
[23]DENG J, GUO J, XUE N, et al. Arcface: Additive angularmargin loss for deep face recognition[C]//Proceedings ofthe IEEE/CVF Conference on Computer Vision and PatternRecognition. Long Beach, CA, USA: IEEE, 2019:4690-4699.
[24]LOU X, LIU Y, LI X. TeCM-CLIP: Text-based controllablemulti-attribute face image manipulation[C]//Proceedingsof the Asian Conference on Computer Vision. Macau,China:ACCV, 2022: 1942-1958.
[25]WEI T, CHEN D, ZHOU W, et al. Hairclip: Design yourhair by text and reference image[C]//Proceedings of theIEEE/CVF Conference on Computer Vision and PatternRecognition. New Orleans, LA, USA: IEEE, 2022: 18072-18081.
[26]KARRAS T, AILA T, LAINE S, et al. Progressive growingof gans for improved quality, stability, andvariation[EB/OL]. (2017-10-27) [2017-11-3]. https://doi.org/10.48550/arXiv.1710.10196.
[27]GROSS R, MATTHEWS I, COHN J, et al. Multi-PIE[C]//2008 8th IEEE International Conference on AutomaticFace amp; Gesture Recognition. Amsterdam, Netherlands:IEEE, 2008: 1-8.
[28]THOMAZ C E, GIRALDI G A. A new ranking method forprincipal components analysis and its application to faceimage analysis[J]. Image and Vision Computing, 2010,28(6): 902-913.
[29]WANG T C, LIU M Y, ZHU J Y, et al. High-resolutionimage synthesis and semantic manipulation with conditionalGANs[C]//Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition. Salt Lake City, UT,USA: IEEE, 2018: 8798-8807.
[30]ZHOU H, LIU J, LIU Z, et al. Rotate-and-render: Unsupervisedphotorealistic face rotation from single-viewimages[C]//Proceedings of the IEEE/CVF Conference onComputer Vision and Pattern Recognition. Seattle, WA,USA: IEEE, 2020: 5911-5920.
[31]QIAN Y, DENG W, HU J. Unsupervised face normalizationwith extreme pose and expression in the wild[C]//2019IEEE/CVF Conference on Computer Vision and PatternRecognition (CVPR). Long Beach, CA, USA: IEEE, 2019:9843-9850.
[32]JU Y J, LEE G H, HONG J H, et al. Complete facerecovery GAN: Unsupervised joint face rotation andde-occlusion from a single-view image[C]//IEEE/CVFWinter Conference on Applications of Computer Vision(WACV). Waikoloa, HI, USA: IEEE, 2022: 1173-1183.
[33]ZHANG R, ISOLA P, EFROS A, et al. The unreasonableeffectiveness of deep features as a perceptualmetric[C]//Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition. Salt Lake City, USA:IEEE, 2018: 586-595.
[34]HEUSEL M, RAMSAUER H, UNTERTHINER T, et al.Gans trained by a two time-scale update rule converge to alocal nash equilibrium[J]. Advances in Neural InformationProcessing Systems, 2017, 30: 6629-6640.
(责任编辑:李娟)
猜你喜欢
计算机应用(2019年9期)2019-10-31 09:21:33
计算机应用(2019年9期)2019-10-31 09:21:33
移动通信(2019年8期)2019-10-18 09:43:57
软件导刊(2019年8期)2019-10-15 02:21:53
计算机应用(2019年5期)2019-08-01 01:48:57
计算机应用(2019年3期)2019-07-31 12:14:01
软件导刊(2019年6期)2019-07-08 03:41:08
电脑知识与技术(2019年2期)2019-03-15 13:31:28
数字技术与应用(2018年6期)2018-10-31 10:49:24
软件导刊(2018年6期)2018-09-04 09:37:16
