
融合图像增强和迁移学习的YOLOv8n夜间苹果检测方法
2024-01-01 00:00:00仝召茂陈学海马志艳杨光友张灿
华中农业大学学报 2024年5期



关键词 苹果; 夜间检测; 图像增强; 迁移学习; YOLOv8
中国是全球最大的苹果生产国,2021 年产量达到4 597.34 万t,占据全球总产量的54.7%[1-2]。在我国苹果产业快速发展和人力资源短缺的背景下,果农对智能农业装备的需求不断增长[3-4]。视觉系统对苹果采摘机器人具有重要意义[4],同时在苹果的产量估算[5]、果实分拣[6]和表型分析[7]等任务中也起着关键作用。目前,大部分采摘机器人与监控设备都是白天作业,如能利用夜间进行连续作业,将提高全天工作效率,有力地推动苹果产业的发展。
夜间环境下光线弱,采集的图像存在暗淡、模糊和阴影等问题[8],同时枝叶枝干遮挡、果实密集重叠等情况又进一步增加了识别难度,准确识别夜间苹果是有挑战性的任务。近年来,一些研究者基于图像处理的方法对夜间果实检测进行了探索。Font等[9]利用人工光源采集成熟葡萄的RGB 图像,并通过检测葡萄表面的球面反射峰值进行葡萄计数,该方法的平均计数误差为14%;赵德安等[10]将R-G 色差分割法用于苹果采摘机器人夜间检测,该方法仅在良好照明条件下表现较佳,在不考虑果实的粘连和遮挡等因素的前提下,正确识别率为83.7%;戴家裕[11]使用明场漫射正面照明作为夜间补光方式,解决了苹果表面阴影和反光的问题,并通过直方图均衡化和gamma 矫正进一步对图像增强,该方法能够同时克服夜间环境和同色系苹果的识别难点,对绿苹果的识别成功率为87%。随着深度学习技术的发展,以YOLO[12]为代表的目标检测算法广泛应用于夜间果实检测。熊俊涛等[13]借鉴DenseNet[14]的思想改进YOLOv3,增强了模型在夜间复杂环境中检测成熟柑橘的稳健性,精确率达到97.67%,但该方法对暗光图像识别效果欠佳,且容易将密集多目标识别为一个目标。孙宝霞等[15]设计了多光源结合的视觉系统,并基于YOLOv4 对夜间自然环境下成熟柑橘进行识别与表征缺陷检测,准确率为95.3%,该方法的有效性依赖于光源系统的设计。何斌等[16]利用YOLOv5 检测夜间环境中的番茄,但由于番茄的绿果在夜间环境下的颜色容易与叶片、秆茎等混淆,且重叠果实的边界区别较为困难,导致番茄的绿果和多果识别率低于红果。
综上所述,传统图像处理方法在夜间果实检测任务中存在精度低、速度慢和通用性差等局限性,难以满足实际作业要求,基于深度学习的方法具备更优的性能,但也有不足之处,许多研究者沿用白天检测环境的思路,忽视了夜间环境的特殊性,导致面对重叠、遮挡、绿果和光线过暗等情形时检测效果欠佳,同时部分研究还过度依赖于外部辅助光源系统弥补图像质量的不足,此外也没有利用迁移学习策略把日间数据纳入到模型训练中。针对上述问题,本研究提出了一种融合图像增强与迁移学习的YO⁃LOv8n 的夜间苹果检测方法,以期实现对夜间苹果的准确实时检测,从而提升苹果采摘机器人及相关机器视觉设备的全天工作效率。
1 材料与方法
1.1 数据集
本研究将MS COCO 的训练集[17]作为源域数据,其中包含80 个类别的118 287 幅图像,苹果类别的实例个数有5 776 个。目标域数据来自2019 年现代果园环境下苹果图像数据集(https://www.agrida⁃ta.cn/data.html#/datadetail?id=289878),该数据集由华盛顿州立大学农业自动化和机器人实验室创建,用于产量估算和机器人收割,其中含有夜间环境下人工照明的苹果图像273 幅。将拍摄过于模糊、遮挡十分严重等容易对神经网络模型训练时产生误导的苹果图像进行裁剪,以提升数据质量,确保模型可以学到代表性的特征。经过处理后的数据集共1 092幅,包含无遮挡、枝叶枝干遮挡、果实重叠、单目标和多目标果实等多种情景。依据数据标注原则,使用LabelImg 将图像中苹果实例的最小外接矩形标注为真实框,得到包含苹果实例的中心坐标和宽高信息的xml 文件,并保存为PASCAL VOC 格式,标注结果示例如图1 所示。
将标注后的数据集按7∶3 划分,得到764 幅图像的训练集和328 幅图像的测试集。然后,在训练集上采用翻转、适度的模糊和噪声等数据增强技术,以提升模型的适应能力,增强结果示例如图2 所示,经过数据增强后的训练集共有1 528 幅图像。
1.2 检测方法
YOLOv8 是当前主流的目标检测网络之一,具备高效的训练和推理能力,能够准确快速地分类和定位果实目标,根据网络深度和特征图宽度的不同有n、s、m、l、x 5 个版本,以满足不同应用场景的需求。为保证相关机器视觉设备的工作效率,本研究采用复杂度较低的YOLOv8n 模型,并在此基础上搭建适合夜间苹果检测的网络,通过零参考深度曲线估计(zero-reference deep curve estimation,Zero-DCE)[18]模块增强夜间图像,并利用SPD-Conv[19]提取细粒度特征,同时结合迁移学习(transfer learning)策略进一步优化模型性能。
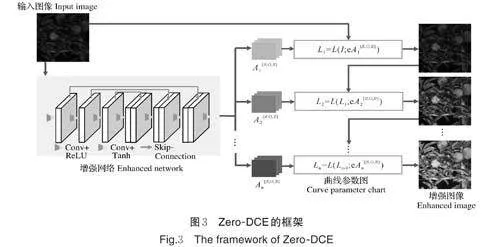
1)Zero-DCE 增强夜间图像。夜间采集的图像整体偏暗,导致部分果实边缘与背景的颜色差异微小,给机器视觉识别带来较大困难,鉴于此,引入Ze⁃ro-DCE 增强夜间图像,更清晰地展现苹果的轮廓和细节,以降低夜间图像识别难度,从而为后续图像处理任务提供基础,Zero-DCE 的框架如图3 所示。
其中,Zero-DCE 以低光图像作为输入,利用DCE-Net 学习曲线参数图,通过亮度增强曲线(lightenhancement curve)对输入的夜间图像进行像素级调整,并经过多次迭代优化输出最终的增强图像,提亮曲线对应的函数表达式为:
式(1)中,x 表示像素坐标,n 为迭代次数,An是与输入图像尺寸相同的参数图。为得到准确的提亮曲线,Zero-DCE 利用DCE-Net 神经网络进行拟合,DCE-Net 包含7 个卷积层和3 个对称跳跃连接层,其中所有卷积层都采用步长为1 的常规3×3 卷积核,为保持相邻像素间的联系,卷积层之后未使用BN层,隐藏层激活函数为ReLU,为确保输出范围落在[-1,1]内,输出层采用Tanh 激活函数。
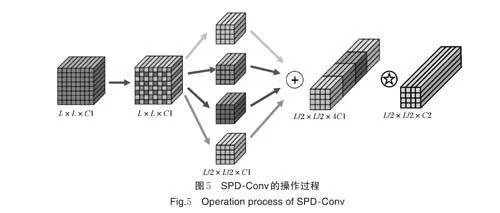
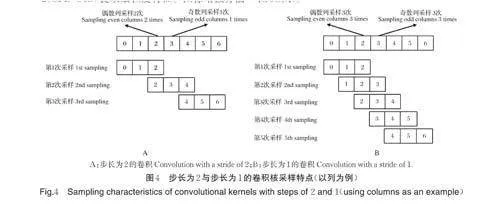
2)SPD-Conv 提取细粒度特征。图像增强方法可以有效降低夜间图像的检测难度,但由于图像分辨率较低,复杂情况下的识别仍然较为困难,因此需要加强模型细粒度特征提取能力。卷积核的步长大小对特征提取的细致程度有重要影响,相较于步长为2 的卷积,步长为1 的卷积能够使特征图的每个像素点被采样多次,并且奇数列和偶数列的采样次数保持一致,这有助于模型提取到细粒度特征,步长为2 与步长为1 的卷积核采样特点如图4 所示。现有的YOLOv8n 网络使用步长为2 的卷积进行下采样和特征提取,这会造成判别特征的丢失。为解决这一问题,在YOLOv8n 中引入SPD-Conv,以使模型提取到更充分、更细致的判别特征,SPD-Conv 通过SPD(space to depth)保持下采样过程中信息的完整性并配合步长为1 的卷积提取细粒度特征,其操作过程如图5 所示。
图5 中,设输入图像形状为L×L×C1,SPD-Conv首先通过SPD 得到4 个形状为L/2×L/2×C1 的子特征图,其次将它们沿着通道维度拼接,获得形状为L/2×L/2×4C1 的特征图,最后使用步长为1 的卷积核提取细粒度特征并调整输出特征图的通道数。
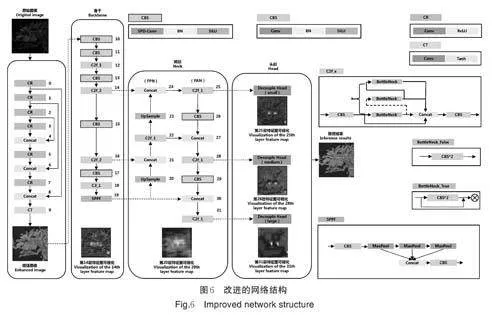
3)改进后的网络。改进后网络的结构如图6 所示,其中选择了一些层次的特征图进行可视化展示。首先Input 通过Zero-DCE 对夜间苹果图像增强,提升夜间图像的清晰度和辨识度,降低夜间场景下苹果的识别难度,为后续的图像处理任务奠定基础;其次Backbone 使用融合SPD-Conv 的CBS、C2f 和SP⁃PF 等模块对增强后的图像进行多层次的特征提取,浅层特征图(14 层)包含丰富的纹理特征,提供较多的位置信息,而深层特征图(20 层)主要包含语义特征,提供较多的类别信息;然后Neck 依次通过FPN、PAN 对Backbone 提取的不同层次的特征图加以利用,将纹理特征与语义特征融合,从而产生更高质量的综合特征;最后通过解耦头(doubled head)分别生成预测目标的类别概率和位置坐标,包括3 个具有不同感受野的检测分支,分别对应25、28 和31 层的特征图,用以检测不同尺度的果实目标,并经过非极大值抑制得到符合需求的检测结果。
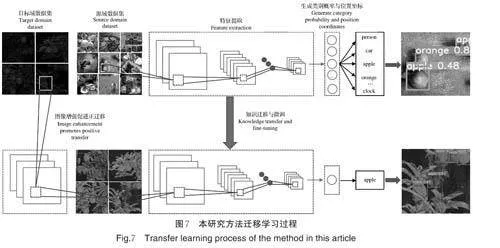
4)迁移学习训练策略。在复杂的夜间环境中,确保模型的通用性和稳定性显得至关重要,这需要大量的、多样的训练数据作为支撑,然而实际场景中数据获取比较困难,且人工标注数据耗时费力,迁移学习可以将一个领域上的预训练模型复用在新领域中,从而降低数据获取和标注的成本。迁移学习的核心思路是借助源域中已有的标注数据,通过算法的开发,最大化地利用这些知识,该过程需要寻找源域和目标域之间的相似性,以便将源域的知识有效地迁移到目标域中[20-21]。为提升迁移学习效果,本研究从源域和目标域对迁移学习策略分别做了改进,本研究所提的迁移学习方法的过程如图7 所示。
其中,针对源域,选取MS COCO 数据集作为源域数据集,与PASCAL VOC[22]等数据集不同,MSCOCO 拥有80 个类别的丰富数据,将MS COCO 作为源域有助于目标域模型习得底层的、普遍性的规则,同时苹果属于其中的一个类别,因此,源域数据中也涵盖了大量的、各种环境下的日间苹果图像,这使得目标域模型在源域模型上微调是容易泛化的。对于目标域,则先将夜间苹果图像数据集送入Zero-DCE 增强,以增加其与日间苹果图像的相似度,促进正迁移的发生,进而在源域模型上微调目标域模型,从而充分利用源域模型中的知识。
1.3 评估指标
本研究将平均精度均值(mean average preci⁃sion,mAP)作为算法质量有效性的评估指标,mAP是基于精确率(percision,P)和召回率(recall,R)计算出来的,精确率P 表示预测的正确样本占总预测样本的比例,召回率R 表示预测的正确样本占实际正确样本的比例,mAP@0.5:0.95 则是模型在不同交并比(intersection over union,IoU)阈值(0.5 至0.95,步长为0.05)下的平均值。另外,将推理速度(单位为帧/s)作为算法实时性的评估指标。
1.4 试验环境与参数设置
模型训练硬件配置为Intel(R) Core(TM) i9-10900KF CPU @ 3.70 GHz,RAM 为64 GB,GPU 为NVIDIA GeForce RTX 3090 24 GB;软件运行环境基于Windows 10(x64)操作系统,采用Python 编程语言和Pytorch 深度学习框架,Python 3.9.18,Pytorch1.13.1,Torchvision 0.14.1,Torchaudio 0.13.1,Cuda11.7.0,Cudnn 8.4.0。
试验采用随机梯度下降法(stochastic gradientdescent,SGD)作为优化器,初始学习率和最终学习率设为0.01,SGD 动量设为0.937,权值衰减参数设为0.000 5,批次大小设为16。运用warm up 训练策略,warm up 轮数设为3,总训练轮数设为100。
2 结果与分析
2.1 训练过程
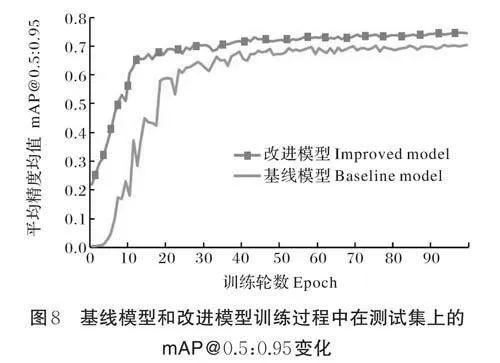
YOLOv8n 基线模型和应用本研究方法得到的改进模型训练过程中在测试集上的mAP0.5:0.95 变化如图8 所示。由图8 可知,对于基线模型,训练初期的较大学习率使mAP@0.5:0.95 快速提升,但也导致了模型的震荡,当训练轮次达到20 左右时,mAP@0.5:0.95 增长速度明显放缓,模型逐步达到饱和,并随着学习率不断减小,曲线逐渐趋于平稳。相比之下,本研究所提方法采用了迁移学习策略,因此曲线起点更高、坡度更陡且渐近线更高,表明本研究方法初始性能更为出色、收敛速度更快且能达到更高的精度。此外,由于迁移学习允许使用较大的学习率训练,本研究方法从训练初期就表现出更好的稳定性。
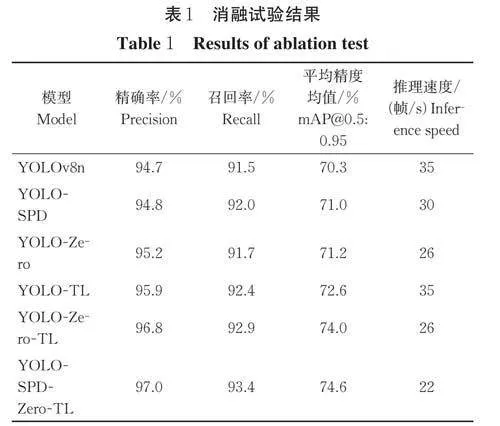
2.2 消融试验
本部分重点就图像增强和迁移学习的改进方法进行了消融试验研究。其中,将YOLOv8n 作为基线模型,记为模型1(YOLOv8n);在模型1 中应用SPDConv,得到模型2(YOLO-SPD);在模型1 中应用Ze⁃ro-DCE,得到模型3(YOLO-Zero);在模型1 中应用迁移学习策略,得到模型4(YOLO-TL);在模型1 中同时应用Zero-DCE 和迁移学习策略,得到模型5(YOLO-Zero-TL);在模型5 中应用SPD-Conv,得到模型6(YOLO-SPD-Zero-TL)。测试结果如表1所示。
由表1 可知,模型2 与模型1(YOLOv8)相比,mAP@0.5:0.95 提升0.7 百分点,这是因为SPDConv可以增强模型细粒度特征的提取能力,从而更准确地识别低分辨率的果实目标;模型3 与模型1 相比,mAP@0.5:0.95 提升了0.9 百分点,说明Zero-CDE 提升了夜间图像的清晰度和辨识度,降低苹果对象的检测难度;模型4 与模型1 相比,mAP@0.5:0.95 提升2.3 百分点,表明迁移学习增强了模型的稳定性和通用性,提升了模型在复杂场景下的检测能力;模型5 与模型1 相比,在mAP@0.5:0.95 表现上提升3.7 百分点,且提升幅度大于模型3 与模型4 增益的总和,这是因为经Zero-DCE 处理的夜间苹果图像有效促进了正迁移;模型6 与模型1 相比,mAP@0.5:0.95 提升4.3 百分点,说明SPD-Conv、Zero-CDE 和迁移学习等改进是可以相互兼容的。此外,从各模型推理速度可以看出,迁移学习策略并未影响模型的推理速度,即使Zero-DCE 和SPD-Conv 在一定程度上降低了推理速度,但是在可接受范围内,而将两者结合使用却能够显著提高模型的精度,这为夜间环境下的果实检测提供了更有效的解决思路。
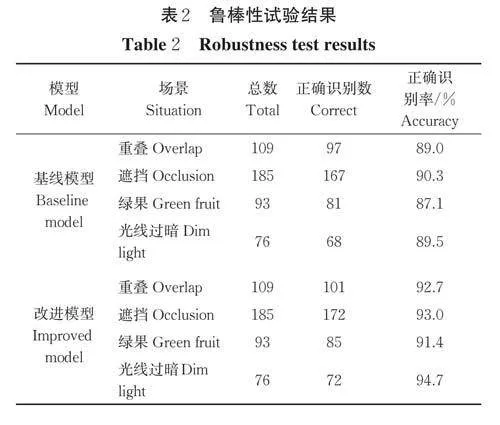
2.3 鲁棒性试验
为探究复杂场景下模型的检测效果,从测试集中随机挑选85 幅图像分别输入到基线模型和应用本研究方法得到的改进模型中进行检测,其中含有重叠、遮挡、绿果、光线过暗的苹果实例个数分别为109、185、93 和76,结果如表2 所示。
由表2 可知,相较于基线模型,改进后的模型在重叠情况下的正确识别率提升3.7 百分点,在遮挡情况下的正确识别率提升2.7 百分点,在绿果情况下的正确识别率提升4.3 个百分点,在光线过暗情况下的正确识别率提升5.2 百分点。对应的检测示例如图9所示,其中正确检测结果采用红色矩形框标记,漏检、误检结果分别采用蓝色和黄色椭圆框标记(上侧、下侧图像分别表示基线模型和本研究所提模型的推理结果)。
由以上结果可知,在面对重叠、遮挡、绿果和光线过暗等复杂情形时,基线模型更容易出现误检和漏检,而本研究所提模型仍然保持较高的检测精度,证明本研究所提模型在稳定性和鲁棒性上表现更好,能够有效地降低夜间苹果检测的误检率和漏检率。
3 讨论
本研究提出了一种融合图像增强与迁移学习的YOLOv8n 苹果夜间检测方法,该方法采用YO⁃LOv8n 模型,通过Zero-DCE 增强夜间图像,并利用SPD-Conv 提取细粒度特征,同时结合迁移学习策略进一步优化模型性能。试验结果表明,本研究所提方法的模型在夜间苹果数据集上的精确率为97.0%,召回率为93.4%,平均精度均值mAP@0.5:0.95 为74.6%,推理速度为22 帧/s,可以满足实时准确检测的需求。
苹果夜间检测具有一定的复杂性,尽管深度学习方法在夜间检测中展现出一定优势,但仍有一些不足。熊俊涛等[13]和何斌等[16]检测夜间果实时仅对YOLO 模型本身改进,尽管取得了一定优化效果,但在密集、重叠、暗光或绿果等情景的果实识别率较低。相比之下,本研究在对YOLOv8n 模型改进的基础上,针对性地引入输入端图像增强方法和迁移学习训练策略,有效地提升了模型在夜间复杂场景下检测苹果的稳定性。
此外,本研究采用的Zero-DCE 夜间图像增强方法基于深度学习技术,可以避免传统图像处理方法[11]导致的模型推理速度慢的问题,而迁移学习策略不增加模型的复杂度,因此本研究模型保持较高检测精度的同时,也具备较好的实时性。
消融试验显示,结合图像增强和迁移学习的方法的效果超过单独应用两者效果的总和。另外,改进后的模型展现出了较强的抗干扰能力,即使在重叠、遮挡、绿果和光线过暗等困难情形下,也能达到良好的识别效果。本研究所提方法为解决夜间果实检测问题提供了一种新的研究思路和技术手段,可为后续的相关研究提供参考。
猜你喜欢
燃气涡轮试验与研究(2021年6期)2021-08-01 03:09:10
海洋信息技术与应用(2020年4期)2021-01-18 06:21:36
中国生物医学工程学报(2019年5期)2019-07-16 07:56:50
北京航空航天大学学报(2017年3期)2017-11-23 05:14:58
知识管理论坛(2016年6期)2017-05-27 19:44:03
振动工程学报(2017年1期)2017-04-21 10:24:46
作文与考试·小学高年级版(2016年17期)2016-12-23 20:21:17
小朋友·快乐手工(2016年10期)2016-12-08 06:15:06
小学生导刊(低年级)(2016年8期)2016-09-24 22:22:30
阅读与作文(小学低年级版)(2016年3期)2016-03-08 22:20:53
